Nuestra empresa tiene un proyecto con un volumen de datos de hasta 50 millones, pero debido a que los datos del informe no son precisos y la base de datos comercial y la base de datos del informe funcionan en varias bases de datos, SQL no se puede usar para la sincronización. El plan en ese momento era sincronizar a través de mysqldump o almacenamiento, pero después de probarlo, descubrí que estas soluciones no eran prácticas:
mysqldump: la copia de seguridad no solo lleva tiempo, la sincronización también lleva tiempo y, durante el proceso de copia de seguridad, puede haber salida de datos (es decir, la sincronización es igual a no sincronizar)
Método de almacenamiento: Esta eficiencia es demasiado lenta. Está bien si la cantidad de datos es pequeña. Cuando usamos este método, solo podemos sincronizar 2,000 piezas de datos en tres horas...
Después de comprobar en línea más tarde:
发现 DataX 这个工具用来同步不仅速度快,而且同步的数据量基本上也相差无几。1. Introducción a DataX
DataX es la versión de código abierto de la integración de datos de Alibaba Cloud DataWorks, que se utiliza principalmente para realizar la sincronización sin conexión entre datos. DataX se compromete a realizar funciones de sincronización de datos estables y eficientes entre varias fuentes de datos heterogéneas (es decir, diferentes bases de datos), incluidas las bases de datos relacionales (MySQL, Oracle, etc.), HDFS, Hive, ODPS, HBase, FTP, etc.

Para resolver el problema de sincronización de fuentes de datos heterogéneas, DataX ha cambiado el enlace de sincronización de malla compleja en un enlace de datos en estrella, y DataX es responsable de conectar varias fuentes de datos como un portador de transmisión intermedio, cuando se necesita acceder a una nueva fuente de datos , Simplemente conecte esta fuente de datos a DataX, y se puede sincronizar sin problemas con la fuente de datos existente.
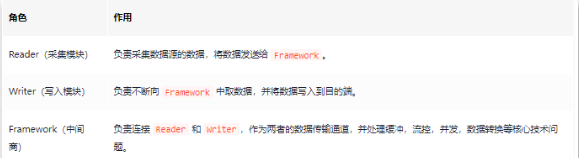
1. Diseño del marco DataX3.0
DataX adopta la arquitectura Framework + Plugin, y la abstracción de lectura y escritura de la fuente de datos se denomina complemento Reader/Writer, que se incorpora en todo el marco de sincronización.

2. Arquitectura central de DataX3.0
DataX completa un solo trabajo de sincronización de datos, al que llamamos trabajo. Después de que DataX recibe un trabajo, comenzará un proceso para completar todo el proceso de sincronización del trabajo. El módulo de trabajo de DataX es el nodo de gestión central de un solo trabajo, que lleva a cabo funciones como la limpieza de datos, la segmentación de subtareas y la gestión de grupos de tareas.
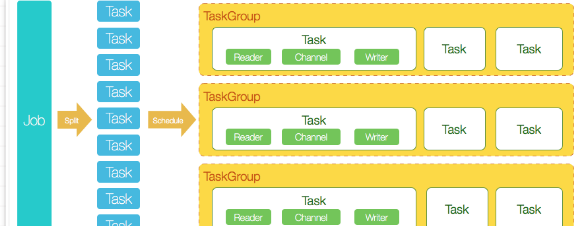
DataX Job 启动后,会根据不同源端的切分策略,将 Job 切分成多个小的 Task (子任务),以便于并发执行。接着 DataX Job 会调用 Scheduler 模块,根据配置的并发数量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组)
每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader --> Channel --> Writer 线程来完成任务同步工作。DataX 作业运行启动后,Job 会对 TaskGroup 进行监控操作,等待所有 TaskGroup 完成后,Job 便会成功退出(异常退出时 值非 0)
DataX 调度过程:
首先 DataX Job 模块会根据分库分表切分成若干个 Task,然后根据用户配置并发数,来计算需要分配多少个 TaskGroup(计算过程:Task / Channel = TaskGroup)
最后由 TaskGroup 根据分配好的并发数来运行 Task(任务)
二、使用 DataX 实现数据同步
准备工作:
JDK(1.8 以上,推荐 1.8)
Python(2,3 版本都可以)
Apache Maven 3.x(Compile DataX)(手动打包使用,使用 tar 包方式不需要安装)
安装 JDK:
[root@MySQL-1 ~]# ls
anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# tar zxf jdk-8u181-linux-x64.tar.gz
[root@DataX ~]# ls
anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# mv jdk1.8.0_181 /usr/local/java
[root@MySQL-1 ~]# cat <<END >> /etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:"$JAVA_HOME/bin"
END
[root@MySQL-1 ~]# source /etc/profile
[root@MySQL-1 ~]# java -version因为 CentOS 7 上自带 Python 2.7 的软件包,所以不需要进行安装。
1.Linux 上安装 DataX 软件
[root@MySQL-1 ~]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
[root@MySQL-1 ~]# tar zxf datax.tar.gz -C /usr/local/
[root@MySQL-1 ~]# rm -rf /usr/local/datax/plugin/*/._* # 需要删除隐藏文件 (重要)当未删除时,可能会输出:
[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 请检查您的配置文件.
验证:
[root@MySQL-1 ~]# cd /usr/local/datax/bin
[root@MySQL-1 ~]# python datax.py ../job/job.json # 用来验证是否安装成功输出
2021-12-13 19:26:28.828 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-13 19:26:28.829 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.060s | All Task WaitReaderTime 0.068s | Percentage 100.00%
2021-12-13 19:26:28.829 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-13 19:26:18
任务结束时刻 : 2021-12-13 19:26:28
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 02.DataX 基本使用
查看 streamreader --> streamwriter 的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
输出:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}根据模板编写 json 文件
[root@MySQL-1 ~]# cat <<END > test.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [ # 同步的列名 (* 表示所有)
{
"type":"string",
"value":"Hello."
},
{
"type":"string",
"value":"河北彭于晏"
},
],
"sliceRecordCount": "3" # 打印数量
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", # 编码
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)
}
}
}
}输出:(要是复制我上面的话,需要把 # 带的内容去掉)

3.安装 MySQL 数据库
分别在两台主机上安装:
[root@MySQL-1 ~]# yum -y install mariadb mariadb-server mariadb-libs mariadb-devel
[root@MySQL-1 ~]# systemctl start mariadb # 安装 MariaDB 数据库
[root@MySQL-1 ~]# mysql_secure_install # 初始化
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB
SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
Enter current password for root (enter for none): # 直接回车
OK, successfully used password, moving on...
Set root password? [Y/n] y # 配置 root 密码
New password: 123123
Re-enter new password: 123123
Password updated successfully!
Reloading privilege tables..
... Success!
Remove anonymous users? [Y/n] y # 移除匿名用户
... skipping.
Disallow root login remotely? [Y/n] n # 允许 root 远程登录
... skipping.
Remove test database and access to it? [Y/n] y # 移除测试数据库
... skipping.
Reload privilege tables now? [Y/n] y # 重新加载表
... Success!1)准备同步数据(要同步的两台主机都要有这个表)
MariaDB [(none)]> create database `course-study`;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> create table `course-study`.t_member(ID int,Name varchar(20),Email varchar(30));
Query OK, 0 rows affected (0.00 sec)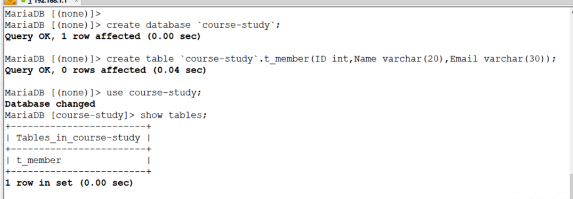
因为是使用 DataX 程序进行同步的,所以需要在双方的数据库上开放权限:
grant all privileges on *.* to root@'%' identified by '123123';
flush privileges;2)创建存储过程:
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
declare A int default 1;
while (A < 3000000)do
insert into `course-study`.t_member values(A,concat("LiSa",A),concat("LiSa",A,"@163.com"));
set A = A + 1;
END while;
END $$
DELIMITER ;
3)调用存储过程(在数据源配置,验证同步使用):
call test();4.通过 DataX 实 MySQL 数据同步
1)生成 MySQL 到 MySQL 同步的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
}
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}2)编写 json 文件:
[root@MySQL-1 ~]# vim install.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}3)验证
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py install.json
输出:
2021-12-15 16:45:15.120 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-15 16:45:15.120 [job-0] INFO StandAloneJobContainerCommunicator - Total 2999999 records, 107666651 bytes | Speed 2.57MB/s, 74999 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 82.173s | All Task WaitReaderTime 75.722s | Percentage 100.00%
2021-12-15 16:45:15.124 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-15 16:44:32
任务结束时刻 : 2021-12-15 16:45:15
任务总计耗时 : 42s
任务平均流量 : 2.57MB/s
记录写入速度 : 74999rec/s
读出记录总数 : 2999999
读写失败总数 : 0你们可以在目的数据库进行查看,是否同步完成。

上面的方式相当于是完全同步,但是当数据量较大时,同步的时候被中断,是件很痛苦的事情;
所以在有些情况下,增量同步还是蛮重要的
5.使用 DataX 进行增量同步
使用 DataX 进行全量同步和增量同步的唯一区别就是:增量同步需要使用 where 进行条件筛选。
即,同步筛选后的 SQL。
1)编写 json 文件:
[root@MySQL-1 ~]# vim where.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"where": "ID <= 1888",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}需要注意的部分就是:where(条件筛选) 和 preSql(同步前,要做的事) 参数。
2)验证:
[root@MySQL-1 ~]# python /usr/local/data/bin/data.py where.json
输出:
2021-12-16 17:34:38.534 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-16 17:34:38.534 [job-0] INFO StandAloneJobContainerCommunicator - Total 1888 records, 49543 bytes | Speed 1.61KB/s, 62 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.002s | All Task WaitReaderTime 100.570s | Percentage 100.00%
2021-12-16 17:34:38.537 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-16 17:34:06
任务结束时刻 : 2021-12-16 17:34:38
任务总计耗时 : 32s
任务平均流量 : 1.61KB/s
记录写入速度 : 62rec/s
读出记录总数 : 1888
读写失败总数 : 0目标数据库上查看:

3)基于上面数据,再次进行增量同步:
主要是 where 配置:"where": "ID > 1888 AND ID <= 2888"(通过条件筛选来进行增量同步)
同时需要将我上面的 preSql 删除 (因为我上面做的操作是 truncate 表)
