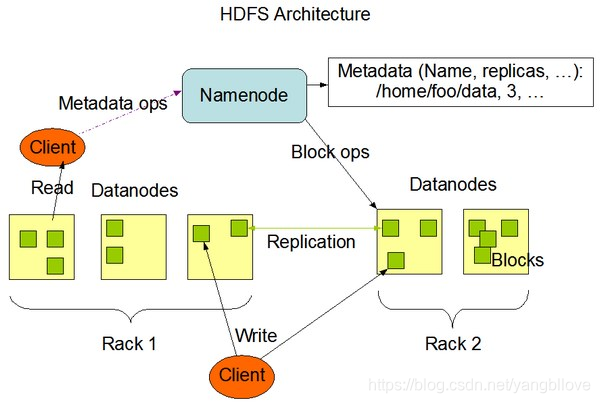
1. Diagrama de arquitectura de hadoop 1.xy 2.x
1. Diagrama de arquitectura
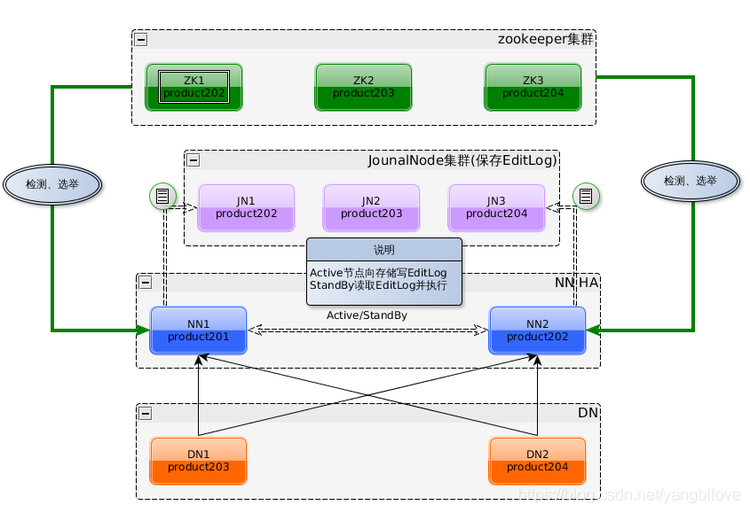
hadoop2.x resolvió el único punto de falla de NameNode en 1.x introduciendo la arquitectura dual NameNode y simultáneamente usando el sistema de almacenamiento compartido Quorum Journal Manager QJM para sincronizar los metadatos.
2. metadatos hadoop2.x
La función principal de los metadatos de Hadoop es mantener información sobre archivos y directorios en el sistema de archivos HDFS. Existen tres tipos principales de almacenamiento de metadatos: duplicación de memoria, duplicación de disco (FSImage) y registro (EditLog) . Cuando se inicia Namenode, cargará la imagen del disco en la memoria para la gestión de metadatos y la almacenará en la memoria NameNode; la imagen del disco es una instantánea de la información de metadatos HDFS en un momento determinado, incluidas todas las relaciones de mapeo de bloques de archivos del nodo Datanode relacionadas y espacios de nombres Información (Espacio de nombres), almacenada en el sistema de archivos local NameNode ; el archivo de registro registra cada información de operación iniciada por el cliente, es decir, guarda todas las modificaciones en el sistema de archivos, que se utilizan para fusionarse periódicamente con la imagen del disco en la última imagen, para garantizar la información de metadatos NameNode Completo, almacenado en el sistema de almacenamiento local y compartido NameNode (QJM) .
A continuación se muestran los formatos de archivo EditLog y FSImage del NameNode. El archivo EditLog tiene dos estados: inprocess y finalized , inprocess indica el archivo de registro que se está escribiendo y el nombre del archivo tiene la forma de editsinprocess [start-txid], y finalized indica el registro que se ha escrito. Archivo, forma del nombre del archivo: ediciones [start-txid] [end-txid]; el archivo FSImage también tiene dos estados, finalizado y punto de verificación , finalizado significa que el archivo ha sido un disco persistente, forma de nombre de archivo: fsimage_ [end-txid], punto de verificación Representa fsimage en la fusión. El proceso de punto de control de la versión 2.x se realiza en el Standby Namenode (SNN). El SNN fusionará periódicamente la FSImage local y el EditLog del ANN retirado de QJM. Una vez completada la fusión, se devolverá al ANN a través de RPC.
data / hbase / runtime / namespace
├── current
│ ├── VERSION
│ ├── edits_0000000003619794209-0000000003619813881
│ ├── edits_0000000003619813882-0000000003619831665
│ ├── edits_0000000003619831666-0000
520000 520000 5200000000000000000000000000000000000000000000MTTKT300000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003636 de 3800000000000000000000000003619813881 │000000000003619813882-0000000003619831664
├── edits_0000000003619871028-0000000003619880765 │
│ ├── edits_0000000003619880766-0000000003620060869
│ ├── edits_inprogress_0000000003620060870
│ ├── fsimage_0000000003618370058
│ ├── fsimage_0000000003618370058.md5
│ ├── fsimage_0000000003620060869
│ ├── fsimage_0000000003620060869.md5
│ └── seen_txid
└─ ─ in_use.lock
Otro archivo importante que se muestra arriba es seen_txid, que guarda un ID de transacción . Este ID de transacción es el último ID de transacción final de EditLog. Cuando se reinicia NameNode, se desplazará secuencialmente desde edits_0000000000000000001 a seen_txid. El archivo de registro donde se encuentra el txid grabado se utiliza para la recuperación de metadatos. Si el archivo se pierde o la ID de la transacción registrada es defectuosa, se perderá la información del bloque de datos.
La esencia de HA es garantizar que los metadatos del NN maestro y en espera sean consistentes, es decir, garantizar que fsimage y editlog también estén completos en el NN en espera. La sincronización de metadatos depende en gran medida de la sincronización de EditLog, y la clave de este paso es el sistema de archivos compartidos. Comencemos con el mecanismo de almacenamiento compartido QJM.
Segundo, principio QJM
1. Introducción a QJM
El nombre completo de QJM es Quorum Journal Manager, compuesto por JournalNode (JN), generalmente compuesto por nodos impares. Cada JournalNode tiene una interfaz RPC simple para NameNode para leer y escribir EditLog en el disco local JN. Al escribir un EditLog, NameNode escribirá archivos en todos los JournalNodes en paralelo al mismo tiempo. Mientras los nodos N / 2 + 1 escriban con éxito, la operación de escritura se considera exitosa y se sigue el protocolo Paxos. El marco de implementación interno es el siguiente:
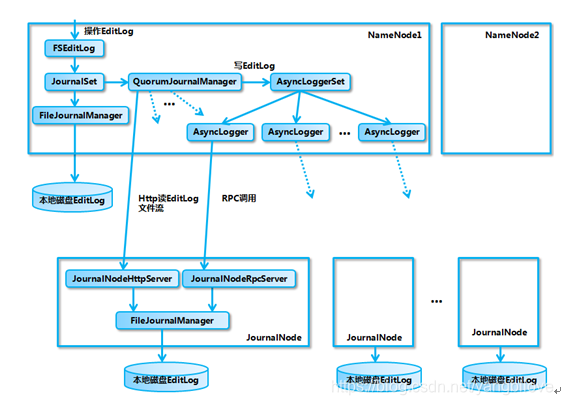
se puede ver en la figura que involucra principalmente diferentes objetos de administración y objetos de flujo de salida relacionados con EditLog, y cada objeto desempeña su propio papel diferente:
FSEditLog: la entrada de todas las operaciones EditLog
: JournalSet: integración de discos locales y operaciones relacionadas de
EditLog en el clúster JournalNode FileJournalManager: implementación de operaciones EditLog en discos locales
QuorumJournalManager: implementación del clúster JournalNode Operaciones
EditLog AsyncLoggerSet: implementación del clúster JournalNode Clúster EditLog recopilación de
solicitudes de inicio de registro RL Logging Asy Para JN, realice la función de sincronización de registro específica
JournalNodeRpcServer: servicio RPC que se ejecuta en el proceso del nodo JournalNode, recibiendo la solicitud RPC del AsyncLogger en el lado NameNode.
JournalNodeHttpServer: un servicio Http que se ejecuta en el proceso del nodo JournalNode, utilizado para recibir solicitudes de sincronización de secuencias de archivos EditLog entre NameNode y otros JournalNodes en estado de espera .
2. Análisis del proceso de escritura QJM
Como se mencionó anteriormente para EditLog, NameNode escribirá EditLog en local y JournalNode. La escritura local está controlada por el parámetro dfs.namenode.name.dir en la configuración, la escritura JN está controlada por el parámetro dfs.namenode.shared.edits.dir, y se utilizan dos flujos de salida diferentes para controlar el proceso de escritura de registros al escribir EditLog, respectivamente Para: EditLogFileOutputStream (flujo de salida local) y QuorumOutputStream (flujo de salida JN). Escribir EditLog no se escribe directamente en el disco. Para garantizar un alto rendimiento, NameNode definirá dos Buffers de igual tamaño para EditLogFileOutputStream y QuorumOutputStream, el tamaño es de aproximadamente 512 KB, un Buffer de escritura (buffCurrent), un Buffer síncrono (buffReady), de esta manera Puede sincronizar mientras escribe, por lo que EditLog es un proceso de escritura asincrónico, pero también un proceso de sincronización por lotes para evitar sincronizar el registro cada vez que se realiza una escritura. Este mecanismo de escritura asincrónica de doble búfer puede convertir metadatos hdfs del disco de escritura a la memoria de escritura. Si el tamaño del clúster es grande, más de 100 unidades, el búfer de metadatos puede convertirse en una condición limitante. Puede reescribir el código fuente y ajustar el tamaño de 512 kb a aproximadamente 5 mb. Además, también puede consultar otros parámetros de configuración de Hadoop para extraer esta opción y configurarla desde el archivo de configuración. Actualmente, la configuración no es compatible.
¿Cómo logra esto la sincronización mientras se escribe? En realidad, hay un proceso de intercambio de buffer en el medio, es decir, bufferCurrent y buffReady activarán el intercambio cuando se alcance la condición , como cuando bufferCurrent alcanza el umbral y los datos de bufferReady se sincronizan nuevamente, bufferReady Los datos se borrarán, al mismo tiempo que el puntero bufferCurrent apuntará a bufferReady para continuar escribiendo, y el puntero bufferReady se apuntará a bufferCurrent para proporcionar una sincronización continua del EditLog. El proceso anterior está representado por un diagrama de flujo de la siguiente manera:
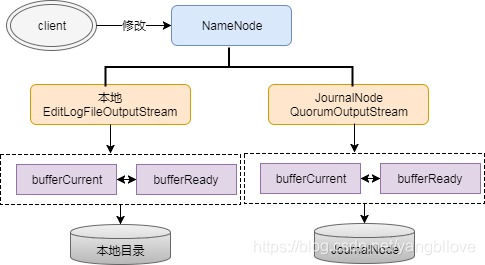
Pregunta uno:
Dado que EditLog se escribe de forma asincrónica, de hecho, cómo asegurarse de que los datos en la memoria caché no se pierdan, de hecho, aunque es asíncrono, pero todos los registros deben sincronizarse con éxito mediante logSync antes de devolver un código de éxito al cliente , suponiendo que NameNode no esté disponible en un momento determinado Los datos en su memoria en realidad no se sincronizan correctamente, por lo que el cliente pensará que esta parte de los datos no se ha escrito correctamente.
Pregunta dos:
¿Cómo puede EditLog ser coherente en varios JN?
1. Escritura doble aislada
Cada vez que ANN sincroniza EditLog a JN, es necesario asegurarse de que no haya dos NN que puedan sincronizar registros a JN al mismo tiempo. ¿Cómo se hace este aislamiento? Esto implica un concepto importante, Epoch Numbers, que se utiliza en muchos sistemas distribuidos. La época tiene las siguientes características:
- Cuando NN se convierte en el nodo activo, se le dará un Número de Época
- Cada EpochNumber es único, y no aparecerá el mismo EpochNumber
- EpochNumber tiene una garantía de orden estricta. Después de cada cambio de NN, su EpochNumber aumentará en uno. El EpochNumber generado más tarde será mayor que el EpochNumber anterior.
¿Cómo asegura el QJM las características anteriores? Los puntos principales para usar EpochNumber son: - En el primer paso, antes de realizar cambios en EditLog, el QuorumJournalManager (en el NameNode) debe recibir un EpochNumber
- En el segundo paso, QJM envía su EpochNumber a todos los nodos JN a través de newEpoch (N)
- El tercer paso, cuando JN recibe la solicitud newEpoch, guardará EpochNumber de QJM en una variable lastPromisedEpoch y la mantendrá en el disco local.
- En el cuarto paso, cualquier solicitud de RPC (como logEdits (), startLogSegment (), etc.) que ANN sincroniza los registros con JN debe incluir el número de época de ANN
- En el quinto paso, después de recibir la solicitud RPC, JN la comparará con lastPromisedEpoch. Si el EpochNumber solicitado es menor que lastPromisedEpoch, la solicitud de sincronización será rechazada. De lo contrario, la solicitud de sincronización será aceptada y el EpochNumber solicitado se guardará en lastPromisedEpoch
De esta manera, se puede garantizar que cuando se cambia el NN maestro en espera, incluso si el registro se sincroniza con el JN al mismo tiempo, el registro no se verá afectado, porque después del cambio, el Número de Epoché original de ANN es definitivamente más pequeño que el nuevo Número de Epoché de ANN, por lo que el número de ANN al JN original Todas las solicitudes de sincronización iniciadas serán rechazadas, y la función de aislamiento se implementará para evitar la división del cerebro.
2. Sincronización de registros
Este paso ha introducido el proceso de sincronización de registros de ANN a JN, de la siguiente manera:
- 1 Ejecute el proceso logSync y coloque los datos de registro en ANN en la cola de caché
- 2 Sincronice los datos en el caché a JN, y JN tiene hilos correspondientes para procesar las solicitudes de logEdits
- 3 Después de recibir los datos, JN primero confirma si EpochNumber es legal, luego verifica si el ID de la transacción de registro es normal, muestra el registro en el disco y devuelve el código de éxito ANN
- 4 ANN devuelve el indicador de éxito de escritura del cliente después de recibir la solicitud JN exitosa y lanza una excepción si falla
3. Restaurar el registro en proceso
¿Por qué este paso? Si la escritura falla durante el proceso de escritura, la longitud del EditLog en cada JN puede ser diferente, y es necesario restaurar las partes inconsistentes antes de comenzar a escribir . El mecanismo de recuperación es el siguiente (en resumen, es comparar y confirmar primero la actualización de EpochNumber, y luego realizar la recuperación del registro basado en el EditLogSegment más grande devuelto por JN. Después de la recuperación exitosa, cambie el estado del registro a finalizado):
- 1 ANN primero envía solicitudes getJournalState a todos los JN;
- 2 JN devolverá una Epoch (lastPromisedEpoch) a ANN;
- 3 Después de recibir la mayoría de las Épocas de JN, ANN selecciona la más grande y agrega 1 como la nueva Época actual, y luego envía una nueva solicitud de nueva Época a JN para entregar la nueva Época a JN;
- 4 Después de que JN reciba la nueva Epoch, compárela con lastPromisedEpoch. Si es más grande, se actualizará al local y se devolverá a ANN. El último Id. De transacción de inicio de EditLogSegment local, si es pequeño, devolverá un error NN;
- 5 Después de recibir la mayoría de las respuestas exitosas de JN, ANN cree que Epoch se genera con éxito y comienza a prepararse para la recuperación de registros;
- 6 ANN seleccionará la ID de transacción EditLogSegment más grande como base para la recuperación, y luego enviará prepareRecovery a JN; solicitud RPC, correspondiente a la Fase 1a de la fase 2p del protocolo Paxos. Si la mayoría de las JN responden a prepareRecovery con éxito, entonces la Fase1a puede considerarse exitosa;
- 7 ANN selecciona la fuente de datos para la sincronización, envía una solicitud acceptRecovery RPC a JN y pasa la fuente de datos como un parámetro a JN.
- 8 Después de que JN reciba la solicitud acceptRecovery, descargará el EditLogSegment de JournalNodeHttpServer y lo reemplazará con el EditLogSegment guardado localmente, que corresponde a la Fase1b de la etapa 2p del protocolo Paxos. Al finalizar, devuelve el estado del éxito de la solicitud ANN.
- 9 Después de que ANN recibe la solicitud de respuesta exitosa de la mayoría de los JN, envía una solicitud finalizeLogSegment a JN, indicando que la recuperación de datos se ha completado, de modo que los registros en todos los JN permanecerán consistentes.
Después de restaurar los datos, el registro en el estado en proceso se renombrará al registro en el estado finalizado en forma de ediciones [start-txid] [stop-txid].
2. Análisis del proceso de lectura de QJM
Este proceso de lectura está orientado hacia NN en espera (SNN), que revisa periódicamente el EditLog en JournalNode en busca de cambios y luego tira el EditLog nuevamente al local. Hay un subproceso StandbyCheckpointer en el SNN, que fusionará periódicamente FSImage y EditLog en el SNN, y transferirá el archivo FSImage combinado de nuevo al NN principal (ANN), que es el proceso de Checkpointing. Echemos un vistazo a cómo funciona Checkpointing.
En la versión 2.x, el Checkpointing original dominado por SecondaryNameNode ha sido reemplazado por Checkpointing dominado por SNN. El siguiente es un diagrama de flujo de CheckPoint:
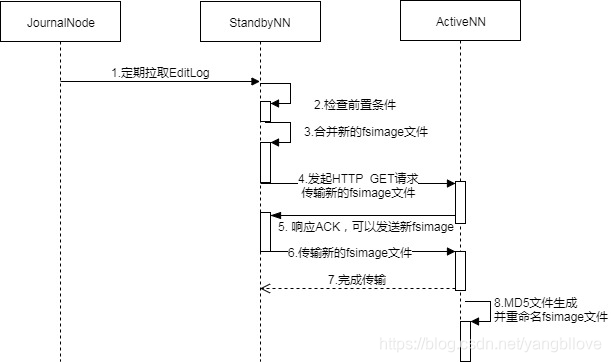
en general, las condiciones previas se verifican en el SNN: las condiciones previas incluyen dos aspectos: el intervalo desde el último Checkpointing y el límite en el número de transacciones en EditLog . Si se cumple alguna de las condiciones previas, se activará Checkpointing, y luego el SNN guardará los últimos datos de NameSpace, es decir, los metadatos del estado actual en la memoria de SNN, en un archivo temporal fsimage (fsimage.ckpt) y luego comparará el último EditLog extraído del JN ID de transacción, combine todos los registros de modificación de metadatos que no estén en fsimage.ckpt_ y EditLog y cámbieles el nombre a un nuevo archivo fsimage, y genere un archivo md5 al mismo tiempo. Envíe la última versión de fsimage a ANN a través de una solicitud HTTP. ¿Cuáles son los beneficios de fusionar fsimage regularmente, principalmente en los siguientes aspectos:
- Puede evitar que EditLog se haga más y más grande, y que el antiguo EditLog se pueda eliminar después de fusionarse en una nueva imagen f
- Puede evitar una presión excesiva en el NN principal (ANN), la fusión se realiza en el SNN
- Puede garantizar que fsimage guarda una copia de los últimos metadatos, para evitar la pérdida de datos cuando se recupera la falla
3. Mecanismo de conmutación activo y en espera
Para completar HA, además de la sincronización de metadatos, debe haber un mecanismo de conmutación maestro-esclavo completo. La elección Hadoop maestro-esclavo se basa en ZooKeeper. El siguiente es el diagrama de estado del conmutador maestro-esclavo:
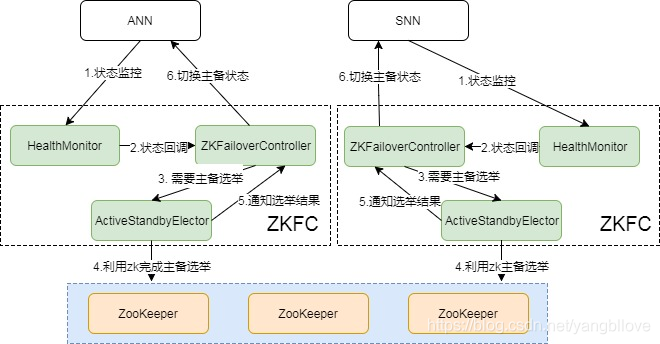
Como se puede ver en la figura, todo el proceso del conmutador está controlado por ZKFC , que se puede dividir en tres componentes: HealthMonitor, ZKFailoverController y ActiveStandbyElector.
- ZKFailoverController: es el padre de HealthMontior y ActiveStandbyElector, y realiza operaciones de conmutación específicas
- HealthMonitor: monitorea el estado de salud del NameNode. Si el estado es anormal, activará la devolución de llamada ZKFailoverController para cambiar automáticamente el estado activo y en espera
- ActiveStandbyElector: notifique a ZK para realizar la elección maestro-esclavo, si ZK completa el cambio, volverá a llamar al método correspondiente de ZKFailoverController para cambiar el estado de espera maestro
Durante la conmutación por error, qué papel desempeña principalmente ZooKeeper , tiene los siguientes puntos:
- Protección contra fallas: cada NameNode en el clúster mantendrá una sesión persistente en ZooKeeper. Una vez que la máquina se cuelga, la sesión caducará y se iniciará la migración de falla
- Selección de Active NameNode: ZooKeeper tiene un mecanismo para seleccionar ActiveNN. Una vez que el ANN existente está inactivo, otros NameNodes pueden aplicar a ZooKeeper para convertirse en el próximo nodo activo.
- División anti-cerebro: ZK en sí es muy consistente y altamente disponible, puede usarlo para asegurarse de que solo haya un nodo activo a la vez
En qué escenarios se activará la conmutación automática , los siguientes escenarios se resumen de HDFS-2185:
- ActiveNN JVM se bloquea: el estado de HealthMonitor informado en ANN tendrá una excepción de tiempo de espera de conexión, HealthMonitor activará la transición de estado a SERVICE_NOT_RESPONDING, luego ZKFC en ANN saldrá de las elecciones, ZKFC en SNN obtendrá Active Lock y se convertirá en nodo activo después del aislamiento correspondiente .
- ActiveNN JVM se congela: Esto se debe a que JVM no se ha bloqueado, pero no puede responder. Al igual que el bloqueo, activará la conmutación automática.
- ActiveNN máquina apagada: en este momento, ActiveStandbyElector perderá el latido del corazón con ZK, y la sesión se agotará. ZKFC en SNN notificará a ZK para eliminar el bloqueo activo de ANN y completar el interruptor de espera maestra después del aislamiento correspondiente.
- Estado de salud anormal de ActiveNN: en este momento, HealthMonitor recibirá una HealthCheckFailedException y activará el cambio automático.
- Bloqueo activo de ZKFC : aunque ZKFC es un proceso independiente, también es fácil causar problemas debido a su diseño simple. Una vez que el proceso ZKFC se cuelga, aunque NameNode está bien en este momento, el sistema también piensa que debe cambiarse y el SNN enviará una solicitud Cuando ANN le pide a ANN que abandone la posición del nodo principal, después de que ANN recibe la solicitud, se activará la finalización de la conmutación automática .
- Accidente de ZooKeeper : si ZK falla, el ZKFC en el NN maestro y de respaldo detectará la desconexión. En este momento, el NN maestro y de respaldo entrará en modo NeutralMode sin cambiar el estado del NN maestro y de respaldo. Si el ANN también falla, el clúster no podrá realizar la conmutación por error y no estará disponible, por lo que para este escenario, ZK generalmente no puede colgar en varias unidades, se requieren al menos N / 2 + 1 unidades para mantener el servicio para que se considere seguro. .
4. Resumen
El mecanismo HadoopHA presentado anteriormente se resume en dos partes: sincronización de metadatos y elección maestro-esclavo . La sincronización de metadatos depende del almacenamiento compartido QJM, y las elecciones maestra y de respaldo dependen de ZKFC y Zookeeper.
