¿Qué es OpenCL?
OpenCL es un marco estándar de la industria para programar computadoras que consta de combinaciones de CPU, GPU y otros procesadores. Estos llamados "sistemas heterogéneos" se han convertido en una clase importante de plataformas, y OpenCL es el primer estándar de la industria que aborda directamente las necesidades de estos sistemas heterogéneos. OpenCL se lanzó por primera vez en diciembre de 2008 y los primeros productos solo salieron en el otoño de 2009, por lo que OpenCL es una tecnología bastante nueva.
Usando OpenCL, es posible escribir un programa que se ejecutará con éxito en una variedad de sistemas, incluidos teléfonos móviles, computadoras portátiles e incluso nodos en supercomputadoras masivas.
OpenCL proporciona un alto grado de portabilidad al exponer el hardware, en lugar de esconderlo detrás de elegantes abstracciones. Esto significa que los programadores de OpenCL deben definir explícitamente plataformas, contextos y programar el trabajo en diferentes dispositivos. No todos los programadores necesitan (o quieren) el control detallado que proporciona OpenCL. Está bien, si hay otras opciones disponibles, el modelo de programación de alto nivel suele ser el mejor enfoque. Sin embargo, incluso un modelo de programación de alto nivel necesita una base sólida (y portátil), y OpenCL puede servir como esa base.
El futuro del multinúcleo: plataformas heterogéneas
El mundo de la informática ha cambiado drásticamente en la última década. En los primeros años, la innovación siempre estuvo impulsada por el rendimiento bruto. Sin embargo, a partir de los últimos años, el enfoque se ha desplazado hacia el rendimiento por vatio de energía consumida. Las empresas de semiconductores seguirán colocando más y más transistores en un chip, pero la competencia entre estos fabricantes ya no es el rendimiento bruto, sino la eficiencia energética.
Este cambio cambió en gran medida las computadoras que producía la industria. En primer lugar, el microprocesador de una computadora se construye a partir de múltiples núcleos de bajo consumo. El concepto de multinúcleo fue propuesto por primera vez por APChandrakasan y otros en su artículo "Optimización de la energía mediante transformaciones". Sus puntos de vista se muestran en la Figura 1-1.
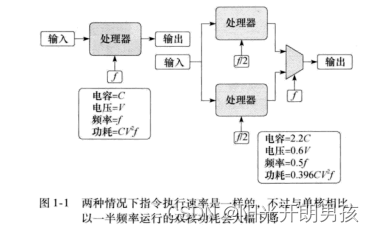
La energía consumida por la conmutación de puerta en la CPU es la capacitancia (C) por el cuadrado del voltaje (V). El número de veces que estas puertas cambian en 1 segundo es igual a la frecuencia. Por lo tanto, el consumo de energía de un microprocesador se calcula como P=CV 2 f. Si compara un procesador de un solo núcleo con frecuencia f y voltaje V con un procesador de doble núcleo similar con cada núcleo a una frecuencia f/2, la cantidad de bucles en el chip aumenta. Siguiendo el modelo descrito en el artículo "Optimización de la potencia mediante transformaciones", esto teóricamente aumenta la capacitancia en un factor de 2,2. Sin embargo, el voltaje se reducirá significativamente a 0,6 V. Entonces, en ambos casos, la cantidad de instrucciones ejecutadas por segundo es la misma, pero el consumo de energía en el procesador de doble núcleo es 0.396 veces mayor que el del procesador de un solo núcleo. Fue esta relación fundamental la que impulsó la transición de los microprocesadores a los chips multinúcleo. El funcionamiento multinúcleo a baja frecuencia tendrá una mejora significativa en la eficiencia energética.
La siguiente pregunta es "¿son estos núcleos iguales (isomorfos) o no?" Para comprender esta tendencia, se debe considerar el rendimiento de potencia de la lógica de propósito especial frente a la lógica de propósito general. Un procesador de propósito general debe, por su naturaleza, incluir una gran cantidad de unidades funcionales para responder a las demandas computacionales. El chip se convierte así en un procesador de propósito general. Sin embargo, los procesadores dedicados a una función en particular no desperdician tantos transistores porque solo contienen las unidades funcionales necesarias para esa función en particular. Los resultados se muestran en la Figura 1-2
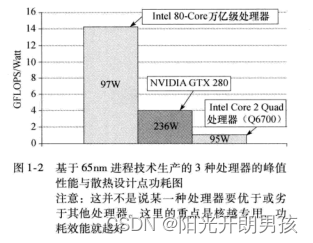
aquí para una CPU de propósito general (Procesador IntelCore 2 Quad (Q6700)), una GPU (NVIDIA GTX 280) y un procesador de investigación bastante especializado (Procesador Intel 80-Core Terascale, en su núcleo es un par de unidades aritméticas de suma y multiplicación de coma flotante) para comparar. Para que el proceso de comparación sea lo más justo posible, cada chip se fabrica con tecnología de proceso de 65 nm y utilizamos el rendimiento máximo y el consumo de energía del punto de diseño térmico publicados por el fabricante. De la Figura 1-2 queda claro que cuanto más especializado sea el chip, mejor será la eficiencia energética, siempre que las tareas coincidan bien con el procesador.
Por lo tanto, es razonable creer que en un mundo que pone mucho énfasis en maximizar el rendimiento por vatio, es totalmente plausible que los sistemas dependan cada vez más de múltiples núcleos y, cuando sea factible, aprovechen el silicio especializado. Esto es especialmente importante para los dispositivos móviles, donde la conservación de energía es fundamental. Sin embargo, la tendencia heterogénea ya está frente a nosotros. Considere el diagrama esquemático de una PC moderna (vea la Figura 1-3).
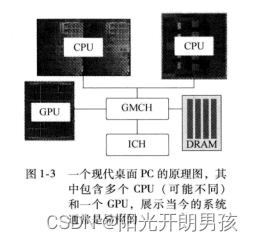
Aquí hay dos zócalos, y cada zócalo puede instalar diferentes CPU multinúcleo, un controlador de gráficos/memoria (GMCH) conectado a la memoria del sistema (DRAM) y una unidad de procesamiento de gráficos (Unidad de procesamiento de gráficos, CPU). Esta es una plataforma heterogénea que ofrece múltiples conjuntos de instrucciones y niveles de paralelismo que deben aprovecharse al máximo para maximizar las capacidades del sistema.
Ya sea ahora o en el futuro, a un alto nivel, la plataforma básica es clara. Si bien la plétora de detalles y las numerosas ideas nuevas seguramente nos sorprenderán, la tendencia del hardware es clara. El futuro definitivamente está dominado por plataformas multinúcleo heterogéneas. La pregunta que enfrentamos es cómo encaja el software en estas plataformas.
Software en un mundo multinúcleo
El hardware paralelo mejora el rendimiento al ejecutar múltiples operaciones simultáneamente. Para ser útil, el hardware paralelo requiere una ejecución de software que pueda ejecutarse simultáneamente como múltiples flujos de operaciones, en otras palabras, necesitamos un software paralelo.
Para entender el software paralelo, primero debemos entender un concepto más general: la concurrencia. La concurrencia es un concepto antiguo en informática con el que todos estamos familiarizados. Se dice que un sistema de software es concurrente cuando contiene múltiples flujos activos de operaciones que avanzan simultáneamente. La concurrencia es importante en todos los sistemas operativos modernos. Mientras que algunos flujos de operación (subprocesos) están esperando ciertos recursos, se permite que continúen otros flujos de operación, lo que puede maximizar la utilización de recursos. A través de la concurrencia, los usuarios que interactúan con el sistema también tienen la ilusión de que la interacción con el sistema es continua y casi instantánea.
Cuando el software concurrente se ejecuta en una computadora con múltiples unidades de procesamiento, los subprocesos pueden ejecutarse concurrentemente, lo que permite la computación paralela. La concurrencia soportada por el hardware es el paralelismo.
Es muy difícil para los programadores averiguar la concurrencia en el problema, expresar esta concurrencia en el software y luego ejecutar el programa resultante para proporcionar el rendimiento requerido a través de la concurrencia. Encontrar simultaneidad en un problema puede ser tan simple como ejecutar un flujo de operaciones separado para cada píxel en una imagen. O podría ser extremadamente complejo, con múltiples flujos de operaciones que comparten información, cuya ejecución debe estar estrechamente coordinada.
Una vez que se identifica la concurrencia en el problema, los programadores deben expresar esta concurrencia en su código fuente. Específicamente, es necesario definir flujos de operaciones ejecutados simultáneamente, asociarles tiempos de ejecución y administrar las dependencias entre estos flujos de operaciones para garantizar que la ejecución de estos flujos de operaciones en paralelo pueda generar resultados correctos. Este es el problema central de la programación paralela.
La mayoría de las personas no están preparadas para lidiar con los detalles de bajo nivel de la computación paralela. Incluso un programador paralelo experto no puede manejar la carga de administrar cada conflicto de memoria o programar un solo hilo. Por lo tanto, la clave para la programación paralela es una abstracción o modelo de alto nivel (modelo), que hace que los problemas de programación paralela sean más manejables.
Existen demasiados modelos de programación, a menudo divididos en diferentes categorías, pero estas categorías se superponen y los nombres de las categorías suelen ser vagos y confusos. Para nuestros propósitos, consideraremos dos modelos de programación paralela: paralelismo de tareas y paralelismo de datos. A un alto nivel, la idea básica detrás de estos dos modelos es simple.
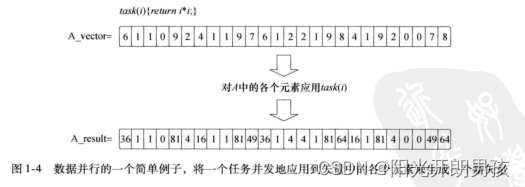
En el modelo de programación paralela de datos, el programador piensa en términos de una colección de elementos de datos que se pueden actualizar simultáneamente. El paralelismo se expresa como la aplicación simultánea del mismo flujo de instrucciones (una tarea) a cada elemento de datos, y el paralelismo se refleja en los datos. Proporcionamos un ejemplo simple de paralelismo de datos en la figura 1-4. Considere una tarea simple: devuelva el cuadrado de un vector de entrada de números (A_vector). Utilizando el modelo de programación de datos paralelos, un vector se actualiza en paralelo aplicando tareas a cada elemento del vector, produciendo un nuevo vector de resultados. Por supuesto, este ejemplo es muy simple. En la práctica, la cantidad de operaciones en una tarea debe ser grande para amortizar la sobrecarga del movimiento de datos y administrar el cómputo paralelo. Sin embargo, el ejemplo simple de la Figura 1-4 ilustra completamente la idea central de este modelo de programación.
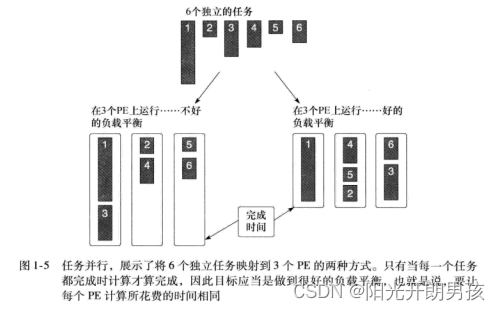
En el modelo de programación paralela de tareas, los programadores definen y procesan directamente tareas concurrentes. El problema se descompone en tareas que pueden ejecutarse simultáneamente y luego se asignan a una unidad de procesamiento (Elemento de procesamiento, PE) de una computadora paralela para su ejecución. Este modelo es más fácil de usar si las tareas son completamente independientes, pero también se puede usar para tareas que comparten datos. Si se va a realizar un cálculo utilizando un conjunto de tareas, el cálculo no se completa hasta que se completa la última tarea. Debido a que las demandas computacionales de las tareas varían ampliamente, puede ser difícil distribuir tareas para que se completen aproximadamente al mismo tiempo. Este es un problema de equilibrio de carga. Considere el ejemplo de la Figura 1-5, donde seis tareas independientes se ejecutan simultáneamente en tres unidades de procesamiento. En el primer caso, la primera unidad de procesamiento tiene demasiado trabajo que hacer y tarda mucho más en ejecutarse que las otras unidades de procesamiento. El segundo caso usa una distribución diferente de tareas, y aquí hay un caso más ideal donde cada unidad de procesamiento se completa casi simultáneamente. Este es un ejemplo de una idea central en la computación paralela, el equilibrio de carga.
La elección entre el paralelismo de datos y el paralelismo de tareas está determinada por las necesidades específicas del problema que se está resolviendo. Por ejemplo, problemas relacionados con la actualización de nodos en un mapa de cuadrícula inmediatamente a un modelo de datos paralelos. Por otro lado, un problema formulado como un gráfico transversal puede naturalmente considerar un modelo paralelo de tareas. Por lo tanto, un programador paralelo completo debe estar familiarizado con ambos modelos de programación. Además, como marco de programación de propósito general (como OpenCL), también debe ser compatible con ambos modelos.
Además del modelo de programación, el próximo paso en el proceso de programación paralela es mapear el programa al hardware real. Aquí, las computadoras heterogéneas plantean problemas únicos. Las unidades de cómputo en un sistema pueden tener diferentes conjuntos de instrucciones y diferentes arquitecturas de memoria, y pueden ejecutarse a diferentes velocidades. Un programa eficiente y viable debe comprender estas diferencias y ser capaz de asignar correctamente el software paralelo al dispositivo OpenCL más adecuado.
A menudo, los programadores abordan este problema imaginando su software como un conjunto de módulos que implementan diferentes partes del problema. Estos módulos están vinculados explícitamente a componentes en plataformas heterogéneas. Por ejemplo, el software de gráficos se ejecuta en la GPU y otro software se ejecuta en la CPU.
La programación de GPU de propósito general (GPGPU) rompe este modelo. Los algoritmos distintos de los gráficos se modifican para que sean adecuados para el procesamiento de GPU. La CPU hace los cálculos y administra los VO, pero todos los cálculos "sustanciales" se "comparten" con la GPU. Básicamente, se ignoran las plataformas heterogéneas y la atención se centra en un componente del sistema: la GPU.
OpenCL no recomienda este enfoque. De hecho, dado que el usuario ha pagado por "todos los dispositivos OpenCL" en el sistema, un programa válido debería usarlos todos. Este es exactamente el enfoque que OpenCL alienta a los programadores a adoptar, y también es nuestra expectativa para los entornos de programación de diseño de plataformas heterogéneas.
La heterogeneidad del hardware es compleja. Los programadores confían cada vez más en abstracciones de alto nivel que ocultan la complejidad del hardware. Los lenguajes de programación heterogéneos anuncian heterogeneidad, yendo en contra de la tendencia de una mayor abstracción.
Esto no es problema. Un lenguaje no tiene que abordar las necesidades de cada comunidad de programadores. El marco de alto nivel que simplifica los problemas de programación se puede asignar a un lenguaje de alto nivel, que se asigna aún más a la capa de abstracción de hardware subyacente para garantizar la portabilidad. OpenCL es exactamente esta capa de abstracción de hardware.