Tabla de contenido
3. Por qué es eficiente la ausencia de bloqueo
3, referencia con sello atómico
4、Referencia con sello atómico
2. Campos clave importantes de LongAdder
Principio de intercambio falso
1. CAS
1. Introducción
Echemos un vistazo a este código. Hemos creado un nuevo AtomicInteger para lograr la seguridad de subprocesos. Al actualizar, primero obtenemos el valor anterior, luego lo modificamos y luego llamamos al método compareAndSet para actualizar. Si tiene éxito, regresará, y si falla, continuará intentándolo en un bucle .
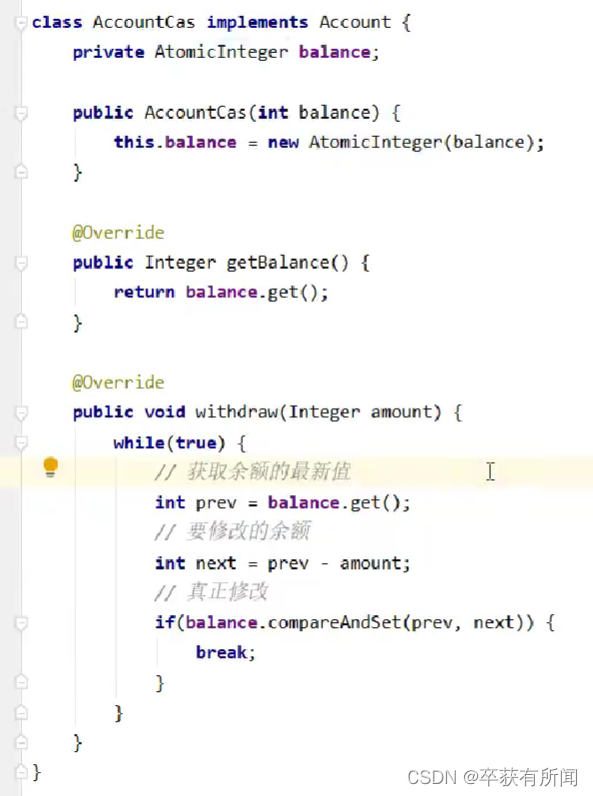
La clave es este compareAndSet. Esta operación es para detectar si la modificación antes y después de la modificación es atómica. Si lo es, tiene éxito. La abreviatura es CAS
El proceso lento aproximado es así: si el subproceso 1 usa cas para operar, si hay un subproceso en medio del proceso de modificación del subproceso para cambiar los datos, fallará y volverá a intentarlo.
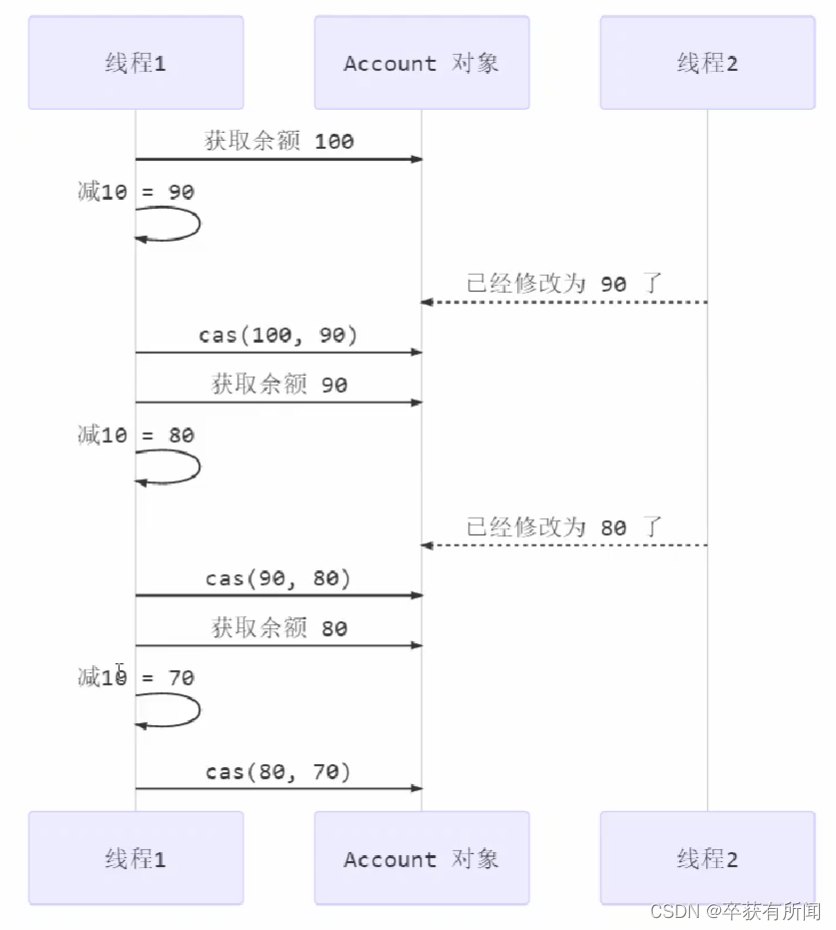
Nota: La capa inferior de cas es la atomicidad garantizada por la instrucción lock cmpxchg (arquitectura x86) tanto en CPU de un solo núcleo como en CPU de varios núcleos.
(En el estado de varios núcleos, cuando un núcleo ejecuta una instrucción con un bloqueo, la CPU bloqueará el bus. Cuando el núcleo ejecute la instrucción, volverá a abrir el bus. Este proceso no será interrumpido por el mecanismo de programación de otros subprocesos. , lo que garantiza la precisión de las operaciones de memoria mediante múltiples subprocesos y es atómico)
2. CAS y volátil
Hicimos clic en la clase AtomicInteger y descubrimos que su atributo de valor tiene un indicador volátil agregado para garantizar la visibilidad de la variable en subprocesos múltiples. Debido a que debe obtener el último para compararlo con cas cada vez, si obtiene el anterior, definitivamente tendrá éxito directamente, por lo que cas debe cooperar con volátil para desempeñar un papel.
3. Por qué es eficiente la ausencia de bloqueo
En el caso de que no haya bloqueo, incluso si el reintento falla, el subproceso siempre se ejecuta a alta velocidad sin detenerse, y syn hará que el contexto del subproceso cambie cuando el subproceso no esté bloqueado (el estado del subproceso cambia de ejecución a bloqueo y el el cambio de contexto de la CPU costará más, porque quiere guardar la información del hilo y restaurarla cuando se despierte nuevamente)
Pero en el caso de que no haya bloqueo, debido a que se debe garantizar que el subproceso se ejecute, necesita soporte de CPU adicional. Aquí, la CPU es como una pista de alta velocidad. Sin una pista adicional, el subproceso no puede ejecutarse. Aunque no lo será. bloqueado, porque no hay un intervalo de tiempo, ¿todavía entrará en un estado ejecutable o provocará un cambio de contexto?
4. Resumen
La combinación de cas y volatile puede lograr una concurrencia sin bloqueos, que se puede usar en escenarios con menos subprocesos y CPU multinúcleo
cas se basa en la idea de bloqueo optimista: la estimación más optimista, sin miedo a otros subprocesos para modificar variables compartidas y volver a intentar después de cambiar
Synchronized se basa en la idea del bloqueo pesimista: es necesario evitar que otros subprocesos modifiquen las variables compartidas y bloquearlas antes de la operación
CAS encarna la concurrencia sin bloqueo y la concurrencia sin bloqueo. Debido a que no se usa syn, los subprocesos múltiples no se bloquearán. Este es uno de los factores que mejoran la eficiencia, pero si la competencia es feroz, afectará la eficiencia.
2. Números enteros atómicos
AtomicInteger es un ejemplo, los principios de AtomicBoolean y AtomicLong son similares a él.
Como se mencionó anteriormente, la capa inferior es usar un valor modificado volátil para garantizar la visibilidad y usar cas para garantizar la seguridad del subproceso.
(volátil puede garantizar el orden, el mismo principio que el singleton, si las instrucciones de la CPU se reorganizan, puede haber problemas al leer, pero agregar una barrera de escritura volátil no causará este problema de asignación de línea)
Hay un método incrementAndGet que significa ++i, y el método getAndIncrement es i++
Para implementar manualmente un cálculo seguro para subprocesos:
(IntUaryOperator es una interfaz con un solo método, una interfaz funcional, que se puede escribir con expresiones lamda, de modo que se usa un patrón de estrategia para saber qué operación hacer, y simplemente pasar un método de la clase de implementación)
public static void updateAndGet(AtomicInteger i, IntUnaryOperator operator){
while(ture){
int prev = i.get();
int next = operator.applyAsInt(prev);
if(i.compareAndSet(prev, next)){
break;
}
}
}3. Referencias atómicas
1. Introducción
AtomicReference, el tipo que queremos proteger no es necesariamente un tipo básico. Si desea proteger un tipo decimal como BigDecimal, debe usar referencias atómicas para garantizar la seguridad de subprocesos.
2. Problemas ABA
En el proceso cas, es solo para juzgar si los valores antes y después son los mismos, y lo mismo tiene éxito, pero en este proceso, otros subprocesos cambian y vuelven a cambiar, aún puede tener éxito, este es el problema de aba , de hecho, la variable se modifica pero ese subproceso no es consciente de ello, y no afectará al negocio en la mayoría de los escenarios
3, referencia con sello atómico
Si queremos que el subproceso sepa si se ha modificado el cas, debemos usar AtomicStampedReference
La capa inferior es para agregar un número de versión sobre la base de AtomicReference, y el número de versión aumentará cada vez que se modifique
4、Referencia con sello atómico
Con el mecanismo de número de versión AtomicStampedReference, podemos saber cuántas veces se ha modificado en el medio, pero no necesitamos saber cuántas veces se ha modificado en el medio, solo queremos saber si se ha modificado .
De hecho, es usar boolean para marcar si se ha cambiado. Es verdadero al principio, mientras se modifique, se convertirá en falso. Si es falso, no tendrá éxito. Después de que tenga éxito, no tendrá éxito. también lo cambiará a falso.
4. Acumulador atómico
1. Introducción
Después de JAVA 8, para acelerar la eficiencia de autoincremento de los enteros atómicos, la clase de autoincremento especialmente diseñada es LongAdder. Es obra del maestro de concurrencia Doug Lea, y el diseño es muy delicado.
El principio de mejora del rendimiento: porque cada vez que se actualiza una unidad, cas continuará intentándolo cuando haya competencia, lo que puede afectar la eficiencia, por lo que configuró varias unidades, el subproceso 1 se cambia a 1 celda unitaria y el subproceso 2 se cambia a 2 unidades, por lo tanto, reduzca la cantidad de reintentos de CAS para mejorar el rendimiento, pero no excederá la cantidad de núcleos de la CPU, porque no tiene sentido
2. Campos clave importantes de LongAdder
Hay varios diseños clave en esta clase de incremento automático LongAdder

Bloqueo CAS
El cas lock es usar un atomicInteger para modificarlo.Si es 0, use cas para modificarlo a 1. Si la modificación es exitosa, significa que el bloqueo es exitoso.Cuando se libera el bloqueo, se cambia a 0 Debido a que solo se libera el hilo de bloqueo, no es necesario bloquearlo. Este tipo de bloqueo cas no debe escribirse en proyectos normales, ya que puede causar problemas. Los subprocesos que no obtienen el bloqueo seguirán intentándolo y ocuparán recursos de la CPU.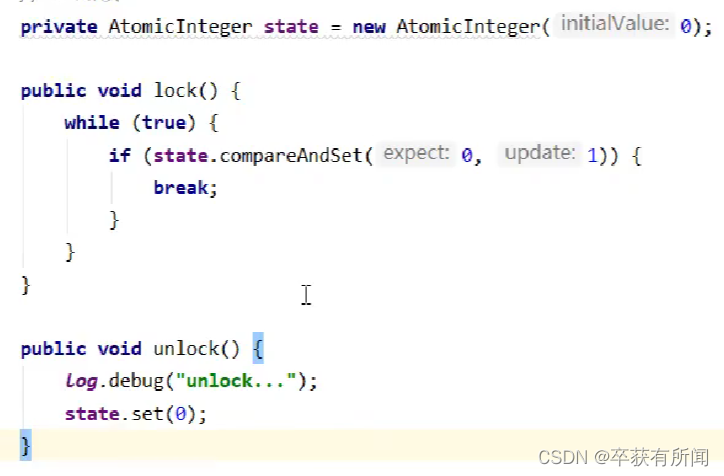
De hecho, cellBusy en el código fuente es similar al cas lock anterior , que se usa como una marca de bloqueo para garantizar la seguridad de subprocesos en ciertas situaciones. Lo usaremos al crear o expandir Cell[] .
Principio de intercambio falso
Donde Cell es la unidad de acumulación

La clase Cell tiene un atributo de valor para registrar el número de incrementos, y luego el constructor le asigna un valor, y luego hay un método cas para hacer el autoincremento, pero podemos ver que hay una anotación contenida en la clase , que es para evitar que la línea de caché sea falsa compartida
¿Qué es una línea de caché?
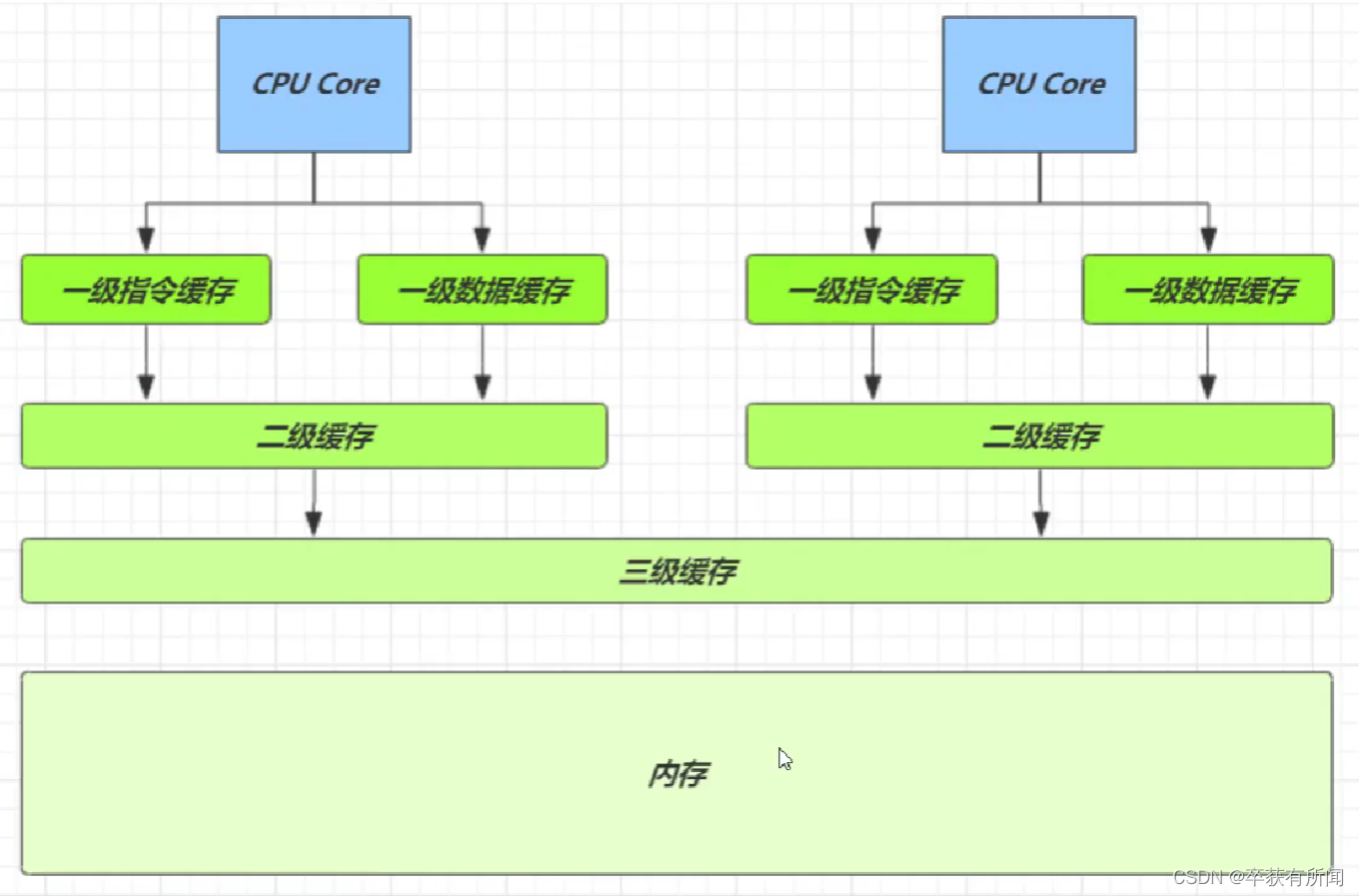
De hecho, hay muchas capas de caché. Cuanto más cerca está el caché, más rápido es. La velocidad del esclavo de primer nivel es docenas de veces más rápida que la de la memoria. El caché es una unidad de línea de caché. Cada caché línea corresponde a una pieza de memoria, generalmente 64 bytes (8 de largo)
Aunque el almacenamiento en caché puede mejorar la eficiencia, puede causar copias de datos . Los mismos datos se almacenarán en caché en las líneas de caché de diferentes núcleos. La CPU debe garantizar la consistencia de los datos. Si un núcleo de CPU cambia los datos, toda la caché corresponde a otros núcleos de CPU. La línea debe ser invalidada , lo que puede afectar la eficiencia, es decir, todas las líneas de caché serán
Toma una castaña:
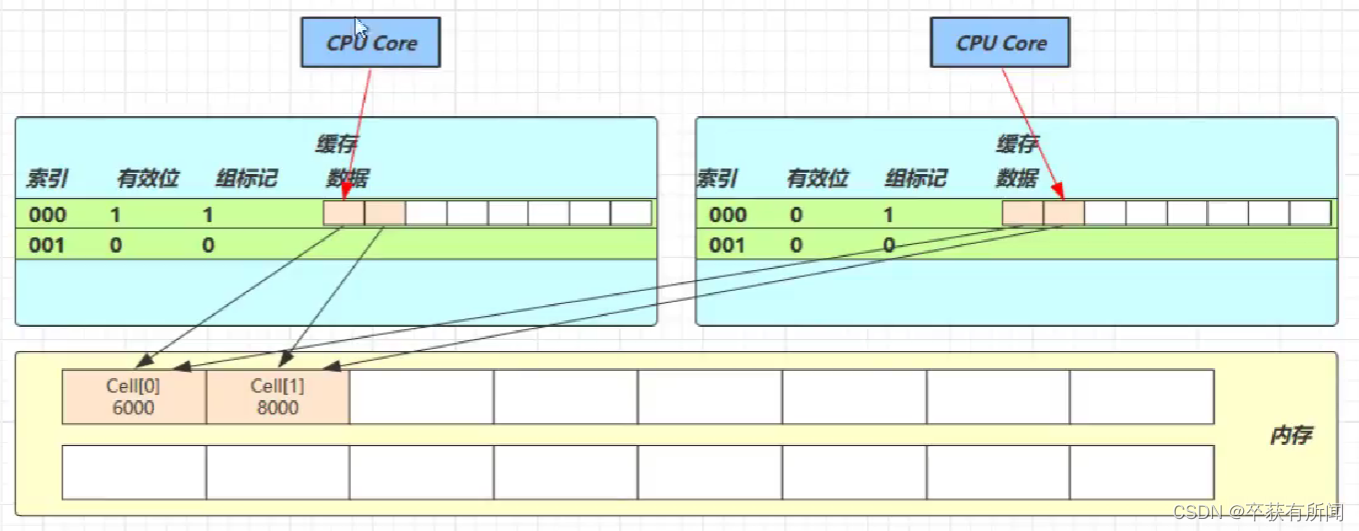
Como se muestra en la figura anterior, nuestra matriz de celdas se almacena continuamente en la memoria, y una celda tiene 24 bytes, por lo que la línea de caché puede almacenar 2 objetos de celda, por lo que surge el problema, el núcleo 1 debe cambiarse a celda[0 ], Core 1 necesita cambiar la celda [1], sin importar quién tenga éxito, invalidará la línea de caché del otro núcleo, porque están en una línea de caché, y dejará de ser válida si es modificada por otros, por lo que necesita ir a la memoria para leer de nuevo
La anotación @sum.misc.Contended se usa para resolver este problema. Su principio es agregar 128 bytes de relleno antes y después del objeto o campo que usa esta anotación, para que la CPU ocupe diferentes líneas de caché al leer previamente el objeto en el caché. , para que no cause la invalidación de la línea de caché de la otra parte

¿Por qué 128?
GPT: En JDK 8,
@Contendedlas anotaciones se implementan agregando una cierta cantidad de bytes de relleno (Padding) antes y después de la variable marcada por la anotación. Estos bytes de relleno separan la variable anotada de otras variables, evitando que varios subprocesos accedan a diferentes variables de la misma línea de caché al mismo tiempo. La longitud de los bytes de relleno suele ser una potencia entera de 2, porque la longitud de una línea de caché suele ser una potencia entera de 2. En la mayoría de los procesadores modernos, la longitud de la línea de caché suele ser de 64 bytes o 128 bytes. Por lo tanto,@Contendedla longitud de la anotación agregada a la línea de caché suele ser un múltiplo entero de la longitud de la línea de caché, lo que puede garantizar que haya suficientes bytes de relleno entre la variable marcada por la anotación y otras variables, evitando así el problema de compartir falso. En JDK 8,@Contendedlos bytes de relleno predeterminados para las anotaciones son 128 bytes, ya que esa es la longitud de una línea de caché en la mayoría de los procesadores modernos.
3. Código fuente de LongAdder
Agregar

Primero juzgará si la matriz de celdas está vacía. La matriz de celdas se crea con pereza. Es nula cuando no hay competencia al principio. Cuando ocurre la competencia, intentará crear la matriz y la celda de unidad de acumulación.
Si se juzga que está vacío, significa que no hay competencia. Vaya directamente a la base de datos básica para acumular. Si la acumulación es exitosa, regresará. Si no es exitosa, ingresará al método longAccumlate para crear. células y células.
Si se juzga que las celdas no están vacías, verifique si el subproceso actual crea una celda. Si se crea, cas acumulará las celdas. Si la acumulación falla o la celda no se crea, longAccumulate
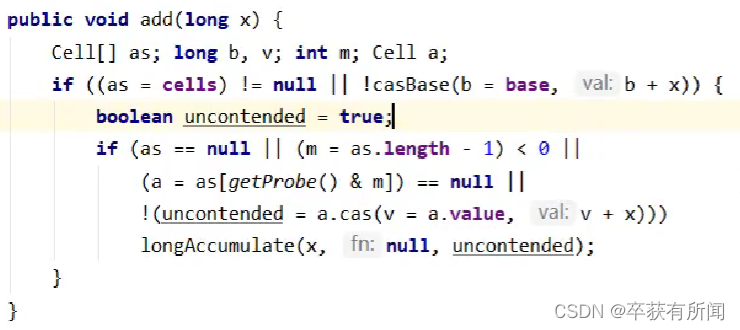
método de acumulación larga
Este método se ingresará cuando la acumulación base del subproceso falle o la acumulación de celdas del subproceso actual falle o no se creen celdas.
crear celdas

Cuando no se crean celdas, irá a crear celdas.
Si el indicador cellBusy es 0 (indicador de bloqueo cas, utilizado para garantizar la seguridad de crear una matriz), cell==as, significa que no ha sido creado por otros subprocesos, y existe una condición de que solo cuando el bloqueo cas es exitoso se pueden crear las celdas con éxito e inicializar una celda (cree una matriz con un tamaño de 2 al principio y una unidad de celda predeterminada, y luego solo cree una celda para el hilo actual , que se combinará con 1 y al azar) asignado a la posición 0 o 1, solo inicializa una celda, después de la carga diferida Se usa para reinicializar la celda)
Si el bloqueo falla, el cas se acumulará en la base, si tiene éxito, regresará, y si falla, volverá a Shun Xun e intentará nuevamente.
crear celdas
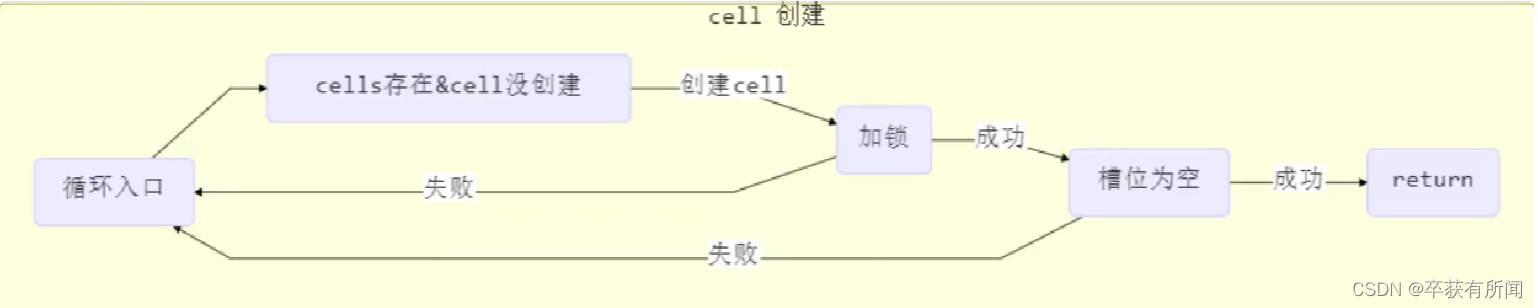
La creación de la matriz solo creará la celda de unidad de acumulación para el subproceso actual. Si otros subprocesos ven que hay celdas de matriz, pero no hay celdas, se crearán.
También creará el bloqueo cas de celdas ocupadas primero. Si es 0, se puede bloquear, crear un objeto de celda y luego juzgar si el bloqueo cas es exitoso. También verificará si la matriz está vacía y si la celda tiene sido creado Si no hay problema, simplemente El objeto se asigna a la ranura vacía y tiene éxito. Si hay una falla de juicio en el medio, recicle y vuelva a intentarlo
celda de acumulacion cas
Primero juzgue que existen celdas y celdas. Si tiene éxito, cas acumulará las celdas y regresará con éxito. Si falla, verifique si la longitud de la matriz es mayor que la línea de la CPU. Si es mayor que eso, no se expandirá. Recién ahora no hay manera de ampliar la capacidad cuando es más grande que la cpu, en este momento intentaré cambiarle una celda y reciclar para ver si la acumulación puede ser exitosa. Si la cpu directa es más pequeña que y se obtiene el bloqueo de cas, amplíe directamente la capacidad.
La expansión consiste en crear una nueva matriz con la longitud original <<1 (el doble del tamaño), y luego copiar el contenido de la matriz anterior en la nueva matriz y reemplazarla. Finalmente, si la expansión tiene éxito, se reciclará. el ciclo puede crear uno nuevo objeto de celda para incrementar
método de suma
La operación estadística final de tantas unidades de acumulación es usar este método de suma. De hecho, es recorrer directamente este número. Si no está vacío, seguirá acumulándose y finalmente regresará.

5. Inseguro
El objeto Unsafa proporciona un método de muy bajo nivel para manipular la memoria y los subprocesos , que no se puede llamar directamente, sino que solo se puede obtener a través de la reflexión.
Es una clase bajo el paquete sum.misc. Final no se puede heredar. Tiene una variable de una sola columna final estática privada, por lo que solo se puede activar a través de la reflexión. Debido a que es de nivel relativamente bajo, no se recomienda para programadores. para usarlo Se llama inseguro
incrementAndGet (++i) de AtomicInteger usa el método getAndAddInt de este objeto inseguro
Use el método objectFeildOffset de inseguro para obtener su desplazamiento en la memoria, y luego puede operar directamente la memoria (use el método compareAndSwap de cas para pasar el objeto y el desplazamiento y el valor antes y después de la modificación)