texto
Como desarrollo de back-end, las operaciones diarias más utilizadas de la base de datos son operaciones de escritura y operaciones de lectura. Hablaremos de las operaciones de lectura a continuación. En esta categoría, veremos principalmente por qué SQL se ralentiza durante las operaciones de escritura.
cepillar las páginas sucias
La definición de una página sucia es la siguiente: cuando la página de datos de la memoria no es coherente con la página de datos del disco, la página de datos de la memoria se denomina página sucia.
Entonces, ¿por qué aparecen las páginas sucias y cómo el cepillado de las páginas sucias puede hacer que SQL se ralentice? Luego tenemos que ver cómo es el proceso de escritura.
Para una operación de escritura de SQL, el proceso de ejecución implica varias situaciones, como la escritura de registros, la memoria y la sincronización de discos.
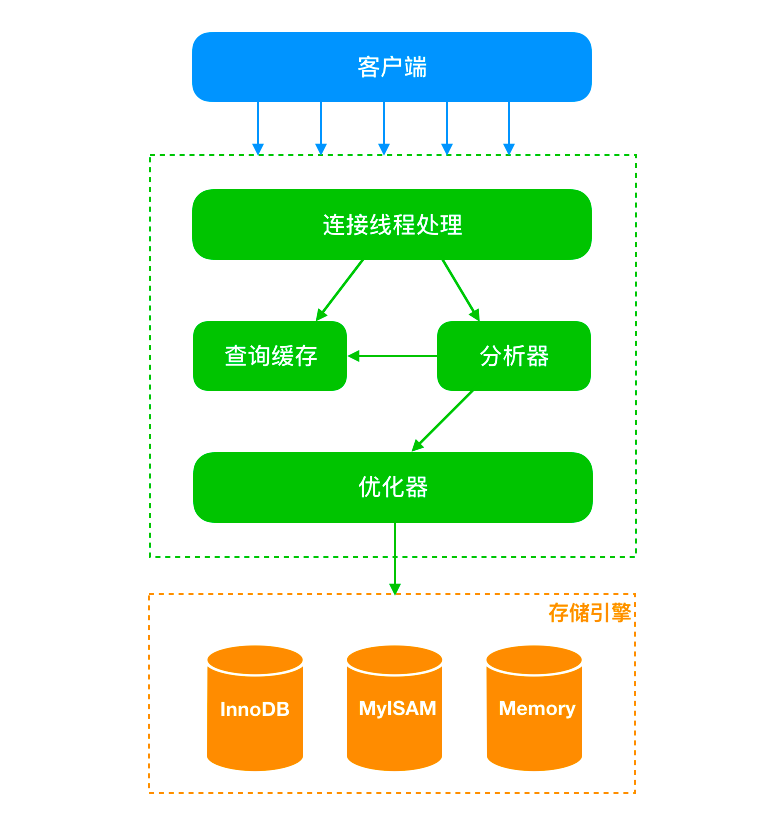
Aquí se menciona un archivo de registro, es decir, un registro de rehacer, que se encuentra en la capa del motor de almacenamiento y se usa para almacenar registros físicos. Durante la operación de escritura, el motor de almacenamiento (Innodb se analiza aquí) escribirá el registro en el registro de rehacer y actualizará la memoria caché, de modo que se complete la operación de actualización. Operaciones posteriores El motor de almacenamiento sincronizará los registros de operaciones con el disco en el momento adecuado.
Al ver esto, es posible que tenga una pregunta. ¿No es el registro de rehacer un archivo de registro? El archivo de registro se almacena en el disco. ¿No es muy lento al escribir?
De hecho, el proceso de escritura de registros de rehacer es escribir en el disco secuencialmente. La escritura secuencial de discos reduce el tiempo de búsqueda y la velocidad es mucho más rápida que la escritura aleatoria (similar al principio de almacenamiento de Kafka), por lo que la escritura La velocidad de los registros de rehacer es muy rápida.
Ok, volvamos a la pregunta original, por qué ocurren las páginas sucias y por qué las páginas sucias ralentizan SQL. Si lo piensa, el tamaño del registro de rehacer es fijo y está escrito en un bucle. En un escenario de alta simultaneidad, el registro de rehacer se llena rápidamente, pero los datos llegan demasiado tarde para sincronizarse con el disco. En este momento, se generarán páginas sucias y se bloquearán las operaciones de escritura posteriores. La ejecución de SQL naturalmente será más lenta.
Cerrar
Otra situación en la que SQL es lento durante las operaciones de escritura es que se pueden encontrar bloqueos, lo cual es fácil de entender. Por ejemplo, compartes una habitación con otra persona, solo hay un baño y ambos quieren ir al mismo tiempo, pero la otra persona está un poco por delante de ti. Entonces, en este momento, solo puede entrar después de que salga la otra parte.
En correspondencia con Mysql, cuando la fila que va a cambiar un determinado SQL simplemente está bloqueada, la operación de seguimiento solo se puede realizar después de que se libera el bloqueo.
Pero hay otra situación extrema, tu compañero de cuarto ha estado ocupando el baño, así que qué debes hacer en este momento, no puedes orinarte en los pantalones, qué vergüenza. En correspondencia con Mysql, hay una situación de interbloqueo o espera de bloqueo. ¿Cómo afrontarlo en este momento?
Mysql proporciona una forma de ver la situación de bloqueo actual:

Al ejecutar las declaraciones en el gráfico en la línea de comando, puede ver el estado actual de la transacción. Aquí hay algunos parámetros importantes en los resultados de la consulta:
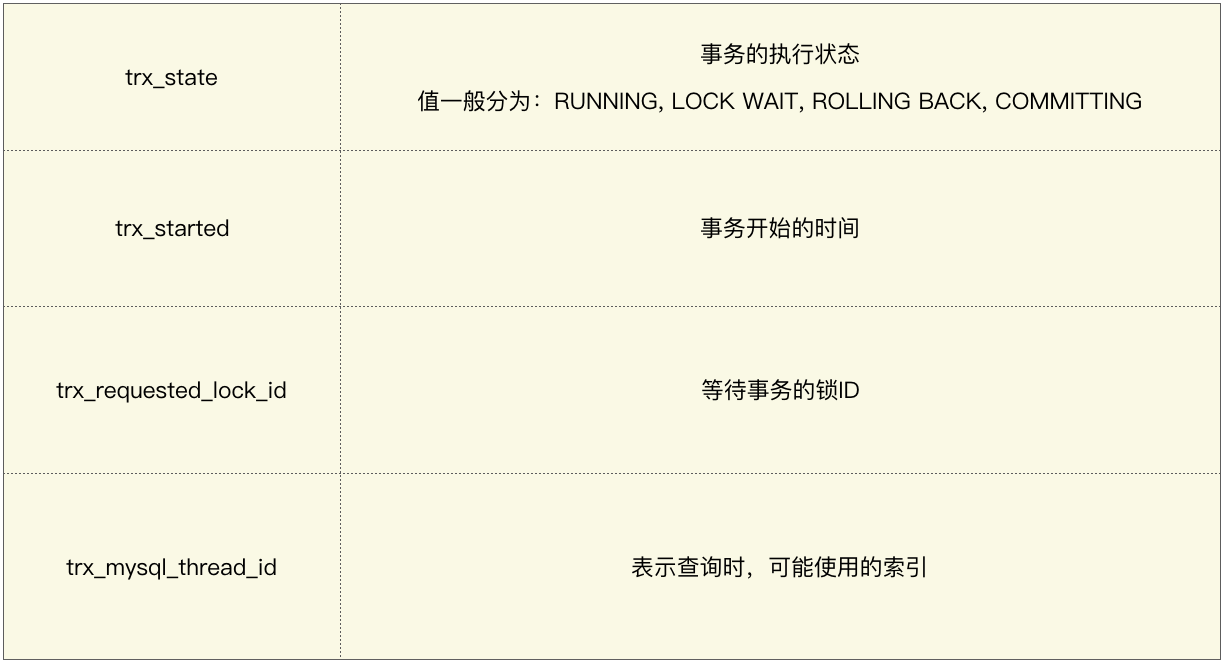
Si la transacción actual espera demasiado o se produce un interbloqueo, puede liberar el bloqueo actual mediante " kill thread ID ".
El ID del subproceso aquí se refiere al parámetro trx_mysql_thread_id en la tabla.
operación de lectura
Después de hablar sobre la operación de escritura, es posible que esté relativamente más familiarizado con la operación de lectura. El problema de SQL lento que conduce a operaciones de lectura lentas a menudo está relacionado con el trabajo.
consulta lenta
Antes de hablar sobre las razones de la operación de lectura lenta, echemos un vistazo a cómo localizar el SQL lento. Hay algo llamado registro de consultas lentas en Mysql , que se usa para registrar declaraciones SQL que exceden un tiempo específico. Está deshabilitado por defecto, y el registro de consultas lentas solo se puede habilitar a través de la configuración manual para el posicionamiento.
El método de configuración específico es el siguiente:
- Compruebe el estado del registro de consultas lentas actual:

- Habilitar el registro de consultas lentas (temporal):


Tenga en cuenta que el registro de consultas lentas solo está habilitado temporalmente aquí y dejará de ser válido después de reiniciar mysql. Se puede configurar en my.cnf para que sea permanente.
razón de la existencia
Ahora que sabemos cómo verificar la ejecución lenta de SQL, veamos por qué la consulta lenta es causada por la operación de lectura.
(1) Índice faltante
Una de las razones de la lentitud de la consulta SQL es que es posible que no se alcance el índice. Ya hay mucho en Internet sobre por qué el uso del índice puede hacer que la consulta sea más rápida y las precauciones al usarlo, así que no lo haré. entrar en detalles aquí.
(2) Problema de página sucia
La otra es la situación de cepillado de páginas sucias que mencionamos anteriormente, pero es diferente de la operación de escritura en que las páginas sucias se cepillan durante la lectura.
Estas un poco confundido, no te preocupes, escúchame:
Para evitar aumentar la sobrecarga de IO al acceder al disco cada vez que se lee y escribe datos, el motor de almacenamiento Innodb mejora la velocidad de lectura y escritura al cargar las páginas de datos y las páginas de índice correspondientes en el grupo de búfer (grupo de búfer) de la memoria. . Luego, mantenga los datos almacenados en caché en el grupo de búfer de acuerdo con el principio utilizado menos recientemente.
Luego, cuando la página de datos que se va a leer no está en la memoria, es necesario solicitar una página de datos en el grupo de búfer, pero la página de datos en el grupo de búfer es segura. Las páginas de datos se desalojan de la memoria. Pero si se eliminan las páginas sucias, entonces las páginas sucias deben vaciarse en el disco para su reutilización.
Verá, volvemos a la situación de tirar las páginas sucias y puede comprender la lentitud de la operación de lectura, ¿verdad?
cortar en sus principios
Sabiendo el motivo, ¿cómo podemos evitar o paliar esta situación?
Primero mire el caso de los índices que faltan:
No sé si tienes la costumbre de usar el Explain en Mysql, de todos modos, lo uso cada vez para verificar el índice de aciertos de SQL actual. Evite algunos peligros ocultos desconocidos que trae.
Aquí hay una breve introducción a su uso. Al agregar explicación antes del SQL ejecutado, puede analizar el plan de ejecución de SQL actual:

La descripción resumida de los campos correspondientes a los resultados después de la ejecución se muestra en la siguiente figura:

Aquí debe centrarse en los siguientes campos:
1, tipo
Indica cómo MySQL encuentra la fila deseada en la tabla. Los tipos comúnmente usados son: ALL, index, range, ref, eq_ref, const, system, NULL Estos tipos de izquierda a derecha, el rendimiento mejora gradualmente.
-
TODO: Mysql recorre toda la tabla para encontrar filas coincidentes;
-
index: la diferencia con ALL es que el tipo de índice solo atraviesa el árbol de índices;
-
rango: solo recupera filas en un rango dado, usando un índice para seleccionar filas;
-
ref: Indica las condiciones de coincidencia de conexión de las tablas anteriores, qué columnas o constantes se utilizan para encontrar el valor en la columna de índice;
-
eq_ref: Similar a ref, la diferencia es si es un índice único o no. Para cada valor de clave de índice, solo coincide un registro en la tabla.En términos simples, la clave principal o clave única se usa como condición de asociación en uniones de varias tablas;
-
const, system: Estos tipos de acceso se utilizan cuando Mysql optimiza cierta parte de la consulta y la convierte en una constante. Si la clave principal se coloca en la lista where, Mysql puede convertir la consulta en una constante. system es un caso especial de tipo const. Cuando la tabla de consulta tiene solo una fila, use system;
-
NULL: Mysql descompone la declaración durante el proceso de optimización y ni siquiera necesita acceder a la tabla o índice durante la ejecución.Por ejemplo, la selección del valor mínimo de una columna de índice se puede realizar a través de una búsqueda de índice separada.
2, llaves_posibles
Índices que se pueden usar al realizar consultas (pero no se usan necesariamente y se muestran como NULL si no hay índice).
3, clave
El índice realmente utilizado.
4 filas
Estime el número de filas necesarias para encontrar el registro correspondiente.
5, adicional
Los más comunes son los siguientes:
-
Utilizando índice: Indica que se utiliza el índice de cobertura, y no hay necesidad de volver a la tabla;
-
Usando where: en lugar de leer toda la información de la tabla, los datos requeridos se pueden obtener solo a través del índice, esto ocurre cuando todas las columnas solicitadas de la tabla forman parte del mismo índice, lo que indica que el servidor mysql recuperará filas en el motor de almacenamiento y luego el filtro;
-
Usar temporal: Indica que MySQL necesita usar una tabla temporal para almacenar el conjunto de resultados, lo cual es común en la clasificación y agrupación de consultas, común agrupar por, ordenar por;
-
Uso de clasificación de archivos: cuando la consulta contiene una orden por operación, y la operación de clasificación que no se puede completar con el índice se denomina "clasificación de archivos".
Para la situación de cepillado de páginas sucias, necesitamos controlar la proporción de páginas sucias para que no se acerque al 75 %. Al mismo tiempo, también debe controlar la velocidad de escritura del registro de rehacer y decirle a InnoDB la capacidad de su disco configurando el parámetro innodb_io_capacity.
Resumir
Siempre nos gusta admirar a los maestros de las grandes fábricas, pero de hecho los maestros no son más que mortales. En comparación con los programadores novatos, piensan un poco más. Si no trabajas duro, la brecha solo se ampliará.
Las preguntas de la entrevista son más o menos útiles para lo que va a hacer a continuación, pero espero que pueda resumir sus propias deficiencias a través de las preguntas de la entrevista para mejorar su competitividad técnica básica. ¡Cada experiencia de entrevista es una alfabetización de sus habilidades, y el efecto de revisión y resumen después de la entrevista es excelente! Si necesita esta versión completa de las notas de la entrevista real , solo necesita respaldar mi artículo.
Cómo obtener la información: haga clic aquí para descargar gratis
Resuma sus propias deficiencias para mejorar su competitividad técnica básica. ¡Cada experiencia de entrevista es una alfabetización de sus habilidades, y el efecto de revisión y resumen después de la entrevista es excelente! Si necesita esta versión completa de las notas de la entrevista real , solo necesita respaldar mi artículo.
Cómo obtener la información: haga clic aquí para descargar gratis