Métodos y técnicas para cargar datos en Pandas
Hola a todos, soy Xianyu
Creo que mis amigos habrán escuchado o usado pandas más o menos en el proceso de aprendizaje del análisis de datos de Python.
pandas es una biblioteca de extensión de python, a menudo utilizada para el análisis de datos
Hoy, Xianyu presentará varios métodos y técnicas para importar datos de pandas
Obtener datos csv de la URL
Con respecto a los pandas que importan datos csv, se utiliza el siguiente método
pandas.read_csv()
Pero este método puede obtener datos CSV de URL a través de HTTP
Sobre la obtención de datos CSV de URL a través de HTTP, lo introduje en el artículo anterior "¿Por qué visitar la misma URL pero devolver contenido diferente"?
Por ejemplo, el siguiente ejemplo mostrará cómo obtener el archivo csv a través de la URL
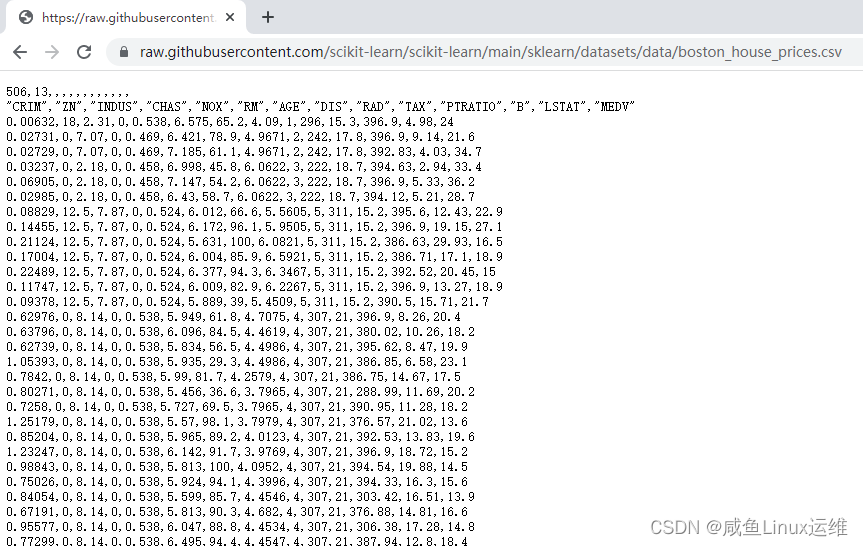
url = 'https://raw.githubusercontent.com/scikit-learn/scikit-learn/main/sklearn/datasets/data/boston_house_prices.csv'
df = pandas.read_csv(url)
Obtener datos CSV a través de la URL puede ahorrar el paso de guardar el archivo CSV localmente primero
Obtener datos de la tabla HTML del sitio web
pandas.read_html()Se utiliza para obtener los datos de la tabla en el archivo HTML (es decir, <table>los datos tabulares de la etiqueta)
Veamos el siguiente ejemplo
import pandas as pd
url = 'http://weather.sina.com.cn/china/shanghaishi/'
df_tables = pd.read_html(url)
print(df_tables)
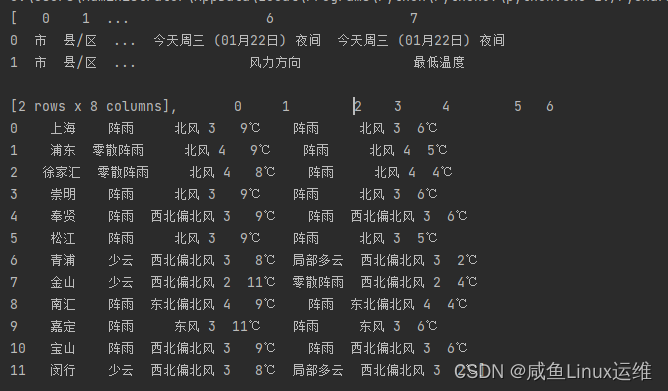
pandas.read_html()Un rastreador simple puede ser realizado por
Formato de datos JSON
A veces, cuando procesamos datos JSON, encontramos que los datos JSON generalmente están anidados en varias capas
Si queremos convertir datos JSON en datos tabulares para hacerlos planos, podemos usar el siguiente método para lograrlo
pandas.json_normalize()
Vea el ejemplo a continuación
impor pandas as pd
data =[
{
"id": "A001",
"name": "咸鱼运维杂谈",
"url": "https://www.cnblogs.com/edisonfish/",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.json_normalize(data)
print(df)
El resultado es el siguiente
id name url likes
0 A001 咸鱼运维杂谈 https://www.cnblogs.com/edisonfish/ 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
A continuación, intentemos leer datos JSON más complejos, que tienen listas y diccionarios anidados.
import pandas as pd
data ={
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "[email protected]",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
# 展平数据
df = pd.json_normalize(
data,
record_path =['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
El resultado es el siguiente
id name math ... class info.president info.contacts.tel
0 A001 Tom 60 ... Year 1 John Kasich 123456789
1 A002 James 89 ... Year 1 John Kasich 123456789
2 A003 Jenny 79 ... Year 1 John Kasich 123456789
[3 rows x 8 columns]
obtener datos del portapapeles
El read_clipboard()método puede obtener cualquier dato almacenado en el portapapeles
Supongamos que desea copiar y pegar los datos de Internet en el local, luego puede leer directamente el contenido del portapapeles con read_clipboard()el método
De forma predeterminada, las expresiones regulares se usan \s+como delimitadores para separar valores (es decir, hacer coincidir uno o más caracteres en blanco, como espacios, tabuladores y líneas nuevas como delimitadores), y luego dividir los datos en el portapapeles en datos tabulares.
import pandas as pd
df = pd.read_clipboard()
print(df)
Artículo de referencia: https://jrashford.com/2022/08/02/loading-data-into-pandas-5-tips-and-tricks-you-may-or-may-not-know/