이전 글에서는 연관 규칙 마이닝 알고리즘 Apriori를 통해 구현할 수 있는 추천 시스템인 ARL(Association Rule Learning)을 소개했는데, 오늘은 콘텐츠 기반 필터링을 통해 추천 시스템을 구현하는 방법에 대해 알아보겠습니다.
콘텐츠 기반 필터링은 추천 시스템으로 사용되는 일반적으로 사용되는 또 다른 방법 중 하나입니다. 콘텐츠 유사성은 사용자가 과거에 구매한 제품과 가장 유사한 권장 사항을 공식화할 수 있는 옵션을 제공하는 제품 메타데이터를 기반으로 계산됩니다.
메타데이터는 제품/서비스의 특성을 나타냅니다. 예를 들어, 영화의 감독, 배우, 각본가, 작가, 뒷표지 기사, 도서 번역가, 제품 카테고리 정보 등이 있습니다. ( 왜 내가 외국 데이터를 사용하는지 묻지 마세요 )

이 이미지에는 사용자가 좋아하는 영화에 대한 설명이 포함되어 있습니다. 사용자가 좋아하는 영화를 기반으로 영화를 추천하려면 이러한 설명을 사용하여 수학적 형식, 즉 텍스트를 측정할 수 있어야 하며 다른 영화와 비교하여 유사한 설명을 찾아야 합니다.
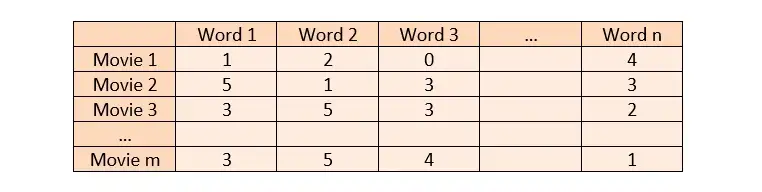
우리는 다양한 영화와 그 영화에 대한 데이터를 가지고 있습니다. 이러한 영화 데이터를 비교할 수 있으려면 데이터를 벡터화해야 합니다. 이러한 설명을 벡터화할 때 모든 영화 설명(n이라고 하자)과 모든 영화(m이라고 하자)에 걸쳐 고유한 단어의 행렬을 생성해야 합니다. 나는 열에 있는 모든 고유한 단어, 행에 있는 모든 영화, 교차로에 있는 영화에서 각 단어가 얼마나 많이 사용되었는지를 가지고 있습니다. 이런 식으로 텍스트를 벡터화할 수 있습니다.
콘텐츠 기반 필터링 단계:
- 텍스트를 수학적으로 표현(텍스트 벡터화):
- 카운트 벡터
- 태스크 포스 - IDF
2. 유사도 계산
1. 텍스트 벡터화
텍스트 벡터화는 텍스트 처리, 텍스트 마이닝 및 자연어 처리를 기반으로 하는 가장 중요한 단계입니다. 텍스트를 벡터로 변환하고 유사성 거리를 계산하는 것과 같은 방법은 데이터 분석의 기초를 형성합니다. 텍스트를 벡터로 표현할 수 있으면 수학 연산을 수행할 수 있습니다.
텍스트를 벡터로 나타내는 두 가지 일반적인 방법은 벡터 계산과 TF-IDF입니다.
- 카운트 벡터:
- 1단계 : 모든 고유 용어는 열에 배치되고 모든 문서는 행에 배치됩니다.

- 2단계 : 문서에서 용어의 빈도를 교차점의 셀에 배치합니다.

- TF-IDF:
TF-IDF는 텍스트와 전체 말뭉치(우리가 관심을 갖는 데이터) 모두에서 단어 빈도에 대해 정규화 프로세스를 수행합니다. 즉, 문서-용어 행렬, 전체 말뭉치, 모든 문서 및 용어의 빈도를 고려하여 우리가 생성할 단어 벡터의 일반적인 정규화를 수행합니다. 이렇게 하면 카운트 벡터로 인한 편향이 일부 제거됩니다.
- 1단계 : 카운트 벡터라이저 계산(각 문서에서 각 단어의 빈도)

- 2단계 : TF(Term Frequency) 계산
(관련 문서의 용어 t 빈도) / (문서의 총 용어 수)

- 3단계 : IDF(역 문서 빈도) 계산
1 + loge((문서 수 + 1) / (용어 t를 포함하는 문서 수 + 1))
총 샘플 확인 파일: 4

단어 t가 전체 말뭉치에서 자주 나타난다면 관련 단어가 전체 말뭉치에 영향을 미쳤음을 의미합니다. 이 경우 용어와 말뭉치 통과 빈도에 대해 정규화가 수행됩니다.
- 4단계 : TF * IDF 계산

- 5단계 : L2 정규화
행 제곱합의 제곱근을 찾고 해당 셀을 찾은 값으로 나눕니다.
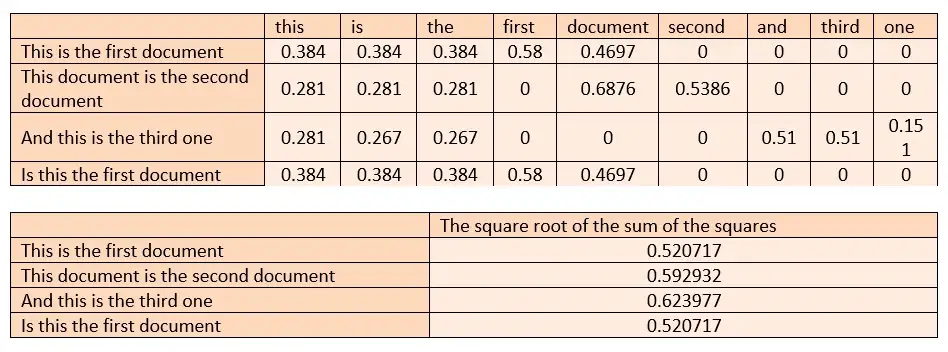
L2 정규화는 일부 행에 누락된 값이 있어 그 효과를 표시할 수 없는 단어를 다시 수정합니다.
2. 유사도 계산
설명에 n개의 고유 단어가 있는 m개의 영화가 있다고 가정합니다. 이러한 영화에 대한 콘텐츠 기반 유사성을 프로그래밍 방식으로 찾기 전에 실제로 이를 수행하는 방법을 살펴보겠습니다.
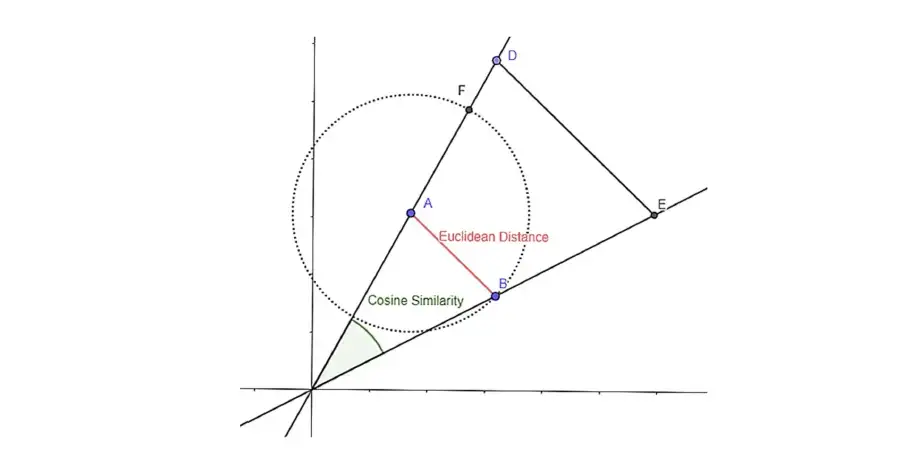
유클리드 거리 또는 코사인 유사성을 사용하여 벡터화된 영화의 유사성을 찾을 수 있습니다.
- 유클리드 거리 :
유클리드 거리를 계산하면 두 영화 사이의 유사성을 나타내는 거리 값을 얻을 수 있다. 거리가 멀어질수록 유사도가 높아짐을 알 수 있다. 이런 식으로 추천 프로세스를 수행할 수 있습니다.
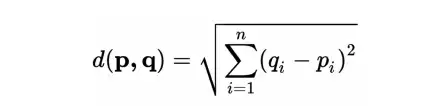
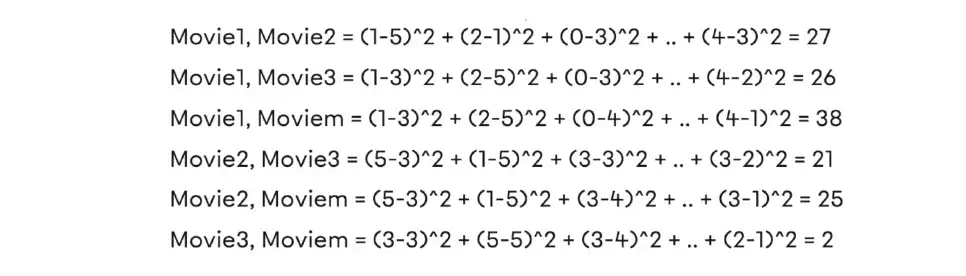
- 코사인 유사도:
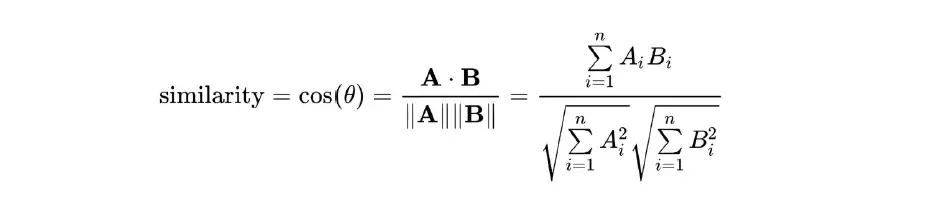
유클리드에는 거리 개념이 있고 코사인 유사도에는 유사도 개념이 있습니다. 거리 근접성과 유사성 비 유사성은 여기서 동일한 개념에 해당합니다.
콘텐츠 기반 필터링의 논리를 소개했으므로 이제 콘텐츠 기반 필터링 권장 사항을 자세히 살펴볼 수 있습니다.
질문:
새로 설립된 온라인 영화 플랫폼에서 사용자에게 영화를 추천하려고 합니다. 사용자의 로그인 비율이 매우 낮기 때문에 사용자의 습관을 알 수 없습니다. 그러나 사용자가 본 영화에 대한 정보는 브라우저의 이동 경로에서 액세스할 수 있습니다. 이러한 정보를 바탕으로 사용자에게 영화를 추천하는 것이 바람직하다.
데이터세트 정보:
기본 영화 메타데이터 파일입니다. Full MovieLens 데이터 세트의 45,000개 영화에 대한 정보를 포함합니다. 기능에는 포스터, 배경, 예산, 수익, 출시 날짜, 언어, 생산 국가 및 회사가 포함됩니다.
여기에서 데이터 세트에 액세스 할 수 있습니다 . 상세 코드 주소
TF-ID 매트릭스를 만듭니다.
프로젝트 시작 시 필요한 라이브러리를 가져오고 데이터 세트를 읽습니다.
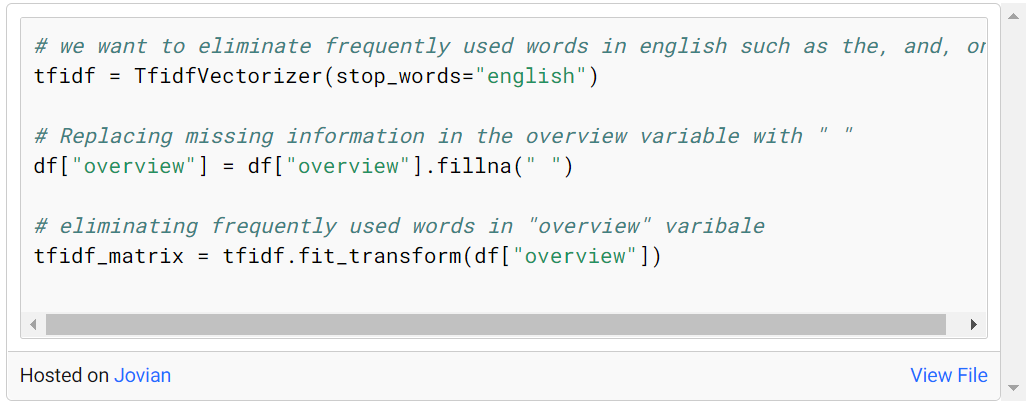
여기서 적용할 첫 번째 절차는 TF-IDF 방법을 사용하는 것이다. 이를 위해 프로젝트 초기에 가져온 TfidfVectorizer의 메소드를 호출합니다. stop_words='english' 매개변수를 입력하여 측량 없이 언어에서 일반적으로 사용되는 단어(및 the, at, on 등)를 제거합니다. 그 이유는 생성할 TF-IDF 행렬에 희소 값이 있어서 발생하는 문제를 피하기 위함입니다.
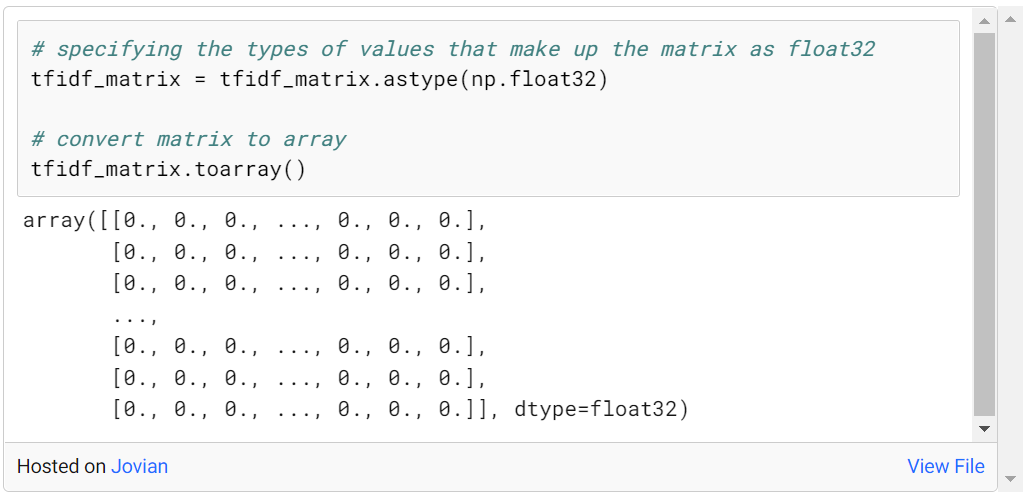
tfidf_matrix의 모양은 (45466, 75827)이며, 여기서 45466은 오버뷰의 개수이고 75827은 고유한 단어의 개수입니다. 이 크기의 데이터로 더 나은 진행을 할 수 있도록 tfidf_matrix 교차점의 값을 float32로 타입 변환하고 그에 따라 처리합니다.
이제 tfidf_matrix의 교차점에 점수가 있으므로 이제 코사인 유사성 매트릭스를 구축하고 영화 간의 유사성을 관찰할 수 있습니다.
코사인 유사성 행렬을 만듭니다.
프로젝트 초기에 가져온 cosine_similarity 메서드를 사용하여 각 영화와 다른 영화의 유사성 값을 찾습니다.

예를 들어, 다음과 같이 다른 모든 영화에 대한 첫 번째 인덱스에서 영화의 유사성 점수를 찾을 수 있습니다.
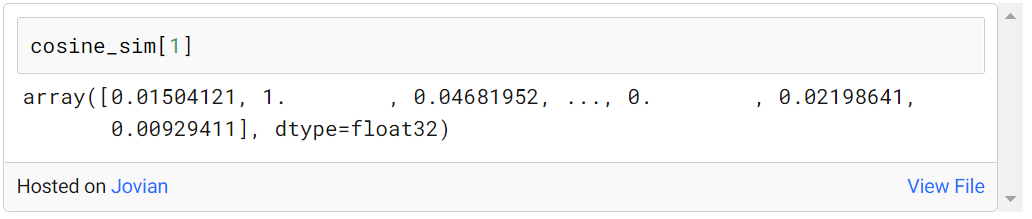
유사성에 기반한 제안:
유사도는 코사인 유사도를 사용하여 계산되지만 이 점수를 평가하려면 영화 제목이 필요합니다. 이를 위해 인덱스가 indices = pd.Series(df.index, index=df[‘title’]).
다음과 같이 일부 영화에서 다중화가 관찰되었습니다.
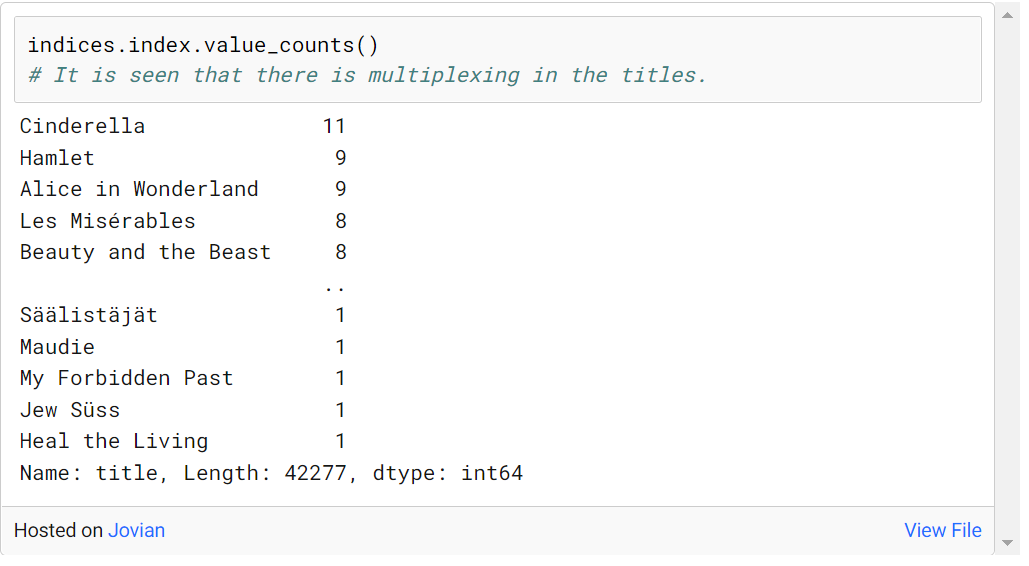
우리는 이러한 배수 중 하나를 유지하고 나머지는 제거하여 가장 최근 날짜에 이러한 배수 중 가장 최근을 가져와야 합니다. 이것은 다음과 같이 할 수 있습니다:

연산 결과, 각각의 타이틀이 단일 인덱스 정보를 통해 단일화되고 접근 가능함을 관찰할 수 있다.
Sherlock Holmes와 유사한 10개의 영화를 찾고 싶다고 가정해 보겠습니다. 먼저 cosine_sim에 Sherlock Holmes 인덱스 정보를 입력하여 Sherlock Holmes 영화를 선택하고 이 영화와 다른 영화의 유사도 관계를 나타내는 점수에 접근합니다.
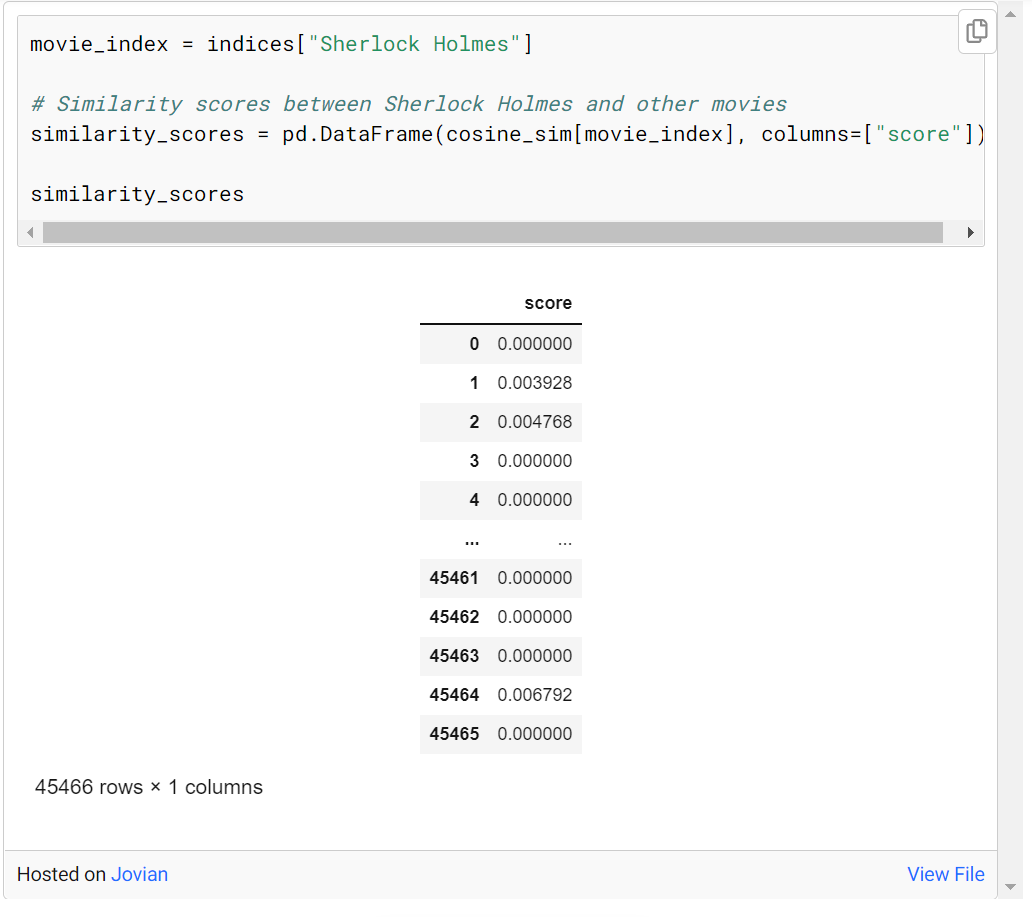
similarity_scores라는 데이터 프레임이 더 읽기 쉬운 형식으로 생성되었습니다. cosine_sim[movie_index]에 대한 선택된 유사성은 이 데이터 프레임에서 "score" 변수로 저장됩니다.

위의 셜록 영화와 가장 유사한 10편의 영화 인덱스를 선택합니다. 이러한 인덱스에 해당하는 영화 제목은 다음과 같이 액세스할 수 있습니다.

다음은 Sherlock Holmes와 가장 유사한 10편의 영화입니다. 이 영화는 Sherlock Holmes-Sherlock을 본 사용자에게 추천할 수 있습니다. 다른 영화를 시도하고 추천 결과를 관찰할 수도 있습니다.
이전 글에서는 연관 규칙 마이닝 알고리즘 Apriori를 통해 구현할 수 있는 추천 시스템인 ARL(Association Rule Learning)을 소개했는데, 오늘은 콘텐츠 기반 필터링을 통해 추천 시스템을 구현하는 방법에 대해 알아보겠습니다.
콘텐츠 기반 필터링은 추천 시스템으로 사용되는 일반적으로 사용되는 또 다른 방법 중 하나입니다. 콘텐츠 유사성은 사용자가 과거에 구매한 제품과 가장 유사한 권장 사항을 공식화할 수 있는 옵션을 제공하는 제품 메타데이터를 기반으로 계산됩니다.
메타데이터는 제품/서비스의 특성을 나타냅니다. 예를 들어, 영화의 감독, 배우, 각본가, 작가, 뒷표지 기사, 도서 번역가, 제품 카테고리 정보 등이 있습니다. ( 왜 내가 외국 데이터를 사용하는지 묻지 마세요 )
이 이미지에는 사용자가 좋아하는 영화에 대한 설명이 포함되어 있습니다. 사용자가 좋아하는 영화를 기반으로 영화를 추천하려면 이러한 설명을 사용하여 수학적 형식, 즉 텍스트를 측정할 수 있어야 하며 다른 영화와 비교하여 유사한 설명을 찾아야 합니다.
우리는 다양한 영화와 그 영화에 대한 데이터를 가지고 있습니다. 이러한 영화 데이터를 비교할 수 있으려면 데이터를 벡터화해야 합니다. 이러한 설명을 벡터화할 때 모든 영화 설명(n이라고 하자)과 모든 영화(m이라고 하자)에 걸쳐 고유한 단어의 행렬을 생성해야 합니다. 나는 열에 있는 모든 고유한 단어, 행에 있는 모든 영화, 교차로에 있는 영화에서 각 단어가 얼마나 많이 사용되었는지를 가지고 있습니다. 이런 식으로 텍스트를 벡터화할 수 있습니다.
콘텐츠 기반 필터링 단계:
- 텍스트 벡터화
- 카운트 벡터
- 태스크 포스 - IDF
2. 유사도 계산
1. 텍스트 벡터화
텍스트 벡터화는 텍스트 처리, 텍스트 마이닝 및 자연어 처리를 기반으로 하는 가장 중요한 단계입니다. 텍스트를 벡터로 변환하고 유사성 거리를 계산하는 것과 같은 방법은 데이터 분석의 기초를 형성합니다. 텍스트를 벡터로 표현할 수 있으면 수학 연산을 수행할 수 있습니다.
텍스트를 벡터로 나타내는 두 가지 일반적인 방법은 벡터 계산과 TF-IDF입니다.
- 카운트 벡터:
- 1단계 : 모든 고유 용어는 열에 배치되고 모든 문서는 행에 배치됩니다.
- 2단계 : 문서에서 용어의 빈도를 교차점의 셀에 배치합니다.
- TF-IDF:
TF-IDF는 텍스트와 전체 말뭉치(우리가 관심을 갖는 데이터) 모두에서 단어 빈도에 대해 정규화 프로세스를 수행합니다. 즉, 문서-용어 행렬, 전체 말뭉치, 모든 문서 및 용어의 빈도를 고려하여 우리가 생성할 단어 벡터의 일반적인 정규화를 수행합니다. 이렇게 하면 카운트 벡터로 인한 편향이 일부 제거됩니다.
- 1단계 : 카운트 벡터라이저 계산(각 문서에서 각 단어의 빈도)
- 2단계 : TF(Term Frequency) 계산
(관련 문서의 용어 t 빈도) / (문서의 총 용어 수)
- 3단계 : IDF(역 문서 빈도) 계산
1 + loge((문서 수 + 1) / (용어 t를 포함하는 문서 수 + 1))
총 샘플 확인 파일: 4
단어 t가 전체 말뭉치에서 자주 나타난다면 관련 단어가 전체 말뭉치에 영향을 미쳤음을 의미합니다. 이 경우 용어와 말뭉치 통과 빈도에 대해 정규화가 수행됩니다.
- 4단계 : TF * IDF 계산
- 5단계 : L2 정규화
행 제곱합의 제곱근을 찾고 해당 셀을 찾은 값으로 나눕니다.
L2 정규화는 일부 행에 누락된 값이 있어 그 효과를 표시할 수 없는 단어를 다시 수정합니다.
2. 유사도 계산
설명에 n개의 고유 단어가 있는 m개의 영화가 있다고 가정합니다. 이러한 영화에 대한 콘텐츠 기반 유사성을 프로그래밍 방식으로 찾기 전에 실제로 이를 수행하는 방법을 살펴보겠습니다.
유클리드 거리 또는 코사인 유사성을 사용하여 벡터화된 영화의 유사성을 찾을 수 있습니다.
- 유클리드 거리 :
유클리드 거리를 계산하면 두 영화 사이의 유사성을 나타내는 거리 값을 얻을 수 있다. 거리가 멀어질수록 유사도가 높아짐을 알 수 있다. 이런 식으로 추천 프로세스를 수행할 수 있습니다.
- 코사인 유사도:
유클리드에는 거리 개념이 있고 코사인 유사도에는 유사도 개념이 있습니다. 거리 근접성과 유사성 비 유사성은 여기서 동일한 개념에 해당합니다.
콘텐츠 기반 필터링의 논리를 소개했으므로 이제 콘텐츠 기반 필터링 권장 사항을 자세히 살펴볼 수 있습니다.
질문:
새로 설립된 온라인 영화 플랫폼에서 사용자에게 영화를 추천하려고 합니다. 사용자의 로그인 비율이 매우 낮기 때문에 사용자의 습관을 알 수 없습니다. 그러나 사용자가 본 영화에 대한 정보는 브라우저의 이동 경로에서 액세스할 수 있습니다. 이러한 정보를 바탕으로 사용자에게 영화를 추천하는 것이 바람직하다.
데이터세트 정보:
기본 영화 메타데이터 파일입니다. Full MovieLens 데이터 세트의 45,000개 영화에 대한 정보를 포함합니다. 기능에는 포스터, 배경, 예산, 수익, 출시 날짜, 언어, 생산 국가 및 회사가 포함됩니다.
여기에서 데이터 세트에 액세스 할 수 있습니다 . 상세 코드 주소
TF-ID 매트릭스를 만듭니다.
프로젝트 시작 시 필요한 라이브러리를 가져오고 데이터 세트를 읽습니다.
여기서 적용할 첫 번째 절차는 TF-IDF 방법을 사용하는 것이다. 이를 위해 프로젝트 초기에 가져온 TfidfVectorizer의 메소드를 호출합니다. stop_words='english' 매개변수를 입력하여 측량 없이 언어에서 일반적으로 사용되는 단어(및 the, at, on 등)를 제거합니다. 그 이유는 생성할 TF-IDF 행렬에 희소 값이 있어서 발생하는 문제를 피하기 위함입니다.
tfidf_matrix의 모양은 (45466, 75827)이며, 여기서 45466은 오버뷰의 개수이고 75827은 고유한 단어의 개수입니다. 이 크기의 데이터로 더 나은 진행을 할 수 있도록 tfidf_matrix 교차점의 값을 float32로 타입 변환하고 그에 따라 처리합니다.
이제 tfidf_matrix의 교차점에 점수가 있으므로 이제 코사인 유사성 매트릭스를 구축하고 영화 간의 유사성을 관찰할 수 있습니다.
코사인 유사성 행렬을 만듭니다.
프로젝트 초기에 가져온 cosine_similarity 메서드를 사용하여 각 영화와 다른 영화의 유사성 값을 찾습니다.
예를 들어, 다음과 같이 다른 모든 영화에 대한 첫 번째 인덱스에서 영화의 유사성 점수를 찾을 수 있습니다.
유사성에 기반한 제안:
유사도는 코사인 유사도를 사용하여 계산되지만 이 점수를 평가하려면 영화 제목이 필요합니다. 이를 위해 인덱스가 indices = pd.Series(df.index, index=df[‘title’]).
다음과 같이 일부 영화에서 다중화가 관찰되었습니다.
우리는 이러한 배수 중 하나를 유지하고 나머지는 제거하여 가장 최근 날짜에 이러한 배수 중 가장 최근을 가져와야 합니다. 이것은 다음과 같이 할 수 있습니다:
연산 결과, 각각의 타이틀이 단일 인덱스 정보를 통해 단일화되고 접근 가능함을 관찰할 수 있다.
Sherlock Holmes와 유사한 10개의 영화를 찾고 싶다고 가정해 보겠습니다. 먼저 cosine_sim에 Sherlock Holmes 인덱스 정보를 입력하여 Sherlock Holmes 영화를 선택하고 이 영화와 다른 영화의 유사도 관계를 나타내는 점수에 접근합니다.
similarity_scores라는 데이터 프레임이 더 읽기 쉬운 형식으로 생성되었습니다. cosine_sim[movie_index]에 대한 선택된 유사성은 이 데이터 프레임에서 "score" 변수로 저장됩니다.
위의 셜록 영화와 가장 유사한 10편의 영화 인덱스를 선택합니다. 이러한 인덱스에 해당하는 영화 제목은 다음과 같이 액세스할 수 있습니다.
다음은 Sherlock Holmes와 가장 유사한 10편의 영화입니다. 이 영화는 Sherlock Holmes-Sherlock을 본 사용자에게 추천할 수 있습니다. 다른 영화를 시도하고 추천 결과를 관찰할 수도 있습니다.