prefacio
¿Cómo realizar el efecto de cambio de sonido de audio en tiempo real en la página web?Antes de encontrar este tipo de necesidades de procesamiento de audio y video, puede pensar que necesita usar código C para realizarlo. Pero ahora, con la mejora del rendimiento del navegador y la riqueza de las API web, los datos de audio se pueden manipular para lograr muchos efectos complejos a través de las API nativas del navegador, lo que brinda más opciones para el desarrollo de audio web. A continuación, se presentan varias soluciones que se han probado en el proceso de uso de la API de audio web nativa para lograr el efecto de cambio de sonido. Los estudiantes interesados aprenderán sobre esto juntos.
Nota: El alcance de este artículo es la velocidad variable y el esquema de cambio de tono en la escena de cambio de voz. Hay otros dos escenarios: velocidad variable sin cambiar el tono y estudiantes que necesitan cambiar el tono sin cambiar la velocidad, consulte el enlace o otras soluciones
Introducción a la API de audio web
Antes de comenzar, comprendamos brevemente la API de audio web La API de audio web proporciona un conjunto de API para operar audio en la web, lo que permite a los desarrolladores elegir fuentes de datos de audio, agregar efectos al audio, visualizar sonido y agregar efectos espaciales al sonido . . El flujo de entrada de audio se puede entender como un conjunto de búferes, y la fuente se puede generar leyendo archivos de audio en la memoria AudioBufferSourceNode, o desde la etiqueta de audio en HTML MediaElementAudioSourceNode, o desde un flujo de audio (como un micrófono) MediaStreamAudioSourceNode. Por ejemplo, para captar el sonido del micrófono de tu propio dispositivo y conectarlo al altavoz:
// 创建音频上下文
const audioContext = new AudioContext();
// 获取设备麦克风流
stream = await navigator.mediaDevices
.getUserMedia({ audio: true})
.catch(function (error) {
console.log(error);
});
// 创建来自麦克风的流的声音源
const sourceNode = audioContext.createMediaStreamSource(stream);
// 将声音连接的扬声器
sourceNode.connect(audioContext.destination);Puede hablar al micrófono y escuchar su propia voz. El procesamiento de los flujos de datos de origen mencionados anteriormente está diseñado como nodos (Nodos) uno por uno, que tiene las características de enrutamiento modular. Qué tipo de efecto debe agregarse y qué tipo de nodos se agregan. Por ejemplo, uno de la operación más común es pasar los datos de muestreo de entrada Amplificar para lograr el efecto de un altavoz ( GainNode), código de muestra:
// 创建音频上下文
const audioContext = new AudioContext();
// 创建一个增益Node
const gainNode = audioCtx.createGain();
// 获取设备麦克风流
stream = await navigator.mediaDevices
.getUserMedia({ audio: true})
.catch(function (error) {
console.log(error);
});
// 创建来自麦克风的流的声音源
const sourceNode = audioContext.createMediaStreamSource(stream);
// 将声音经过gainNode处理
sourceNode.connect(gainNode);
// 将声音连接的扬声器
gainNode.connect(audioContext.destination);
// 设置声音增益,放大声音
gainNode.gain.value = 2.0;Lo anterior solo está conectado al nodo para amplificación de sonido. Si desea agregar otros efectos, puede continuar agregando nodos para conectar, como filtro (), control estéreo (), distorsión de señal ( BiquadFilterNode) StereoPannerNode, WaveShaperNodeetc. Este diseño modular proporciona una forma flexible de crear efectos dinámicos y audio compuesto. Se siente mágico, donde modificar (agregar Nodo) es muy conveniente. Por ejemplo, a continuación se muestra AudioContextun Biquad filter nodeejemplo de creación de un nodo de filtro de cuatro términos ( ):
var audioCtx = new (window.AudioContext || window.webkitAudioContext)();
// 创建多个不同作用功能的node节点
var analyser = audioCtx.createAnalyser();
var distortion = audioCtx.createWaveShaper();
var gainNode = audioCtx.createGain();
var biquadFilter = audioCtx.createBiquadFilter();
var convolver = audioCtx.createConvolver();
// 将所有节点连接在一起
source = audioCtx.createMediaStreamSource(stream);
source.connect(analyser);
analyser.connect(distortion);
distortion.connect(biquadFilter);
biquadFilter.connect(convolver);
convolver.connect(gainNode);
gainNode.connect(audioCtx.destination);
// 控制双二阶滤波器
biquadFilter.type = "lowshelf";
biquadFilter.frequency.value = 1000;
biquadFilter.gain.value = 25;Se puede ver que agregar efectos de procesamiento al flujo de sonido es como usar un collar, uno por uno, y finalmente obtener el efecto final. Para el efecto, puede consultar la muestra oficial de voice-change-o-matic. Un proceso de audio web simple y típico es el siguiente:
Crear un contexto de audio
Cree fuentes en un contexto de audio, por ejemplo, osciladores, flujos
Crea nodos de efectos como reverb, biquad, pan, compresor
Elija un destino para el audio, como los altavoces de su sistema
Conecte la fuente a la unidad de efectos y la salida de efectos al destino

Realización del efecto de cambio de voz.
Primero, repase los conceptos básicos del sonido. El sonido es una onda mecánica generada por la vibración de un objeto. A menudo está expuesto a las siguientes tres características:
Frecuencia : Cuanto más alta es la frecuencia, más alto es el tono; cuanto más baja es la frecuencia, más bajo es el tono.
Amplitud : cuanto mayor sea la amplitud, mayor será el volumen (sonoridad); cuanto menor sea la amplitud, menor será el volumen.
Timbre : es decir, la forma de onda, la base principal para distinguir a las personas al escuchar
El efecto de cambio de voz mencionado aquí es cambiar el tono de la voz. De acuerdo con las diferentes escenas, el efecto de cambio de voz se puede dividir en tres tipos: cambiar la velocidad sin cambiar el tono, cambiar el tono sin cambiar la velocidad y cambiar el tono y cambiar velocidad. La velocidad variable se refiere a alargar o acortar una voz en el dominio del tiempo, mientras que la frecuencia de muestreo, la frecuencia fundamental y el formante del sonido no cambian. La transposición de tono se refiere a bajar o subir la frecuencia del gen de la voz, el formante cambia en consecuencia y la frecuencia de muestreo permanece sin cambios. Los escenarios de aplicación de varias soluciones son los siguientes:
Velocidad variable y sin ajuste: la velocidad de reproducción de 2x y 0,5x en varios reproductores de video es el principio de velocidad variable de voz y no se aplica ajuste, por supuesto, la velocidad variable y sin ajuste también se aplica a la fluctuación de la red en VOIP. es Cuando la red es mala, el reproductor extrae menos datos de la red y los datos en el área de caché no son suficientes, por lo que los datos almacenados en caché se usan para jugar más lento. Por el contrario, si hay demasiados datos en el área del búfer, la reproducción será más rápida. La implementación de esta parte puede referirse al módulo netEQ de webrtc. Por lo general, cuando usa la voz de WeChat, debe sentir que la red está particularmente atascada. Para mantener la voz continua, la voz se ralentizará deliberadamente.
Cambio de tono y cambio de velocidad: se utiliza principalmente en efectos de sonido. Eleve el tono de la voz para convertir una voz masculina en una voz femenina, o convertir una voz femenina en una voz masculina; además, la velocidad constante de cambio de tono se combina con Se pueden realizar otros algoritmos de efectos de sonido, como EQ, reverberación, trémolo y vibrato. Se pueden realizar efectos de cambio de voz, como la voz loli y la voz del tío en QQ.
Velocidad variable y cambio de tono: cuando se cambia la velocidad de reproducción del sonido, el tono y el timbre también cambiarán en consecuencia. Por ejemplo, cualquier persona que haya reproducido cintas sabe que presionar la función de avance rápido hará que el sonido sea más nítido y elevará el tono, y el La función de reproducción lenta hará que el sonido sea más grueso y el tono más bajo.
Las primeras dos implementaciones requieren una comprensión más profunda del campo del conocimiento del sonido. El dominio del tiempo, el dominio de la frecuencia y los cambios de transformada de Fourier de la señal deben revisarse nuevamente. El costo de aprendizaje es relativamente alto. El tercer método se usa aquí. Buen acceso . Para cambiar la velocidad de reproducción del sonido, se proporcionan propiedades en la API de audio web , que puede establecer la velocidad de reproducción del audio y usar el contexto de audio para obtener una instancia. El código de muestra es el siguiente:AudioBufferSourceNodeplaybackRateAudioContext.createBufferSource
const play = ()=> {
const audioSrc = ref("src/assets/sample_orig.mp3")
const url = audioSrc.value
const request = new XMLHttpRequest()
request.open('GET', url, true)
request.responseType = 'arraybuffer'
request.onload = function() {
const audioData = request.response
const audioCtx = new (window.AudioContext || window.webkitAudioContext)();
audioCtx.decodeAudioData(audioData, (audioBuffer) => {
let source = audioCtx.createBufferSource();
source.buffer = audioBuffer;
// 改变声音播放速率,2倍播放
source.playbackRate.value = 2;
source.connect(audioCtx.destination);
source.start(0);
});
}
request.send()
}Puede ajustar source.playbackRate.valueel valor para cambiar el tono, más de 1 aumenta el tono y menos de 1 lo disminuye.
Aunque se logra el efecto de cambio de sonido, este método solo es adecuado para reproducir archivos de audio u obtener secuencias de audio completas. No es adecuado para obtener secuencias de sonido de entrada continuas, como micrófonos. Similar es SoundTouchJS, que es una gran versión de JS implementada por el chico SoundTouchtambién se usa para obtener el flujo de datos del audio completo. El autor también explicó en consecuencia.  Cómo lidiar con el flujo de audio en tiempo real obtenido por el micrófono en el enlace de referencia. Aquí puede usar la API de audio web
Cómo lidiar con el flujo de audio en tiempo real obtenido por el micrófono en el enlace de referencia. Aquí puede usar la API de audio webScriptProcessorNode , que permite el uso de JavaScript Generar, procesar y analizar audio. El diagrama de flujo de procesamiento es el siguiente: 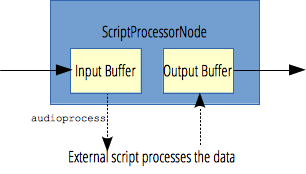 Utilícelo para procesar los datos del flujo de audio en tiempo real para obtener datos del flujo de audio acelerado o en cámara lenta. El código de ejemplo es el siguiente:
Utilícelo para procesar los datos del flujo de audio en tiempo real para obtener datos del flujo de audio acelerado o en cámara lenta. El código de ejemplo es el siguiente:
const audioprocess = async () => {
const audioContext = new AudioContext();
// 采集麦克风输入声音流
let stream = await navigator.mediaDevices
.getUserMedia({ audio: true})
.catch(function (error) {
console.log(error);
});
const sourceNode = audioContext.createMediaStreamSource(stream);
const processor = audioContext.createScriptProcessor(4096, 1, 1);
processor.onaudioprocess = async event => {
// 处理回调中拿到输入声音数据
const inputBuffer = event.inputBuffer;
// 创建新的输出源
const outputSource = audioContext.createMediaStreamDestination();
const audioBuffer = audioContext.createBufferSource();
audioBuffer.buffer = inputBuffer;
// 设置声音加粗,慢放0.7倍
audioBuffer.playbackRate.value = 0.7
audioBuffer.connect(outputSource);
audioBuffer.start();
// 返回新的 MediaStream
const newStream = outputSource.stream;
const node = audioContext.createMediaStreamSource(newStream)
// 连接到扬声器播放
node.connect(audioContext.destination)
};
// 添加处理节点
sourceNode.connect(processor);
processor.connect(audioContext.destination)
}Además, hay una biblioteca de cambio de tono implementada mediante el uso de la jungla de código abierto de Google, y hay varios efectos de reverberación, visualización de audio y otras funciones interesantes, que también se implementan mediante la API de audio web. La dirección del enlace de github se coloca aquí , si te interesa también puedes experimentarlo, la pantalla se ve así
Resumir
Lo anterior es una breve introducción y análisis del uso de Web Audio API , y varias implementaciones del uso de Web Audio API para lograr efectos de cambio de voz simples. Si tiene mejores soluciones de implementación, ¡bienvenido a comunicarse en el área de comentarios!
referencia
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
https://github.com/cwilso/Audio-Input-Effects
https://mdn.github.io/voice-change-o-matic/
https://github.com/cutterbl/SoundTouchJS
https://cloud.tencent.com/developer/news/818606
https://zhuanlan.zhihu.com/p/110278983
https://www.nxrte.com/jishu/3146.html
- FIN -
Acerca de Qi Wu Troupe
Qi Wu Troupe es el equipo front-end más grande de 360 Group y participa en el trabajo de los miembros de W3C y ECMA (TC39) en nombre del grupo. Qi Wu Troupe otorga gran importancia a la capacitación de talentos y tiene varias direcciones de desarrollo, como ingenieros, profesores, traductores, personas de interfaz comercial y líderes de equipo para que los empleados elijan, y brinda el curso de capacitación técnica, profesional, general y de liderazgo correspondiente. Qi Dance Troupe da la bienvenida a todo tipo de talentos destacados para que presten atención y se unan a Qi Dance Troupe con una actitud abierta y de búsqueda de talentos.
