Combate de programación FlinkTableAPI y SQL
A continuación, ingresemos juntos la codificación real de FlinkSQL y realicemos el desarrollo de la codificación de FlinkSQL a través del código.
1. Práctica de API de tabla Flink
1.1 Cree un proyecto Maven y agregue dependencias con las coordenadas del paquete jar
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.binary.version>2.12</scala.binary.version>
<flink.version>1.14.3</flink.version>
<hadoop.version>3.1.4</hadoop.version>
<hbase.version>2.2.7</hbase.version>
<hive.version>3.1.2</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.15</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.15</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.5</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<artifactId>commons-math3</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<artifactId>hadoop-hdfs</artifactId>
<groupId>org.apache.hadoop</groupId>
</exclusion>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
-->
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr-runtime</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
<!-- put your configurations here -->
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.10</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2. Funcionamiento de la API de FlinkTable
FlinkTable API proporciona muchos conectores para conectar varias fuentes de datos, como CSV, json, datos HDFS, datos HBase, datos Kafka, datos JDBC, datos Hive, etc., y puede conectar directamente datos de varios sistemas a Flink para procesar, y luego los datos procesados también se pueden escribir en varios lugares
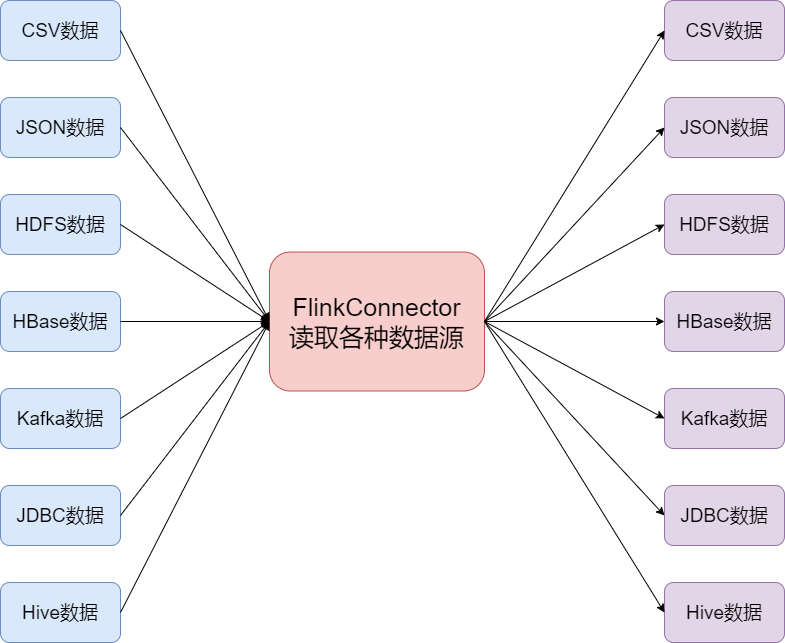
Echemos un vistazo al uso de varias fuentes de datos de entrada.
2.1, lea los datos de la colección y realice la consulta de datos en el registro
Lea los datos en la colección, luego regístrese y realice la operación de consulta de los datos
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.row;
public class FlinkTableStandardStructure {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2、创建source table: 1)读取外部表;2)从Table API或者SQL查询结果创建表
Table projTable = tEnv.fromValues(
DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.DECIMAL(10, 2)),
DataTypes.FIELD("name", DataTypes.STRING())
),
row(1, "zhangsan"),
row(2L, "lisi")
).select($("id"), $("name"));
//注册表到catalog(可选的)
tEnv.createTemporaryView("sourceTable", projTable);
//3、创建sink table
final Schema schema = Schema.newBuilder()
.column("id", DataTypes.DECIMAL(10, 2))
.column("name", DataTypes.STRING())
.build();
//https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/print/
tEnv.createTemporaryTable("sinkTable", TableDescriptor.forConnector("print")
.schema(schema)
.build());
//4、Table API执行查询(可以执行多次查询,中间表可以注册到catalog也可以不注册)
Table resultTable = tEnv.from("sourceTable").select($("id"), $("name"));
//如果不注册sourceTable,可以这么写
//Table resultTable = projTable.select($("id"), $("name"));
//5、输出(包括执行,不需要单独在调用tEnv.execute("job"))
resultTable.executeInsert("sinkTable");
}
}
2,2, conector integrado de mesa Flink
Table API & SQL de Flink se conecta a sistemas externos a través de conectores y realiza operaciones de lectura y escritura por lotes/flujos. Los conectores proporcionan una gran cantidad de conectores de sistemas externos y admiten diferentes formatos, como CSV, Avro, Parquet u ORC, según el tipo de fuente y sumidero. Nota: si es un sumidero, también debe prestar atención a los modos de salida admitidos (Agregar/Retraer/Insertar)
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/overview/
| nombre | versión compatible | fuente | hundir |
|---|---|---|---|
| sistema de archivos | Se admiten búsquedas y escaneos limitados e ilimitados | Fregadero de transmisión, Fregadero de lote | |
| Kafka | 0.10+ | escaneo ilimitado | Fregadero de transmisión, Fregadero de lote |
| JDBC | Exploración y búsqueda limitadas | Fregadero de transmisión, Fregadero de lote | |
| HBase | 1.4.x, 2.2.x | Exploración y búsqueda limitadas | Fregadero de transmisión, Fregadero de lote |
| Colmena | 1.0, 1.1, 1.2, 2.0, 2.1, 2.2, 2.3, 3.1 | Exploración ilimitada, exploración limitada y búsqueda | Fregadero de transmisión, Fregadero de lote |
| Elasticsearch | 6.x y 7.x | no apoyo | Fregadero de transmisión, Fregadero por lotes |
Formato de tabla
Los datos se almacenan en varios formatos en diferentes almacenamientos (CSV, Avro, Parquet o ORC, etc.), y Flink define Format para admitir la lectura de datos en diferentes formatos.
| Formatos | Conectores de soporte |
|---|---|
| CSV | Apache Kafka, Upsert Kafka, sistema de archivos |
| JSON | Apache Kafka, Upsert Kafka, sistema de archivos, Elasticsearch |
| apache avro | Apache Kafka, Upsert Kafka, sistema de archivos, |
| parquet apache | sistema de archivos |
| Apache ORCO | sistema de archivos |
| Debezium | Apache Kafka, |
| Canal | Apache Kafka, |
| Maxwell | Apache Kafka, |
| Crudo | Apache Kafka, |
2.3 Realice la lectura de datos JSON a través del conector integrado y escriba los datos en HDFS para convertirlos en formato de datos CSV
Leer datos JSON a través del conector integrado de Flink
Lea el contenido del archivo CSV a través de TableAPI y luego escriba los datos en HDFS
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class FlinkJson2HDFSCsv {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE json_table (\n" +
" id Integer,\n" +
" name STRING,\n" +
" email STRING,\n" +
" date_time STRING" +
") WITH (\n" +
" 'connector'='filesystem',\n" +
" 'path'='input/userbase.json',\n" +
" 'format'='json'\n" +
")";
String sink_sql = "CREATE TABLE sink_hdfs (\n" +
" id Integer,\n" +
" name STRING,\n" +
" email STRING,\n" +
" date_time STRING" +
") WITH ( \n " +
" 'connector' = 'filesystem',\n" +
" 'path' = 'hdfs://bigdata01:8020/output_csv/userbase.csv' , \n" +
" 'format' = 'csv'\n" +
")";
String insert_SQL = "insert into sink_hdfs select id,name ,date_time,email from json_table ";
//注册表
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(insert_SQL);
}
}
2.4 A través del conector incorporado, lea los datos en formato csv en HDFS y escríbalos en HBase
Lea datos json a través del conector integrado de Flink y luego escriba los datos leídos en HBase
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/filesystem/
Ingrese al cliente de shell HBase y cree una tabla
[hadoop@bigdata01 ~]$ cd /opt/install/hbase-2.2.7/
[hadoop@bigdata01 hbase-2.2.7]$ bin/hbase shell
hbase(main):009:0> create 'hTable','f1'
Lea el contenido del archivo CSV a través de TableAPI y luego escriba los datos en HBase
import org.apache.flink.table.api.*;
public class FlinkWithHDFSCSV2HBase {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE source_hdfs (\n" +
" id Integer,\n" +
" name STRING,\n" +
" date_time STRING,\n" +
" email STRING" +
") WITH ( \n " +
" 'connector' = 'filesystem',\n" +
" 'path' = 'hdfs://bigdata01:8020//output_csv/userbase.csv/' , \n" +
" 'format' = 'csv'\n" +
")";
String sink_sql = "CREATE TABLE sink_table (\n" +
" rowkey Integer,\n" +
" f1 ROW<name STRING,email STRING,date_time STRING > ,\n" +
" PRIMARY KEY (rowkey) NOT ENFORCED \n" +
") WITH (\n" +
" 'connector' = 'hbase-2.2',\n" +
" 'table-name' = 'hTable',\n" +
" 'zookeeper.quorum' = 'bigdata01:2181,bigdata02:2181,bigdata03:2181'\n" +
") ";
String execute_sql = "insert into sink_table select id as rowkey,ROW(name,email,date_time) from source_hdfs ";
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(execute_sql);
}
}
2.6 Lea los datos en HBase a través del conector incorporado y escríbalos en Kafka
Lea los datos de HBase a través del conector integrado de Flink y luego escriba los datos en Kafka
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/hbase/
Cree una tabla HBase y agregue el siguiente contenido de datos
准备HBase数据集
hbase(main):003:0> create 'opt_log','f1'
#插入数据集
put 'opt_log','1','f1:username','郑剃'
put 'opt_log','1','f1:email','[email protected]'
put 'opt_log','1','f1:date_time','2022-10-04 08:01:48'
put 'opt_log','2','f1:username','王曙介'
put 'opt_log','2','f1:email','[email protected]'
put 'opt_log','2','f1:date_time','2022-10-04 08:04:39'
put 'opt_log','3','f1:username','赖溯姆'
put 'opt_log','3','f1:email','[email protected]'
put 'opt_log','3','f1:date_time','2022-10-04 08:00:19'
Cree un tema de Kafak y abra al consumidor para el consumo
#查看topic列表
cd /opt/install/kafka_2.12-2.6.3/
bin/kafka-topics.sh --zookeeper bigdata01:9092,bigdata02:9092,bigdata03:9092 --list
#创建topic
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_output --replication-factor 3 --partitions 3
#打开消费者
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_output
Lea el contenido del archivo HBase a través de TableAPI y luego escriba los datos en Kafka
import org.apache.flink.table.api.*;
public class FlinkTableWithHBase2Kafka {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_table = "CREATE TABLE hTable (\n" +
" rowkey STRING,\n" +
" f1 ROW<username STRING,email STRING,date_time String> ,\n" +
" PRIMARY KEY (rowkey) NOT ENFORCED \n" +
") WITH (\n" +
" 'connector' = 'hbase-2.2',\n" +
" 'table-name' = 'opt_log',\n" +
" 'zookeeper.quorum' = 'bigdata01:2181,bigdata02:2181,bigdata03:2181'\n" +
") ";
String sink_table = "CREATE TABLE KafkaTable (\n" +
" `username` STRING,\n" +
" `email` STRING,\n" +
" `date_time` STRING \n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'user_output',\n" +
" 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',\n" +
" 'format' = 'json'\n" +
")";
String insert_sql = "insert into KafkaTable select username,email,date_time from hTable";
tableEnvironment.executeSql(source_table);
tableEnvironment.executeSql(sink_table);
tableEnvironment.executeSql(insert_sql);
}
}
2.7 Lea los datos en Kafka a través del conector incorporado y luego escriba los datos en mysql
Leer datos de Kafka a través del conector integrado de Flink
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/kafka/
Cree un tema de Kafka y agregue el siguiente contenido de datos
#创建topic
bin/kafka-topics.sh --zookeeper bigdata01:2181,bigdata02:2181,bigdata03:2181 --create --topic usr_opt --replication-factor 3 --partitions 3
#打开生产者
bin/kafka-console-producer.sh --broker-list bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic usr_opt
测试数据
{
"date_time":"2022-10-04 08:01:48","email":"[email protected]","id":0,"name":"郑剃"}
{
"date_time":"2022-10-04 08:06:31","email":"[email protected]","id":1,"name":"闾丘喜造"}
{
"date_time":"2022-10-04 08:04:39","email":"[email protected]","id":2,"name":"王曙介"}
{
"date_time":"2022-10-04 08:00:19","email":"[email protected]","id":3,"name":"赖溯姆"}
Kafka数据生产与消费
#查看topic列表
cd /opt/install/kafka_2.12-2.6.3/
bin/kafka-topics.sh --zookeeper bigdata01:9092,bigdata02:9092,bigdata03:9092 --list
#创建topic
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_input --replication-factor 3 --partitions 3
bin/kafka-topics.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --create --topic user_output --replication-factor 3 --partitions 3
#打开消费者
bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_output
#打开生产者
bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic user_input
#输入数据内容如下
{
"user":"Cidy","visit_url":"./home","op_time":"2022-02-03 12:00:00"}
{
"user":"Lili","visit_url":"./index","op_time":"2022-02-03 13:30:50"}
{
"user":"Tom","visit_url":"./detail","op_time":"2022-02-04 13:35:30"}
definir tabla mysql
CREATE DATABASE /*!32312 IF NOT EXISTS*/`user_log` /*!40100 DEFAULT CHARACTER SET latin1 */;
USE `user_log`;
/*Table structure for table `clickcount` */
DROP TABLE IF EXISTS `clickcount`;
CREATE TABLE `clickcount` (
`username` varchar(64) DEFAULT NULL,
`result` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `clickcount` */
/*Table structure for table `clicklog` */
DROP TABLE IF EXISTS `clicklog`;
CREATE TABLE `clicklog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL,
`date_time` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
/*Data for the table `clicklog` */
insert into `clicklog`(`id`,`username`,`email`,`date_time`) values (1,'zhangsan','[email protected]','2022-10-04 08:01:48'),(2,'lisi','[email protected]','2022-10-04 08:06:31');
Lea el contenido de datos de Kafka a través de TableAPI y luego escriba los datos en mysql
import org.apache.flink.table.api.*;
public class FlinkTableWithKafka2MySQL {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
String source_sql = "CREATE TABLE KafkaTable (\n" +
" id Integer,\n" +
" name STRING,\n" +
" email STRING,\n" +
" date_time STRING" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'usr_opt',\n" +
" 'properties.bootstrap.servers' = 'bigdata01:9092,bigdata02:9092,bigdata03:9092',\n" +
" 'properties.group.id' = 'user_opt_group',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")";
String sink_sql = "CREATE TABLE mysql_sink (\n" +
" id Integer,\n" +
" name STRING,\n" +
" email STRING,\n" +
" date_time STRING" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://localhost:3306/user_log?characterEncoding=utf-8&serverTimezone=GMT%2B8',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'table-name' = 'clicklog',\n" +
" 'username' = 'root',\n" +
" 'password' = '123456'\n" +
")";
String execute_sql = "insert into mysql_sink select id,name,email,date_time from KafkaTable";
tableEnvironment.executeSql(source_sql);
tableEnvironment.executeSql(sink_sql);
tableEnvironment.executeSql(execute_sql);
}
}
2.8 Leer datos de Hive y escribir datos de Hive a través del conector integrado
Leer datos de colmena a través del conector integrado de Flink
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/hive/overview/
Modifique las propiedades de configuración de hive-site.xml y agregue la siguiente configuración
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.52.120:9083</value>
</property>
Almacenar hive-site.xml en la ruta del proyecto
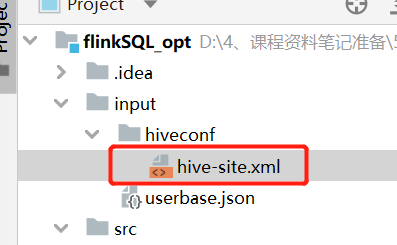
Inicie el servicio de metastore de Hive y cree una base de datos de Hive y una tabla de base de datos de Hive
#启动hive的metastore服务以及hiveserver2服务
[hadoop@bigdata03 apache-hive-3.1.2]$ cd /opt/install/apache-hive-3.1.2/
[hadoop@bigdata03 apache-hive-3.1.2]$ bin/hive --service metastore
[hadoop@bigdata03 apache-hive-3.1.2]$ bin/hive --service hiveserver2
#创建本地文件
[hadoop@bigdata03 install]$ cd /opt/install/
[hadoop@bigdata03 install]$ vim userbase.csv
#文件内容如下
0,郑剃,"2022-10-04 08:01:48",kyzqcd0686@vjikq.tng
1,闾丘喜造,"2022-10-04 08:06:31",bvkqwbmgwi@lh80q.4ln
2,王曙介,"2022-10-04 08:04:39",axvcbj7vbo@ecyi1.4gw
3,赖溯姆,"2022-10-04 08:00:19",ew1qu5sunz@caxtg.vtn
4,钱泼奎,"2022-10-04 08:04:51",50xdhnfppw@vwreu.kxk
5,尉迟亏,"2022-10-04 08:02:25",h8ist2s54k@lorkp.79s
6,贾盏,"2022-10-04 08:05:22",hnzfdmnjgo@rsiq9.syx
7,蔡辟,"2022-10-04 08:03:53",apjlg5pyuo@lhs6l.oj4
8,蔡矛,"2022-10-04 08:05:35",cpqofnn5xd@7iknh.qc5
9,赖妖炬,"2022-10-04 08:05:03",0wg3nfjdv9@fomvu.2kb
10,毛溜孝,"2022-10-04 08:06:37",1kkaib5i4e@ecvb8.6cs
准备Hive数据
#创建test数据库
create database if not exists test location "/user/hive/warehouse/test";
use test;
#创建Hive表
drop table userbase;
create table if not exists userbase
(id int,
name string,
date_time string,
email string
)
row format delimited fields terminated by ","
stored as textfile;
#加载click.txt至Hive表
load data local inpath '/opt/install/userbase.csv' into table userbase;
#查询Hive
select * from userbase;
#创建hive表数据保存目的地表
create table user_count (username string,count_result int) row format delimited fields terminated by '\t';
Leer contenido de datos de Hive a través de TableAPI
import org.apache.flink.table.api.*;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.module.hive.HiveModule;
public class FlinkTableWithHive {
public static void main(String[] args) {
//1.创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inBatchMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2.创建HiveCatalog
String name = "myCataLog";
String defaultDatabase = "test";
String hiveConfDir = "input/hiveconf/";
tEnv.loadModule(name,new HiveModule("3.1.2"));
tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
HiveCatalog hive = new HiveCatalog(name,defaultDatabase,hiveConfDir);
//3.注册catalog
tEnv.registerCatalog(name,hive);
//4.设置当前会话使用的catalog和database
tEnv.useCatalog(name);
tEnv.useDatabase(defaultDatabase);
tEnv.executeSql("insert into user_count select username,count(1) as count_result from clicklog group by username");
}
}
3. Tipo de tiempo de Flink
-
Para el procesamiento de datos de transmisión, la característica más importante es que los datos tienen atributos de tiempo.
-
Flink puede distinguir el tiempo en tres tipos de tiempo según la ubicación donde se genera el tiempo:
-
Hora del evento(hora del evento)
- La hora en que se generó el evento, que generalmente se describe mediante una marca de tiempo en el evento.
-
Tiempo de ingestión(hora de acceso al evento)
- La hora en que el evento ingresó al programa Flink.
-
Tiempo de procesamiento(tiempo de procesamiento del evento)
- La hora actual del sistema cuando se procesó el evento
-
-
Flink admite diferentes tipos de tiempo en los programas de procesamiento de flujo.
3.1 Hora del evento
- 1. El tiempo en que se genera el evento existe antes de ingresar a Flink y se puede extraer del campo del evento
- 2. Se debe especificar
watermarksel método de generación de (línea de nivel de agua) - 3. Ventajas: el determinismo, el desorden, el retraso o la reproducción de datos pueden dar resultados correctos
- 4. Debilidades: el rendimiento y la latencia se ven afectados al procesar eventos desordenados
3.2 Tiempo de ingesta
- 1. La hora de entrada del evento a Flink, es decir, la hora del sistema actual obtenida en la fuente, que se utiliza uniformemente para operaciones posteriores.
- 2. No es necesario especificar el método de generación de marcas de agua (generadas automáticamente)
- 3. Debilidades: no puede manejar eventos fuera de orden y datos retrasados
3.3 Tiempo de procesamiento
-
1. La hora actual del sistema de la máquina que realiza la operación (cada operador es diferente)
-
2. No requiere coordinación entre flujos y máquinas
-
3. Ventajas: mejor rendimiento y menor latencia
-
4. Debilidades: Incertidumbre, susceptible a varios factores (velocidad de generación de eventos, velocidad de flink, velocidad de transmisión entre operadores, etc.), independientemente del orden y la demora
3.4 Comparación integral de tres tipos de tiempo
-
actuación
- Tiempo de procesamiento > Tiempo de ingesta > Tiempo de evento
-
Demora
- Tiempo de procesamiento < Tiempo de ingesta < Tiempo de evento
-
Certeza
- EventTime > IngestionTime > ProcessingTime
3.5 Problema de desorden de mensajes
En un sistema en tiempo real, debido a los retrasos causados por varias razones, el momento en que se envían algunos mensajes a flink se retrasa desde el momento en que se genera el evento. Si la ventana se construye en función del tiempo del evento, pero para elementos tardíos, no podemos esperar indefinidamente, debe haber un mecanismo para garantizar que después de un tiempo específico, la ventana debe dispararse para realizar los cálculos.

4. Mecanismo de marca de agua de Flink
Mecanismo de marcas de agua (marca de agua)
Es una señal del progreso del procesamiento del tiempo del evento.
Indica que han llegado eventos anteriores (más antiguos) que la marca de agua (no hay datos inferiores a la marca de agua)
Juicio del cálculo del activador de la ventana basado en la marca de agua
1 Lo que está fuera de servicio
-
Cuando los datos se envían uno por uno de acuerdo con el proceso de manera regular, luego de ser transmitidos por MQ, y luego procesados por Flink después de recibirlos, en este momento, se procesan de manera ordenada.

-
Cuando ocurre una excepción, algunos datos se retrasan y los datos en la parte posterior aparecen en el frente, lo que conduce a un desorden.

-
Reflexionar: ¿Qué tipo de tiempo debemos usar para juzgar fuera de orden?
2 El concepto de marca de agua
- WaterMark (marca de agua) se usa principalmente para tratar eventos fuera de orden, y para manejar correctamente eventos fuera de orden, generalmente se implementa mediante el uso del mecanismo WaterMark combinado con la ventana.
- Desde el procesamiento de flujo de eventos de dispositivos sin procesar, hasta la lectura de datos del programa Flink, hasta el procesamiento de datos de múltiples operadores de Flink, en este proceso, debido a la influencia de factores externos como la red o el sistema, los datos están fuera de servicio para garantizar el cálculo. resultados La corrección necesita esperar los datos, lo que trae el retraso del cálculo.
- Para los datos que se han retrasado durante demasiado tiempo, no pueden esperar indefinidamente, por lo que debe haber un mecanismo para garantizar que la ventana se activará para el cálculo después de un cierto período de tiempo.Este mecanismo de activación es WaterMark.
3 Principio de la marca de agua
-
Durante el procesamiento de la ventana de Flink, si se determina que han llegado todos los datos, se pueden realizar operaciones de cálculo de la ventana (como resumen, agrupación, etc.) en todos los datos de la ventana. Si no llegan todos los datos, continúe con espere a que lleguen todos los datos de la ventana. Comience a procesar.

- Fuera de servicio puede causar problemas con varios resultados estadísticos. Por ejemplo, una ventana de tiempo debe calcular 1, 2 y 3, pero 3 es tarde, entonces las estadísticas de esta ventana perderán datos y el resultado será inexacto.
-
En este caso, debe utilizar el mecanismo de marca de agua, que puede medir el progreso del procesamiento de datos (expresar la integridad de la llegada de datos), asegurarse de que los datos del evento (todos) lleguen al sistema Flink, o cuando lleguen fuera de servicio y retrasado, también Los resultados correctos y continuos se calculan como se esperaba.
-
Cuando cualquier evento ingresa al sistema Flink, se generará una marca de tiempo de marcas de agua en función del tiempo máximo actual del evento.
-
Entonces, ¿cómo calcula Flink el valor de WaterMark?
- Marca de agua = tiempo máximo de generación de eventos que ingresan a Flink (maxEventTime) - tiempo fuera de servicio especificado (t)
-
Entonces, ¿cómo la ventana con marca de agua activa la función de ventana?
(1) marca de agua >= la hora de finalización de la ventana
(2) La ventana debe tener datos Nota: hay datos en [window_start_time, window_end_time), antes del cierre y luego del intervalo de apertura
4 Escena de la vida comprensión WaterMark
-
Los estudiantes que suelen hacer senderismo al aire libre deben saber que los equipos de senderismo suelen tener un líder y dos líderes adjuntos, un líder adjunto al frente del equipo y un líder adjunto al final del equipo Coordinación intercalada en el equipo.

-
El líder al final del equipo se llama líder del equipo de retaguardia, su responsabilidad es lograr que todos los jugadores estén al frente, es decir, el líder de la retaguardia es la cola de todo el equipo. Cuando el equipo está cerrado, si ves al líder al final del equipo, significa que todo el equipo ha llegado por completo.
-
Esto
WaterMarkes equivalente a establecer un líder posterior para todo el flujo de datos. Pero la ventana no sabe cuántos datos llegarán, por lo que solo puede establecer un límite de tiempo para adivinar si ha llegado el último dato de la ventana actual. Suponiendo que el tamaño de la ventana es de 10 segundos, la marca de agua es el tiempo máximo de generación de eventos (maxEventTime) que ingresa a Flink: el tiempo fuera de servicio especificado (t) -
A continuación hará el siguiente procesamiento
- Para cada dato, tome el mayor tiempo de ocurrencia del evento de todos los datos en la ventana actual
- Reste el tiempo fuera de servicio especificado del tiempo de ocurrencia del evento más grande
- Ver si cumple con las condiciones que activan el cálculo de cierre de ventana
- Si no, continúa ingresando los datos.
- Si es así, cierre la ventana y comience el cálculo.
-
Mira, es más como caminar al aire libre
-
Cada vez que venga una persona, pregúntale qué número tenía cuando partió, y luego confirma el mayor número de todos los jugadores que han llegado.
-
Use el número más grande para comparar con el número del líder del equipo
-
Si el número es menor que el número del líder, el equipo no será aceptado, y si el número es mayor o igual que el número del líder, ¡el equipo será aceptado! ! !
5 Tres situaciones en las que se utiliza la marca de agua
-
(1) Marca de agua en el flujo de datos secuenciales
-
En algunos casos, se ordena el flujo de datos basado en el tiempo del evento (en relación con el tiempo del evento). En un flujo ordenado, una marca de agua es simplemente un marcador periódico.
如果数据元素的事件时间是有序的,Watermark 时间戳会随着数据元素的事件时间按顺序生成,此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置乱序时间了,那么 t 就是 0。 所以 watermark= maxEventtime-0 = maxEventtime),也就是理想状态下的水位线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推, 下一个 Window 也是一样。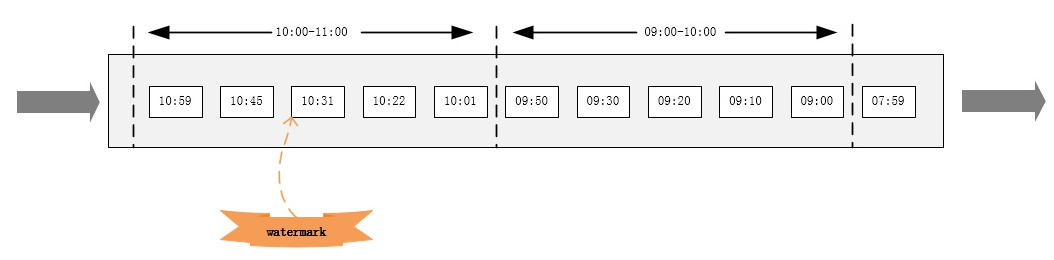
-
-
(2) Marca de agua en flujo de datos desordenado
-
En realidad, los elementos de datos a menudo no están conectados al sistema Flink para su procesamiento en el orden en que se generan, sino que llegan fuera de servicio o llegan tarde con frecuencia, lo que requiere el uso de marcas de agua para su tratamiento.
比如下图,假设窗口大小为1小时,延迟时间设为10分钟。明显,数据09:38已经迟到,但它依然会被正确计算,只有当有数据时间大于10:10的数据到达之后(即对应的watermark大于等于10:10-10min) 09:00~10:00的窗口才会执行计算。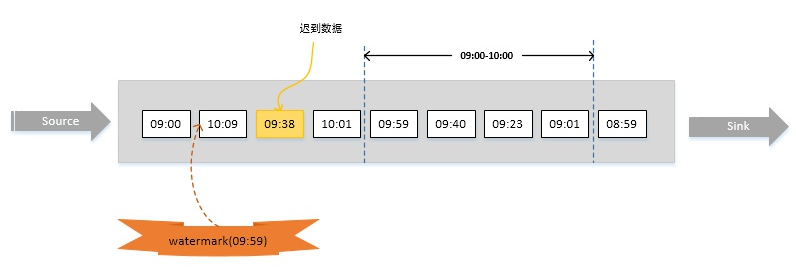
-
-
(3) Marca de agua en flujo de datos paralelo
-
Correspondiente a una tarea fuente con un paralelismo mayor a 1, cada subtarea independiente generará su propia marca de agua. Estas marcas de agua se distribuirán a los operadores intermedios junto con los datos de transmisión y sobrescribirán las marcas de agua anteriores. Cuando varias marcas de agua llegan al operador intermedio al mismo tiempo, Flink seleccionará una marca de agua más pequeña para actualizar. Cuando la marca de agua de una tarea es mayor que la hora de finalización de la ventana, la operación de la ventana se activará de inmediato.
En el caso de múltiples grados de paralelismo, Watermark tendrá un mecanismo de alineación, que tomará la marca de agua más pequeña entre todos los canales.
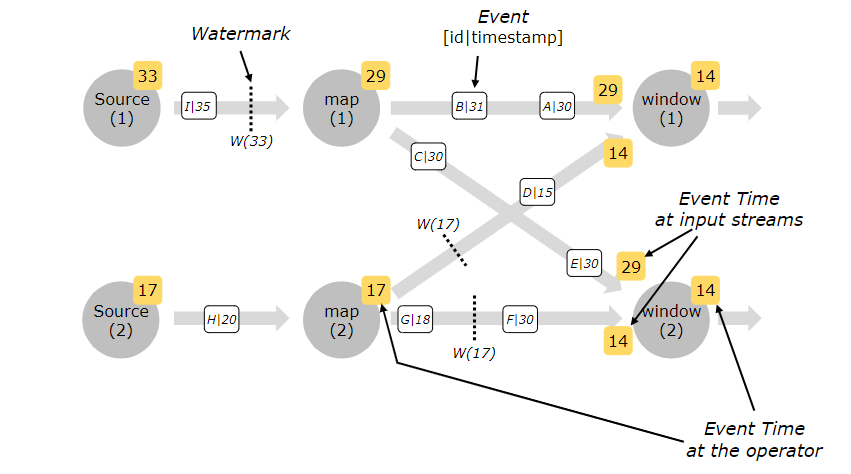
-
6. Use EventTime como tiempo de referencia para procesar datos json locales
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
public class FlinkSQLEvent {
public static void main(String[] args) {
//1.创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
//2.创建source table,这种方式会自动注册表
tEnv.executeSql("CREATE TABLE userbase ("+
" id Integer,"+
" name STRING,"+
" email STRING,"+
" date_time TIMESTAMP(3),"+
" WATERMARK FOR date_time AS date_time - INTERVAL '10' SECOND"+
") WITH ("+
" 'connector' = 'filesystem',"+
" 'path' = 'input/userbase.json',"+
" 'format' = 'json'"+
")");
//3.Flink SQL 查询
Table resultTable = tEnv.sqlQuery("select * from userbase");
resultTable.printSchema();
//4.执行Flink SQL
resultTable.execute().print();
}
}
5. Operación de ventana en Flink
Con el atributo de tiempo, podemos cooperar con la ventana para completar varios cálculos comerciales. Flink Table API/SQL proporciona una gran cantidad de operaciones de ventana.
Flink DataStream ya es compatible con Group Windows
Flink Table API/SQL también es compatible con Over Windows
concepto de ventana 5.1
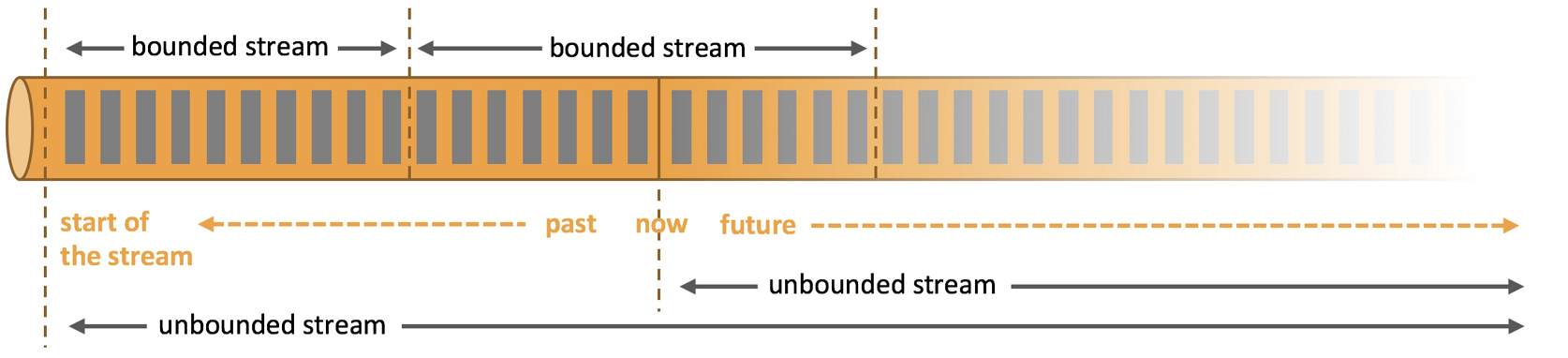
- Streaming Streaming computing es un motor de procesamiento diseñado para procesar conjuntos de datos infinitos.Un conjunto de datos infinito se refiere a un tipo de datos que crece con el tiempo, y una ventana es un medio para cortar datos infinitos en bloques finitos para su procesamiento.
- La ventana es una forma de cortar el flujo ilimitado en un flujo limitado, lo que distribuirá el flujo en cubos de tamaño limitado para el análisis.
5.2 Tipos de ventanas
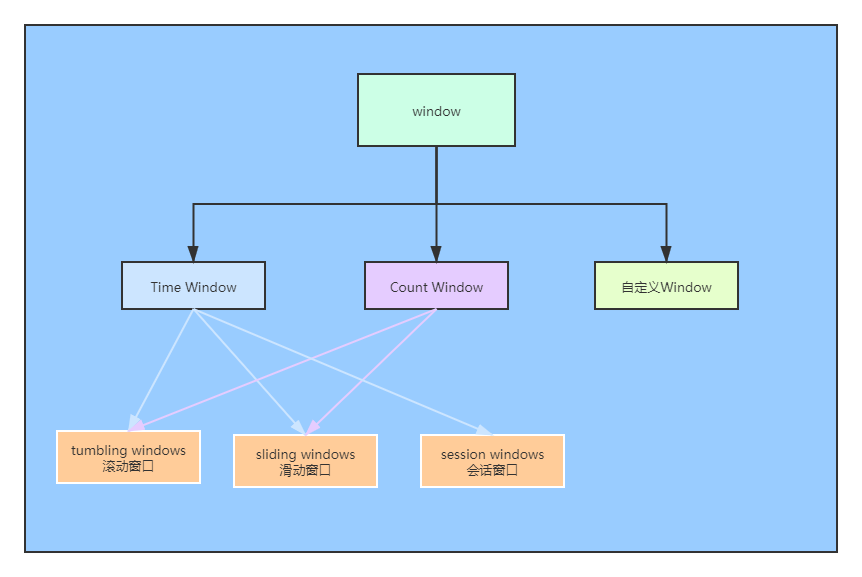
- Las ventanas se pueden dividir en dos categorías:
- Ventana de tiempo
- Ventana de tiempo: la ventana se genera de acuerdo con un tiempo determinado (por ejemplo: cada 10 segundos)
- ContarVentana
- Ventana de conteo: Generar una Ventana de acuerdo a la cantidad de datos especificada, independientemente del tiempo (por ejemplo: cada 100 elementos)
- Ventana de tiempo

- Resumen de tipos de ventanas:
5.3 Clasificación de Ventanas de Tiempo
- Para TimeWindow, se puede dividir en tres categorías según el principio de implementación de la ventana:
- Ventana Tumbling (Ventana Tumbling)
- Ventana deslizante
- Ventana de sesión
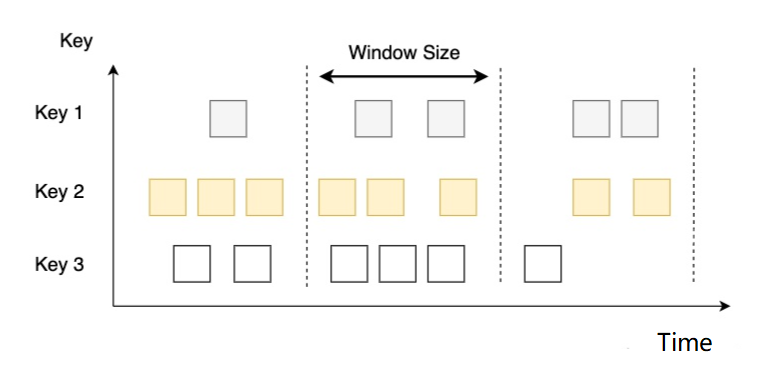
5.3.1 Ventanas giratorias
-
concepto
- Cortar los datos de acuerdo con una longitud de ventana fija
-
características
- Alineado en el tiempo, longitud de la ventana fija, sin superposición
-
Por ejemplo
- Si especifica una ventana de volteo de 5 minutos, la ventana se crea como se muestra a continuación

-
escena aplicable
- Adecuado para estadísticas de BI, etc. (cálculo de agregación para cada período de tiempo)
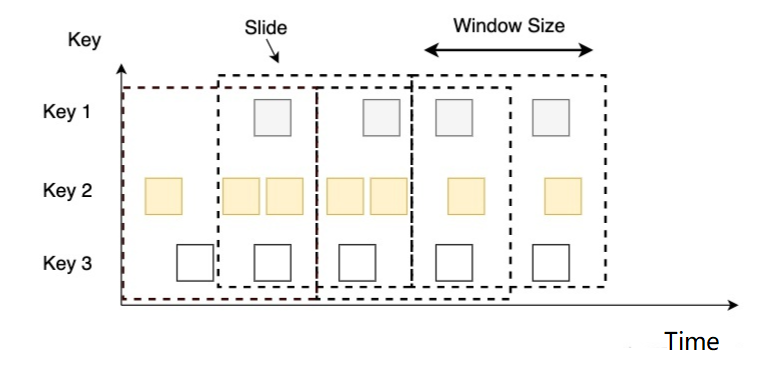
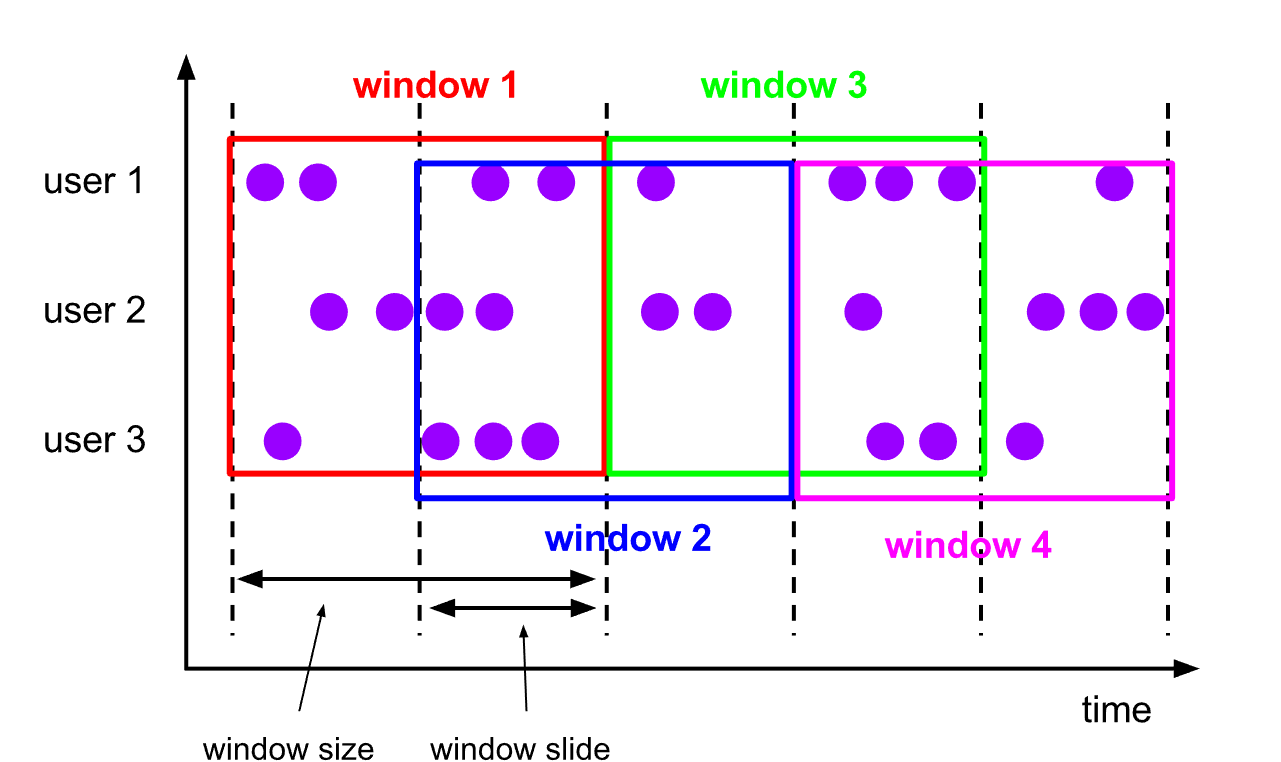
5.3.2 Ventanas corredizas
-
concepto
- Una ventana deslizante es una forma más generalizada de una ventana fija, que consta de una longitud de ventana fija y un intervalo deslizante
-
características
- Alineación de tiempo, longitud de ventana fija, puede superponerse
-
Por ejemplo
-
Tiene una ventana de 10 minutos y una diapositiva de 5 minutos, luego la ventana de 5 minutos en cada ventana contiene los datos generados en los 10 minutos anteriores, como se muestra en la figura a continuación.
-
-
escena aplicable
- Estadísticas en el último período de tiempo (encuentre la tasa de falla de una interfaz en los últimos 5 minutos para decidir si llamar a la policía)
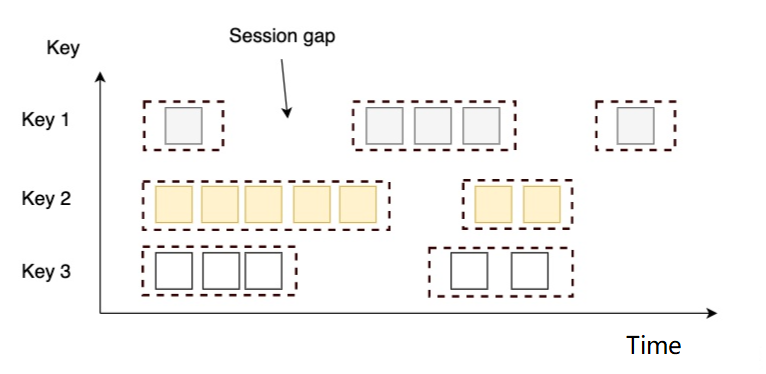
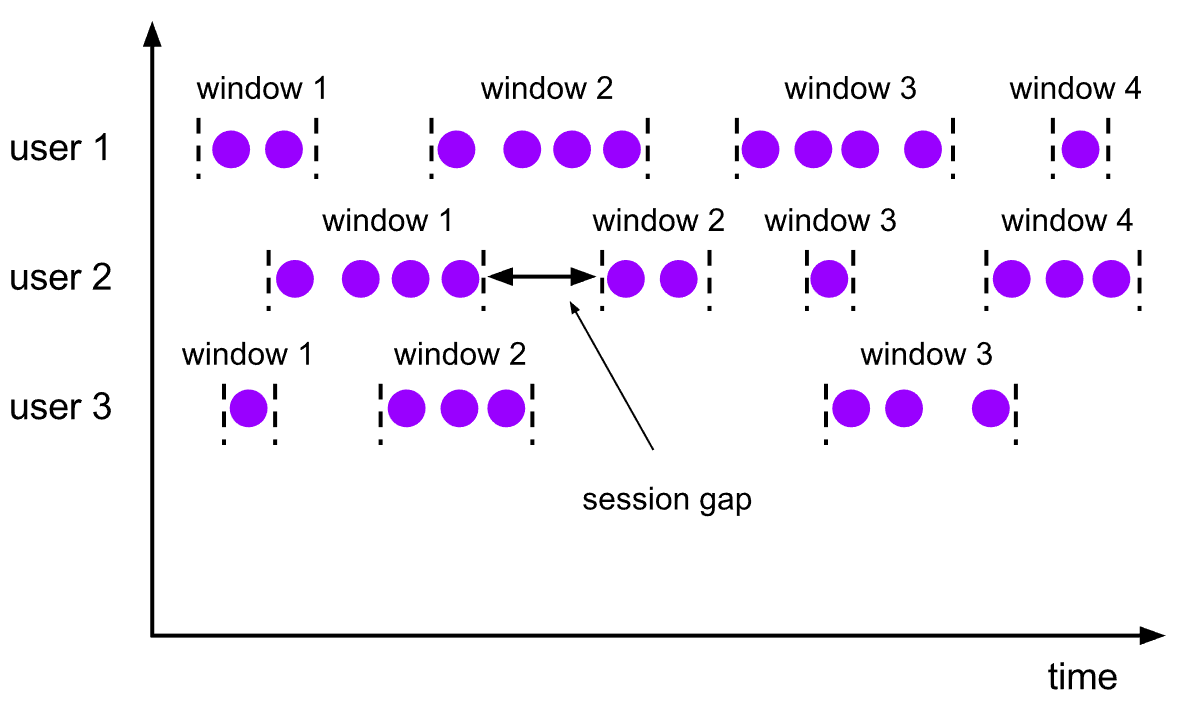
5.3.3 Ventana de sesión (ventanas de sesión)
-
concepto
- Consiste en una serie de eventos combinados con un
timeoutintervalo , similar a la sesión de una aplicación web, es decir, se generará una nueva ventana si no se reciben nuevos datos durante un período de tiempo.
- Consiste en una serie de eventos combinados con un
-
características
- El tamaño de la ventana está determinado por los datos en sí, no tiene una hora fija de inicio y finalización.
- La ventana de sesión se divide en diferentes ventanas según el intervalo de sesión, cuando una ventana no recibe nuevos datos en un tiempo superior al intervalo de sesión, la ventana se cerrará.
-
Por ejemplo
-
El intervalo de tiempo establecido es de 6 segundos, luego, cuando la diferencia entre registros adyacentes es >=6 segundos, la ventana se activará
-
-
escena aplicable
- El tiempo medio de acceso a la página de cada usuario en una sesión independiente, y el intervalo entre sesiones es de 15 minutos.
5.3.4, ventanas de grupo
El llamado grupo de ventanas (ventana de agrupación) consiste en dividir el evento en varios grupos según el tiempo o el conteo, y luego ejecutar la función de ventana en cada grupo. La ventana de grupo se divide en ventana con clave y ventana sin clave en términos de clave. , según la lógica de distribución de eventos de Window se divide en varios tipos.
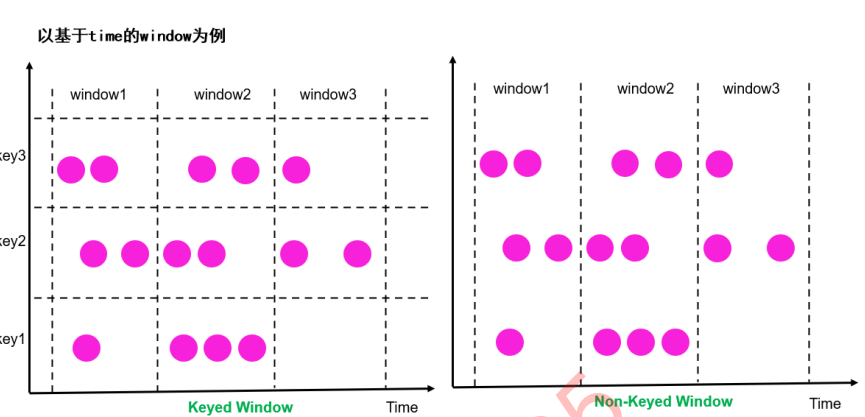
Ventana con llave y ventana sin llave
Según si se agrupa según la clave especificada (campo/atributo) primero y luego se crea la ventana en función del tiempo/recuento, la ventana de grupo se puede dividir en [ventana con clave] [ventana sin clave]
Las ventanas con llave a veces se confunden con las ventanas giratorias/deslizantes, que son diferentes capas de cosas:
| concepto | definición | |
|---|---|---|
| ventana con llave | Primero agrupe de acuerdo con la clave especificada (campo/atributo) y luego construya la ventana según el tiempo/recuento (agrupación doble) | |
| Ventana sin clave | Ventana creada directamente en función del tiempo/recuento sin agrupar por clave específica (campo/atributo) |
Nota: las ventanas también son un tipo de agrupación
5.3.5 Según la clasificación de la lógica de asignación de eventos
Ventana de tiempo: agrupar y segmentar flujos de datos según el tiempo
Ventana de tiempo de caída: Ventana de tiempo de caída
Ventana de tiempo deslizante: Ventana de tiempo deslizante
Ventana de sesión: Ventana de sesión
Ventana de conteo: agrupa y divide el flujo de datos según la cantidad de elementos
Ventana de conteo de caídas: Tumbling CountWindow
Ventana de conteo deslizante: ventana de conteo deslizante
Nota: ventana de tiempo [inicio, fin), izquierda cerrada y derecha abierta
5.4, el uso de ventanas en flinkSQL
En Flink SQL, la función Group Windows se utiliza para definir la ventana de grupo

Nota especial: FlinkSQL solo admite ventanas de agrupación basadas en el tiempo, y time_attr debe ser del tipo TIMESTAMP para el procesamiento por lotes
Además, hay algunas funciones auxiliares que se pueden usar en la cláusula de selección para consultar las marcas de tiempo de inicio y finalización de la ventana de grupo, así como los atributos de tiempo (inicio, fin, tiempo de fila, tiempo de proceso).
| función auxiliar | ilustrar |
|---|---|
| TUMBLE_START(atributo_tiempo, intervalo) HOP_START(atributo_tiempo, intervalo, intervalo) SESSION_START(atributo_tiempo, intervalo) | Devuelve la marca de tiempo de inicio de la ventana (inicio), que es la marca de tiempo del límite inferior de la ventana |
| TUMBLE_END(atributo_tiempo, intervalo) HOP_END(atributo_tiempo, intervalo, intervalo) SESSION_END(atributo_tiempo, intervalo) | Devuelve la marca de tiempo final (final) de la ventana, es decir, la marca de tiempo fuera del límite superior de la ventana que no está incluida en esta ventana atributo, como la operación de agregación de la ventana de grupo o sobre la ventana |
| TUMBLE_ROWTIME(atributo_tiempo, intervalo) HOP_ROWTIME(atributo_tiempo, intervalo, intervalo) SESSION_ROWTIME(atributo_tiempo, intervalo) | Devuelve la marca de tiempo del límite superior de la ventana en forma de tiempo de fila Nota: el resultado es el atributo de tiempo de fila, [puede] usarse para operaciones posteriores basadas en el tiempo, como la ventana de grupo o las operaciones de agregación de ventana, etc. |
| TUMBLE_PROCTIME(atributo_tiempo, intervalo) HOP_PROCTIME(atributo_tiempo, intervalo, intervalo) SESSION_PROCTIME(atributo_tiempo, intervalo) |
NOTA: La función auxiliar debe llamarse con exactamente los mismos argumentos que la función de ventana en la cláusula GROUP BY.
La sintaxis básica es la siguiente
CREATE TABLE Orders (
user BIGINT,
product STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '1' MINUTE
) WITH (...);
SELECT
user,
TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,//参数必须跟下⾯GROUP BY⼦句中的窗⼝
函数参数⼀致
SUM(amount) FROM Orders
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
user
5.4.1 Implementación de ventana móvil basada en tiempo de eventos
El contenido de datos existente es el siguiente: Indica los registros de productos comprados por diferentes usuarios. Los siguientes datos son todos los productos con un product_id de 1, que son ordenados por diferentes usuarios en diferentes momentos. La cantidad gastada es la siguiente. Use la ventana móvil en flinkSQL para calcular cada El valor máximo de la cantidad cada 2 segundos, o el valor promedio,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
Defina el objeto javaBean de la siguiente manera
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UserProduct {
private Integer product_id;
private String buyer_name;
private Long date_time;
private Double price;
}
Inicie el servicio de socket, luego escriba los datos anteriores en el socket y realice el procesamiento de datos a través del programa FlinkSQL
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLTumbEvtWindowTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
//4.流转换为动态表
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),$("buyer_name"),$("price"),$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price),"+
"TUMBLE_START(date_time,INTERVAL '5' second) as winstart "+
"from "+table+" GROUP BY product_id,TUMBLE(date_time,INTERVAL '5' second) ");
//6.执行Flink
resultTable.execute().print();
}
}
5.4.2 Implementación de ventana deslizante basada en Event-time
El contenido de los datos existentes es el siguiente: Indica los registros de productos comprados por diferentes usuarios. Los siguientes datos son todos los productos con un product_id de 1, que son pedidos por diferentes usuarios en diferentes momentos. La cantidad gastada es la siguiente. Use la ventana deslizante en flinkSQL para calcular cada El valor máximo de la cantidad cada 2 segundos, o el valor promedio,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
Inicie el servicio de socket, luego escriba los datos anteriores en el socket y realice el procesamiento de datos a través del programa FlinkSQL
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLSlideWindowEvtTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Schema schema = Schema.newBuilder()
.column("product_id", "bigint")
.column("buyer_name", "String")
.column("date_time", "Long")
.column("price", "double")
.build();
Table table = tEnv.fromDataStream(userProductDataStream, $("product_id"),$("buyer_name"),$("price"),$("date_time").rowtime());
Table resulTable = tEnv.sqlQuery("select product_id,max(price), HOP_START(date_time ,INTERVAL '2' second,INTERVAL '4' second ) " +
"as winstart from " + table +
" group by product_id, HOP(date_time, INTERVAL '2' second, INTERVAL '4' second) ");
resulTable.execute().print();
}
}
5.4.3 Implementación de la ventana de sesión basada en Event_time
El contenido de datos existente es el siguiente: Indica los registros de productos comprados por diferentes usuarios. Los siguientes datos son todos los productos con un product_id de 1, que son pedidos por diferentes usuarios en diferentes momentos. La cantidad gastada es la siguiente. Use la ventana de sesión en flinkSQL para calcular cada El valor máximo de la cantidad cada 2 segundos, o el valor promedio,
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
Inicie el servicio de socket, luego escriba los datos anteriores en el socket y realice el procesamiento de datos a través del programa FlinkSQL
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLSessionWindowEvtTime {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
Table resulTable = tEnv.sqlQuery("select product_id,max(price),SESSION_START( date_time,INTERVAL '5' second ) as winstart from " + table + " group by product_id, SESSION(date_time , INTERVAL '5' second )");
resulTable.execute().print();
}
}
5.4.4 La ventana Over utiliza un valor preespecificado basado en el tiempo
Los agregados Over Window ya están presentes en SQL estándar (la cláusula Over) y se pueden definir en la cláusula SELECT de una consulta. La agregación sobre ventana, para cada fila de entrada, calcula la agregación en el rango de filas adyacentes. Las ventanas superiores se definen mediante la cláusula .window(w:overwindows*) y se hace referencia a ellas mediante un alias en el método select(). ejemplo:
val table = input.window([w: OverWindow] as 'w).select('a, 'b.sum over 'w, 'c.min over 'w)
Table API proporciona la clase Over para configurar las propiedades de la ventana Over. Las ventanas adicionales se pueden definir en tiempo de evento o tiempo de procesamiento, y en rangos especificados como intervalos de tiempo o recuentos de filas.
Una ventana superior ilimitada se especifica mediante una constante. Es decir, se especifica un intervalo de tiempo UNBOUNDED_RANGEo se especifica un intervalo de recuento de filas UNBOUNDED_ROW. Una ventana delimitada se especifica por el tamaño del intervalo.
// 无界的事件时间
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)//无界的处理时间
over window (时间字段"proctime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)// 无界的事件时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)//无界的处理时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
Use la ventana Over para ordenar por tiempo de evento limitado a == los primeros 5 segundos para abrir la ventana == para encontrar la cantidad máxima y la cantidad promedio
El formato de datos es el siguiente
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLOverWinEvTimeRange {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price) OVER w AS max_price,"+
"avg(price) OVER w AS avg_price "+
"from "+table+" WINDOW w AS (\n" +
" PARTITION BY product_id\n" +
" ORDER BY date_time\n" +
" RANGE BETWEEN INTERVAL '5' second PRECEDING AND CURRENT ROW) \n");
//6.执行Flink
resultTable.execute().print();
}
}
5.4.4 La ventana Over usa una preposición basada en el número de elementos de datos
Los agregados Over Window ya están presentes en SQL estándar (la cláusula Over) y se pueden definir en la cláusula SELECT de una consulta. La agregación sobre ventana, para cada fila de entrada, calcula la agregación en el rango de filas adyacentes. Las ventanas superiores se definen mediante la cláusula .window(w:overwindows*) y se hace referencia a ellas mediante un alias en el método select(). ejemplo:
val table = input.window([w: OverWindow] as 'w).select('a, 'b.sum over 'w, 'c.min over 'w)
Table API proporciona la clase Over para configurar las propiedades de la ventana Over. Las ventanas adicionales se pueden definir en tiempo de evento o tiempo de procesamiento, y en rangos especificados como intervalos de tiempo o recuentos de filas.
Una ventana superior ilimitada se especifica mediante una constante. Es decir, se especifica un intervalo de tiempo UNBOUNDED_RANGEo se especifica un intervalo de recuento de filas UNBOUNDED_ROW. Una ventana delimitada se especifica por el tamaño del intervalo.
// 无界的事件时间
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)//无界的处理时间
over window (时间字段"proctime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)// 无界的事件时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)//无界的处理时间 Row-count
over window (时间字段 "rowtime").window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
Use la ventana Over para ordenar por límite de tiempo de evento == los primeros 3 datos ==, encuentre la cantidad máxima y la cantidad promedio
El formato de datos es el siguiente
product_id,buyer_name,date_time,price
1,郑剃,1664841620,68
1,闾丘喜造,1664841622,75
1,王曙介,1664841624,84
1,赖溯姆,1664841626,56
1,钱泼奎,1664841628,74
1,尉迟亏,1664841630,35
1,贾盏,1664841632,53
1,蔡辟,1664841634,45
1,蔡矛,1664841636,38
1,赖妖炬,1664841638,89
1,毛溜孝,1664841640,45
1,邵省充,1664841642,42
1,邓瑟冕,1664841644,68
1,史符先,1664841646,66
1,钟驯,1664841648,80
import cn.flink.bean.UserProduct;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkSQLOverWinEvRowRange {
public static void main(String[] args) {
StreamExecutionEnvironment senv= StreamExecutionEnvironment.getExecutionEnvironment();
senv.setParallelism(1);
//2.创建表执行环境
StreamTableEnvironment tEnv = StreamTableEnvironment.create(senv);
//3.读取数据
WatermarkStrategy<UserProduct> watermarkStrategy = WatermarkStrategy
.<UserProduct>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<UserProduct>() {
@Override
public long extractTimestamp(UserProduct t, long l) {
return t.getDate_time() * 1000;
}
});
DataStream<UserProduct> userProductDataStream=senv.socketTextStream("bigdata01",9999)
.map(event -> {
String[] arr = event.split(",");
return UserProduct.builder()
.product_id(Integer.parseInt(arr[0]))
.buyer_name(arr[1])
.date_time(Long.valueOf(arr[2]))
.price(Double.valueOf(arr[3]))
.build();
}).assignTimestampsAndWatermarks(watermarkStrategy);
Table table = tEnv.fromDataStream(userProductDataStream,
$("product_id"),
$("buyer_name"),
$("price"),
$("date_time").rowtime());
//5.自定义窗口并计算
Table resultTable = tEnv.sqlQuery("select "+
"product_id,"+
"max(price) OVER w AS max_price,"+
"avg(price) OVER w AS avg_price "+
"from "+table+" WINDOW w AS (\n" +
" PARTITION BY product_id\n" +
" ORDER BY date_time\n" +
" ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) \n");
//6.执行Flink
resultTable.execute().print();
}
}
6. Funciones en FlinkSQL
FlinkSQL también tiene una gran cantidad de funciones integradas. Usamos SQL principalmente para usar varias funciones. Aquí le daremos una introducción unificada a las funciones integradas y funciones personalizadas.
6.1 Descripción general de las funciones integradas
Flink Table API/SQL proporciona una gran cantidad de funciones integradas, que puede usar como una búsqueda de diccionario:
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/functions/systemfunctions/

6.2, función personalizada FlinkSQL
Además de las funciones integradas anteriores, también hay funciones personalizadas en flinkSQL. A continuación, echemos un vistazo a cómo implementar las funciones personalizadas de FlinkSQL.
Clasificación de funciones personalizadas
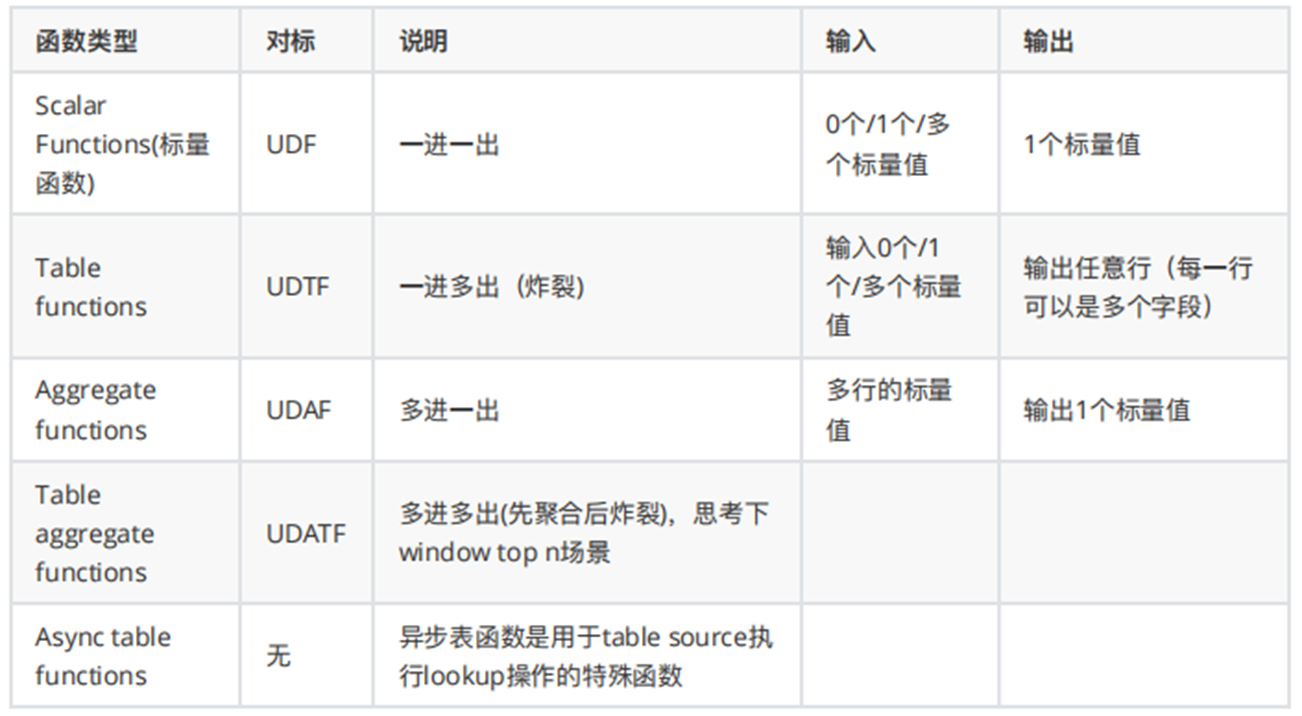
En Hive, hay varias funciones personalizadas como UDF, UDAF y UDTF, pero estos conceptos se simplifican en FlinkSQL, que están representados por funciones escalares, Tabel Function y Aggregate Function.La siguiente tabla identifica varias funciones en flinkSQL
6.2.1 Método de llamada de función personalizada
Cómo usar las funciones personalizadas de FlinkSQL:
Se puede llamar en línea a través de la función de llamada

6.2.2, implementación de funciones personalizadas de FlinkSQL
Si necesita una función personalizada, primero debe heredar la clase base correspondiente, como ScalarFunction, y esta clase debe declararse como pública, no abstracta y accesible globalmente. Por lo tanto, no se permiten clases internas no estáticas o clases anónimas. Debe haber un constructor predeterminado (porque Flink debe ser instanciado y registrado en el catálogo)
Debe proporcionar un método de evaluación público con parámetros bien definidos (sobrecargable, varargs, herencia)

6.2.3, método de apertura y cierre de inicialización al final
Los métodos de apertura y cierre de la clase base de UDF se pueden anular para personalizar la lógica de inicialización y limpieza de UDF, respectivamente. En el método abierto, proporcione el parámetro FunctionContext, a través del cual se puede obtener información diversa sobre el entorno Runtime:

6.3, función personalizada FlinkSQL uno dentro y otro UDF de combate real
El análisis json se realiza a través de la función personalizada ScalarFunction en FlinkSQL, y el valor del campo de valor correspondiente a json se obtiene al pasar la clave de json
El contenido del formato de datos json es el siguiente
{"date_time":"2022-10-04 08:01:48","email":"[email protected]","id":0,"name":"郑剃"}
{"date_time":"2022-10-04 08:06:31","email":"[email protected]","id":1,"name":"闾丘喜造"}
{"date_time":"2022-10-04 08:04:39","email":"[email protected]","id":2,"name":"王曙介"}
{"date_time":"2022-10-04 08:00:19","email":"[email protected]","id":3,"name":"赖溯姆"}
Definir la función de análisis json
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public class JsonParseFunction extends ScalarFunction {
@Override
public void open(FunctionContext context) throws Exception {
}
public String eval(String jsonLine,String key){
JSONObject jsonObject = JSONObject.parseObject(jsonLine);
if(jsonObject.containsKey(key)){
return jsonObject.getString(key);
}else{
return "";
}
}
@Override
public void close() throws Exception {
}
}
El código se implementa de la siguiente manera:
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
public class FlinkSQLScalarFunction {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
tableEnvironment.createTemporarySystemFunction("JsonParse",JsonParseFunction.class);
String source_sql = "CREATE TABLE json_table (\n" +
" line STRING \n" +
") WITH (\n" +
" 'connector'='filesystem',\n" +
" 'path'='input/userbase.json',\n" +
" 'format'='raw'\n" +
")";
tableEnvironment.executeSql(source_sql);
tableEnvironment.sqlQuery("select * from json_table").execute().print();
tableEnvironment.sqlQuery("select JsonParse(line,'date_time'),JsonParse(line,'email'),JsonParse(line,'id'),JsonParse(line,'name') from json_table")
.execute().print();
}
}
6.4, función personalizada FlinkSQL una entrada y salida múltiple UDTF de combate real
También podemos personalizar la función para darnos cuenta de que después de que ingresa un dato, se emiten varios datos, lo cual es similar a la función de explosión.
Las funciones de tabla (funciones de tabla) tienen una entrada y varias salidas (ráfagas), heredan TableFunction, proporcionan un método de evaluación sin valor de retorno y usan recopilar para generar.
El valor de retorno de las funciones de tabla es una tabla, que debe unirse con la tabla original para obtener el resultado final, por lo que se usa una tabla de perfil (si no lo entiende, puede
Para estudiar bajo MESA LATERAL)
El contenido de datos json existente es el siguiente: userBaseList es una matriz que almacena información de varios usuarios y utiliza la función personalizada UDTF para analizar la información de cada usuario.
{"date_time":1665145907806,"price":258.7,"productId":920956185,"userBaseList":[{"begin_time":"2022-10-07 08:38:31","email":"[email protected]","id":"0","name":"尹修彻"},{"begin_time":"2022-10-07 08:33:59","email":"[email protected]","id":"1","name":"萧幅括"},{"begin_time":"2022-10-07 08:37:40","email":"[email protected]","id":"2","name":"胡乘"},{"begin_time":"2022-10-07 08:38:05","email":"[email protected]","id":"3","name":"黄煎"},{"begin_time":"2022-10-07 08:37:12","email":"[email protected]","id":"4","name":"袁肇"}]}
{"date_time":1665145918652,"price":258.7,"productId":-786075263,"userBaseList":[{"begin_time":"2022-10-07 08:39:47","email":"[email protected]","id":"0","name":"程痢"},{"begin_time":"2022-10-07 08:32:03","email":"[email protected]","id":"1","name":"程盐殃"},{"begin_time":"2022-10-07 08:40:17","email":"[email protected]","id":"2","name":"蔡锻"},{"begin_time":"2022-10-07 08:35:24","email":"[email protected]","id":"3","name":"李猎甩"},{"begin_time":"2022-10-07 08:33:05","email":"[email protected]","id":"4","name":"夏焙匈"}]}
{"date_time":1665145927285,"price":258.7,"productId":-988723330,"userBaseList":[{"begin_time":"2022-10-07 08:37:04","email":"[email protected]","id":"0","name":"郝疯框"},{"begin_time":"2022-10-07 08:40:20","email":"[email protected]","id":"1","name":"万侨"},{"begin_time":"2022-10-07 08:33:52","email":"[email protected]","id":"2","name":"侯临迸"},{"begin_time":"2022-10-07 08:33:05","email":"[email protected]","id":"3","name":"闾丘耘"},{"begin_time":"2022-10-07 08:34:26","email":"[email protected]","id":"4","name":"皇甫坡"}]}
El código se implementa de la siguiente manera
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.json.JSONArray;
import org.json.JSONObject;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public class FlinkSQLTableFunction {
public static void main(String[] args) {
Logger.getLogger("org").setLevel(Level.ERROR);
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
tableEnvironment.createTemporarySystemFunction("JsonFunc",JsonFunction.class);
tableEnvironment.createTemporarySystemFunction("explodeFunc",ExplodeFunc.class);
String source_sql = "CREATE TABLE json_table (\n" +
" line STRING \n" +
") WITH (\n" +
" 'connector'='filesystem',\n" +
" 'path'='input/product_user.json',\n" +
" 'format'='raw'\n" +
")";
tableEnvironment.executeSql(source_sql);
//方式一:使用TableAPI通过内连接来实现
tableEnvironment.from("json_table")
.joinLateral(call(ExplodeFunc.class,$("line"),"userBaseList")
.as("id","name","begin_time","email"))
.select(call(JsonFunction.class,$("line"),"date_time"),
call(JsonFunction.class,$("line"),"price"),
call(JsonFunction.class,$("line"),"productId"),
$("id"),
$("name"),
$("begin_time"),
$("email")
).execute().print();
//方式二:使用TableAPI通过左外连接来实现
tableEnvironment.from("json_table")
.leftOuterJoinLateral(call(ExplodeFunc.class,$("line"),"userBaseList")
.as("id","name","begin_time","email"))
.select(call(JsonFunction.class,$("line"),"date_time"),
call(JsonFunction.class,$("line"),"price"),
call(JsonFunction.class,$("line"),"productId"),
$("id"),
$("name"),
$("begin_time"),
$("email")
).execute().print();
//方式三:使用FlinkSQL内连接来实现
tableEnvironment.sqlQuery("select " +
"JsonFunc(line,'date_time')," +
"JsonFunc(line,'price')," +
"JsonFunc(line,'productId')," +
"id," +
"name," +
"begin_time " +
"email " +
" from json_table " +
",lateral table(explodeFunc(line,'userBaseList')) "
).execute().print();
//方式四:使用FlinkSQL左外连接来实现
tableEnvironment.sqlQuery("select " +
"JsonFunc(line,'date_time') as date_time," +
"JsonFunc(line,'price') as price ," +
"JsonFunc(line,'productId') as productId," +
"id," +
"name," +
"begin_time " +
"email " +
" from json_table left join lateral table (explodeFunc(line,'userBaseList')) as sc(id,name,begin_time,email) on true"
).execute().print();
}
/**
* 自定义udf
*/
public static class JsonFunction extends ScalarFunction {
public String eval(String line,String key){
//转换为JSON
JSONObject baseJson = new JSONObject(line);
String value = "";
if(baseJson.has(key)){
//根据key获取value
return baseJson.getString(key);
}
return value;
}
}
/**
* 自定义UDTF
*/
@FunctionHint(output = @DataTypeHint("ROW<id String,name String,begin_time String,email String>"))
public static class ExplodeFunc extends TableFunction {
public void eval(String line,String key){
JSONObject jsonObject = new JSONObject(line);
JSONArray jsonArray = new JSONArray(jsonObject.getString(key));
for(int i = 0;i< jsonArray.length();i++){
String date_time = jsonArray.getJSONObject(i).getString("begin_time");
String email = jsonArray.getJSONObject(i).getString("email");
String id = jsonArray.getJSONObject(i).getString("id");
String name = jsonArray.getJSONObject(i).getString("name");
collect(Row.of(id,name,date_time,email));
}
}
}
}
6.5 La función personalizada de FlinkSQL realiza múltiples entradas y una salida UDAF
Las funciones agregadas (funciones agregadas) asignan valores escalares de varias filas a nuevos valores escalares (múltiples entradas y una salida). Las funciones agregadas usan acumuladores. La siguiente figura muestra el proceso de agregación:
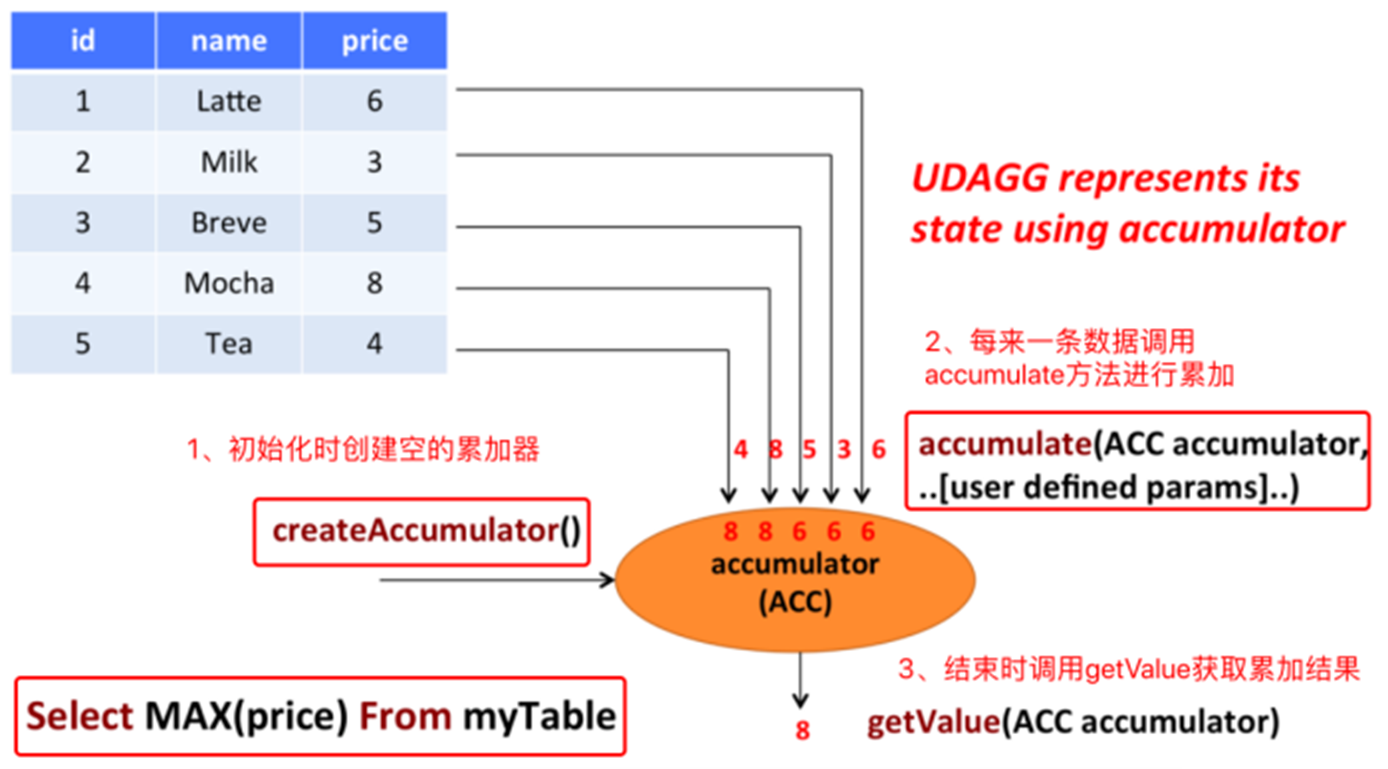
Las funciones agregadas (funciones agregadas) asignan valores escalares de varias filas a nuevos valores escalares (múltiples entradas y una salida). Las funciones agregadas usan acumuladores. La siguiente figura muestra el proceso de agregación:
Heredar función agregada
debe anular createAccumulator y getValue
Proporcione el método de acumulación
El método de retracción solo es necesario en las ventanas OVER
Se requieren tanto la agregación limitada de fusión como la ventana de sesión y la agregación de ventana deslizante (también es bueno para la optimización del rendimiento)
Requisito: use una función UDAF personalizada para encontrar el puntaje promedio de cada curso
El contenido de datos CSV existente es el siguiente
1,zhangsan,Chinese,80
1,zhangsan,Math,76
1,zhangsan,Science,84
1,zhangsan,Art,90
2,lisi,Chinese,60
2,lisi,Math,78
2,lisi,Science,86
2,lisi,Art,88
El código se implementa de la siguiente manera
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.functions.AggregateFunction;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public class FlinkUdafAggregrate {
public static void main(String[] args) {
//1、创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
//.useBlinkPlanner()//Flink1.14开始就删除了其他的执行器了,只保留了BlinkPlanner,默认就是
//.inStreamingMode()//默认就是StreamingMode
//.inBatchMode()
.build();
TableEnvironment tableEnvironment = TableEnvironment.create(settings);
//注册函数
tableEnvironment.createTemporarySystemFunction("AvgFunc",AvgFunc.class);
String source_sql = "CREATE TABLE source_score (\n" +
" id int,\n" +
" name STRING,\n" +
" course STRING,\n" +
" score Double" +
") WITH ( \n " +
" 'connector' = 'filesystem',\n" +
" 'path' = 'input/score.csv' , \n" +
" 'format' = 'csv'\n" +
")";
//创建表
tableEnvironment.executeSql(source_sql);
tableEnvironment.from("source_score")
.groupBy($("course"))
.select($("course"),call("AvgFunc",$("score").as("avg_score")))
.execute().print();
tableEnvironment.executeSql("select course,AvgFunc(score) as avg_score from source_score group by course")
.print();
}
public static class AvgFunc extends AggregateFunction<Double,AvgAccumulator> {
@Override
public Double getValue(AvgAccumulator avgAccumulator) {
if(avgAccumulator.count==0){
return null;
}else {
return avgAccumulator.sum/avgAccumulator.count;
}
}
//初始化累加器
@Override
public AvgAccumulator createAccumulator() {
return new AvgAccumulator();
}
//迭代累加
public void accumulate(AvgAccumulator acc,Double score){
acc.setSum(acc.sum+score);
acc.setCount(acc.count+1);
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class AvgAccumulator {
public double sum = 0.0;
public int count = 0;
}
}