1 Parámetros conocidos que pueden afectar los efectos del diálogo (ubicados en el archivo configs/model_config.py):
# 文本分句长度
SENTENCE_SIZE = 100
# 匹配后单段上下文长度
CHUNK_SIZE = 250
# 传入LLM的历史记录长度
LLM_HISTORY_LEN = 3
# 知识库检索时返回的匹配内容条数
VECTOR_SEARCH_TOP_K = 5
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准
VECTOR_SEARCH_SCORE_THRESHOLD = 0
Entre ellas, las variables que pueden tener un mayor impacto en la lectura de la base de conocimiento son CHUNK_SIZE (la longitud de un solo contexto de referencia), VECTOR_SEARCH_TOP_K (el número de párrafos de referencia en la base de conocimiento) y VECTOR_SEARCH_SCORE_THRESHOLD (la correlación mínima requerida para hacer coincidir contenido de la base de conocimientos). Este experimento preguntará a los modelos bajo diferentes configuraciones de parámetros y clasificará las respuestas de diferentes modelos a cada pregunta. Finalmente, experimentamos con la prueba de Friedman y la prueba de seguimiento de Nemenyi para analizar si las clasificaciones de respuesta de diferentes modelos son significativamente diferentes.
2 Preguntas de diseño
La base de conocimiento del modelo utiliza el libro "Introducción al aprendizaje profundo: teoría e implementación basada en Python" como base de conocimiento. Las preguntas al modelo cubren los siguientes tipos:
Tipo de conocimiento (K - conocimiento): conocimiento general sobre el aprendizaje profundo, no necesariamente necesita confiar en el contenido de la base de conocimiento para responder, pero el tipo de contenido de respuesta de referencia (C - contexto
) de la base de conocimientos: sobre el libro Las preguntas sobre contenido específico solo se pueden responder apoyándose en la base de conocimientos.
Las preguntas también se pueden dividir en las siguientes dos categorías:
tipo general (G - general): preguntas sobre conocimientos conceptuales generales, o requieren un resumen de parte del contenido del libro en detalle
(S - específico): Haga preguntas sobre el conocimiento de aprendizaje profundo o detalles técnicos del contenido del libro
Cada pregunta se describe usando las siguientes dos clasificaciones. Por ejemplo, KG significa preguntas de conocimiento general, como "qué es el aprendizaje profundo", y CS significa preguntas específicas de contenido, como "¿qué conjunto de datos se usó como entrenamiento?" ejemplo para el ejemplo de reconocimiento de dígitos escritos a mano en el libro?" conjunto de datos". Se diseñaron 5 preguntas para cada categoría, y se hicieron un total de 20 preguntas para el modelo.
Preguntas de diseño
KG:
1 Qué es el aprendizaje profundo
2 Qué es una red neuronal
3 Qué es una red neuronal convolucional
4 Una breve introducción a la retropropagación de redes neuronales
5 Qué es el sobreajuste de redes neuronales y cómo evitarlo
CG:
1 libro Qué tipos de redes neuronales se presentan principalmente
2 Qué tipos de métodos para actualizar los parámetros de redes neuronales se presentan en el libro
3 Qué tipos de funciones de activación comúnmente utilizadas se presentan en el libro
4 Qué tipos de métodos para establecer el valor inicial de los pesos de las redes neuronales se presentan en el libro
5 ¿Qué tipos de métodos
KS ?
1 ¿Por qué el valor inicial de los pesos de las redes neuronales no puede establecerse en 0?
2 ¿Por qué el cálculo de los gradientes de peso generalmente usa propagación hacia atrás en lugar de diferenciación numérica
? las funciones de activación no lineales se pueden profundizar El número de capas de red
4 ¿Cuáles son las funciones de la capa convolucional y la capa de agrupación de la red neuronal convolucional?
5 Por qué el conjunto de datos de entrenamiento y el conjunto de datos de prueba deben estar separados
CS:
1 ¿Qué función de activación es utilizado para la capa de salida de la red neuronal que resuelve el problema de clasificación en el libro
2 ¿Qué conjunto de datos se utiliza como conjunto de datos de entrenamiento en el programa de muestra de reconocimiento de dígitos escritos a mano en el libro
3 ¿Por qué el programa de muestra de reconocimiento de dígitos escritos a mano en el proceso por lotes del libro el conjunto de datos de entrada
4 ¿Cuáles son las ventajas de la normalización por lotes mencionadas en el libro
5 ¿Qué se menciona en el libro Condiciones propensas al sobreajuste
Para cada tipo de pregunta, clasificamos de acuerdo con los siguientes criterios:
Pregunta K:
1 Corrección de la respuesta: si hay errores de conocimiento en la respuesta del modelo
2 Relevancia de la cita: si el texto original citado por el modelo está relacionado con la respuesta
Pregunta C:
1 Exhaustividad del contenido: si el modelo relata correctamente todo el contenido relevante del libro
2 Ajuste del texto original: si el modelo está fabricado y el contenido no se menciona en el libro (si la parte fabricada es correcta o no) 3
Cita relevancia: si el contenido original citado por el modelo está relacionado con la respuesta
3 Pasos experimentales
1 Modifique los parámetros relevantes en el archivo de configuración del modelo, inicie el programa webui.py de langchain-ChatGLM para abrir la interfaz de preguntas en línea
2 En la interfaz de preguntas, elija importar la "Introducción al aprendizaje profundo: basado en la teoría y la implementación". en Python" archivo pdf como base de conocimiento.
3 Pase las 20 preguntas diseñadas anteriormente al modelo una por una, mantenga la respuesta completa del modelo y guarde la cita del texto original
4 Repita los pasos 1 a 3 con diferentes configuraciones de parámetros
grupo de prueba:
1 VECTOR_SEARCH_SCORE_THRESHOLD tiene un impacto en los efectos del diálogo
Número de serie CHUNK_SIZE VECTOR_SEARCH_TOP_K VECTOR_SEARCH_SCORE_THRESHOLD
1 250 5 0
2 250 10 0
3 500 5 0
4 250 5 500
puntaje de respuesta

Análisis de datos:
después de usar la prueba de Friedman y la prueba posterior de Nemenyi (para un análisis específico, consulte la puntuación del diálogo del modelo de archivo de Excel). No hay diferencia significativa en la capacidad de los cuatro modelos para responder a todo tipo de preguntas (valor p = 0,8368)




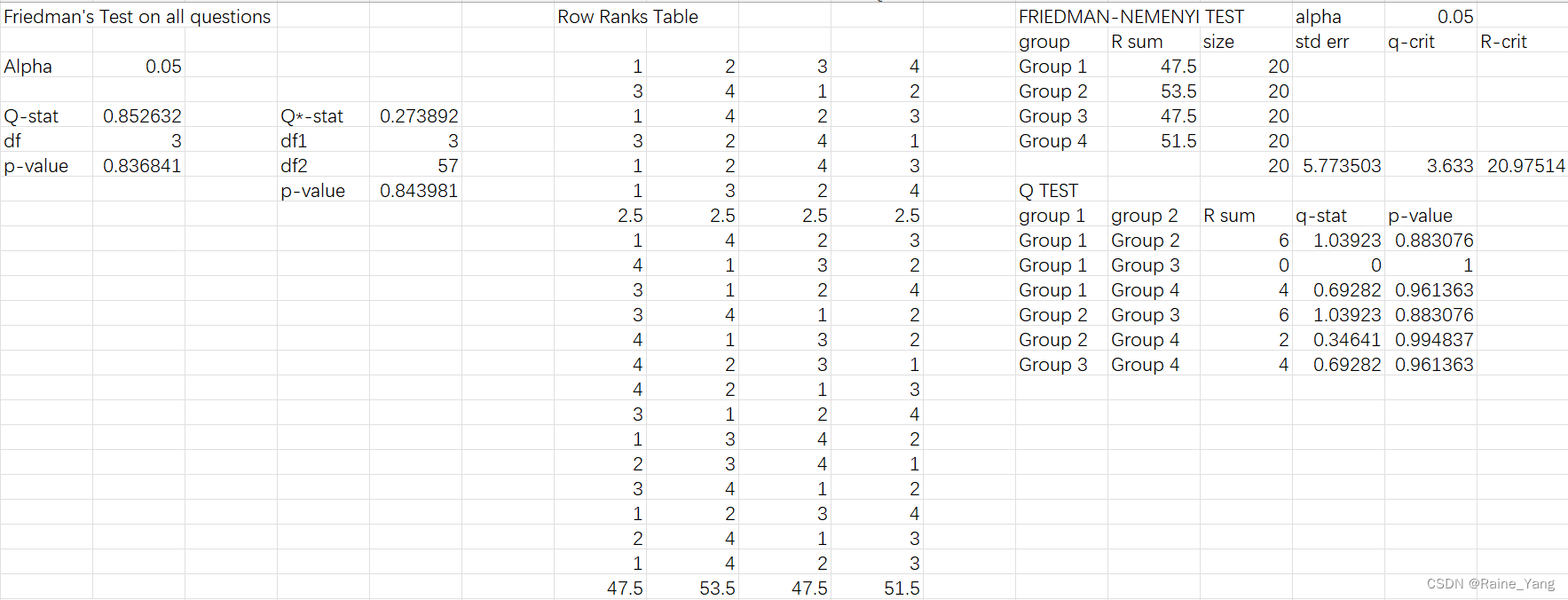
Para las respuestas a las cuatro preguntas de clasificación (conocimiento, contenido, general y detalle), aún no hay diferencia significativa en las respuestas de los cuatro modelos. Vale la pena señalar que para las preguntas de tipo de contenido, los cuatro modelos ven una gran brecha, y el modelo 1 y el modelo 2, el modelo y el modelo 3 tienen una gran brecha entre grupos. Pero estas diferencias no son estadísticamente significativas (valor de p general = 0,233, valor de p de la prueba Q del modelo 1 y del modelo 2 = 0,350, valor de p de la prueba Q del modelo 2 y del modelo 3 = 0,350).
Conclusiones experimentales y sugerencias de ajuste de parámetros:
el modelo langchain-ChatGLM combinado con la base de conocimiento local para responder la respuesta se verá afectado por los parámetros CHUNK_SIZE, VECTOR_SEARCH_TOP_K, VECTOR_SEARCH_SCORE_THRESHOLD. Pero estos cambios de parámetros no tuvieron un efecto significativo en la precisión general de las respuestas del modelo.
También vale la pena señalar que en el segundo y tercer grupo de experimentos, el mayor CHUNK_SIZE y VECTOR_SEARCH_TOP_K hacen que el contenido de respuesta del modelo sea significativamente más largo, lo que hace que el modelo aumente significativamente el consumo de memoria del servidor. (En los grupos 1 y 4, la memoria de video generalmente está llena cuando hay alrededor de 15 preguntas, mientras que en los grupos 2 y 3, solo se necesitan de 1 a 2 preguntas). En aplicaciones prácticas, estos dos parámetros deben seleccionarse adecuadamente con valores más bajos, o directamente utilizar los valores iniciales predeterminados de 250 y 5
Puede haber las siguientes lagunas en este experimento:
1. Solo se usó el libro "Introducción al aprendizaje profundo: teoría e implementación basada en Python" para realizar pruebas al seleccionar los datos de la base de conocimientos. No hay una prueba sobre una base de conocimiento a gran escala, ni se prueba si la introducción de textos de diferentes temas en la misma base de conocimiento interferirá con el modelo.La
memoria es graduada, lo que tiene un cierto grado de subjetividad. Además, debido a la imposibilidad de realizar experimentos doble ciego, mis expectativas para diferentes modelos pueden causar errores en la puntuación.
3 respuestas LLM hacen referencia a conversaciones históricas. Dado que sería demasiado lento y laborioso reiniciar el modelo para cada pregunta y respuesta, en este experimento, la ronda actual de diálogo solo terminará cuando la memoria del modelo esté llena, lo que hace que los problemas históricos del modelo puede tener un impacto en las respuestas del modelo.
En vivo: el diálogo completo es demasiado largo (casi 100,000 palabras) para mostrarse en el artículo