Configuración relacionada con el inicio de Hadoop
Directorio de artículos
El caso de formatear nodos
¿En qué circunstancias necesita Hadoop formatear los nodos?
Hadoop requiere que NameNode esté formateado en los siguientes casos:
- Instalación de Hadoop por primera vez: al crear y configurar un clúster de Hadoop por primera vez, debe formatear el NameNode. La operación de formateo crea la estructura de almacenamiento de metadatos HDFS e inicializa NameNode. Tenga en cuenta que en las operaciones posteriores, no es necesario volver a formatear el NameNode, a menos que se restablezca todo el HDFS.
- Restablecer HDFS: si desea restablecer todo el HDFS, eliminando todos los datos y metadatos, puede volver a formatear el NameNode. Pero tenga en cuenta que esto provocará la pérdida de todos los datos en HDFS.
Para formatear el NameNode, ejecute el siguiente comando:
$HADOOP_HOME/bin/hadoop namenode -format
Pasos de inicio de Hadoop
¿El paso de inicio de Hadoop es solo start-dfs.sh?
start-dfs.shEl script solo se usa para iniciar los componentes relacionados con el sistema de archivos distribuidos de Hadoop (HDFS), como NameNode, Second NameNode (si está configurado) y DataNode. Después de ejecutar este script, el servicio HDFS estará en funcionamiento.
Sin embargo, el ecosistema de Hadoop también incluye otros componentes como YARN (para la gestión de recursos y la programación de tareas). Para iniciar los componentes de YARN, se deben ejecutar los siguientes comandos:
$HADOOP_HOME/sbin/start-yarn.sh
Esto iniciará ResourceManager y NodeManager.
Por lo tanto, para iniciar completamente un clúster de Hadoop, se deben ejecutar dos scripts: start-dfs.shy start-yarn.sh. Esto iniciará los componentes HDFS y YARN. Si solo le preocupa la funcionalidad HDFS, ejecutar start-dfs.shes suficiente.
descripción del parámetro de la página de administración web hdfs
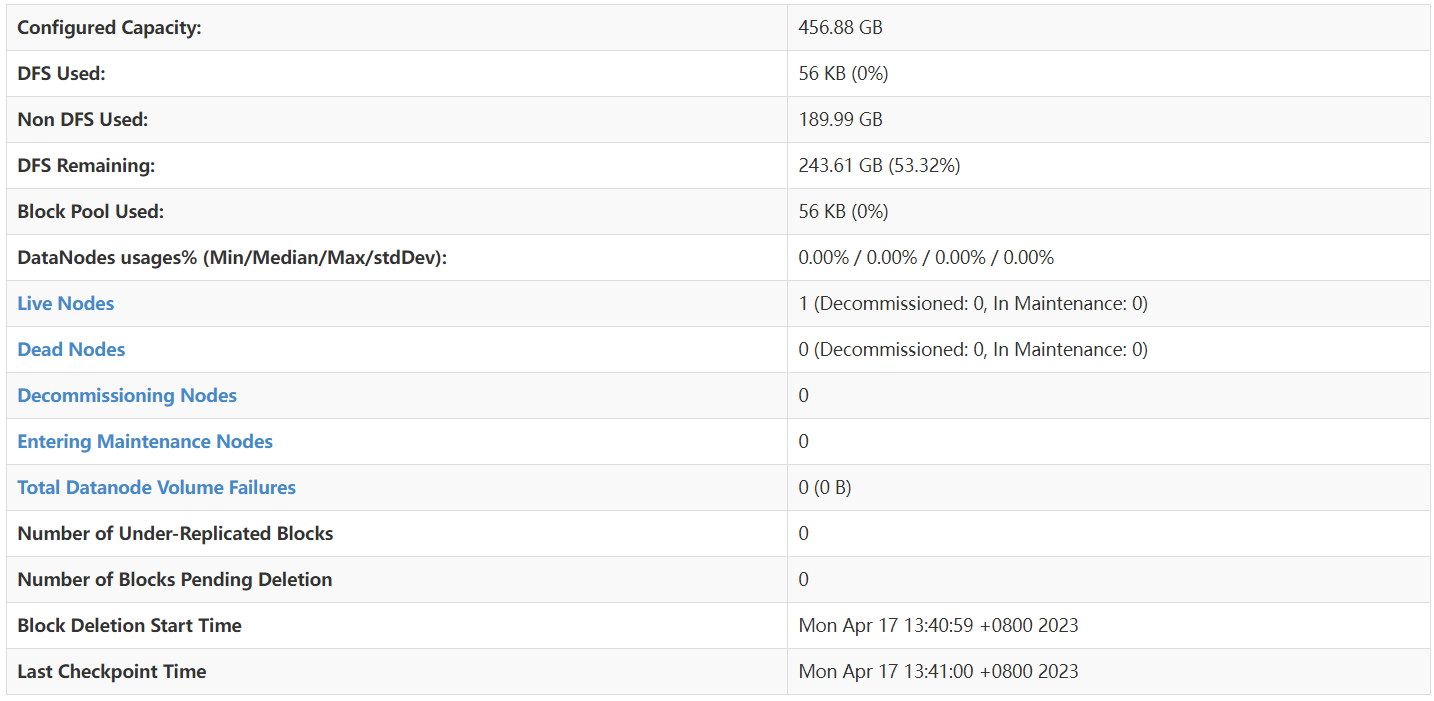
- Capacidad configurada: la capacidad configurada es la capacidad de almacenamiento total de todos los DataNodes en el clúster HDFS . En este ejemplo, la capacidad configurada es de 456,88 GB.
- DFS utilizado: el espacio de almacenamiento utilizado por DFS. Esta es la cantidad de datos ya almacenados en HDFS . En este ejemplo, se han utilizado 56 KB.
- Uso no DFS: espacio de almacenamiento utilizado no DFS. Este es espacio de almacenamiento en el DataNode utilizado para otros fines (no HDFS) . En este ejemplo, no DFS ha utilizado 189,99 GB.
- DFS restante: el espacio de almacenamiento restante de DFS. Este es espacio de almacenamiento no utilizado en el clúster HDFS . En este ejemplo quedan 243,61 GB (53,32% de la capacidad configurada).
- Agrupación de bloques utilizada: el espacio de almacenamiento utilizado por la agrupación de bloques. Este es el espacio de almacenamiento en HDFS que se ha asignado al grupo de bloques. En este ejemplo, se han utilizado 56 KB.
- Usos de DataNodes% (Min/Median/Max/stdDev): Estadísticas de uso de DataNode, incluidos el mínimo, la mediana, el máximo y la desviación estándar. En este ejemplo, todos estos valores son 0,00%.
- Nodos activos: la cantidad de nodos de datos que se están ejecutando actualmente. En este ejemplo, hay 1 DataNode activo (no dado de baja o en mantenimiento).
- Nodos muertos: la cantidad de nodos de datos que actualmente no están disponibles o están inactivos. En este ejemplo, no hay DataNodes muertos.
- Nodos en desmantelamiento: el número de DataNodes que se están desmantelando. En este ejemplo, no hay ningún DataNode que se esté desmantelando.
- Entrando en nodos de mantenimiento: el número de nodos de datos que están entrando en el estado de mantenimiento. En este ejemplo, no hay ningún DataNode que entre en estado de mantenimiento.
- Total de fallas de volumen de nodo de datos: el número total de fallas de volumen de nodo de datos. En este ejemplo, las fallas del disco del nodo de datos son 0.
- Número de bloques sub-replicados: el número de bloques cuyo recuento de réplicas está por debajo del valor configurado. En este ejemplo, no hay réplicas por debajo del valor configurado.
- Número de bloques pendientes de eliminación: el número de bloques que se eliminarán. En este ejemplo, no hay bloques para eliminar.
- Hora de inicio de la eliminación de bloques: la hora en que comenzó la eliminación de bloques. En este ejemplo, la eliminación de bloques comenzó a las 13:40:59 del 17 de abril de 2023 (UTC+8).
- Hora del último punto de control: la hora del último punto de control. En este ejemplo, el punto de control más reciente ocurrió el 17 de abril de 2023 a las 13:41:00 (UTC+8).
Escenario de evaluación de parámetros
- Monitoreo del estado del clúster: estos parámetros ayudan a monitorear el estado del clúster HDFS para garantizar que el clúster funcione correctamente . Por ejemplo, al ver los parámetros **"Nodos activos" y "Nodos muertos", puede conocer el estado de ejecución de los nodos de datos**, a fin de determinar si el clúster se ejecuta con normalidad .
- Gestión del espacio de almacenamiento: comprender el uso del espacio de almacenamiento es fundamental para la gestión de clústeres . Por ejemplo, al ver parámetros como " Capacidad configurada ", " DFS usado ", " No DFS usado " y " DFS restante ", puede comprender el uso del espacio de almacenamiento del clúster y, por lo tanto, determinar si expandir u optimizar el espacio de almacenamiento. .
- Monitoreo de replicación y consistencia de datos: Ciertos parámetros ayudan a evaluar el estado de replicación y consistencia de los datos . Por ejemplo, " Número de bloques sub-replicados" indica el número de bloques para los cuales el número de réplicas está por debajo del valor configurado , lo que puede generar un mayor riesgo de pérdida de datos . El monitoreo de estos parámetros ayuda a garantizar la confiabilidad y consistencia de los datos.
- Optimización del rendimiento: algunos parámetros pueden ayudar a comprender el rendimiento y la carga del clúster , como " % de usos de DataNodes ". Puede usar este parámetro para comprender la utilización de los nodos de datos . Esta información ayuda a optimizar la configuración del clúster y mejorar el rendimiento del clúster.
- Solución de problemas y recuperación: cuando ocurre un problema, estos parámetros pueden ayudar a identificar la causa del problema. Por ejemplo, el parámetro " Total de fallas de volumen de nodos de datos " representa la cantidad total de fallas de disco de nodos de datos , lo que puede provocar la pérdida de datos o la degradación del rendimiento del clúster . Conocer estos parámetros puede ayudar a diagnosticar y resolver problemas rápidamente.