Debido a que es necesario brindar varios servicios de red a millones, decenas de millones o incluso más de 100 millones de usuarios, uno de los requisitos clave para entrevistar y promover a los estudiantes de desarrollo de back-end en empresas de Internet de primera línea es poder soportar alta la concurrencia y comprender la sobrecarga de rendimiento, se optimizará para el rendimiento. Y muchas veces, si no tiene un conocimiento profundo de Linux subyacente, sentirá que no tiene forma de comenzar cuando se encuentre con muchos cuellos de botella en el rendimiento en línea.
Hoy, usamos un método gráfico para entender profundamente el proceso de recepción de paquetes de red bajo Linux. O siga la convención para tomar prestada la pieza de código más simple para comenzar a pensar. Para simplificar, usamos udp como ejemplo, de la siguiente manera:
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0'; printf("Receive from client:%s\n", buff);
}El código anterior es una parte de la lógica para que el servidor UDP reciba recibos. Al verlo desde una perspectiva de desarrollo, siempre que el cliente envíe los datos correspondientes, el servidorrecv_from puede recibirlos e imprimirlos después de la ejecución . Lo que queremos saber ahora es, cuando el paquete de red llega a la tarjeta de red, hasta que recibimos recvfromlos datos, ¿qué pasó en el medio?
A través de este artículo, tendrá una comprensión profunda de cómo se implementa internamente el sistema de red de Linux y cómo interactúa cada parte. Creo que esto será de gran ayuda para su trabajo. Este artículo se basa en Linux 3.10. Consulte https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ para obtener el código fuente. El controlador de la tarjeta de red usa la tarjeta de red igb de Intel como ejemplo.
Recordatorio amistoso, este artículo es un poco largo, ¡puedes marcarlo primero y luego leerlo!
Una descripción general de la recepción de paquetes de red de Linux
En el modelo de capas de red TCP/IP, toda la pila de protocolos se divide en capa física, capa de enlace, capa de red, capa de transporte y capa de aplicación. La capa física corresponde a las tarjetas y cables de red, y la capa de aplicación corresponde a nuestras aplicaciones comunes Nginx, FTP y otras. Linux implementa tres capas: capa de enlace, capa de red y capa de transporte.
En la implementación del kernel de Linux, el controlador de la tarjeta de red implementa el protocolo de la capa de enlace, y la pila del protocolo del kernel implementa la capa de red y la capa de transporte. El núcleo proporciona una interfaz de socket a la capa superior de la aplicación para que accedan los procesos de usuario. El modelo de capas de red TCP/IP que vemos desde la perspectiva de Linux debería verse así.

Figura 1 Pila de protocolos de red desde la perspectiva de Linux
En el código fuente de Linux, se encuentra la lógica correspondiente al controlador del dispositivo de red driver/net/ethernet, y el controlador de la tarjeta de red de la serie Intel está en driver/net/ethernet/intelel directorio. El código del módulo de la pila de protocolos se encuentra en el directorio kernely net.
Los controladores de dispositivos de red y kernel se manejan mediante interrupciones. Cuando los datos llegan al dispositivo, activará un cambio de voltaje en el pin correspondiente de la CPU para notificar a la CPU que procese los datos. Para el módulo de red, debido al procesamiento complejo y lento, si todo el procesamiento se completa en la función de interrupción, la función de procesamiento de interrupción (con una prioridad demasiado alta) ocupará la CPU en exceso y la CPU no podrá responder a otros dispositivos Por ejemplo, mensajes de mouse y teclado. Por lo tanto, la función de procesamiento de interrupciones de Linux se divide en la mitad superior y la mitad inferior. La parte superior es hacer el trabajo más simple, procesar rápidamente y luego liberar la CPU, y luego la CPU puede permitir que entren otras interrupciones. La mayor parte del resto del trabajo se coloca en la mitad inferior, que se puede manejar lenta y tranquilamente. La mitad inferior del método de implementación adoptado por la versión del kernel después de la 2.4 es la interrupción suave, que es manejada completamente por el subproceso del kernel ksoftirqd. A diferencia de las interrupciones duras, las interrupciones duras aplican cambios de voltaje a los pines físicos de la CPU, mientras que las interrupciones suaves notifican al controlador de interrupciones suaves dando un valor binario a una variable en la memoria.
Bueno, después de obtener una comprensión general de los controladores de tarjetas de red, las interrupciones duras, las interrupciones suaves y los subprocesos ksoftirqd, daremos un diagrama esquemático de la ruta para que el núcleo reciba paquetes en función de estos conceptos:

Figura 2 Descripción general de la red del kernel de Linux que recibe paquetes
Cuando se reciben datos en la tarjeta de red, el primer módulo de trabajo en Linux es el controlador de red. El controlador de red escribirá el marco recibido en la tarjeta de red en la memoria mediante DMA. Luego inicie una interrupción a la CPU para notificar a la CPU que han llegado datos. En segundo lugar, cuando la CPU recibe una solicitud de interrupción, llamará al controlador de interrupción registrado por el controlador de red. La función de procesamiento de interrupciones de la tarjeta de red no hace demasiado trabajo, envía una solicitud de interrupción suave y luego libera la CPU lo antes posible. Cuando ksoftirqd detecta que llega una solicitud de interrupción suave, llama a sondeo para comenzar a sondear y recibir paquetes, y después de recibirlo, se entrega a las pilas de protocolos en todos los niveles para su procesamiento. Para los paquetes UDP, se colocarán en la cola de recepción del socket del usuario.
De la imagen de arriba, hemos captado el proceso de procesamiento de Linux en el paquete de datos como un todo. Pero si queremos comprender más detalles sobre el funcionamiento del módulo de red, tenemos que mirar hacia abajo.
Arranque de dos Linux
El controlador de Linux, la pila de protocolos del kernel y otros módulos deben realizar una gran cantidad de trabajo preparatorio antes de que puedan recibir paquetes de datos de la tarjeta de red. Por ejemplo, el subproceso del kernel ksoftirqd debe crearse con anticipación, las funciones de procesamiento correspondientes a cada protocolo deben registrarse, el subsistema del dispositivo de red debe inicializarse con anticipación y la tarjeta de red debe iniciarse. Solo después de que estos estén listos, podemos comenzar a recibir paquetes. Así que echemos un vistazo a cómo se hacen estos preparativos.
2.1 Crear hilo del núcleo ksoftirqd
Todas las interrupciones suaves de Linux se realizan en un hilo de kernel dedicado (ksoftirqd), por lo que es muy necesario que veamos cómo se inicializan estos procesos, para que podamos comprender el proceso de recepción de paquetes con mayor precisión más adelante. El número de procesos no es 1, sino N, donde N es igual al número de núcleos de su máquina.
Cuando se inicializa el sistema, se llama a smpboot_register_percpu_thread en kernel/smpboot.c, y esta función se ejecutará posteriormente en spawn_ksoftirqd (ubicado en kernel/softirq.c) para crear un proceso softirqd.

Figura 3 Crear subproceso de kernel ksoftirqd
El código correspondiente es el siguiente:
//file: kernel/softirq.c
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",};static __init int spawn_ksoftirqd(void){
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0;
}
early_initcall(spawn_ksoftirqd);Cuando se crea ksoftirqd, ingresará su propia función de bucle de subprocesos ksoftirqd_should_run y run_ksoftirqd. Evalúe constantemente si hay una interrupción suave que necesita ser procesada. Una cosa a tener en cuenta aquí es que las interrupciones suaves no son solo interrupciones suaves de red, sino también otros tipos.
//file: include/linux/interrupt.henum{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
};2.2 Inicialización del subsistema de red

Figura 4 Inicialización del subsistema de red
El kernel de Linux subsys_initcallinicializa varios subsistemas a través de llamadas, y puede realizar muchas llamadas a esta función en el directorio del código fuente. De lo que estamos hablando aquí es de la inicialización del subsistema de red, que ejecutará net_dev_initla función.
//file: net/core/dev.c
static int __init net_dev_init(void){
......
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
memset(sd, 0, sizeof(*sd));
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
sd->completion_queue = NULL;
INIT_LIST_HEAD(&sd->poll_list);
......
}
......
open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
subsys_initcall(net_dev_init);softnet_dataEn esta función, se aplicará una estructura de datos para cada CPU. En esta estructura de datos, poll_listestá esperando que el controlador registre su función de encuesta. Podemos ver este proceso cuando se inicializa el controlador de la tarjeta de red más adelante.
Además, open_softirq registra una función de procesamiento para cada interrupción suave. La función de procesamiento de NET_TX_SOFTIRQ es net_tx_action y la de NET_RX_SOFTIRQ es net_rx_action. Después de continuar con el seguimiento, open_softirqencontré que el método de registro está registrado en softirq_vecla variable. Cuando el subproceso ksoftirqd recibe una interrupción suave más tarde, también utilizará esta variable para encontrar la función de procesamiento correspondiente a cada interrupción suave.
//file: kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *)){
softirq_vec[nr].action = action;
}2.3 Registro de la pila de protocolos
El kernel implementa el protocolo ip en la capa de red, así como el protocolo tcp y el protocolo udp en la capa de transporte. Las funciones de implementación correspondientes a estos protocolos son ip_rcv(), tcp_v4_rcv() y udp_rcv() respectivamente. A diferencia de la forma en que solemos escribir código, el núcleo se implementa a través del registro. fs_initcallSimilar al kernel de Linux subsys_initcall, también es el punto de entrada del módulo de inicialización. Inicie el registro de la pila de protocolos de red después de fs_initcallllamar . inet_initAprobadas inet_init, estas funciones se registran en las estructuras de datos inet_protos y ptype_base. Como se muestra abajo:

Figura 5 Registro de la pila de protocolos AF_INET
El código relevante es el siguiente
//file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,};static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,};static const struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1, .netns_ok = 1,
};
static int __init inet_init(void){
......
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
...... dev_add_pack(&ip_packet_type);
}En el código anterior, podemos ver que el controlador en la estructura udp_protocol es udp_rcv, y el controlador en la estructura tcp_protocol es tcp_v4_rcv, que se inicializa a través de inet_add_protocol.
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol], NULL, prot) ? 0 : -1;
}inet_add_protocolLa función registra las funciones de procesamiento correspondientes a tcp y udp en la matriz inet_protos. Mire dev_add_pack(&ip_packet_type);esta línea nuevamente, el tipo en la estructura ip_packet_type es el nombre del protocolo, y func es la función ip_rcv, que se registrará en la tabla hash ptype_base en dev_add_pack.
//file: net/core/dev.c
void dev_add_pack(struct packet_type *pt){
struct list_head *head = ptype_head(pt); ......
}
static inline struct list_head *ptype_head(const struct packet_type *pt){
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}Aquí debemos recordar que inet_protos registra la dirección de la función de procesamiento udp y tcp, y ptype_base almacena la dirección de procesamiento de la función ip_rcv(). Más adelante veremos que softirq encontrará la dirección de la función ip_rcv a través de ptype_base, y luego enviará el paquete ip a ip_rcv() correctamente para su ejecución. En ip_rcv, la función de procesamiento tcp o udp se encontrará a través de inet_protos, y luego el paquete se reenviará a la función udp_rcv() o tcp_v4_rcv().
Para ampliar, si observa los códigos de funciones como ip_rcv y udp_rcv, puede ver el procesamiento de muchos protocolos. Por ejemplo, ip_rcv manejará el filtrado de netfilter e iptable.Si tiene muchas o muy complejas reglas de netfilter o iptables, estas reglas se ejecutan en el contexto de interrupciones suaves, lo que aumentará el retraso de la red. Para otro ejemplo, udp_rcv juzgará si la cola de recepción de sockets está llena. Los parámetros de kernel relacionados correspondientes son net.core.rmem_max y net.core.rmem_default. Si está interesado, le sugiero que lea inet_initdetenidamente el código de esta función.
2.4 Inicialización del controlador de la tarjeta de red
Todos los controladores (no solo los controladores de tarjetas de red) utilizarán module_init para registrar una función de inicialización con el kernel, y el kernel llamará a esta función cuando se cargue el controlador. Por ejemplo, el código del controlador de la tarjeta de red igb se encuentra endrivers/net/ethernet/intel/igb/igb_main.c
//file: drivers/net/ethernet/intel/igb/igb_main.c
static struct pci_driver igb_driver = {
.name = igb_driver_name,
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove, ......
};
static int __init igb_init_module(void){
......
ret = pci_register_driver(&igb_driver); return ret;
}Una vez que se completa la llamada del controlador pci_register_driver, el kernel de Linux conoce la información relevante del controlador, como el controlador de la tarjeta de red igb igb_driver_namey igb_probela dirección de la función, etc. Cuando se reconoce el dispositivo de la tarjeta de red, el kernel llamará al método de sondeo de su controlador (el método de sondeo de igb_driver es igb_probe). El propósito de impulsar la ejecución del método de sondeo es preparar el dispositivo. Para la tarjeta de red igb, se igb_probeencuentra en drivers/net/ethernet/intel/igb/igb_main.c. Las principales operaciones realizadas son las siguientes:

Figura 6 Inicialización del controlador de la tarjeta de red
En el paso 5, podemos ver que el controlador de la tarjeta de red implementa la interfaz requerida por ethtool y también se registra aquí para completar el registro de la dirección de la función. Cuando ethtool inicia una llamada al sistema, el núcleo encontrará la función de devolución de llamada para la operación correspondiente. Para la tarjeta de red igb, todas sus funciones de implementación se encuentran en drivers/net/ethernet/intel/igb/igb_ethtool.c. Creo que puedes entender completamente el principio de funcionamiento de ethtool esta vez, ¿verdad? La razón por la que este comando puede ver las estadísticas de envío y recepción de paquetes de la tarjeta de red, modificar el modo adaptativo de la tarjeta de red y ajustar el número y el tamaño de la cola RX es que el comando ethtool finalmente llama al método correspondiente de la red. controlador de tarjeta, en lugar de que ethtool tenga este superpoder.
El igb_netdev_ops registrado en el paso 6 contiene funciones como igb_open, que se llamará cuando se inicie la tarjeta de red.
//file: drivers/net/ethernet/intel/igb/igb_main.c
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu, .ndo_do_ioctl = igb_ioctl,
......En el paso 7, durante el proceso de inicialización de igb_probe, también se llama igb_alloc_q_vector. Registró una función de encuesta necesaria para el mecanismo NAPI Para el controlador de la tarjeta de red igb, esta función es igb_poll, como se muestra en el siguiente código.
static int igb_alloc_q_vector(struct igb_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int rxr_count, int rxr_idx){
......
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
}2.5 Iniciar la tarjeta de red
Cuando se completa la inicialización anterior, puede iniciar la tarjeta de red. Recordando la inicialización anterior del controlador de la tarjeta de red, mencionamos que el controlador registró la variable de estructura net_device_ops con el kernel, que contiene funciones de devolución de llamada (punteros de función) como la activación de la tarjeta de red, el envío de paquetes y la configuración de la dirección mac. Cuando se habilita una tarjeta de red (por ejemplo, a través de ifconfig eth0 up), se llama al método igb_open en net_device_ops. Suele hacer lo siguiente:

Figura 7 Inicie la tarjeta de red
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming){
/* allocate transmit descriptors */
err = igb_setup_all_tx_resources(adapter);
/* allocate receive descriptors */
err = igb_setup_all_rx_resources(adapter);
/* 注册中断处理函数 */
err = igb_request_irq(adapter);
if (err)
goto err_req_irq;
/* 启用NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi)); ......
}La función anterior __igb_openllama a igb_setup_all_tx_resources e igb_setup_all_rx_resources. En igb_setup_all_rx_resourceseste paso, se asigna el RingBuffer y se establece la relación de mapeo entre la memoria y la cola Rx. (La cantidad y el tamaño de las colas Rx Tx se pueden configurar a través de ethtool). Veamos de nuevo el registro de la función de interrupción igb_request_irq:
static int igb_request_irq(struct igb_adapter *adapter){
if (adapter->msix_entries) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
...... }
}
static int igb_request_msix(struct igb_adapter *adapter){
......
for (i = 0; i < adapter->num_q_vectors; i++) {
...
err = request_irq(adapter->msix_entries[vector].vector,
igb_msix_ring, 0, q_vector->name,
}Al rastrear la llamada a la función en el código anterior, __igb_open=> igb_request_irq=> igb_request_msix, igb_request_msixpodemos ver que para las tarjetas de red de varias colas, las interrupciones se registran para cada cola y la función de procesamiento de interrupciones correspondiente es igb_msix_ring (esta función también está en drivers/net/ ethernet/intel/igb/igb_main.c). También podemos ver que en el modo msix, cada cola RX tiene una interrupción MSI-X independiente.Desde el nivel de la interrupción de hardware de la tarjeta de red, se puede configurar para que los paquetes recibidos sean procesados por diferentes CPU. (Puede modificar el comportamiento de enlace con la CPU a través de irqbalance, o modificar /proc/irq/IRQ_NUMBER/smp_affinity).
Cuando haya terminado con los preparativos anteriores, ¡puede abrir la puerta para dar la bienvenida a los invitados (paquetes de datos)!
Tres dan la bienvenida a la llegada de los datos
3.1 Procesamiento de interrupción dura
En primer lugar, cuando la trama de datos llega a la tarjeta de red desde el cable de red, la primera parada es la cola de recepción de la tarjeta de red. La tarjeta de red busca una ubicación de memoria disponible en el RingBuffer asignado a sí misma. Después de encontrarla, el motor DMA enviará los datos a la memoria asociada con la tarjeta de red antes. En este momento, la CPU es insensible. Cuando se completa la operación DMA, la tarjeta de red iniciará una interrupción dura como la CPU para notificar a la CPU que han llegado datos.

Figura 8 Proceso de procesamiento de interrupción dura de datos de NIC
Nota: cuando el RingBuffer esté lleno, los nuevos paquetes de datos se descartarán. Cuando ifconfig comprueba la tarjeta de red, es posible que se haya desbordado, lo que indica que el paquete se descartó porque la cola de llamada estaba llena. Si se encuentra una pérdida de paquetes, es posible que deba usar el comando ethtool para aumentar la longitud de la cola de llamada.
En la sección sobre cómo iniciar la tarjeta de red, mencionamos que la función de procesamiento del registro de interrupción dura de la tarjeta de red es igb_msix_ring.
//file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data){
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi); return IRQ_HANDLED;
}igb_write_itrSimplemente registre la frecuencia de interrupción del hardware (se dice que el propósito es reducir la frecuencia de interrupción de la CPU). Siga la llamada de napi_schedule hasta el final, __napi_schedule=>____napi_schedule
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi){
list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ);
}Aquí vemos que list_add_tailpoll_list en la variable de CPU softnet_data se modifica y se agrega poll_list pasado por el controlador napi_struct. Poll_list en softnet_data es una lista bidireccional en la que los dispositivos tienen marcos de entrada que esperan ser procesados. Luego __raise_softirq_irqoffse activa una interrupción suave NET_RX_SOFTIRQ.Este llamado proceso de activación es solo una operación OR en una variable.
void __raise_softirq_irqoff(unsigned int nr){
trace_softirq_raise(nr); or_softirq_pending(1UL << nr);
}
//file: include/linux/irq_cpustat.h
#define or_softirq_pending(x) (local_softirq_pending() |= (x))Hemos dicho que Linux solo completa el trabajo simple y necesario en interrupciones duras, y la mayor parte del procesamiento restante se entrega a interrupciones suaves. Como puede ver en el código anterior, el proceso de procesamiento de interrupción dura es realmente muy corto. Simplemente grabó un registro, modificó la lista de encuestas de la CPU y luego emitió una interrupción suave. Es así de simple, incluso si se completa el trabajo de interrupción dura.
3.2 El subproceso del núcleo ksoftirqd maneja las interrupciones suaves

Figura 9 subproceso del núcleo ksoftirqd
Cuando se inicializa el subproceso del núcleo, presentamos dos funciones de subproceso ksoftirqd_should_runy en ksoftirqd run_ksoftirqd. El código es el ksoftirqd_should_runsiguiente:
static int ksoftirqd_should_run(unsigned int cpu){ return local_softirq_pending();
}
#define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)Aquí vemos que se llama a la misma función en la interrupción dura local_softirq_pending. La diferencia en el uso es que la posición de interrupción dura es para escribir la marca, aquí es solo para leer. Si está configurado en la interrupción dura NET_RX_SOFTIRQ, se puede leer aquí de forma natural. A continuación, entrará en la función de subproceso para su run_ksoftirqdprocesamiento:
static void run_ksoftirqd(unsigned int cpu){
local_irq_disable();
if (local_softirq_pending()) {
__do_softirq();
rcu_note_context_switch(cpu);
local_irq_enable();
cond_resched();
return;
} local_irq_enable();
}En __do_softirq, juzgue según el tipo de interrupción suave de la CPU actual y llame a su método de acción registrado.
asmlinkage void __do_softirq(void){
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
...
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
...
}
h++;
pending >>= 1; } while (pending);
}En la sección de inicialización del subsistema de red, vimos que registramos la función del controlador net_rx_action para NET_RX_SOFTIRQ. Entonces net_rx_actionla función será ejecutada.
Aquí debemos prestar atención a un detalle: el indicador de interrupción suave se establece en la interrupción fuerte, y el juicio de ksoftirq sobre si llega una interrupción suave se basa en smp_processor_id(). Esto significa que mientras la interrupción dura se responda en qué CPU, la interrupción suave también se procesa en esta CPU. Entonces, si encuentra que su consumo de CPU de interrupción suave de Linux se concentra en un núcleo, el método es ajustar la afinidad de CPU de la interrupción fuerte para dispersar la interrupción dura a diferentes núcleos de CPU.
Centrémonos en esta función central de nuevo net_rx_action.
static void net_rx_action(struct softirq_action *h){
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
......
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
budget -= work; }
}El límite de tiempo y el presupuesto al comienzo de la función se utilizan para controlar la salida activa de la función net_rx_action, y el propósito es garantizar que la recepción de paquetes de red no ocupe la CPU. Espere hasta la próxima vez que la tarjeta de red tenga una interrupción fuerte y luego procese los paquetes de datos recibidos restantes. El presupuesto se puede ajustar a través de los parámetros del kernel. La lógica central restante en esta función es obtener la variable de CPU actual softnet_data, recorrer su poll_list y luego ejecutar la función de encuesta registrada en el controlador de la tarjeta de red. Para la tarjeta de red igb, es igb_polluna función de la fuerza impulsora igb.
static int igb_poll(struct napi_struct *napi, int budget){
...
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget); ...
}En la operación de lectura, igb_pollel trabajo clave es igb_clean_rx_irqla llamada a .
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget){
...
do {
/* retrieve a buffer from the ring */
skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
}
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
}
}igb_fetch_rx_bufferLa función de sum igb_is_non_eopes eliminar el marco de datos de RingBuffer. ¿Por qué necesitas dos funciones? Debido a que es posible que el marco ocupe varios RingBuffers, se adquiere en bucle hasta el final del marco. Un marco de datos obtenido se representa mediante un sk_buff. Después de recibir los datos, realice algunas comprobaciones y luego comience a configurar la marca de tiempo, la identificación de VLAN, el protocolo y otros campos de la variable sbk. Luego ingrese napi_gro_receive:
//file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb){
skb_gro_reset_offset(skb); return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}dev_gro_receiveEsta función representa la característica GRO de la tarjeta de red. Se puede entender simplemente como la combinación de paquetes pequeños relacionados en un paquete grande. El propósito es reducir la cantidad de paquetes enviados a la pila de red, lo que ayuda a reducir el uso de la CPU. Ignorémoslo por ahora, y miremos directamente napi_skb_finish, esta función se llama principalmente netif_receive_skb.
//file: net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb){
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb(skb))
ret = GRO_DROP;
break; ......
}En netif_receive_skb, el paquete de datos se enviará a la pila de protocolos. Declaración, los siguientes 3.3, 3.4, 3.5 también pertenecen al proceso de procesamiento de interrupción suave, pero debido a que la longitud es demasiado larga, se extrae por separado en subsecciones.
3.3 Procesamiento de pila de protocolos de red
netif_receive_skbSegún el protocolo del paquete, si se trata de un paquete udp, la función enviará el paquete a la función de procesamiento del protocolo ip_rcv(), udp_rcv() para su procesamiento.

Figura 10 Procesamiento de pila de protocolo de red
//file: net/core/dev.c
int netif_receive_skb(struct sk_buff *skb){
//RPS处理逻辑,先忽略 ...... return __netif_receive_skb(skb);
}
static int __netif_receive_skb(struct sk_buff *skb){
......
ret = __netif_receive_skb_core(skb, false);}static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc){
......
//pcap逻辑,这里会将数据送入抓包点。tcpdump就是从这个入口获取包的 list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
......
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
} }
}En __netif_receive_skb_core, observé el punto de captura de paquetes de tcpdump que usaba con frecuencia y estaba muy emocionado. Parece que el tiempo para leer el código fuente realmente no se desperdicia. Luego __netif_receive_skb_coresaque el protocolo, sacará la información del protocolo del paquete de datos y luego recorrerá la lista de funciones de devolución de llamada registradas en este protocolo. ptype_baseEs una tabla hash, que mencionamos en la sección de registro de protocolo. La dirección de la función ip_rcv se almacena en esta tabla hash.
//file: net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev){
...... return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}pt_prev->funcEsta línea llama a la función de controlador registrada por la capa de protocolo. Para paquetes ip ingresará ip_rcv(si es un paquete arp ingresará arp_rcv).
3.4 Procesamiento de la capa de protocolo IP
Echemos un vistazo general a lo que hace Linux en la capa del protocolo ip y cómo se envía el paquete a la función de procesamiento del protocolo udp o tcp.
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
}Aquí NF_HOOKhay una función de gancho. Cuando se ejecuta el gancho registrado, se ejecutará la función a la que apunta el último parámetro ip_rcv_finish.
static int ip_rcv_finish(struct sk_buff *skb){
......
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
...
}
...... return dst_input(skb);
}Después de rastrear, ip_route_input_norefvi que se llamaba de nuevo ip_route_input_mc. En ip_route_input_mc, la función ip_local_deliverse asigna a dst.input, de la siguiente manera:
//file: net/ipv4/route.c
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev, int our){
if (our) {
rth->dst.input= ip_local_deliver;
rth->rt_flags |= RTCF_LOCAL; }
}Así que volvamos a ip_rcv_finisheso return dst_input(skb);.
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb){
return skb_dst(skb)->input(skb);
}skb_dst(skb)->inputEl método de entrada llamado es el ip_local_deliver asignado por el subsistema de enrutamiento.
//file: net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb){
/* * Reassemble IP fragments. */
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL, ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct sk_buff *skb){
......
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
ret = ipprot->handler(skb); }
}Como se ve en la sección de registro del protocolo, las direcciones de función de tcp_rcv() y udp_rcv() se almacenan en inet_protos. Aquí, la distribución se seleccionará de acuerdo con el tipo de protocolo en el paquete.Aquí, el paquete skb se enviará al protocolo de capa superior, udp y tcp.
3.5 Procesamiento de la capa del protocolo UDP
Dijimos en la sección de registro del protocolo que la función de procesamiento del protocolo udp es udp_rcv.
//file: net/ipv4/udp.c
int udp_rcv(struct sk_buff *skb){
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto){
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
int ret = udp_queue_rcv_skb(sk, skb
} icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
}__udp4_lib_lookup_skbEs encontrar el socket correspondiente de acuerdo con el skb, y cuando lo encuentre, coloque el paquete de datos en la cola del búfer del socket. Si no se encuentra, se envía un paquete icmp con destino inalcanzable.
//file: net/ipv4/udp.c
int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb){
......
if (sk_rcvqueues_full(sk, skb, sk->sk_rcvbuf))
goto drop;
rc = 0;
ipv4_pktinfo_prepare(skb);
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk); return rc;
}sock_owned_by_user juzga si el usuario está realizando una llamada al sistema en este socket (el socket está ocupado), si no, puede colocarse directamente en la cola de recepción del socket. Si lo hay, agregando sk_add_backlogel paquete a la cola de trabajo pendiente. Cuando el usuario libera el socket, el kernel verificará la cola de trabajos pendientes y la moverá a la cola de recepción si hay datos.
sk_rcvqueues_fullSi la cola de recepción está llena, el paquete se descartará directamente. El tamaño de la cola de recepción se ve afectado por los parámetros del kernel net.core.rmem_max y net.core.rmem_default.
Cuatro llamadas al sistema recvfrom
Brotan dos flores, cada una de las cuales representa una rama. Arriba, hemos terminado el proceso de recepción y procesamiento del paquete de datos por todo el kernel de Linux, y finalmente colocamos el paquete de datos en la cola de recepción del socket. Luego, echemos un vistazo a recvfromlo que sucedió después de la llamada al proceso del usuario. Lo que llamamos en el código recvfromes una función de la biblioteca glibc.Después de ejecutar la función, el usuario entrará en el modo kernel e ingresará a la llamada del sistema implementada por Linux sys_recvfrom. Antes de comprender el par de Linux sys_revvfrom, echemos un breve vistazo a socketesta estructura de datos central. Esta estructura de datos es demasiado grande, solo dibujamos el contenido relacionado con nuestro tema de hoy, de la siguiente manera:

Figura 11 organización de datos del núcleo del socket
socketconst struct proto_opsCorrespondiente en la estructura de datos es el conjunto de métodos del protocolo. Cada protocolo implementa un conjunto diferente de métodos.Para la familia de protocolos de Internet IPv4, cada protocolo tiene un método de procesamiento correspondiente, como se indica a continuación. Para UDP, está inet_dgram_opsdefinido por , donde se registran los métodos inet_recvmsg.
//file: net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
......
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap, ......
}
const struct proto_ops inet_dgram_ops = {
......
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg, ......
}socketOtra estructura de datos en la estructura de datos struct sock *skes una subestructura muy grande y muy importante. Entre ellas, sk_protse define la función de procesamiento secundario. Para el protocolo UDP, se establecerá en el conjunto de métodos implementado por el protocolo UDP udp_prot.
//file: net/ipv4/udp.c
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
......
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage, ......
}Después de leer socketlas variables, veamos sys_revvfromel proceso de implementación.
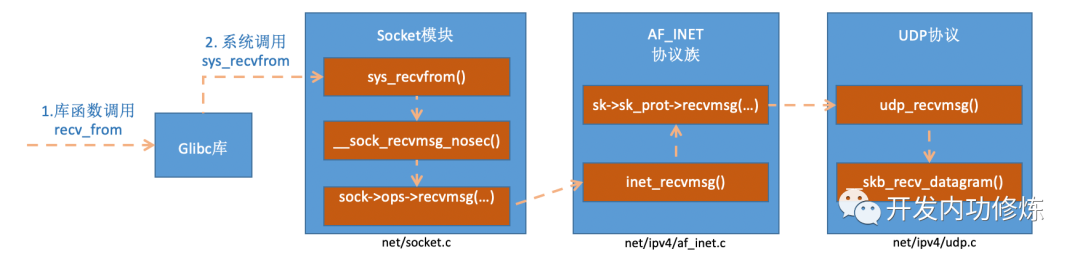
Figura 12 El proceso de implementación interna de la función recvfrom
está inet_recvmsgllamando sk->sk_prot->recvmsg_
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,size_t size, int flags){
......
err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len; return err;
}Dijimos anteriormente que este sk_protes net/ipv4/udp.cel caso del socket del protocolo udp struct proto udp_prot. A partir de esto encontramos udp_recvmsguna manera.
//file:net/core/datagram.c:EXPORT_SYMBOL(__skb_recv_datagram);
struct sk_buff *__skb_recv_datagram(struct sock *sk, unsigned int flags,int *peeked, int *off, int *err){
......
do {
struct sk_buff_head *queue = &sk->sk_receive_queue;
skb_queue_walk(queue, skb) {
......
}
/* User doesn't want to wait */
error = -EAGAIN;
if (!timeo)
goto no_packet; } while (!wait_for_more_packets(sk, err, &timeo, last));
}Finalmente encontramos el punto que queríamos ver, arriba vimos el llamado proceso de lectura, que es el acceso sk->sk_receive_queue. Si no hay datos y el usuario permite esperar, se llamará a wait_for_more_packets() para realizar la operación de espera, lo que pondrá el proceso del usuario en suspensión.
cinco resumen
El módulo de red es el módulo más complicado en el kernel de Linux.Parece que un proceso simple de recepción de paquetes implica la interacción entre muchos componentes del kernel, como el controlador de la tarjeta de red, la pila de protocolos, el hilo ksoftirqd del kernel, etc. Parece muy complicado Este artículo quiere explicar claramente el proceso de recepción de paquetes del kernel de una manera fácil de entender a través de ilustraciones. Ahora vamos a unir todo el proceso de recopilación de paquetes.
Después de que el usuario ejecuta recvfromla llamada, el proceso del usuario pasa al modo kernel a través de la llamada al sistema. Si no hay datos en la cola de recepción, el proceso entra en suspensión y el sistema operativo lo suspende. Esta pieza es relativamente simple y la mayoría de las escenas restantes son realizadas por otros módulos del kernel de Linux.
Primero, antes de comenzar a recibir paquetes, Linux necesita hacer mucho trabajo preparatorio:
- 1. Cree un subproceso ksoftirqd, configure su propia función de subproceso para él y luego cuente con él para manejar interrupciones suaves
- 2 registro de pila de protocolos, Linux necesita implementar muchos protocolos, como arp, icmp, ip, udp, tcp, cada protocolo registrará su propia función de procesamiento, por lo que es conveniente encontrar rápidamente la función de procesamiento correspondiente cuando llega el paquete
- 3. Inicialización del controlador de la tarjeta de red, cada controlador tiene una función de inicialización y el kernel permitirá que el controlador lo inicialice. En este proceso de inicialización, prepare su propio DMA y dígale al núcleo la dirección de la función de encuesta de NAPI
- 4. Inicie la tarjeta de red, asigne colas RX y TX y registre la función de procesamiento correspondiente a la interrupción
Lo anterior es el trabajo importante antes de que el kernel esté listo para recibir el paquete. Cuando lo anterior esté listo, puede abrir la interrupción dura y esperar la llegada del paquete de datos.
Cuando llegan los datos, lo primero que saluda es la tarjeta de red (me voy, no es esta tontería):
- 1. La tarjeta de red DMA envía el marco de datos al RingBuffer de la memoria y luego inicia una notificación de interrupción a la CPU.
- 2. La CPU responde a la solicitud de interrupción y llama a la función de procesamiento de interrupción registrada cuando se inicia la tarjeta de red
- 3. La función de procesamiento de interrupciones no hace casi nada e inicia una solicitud de interrupción suave
- 4. El hilo del kernel ksoftirqd encuentra que hay una solicitud de interrupción suave y primero cierra la interrupción fuerte
- 5. El subproceso ksoftirqd comienza a llamar a la función de encuesta del controlador para recibir paquetes.
- 6. La función de encuesta envía el paquete recibido a la función ip_rcv registrada en la pila de protocolo
- 7. La función ip_rcv envía el paquete a la función udp_rcv (para paquetes tcp, se envía a tcp_rcv)
Ahora podemos volver a la pregunta del principio, la línea simple que vimos en la capa de usuario recvfrom, el kernel de Linux tiene que hacer mucho trabajo por nosotros, para que podamos recibir los datos sin problemas. Este sigue siendo un UDP simple. Si es TCP, el kernel tiene que hacer más trabajo. No puedo evitar suspirar que los desarrolladores del kernel tienen muy buenas intenciones.
Después de comprender todo el proceso de recepción de paquetes, podemos saber claramente la sobrecarga de la CPU de Linux al recibir un paquete. En primer lugar, el primer bloque es la sobrecarga del proceso de usuario que llama al sistema y entra en modo kernel. El segundo bloque es la sobrecarga de la CPU de la interrupción fuerte del paquete de respuesta de la CPU. El tercer bloque lo gasta el contexto de interrupción suave del subproceso del núcleo ksoftirqd. Más adelante, publicaremos un artículo dedicado a observar estos gastos.
Además, hay muchos detalles en la red de envío y recepción que no hemos ampliado, como NAPI, GRO, RPS, etc. Debido a que creo que lo que dije es demasiado correcto, afectará la comprensión de todo el proceso por parte de todos, así que trate de mantener solo el cuadro principal, ¡menos es más!