YOLOV1:Solo miras una vez:Detección unificada de objetos en tiempo real
- introducción
- 1. Introducción
- 2 Marco unificado de detección de objetos
- 3 Comparación con otros sistemas de detección
- 4 experimentos
-
- 4.1 Comparación de rendimiento entre YOLO y otros métodos de detección de objetivos en tiempo real
- 4.2 Análisis de errores de YOLO y Fast R-CNN en el conjunto de datos VOC 2007
- 4.3 Fast R-CNN y YOLO se complementan
- 4.4 Resultados en el conjunto de datos VOC 2012
- 4.5 Generalización: Detección de personas en obras de arte
- 5 detectores en tiempo real en la realidad
- 6. Conclusión
- referencias
introducción
Para una lectura intensiva del documento, puede ver el video del jefe en la estación B: [Lectura intensiva de documentos de IA] Detección de objetivos YOLO V1, solo mirarme es suficiente

Propusimos YOLO, un nuevo método de detección de objetivos. El trabajo previo sobre la detección de objetos realiza la detección mediante la reutilización de clasificadores. En su lugar, definimos la detección de objetos como un problema de regresión en el que la localización de los cuadros delimitadores y las probabilidades de clase asociadas se separan espacialmente. Una sola red neuronal predice cuadros delimitadores y probabilidades de clasificación directamente a partir de la entrada de imagen completa con una inferencia de paso hacia adelante. Todo el flujo de trabajo de detección se consolida en una sola red, lo que permite la optimización de extremo a extremo directamente en el rendimiento de detección.

Nuestro marco unificado es increíblemente rápido. Nuestro modelo de referencia YOLO puede procesar imágenes a una velocidad en tiempo real de 45 fotogramas por segundo. La versión pequeña de la red, Fast YOLO, puede procesar a una asombrosa velocidad de 155 fotogramas por segundo y aún puede alcanzar el doble de mAP que otros detectores en tiempo real. En comparación con el sistema de detección óptimo actual, aunque el error de posicionamiento de YOLO es relativamente grande, el error de predecir el fondo como caso de falso positivo es menor. Finalmente, YOLO puede aprender características de apariencia de objetos más generales (un modelo general de detección de objetivos). Al generalizar desde la transferencia de imágenes naturales a otros campos, como las obras de arte, el rendimiento de YOLO supera a los métodos de detección como DPM y R-CNN.
1. Introducción

Los humanos pueden decir de un vistazo qué objetos están en una imagen, dónde están y cómo interactúan. El sistema visual humano es lo suficientemente rápido y preciso para realizar tareas complejas como conducir con un período de atención mínimo. Los algoritmos de detección de objetos rápidos y precisos permiten que las computadoras conduzcan automóviles sin sensores especiales, permiten que los dispositivos auxiliares comuniquen información de la escena en tiempo real a los usuarios y desbloquean aplicaciones potenciales y sistemas robóticos de respuesta en tiempo real.

La detección actual recuerda que la detección se realiza reutilizando el clasificador. Estos sistemas emplean un clasificador para realizar la detección de objetos y evaluar sus diferentes ubicaciones y escalas en imágenes de prueba. El modelo de pieza deformable (DPM) utiliza un enfoque de ventana deslizante en el que un clasificador se desliza uniformemente sobre toda la imagen.

Recientemente, se utilizan cada vez más métodos, como R-CNN, para extraer regiones candidatas, primero generar cuadros de candidatos potenciales en la imagen y luego realizar clasificadores en estos cuadros de candidatos. Después de la clasificación y el posprocesamiento, ajuste el cuadro delimitador del objetivo, elimine los resultados de detección duplicados y puntúe otros cuadros de objetivo en la imagen. Estos flujos de trabajo complejos son lentos y difíciles de optimizar porque los pasos independientes deben entrenarse por separado.

Reformulamos la detección de objetos como un problema de regresión simple, mapeando directamente desde el espacio de píxeles de una imagen de entrada hasta las coordenadas del cuadro delimitador y las probabilidades de clase (resultados de detección). Usando nuestro sistema, es posible predecir qué objetos están presentes y dónde están ubicados, simplemente mirando una imagen.

YOLO es extremadamente simple, como se muestra en la Figura 1. Una sola red neuronal convolucional predice simultáneamente múltiples cuadros delimitadores y sus probabilidades de clase. YOLO se entrena en función de imágenes de fotograma completo, que pueden optimizar directamente el rendimiento de detección. Este modelo unificado tiene muchos beneficios sobre los algoritmos tradicionales de detección de objetos.

Primero, YOLO es extremadamente rápido. Replanteamos la detección como un problema de regresión, por lo que no se requiere un flujo de trabajo complejo. Para las pruebas, simplemente ejecutamos la red neuronal para predecir detecciones en nuevas imágenes. Nuestra red básica se ejecuta a 45 fotogramas por segundo sin procesamiento por lotes en una GPU Titan X, mientras que la versión rápida supera los 150 fotogramas por segundo. Esto significa que podemos procesar transmisiones de video en tiempo real con una latencia inferior a 25 milisegundos. Además, el mAP de YOLO es más del doble que el de otros sistemas en tiempo real. Puede encontrar un ejemplo en vivo de nuestro sistema ejecutándose en una cámara web en la página web de nuestro proyecto.

En segundo lugar, YOLO analiza la imagen globalmente cuando realiza predicciones. A diferencia de los métodos basados en propuestas y ventanas deslizantes, YOLO explora la imagen completa durante el entrenamiento y las pruebas, por lo que codifica implícitamente información contextual sobre las categorías y sus características aparentes. Fast R-CNN, un método de detección de última generación, confundió el fondo de la imagen con un objeto porque no podía ver la información de textura más grande. En comparación con Fsat R-CNN, YOLO genera menos de la mitad de este error de fondo.

En tercer lugar, YOLO puede aprender una representación de características más generales del objetivo. Cuando se entrena con imágenes naturales y se prueba con obras de arte, YOLO supera con creces a los mejores algoritmos de detección como DPM y R-CNN. Dado que YOLO es muy generalizable, es poco probable que se produzca una pérdida de rendimiento cuando se aplica a nuevos dominios o imágenes de entrada que no se ajustan a la distribución del conjunto de entrenamiento.

YOLO todavía va a la zaga de los sistemas de detección avanzados en términos de precisión de detección. Si bien puede identificar rápidamente objetos en imágenes, tiene dificultades para ubicar con precisión algunos objetos, especialmente los pequeños. Investigamos más a fondo estas compensaciones en nuestros experimentos.
Todo nuestro código de entrenamiento y prueba es de código abierto. Varios modelos preentrenados están disponibles para descargar.

Figura 1: Sistema de detección YOLO. Procesar imágenes con YOLO es simple y directo. Nuestro sistema (1) escala la imagen de entrada a 448*448, (2) ejecuta una única red neuronal convolucional en la imagen y (3) establece un umbral para los resultados de detección en función de la confianza del modelo.
2 Marco unificado de detección de objetos

Integramos los componentes independientes de la detección de objetos en una única red neuronal. Nuestra red utiliza funciones de imagen completa para predecir cada cuadro delimitador. También predice todos los cuadros delimitadores para todas las clases de una imagen simultáneamente. Esto significa que nuestra red hace inferencias globales sobre la imagen completa y todos los objetos de la imagen. YOLO está diseñado para permitir el entrenamiento de extremo a extremo y la velocidad en tiempo real mientras mantiene una alta precisión promedio (AP).
Nuestro sistema divide la imagen de entrada en una cuadrícula de SxS. Si el centro del objeto cae en una cuadrícula, entonces esa cuadrícula es responsable de predecir el objeto.

Cada cuadrícula predice B cuadros delimitadores y la confianza de estos cuadros delimitadores. Estas puntuaciones de confianza reflejan la confianza que tiene el modelo en que la caja contiene el objeto y la precisión con la que se predice la caja. Formalmente, definimos la confianza como P r (Objeto) ∗ IOU predtruth P_r(Object)*IOU^{truth}_{pred}PAGr( Objeto ) _ _ _∗YO TU _antes de _ _la verdad _ _ _. Si no hay ningún objetivo en la celda, la confianza se pone a cero. De lo contrario, definimos la confianza como la relación de intersección sobre unión del cuadro predicho al cuadro de verdad fundamental.
Cada cuadro delimitador contiene 5 predicciones: x , y , w , hx,y,w,hx ,y ,w ,h y confianza. (x, y) (x, y)( X ,y ) representa las coordenadas del centro del cuadro delimitador en relación con los bordes de la cuadrícula. El ancho y la altura se predicen en relación con la imagen completa. Finalmente, la predicción de confianza representa la relación de intersección sobre unión (IOU) del cuadro predicho con el cuadro de verdad fundamental.

Cada celda también predice la probabilidad de clase condicional de C, P r ( Classi ∣ O bject ) Pr(Class_i|Object)P r ( Clase _ _ _yo∣ O bj e t ) Estas probabilidades se basan en la condición de que la celda contenga el objetivo. Independientemente del número de casillas de predicción B, solo predecimos una categoría para cada celda.
Durante la fase de prueba, multiplicamos las probabilidades de clase condicional con las predicciones de confianza de caja pronosticadas para cada una. P r ( C lassi ∣ O bject ) ∗ P r ( O bject ) ∗ IOU predtruth = P r ( C lassi ) ∗ IOU predtruth Pr(Clase_i|Objeto)*P_r(Objeto)*IOU^{verdad}_{pred} =P_r(Class_i)*IOU^{verdad}_{pred}P r ( Clase _ _ _yo∣ O bjeto ) _ _∗PAGr( Objeto ) _ _ _∗YO TU _antes de _ _la verdad _ _ _=PAGr( Clase _ _ _yo)∗YO TU _antes de _ _la verdad _ _ _Esta fórmula proporciona la puntuación de confianza específica de la clase para cada casilla predicha. Esta puntuación codifica tanto la probabilidad de que el cuadro predicho aparezca en esa clase como qué tan bien el cuadro predicho coincide con el objetivo.
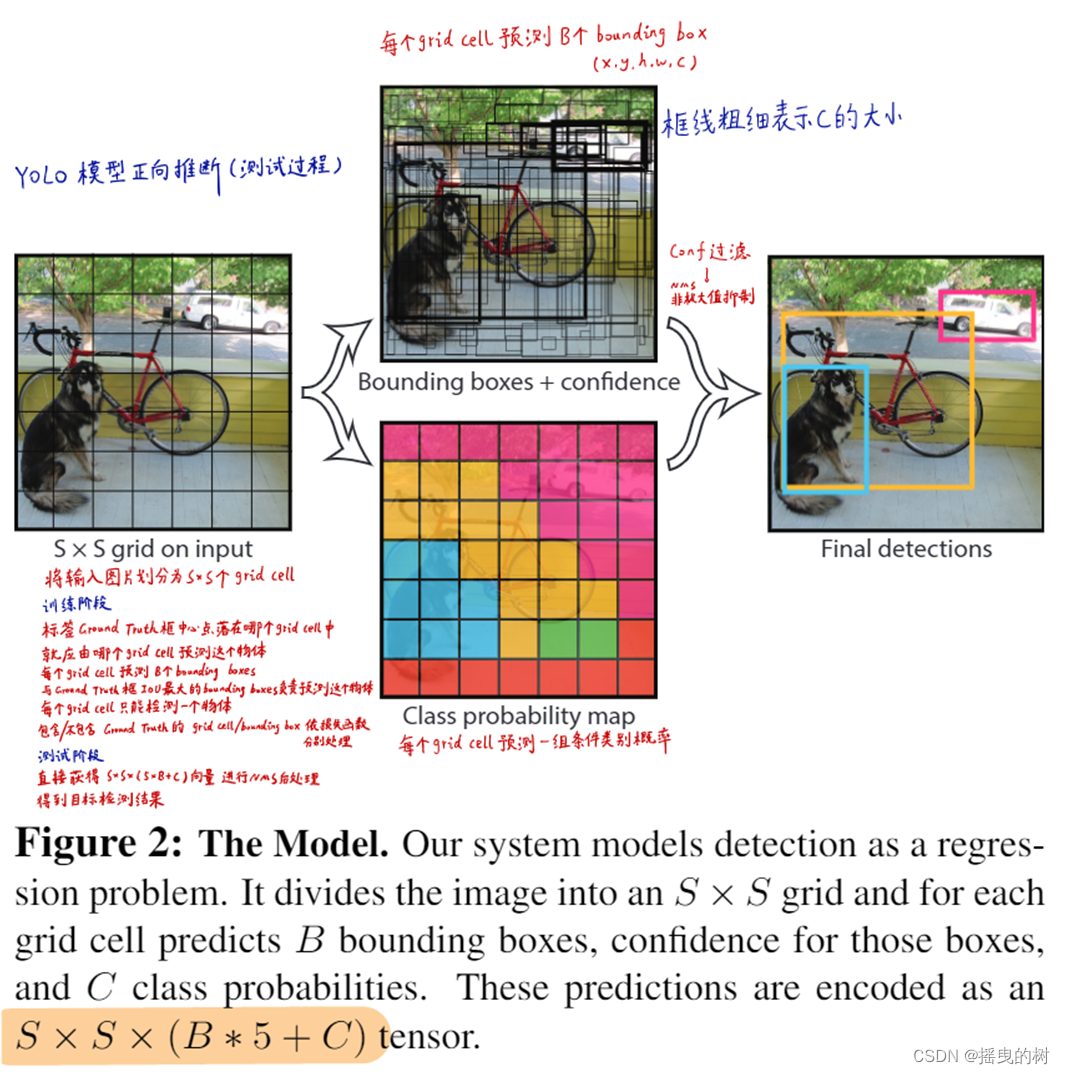
Figura 2: Modelo. Nuestro sistema modela el modelo de detección como un problema de regresión. Divide la imagen en S x S SxSUna cuadrícula de S x S , cada cuadrícula predice B cuadros delimitadores, la confianza de cada cuadro predicho y la probabilidad de C clases. Estas predicciones están codificadas comoS ∗ S ∗ B ∗ 5 + CS*S*B*5+CS∗S∗B∗5+Tensor dimensional C.
Para evaluar YOLO en el conjunto de datos PASCAL VOC, establecemos S = 7, B = 2 S = 7, B = 2S=7 ,B=2 , PASCAL VOC tiene 20 etiquetas de categoría, por lo queC = 20 C=20C=20 , finalmente predecimos7 ∗ 7 ∗ 30 7*7*307∗7∗30维的张量。
2.1 网络架构的设计

我们将模型实现为卷积神经网络,并在Pascal VOC检测数据集上进行了评估。网络的初始卷积层提取图像的特征,而全连接层预测输出概率和坐标。
我们的网络架构是受到GoogLeNet图像分类模型的启发。我们网络有24层卷积接2层全连接层。不同于GoogLeNet使用inception模块,我们简单地使用11降维层和33的卷积层,类似于文献22.整个网络如图3 所示。
我们还训练一个快速版本的YOLO,旨在突破快速目标检测的界限。快速版本的YOLO使用的神经网络包含更少的卷积层(9层取代原先的24层),这些网络层包含更少的滤波器。除了网络规模外,YOLO和Fast YOLO所有训练和测试的参数都是相同的。
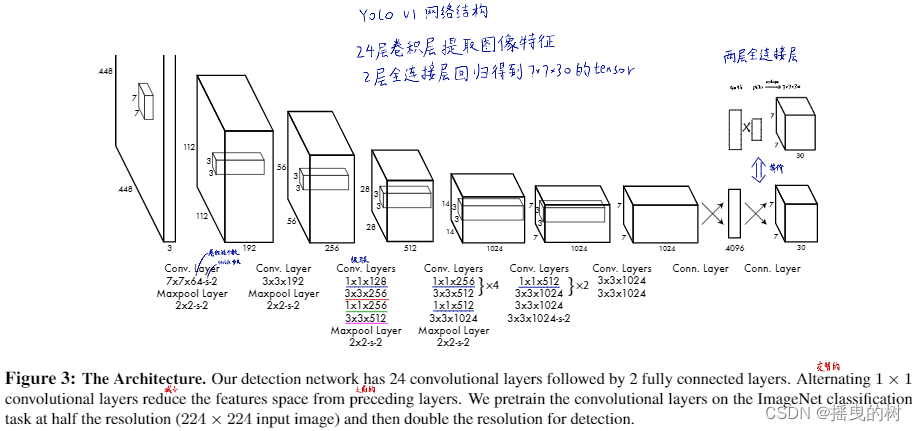
图3:模型架构。我们的检测网络有24层卷积层接着2层全连接层。交替使用1x1的卷积层来减少前一层的特征空间。我们在 ImageNet分类任务上以一半的分辨率(224*224输入图像)预训练卷积层,然后将分辨率加倍用于检测。
2.2 训练

我们再在ImageNet1000类竞赛数据集中预训练了我们的卷积层。我们使用图3中的前20个卷积层,紧接一个平均池化层和全连接层进行预训练。我们训练该模型花了大约一周的时间,在 ImageNet 2012 验证集上实现了无裁剪条件下前五准确率的平均值为88%,该准确率相当于在Caffe框架下训练的GoogLeNet模型。所有的训练和推理过程我们都使用Darknet框架。
然后,我们将模型转化为执行检测。任少卿的论文中表明预训练网络中增加卷积层和全连接层可以提高性能。效仿他们的研究,我们增加了四个卷积层和两个全连接层并随机初始化权重。检测往往需要细粒度的视觉信息,因此我们将网络输入分辨率由224x224增加到448x448.

我们的最终层同时预测类别概率和边界框坐标。我们将边界框的宽和高除以图像的宽和高使其归一化到0-1之间。我们将边界框的x,y参数化为特定网格位置的偏移量,因此它们也在0-1之间。
我们对最终层使用线性激活函数,而其他层使用如下的leaky 校正线性激活函数。

在模型输出端我们优化了平方和误差。我们使用平方和误差因为它易于优化,但不符合最大化平均精度的目标。它使定位误差和并不理想的分类误差平分秋色。此外,每张图像上许多网格都不包含任何对象。这会导致这些网格的置信度趋于零,通常会压倒性超过确实包含对象的单元格梯度。这会导致模型不稳定,导致早期训练发散。

为了补救,我们提高边界框预测损失权重,降低那些不包含目标的边界框预测置信度的损失。我们引入两个参数 λ c o o r d , λ n o o b j \lambda_{coord},\lambda_{noobj} λcoord,λnoobj来实现,设置值为 λ c o o r d = 5 , λ n o o b j = 0.5 \lambda_{coord}=5,\lambda_{noobj}=0.5 λcoord=5,λnoobj=0.5。
平方和误差对大的预测框和小的预测框赋予相同权重。我们的误差矩阵理应反应大框的小偏差不如小框的偏差重要。为了部分解决这个问题,我们预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO预测每个单元格有多个预测框。在训练阶段我们只需要一个边界框预测器负责每一个对象。我们指定一个预测器负责预测一个对象,基于该预测结果当前与真实预测有更高的IOU。这导致预测框之间的特化。每个预测器能够更好的预测对象的尺寸、长宽比和列别,从而提高整体的召回率。
损失函数如下:


其中 1 i o b j 1^{obj}_i 1iobj对象出现在单元格i中, 1 i j o b j 1^{obj}_{ij} 1ijobj表示单元格i中的第j个预测框负责该预测。
注意,损失函数仅在该网格存在对象时才会对类别损失进行惩罚(前面讨论的条件类别概率)。如果该预测器负责真实框预测才会惩罚预测框定位损失(该单元格中最高的IOU预测器)。
我们在 PASCAL VOC 2007和2012的训练集和验证集上对网络训练了大约135轮。在2012的测试集中还包含了用于训练的VOC2007测试数据。在整个训练过程中,我们使用的batch size为64,动量为0.9,衰减率为0.0005.

我们的学习率进度安排如下:前几轮我们从 1 0 − 3 到 1 0 − 2 10^{-3}到10^{-2} 10−3到10−2缓慢提升学习率。如果我们以较高的学习率开始训练,我们的模型往往会因为不稳定的梯度而发散。我们继续以 1 0 − 2 10^{-2} 10−2训练75轮,然后 1 0 − 3 10^{-3} 10−3训练30轮,最后 1 0 − 4 10^{-4} 10−4训练30轮。
为了避免过拟合我们使用dropout和大量的数据增强。dropout层以0.5的概率接在第一个全连接层防止各个层之间的共同适应。对于数据增强我们引入了随机缩放和达到原始图像20%的平移。我们还在HSV颜色空间中随机调整图像的曝光和饱和度,最高有1.5。

2.3 推理

就像在训练阶段一样,对测试图像的预测检测只需要一次网络评估。 在PASCAL VOC数据集中网络对每张图预测98个预测框及其类概率。与基于分类器的方法不同,YOLO在测试时非常快,因为它只要单一的网络评估。
网络设计加强了边界框预测的空间多样性。通常对象属于哪一个网格是非常清楚的,网络对每一个对象只预测一个框。但是一些大目标或者临近多个网格边缘的目标容易会被多个网格定位。非极大抑制可以解决这种重复预测。虽然不像R-NN或DPM那样对性能至关重要,得极大抑制可以增加2%-3%的mAP。
2.4 YOLO的局限

YOLO对边界框预测强制执行严格的空间限制,因为每个网格单元智能预测两个框,并且只能有一个类别。这种空间限制制约了我们的模型可以预测临近对象的数量。我们模型难以预测成群出现的小目标,如鸟群。
因为我们的模学习从数据中预测边界框,它难以泛化到新的目标或长宽比或构形不常见的对象。我们的模型仍然使用粗粒度特征来预测边界框,因为我们的算法对输入图像经过多次下采样层。
最后,当我们寻来你一个近似检测性能的损失函数时,我们的损失函数对小框和大框的误差进行相同处理。大框的小误差大体上是良性的,但小框的小误差会对IOU产生更大的影响。我们的误差主要来源于不正确的定位。
3 对比其他的检测系统

目标检测是计算机视觉的核心问题。检测工作流通常是从输入图像中提取一组鲁棒的特征开始(Haar、 SIFT、HOG和卷积特征)。然后分类器和定位器用来在特征空间中识别目标。这些分类器和定位器以滑动窗口的方式在全幅图像中运行,或者在图像区域的某些子集中运行。我们将YOLO检测系统和其他顶级的检测框架进行比较,强调关键测相似和不同之处。
可变性的组件模型(DPM)使用滑动窗口的方法进行目标检测。DPM使用不相交的工作流来提取静态特征、对区域进行分类,预测高得分预测的边界框。我们的系统使用一个单一的卷积神经网络替代所有这些不同的部分。网络同时执行特征提取,边界框预测
非极大抑制和上下文信息推理。该网络不是静态特征,而是在线训练特征并针对检测任务对齐进行优化。我们统一的框架带来了比DPM更快、更准的模型。

R-CNN及其衍生网络使用候选区域提取替代滑动窗口在图象中寻找目标。选择性搜索产生候选边界框,卷积网络提取特征,SVM对边界框进行打分,线性模型调整边界框,非极大抑制剔除重复的检测结果。复杂工作流中的每一个阶段都必须独立进行微调,导致系统非常慢,在测试阶段每张图像需要40秒以上的时间。
YOLO与R-CNN有一些相似之处。每个网络单元格提取潜在的边界框,并用卷积特征对这些框进行打分。但是我们系统对单元网格施加空间约束,这有助于减少对同一对象的多次检测。我们网络提取更少的边界框,每张图像只有98个候选框,远少于选择性搜索的2000个候选框。最后,我们系统将这些独立的组件整合成一个联合优化的模型。

其他快速检测器:Fast 和 Faster R-CNN专注于通过共享算力和使用神经网络来提取候选区域而不是选择性搜索来加速R-CNN框架。虽然它们提供了比R-CNN更快的速度和更高的精度,但仍没有达到实时性能。
许多研究工作都集中在加速DPM的工作流速度上。他们加快HOG计算、使用级联,并使用GPU来进行计算。但是真正实时运行的只有30赫兹DPM
不是试图优化巨大检测工作流的独立组件,YOLO丢到了所有的工作流专为快速而设计。
像人脸和人这样单一类别的检测器可以高度优化,因需要处理的变化要少得多。YOLO是一种通用的检测器可以学习同时检测多种对象。

Deep MultiBox:不同于 R-CNN训练卷积神经网络预测感兴趣区域,而不是使用选择性搜索。MultiBox还可以通过将置信度预测替换为单类别预测来执行单目标检测。但是MultiBox无法执行通用目标检测,因为它只是更大检测流程中的一部分,需要进一步的图像块分类。YOLO和MultiBox都使用卷积网络在图像中预测边界框,但YOLO是一个完整的检测系统。
OverFeat:Sermanet等人训练一个卷积神经网络来执行定位,并使用该定位器执行检测。OverFeat高效地执行滑窗检测但仍然是一个分离的系统。OverFeat针对定位进行了优化而不是检测性能。如DPM,定位器在预测时只能看到局部信息。OverFeat不能对全局上下文进行推理,因此需要大量的后处理才能产生合乎逻辑的检测结果。

MultiGrasp:我们的工作在设计上类似于Redmon的抓取检测工作。我们的网格边界框预测方法是基于MultiGrasp系统的回归抓取。但是抓取检测是比目标检测简单得多的任务。对于包含一个对象的图像,MultiGrasp只需预测单个可抓取的区域。它不需要估计尺寸、定位和对象边框或者预测其类别,只需要找到适合抓取的区域。YOLO预测图像中多个类别的多个对象的边界框和类别概率。
4 实验

我们在PASCAL VOC 2007数据集上对比了YOLO和其他实时检测系统。为了理解YOLO和 R-CNN衍生模型的不同之处,我们探究了YOLO和 Fast R-CNN在 VOC 2007数据集上的误差,后者是R-CNN性能最高的版本之一。基于不同的误差分布,我们表明YOLO可以用于Fast R-CNN检测的重新评分,并减少背景误报带来的错误,从而显著提高了性能。我们还展示了VOC 2012的结果,并将mAP与当前最先进的方法进行了比较。最后我们在两个艺术作品数据集上证明了YOLO比其他检测器更好地泛化到新的领域。
4.1 YOLO与其他实时目标检测方法性能比较

目标检测方面的许多研究都集中在快速实现标准检测工作流。但是只有 Sadeghi等人真正实现了实时运行的系统(每秒30帧或者更快)。我们将YOLO和其他基于GPU实现的DPM进行比较,后者运行速度可以达到30Hz或100Hz。虽然其他的研究没有达到实时的里程碑,但是我们也比较了它们相对的 mAP和速度,以分析目标检测系统中已实现的精度和性能之间的权衡。
Fast YOLO是PASCAL数据集上最快的目标检测方法,总所周知,它是目前现存最快的目标检测器。实现52.7% mAP,精度是先前实时检测工作的2倍多。 YOLO将 mAP逼近63.4%却仍然能保持实时的性能。
我们也用VGG-16骨干网络训练了YOLO。该模型精度更高但也比YOLO慢得多。和其他基于VGG-16骨干的检测系统相比是有用的,但它相对于实时仍然是慢的,因此本文的其余部分集中在更快的模型。
Fastest DPM在没有牺牲太多 mAP基础上有效地加快了DPM,但它仍将实时性能降低了两倍。和神经网络的方法相比,DPM的精度相对较低,这也限制了它的应用。

R-CNN中的R是将选择性搜索换成了静态的候选框。虽然比原生的R-CNN快,但仍然没有达到实时的性能,并且没有好的候选区域造成了准确率的损失。
Fast R-CNN虽然加速了 R-CNN 的分类阶段但它仍然依赖选择性搜索,每张图片需要耗费大约2秒来产生候选框。因此它可以达到较高的 mAP但每秒0.5帧的速度远达不到实时。
最近的Faster R-CNN用神经网络取代选择性搜索产生候选框,类似于Szegedy等人的研究。在我们的测试中,他们最高精度的模型实现了每秒7帧的速度,而更小更低精度的模型达到每秒18帧的速度。 VGG-16 版本的Faster R-CNN高出了10 mAP但还是比YOLO慢了6倍之多。 ZeilerFergus(人名)的 Faster R-CNN只比YOLO满了2.5倍,但准确率很低。
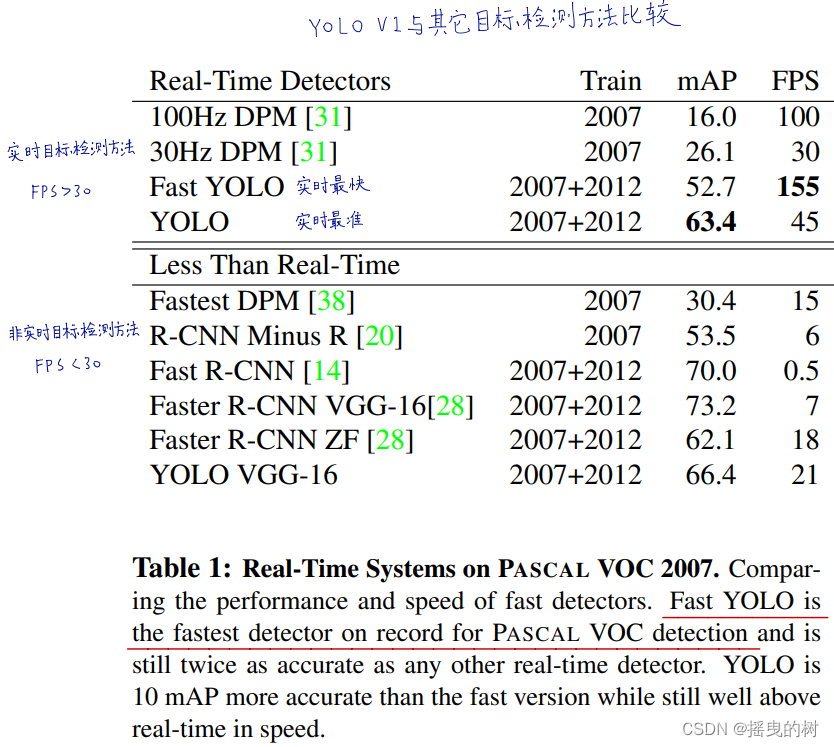
表1:在PASCAL VOC 2007数据集上的实时系统。对比快速检测模型的性能和速度。 Fast YOLO是 PASCAL VOC检测记录上最快的检测器,其精度仍然是其他任何实时检测器的两倍。YOLO的精度比其他快速检测器高了10 mAP,在速度上仍能达到实时以上。
4.2 YOLO和Fast R-CNN在VOC 2007数据集上的误差分析

为了进一步研究YOLO和最先进检测器之间的差异,我们查看了VOC 2007 的详细结果条目。我们将 YOLO和Fast RCNN对比,因其是 PASCAL数据集上性能最高的检测器之一,并且它的检测结果是公开可得的。
我们使用Hoiem等人的方法和工具。对于测试阶段的每一类我们看前N个的类别预测结果。每个预测要么正确,要么根据误差类别进行分类:

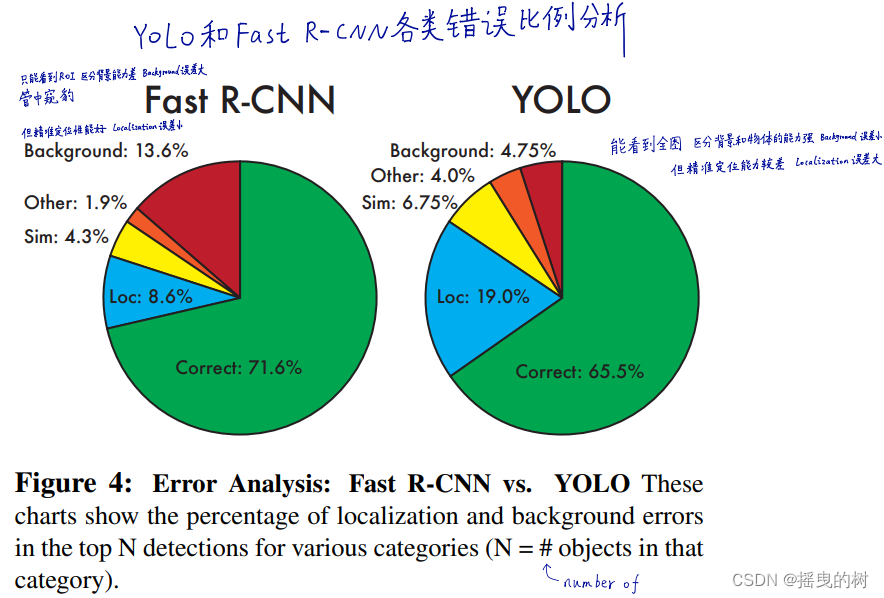
Fast R-CNN vs YOLO误差分析。这些图标显示了不同类别前N项检测结果的定位和背景误差的概率。(N为该类的对象数)

图4显示了20类中每种错误类型的分析。
YOLO难以准确地定位目标。YOLO的定位误差比其他误差的总和还多。 Fast R-CNN产生的定位误差少但背景误差较多。检测结果中最高的13.6%来自那些不包含目标的假阳例。Fast R-CNN预测背景的可能性几乎是是YOLO的3倍。
4.3 Fast R-CNN和YOLO优势互补

YOLO相比 Fast R-CNN产生的背景错误少得多。通过使用YOLO来消除Fast R-CNN中的背景检测,我们在性能上得到了显著的提高。 对于每个R-CNN的预测框我们查看YOLO是否有相似的预测框。如果存在,我们会根据YOLO的预测概率和两框的重贴程度来提升预测。
最好的Fast R-CNN模型在VOC 2007测试集上mAP达到了71.8%。和YOLO结合mAP增加了3.2%达到了75%。我们还尝试了结合最优的 Fast R-CNN模型和其他版本的 Fast R-CNN。这些组合产生了0.3%-0.6%之间mAP小幅增长,详情见表2.
YOLO带来的提升是因为它不是模型集成的副产品,因为集成不同版本的 Fast R-CNN几乎无法带来提升。相反,正因为YOLO在测试阶段犯了不同类型的错误,它才能如此有效的提升 Fast R-CNN的性能。
不幸的是,这种结合无法发挥YOLO在速度方面的优势,因为我们单独运行每个模型再整合结果。但是,正因为YOLO如此之快,相比 Fast R-CNN它不会增加任何显著的计算时间。
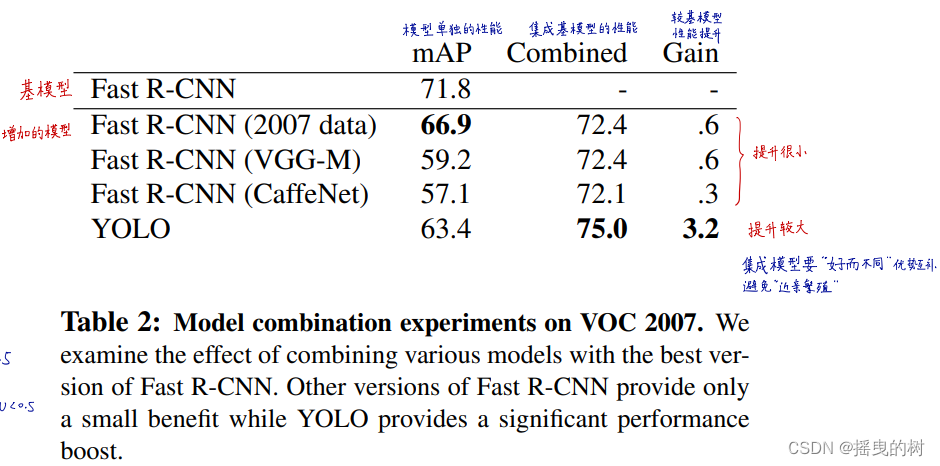
表2:集成模型再VOC 2007上的实验。我们分析了将各种模型与最优版本 Fast R-CNN结合的效果。其他版本的 Fast R-CNN只能带来微小的益处,而YOLO可以带来显著的性能提升。
4.4 VOC 2012数据集上的结果
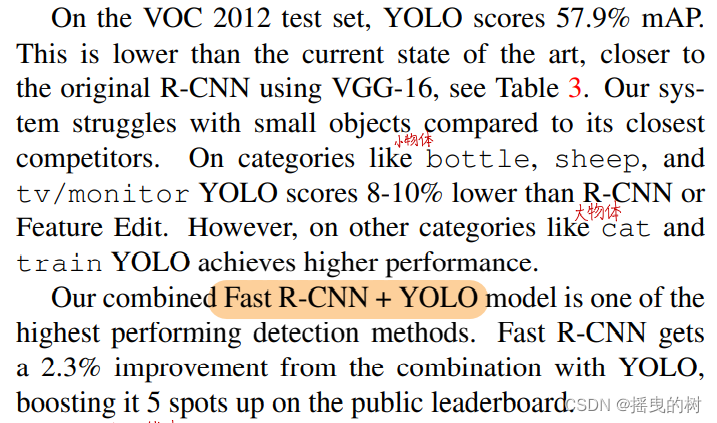
在VOC2012测试集上,YOLO获得mAP57.9% 的得分。这低于目前先进的检测模型,接近于使用VGG-16的R-CNN,见表3。与最接近的竞争模型对比,我们系统难以识别小目标。在像瓶子、羊群和电视/显示器电视/显示器等类别上,YOLO的得分比R-CNN或Feature Edit低8-10%。但是其他像猫和火车等类别,YOLO可以实现更高的性能。
我们集成的Fast R-CNN+YOLO模型是性能最高的检测方法之一。Fast R-CNN与YOLO的合并提高了2.3%,在公众排行榜上上升了5个名次。
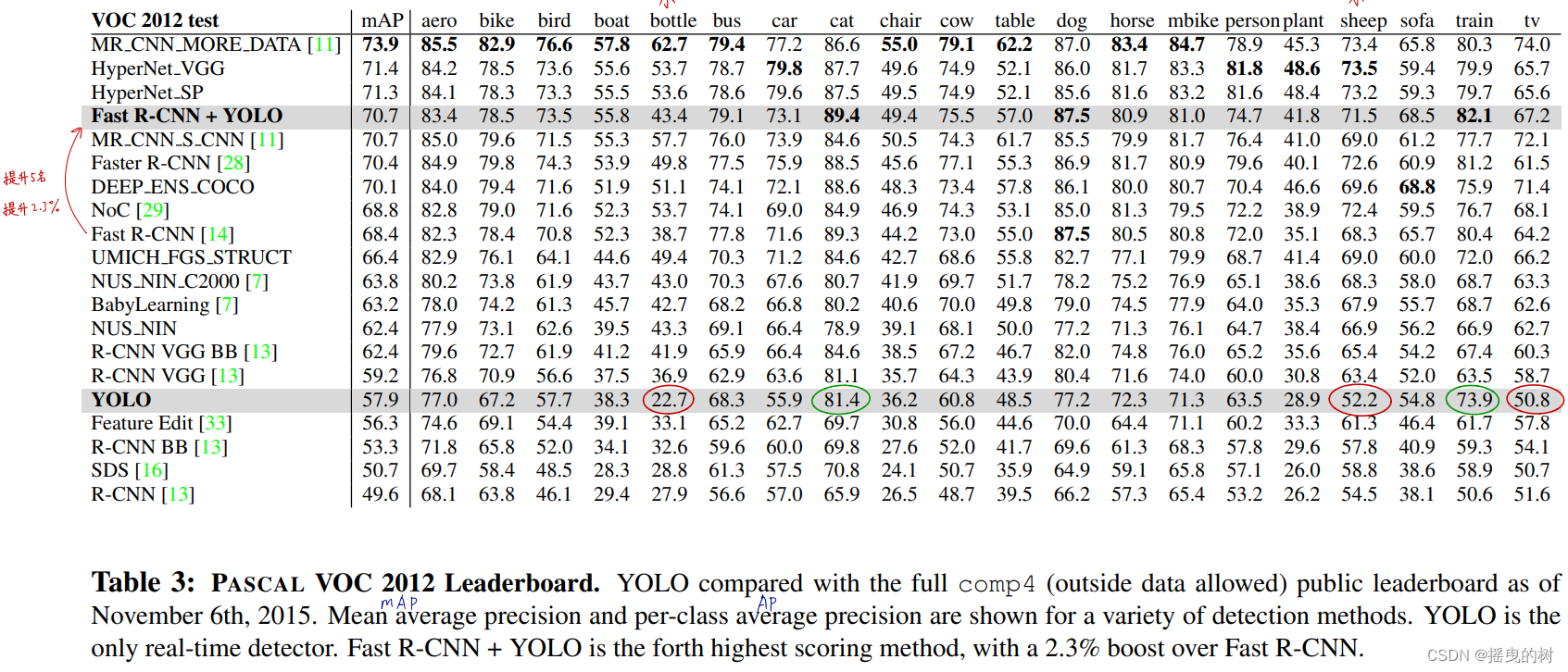
表3:PASCAL VOC 2012排行榜。YOLO与截至2015年11月6日的完整Comp4(允许外部数据)公共排行榜进行比较。对于各种检测方法,显示了平均平均精度和每类平均精度。YOLO是唯一的实时检测器。FAST R-CNN+YOLO是得分第四高的方法,比Fast R-CNN高出2.3%。
4.5 泛化性:在艺术作品上的人物检测

用于学术的数据集对于目标检测在训练集和测试集上的数据分布是一样的。但在真实世界的应用中,很难预测所有可能的场景,并且测试数据可能是系统从未见过的。我们在 毕加索数据集和人类艺术作品集上对比了YOLO和其他检测系统,这两个数据集用于测试艺术作品上的人物检测。
图5显示了YOLO和其他检测方法的性能比较。便于参考,我们对人这类目标提供了VOC 2007检测AP,其中所有的模型只在VOC 2007上进行训练。在毕加索数据集上测试的模型在VOC2012上训练,而人类艺术作品上的模型在VOC 2010上训练。
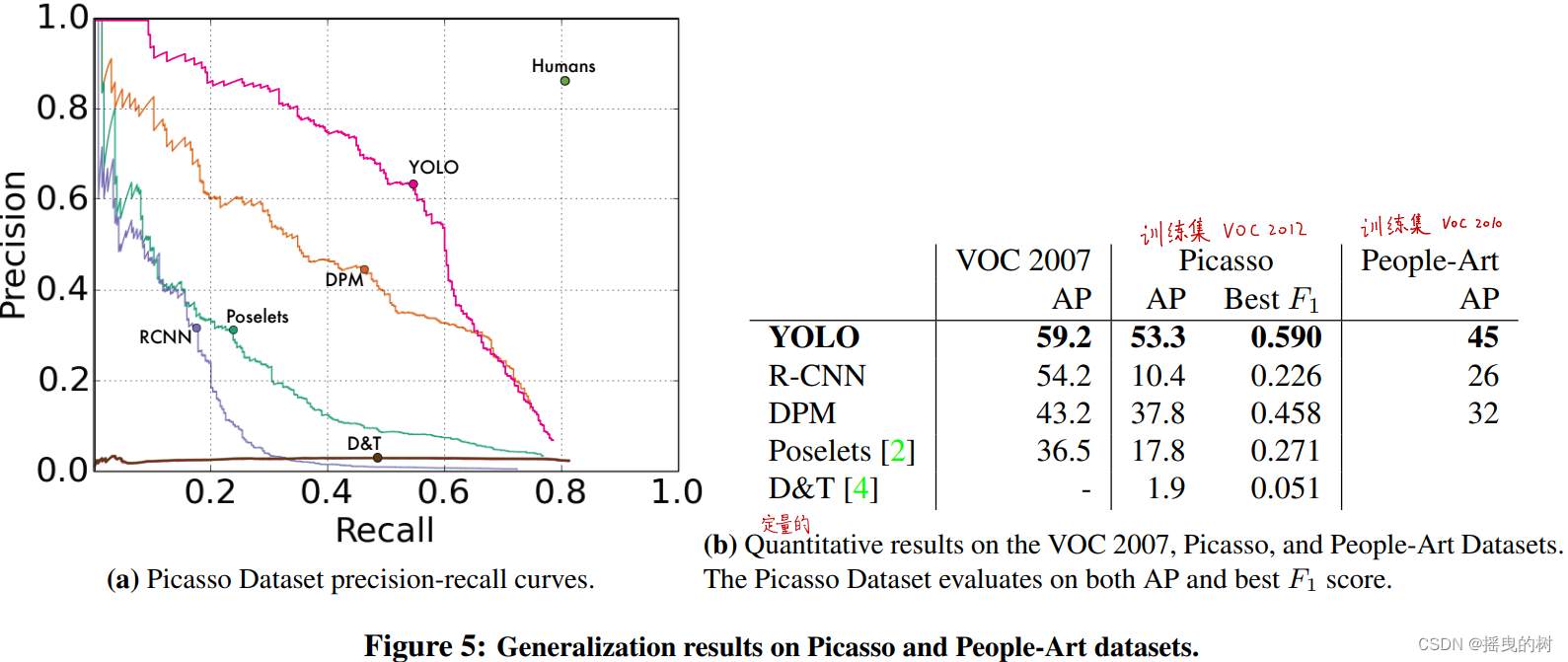
图5:毕加索和人类艺术作品数据集的泛化结果。(a)毕加索数据集上的P-R曲线;(b)VOC 2007、毕加索和人类艺术作品数据集的定量结果。毕加索数据集对AP和最佳F1得分进行评估。

R-CNN在VOC 2007上有较高的 AP。但是,R-CNN应用到艺术作品集上就显著地掉性能了。R-CNN使用选择性搜索来提取边界框,这是针对自然图像调整的。R-CNN中的分类器只能看到小区域,因此需要较佳的候选框。
DPM在艺术作品集上仍很好地保持 AP。先前的工作理论认为,DPM表现良好是因为强大的对象形状和布局的空间模型。虽然DPM不像 R-CNN一样显著地掉性能,因为它原来的AP就很低。
YOLO在VOC 2007表现出了优异地性能,当应用到艺术作品中相比其他方法较少掉性能。和DPM一样,YOLO对对象地尺寸、形状以及对象之间的关系和对象通常出现的位置进行建模。艺术作品和自然图像在像素层面是非常不同的,但是就对象的尺寸和形状是相似的,因此YOLO仍可以预测出较好的边界框和检测结果。
5 现实中的实时检测器

YOLO es un detector de objetos rápido y preciso y un modelo ideal para la visión artificial. Conectamos YOLO a la cámara y verificamos que puede mantener el rendimiento en tiempo real, incluida la obtención de imágenes de la cámara y la visualización de los resultados de la detección.
Dichos sistemas son interactivos y atractivos. Mientras que YOLO procesa imágenes solo, cuando se conecta a una cámara funciona como un sistema de seguimiento, detectando objetos a medida que se mueven y cambian de apariencia. Las muestras del sistema y el código fuente se pueden encontrar en el sitio web de nuestro proyecto: http://pjreddie.com/yolo/

Figura 6: Resultados cualitativos. YOLO funciona con obras de arte de muestra e imágenes naturales de Internet. Es mayormente preciso, aunque cree que una persona es un avión (segunda imagen inferior izquierda).
6. Conclusión

Presentamos YOLO, un modelo unificado de detección de objetos. Nuestro modelo tiene una estructura simple y se puede entrenar directamente en la imagen completa. A diferencia de los modelos basados en clasificadores, YOLO se entrena en una función de pérdida correspondiente al rendimiento de detección, y todo el modelo se entrena de forma conjunta.
Fast YOLO es el modelo de detección de objetos de propósito general más rápido en la literatura, y YOLO avanza el estado del arte en la detección de objetos en tiempo real. YOLO también se generaliza bien a nuevos dominios, lo que lo convierte en una aplicación ideal para la detección rápida y robusta de objetos.
Agradecimientos: Esta investigación fue financiada en parte por ONR N00014-13-1-0720, NSF IIS-1338054 y un Premio Allen al Investigador Distinguido.
referencias
