Tabla de contenido
2 Recibir entrada tcp_v4_rcv ()
2.1 Agregar a la cola de precola tcp_prequeue
2.2 Agregar cola de trabajos pendientes sk_add_backlog
2.3 procesamiento de la cola de recepción tcp_v4_do_rcv
1 Tres colas recibidas
Después de que la capa IP ensambla un paquete de datos, si el campo de protocolo en el encabezado del paquete de datos indica que el protocolo de la capa superior es TCP, se llama a la función TCP_v4_rcv () para pasar los datos a la capa de transporte para su procesamiento posterior. El proceso general de procesamiento de la capa de transporte es muy complicado. Esta nota primero echará un vistazo a cómo se maneja la entrada de la capa de transporte.
El flujo de procesamiento general de TCP para los paquetes de datos de entrada se puede expresar simplemente de la siguiente manera: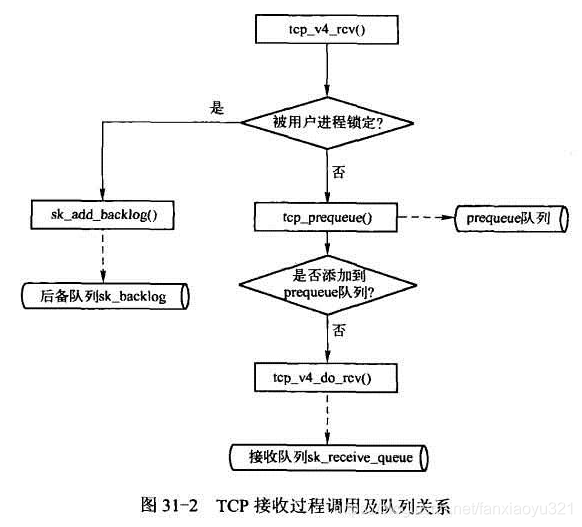
En la figura anterior, puede ver que el proceso de recepción de TCP involucra tres colas: la cola de precola, la cola de recepción y la cola de trabajos pendientes. Aquí primero presentamos el rol de estas tres colas y luego trazamos la implementación del código fuente.
Desde la perspectiva de la recepción de datos, el estado del bloque de control de transmisión TCP se puede dividir en los siguientes tres tipos:
- El proceso del usuario está leyendo y escribiendo datos, en este momento TCB está bloqueado
- El proceso del usuario está leyendo y escribiendo datos, pero entra en estado inactivo porque no hay datos disponibles, esperando que los datos estén disponibles, entonces el proceso del usuario no bloqueará la TCB
- El proceso del usuario no lee ni escribe datos en absoluto y, por supuesto, el proceso del usuario no bloqueará la TCB en este momento.
Considere un punto más, debido a que el procesamiento de la pila de protocolos de los paquetes de datos de entrada en realidad se lleva a cabo en interrupciones suaves, por consideraciones de rendimiento, siempre esperamos que las interrupciones suaves terminen rápidamente.
De esta manera, entendamos la imagen de arriba:
- Si está bloqueado por el proceso del usuario, entonces se encuentra en la situación 1. En este momento, debido a la exclusión mutua, no hay otra opción. Para terminar rápidamente el procesamiento de interrupciones suaves, coloque el paquete de datos en la cola de trabajos pendientes. El procesamiento real de este tipo de paquete de datos está en el proceso del usuario Cuando se suelta la TCB;
- Si no está bloqueado por el proceso, primero intente poner el paquete de datos en la cola de precola. El motivo es dejar que la interrupción suave finalice lo antes posible. El procesamiento de este paquete de datos se procesa en el proceso de lectura de datos por el proceso del usuario;
- Si no está bloqueado por el proceso y la cola de precola no acepta el paquete de datos (por razones de rendimiento, por ejemplo, la cola de precola no se puede aumentar indefinidamente), entonces no hay mejor manera. El paquete de datos debe procesarse en una interrupción suave. Después de terminar, agregue el paquete de datos a la cola de recepción.
En resumen, se puede resumir de la siguiente manera:
- Los paquetes de datos que se colocan en la cola de recepción son todos los paquetes de datos que han sido procesados por TCP, como comprobar, ACK y otras acciones que se han completado, estos paquetes de datos pueden ser leídos por el programa de espacio de usuario; por el contrario, ponerlos en la cola de trabajos pendientes y en la precola Los paquetes de datos en la cola aún necesitan procesamiento TCP, de hecho, estos paquetes de datos también son procesados por tcp_v4_do_rcv () en el momento adecuado;
- El diseño de las tres colas tiene un propósito especial y es muy importante comprender la intención del diseño detrás de él.
2 Recibir entrada tcp_v4_rcv ()
tcp_v4_rcv () es la función de entrada de recepción del protocolo TCP.
int tcp_v4_rcv(struct sk_buff *skb)
{
const struct iphdr *iph;
struct tcphdr *th;
struct sock *sk;
int ret;
//非本机数据包扔掉
if (skb->pkt_type != PACKET_HOST)
goto discard_it;
/* Count it even if it's bad */
TCP_INC_STATS_BH(TCP_MIB_INSEGS);
//下面主要是对TCP段的长度进行校验。注意pskb_may_pull()除了校验,还有一个额外的功能,
//如果一个TCP段在传输过程中被网络层分片,那么在目的端的网络层会重新组包,这会导致传给
//TCP的skb的分片结构中包含多个skb,这种情况下,该函数会将分片结构重组到线性数据区
//保证skb的线性区域至少有20个字节数据
if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
goto discard_it;
th = tcp_hdr(skb);
if (th->doff < sizeof(struct tcphdr) / 4)
goto bad_packet;
//保证skb的线性区域至少包括实际的TCP首部
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
//数据包校验相关,校验失败,则悄悄丢弃,不产生任何的差错报文
/* An explanation is required here, I think.
* Packet length and doff are validated by header prediction,
* provided case of th->doff==0 is eliminated.
* So, we defer the checks. */
if (!skb_csum_unnecessary(skb) && tcp_v4_checksum_init(skb))
goto bad_packet;
//初始化skb中的控制块
th = tcp_hdr(skb);
iph = ip_hdr(skb);
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->when = 0;
TCP_SKB_CB(skb)->flags = iph->tos;
TCP_SKB_CB(skb)->sacked = 0;
//根据传入段的源和目的地址信息从ehash或者bhash中查询对应的TCB,这一步决定了
//输入数据包应该由哪个套接字处理,获取到TCB时,还会持有一个引用计数
sk = __inet_lookup(skb->dev->nd_net, &tcp_hashinfo, iph->saddr,
th->source, iph->daddr, th->dest, inet_iif(skb));
if (!sk)
goto no_tcp_socket;
process:
//TCP_TIME_WAIT需要做特殊处理,这里先不关注
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
//IPSec相关
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
goto discard_and_relse;
nf_reset(skb);
//TCP套接字过滤器,如果数据包被过滤掉了,结束处理过程
if (sk_filter(sk, skb))
goto discard_and_relse;
//到了传输层,该字段已经没有意义,将其置为空
skb->dev = NULL;
//先持锁,这样进程上下文和其它软中断则无法操作该TCB
bh_lock_sock_nested(sk);
ret = 0;
//如果当前TCB没有被进程上下文锁定,首先尝试将数据包放入prequeue队列,
//如果prequeue队列没有处理,再将其处理后放入receive队列。如果TCB已
//经被进程上下文锁定,那么直接将数据包放入backlog队列
if (!sock_owned_by_user(sk)) {
//DMA部分,忽略
#ifdef CONFIG_NET_DMA
struct tcp_sock *tp = tcp_sk(sk);
if (!tp->ucopy.dma_chan && tp->ucopy.pinned_list)
tp->ucopy.dma_chan = get_softnet_dma();
if (tp->ucopy.dma_chan)
ret = tcp_v4_do_rcv(sk, skb);
else
#endif
{
//prequeue没有接收该数据包时返回0,那么交由tcp_v4_do_rcv()处理
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
} else {
//TCB被用户进程锁定,直接将数据包放入backlog队列
sk_add_backlog(sk, skb);
}
//释放锁
bh_unlock_sock(sk);
//释放TCB引用计数
sock_put(sk);
//返回处理结果
return ret;
no_tcp_socket:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard_it;
if (skb->len < (th->doff << 2) || tcp_checksum_complete(skb)) {
bad_packet:
TCP_INC_STATS_BH(TCP_MIB_INERRS);
} else {
tcp_v4_send_reset(NULL, skb);
}
discard_it:
/* Discard frame. */
kfree_skb(skb);
return 0;
discard_and_relse:
sock_put(sk);
goto discard_it;
do_time_wait:
...
}
2.1 Agregar a la cola de precola tcp_prequeue
/* Packet is added to VJ-style prequeue for processing in process
* context, if a reader task is waiting. Apparently, this exciting
* idea (VJ's mail "Re: query about TCP header on tcp-ip" of 07 Sep 93)
* failed somewhere. Latency? Burstiness? Well, at least now we will
* see, why it failed. 8)8) --ANK
*
* NOTE: is this not too big to inline?
*/
static inline int tcp_prequeue(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
//sysctl_tcp_low_latency(/proc/net/ipv4/tcp_low_latency)系统参数的含义是
//“是否启动tcp低时延”,如果启用则为1,否则为0(默认)
//tp->ucopy.task不为空,表示有进程正阻塞到该套接字上等待数据可用,所以,下面这两
//个条件表示没有启动TCP低时延并且当前有进程在等待数据时,则把数据包放入prequeue队列
//为什么放入prequeue队列就增加了tcp时延也非常好理解,因为放入prequeue队列的数据
//包实际上会被延迟处理,也就会延迟给对端回复ACK,所以增加了时延
if (!sysctl_tcp_low_latency && tp->ucopy.task) {
__skb_queue_tail(&tp->ucopy.prequeue, skb);
tp->ucopy.memory += skb->truesize;
//为了防止prequeue队列无线增大,这里设置了门限,超过了该门限,
//则直接在这里处理prequeue队列中的数据包
if (tp->ucopy.memory > sk->sk_rcvbuf) {
struct sk_buff *skb1;
BUG_ON(sock_owned_by_user(sk));
while ((skb1 = __skb_dequeue(&tp->ucopy.prequeue)) != NULL) {
sk->sk_backlog_rcv(sk, skb1);
NET_INC_STATS_BH(LINUX_MIB_TCPPREQUEUEDROPPED);
}
tp->ucopy.memory = 0;
} else if (skb_queue_len(&tp->ucopy.prequeue) == 1) {
//这里是另外一种情况,当prequeue队列由空变为不空时,唤醒等待进程,
//让等待进程有机会快速处理prequeue队列
wake_up_interruptible(sk->sk_sleep);
//延迟确认相关
if (!inet_csk_ack_scheduled(sk))
inet_csk_reset_xmit_timer(sk, ICSK_TIME_DACK,
(3 * TCP_RTO_MIN) / 4,
TCP_RTO_MAX);
}
return 1;
}
return 0;
}
2.2 Agregar cola de trabajos pendientes sk_add_backlog
Se trata de agregar directamente el paquete de datos a la cola de respaldo del bloque de control de transmisión, que es una operación simple de inserción de lista enlazada circular bidireccional.
/* The per-socket spinlock must be held here. */
static inline void sk_add_backlog(struct sock *sk, struct sk_buff *skb)
{
if (!sk->sk_backlog.tail) {
sk->sk_backlog.head = sk->sk_backlog.tail = skb;
} else {
sk->sk_backlog.tail->next = skb;
sk->sk_backlog.tail = skb;
}
skb->next = NULL;
}
2.3 procesamiento de la cola de recepción tcp_v4_do_rcv
Esta función completa la recepción y el procesamiento de un paquete de datos por parte de TCP y luego coloca el paquete de datos procesados en la cola de recepción (si hay datos). De hecho, el procesamiento de skb en las colas de prequeue y backlog se denomina eventualmente esta función, que se puede ver claramente en el procesamiento de tcp_recvmsg ().
Esta función es solo una simple distinción basada en el estado de la TCB, y el contenido relacionado se presentará por separado en otras notas.
/* The socket must have it's spinlock held when we get
* here.
*
* We have a potential double-lock case here, so even when
* doing backlog processing we use the BH locking scheme.
* This is because we cannot sleep with the original spinlock
* held.
*/
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
#ifdef CONFIG_TCP_MD5SIG
/*
* We really want to reject the packet as early as possible
* if:
* o We're expecting an MD5'd packet and this is no MD5 tcp option
* o There is an MD5 option and we're not expecting one
*/
if (tcp_v4_inbound_md5_hash(sk, skb))
goto discard;
#endif
//连接态的数据包由tcp_rcv_established()处理
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
TCP_CHECK_TIMER(sk);
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
TCP_CHECK_TIMER(sk);
return 0;
}
//再次检查头部长度,并完成校验
if (skb->len < tcp_hdrlen(skb) || tcp_checksum_complete(skb))
goto csum_err;
//LISTEN状态数据包处理过程,见连接建立过程分析
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}
//其它TCP状态到达的数据包都由tcp_rcv_state_process处理
TCP_CHECK_TIMER(sk);
if (tcp_rcv_state_process(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
TCP_CHECK_TIMER(sk);
return 0;
reset:
tcp_v4_send_reset(rsk, skb);
discard:
kfree_skb(skb);
/* Be careful here. If this function gets more complicated and
* gcc suffers from register pressure on the x86, sk (in %ebx)
* might be destroyed here. This current version compiles correctly,
* but you have been warned.
*/
return 0;
csum_err:
TCP_INC_STATS_BH(TCP_MIB_INERRS);
goto discard;
}