
Python se ha convertido en uno de los lenguajes más populares en el campo de la ciencia de datos en los últimos años. Una de las razones importantes es que Python tiene una gran cantidad de paquetes y herramientas fáciles de usar. Entre estas bibliotecas, Pandas es una de las herramientas más prácticas para las operaciones de ciencia de datos. Este artículo comparte 12 métodos de Pandas para la manipulación de datos de Python y también agrega algunos consejos y sugerencias que pueden mejorar la eficiencia de su trabajo.
Conjunto de datos: este artículo utiliza el conjunto de datos utilizado en un problema de "predicción de préstamos" en el concurso de ciencia de datos Analytics Vidhya.
https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii/
Primero, importamos el módulo y cargamos el conjunto de datos en el entorno de Python:
import pandas as pd
import numpy as np
data = pd.read_csv("train.csv", index_col="Loan_ID")
Índice booleano
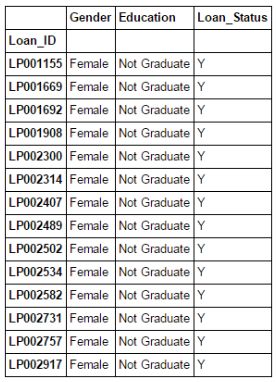
¿Qué sucede si desea filtrar el valor de una columna de un conjunto de columnas en función de ciertas condiciones? Por ejemplo, queremos una lista que contenga una lista de todas las mujeres que han obtenido préstamos y aún no se han graduado. Usar la indexación booleana aquí puede ayudar. Puede utilizar el siguiente código:
data.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]]
Aplicar función
La función Aplicar es una de las funciones más utilizadas para procesar datos y crear nuevas variables. Después de aplicar una función a una fila / columna del DataFrame, Apply devuelve algunos valores. La función puede usar la predeterminada o personalizarla. Por ejemplo, se puede utilizar aquí para encontrar valores perdidos para cada fila y cada columna.
#创建一个新函数
def num_missing(x):
return sum(x.isnull())
#应用每一列
print "Missing values per column:"
print data.apply(num_missing, axis=0) #axis=0 defines that function is to be applied on each column
#应用每一行
print "\nMissing values per row:"
print data.apply(num_missing, axis=1).head() #axis=1 defines that function is to be applied on each row
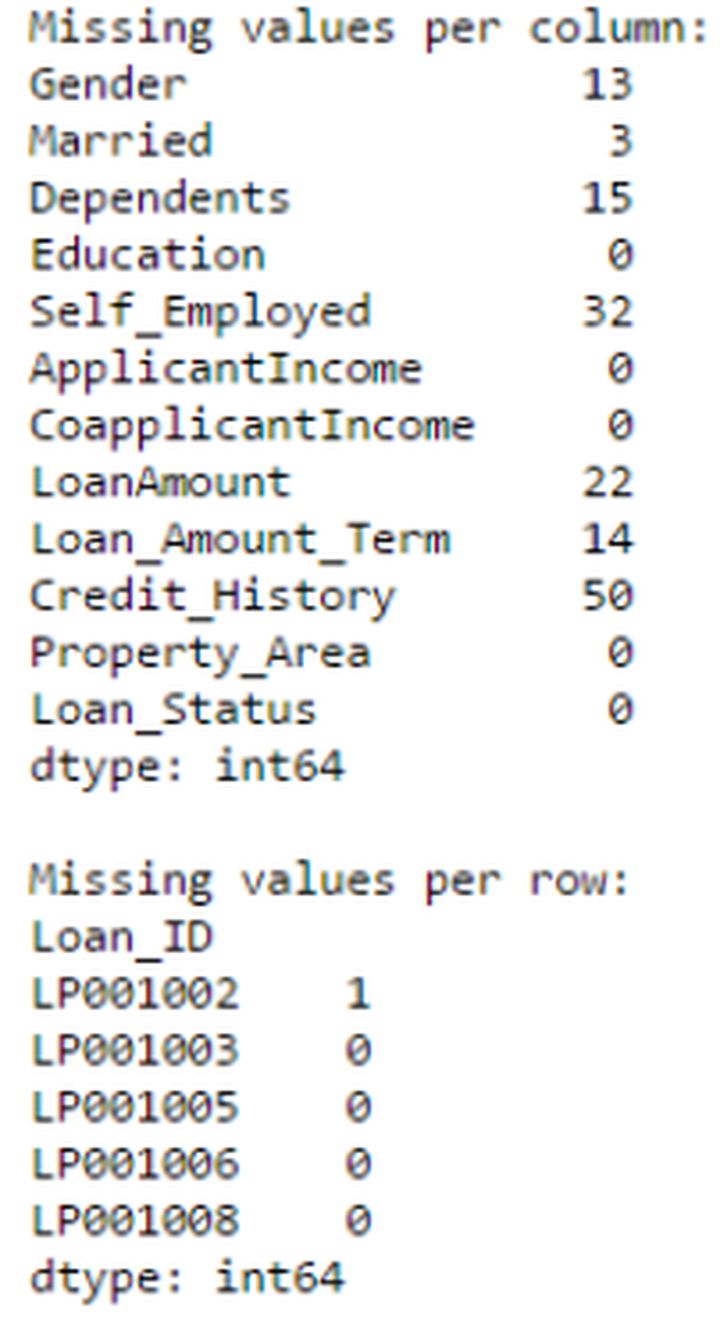
De esta forma obtuvimos el resultado deseado.
Nota: Utilice la función head () en la segunda salida porque contiene muchas líneas.
Reemplazar valores perdidos
Utilice fillna () para reemplazar los valores faltantes en un solo paso. Puede actualizar los valores faltantes con el promedio / modo / mediana de la columna de destino. En el siguiente ejemplo, usamos los modos de las columnas 'Género', 'Casado' y 'Autoempleado' para reemplazar sus valores faltantes.
#首先我们导入一个函数来确定模式
from scipy.stats import mode
mode(data['Gender'])
Producción:
ModeResult(mode=array([‘Male’], dtype=object), count=array([489]))
Recuerde, el modo a veces es una matriz porque puede haber múltiples valores de alta frecuencia. Por defecto usamos el primero:
mode(data['Gender']).mode[0]Producción:
‘Male’Ahora podemos completar los valores faltantes, use el segundo método anterior para verificar.
#导入值:
data['Gender'].fillna(mode(data['Gender']).mode[0], inplace=True)
data['Married'].fillna(mode(data['Married']).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(data['Self_Employed']).mode[0], inplace=True)
#现在再次检查缺失值进行确认:
print data.apply(num_missing, axis=0)
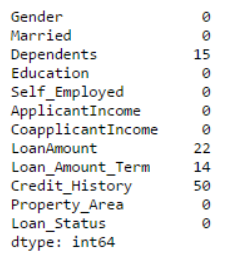
Se confirma que el valor faltante ha sido reemplazado. Tenga en cuenta que este es solo un método de reemplazo común y que existen otros métodos complejos, como modelar valores perdidos.
Tabla dinámica
Pandas también se puede utilizar para crear tablas dinámicas al estilo de Excel. Por ejemplo, en nuestro ejemplo, la columna clave de los datos es'LoanAmount 'que contiene los valores faltantes. Podemos reemplazar los valores faltantes con el promedio de los grupos 'Género', 'Casado' y 'Autoempleado'. De esta manera, el 'LoanAmount' promedio de cada grupo se puede determinar como:
#确定数据透视表
impute_grps = data.pivot_table(values=["LoanAmount"], index=["Gender","Married","Self_Employed"], aggfunc=np.mean)
print impute_grps

Índice múltiple
Si presta atención al resultado de la tercera técnica, encontrará que tiene una característica extraña: cada índice consta de 3 valores. Este es un índice múltiple, puede acelerar nuestra velocidad de operación.
Continuando con el ejemplo de la tercera técnica anterior, tenemos valores para cada grupo, pero aún no hemos estimado los valores faltantes.
Podemos usar las técnicas que usamos antes para resolver este problema:
#用缺失的 LoanAmount仅迭代所有的行
for i,row in data.loc[data['LoanAmount'].isnull(),:].iterrows():
ind = tuple([row['Gender'],row['Married'],row['Self_Employed']])
data.loc[i,'LoanAmount'] = impute_grps.loc[ind].values[0]
#现在再次检查缺失值进行确认
print data.apply(num_missing, axis=0)
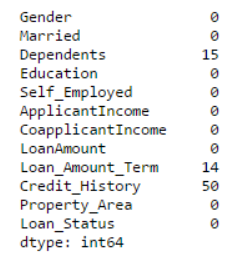
Nota:
El índice múltiple requiere una tupla para definir el grupo de índices en la instrucción loc, que es una tupla utilizada en la función.
El sufijo .values [0] aquí es necesario porque una serie de elementos se devuelven por defecto, lo que producirá un índice que no coincide con el DataFrame. En este ejemplo, asignar valores directamente producirá un error.
Tabla cruzada
Esta función se utiliza para obtener una "sensación" preliminar (descripción general) de los datos. Aquí, podemos verificar un supuesto básico. Por ejemplo, en este ejemplo, esperamos que "Credit_History" afecte en gran medida el estado del préstamo. Entonces podemos usar la tabla cruzada como se muestra a continuación para probar:
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True)
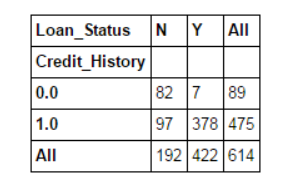
Estos son valores absolutos. Sin embargo, es más intuitivo usar porcentajes. Podemos usar la función de aplicar para completar:
def percConvert(ser):
return ser/float(ser[-1])
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True).apply(percConvert, axis=1)
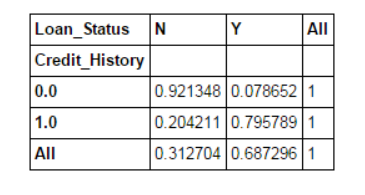
Ahora, está claro que las personas con historial crediticio tienen una mayor probabilidad de obtener un préstamo: 80%, en comparación con el 9% de las personas sin crédito.
Pero el hecho no es tan sencillo. Dado que sabemos que tener un historial crediticio es muy importante, ¿qué pasa si predecimos el estado de préstamo de una persona con un historial crediticio como Y y una persona sin historial crediticio como N? Nos sorprenderá descubrir que de las 614 pruebas, 82 + 378 = 460 predicciones fueron correctas y la tasa de precisión alcanzó el 75%.
Quizás se pregunte por qué necesitamos modelos estadísticos, pero debe saber que es un desafío muy difícil aumentar la precisión incluso en un 0,001%.
Nota: La tasa de precisión del 75% es la tasa de precisión obtenida en el equipo de entrenamiento. Será ligeramente diferente en el equipo de prueba, pero es similar.
Fusionar DataFrame
Si tenemos información de múltiples fuentes de datos que necesitan ser verificadas, entonces fusionar DataFrame será una operación básica. Considere una situación hipotética en la que diferentes tipos de propiedades tienen diferentes precios promedio de propiedades (precios por metro cuadrado). Definimos el DataFrame como:
prop_rates = pd.DataFrame([1000, 5000, 12000], index=['Rural','Semiurban','Urban'],columns=['rates'])
prop_rates
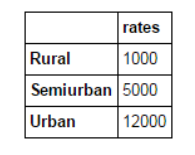
Ahora, podemos fusionar esta información con el DataFrame inicial en:
data_merged = data.merge(right=prop_rates, how='inner',left_on='Property_Area',right_index=True, sort=False)
data_merged.pivot_table(values='Credit_History',index=['Property_Area','rates'], aggfunc=len)
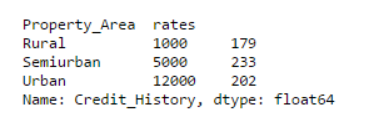
A través de la tabla dinámica, podemos saber que la fusión se realizó correctamente. Tenga en cuenta que el parámetro 'valores' no tiene nada que ver con esto, porque simplemente calculamos el valor.
Ordenar DataFrame
Pandas nos permite ordenar por múltiples columnas fácilmente, lo que se puede hacer de la siguiente manera:
data_sorted = data.sort_values(['ApplicantIncome','CoapplicantIncome'], ascending=False)
data_sorted[['ApplicantIncome','CoapplicantIncome']].head(10)
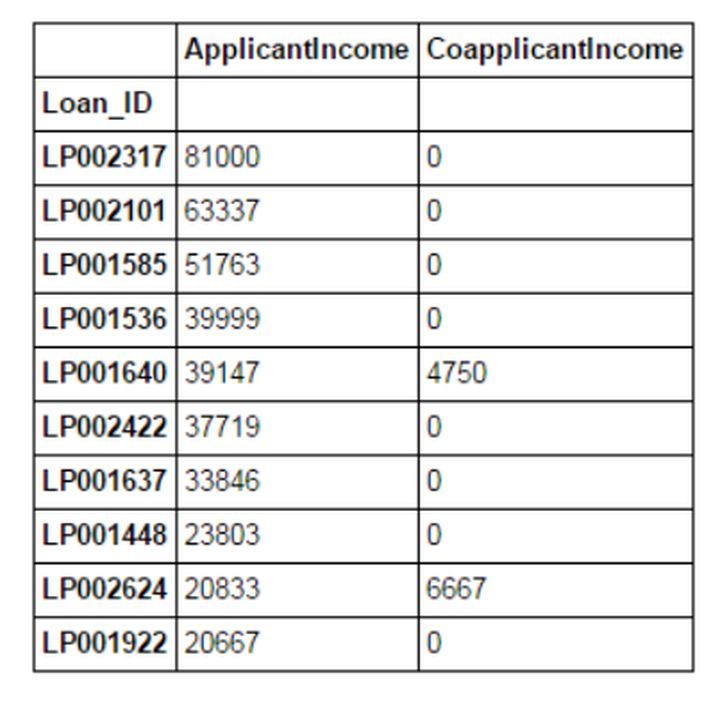
Nota: La función "Ordenar" de Pandas ya no está disponible, deberíamos usar "sort_values" en su lugar.
Trazado (diagrama de caja e histograma)
Es posible que muchas personas no sepan que podemos dibujar diagramas de caja e histogramas directamente en Pandas. De hecho, no es necesario llamar a matplotlib. Solo se requiere una línea de comando. Por ejemplo, si queremos comparar la distribución de ingresos de los solicitantes de préstamos según Loan_Status:
import matplotlib.pyplot as plt
%matplotlib inline
data.boxplot(column="ApplicantIncome",by="Loan_Status")
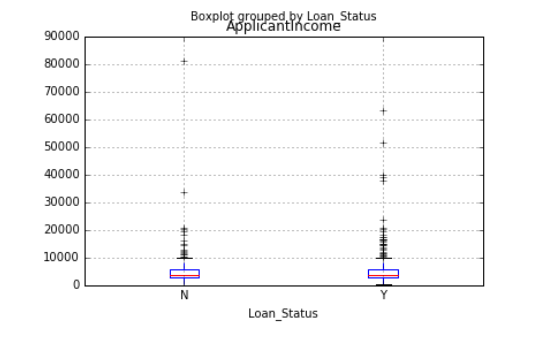
data.hist(column="ApplicantIncome",by="Loan_Status",bins=30)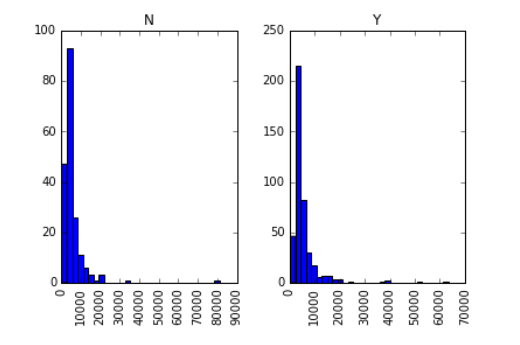
Como puede ver en el gráfico, los ingresos no son un gran factor decisivo, porque no existe una diferencia obvia entre los ingresos de la persona que recibió el préstamo y la persona a la que se le negó el préstamo.
Utilice la función de corte para la combinación de datos
A veces, después de la agrupación, el valor será más significativo. Por ejemplo, queremos modelar el flujo de tráfico en un día (la unidad de tiempo es minutos), con una precisión de cada hora y cada minuto. Para predecir el flujo de tráfico, es posible que la correlación no sea tan alta. Utilice el período de tiempo real de la día como "mañana" Tarde "," Tarde "," Noche "y" Tarde en la noche "tendrán mejores efectos. Modelar el flujo de tráfico de esta manera será más intuitivo y evitará el sobreajuste.
Aquí definimos una función simple que se puede reutilizar para combinar cualquier variable:
#组合:
def binning(col, cut_points, labels=None):
#定义最小和最大值
minval = col.min()
maxval = col.max()
#向cut_points添加最大和最小值来创建列表
break_points = [minval] + cut_points + [maxval]
#如果没提供标签就用默认标签 0 ... (n-1)
if not labels:
labels = range(len(cut_points)+1)
#用Pandas的cut函数进行组合
colBin = pd.cut(col,bins=break_points,labels=labels,include_lowest=True)
return colBin
#组合:
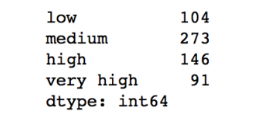
cut_points = [90,140,190]
labels = ["low","medium","high","very high"]
data["LoanAmount_Bin"] = binning(data["LoanAmount"], cut_points, labels)
print pd.value_counts(data["LoanAmount_Bin"], sort=False)
Datos de nombre de código
Por lo general, nos encontraremos con una situación en la que se debe modificar la categoría de la variable nominal. Esto puede deberse a varias razones:
Algunos algoritmos (como la regresión logística) requieren que todas las entradas sean numéricas. Por lo tanto, la mayoría de las variables nominales se escriben como 0,1 ··· (n-1).
A veces, una categoría se puede expresar de dos formas. Por ejemplo, la temperatura se puede registrar como "Alta", "Media" y "Baja", o "H" y "baja", donde tanto "Alta" como "H" indican la misma categoría. Del mismo modo, "bajo" y "bajo" son solo ligeramente diferentes. Sin embargo, Python los leerá como niveles diferentes.
Algunas categorías pueden parecer muy bajas, por lo que suele ser una buena idea combinarlas. Aquí definimos una función general cuya entrada está en forma de diccionario, y luego usamos la función 'reemplazar' en Pandas para codificar el valor de entrada.
#用Pandas的replace函数定义一个通用函数
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
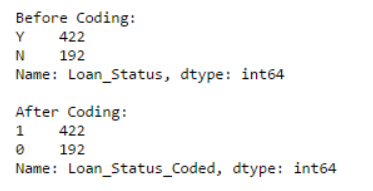
#将LoanStatus 编码为 Y=1, N=0:
print 'Before Coding:'
print pd.value_counts(data["Loan_Status"])
data["Loan_Status_Coded"] = coding(data["Loan_Status"], {'N':0,'Y':1})
print '\nAfter Coding:'
print pd.value_counts(data["Loan_Status_Coded"])
Iterar las filas de DadaFrame
Esta técnica no se usa con frecuencia, pero en caso de que encuentre un problema de este tipo, no tiene miedo, ¿verdad? En algunos casos, puede usar un bucle for para recorrer todas las filas. Por ejemplo, un problema común al que nos enfrentamos es que las variables en Python no se tratan correctamente. Suele ocurrir en las dos situaciones siguientes:
- Las variables nominales con categorías numéricas se tratan como variables numéricas
- Cuando una variable numérica con caracteres en una fila (debido a errores de datos) se trata como una variable categórica
Por lo tanto, a menudo es una mejor manera de definir manualmente el tipo de columna. Si comprobamos los tipos de datos de todas las columnas:
#检查当前类型:
data.dtypes

Aquí podemos ver que Credit_History es una variable nominal, pero aparece como un valor de punto flotante. Una buena forma de resolver este problema es crear un archivo CSV con nombres y tipos de columnas. De esta forma, podemos escribir una función general para leer el archivo y asignar el tipo de datos de la columna. Por ejemplo, aquí hemos creado un archivo CSV datatypes.csv.
#加载文件:
colTypes = pd.read_csv('datatypes.csv')
print colTypes

Después de cargar el archivo, podemos iterar a través de cada fila y usar la columna "tipo" para asignar el tipo de datos al nombre de variable definido en la columna "característica".
#迭代每一行,并分配变量类型
#注:astype 用来分配类型
for i, row in colTypes.iterrows(): #i: dataframe index; row: each row in series format
if row['type']=="categorical":
data[row['feature']]=data[row['feature']].astype(np.object)
elif row['type']=="continuous":
data[row['feature']]=data[row['feature']].astype(np.float)
print data.dtypes

De esta manera, la columna Credit_History se modifica a un tipo de "objeto", que se puede utilizar para representar variables nominales en Pandas.
Conclusión
En este artículo, exploramos una serie de técnicas en Pandas que hacen que sea más conveniente y eficiente para nosotros usar Pandas para manipular datos y realizar ingeniería de características. Además, también hemos definido algunas funciones generales, que se pueden reutilizar para lograr el mismo efecto en diferentes conjuntos de datos.