La primera parte de la capacitación se presentó anteriormente, que también es un artículo que la mayoría de la gente puede encontrar en Internet, pero las últimas dos partes deben ser información que no está disponible en Internet. Espero que les guste.
0. datos
Mis datos son algunos palés, principalmente para detectar los agujeros en los palés, e identificar la posición y el ángulo de deflexión de los agujeros. La imagen original es la siguiente

Mi anotación

Utilizo labelme para anotar y luego convertir al formato yolo, el código de conversión es el siguiente.
# coding=utf-8
import os
import sys
path = os.path.dirname(__file__)
sys.path.append(path)
'''
Author:Don
date:2022/8/3 11:49
desc:
'''
import os
import json
import glob
#输入口,就是你图片和json存放的那个文件,输出的txt也在这个文件夹里
labelme_dir=r"E:\2022\work\shchaiduo\image"
def get_labelme_data(labelme_dir):
with open(labelme_dir) as f:
j=json.load(f)
out_data=[]
img_h =j["imageHeight"]
img_w =j["imageWidth"]
for shape in j["shapes"]:
label=shape["label"]
points=shape["points"]
x,y,x2,y2=points[0][0],points[0][1],points[1][0],points[1][1]
x_c=(x+x2)//2
y_c=(y+y2)//2
w=abs(x-x2)
h=abs(y-y2)
out_data.append([label,x_c,y_c,w,h])
return img_h,img_w,out_data
def rename_Suffix(in_,mode=".txt"):
in_=in_.split('.')
return in_[0]+mode
def make_yolo_data(in_dir):
json_list=glob.glob(os.path.join(in_dir,'*.json'))
for json_ in json_list:
json_path=os.path.join(in_dir,json_)
json_txt=rename_Suffix(json_)
img_h,img_w,labelme_datas=get_labelme_data(json_path)
with open(os.path.join(in_dir,json_txt),'w+') as f:
for labelme_data in labelme_datas:
label=labelme_data[0]
x_c=labelme_data[1]/img_w
y_c=labelme_data[2]/img_h
w=labelme_data[3]/img_w
h=labelme_data[4]/img_h
f.write("{} {} {} {} {}\n".format(label,x_c,y_c,w,h))
f.close()
if __name__ == '__main__':
make_yolo_data(labelme_dir)
las imágenes son imágenes
etiquetas es el formato txt de la etiqueta,
concretamente la siguiente figura, 0 es el identificador de la etiqueta, porque solo hay una clase, entonces la primera en mis datos es 0, y la segunda es la xywh correspondiente al agujero, pero debe ser dividido por el largo y el ancho de la imagen, específicamente Ver el código de conversión de etiquetas arriba. Debido a que solo hay 2 agujeros en una paleta, mi txt solo tiene 2 conjuntos de datos.

la prueba es una imagen

1. Preparación de datos antes del entrenamiento
Debido a que mis datos se recopilan en el sitio, no se necesitan muchas técnicas de mejora de datos (comprensión personal). En la industria, lo más importante es la seguridad más que la precisión. Significa que si es correcto, es 100%, y si es incorrecto, es 0%, lo mejor es que no haya detección falsa, y la detección perdida es aceptable. Por lo tanto, el modelo no sugiere una mejor capacidad de generalización. Es mejor llamar directamente a la policía por cosas que no se han visto, en lugar de dar un rango de detección aproximado. Así que solo usé la API de aLbumentations en v8 y eliminé todo lo demás. El tamaño de lote predeterminado = 1.

from pathlib import Path
import glob
import os
from torch.utils.data import Dataset
from tqdm import tqdm
from multiprocessing.pool import ThreadPool
from PIL import Image, ImageOps
import random
import albumentations as A
import numpy as np
import torch
NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
IMG_FORMATS = "bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm" # include image suffixes
class Albumentations:
# YOLOv8 Albumentations class (optional, only used if package is installed)
def __init__(self, p=1.0):
self.p = p
T = [
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0), ] # transforms
self.transform = A.Compose(T, bbox_params=A.BboxParams(format="yolo", label_fields=["class_labels"]))
def __call__(self, labels):
im = labels["img"]
cls = labels["cls"]
if len(cls):
if self.transform and random.random() < self.p:
new = self.transform(image=im, bboxes=labels["bboxes"], class_labels=cls) # transformed
labels["img"] = self._format_img(new["image"])
labels["cls"] = torch.tensor(new["class_labels"])
labels["bboxes"] = torch.tensor(new["bboxes"])
labels["batch_idx"] = torch.zeros(labels["cls"].shape[0])
return labels
def _format_img(self, img):
if len(img.shape) < 3:
img = np.expand_dims(img, -1)
img = np.ascontiguousarray(img.transpose(2, 0, 1)[::-1]).astype(np.float32)
img = torch.from_numpy(img)
return img
# 读取数据集存储
def verify_image_label(args):
im_file, lb_file = args
try:
im = Image.open(im_file)
im.verify() # PIL verify
shape = im.size # image size
shape = (shape[1], shape[0]) # hw
if im.format.lower() in ("jpg", "jpeg"):
with open(im_file, "rb") as f:
f.seek(-2, 2)
if f.read() != b"\xff\xd9": # corrupt JPEG
ImageOps.exif_transpose(Image.open(im_file)).save(im_file, "JPEG", subsampling=0, quality=100)
# verify labels
if os.path.isfile(lb_file):
with open(lb_file) as f:
lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
lb = np.array(lb, dtype=np.float32)
nl = len(lb)
if nl:
_, i = np.unique(lb, axis=0, return_index=True)
if len(i) < nl: # duplicate row check
lb = lb[i] # remove duplicates
else:
lb = np.zeros((0, 5), dtype=np.float32)
else:
lb = np.zeros((0, 5), dtype=np.float32)
lb = lb[:, :5]
return im_file, lb, shape
except Exception as e:
return [None, None, None]
class YOLODataset(Dataset):
def __init__(self, img_path, imgsz=640, augment=True):
super(YOLODataset, self).__init__()
self.img_path = img_path
self.imgsz = imgsz
self.augment = augment
self.im_files = self.get_img_files(self.img_path) # 读取图片
self.labels = self.get_labels() # 读取label
self.ni = len(self.labels)
# transforms
self.transforms = Albumentations(p=1.0)
def get_img_files(self, img_path):
"""Read image files."""
try:
f = [] # image files
for p in img_path if isinstance(img_path, list) else [img_path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / "**" / "*.*"), recursive=True)
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace("./", parent) if x.startswith("./") else x for x in t] # local to global path
im_files = sorted(x.replace("/", os.sep) for x in f if x.split(".")[-1].lower() in IMG_FORMATS)
except Exception as e:
raise FileNotFoundError(f"Error loading data from") from e
return im_files
def img2label_paths(self, img_paths):
# Define label paths as a function of image paths
sa, sb = f"{
os.sep}images{
os.sep}", f"{
os.sep}labels{
os.sep}" # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit(".", 1)[0] + ".txt" for x in img_paths]
def get_labels(self):
self.label_files = self.img2label_paths(self.im_files)
cache_path = Path(self.label_files[0]).parent.with_suffix(".cache")
try:
cache, exists = np.load(str(cache_path), allow_pickle=True).item(), True # load dict
except (FileNotFoundError, AssertionError, AttributeError):
cache, exists = self.cache_labels(cache_path), False # run cache ops
return cache["labels"]
def cache_labels(self, path=Path("./labels.cache")):
# Cache dataset labels, check images and read shapes
if path.exists():
path.unlink() # remove *.cache file if exists
x = {
"labels": []}
desc = f"Scanning {
path.parent / path.stem}..."
total = len(self.im_files)
with ThreadPool(NUM_THREADS) as pool:
results = pool.imap(func=verify_image_label,
iterable=zip(self.im_files, self.label_files)) # im_file, lb, shape
pbar = tqdm(results, desc=desc, total=total, bar_format=TQDM_BAR_FORMAT)
for im_file, lb, shape, in pbar:
if im_file:
x["labels"].append(
dict(
im_file=im_file,
shape=shape,
cls=lb[:, 0:1], # n, 1
bboxes=lb[:, 1:], # n, 4
segments=None,
keypoints=None,
normalized=True,
bbox_format="xywh"))
pbar.close()
np.save(str(path), x) # save cache for next time
return x
2. Toma datos durante el entrenamiento
Para obtener datos, es necesario implementar las funciones len y getitem, porque se utiliza el conjunto de datos de torch. Como queremos reescribir el índice, reescribimos la función collate_fn

def __len__(self):
return len(self.labels)
def __getitem__(self, index):
return self.transforms(self.get_label_info(index))
def get_label_info(self, index):
label = self.labels[index].copy()
label["img"], label["ori_shape"], label["resized_shape"] = self.load_image(index)
return label
def load_image(self, i):
# Loads 1 image from dataset index 'i', returns (im, resized hw)
f = self.im_files[i]
im = cv2.imread(f) # BGR
if im is None:
raise FileNotFoundError(f"Image Not Found {
f}")
h0, w0 = im.shape[:2] # orig hw
r = self.imgsz / max(h0, w0) # ratio
if r != 1: # if sizes are not equal
interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
im = cv2.resize(im, (640, 512), interpolation=interp)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
@staticmethod
def collate_fn(batch):
new_batch = {
}
keys = batch[0].keys()
values = list(zip(*[list(b.values()) for b in batch]))
for i, k in enumerate(keys):
value = values[i]
if k == "img":
value = torch.stack(value, 0)
if k in ["bboxes", "cls"]:
value = torch.cat(value, 0)
new_batch[k] = value
new_batch["batch_idx"] = list(new_batch["batch_idx"])
for i in range(len(new_batch["batch_idx"])):
new_batch["batch_idx"][i] += i # add target image index for build_targets()
new_batch["batch_idx"] = torch.cat(new_batch["batch_idx"], 0)
return new_batch
3. Integra datos
def seed_worker(worker_id):
# Set dataloader worker seed https://pytorch.org/docs/stable/notes/randomness.html#dataloader
worker_seed = torch.initial_seed() % 2 ** 32
np.random.seed(worker_seed)
random.seed(worker_seed)
TQDM_BAR_FORMAT = '{l_bar}{bar:10}{r_bar}' # tqdm bar format
img_path = "../datasets/kongdong/images"
dataset = YOLODataset(img_path=img_path, imgsz=640, augment=True)
RANK = int(os.getenv('RANK', -1))
PIN_MEMORY = str(os.getenv("PIN_MEMORY", True)).lower() == "true"
generator = torch.Generator()
generator.manual_seed(6148914691236517205 + RANK)
train_loader = DataLoader(dataset=dataset, batch_size=1, shuffle=True,
pin_memory=PIN_MEMORY,
collate_fn=getattr(dataset, "collate_fn", None),
worker_init_fn=seed_worker,
generator=generator)
pbar = tqdm(enumerate(train_loader), total=1, bar_format=TQDM_BAR_FORMAT)
for i, batch in pbar:
Tomamos el conjunto de datos en un bucle for, entonces, ¿qué hay en el lote? vamos a ver
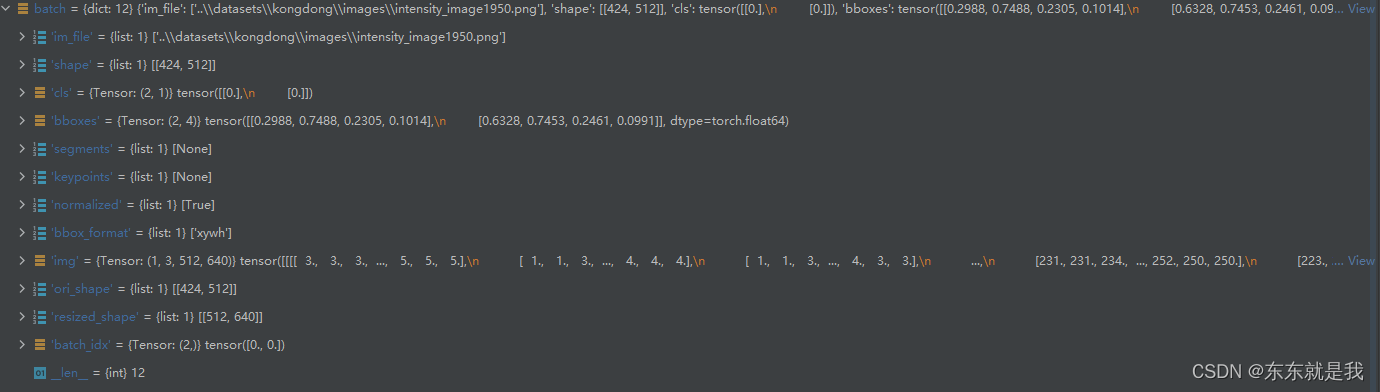
Ahora vamos a comprobar si los datos son correctos después de la transformación.
# 检测输入的数据图像对不对
def check_data(batch):
img = batch["img"]
labels = batch['bboxes'] # xywh
labels[:, 0] *= 640
labels[:, 1] *= 512
labels[:, 2] *= 640
labels[:, 3] *= 512
input_tensor = img.squeeze()
# 从[0,1]转化为[0,255],再从CHW转为HWC,最后转为cv2
input_tensor = input_tensor.permute(1, 2, 0).type(torch.uint8).numpy()
# RGB转BRG
input_tensor = cv2.cvtColor(input_tensor, cv2.COLOR_RGB2BGR)
for box in labels.int(): # xywh
cv2.rectangle(input_tensor, (int(box[0] - box[2] / 2), int(box[1] - box[3] / 2)),
(int(box[0] + box[2] / 2), int(box[1] + box[3] / 2)), (255, 0, 255), -1)
cv2.imshow('img', input_tensor)
cv2.waitKey(0)
for i, batch in pbar:
# Forward
with torch.cuda.amp.autocast(False):
check_data(batch)
img = batch["img"]
preds = model(img)
ok, así es,

veamos si la salida del modelo es correcta
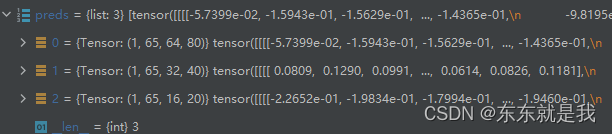
y tiene el mismo tamaño que la salida de la red de inferencia directa en nuestro primer artículo.