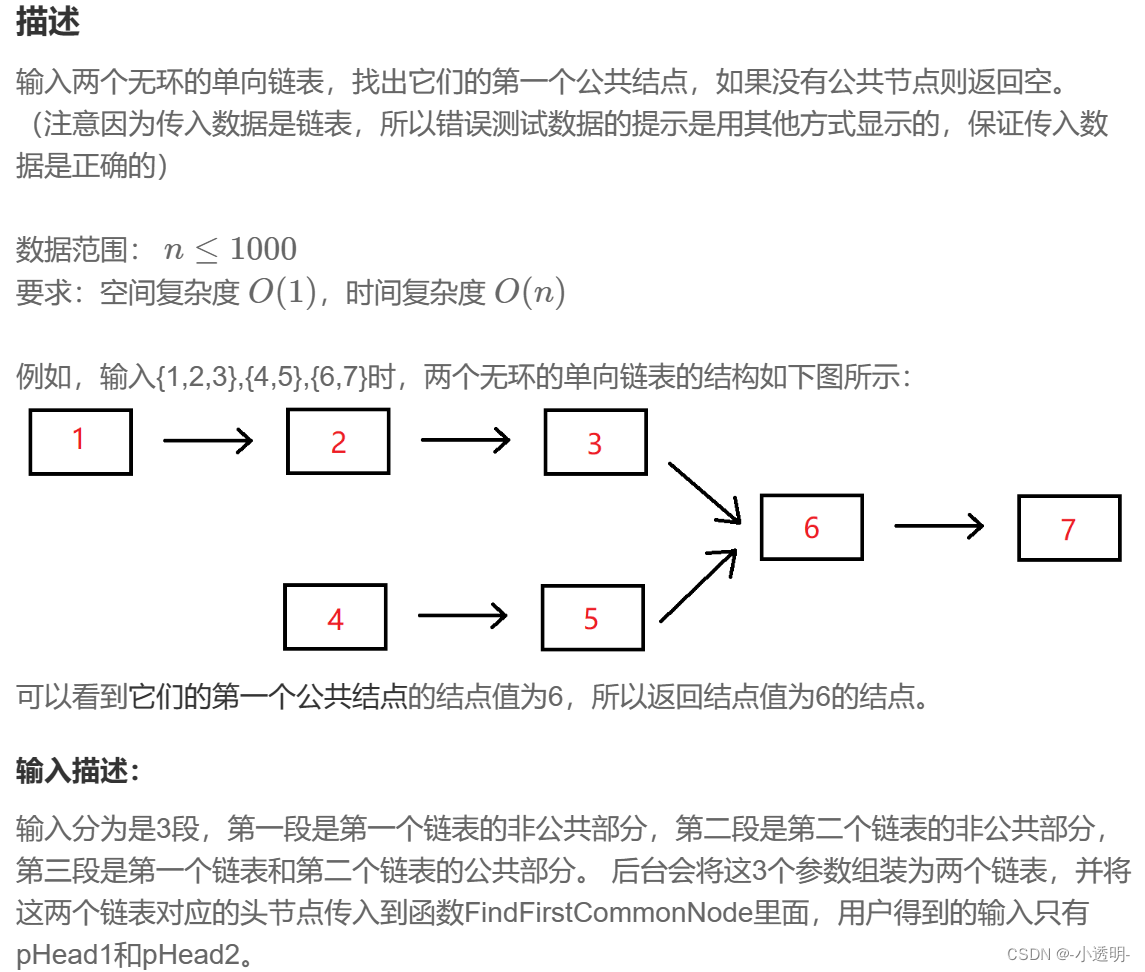
두 연결 리스트의 첫 번째 공통 노드
이중 포인터
두 개의 포인터 p와 q를 사용하여 각각 두 연결 목록 head1과 head2의 헤드 노드를 가리킨 다음 동시에 노드별로 순회하여 p가 연결 목록 head1의 끝에 도달하면 헤드 노드로 재배치합니다. 연결 리스트 head2; q가 도착하면 연결 리스트 head2의 끝에서 연결 리스트 head1의 헤드 노드로 재배치한다. 이와 같이 p와 q가 만날 때 가리키는 노드가 첫 번째 공통 노드입니다. head1에서 공통 노드까지의 길이를 a, head2에서 공통 노드까지의 길이를 b라고 하면 a+b=b+a, splicing 후 head1과 2에서 공통 노드까지의 길이는 동일합니다.
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
ListNode *p=pHead1, *q=pHead2;
while(p!=q){
if(p==NULL) p=pHead2;
else p=p->next;
if(q==NULL) q=pHead1;
else q=q->next;
}
return p;
}
};
스택: 연결 리스트의 노드를 스택에 로드하고 상위 노드를 비교한 다음 스택을 순회하여 공통 노드를 찾습니다.
Linked list 길이 차이: 두 개의 연결 목록 headA와 headB를 각각 순회하고, 포인터가 같으면 직접 반환하고, 그렇지 않으면 연결 목록의 길이 차이를 계산하고 변수 step을 사용하여 긴 연결 목록의 길이를 계산합니다. 짧은 연결 목록과 비교하여 다음으로 긴 연결 목록이 먼저 단계를 실행한 다음 연결 목록 headA와 headB가 동기적으로 이동하여 공통 노드를 찾습니다.
연결 리스트 추가 (2)
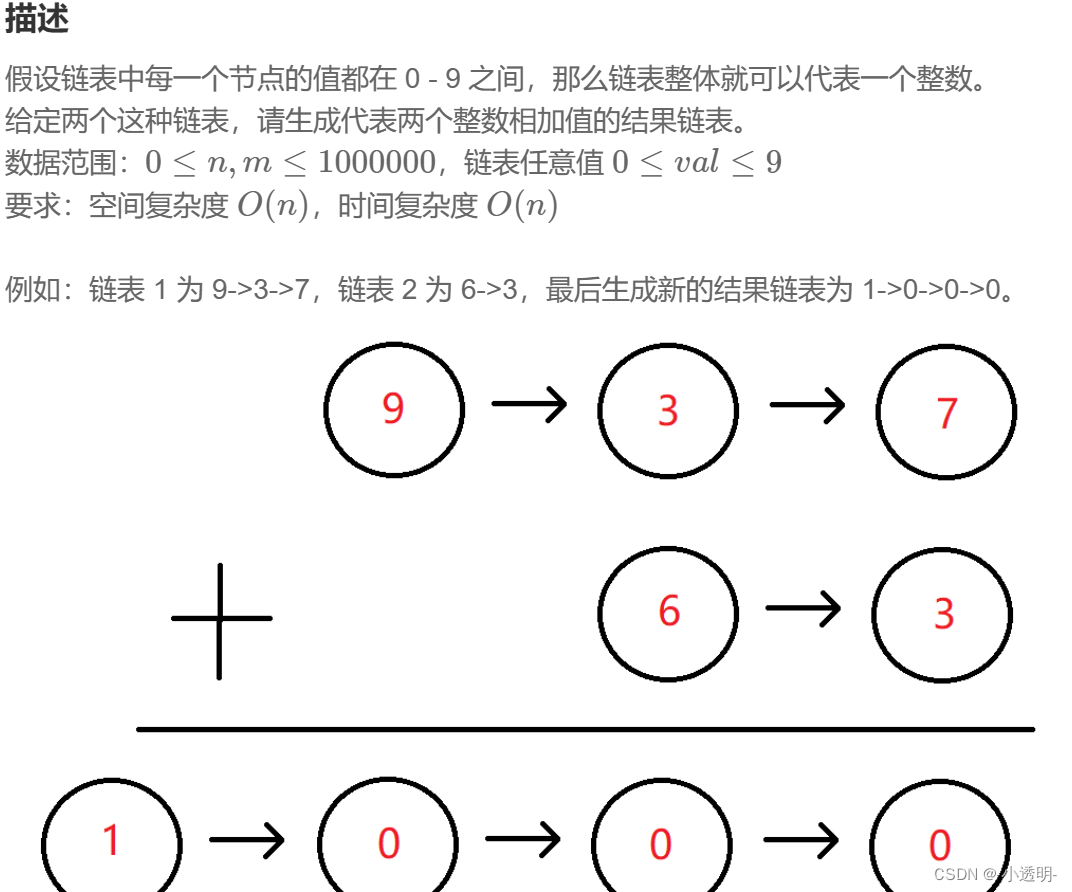

두 개의 연결된 목록을 뒤집고 더하기
뒤집은 후 처음부터 더하고, 정수 변수를 사용하여 캐리 값을 기록하고, 헤드 보간을 사용하여 결과를 저장하고, 마지막으로 결과를 뒤집습니다.
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
/**
*
* @param head1 ListNode类
* @param head2 ListNode类
* @return ListNode类
*/
ListNode* addInList(ListNode* head1, ListNode* head2) {
// write code here
head1=reverse(head1);
head2=reverse(head2);
ListNode *dummy = new ListNode(0);
ListNode *cur=dummy;
int jw=0;//进位
while (head1 || head2 || jw) {
int sum = jw;
if(head1){
sum += head1->val;
head1=head1->next;
}
if(head2){
sum += head2->val;
head2=head2->next;
}
jw = sum /10;
sum %= 10;
cur->next=new ListNode(sum);
cur=cur->next;
}
ListNode *res=reverse(dummy->next);//结果翻转
return res;
}
ListNode* reverse(ListNode *head){
ListNode *pre=NULL, *cur=head;
while(cur!=NULL){
ListNode *next=cur->next;
cur->next=pre;
pre=cur,cur=next;
}
return pre;
}
};단일 연결 리스트의 정렬

병합 정렬
비순차 리스트를 좌우 2개로 나누고 재귀적으로 분해하여 각각을 순차 리스트로 간주한 다음, 순차 리스트를 쌍으로 병합
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
#include <algorithm>
class Solution {
public:
/**
*
* @param head ListNode类 the head node
* @return ListNode类
*/
ListNode* sortInList(ListNode* head) {
// 归并排序
if (!head || !head->next) return head;
ListNode *slow = head, *fast = head;
while (fast->next && fast->next->next) {
slow = slow->next;
fast = fast->next->next;
}
ListNode *mid = slow->next;//注意1
slow->next = nullptr;
ListNode *left = sortInList(head);
ListNode *right = sortInList(mid);
return merge(left, right);
}
ListNode *merge(ListNode* h1, ListNode* h2){
ListNode dummy(0),*p = &dummy;
while(h1 && h2){
if(h1->val < h2->val){
p->next=h1;
h1=h1->next;
}else{
p->next=h2;
h2=h2->next;
}
p=p->next;//注意2
}
if(h1) p->next=h1;
if(h2) p->next=h2;
return dummy.next;
}
};빠른 정렬
벤치마크 찾기: 다음 노드를 순회합니다: 왼쪽에 작은 노드를 놓고 오른쪽에 큰 노드를 놓은 다음 왼쪽 + 벤치마크 + 오른쪽을 병합합니다.
// 快速排序函数
ListNode* quickSortList(ListNode* head) {
if (head == NULL || head->next == NULL) {
return head;
}
// 选择一个基准元素
ListNode *pivot = head;
head = head->next;
pivot->next = NULL;
// 将链表分成两个部分
ListNode *left = NULL, *right = NULL;
while (head != NULL) {
ListNode *next = head->next;
if (head->val < pivot->val) {
head->next = left;
left = head;
} else {
head->next = right;
right = head;
}
head = next;
}
// 递归地对左右两个部分进行排序
left = quickSortList(left);
right = quickSortList(right);
// 将左右两个部分和基准元素拼接起来
if (left == NULL) {
pivot->next = right;
return pivot;
} else {
ListNode *tail = left;
while (tail->next != NULL) {
tail = tail->next;
}
tail->next = pivot;
pivot->next = right;
return left;
}
}