Directorio de artículos
Prefacio:
Antes, hemos estudiado tablas lineales, arreglos, cadenas y árboles, todos tienen tal defecto que la búsqueda de condiciones numéricas de datos requiere atravesar todos o parte de los datos . Entonces, ¿hay alguna manera de omitir el proceso de comparación de datos, mejorando así aún más la eficiencia de la búsqueda de condiciones numéricas?
¡La respuesta es, por supuesto, sí! En esta lección, presentaremos un artefacto de búsqueda tan eficiente: tabla hash.

Uno, que es una tabla hash
El nombre de la tabla hash se deriva de Hash y también se puede llamar tabla hash . La tabla hash es una estructura de datos especial, que es muy diferente de las estructuras de datos que hemos aprendido antes, como matrices, listas enlazadas y árboles.
1.1 Principio de la tabla hash
Una tabla hash es una estructura de datos que utiliza funciones hash para organizar los datos y permitir una rápida inserción y búsqueda . La idea central de una tabla hash es usar una función hash para asignar claves a depósitos . más específicamente:
- Cuando insertamos una nueva clave, la función hash determinará a qué depósito se debe asignar la clave y almacenará la clave en el depósito correspondiente;
- Cuando queremos buscar una clave, la tabla hash usará la misma función hash para encontrar el depósito correspondiente y solo buscará en un depósito específico.
Aquí hay un ejemplo simple, entendamos:
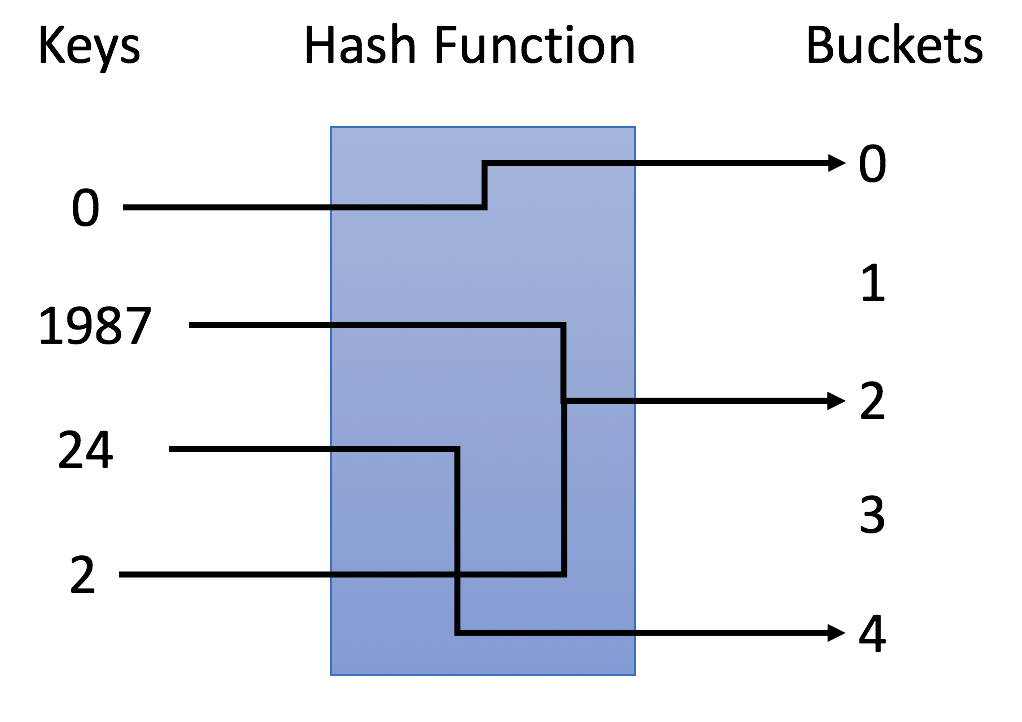
En el ejemplo, usamos y = x% 5 como función hash. Usemos este ejemplo para completar la estrategia de inserción y búsqueda:
- Inserción: analizamos las claves a través de la función hash y las asignamos a los depósitos correspondientes. Por ejemplo, 1987 se asigna al segmento 2 y 24 se asigna al segmento 4.
- Búsqueda: analizamos las claves mediante la misma función hash y buscamos solo en depósitos específicos. Por ejemplo, si buscamos 23, asignaremos 23 a 3 y buscaremos en el depósito 3. Encontramos que 23 no está en el cubo 3, lo que significa que 23 no está en la tabla hash.
1.2 Diseñar una función hash
La función hash es una tabla hash de los componentes más importantes, la tabla hash se utiliza para asignar claves a un depósito en particular . En el ejemplo anterior, usamos y = x% 5 como función hash, donde x es el valor clave e y es el índice del depósito asignado .
La función hash dependerá del rango de valores clave y el número de depósitos . A continuación se muestran algunos ejemplos de
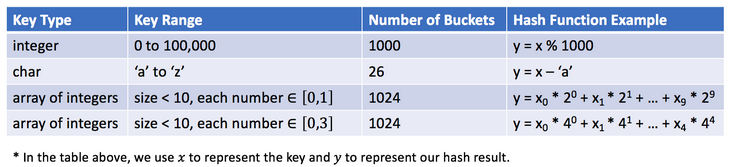
funciones hash : El diseño de funciones hash es una cuestión abierta. La idea es asignar claves a los depósitos tanto como sea posible. Idealmente, la función hash perfecta será un mapeo uno a uno entre claves y depósitos. Sin embargo, en la mayoría de los casos, la función hash no es perfecta, requiere una compensación entre la cantidad de cubos y la capacidad del cubo.
Por supuesto, también podemos personalizar algunas funciones hash. Los métodos generales son:
- Método de personalización directo . La función hash es una función lineal desde palabras clave hasta direcciones. Por ejemplo, H (tecla) = a * tecla + b. Aquí, ayb son constantes establecidas.
- Método de análisis digital . Suponga que cada clave en el conjunto de claves se compone de números de dígitos s (k1, k2, ..., Ks), y se extraen varios bits distribuidos uniformemente para formar una dirección hash.
- El cuadrado es el método chino . Si cada dígito de la palabra clave tiene ciertos dígitos repetidos y la frecuencia es muy alta, primero podemos encontrar el valor cuadrado de la palabra clave, expandir la diferencia a través del cuadrado y luego tomar los dígitos del medio como la dirección de almacenamiento final.
- Método de plegado . Si la palabra clave tiene muchos dígitos, puede dividir la palabra clave en varias partes de igual longitud y tomar el valor de su superposición y (redondear hacia arriba) como la dirección hash.
- Además del método del resto . Establezca un número p de antemano y luego realice la operación restante en la palabra clave. Es decir, la dirección es clave% p.
Dos, resuelve los conflictos de hash
Idealmente, si nuestra función hash es un mapeo uno a uno perfecto, no necesitaremos lidiar con conflictos. Desafortunadamente, en la mayoría de los casos, el conflicto es casi inevitable. Por ejemplo, en nuestra función hash anterior (y = x% 5), tanto 1987 como 2 se asignan al depósito 2, que es una colisión hash.
Se deben considerar las siguientes preguntas para resolver conflictos de hash:
- ¿Cómo organizar los valores en un mismo cubo?
- ¿Qué pasa si se asignan demasiados valores al mismo depósito?
- ¿Cómo buscar el valor objetivo en un segmento específico?
Entonces, una vez que ocurre un conflicto, ¿cómo lo resolvemos?
Hay dos métodos de uso común: el método de direccionamiento abierto y el método de direccionamiento en cadena .
2.1 Método de direccionamiento abierto
Es decir, cuando una palabra clave entra en conflicto con otra palabra clave, se forma una secuencia de detección en la tabla hash utilizando una determinada tecnología de detección, y luego se busca la secuencia de detección a su vez. Cuando se encuentra una celda vacía, se inserta en ella.
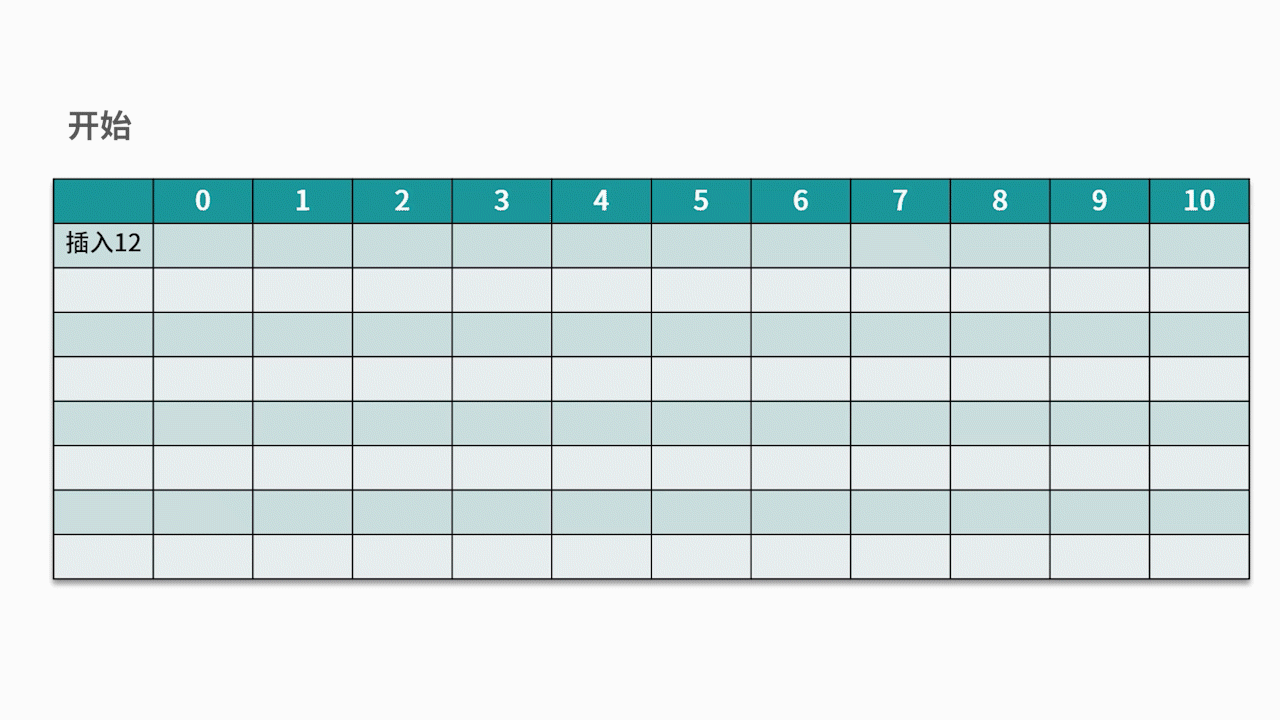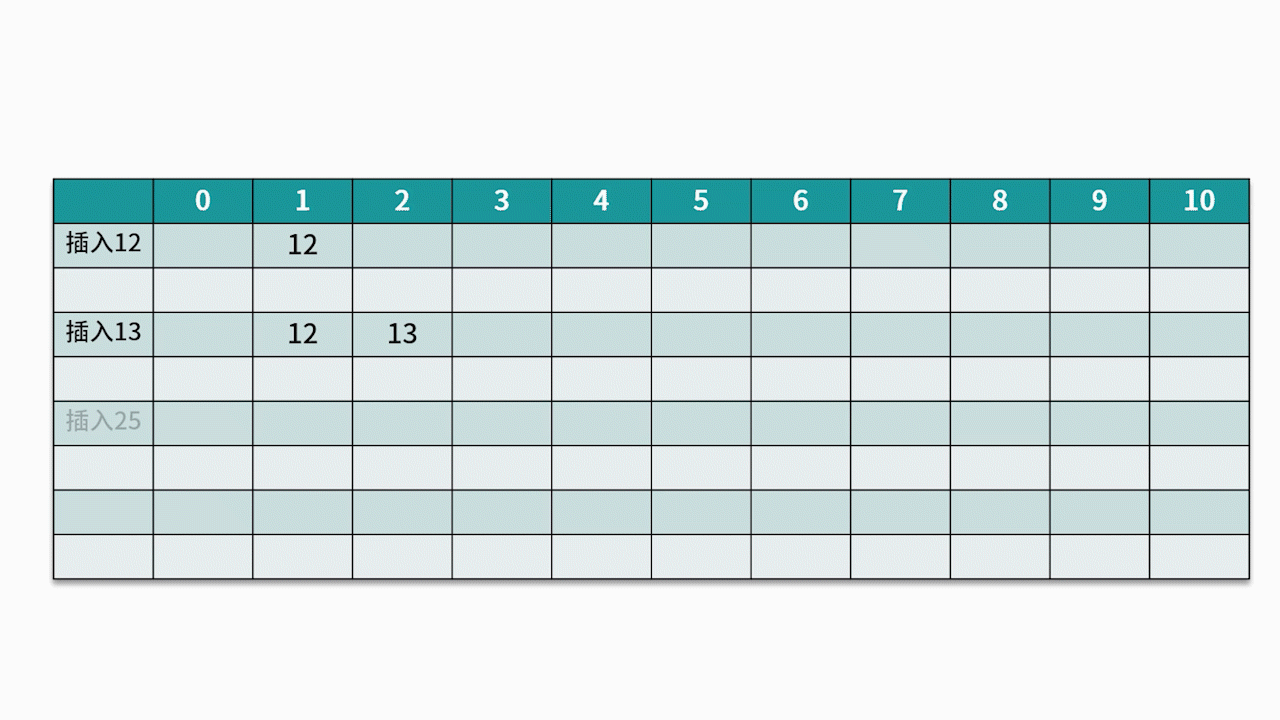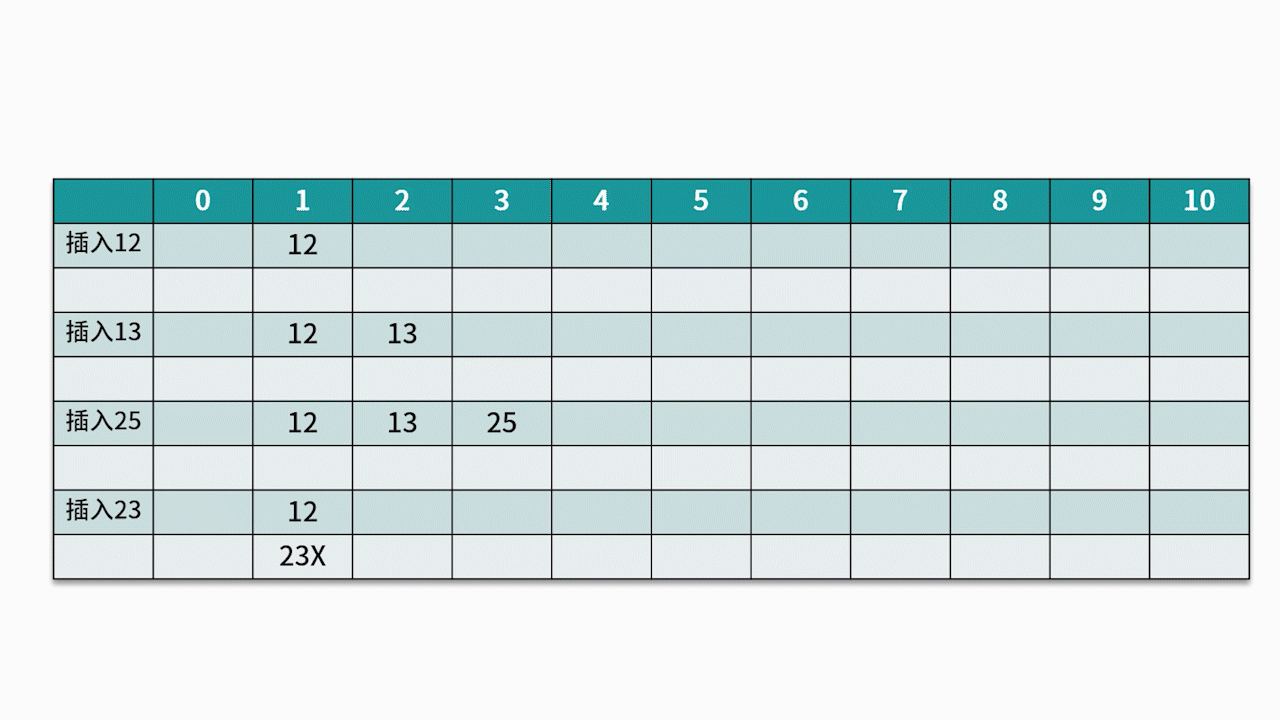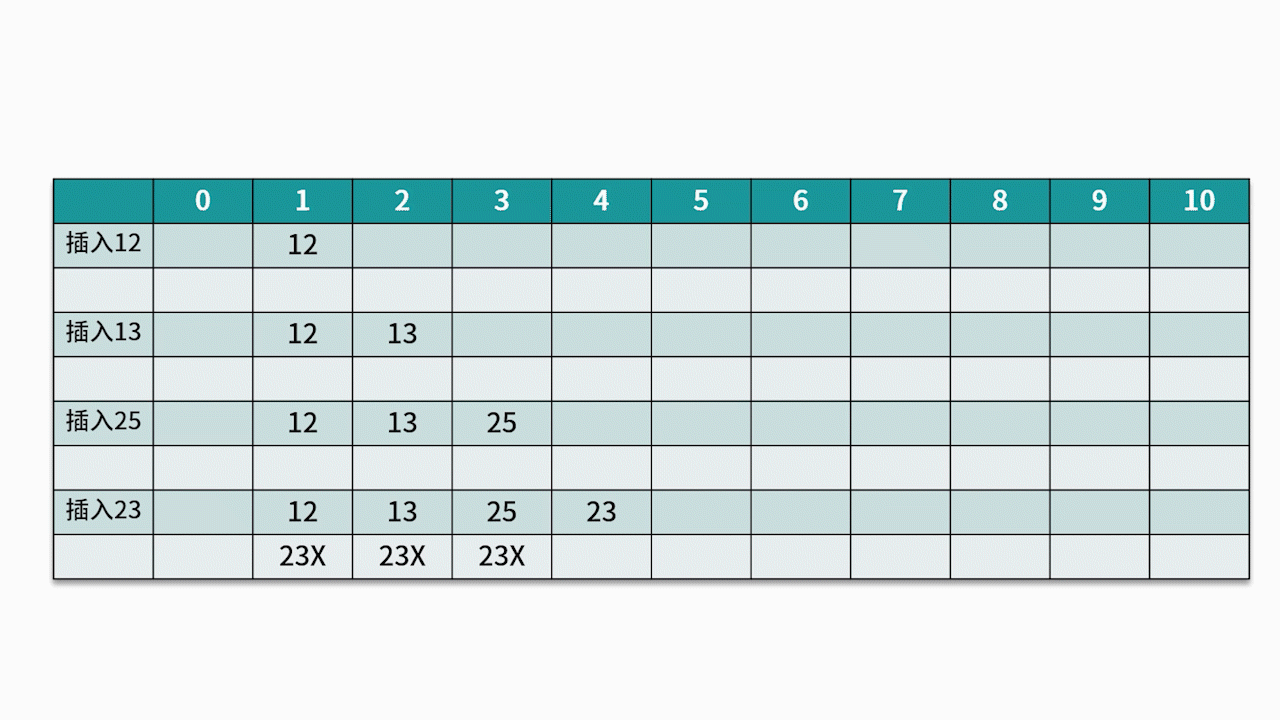
El método de detección más utilizado es el método de detección lineal . Por ejemplo, hay un conjunto de palabras clave {12, 13, 25, 23} y la función hash utilizada es la clave% 11 . Al insertar 12, 13, 25, se puede insertar directamente, las direcciones son 1, 2 y 3 respectivamente. Cuando se inserta 23, la dirección hash es 23% 11 = 1.
Sin embargo, la dirección 1 ya está ocupada, así que siga la dirección 1 en secuencia hasta que se detecte la dirección 4 y se encuentre vacía, luego se inserta 23 en ella. Como se muestra abajo:
2.2 Método de dirección en cadena
Almacene los registros con la misma dirección hash en una lista vinculada lineal. Por ejemplo, hay un conjunto de palabras clave {12,13,25,23,38,84,6,91,34} y la función hash utilizada es la clave% 11. Como se muestra abajo:
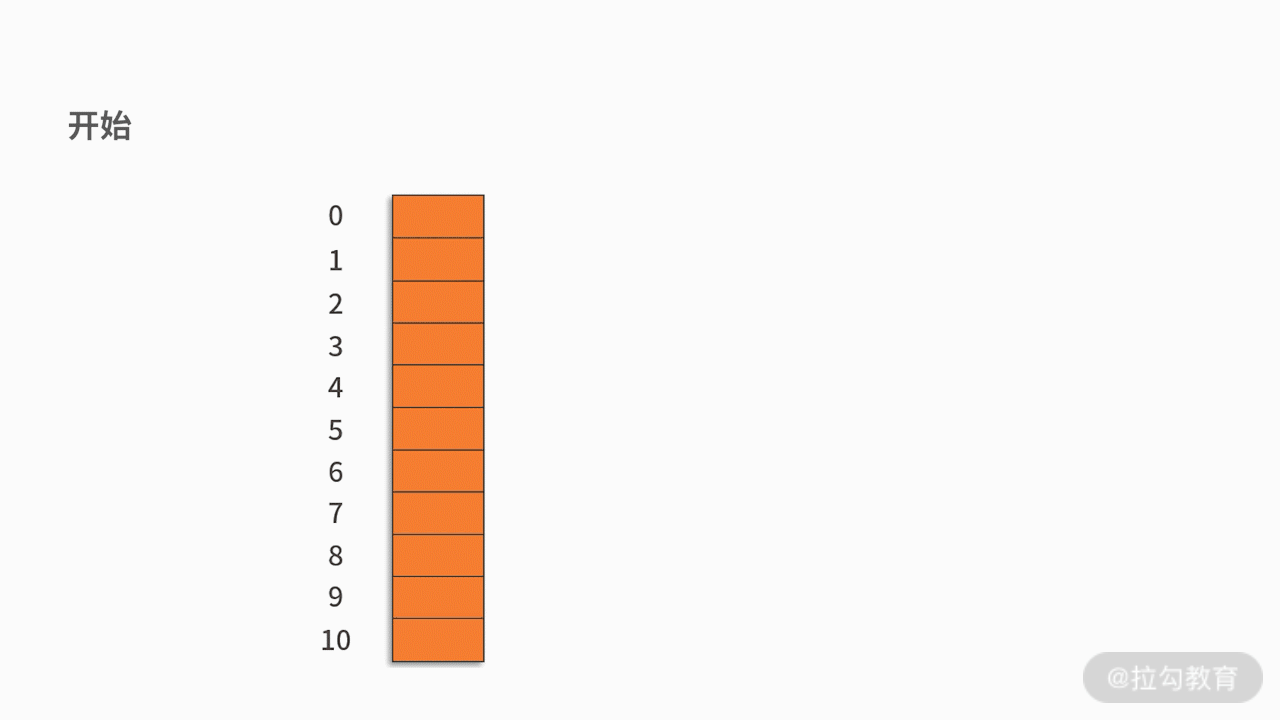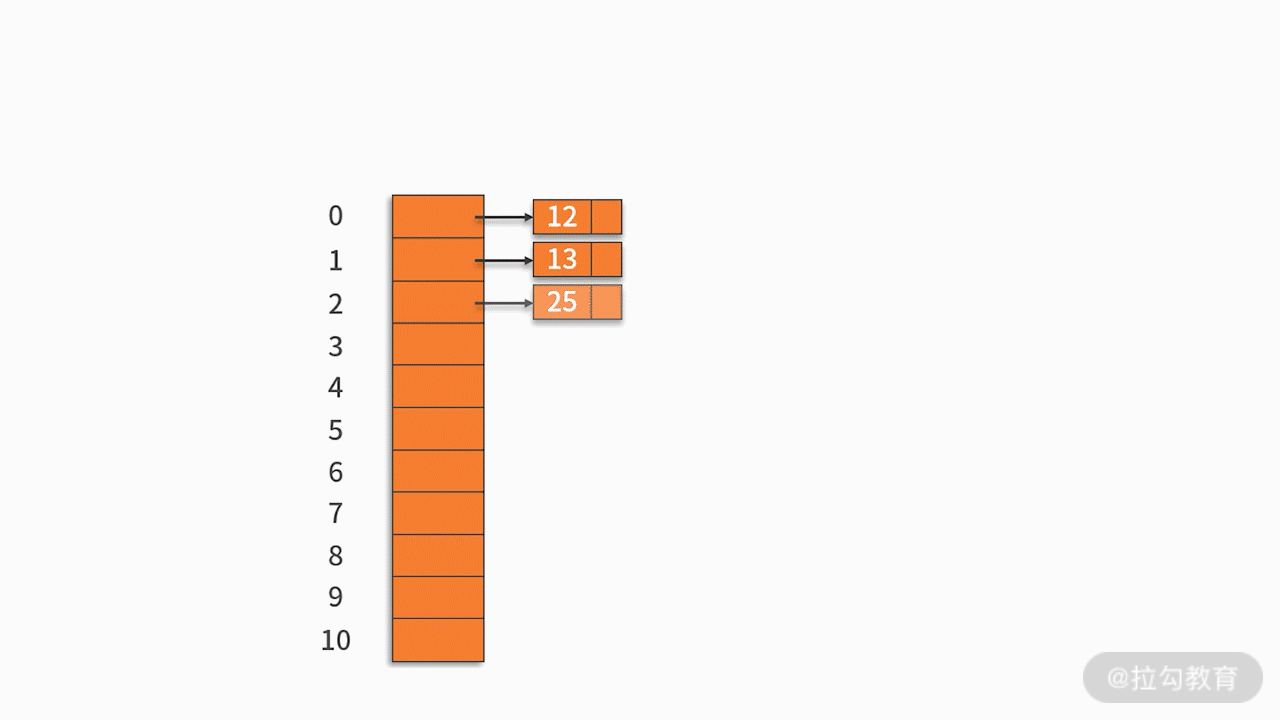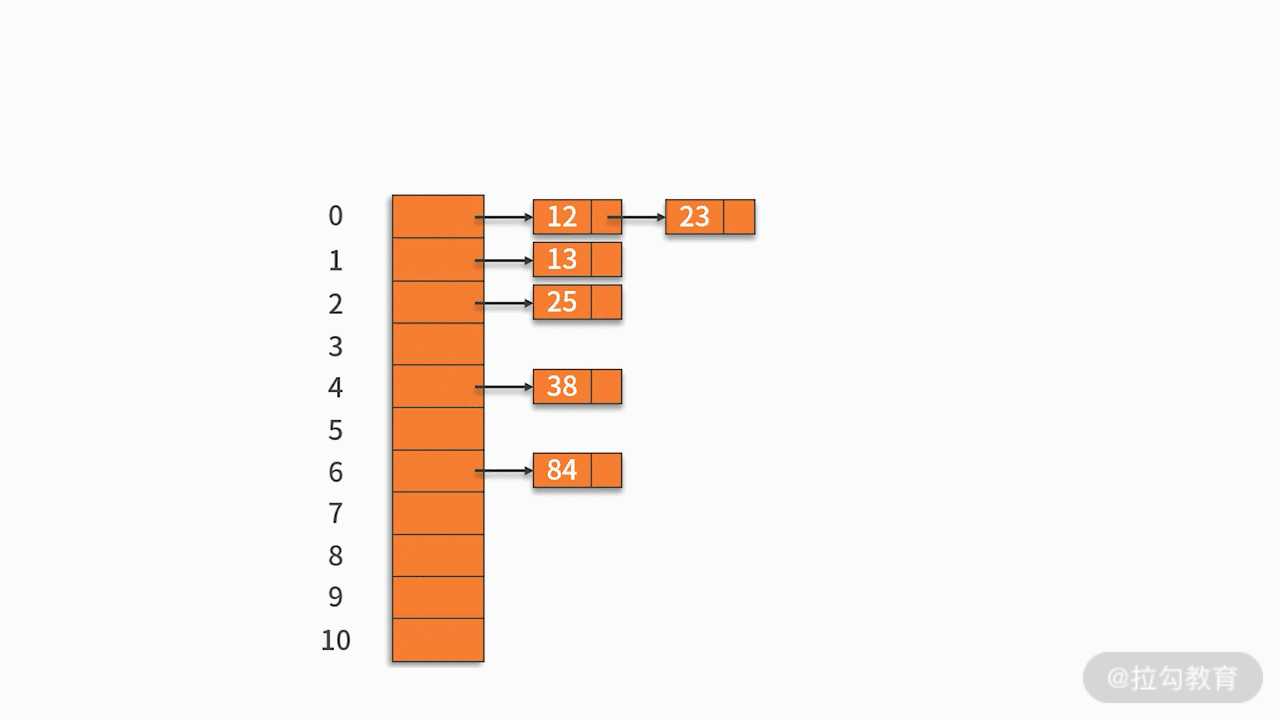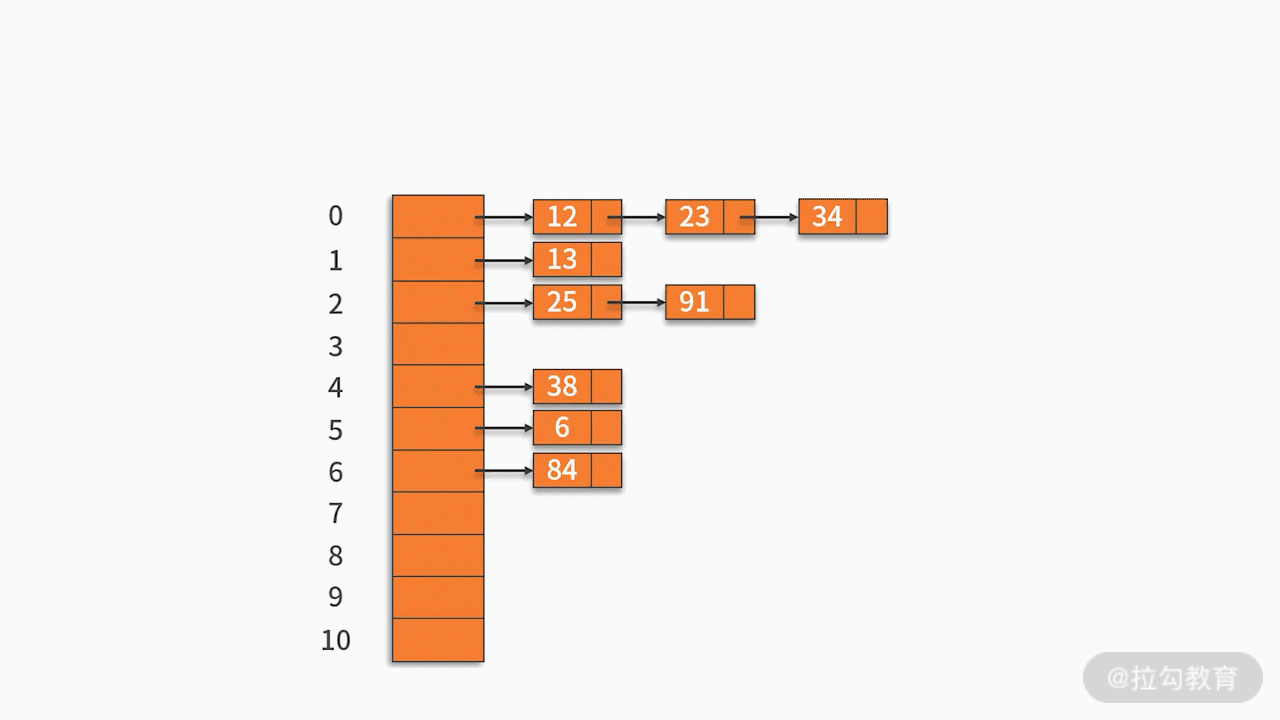
Tres, la aplicación de la tabla hash.
3.1 Operación básica de la tabla hash
En muchos lenguajes de alto nivel, las funciones hash y los conflictos hash se han incluido en una caja negra en la parte inferior, y los desarrolladores no necesitan diseñarlos ellos mismos. En otras palabras, la tabla hash completa la asignación de palabras clave a direcciones, y los datos se pueden encontrar a través de palabras clave dentro de un nivel constante de complejidad temporal.
En cuanto a los detalles de implementación, como qué función hash se usa, qué manejo de conflictos se usa e incluso la dirección hash de un determinado registro de datos, no es necesario que los desarrolladores presten atención. A continuación, desde el punto de vista del desarrollo real, echemos un vistazo a la adición, eliminación y verificación de datos mediante la tabla hash.
La operación de agregar y eliminar datos en la tabla hash no implica el problema de cambiar los datos después de agregarlos o eliminarlos (se deben considerar las matrices), por lo que el procesamiento está bien.
El proceso detallado de la búsqueda de la tabla hash es: para una clave determinada, la dirección hash H (clave) se calcula mediante una función hash.
- Si el valor correspondiente a la dirección hash está vacío, la búsqueda no se realiza correctamente.
- De lo contrario, la búsqueda se realiza correctamente.
Aunque el proceso detallado de búsqueda de tablas hash es aún más problemático, debido al procesamiento de caja negra de algunos lenguajes de alto nivel, los desarrolladores no necesitan desarrollar realmente el código subyacente, solo llamar a las funciones relevantes.
3.2 Ventajas y desventajas de las tablas hash
- Ventajas : Puede proporcionar operaciones muy rápidas de inserción-eliminación-búsqueda, sin importar cuántos datos, insertar y eliminar valores requieran un tiempo casi constante . En términos de búsqueda, la velocidad de la tabla hash es más rápida que la del árbol y el elemento deseado se puede encontrar en un instante.
- Desventaja : Los datos de la tabla hash no tienen un concepto de orden , por lo que los elementos no se pueden atravesar de forma fija (por ejemplo, de pequeños a grandes). Cuando el orden de procesamiento de datos es delicado, elegir una tabla hash no es una buena solución. Al mismo tiempo, las
claves de la tabla hash no se pueden repetir y la tabla hash no es una buena opción para datos con una repetibilidad muy alta.
Cuarto, diseña un mapa hash
4.1 Requisitos de diseño
Reclamación:
Diseñe un mapa hash sin utilizar ninguna biblioteca de tablas hash incorporada. Específicamente, el diseño debe incluir las siguientes funciones:
- put (clave, valor) : inserta el par de valores de (clave, valor) en el mapa hash. Si el valor correspondiente a la clave ya existe, actualice este valor.
- get (key) : Devuelve el valor correspondiente a la clave dada, si la clave no está incluida en el mapa, devuelve -1.
- eliminar (clave ): si la clave existe en el mapa, elimine el par de valores.
Ejemplo:
MyHashMap hashMap = new MyHashMap();
hashMap.put(1, 1);
hashMap.put(2, 2);
hashMap.get(1); // 返回 1
hashMap.get(3); // 返回 -1 (未找到)
hashMap.put(2, 1); // 更新已有的值
hashMap.get(2); // 返回 1
hashMap.remove(2); // 删除键为2的数据
hashMap.get(2); // 返回 -1 (未找到)
Nota:
所有的值都在 [0, 1000000]的范围内。
操作的总数目在[1, 10000]范围内。
不要使用内建的哈希库。
4.2 Ideas de diseño
La tabla hash es una estructura de datos común disponible en diferentes idiomas. Por ejemplo, dict en Python, map en C ++ y Hashmap en Java. La característica de la tabla hash es que se puede acceder rápidamente al valor de acuerdo con la clave dada.
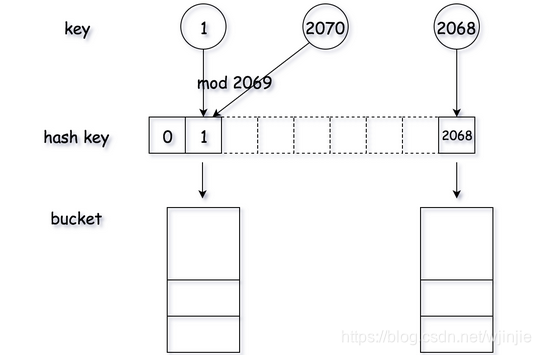
La idea más sencilla es utilizar la aritmética modular como método hash. Para reducir la probabilidad de colisiones hash, se suele utilizar el módulo de números primos, como el módulo 2069.
Defina la matriz como espacio de almacenamiento y calcule el subíndice de la matriz mediante el método hash. Para resolver la colisión de hash (es decir, el valor de la clave es diferente, pero el subíndice de mapeo es el mismo), se usa un depósito para almacenar todos los valores correspondientes. Los depósitos se pueden implementar como matrices o listas enlazadas. En las siguientes implementaciones específicas, las matrices se utilizan en Python.
Defina los métodos de la tabla hash, get (), put () y remove (). El proceso de direccionamiento es el siguiente:
- Para un valor de clave dado, use el método hash para generar el código hash del valor clave y use el código hash para ubicar el espacio de almacenamiento. Para cada código hash, se puede encontrar un depósito para almacenar el valor correspondiente al valor de la clave.
- Después de encontrar un depósito, compruebe si el par clave-valor ya existe atravesando .
4.3 Caso práctico
La implementación de Python es la siguiente:
class Bucket:
def __init__(self):
self.bucket = []
def get(self, key):
for (k, v) in self.bucket:
if k == key:
return v
return -1
def update(self, key, value):
found = False
for i, kv in enumerate(self.bucket):
if key == kv[0]:
self.bucket[i] = (key, value)
found = True
break
if not found:
self.bucket.append((key, value))
def remove(self, key):
for i, kv in enumerate(self.bucket):
if key == kv[0]:
del self.bucket[i]
class MyHashMap(object):
def __init__(self):
"""
Initialize your data structure here.
"""
# better to be a prime number, less collision
self.key_space = 2069
self.hash_table = [Bucket() for i in range(self.key_space)]
def put(self, key, value):
"""
value will always be non-negative.
:type key: int
:type value: int
:rtype: None
"""
hash_key = key % self.key_space
self.hash_table[hash_key].update(key, value)
def get(self, key):
"""
Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key
:type key: int
:rtype: int
"""
hash_key = key % self.key_space
return self.hash_table[hash_key].get(key)
def remove(self, key):
"""
Removes the mapping of the specified value key if this map contains a mapping for the key
:type key: int
:rtype: None
"""
hash_key = key % self.key_space
self.hash_table[hash_key].remove(key)
# Your MyHashMap object will be instantiated and called as such:
# obj = MyHashMap()
# obj.put(key,value)
# param_2 = obj.get(key)
# obj.remove(key)
Análisis de complejidad:
- Complejidad de tiempo: la complejidad de tiempo de cada método es O (N / K), donde N es el número de todos los valores clave posibles, K es el número de depósitos predefinidos en la tabla hash, donde K es 2069. Aquí asumimos que el valor de la clave se distribuye uniformemente en todos los depósitos y el tamaño medio del depósito es N / K. En el peor de los casos, es necesario atravesar un depósito completo, por lo que la complejidad del tiempo es O (N / K).
- Complejidad del espacio: O (K + M), donde K es el número de depósitos predefinidos en la tabla hash y M es el número de valores clave insertados en la tabla hash.
El intercambio de hoy ha terminado, ¡espero que sea útil para su estudio!
