NCCL
Descripción general de NCCL
NCCL: Biblioteca de comunicaciones colectivas de NVIDIA Biblioteca de comunicaciones colectivas de NVIDIA
Proporciona primitivas de envío/recepción para la comunicación colectiva y la comunicación punto a punto. No es un marco de programación paralelo completo, sino una biblioteca para acelerar la comunicación dentro de la GPU
NCCL proporciona las siguientes primitivas de comunicación colectiva:
- TodoReducir
- Transmisión
- Reducir
- TodosReúnen
- ReducirDispersión
También permite enviar y recibir comunicaciones punto a punto, que incluyen: operaciones de dispersión (scatter), recopilación (recopilación) o de todos a todos.
La estrecha sincronización entre los procesadores de comunicación es un aspecto clave de la comunicación colectiva. Los colectivos basados en CUDA se implementan tradicionalmente a través de operaciones de copia de memoria de CUDA y núcleos de CUDA para la redacción local. NCCL, que implementa cada colección para manejar las operaciones de comunicación y computación en un solo núcleo. Esto permite una sincronización rápida y reduce los recursos necesarios para alcanzar el ancho de banda máximo.
NCCL elimina convenientemente la necesidad de que los desarrolladores optimicen sus aplicaciones en máquinas específicas. NCCL proporciona colectivos rápidos de múltiples GPU dentro de un nodo o entre nodos. Admite varias tecnologías de interconexión, incluidas PCIe, NVLINK, InfiniBand Verbs y sockets IP.
Además del rendimiento, la facilidad de uso también es una consideración en el diseño de NCCL. NCCL utiliza la conocida API C a la que se puede acceder fácilmente desde múltiples lenguajes de programación.
NCCL es compatible con casi cualquier modelo de paralelización de múltiples GPU, como:
- Un solo hilo controla todas las GPU
- Multiproceso, es decir, cada GPU está controlada por un subproceso
- Multiproceso, como MPI
NCCL juega un papel muy importante en el marco de aprendizaje profundo, y el conjunto AllReduce se usa ampliamente en el entrenamiento de redes neuronales. A través de la comunicación multi-GPU y multi-nodo proporcionada por NCCL, el entrenamiento de la red neuronal se puede expandir de manera efectiva.
Operaciones Colectivas
Las operaciones colectivas deben ser utilizadas por cada rango (el rango se refiere al dispositivo CUDA) para formar una operación colectiva completa. De lo contrario, los demás equipos tendrán que esperar indefinidamente.
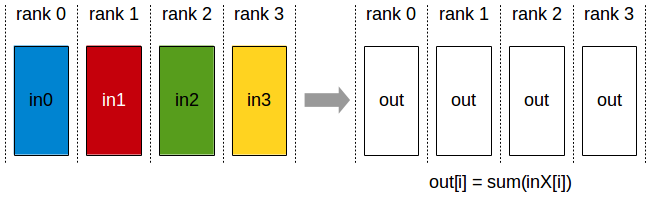
TodoRedeuce
La operación AllReduce realiza una operación de reducción en los datos de todos los dispositivos y escribe el resultado en el búfer de recepción de cada rango.
Las operaciones de AllReduce son independientes del orden de clasificación.
AllReduce comienza con matrices K que contienen valores N individualmente. y terminar con N arreglos de S con el mismo valor. Para cada rango, S[i] = V0[i] + V1[i] +...+Vk-1[i]
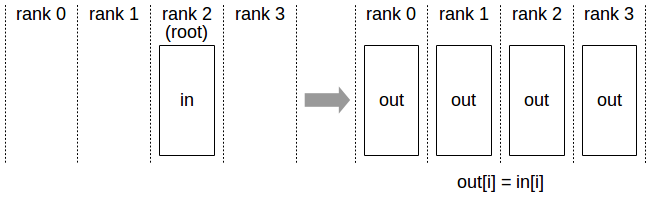
Transmisión
Copie el búfer de N elementos de un rango raíz a todos los rangos
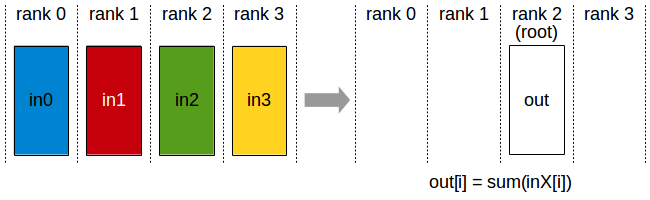
Reducir
El proceso de ejecución es similar a allReduce, pero solo escribe el resultado en un rango raíz específico
Después de una operación de reducción, el efecto de realizar una operación de transmisión es el mismo que el de allreduce
TodosReúnen
En los rangos K, se agrupan los valores de N en cada rango. La salida se ordena de acuerdo con la etiqueta de clasificación.
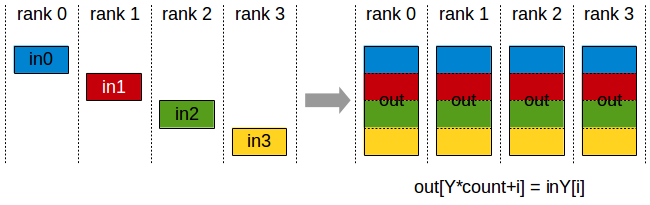
ReducirDispersión
La ejecución es similar a reducir, pero los resultados estarán dispersos en los bloques de cada rango. Cada rango obtiene una parte de los datos de acuerdo con su etiqueta.
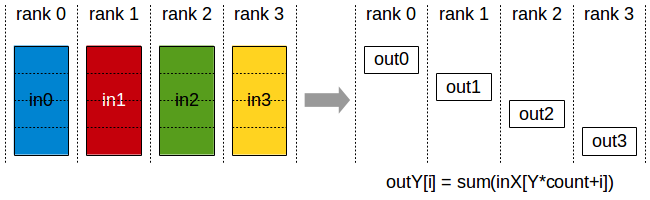
ReduceScatter se verá afectado por el diseño de clasificación.
anillo-todoreduce
Referencia: artículo de Zhihu Artículo CSDN

Computación distribuida por GPU, tarjetas GPU1~4, responsables del entrenamiento de los parámetros de la red, la misma red de aprendizaje profundo se organiza en cada tarjeta y cada tarjeta se asigna a un minilote de datos diferentes. Después del entrenamiento de cada tarjeta, los parámetros de red se sincronizan con GPU0, es decir, la tarjeta reductora, y luego se calcula el promedio de la transformación de parámetros y se envía a cada tarjeta de computación.Todo el proceso es un poco como el principio de mapreduce .
Se involucran dos cuestiones :
-
Cada ronda de iteraciones de entrenamiento requiere que todas las tarjetas sincronicen los datos y realicen una reducción antes de que finalice. Si el número de tarjetas es relativamente pequeño, el impacto es realmente pequeño, pero si hay muchas tarjetas paralelas, implica la situación de que la tarjeta de computación rápida debe esperar a la tarjeta de computación lenta, lo que resulta en una pérdida de recursos informáticos.
-
Todas las tarjetas GPU informáticas deben comunicarse con la tarjeta Redcue para todos los parámetros del modelo en cada iteración. La cantidad de datos es grande y la sobrecarga de comunicación es alta. A medida que aumenta el número de tarjetas, la sobrecarga aumentará linealmente.
Ring Allredcue, empalmando el modelo de comunicación de la tarjeta GPU en un anillo, reduciendo así el consumo de recursos provocado por el aumento del número de tarjetas.
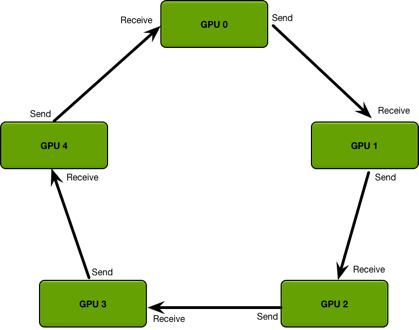
El proceso del algoritmo se divide principalmente en dos pasos: 1. scatter-reduce 2. allgather
1.
Si scatter-reduce tiene n GPU, divida los datos en la GPU en n bloques, especifique los vecinos izquierdo y derecho de la GPU y
luego inicie operaciones n-1. En la i-ésima operación, GPU j dividirá su (ji)%n envía datos rápidos a GPU j+1 y acepta (ji-1)%n datos de GPU j-1, como se muestra en la siguiente figura, cuando se completan n-1 operaciones, el primer gran paso
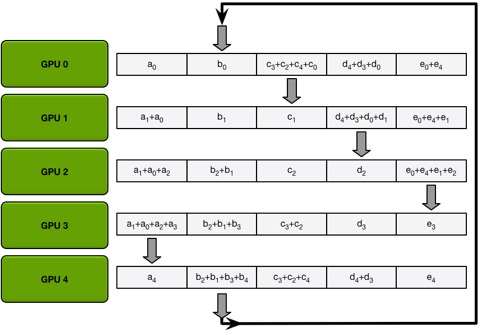
de ring-allreduce La reducción de dispersión se ha completado. En este momento, el (i + 1) % n-ésimo dato de la gpu i-ésima ha recopilado el (i + 1) % n-ésimo dato de todos los n-ésimos. th gpus, entonces, hágalo de nuevo allgather puede completar el algoritmo.
La segunda parte: todos recopilan, transfieren los datos del bloque (i+1)%n de la i-ésima GPU a otras GPU a través de la transferencia n-1.
Finalmente, cada GPU queda de la siguiente manera:
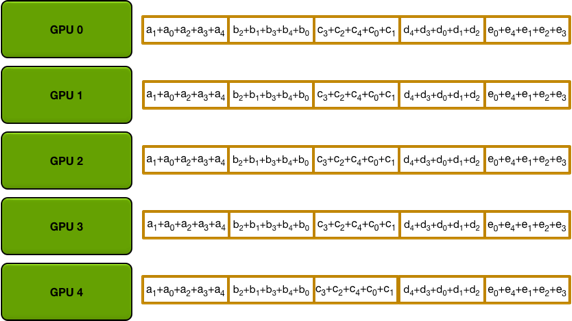
La imagen a continuación es de https://blog.csdn.net/dpppBR/article/details/80445569
para dar un ejemplo de 3gpu:
el primero es el primer paso, scatter-reduce:

y luego el ejemplo de allgather: