RLHF에서 PPO 알고리즘의 원리 및 구현
ChatGPT는 InstructGPT를 기반으로 하는 다중 라운드 대화 생성 대형 모델입니다. 주로 ChatGPT와 관련된 기술은 다음과 같습니다.
- 명령 조정;
- 인과적 언어 모델링;
- 인간의 정렬
블로거는 이전 기사 (참조: Prompt-Tuning——새로운 미세 조정 패러다임에 대한 심층 해석 ) 및 GPT와 같은 인과 언어 모델 에 대한 관련 소개 에서 지침 미세 조정 및 관련 Prompting 기술 의 원칙을 소개했습니다 . 사전 학습된 언어 모델] GPT: Generative Pre-Training을 통한 언어 이해 향상 . 따라서 기본 생성 모델을 훈련하는 방법 외에도 대형 모델은 생성 대형 모델을 인간의 가치와 더 일치하도록 만드는 방법 에 중점을 두어야 합니다 .
이전 기사 InstructGPT 원리 설명 및 ChatGPT 오픈 소스 프로젝트에서 ChatGPT 및 최근 일부 오픈 소스 ChatGPT 모델이 정렬을 달성하는 방법을 소개했습니다. 여기서는 InstructGPT - RLHF(인간 정렬 강화 학습)에서 인간 정렬을 위한 핵심 알고리즘을 자세히 소개합니다. PPO 알고리즘.
이 문서는 주로 다음 두 가지 참조 자료를 참조합니다.
[1] 강화 학습에 대한 간단한 소개: MDP, DP MC TC 및 Q 학습, 정책 그래디언트, PPO에 대한 대중적인 이해
[2] DeepSpeed 기반의 ChatGPT 교육
1. RLHF PPO 알고리즘의 원리
PPO 알고리즘은 특정 Actor-Critic 알고리즘을 구현한 것입니다.예를 들어 대화 로봇에서 입력 프롬프트는 state이고 출력 응답은 action입니다.원하는 전략은 최대 보상을 얻기 위해 프롬프트에서 action을 생성하는 방법입니다. , 그것은 인간의 선호도를 맞추는 것입니다.
PPO 알고리즘에는 두 가지 전략이 포함됩니다.
- 근접 정책 최적화 페널티(PPO 페널티);
- 근접 전략은 PPO 클립의 클리핑을 최적화합니다.
중요도 샘플링
Actor-Critic 교육 중에 정책 기능 매개 변수가 최적화된 후 이전 정책 샘플링 라운드의 동작-상태 시퀀스를 사용할 수 없으므로 정책 기능의 각 업데이트 후 반복 샘플링 문제를 피하기 위해 중요도 샘플링이 필요합니다. . 데이터를 분포 p에서 샘플링할 수 없고 다른 분포 q에서만 샘플링할 수 있는 경우(q는 모든 분포일 수 있음).
중요도 샘플링 원칙:

KL 발산 제약:
중요도 샘플링에서 p 및 q 분포를 너무 멀리 확인할 수 없으므로 제약 조건을 부과하려면 KL 발산이 필요합니다.
이점:
Actor-Critic 알고리즘에서 Advantage를 정의해야 하는데, 가장 쉬운 방법은 Reward-baseline을 정의하는 것으로, 로 정의할 수도 있습니다. 여기서 V π ( s ) V_{\pi}(s)V피( s )는 현재 상태ss모든 행동이 s 아래에서 실행된 후 얻을 보상의 기대치Q π ( s , a ) Q_{\pi}(s, a)큐피( , _a )는 현재 상태ss를s 아래에 작업aa받은 보상 . 따라서 만약A π ( s , a ) > 0 A_{\pi}(s, a)>0ㅏ피( , _) _>0 , 현재 동작aa를a 가 얻은 보상은 전체 기대치보다 크므로 이 작업의 확률을 최대화해야 합니다.
일반적으로 Advantage는 긍정적인 값과 부정적인 값을 통해 어떤 행동이 긍정적인 피드백을 얻을 수 있는지 전략에 알리고, Reward만 절대값으로 사용할 때 발생하는 높은 분산 문제를 피하는 것을 목표로 합니다.
이점+중요도 샘플링:
Advantage는 중요도 샘플링에서 f ( x ) f(x) 로 간주할 수 있습니다.에프 ( 엑스 ) . 최적화 프로세스 중에 매개변수가 변경되기 때문에 중요도 샘플링이 필요하므로 최적화 목표는 다음과 같습니다.
J θ ′ = E st , at ~ π θ ′ [ p θ ( at ∣ st ) p θ ′ ( at , st ) A θ ′ ( st , at ) ] J^{\theta'}=\mathbb{E} _{s_t, a_t}\sim\pi_{\theta'}\bigg[\frac{p_{\theta}(a_t|s_t)}{p_{\theta'}(a_t, s_t)}A^{\theta '}(s_t, a_t)\bigg]제이나′′=이자형에스티, _티.~파이나′[피나′( _티,에스티)피나( _티∣ 초티)ㅏ나′ (들티,ㅏ티) ]
근접 정책 최적화 페널티(PPO 페널티)
PPO 알고리즘의 근접 정책 최적화 페널티의 원리는 다음 그림과 같습니다.

근접 전략 최적 클리핑 PPO-클립
최적화 목표는 다음과 같이 변경됩니다.
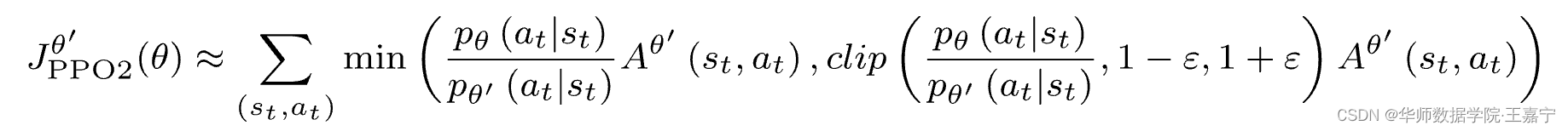
공식의 이해:
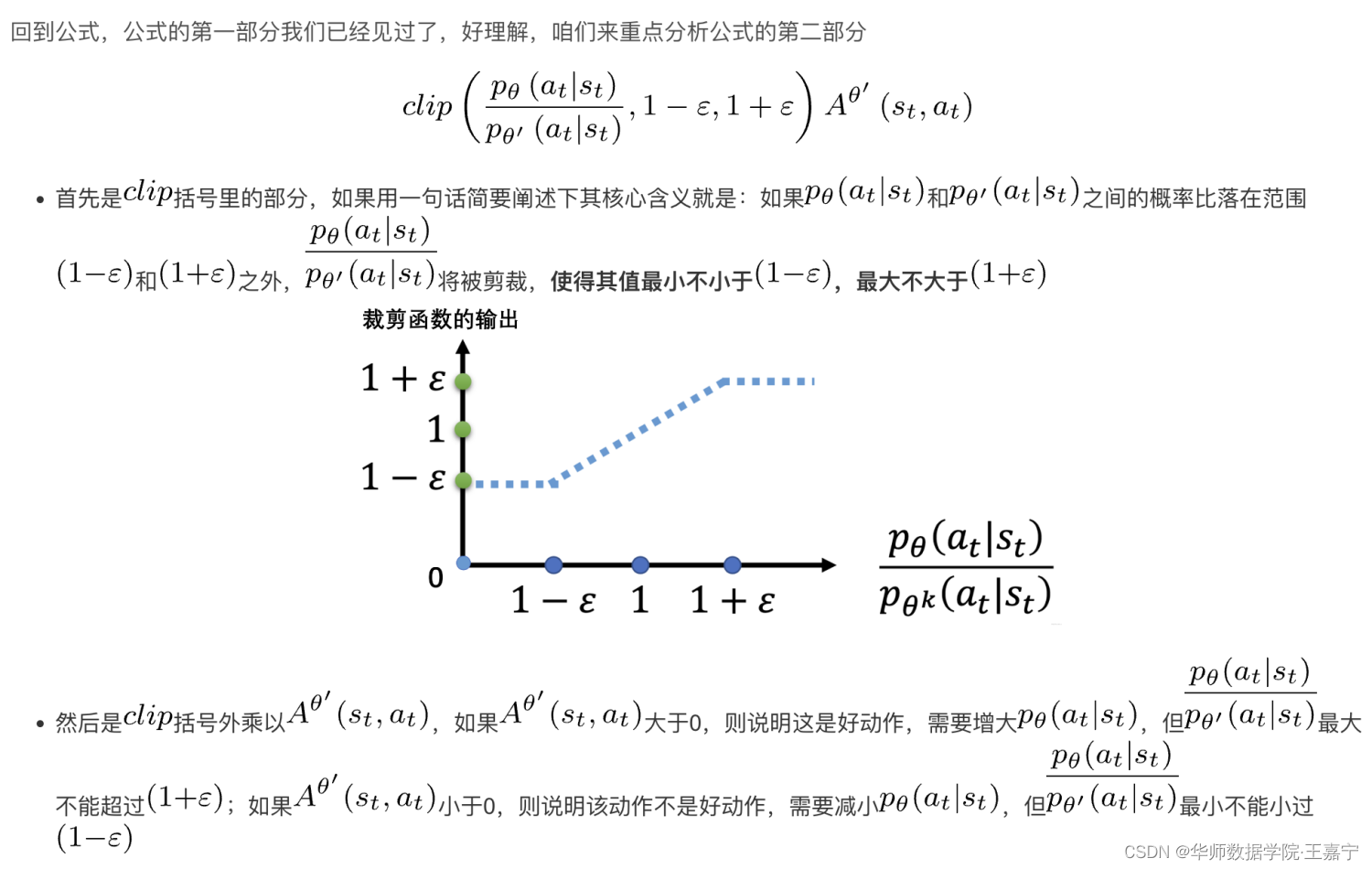
따라서 클립은 본질적으로 두 분포가 너무 멀리 떨어져 있지 않도록 구속합니다.KL 발산과 비교하여 KL 발산은 두 분포의 출력 로짓에 구속되는 반면 클립 방법은 확률 비율에 직접 구속합니다.
2. RLHF PPO 알고리즘 구현
(1) 먼저 RLHF 클래스와 PPOTrainer를 초기화합니다.
rlhf_engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args)
ppo_trainer = DeepSpeedPPOTrainer
trainer = ppo_trainer(rlhf_engine, args)
초기화하는 동안 Actor, SFT, Critic 및 Reward를 포함한 4개의 모델을 로드합니다.
코드의 self.ref는 실제로 SFT 모델입니다.
class DeepSpeedRLHFEngine():
def __init__(self, actor_model_name_or_path, critic_model_name_or_path,
tokenizer, args, num_total_iters):
self.args = args
self.num_total_iters = num_total_iters
self.tokenizer = tokenizer
# 用训练好的SFT模型初始化Actor模型
self.actor = self._init_actor(
actor_model_name_or_path=actor_model_name_or_path)
# 用训练好的SFT模型初始化SFT模型
self.ref = self._init_ref(
actor_model_name_or_path=actor_model_name_or_path)
self.actor_ema = None
if self.args.enable_ema:
self.actor_ema = self._init_ema(
actor_model_name_or_path=actor_model_name_or_path)
# 用训练好的RW初始化Critic模型
self.critic = self._init_critic(
critic_model_name_or_path=critic_model_name_or_path)
# 用训练好的RW初始化reward模型
self.reward = self._init_reward(
critic_model_name_or_path=critic_model_name_or_path)
if self.args.critic_gradient_checkpointing:
self.critic.gradient_checkpointing_enable()
(2) RLHF에 대한 훈련 데이터 로드
prompt_train_dataloader, num_total_iters = create_datasets(
args=args, tokenizer=tokenizer, train_phase=3)
(3) RLHF의 전반적인 교육 과정은 다음과 같으며
구체적인 과정은 코드 주석에서 확인할 수 있으며 일반적으로 주요 과정은 다음과 같습니다.
- 각 에포크 순회, 각 에포크의 각 배치 순회
- 각 배치에 대해 먼저 여러 경험적 데이터를 샘플링합니다.
- 경험적 데이터를 기반으로 Actor 및 Critic 모델 학습
# 训练的总Epoch数
for epoch in range(args.num_train_epochs):
# 遍历每一个Batch
for step, (batch_prompt) in enumerate(prompt_train_dataloader):
batch_prompt = to_device(batch_prompt, device)
prompts = batch_prompt['prompt'] # prompt
length = prompts.size(-1)
# 进行采样,并加入到经验池,详见(3.1)
out = trainer.generate_experience(prompts)
exp_dataset = exp_mini_dataset.add(out)
if exp_dataset is not None:
inner_iter = 0
critic_loss, actor_loss = 0, 0
average_reward = 0
if args.actor_gradient_checkpointing:
rlhf_engine.actor.gradient_checkpointing_enable()
# 从经验池中进行学习Epoch轮
for ppo_ep in range(args.ppo_epochs):
for i, (exp_data) in enumerate(exp_dataset):
# 得到actor和critic loss,详见(3.2)
actor_loss, critic_loss = trainer.train_rlhf(exp_data)
critic_loss += actor_loss.item()
actor_loss += critic_loss.item()
average_reward += exp_data["rewards"].mean()
inner_iter += 1
if args.enable_ema:
moving_average(rlhf_engine.actor,
rlhf_engine.actor_ema,
zero_stage=args.actor_zero_stage)
# 每一轮结束后打乱经验池
random.shuffle(exp_dataset)
average_reward = get_all_reduce_mean(average_reward).item()
if args.actor_gradient_checkpointing:
rlhf_engine.actor.gradient_checkpointing_disable()
이 교육 프로세스에는 주로 두 가지 핵심 단계가 포함됩니다.
- 샘플링 경험 데이터
- 샘플링된 데이터를 기반으로 Actor 및 Critic 모델을 교육합니다.
이 두 가지 핵심 단계를 자세히 분석해 보겠습니다.이 두 가지 핵심 단계를 이해하면 RLHF PPO 알고리즘을 거의 이해할 수 있습니다.
체험 샘플링

여기 에서 그림 .
구현 세부 정보는 코드 및 주석을 참조하십시오.
def generate_experience(self, prompts):
self.eval() # 开启eval模式
# 输入instruct prompt,由Actor生成seq,上图中红色步骤(1),seq由instruct和response组成
seq = self._generate_sequence(prompts)
self.train() # 恢复训练模型
pad_token_id = self.tokenizer.pad_token_id
attention_mask = seq.not_equal(pad_token_id).long()
with torch.no_grad():
# 将seq喂入actor中得到action_logits,上图中棕色步骤(2)
output = self.actor_model(seq, attention_mask=attention_mask)
# 将seq喂入SFT中得到sft_logits,上图中黑色步骤(5)
output_ref = self.ref_model(seq, attention_mask=attention_mask)
# 将seq喂入reward模型中打分,得到r(x, y),上图绿色步骤(4)
reward_score = self.reward_model.forward_value(
seq, attention_mask,
prompt_length=self.prompt_length)['chosen_end_scores'].detach(
)
# 将seq喂入critic,获得critic的value,上图蓝色步骤(3)
values = self.critic_model.forward_value(
seq, attention_mask, return_value_only=True).detach()[:, :-1]
logits = output.logits
logits_ref = output_ref.logits
# 获得经验数据
return {
'prompts': prompts,
'logprobs': gather_log_probs(logits[:, :-1, :], seq[:, 1:]),
'ref_logprobs': gather_log_probs(logits_ref[:, :-1, :], seq[:, 1:]),
'value': values,
'rewards': reward_score,
'input_ids': seq,
"attention_mask": attention_mask
}
Advantage를 얻고 Actor 및 Critic 매개변수를 업데이트합니다.
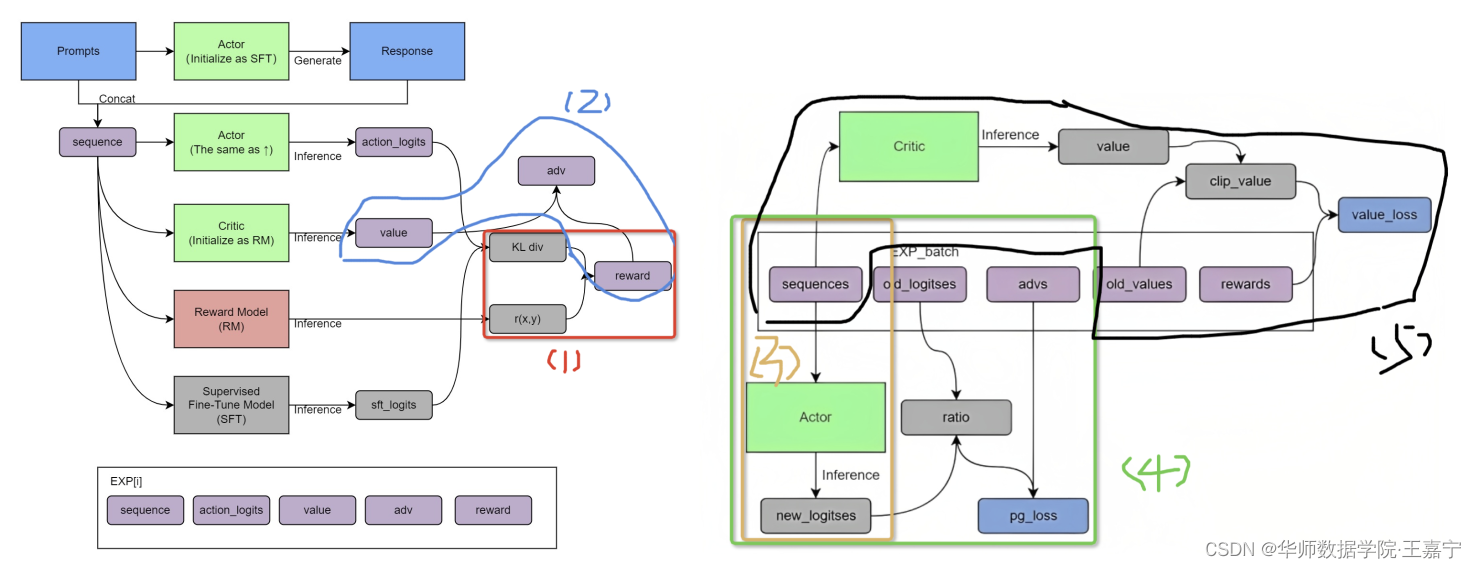
def train_rlhf(self, inputs):
# 当前RLHF轮次最初采样的经验池中采样一批数据
prompts = inputs['prompts'] # instruct prompt
log_probs = inputs['logprobs'] # actor模型生成response对应的action_logist
ref_log_probs = inputs['ref_logprobs'] # SFT模型生成response对应的sft_logits
reward_score = inputs['rewards'] # reward模型预测的奖励r(x, y)
values = inputs['value'] # critic模型预测的奖励
attention_mask = inputs['attention_mask']
seq = inputs['input_ids']
start = prompts.size()[-1] - 1
action_mask = attention_mask[:, 1:]
### 根据经验数据,接下来计算相应的reward和advantage
old_values = values # RLHF训练之前的critic给的value值
with torch.no_grad():
# 根据SFT的sft_logits和Actor的action_logist,计算KL散度;
# 并根据KL散度与reward模型预测的奖励r(x, y),获得最终奖励
# 上图中红色步骤(1)
old_rewards = self.compute_rewards(prompts, log_probs,
ref_log_probs, reward_score,
action_mask)
"""
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score,
action_mask):
# self.kl_ctl = 0.02
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
start = prompts.shape[1] - 1
ends = start + action_mask[:, start:].sum(1)
reward_clip = torch.clamp(reward_score, -self.clip_reward_value,
self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j]
"""
# 由critic或的的value与前面根据KL散度和r(x, y)得到的reward,从而计算得到advantage
# 上图蓝色步骤(2)
advantages, returns = self.get_advantages_and_returns(
old_values, old_rewards, start)
"""
def get_advantages_and_returns(self, values, rewards, start):
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values[:, start:]
return advantages.detach(), returns
"""
### 根据经验数据以及得到的advatage,下面开始获得一系列的loss
batch = {
'input_ids': seq, "attention_mask": attention_mask}
# 将这一批经验数据的seq(instruct prompt+response)再一次喂入actor得到logits
# 因为现在是在更新actor和critic,而经验数据所采用的actor和critic早已经是之前的了,所以
# 现在正在更新的actor和critic与当时进行经验采样时的actor、critic的参数已经有差异了;
# 所以需要重新获得当前最新的actor输出的logits
# 上图中棕色步骤(3)
actor_prob = self.actor_model(**batch, use_cache=False).logits
actor_log_prob = gather_log_probs(actor_prob[:, :-1, :],
inputs['input_ids'][:, 1:])
# 根据新的actor logits以及经验数据中的logits,以及advantage,计算actor loss
# 上图中绿色步骤(4)
actor_loss = self.actor_loss_fn(actor_log_prob[:, start:],
log_probs[:, start:], advantages,
action_mask[:, start:])
"""
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
## policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange,
1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum()
return pg_loss
"""
# 更新actor模型参数
self.actor_model.backward(actor_loss)
self.actor_model.step()
# 经验数据中的seq(instruct prompt+response)再一次喂入critic得到value
# 同理,由于当前的critic和当初进行经验数据采样时的critic相差很远;所以需要重新获得value
# 上图中黑色步骤(5)
value = self.critic_model.forward_value(**batch,
return_value_only=True,
use_cache=False)[:, :-1]
# 根据最新的critic的value,经验数据的old_value,以及advatage,计算得到critic loss
critic_loss = self.critic_loss_fn(value[:, start:], old_values[:,
start:],
returns, action_mask[:, start:])
"""
def critic_loss_fn(self, values, old_values, returns, mask):
## value loss
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask) / mask.sum()
return vf_loss
"""
# 更新critic参数
self.critic_model.backward(critic_loss)
self.critic_model.step()
return actor_loss, critic_loss
블로거는 대형 모델에 대한 더 많은 기술을 계속 업데이트할 예정입니다.관련 기사는 다음을 참조하십시오.
【1】대규모 모델 학습 및 추론 최적화 기술에 대해 자세히 논의합니다.
【2】Prompt-Tuning - 새로운 미세 조정 패러다임에 대한 심층 해석
【3】InstructGPT 원리 설명 및 ChatGPT 오픈 소스 프로젝트
【4】DeepSpeed 기반 ChatGPT 교육
【5】【 HuggingFace는 시작하기 쉽습니다.] Wikipedia를 기반으로 지식이 강화된 사전 교육
[6] Pytorch 단일 시스템 다중 카드 GPU 구현(원리 개요, 기본 프레임워크, 공통 오류 보고서)