Каталог статей
Сегодня я подробно объясню алгоритм SqueezeNet.SqueezeNet — это легкая и эффективная модель CNN, ее параметры в 50 раз меньше, чем у AlexNet, но производительность модели (точность) близка к AlexNet.
Этот настоящий бой до сих пор является классической проблемой классификации: классификацией птиц.
Фактический набор данных о птицах этого проекта в основном разделен на 4 категории, а именно бананокит (банановая камышевка), черный скиммер (черная крачка), чернозобый буштити (чернозобая древесная камышевка), какаду (какаду или подсолнуховый попугай)), a всего 565 листов.

1. Теоретическая основа
1. Введение
Алгоритм SqueezeNet, как следует из названия, Squeeze означает сжатие и выдавливание на китайском языке, поэтому из названия алгоритма мы можем догадаться, что алгоритм должен уменьшить количество параметров модели путем распаковки модели. Конечно, улучшение любого алгоритма заключается в повышении точности или уменьшении параметров модели на исходной основе, поэтому основная цель алгоритма — уменьшить количество параметров модели при сохранении точности модели.
С исследованиями и разработками сверточной нейронной сети CNN было разработано все больше и больше моделей, и для повышения точности модели все получили широкое признание глубоких моделей, таких как AlexNet и ResNet. Однако из-за требований сценариев приложений многие модели не могут соответствовать требованиям реальных сценариев приложений из-за большого количества параметров, таких как такие технологии, как автоматическое вождение. Поэтому люди начали ориентироваться на легкие модели,
Таким образом, модель SqueezeNet «рождена вовремя».
В документе SqueezeNet преимущества облегченной модели резюмируются следующим образом:
● Более эффективное распределенное обучение. Взаимодействие между серверами является ограничивающим фактором масштабируемости распределенного обучения CNN. Для обучения с распределенным параллельным обменом данными затраты на связь пропорциональны количеству параметров в модели. Короче говоря, маленькие модели обучаются быстрее, потому что требуется меньше общения.
● Сокращение накладных расходов при экспорте новых моделей клиентам. Когда дело доходит до автономного вождения, такие компании, как Tesla, регулярно копируют новые модели со своих серверов на автомобили клиентов. Эту практику часто называют беспроводным обновлением. Consumer Reports обнаружил, что с недавними беспроводными обновлениями безопасность полуавтономного вождения Tesla Autopilot постепенно улучшалась (Consumer Reports, 2016). Однако беспроводные обновления современных типичных моделей CNN/DNN могут потребовать передачи больших объемов данных. При использовании AlexNet для этого потребуется 240 МБ связи между сервером и автомобилем. Меньшие модели требуют меньше связи, что делает частые обновления более осуществимыми.
● Возможное развертывание на ПЛИС и встроенных устройствах. Встроенная память fpga обычно меньше 10 МБ1, а внечипная память или память отсутствуют. Для логического вывода достаточно небольшие модели могут храниться непосредственно на FPGA, не ограничиваясь пропускной способностью памяти (Qiu et al., 2016), в то время как видеокадры передаются через FPGA в режиме реального времени. Кроме того, когда CNN развернуты на специализированных интегральных схемах (ASIC), достаточно небольшие модели могут храниться непосредственно на кристалле, а меньшие модели позволяют ASIC вписываться в меньшие чипы.
2. Концепция дизайна
В прошлом существовали способы уменьшить параметры модели, и разумный подход состоит в том, чтобы взять существующую модель CNN и сжать ее с потерями. В последние годы появилось исследовательское сообщество вокруг темы сжатия моделей, и было сообщено о нескольких подходах. Довольно простой подход Дентона и др. заключается в применении разложения по сингулярным числам (SVD) к предварительно обученной модели CNN. Хан и др. разработали Network Pruning, начиная с предварительно обученной модели, заменяя параметры ниже определенного порога нулем, чтобы сформировать разреженную матрицу, и, наконец, выполняя несколько итераций обучения на разреженной CNN. Хан и др. расширили свою работу, объединив сокращение сети с квантованием (до 8 бит или менее) и кодированием Хаффмана, создав метод под названием «Глубокое сжатие» и дополнительно разработав аппаратный ускоритель под названием EIE, который работает непосредственно на сжатой модели, достигает значительных результатов. ускорение и энергосбережение.
Основная стратегия алгоритма SqueezeNet также является стратегией сжатия.С точки зрения сжатия модели используются всего три метода и стратегии, которые мы опишем ниже.
2.1 Микроархитектура CNN (CNN MicroArchitecture)
В то же время автор статьи SqueezeNet считает, что с тенденцией проектирования глубоких сверточных нейронных сетей CNN становится очень проблематично вручную выбирать размер каждого слоя фильтров. Поэтому для решения этой проблемы в Интернете были предложены различные высокоуровневые строительные блоки или модули, состоящие из нескольких сверточных слоев с определенной фиксированной организацией. Например, в документе GoogleNet предлагается начальный модуль, который состоит из фильтров многих различных размеров, обычно включая 1 × 1 1\times1.1×1 и3 × 3 3\times33×3 , иногда добавляем5 × 5 5\times55×5 , иногда плюс1 × 3 1\times31×3 и3 × 1 3\times13×1 , возможно, с дополнительными специальными слоями для формирования полной сети. В алгоритме WideResNet, который мы объяснили в предыдущей статье, мы также объяснили аналогичный блок, остаточный блок. Автор статьи SqueezeNet в совокупности называет конкретную организацию и размерность каждого модуля микроархитектурой CNN.
2.2 Макроархитектура CNN
Микроархитектура CNN относится к отдельным слоям и модулям, в то время как макроархитектура CNN может быть определена как организация нескольких модулей на системном уровне, формирующая сквозную архитектуру CNN. Возможно, наиболее широко изучаемой темой макроархитектуры CNN в недавней литературе является влияние глубины (то есть количества слоев) в сети. Например, слой VGG12-19 обеспечивает более высокую точность набора данных ImageNet-1k. Выбор соединений между несколькими уровнями или модулями — новая область исследований макроархитектуры CNN. Например, как остаточная сеть (ResNet), так и магистральная сеть (Highway Network) рекомендуют пропускать многоуровневые соединения, например соединять активацию третьего уровня с активацией шестого уровня Мы называем это соединение обходным соединением. Автор ResNet приводит сравнение A/B 34-слойной CNN с обходными соединениями и без них (т. е. с пропуском соединений).Экспериментальное сравнение показало, что добавление обходных соединений может повысить точность пятерки лучших ImageNet на 2 процентных пункта.
2.3 Процесс исследования проекта модели сети
Авторы статьи считают, что нейронные сети (в том числе глубокая нейронная сеть DNN и сверточная нейронная сеть CNN) имеют большое пространство для проектирования с множеством вариантов микроархитектуры, макроархитектуры, решателя и других гиперпараметров. Естественно, сообщество хочет получить интуитивное представление (то есть форму пространства проектирования) о том, как эти факторы влияют на точность нейронных сетей. Большая часть работы по исследованию пространства проектирования (DSE) нейронных сетей была сосредоточена на разработке автоматизированных методов поиска архитектур нейронных сетей, обеспечивающих более высокую точность. Эти автоматизированные методы DSE включают байесовскую оптимизацию (Snoek et al, 2012), имитация отжига (Ludermir et al, 2006), случайный поиск (Bergstra & Bengio, 2012) и генетические алгоритмы (Stanley & Miikkulainen, 2002). К их чести, каждая из этих статей представляет собой случай, когда предложенный метод DSE создает архитектуру NN с более высокой точностью, чем репрезентативные базовые модели. Однако в этих статьях не делается попыток дать интуитивное представление о форме пространства проектирования нейронной сети. Позже в статье SqueezeNet авторы избегают автоматизированных подходов — вместо этого авторы рефакторят CNN, чтобы можно было провести принципиальное сравнение A/B для изучения того, как архитектурные решения CNN влияют на размер и точность модели.
2.4 Стратегия структурного проектирования
Основная цель алгоритма SqueezeNet — построить архитектуру CNN с небольшим количеством параметров, гарантируя при этом точность, которой обладают и другие модели. Для достижения этой цели автор принял в общей сложности три стратегии для разработки архитектуры CNN, а именно:
Стратегия 1: Разделите 3×3 на 3×33×3 Свертка заменена на1 × 1 1 × 11×1 Свертка: на этом шаге количество параметров операции свертки уменьшается на9 99 раз;
Стратегия 2: Уменьшить 3 × 3 3\times33×Количество каналов на 3 витка: a3×3 3\times33×3 Расчетное количество свертки составляет3 × 3 × M × N 3\times3\times M\times N3×3×М×N (где M и N — количество каналов входной карты признаков и выходной карты признаков соответственно), автор считает, что такой расчет слишком велик, поэтому он надеется максимально уменьшить M и N, чтобы уменьшить количество параметров.
Стратегия 3: Даунсэмплинг на поздних этапах сети, чтобы сверточные слои имели большие карты активации. В сверточной сети каждый сверточный слой создает выходную карту активации с пространственным разрешением не менее 1x1 и обычно намного больше 1x1. Высота и ширина этих карт активации определяются: (1) размером входных данных (например, изображения 256x256) и (2) выбором слоев понижающей дискретизации в архитектуре CNN.
Где стратегии 1 и 2 заключаются в разумном сокращении количества параметров в CNN при сохранении точности. Стратегия 3 направлена на максимальную точность при ограниченном бюджете параметров. Далее мы опишем модуль Fire, строительный блок нашей архитектуры CNN, который позволяет нам успешно применять стратегии 1, 2 и 3.
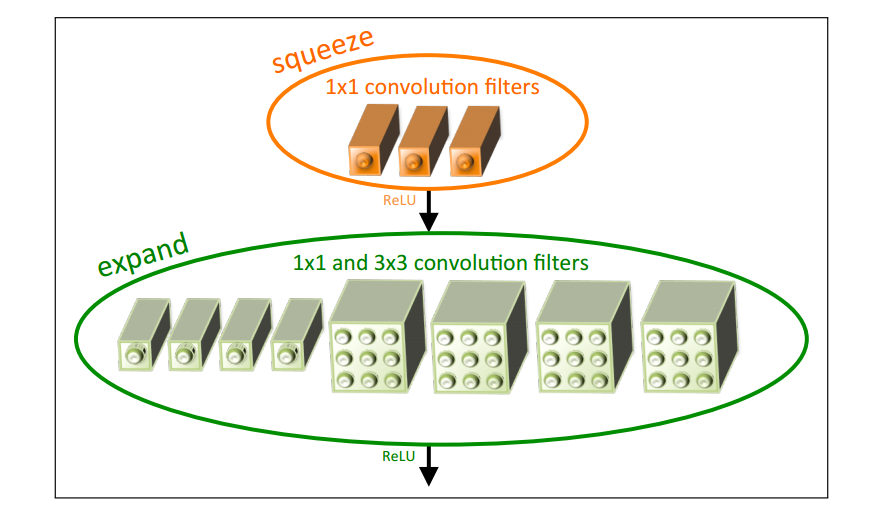
2.5 Пожарный модуль
Модуль Fire включает в себя: слой сжатия свертки (squeeze convolution), слой расширения ввода (expand), который имеет 1 × 1 1\times11×1 и3 × 3 3\times33×Смесь из 3-х сверточных фильтров. Только 1 × 1 1\times1в сжатом сверточном слое1×1 сверточный фильтр, а слой расширения смешивается с1 × 1 1\times11×1 и3 × 3 3\times33×3 сверточных фильтра. В то же время модуль вводит три гиперпараметра для настройки размеров:
● с 1 x 1 с_{1x1}с1 х 1: при сжатии 1 × 1 1 \times 11×1 Количество сверточных фильтров;
● e 1 x 1 e_{1x1}е1 х 1: 1 × 1 1\times1 в расширении1×1 Количество сверточных фильтров;
● e 3 x 3 e_{3x3}е3 х 3: 3 × 3 3 \times 3 в развернуть3×3 количество сверточных фильтров;
3. Структура сети
Сетевая архитектура SqueezeNet показана на рисунке ниже:

● Слева: SqueezeNet;
● Средняя панель: SqueezeNet с простым байпасом;
● Справа: SqueezeNet со сложными обходами;
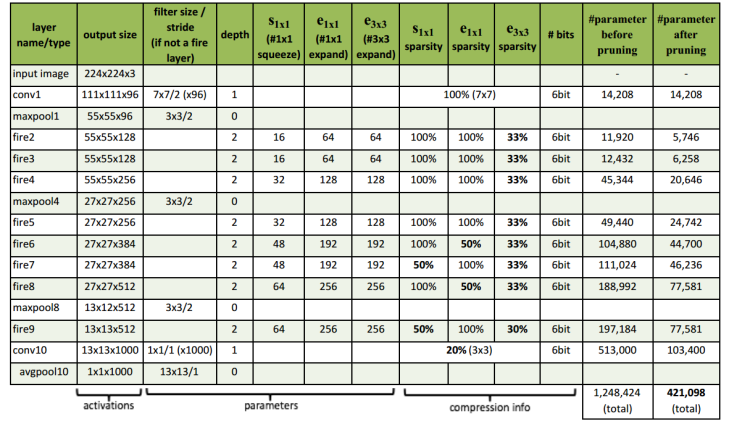
Из левого рисунка на рис. 1-2 видно, что SqueezeNet начинается с независимого сверточного слоя (Conv1), затем проходит через 8 модулей Fire (fire2-9) и, наконец, заканчивается сверточным слоем (Conv10). Мы постепенно увеличиваем количество фильтров на пожарный модуль от начала до конца сети. После уровней conv1, fire4, fire8 и conv10 SqueezeNet выполняет максимальное объединение с шагом 2; эти относительно поздние размещения пулов соответствуют стратегии 3 в 2.4.
Принимая во внимание, что простая архитектура обхода добавляет обходные соединения вокруг модулей 3, 5, 7 и 9, требуя, чтобы эти модули изучали остаточную функцию между входом и выходом. Как и в ResNet, для установления соединения в обход Fire3 вход Fire4 устанавливается на (выход Fire2 + выход Fire3), где оператор + является поэлементным сложением. Это изменяет регуляризацию, применяемую к параметрам этих модулей Fire, и, в зависимости от ResNet, может улучшить либо окончательную точность, либо возможность обучения полной модели.
В то время как простые обходы представляют собой «всего один провод», сложные обходы состоят из обходов сверточных слоев 1x1 с количеством фильтров, равным желаемому количеству выходных каналов.
Примечание. В простых случаях количество входных и выходных каналов должно совпадать. Следовательно, только половина модулей Fire может быть подключена для простого байпаса, как показано на схеме на рисунке 2. Когда требование «одинаково количество каналов» не может быть выполнено, мы используем сложные обходные соединения, как показано в правой части рис. 1-2. Сложные обходные соединения добавляют в модель дополнительные параметры, а простые обходные соединения — нет.
Полная архитектура SqueezeNet показана на рисунке ниже:
4. Анализ оценки
Результаты сравнения SqueezeNet и различных методов сжатия моделей следующие:

Влияние коэффициента сжатия (SR) на размер и точность модели в микроархитектуре и 3 × 3 3\x3 на уровне расширения3×3 Экспериментальная сравнительная диаграмма влияния коэффициента фильтрации на размер и точность модели выглядит следующим образом:
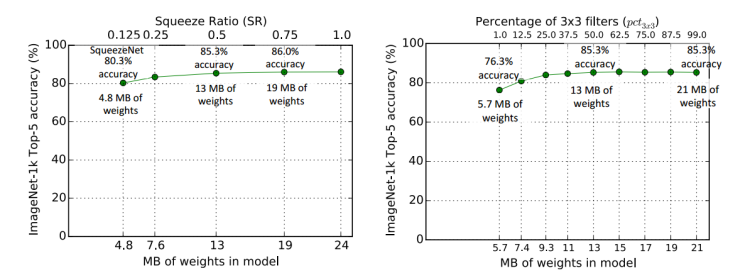
Таблица сравнения точности трех структур (обычная структура, простая структура ветвей и сложная структура ветвей) в макроструктуре выглядит следующим образом:

Два, реальный бой
1. Предварительная обработка данных
!unzip /home/aistudio/data/data223822/bird_photos.zip -d /home/aistudio/work/dataset
Поскольку при обработке файла набора данных существует дополнительный файл ipynb_checkpoints, нам нужно удалить следующее с помощью следующей команды. Помнить! Обязательно удалите~
%cd /home/aistudio/work
!rm -rf .ipynb_checkpoints
- Разделить набор данных
import os
import random
train_ratio = 0.7
test_ratio = 1-train_ratio
rootdata = "/home/aistudio/work/dataset"
train_list, test_list = [],[]
data_list = []
class_flag = -1
for a,b,c in os.walk(rootdata):
for i in range(len(c)):
data_list.append(os.path.join(a,c[i]))
for i in range(0, int(len(c)*train_ratio)):
train_data = os.path.join(a, c[i])+' '+str(class_flag)+'\n'
train_list.append(train_data)
for i in range(int(len(c)*train_ratio),len(c)):
test_data = os.path.join(a,c[i])+' '+str(class_flag)+'\n'
test_list.append(test_data)
class_flag += 1
random.shuffle(train_list)
random.shuffle(test_list)
with open('/home/aistudio/work/train.txt','w',encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img))
with open('/home/aistudio/work/test.txt', 'w', encoding='UTF-8') as f:
for test_img in test_list:
f.write(test_img)
2. Чтение данных
- Импортируйте следующие необходимые библиотеки
import paddle
import paddle.nn.functional as F
import numpy as np
import math
import random
import os
from paddle.io import Dataset # 导入Datasrt库
import paddle.vision.transforms as transforms
import paddle.nn as nn
import numpy as np
from PIL import Image
- Определите средство чтения данных с помощью paddle.io.DataLoader.
# 归一化
transform_BZ = transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
class LoadData(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.RandomHorizontalFlip(), # 随机左右翻转图像
transforms.RandomVerticalFlip(), # 随机上下翻转图像
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些复杂变换操作
])
self.val_tf = transforms.Compose([
transforms.Resize(224), # 调整图像大小为224x224
transforms.ToTensor(), # 将 PIL 图像转换为张量
transform_BZ # 执行某些变换操作
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split(' '), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 32. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 32
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img_path = os.path.join('',img_path)
img = Image.open(img_path)
img = img.convert("RGB")
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
- Загрузите тренировочный набор и тестовый набор
train_data = LoadData("/home/aistudio/work/train.txt", True)
test_data = LoadData("/home/aistudio/work/test.txt", True)
#数据读取
train_loader = paddle.io.DataLoader(train_data, batch_size=32, shuffle=True)
test_loader = paddle.io.DataLoader(test_data, batch_size=32, shuffle=True)
3. Импортируйте модель
class Fire(nn.Layer):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2D(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU()
self.expand1x1 = nn.Conv2D(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU()
self.expand3x3 = nn.Conv2D(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU()
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return paddle.concat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Layer):
def __init__(self, version='1_0', num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
if version == '1_0':
self.features = nn.Sequential(
nn.Conv2D(3, 96, kernel_size=7, stride=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == '1_1':
self.features = nn.Sequential(
nn.Conv2D(3, 64, kernel_size=3, stride=2),
nn.ReLU(),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2D(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
# FIXME: Is this needed? SqueezeNet should only be called from the
# FIXME: squeezenet1_x() functions
# FIXME: This checking is not done for the other models
raise ValueError("Unsupported SqueezeNet version {version}:"
"1_0 or 1_1 expected".format(version=version))
# Final convolution is initialized differently from the rest
final_conv = nn.Conv2D(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(),
nn.AdaptiveAvgPool2D((1, 1))
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return paddle.flatten(x, 1)
4. Распечатайте информацию о параметрах модели.
import paddle
model = SqueezeNet("1_0", num_classes=4)
params_info = paddle.summary(model,(1, 3, 224, 224))
print(params_info)
``

## 5.模型训练
```python
epoch_num = 60 #训练轮数
learning_rate = 0.0001 #学习率
val_acc_history = []
val_loss_history = []
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
for epoch in range(epoch_num):
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
acc_train.append(acc.numpy())
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
avg_acc = np.mean(acc_train)
print("[train] accuracy: {}".format(avg_acc))
loss.backward()
opt.step()
opt.clear_grad()
# evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[test] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
train(model)
paddle.save(model.state_dict(), "model.pdparams")
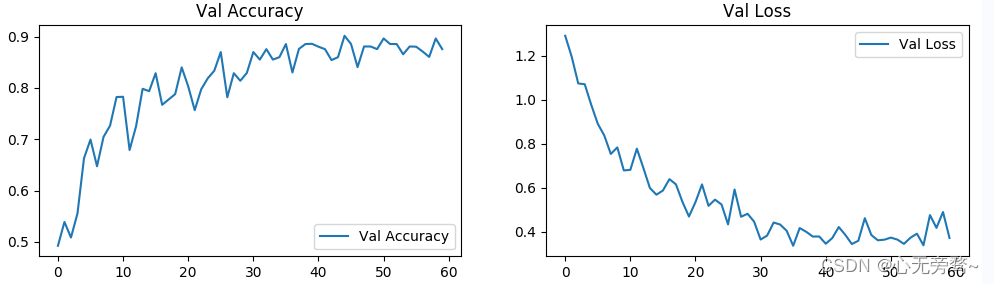
6. Визуализация результатов
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
epochs_range = range(epoch_num)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, val_acc_history, label='Val Accuracy')
plt.legend(loc='lower right')
plt.title('Val Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, val_loss_history, label='Val Loss')
plt.legend(loc='upper right')
plt.title('Val Loss')
plt.show()
7. Отображение результатов индивидуального прогнозирования
data_transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize((32, 32)),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
img = Image.open("/home/aistudio/work/dataset/Bananaquit/008.jpg")
plt.imshow(img)
image=data_transform(img)
plt.rcParams['font.sans-serif']=['FZHuaLi-M14S']
name=['风头鹦鹉','黑燕鸥类','黑喉树莺','蕉林莺']
image=paddle.reshape(image,[1,3,32,32])
model.eval()
predict=model(image)
print(predict.numpy())
plt.title(name[predict.argmax(1)])
plt.show()
Подведем итог
SqueezeNet — это легкая сверточная нейронная сеть, предназначенная для минимизации размера модели и потребления вычислительных ресурсов при сохранении высокой точности. Ниже приводится краткое изложение SqueezeNet:
-
Легкий дизайн: SqueezeNet использует специальную структуру, а именно «модуль Fire», для извлечения богатых функций с использованием меньшего количества параметров. Это позволяет SqueezeNet иметь меньший размер модели по сравнению с другими глубокими сетями.
-
Сжатие параметров: SqueezeNet уменьшает количество параметров за счет использования ядра свертки 1x1 и использует сжатие канала для уменьшения объема вычислений. Такой дизайн позволяет SqueezeNet хорошо работать в средах с ограниченными вычислительными ресурсами.
-
Высокая точность: хотя SqueezeNet является легкой сетью, она по-прежнему обеспечивает относительно высокую точность при сохранении небольшого размера модели. Благодаря разумному дизайну SqueezeNet может эффективно извлекать и использовать информацию об особенностях изображений.
-
Применимые сценарии: благодаря своей миниатюризации SqueezeNet особенно подходит для использования в средах с ограниченными ресурсами, таких как мобильные устройства и встроенные системы. Он позволяет выполнять ресурсоемкие задачи, такие как классификация изображений, обнаружение объектов и сегментация изображений.
В общем, SqueezeNet — это облегченная сеть, которая минимизирует размер модели и потребление вычислительных ресурсов, сохраняя при этом высокую точность. Его дизайн и стратегия сжатия параметров делают его отличным выбором для задач обработки изображений в средах с ограниченными ресурсами.