arquitectura JVM


Incluye principalmente dos subsistemas y dos componentes:
Subsistema de cargador de clases (cargador de clases) (utilizado para cargar archivos .class);
Subsistema del motor de ejecución (motor de ejecución) (ejecutar código de bytes o ejecutar método nativo);
Componentes del área de datos de tiempo de ejecución (área de datos de tiempo de ejecución) (área de métodos, pila, pila java, registro de PC, pila de métodos locales);
Componentes de interfaz nativa (interfaz local).
-
Subsistema del cargador de clases : cargue el contenido del archivo de clase en el área de método (área de método) en el área de datos de tiempo de ejecución de acuerdo con el nombre de clase completo proporcionado (como java.lang.Object).
-
Subsistema motor de ejecución : ejecutar las instrucciones en clases. El bytecode de un método está compuesto por la secuencia de instrucciones de la máquina virtual Java. Cada instrucción consta de un código de operación de un solo byte seguido de cero o más operandos. Cuando el motor de ejecución ejecuta el código de bytes, primero obtiene un código de operación y, si el código de operación tiene un operando, obtiene su operando. Realiza la acción especificada por el código de operación y los siguientes operandos antes de obtener el siguiente código de operación. Este proceso de ejecución de bytecode continuará hasta que se complete el subproceso. El núcleo de cualquier implementación de JVM es el motor de ejecución, es decir, la calidad del JDK de Sun y del JDK de IBM depende principalmente de la calidad de sus respectivas implementaciones del motor de ejecución.
-
Componente de interfaz nativa : interactúa con bibliotecas nativas y es una interfaz para interactuar con otros lenguajes de programación. La mayoría de los métodos declarados como nativos en Java se pueden encontrar en jdk/src/<platform>/native. Puede ser share, es decir, código plataforma neutral, también puede ser una plataforma específica. La estructura en este directorio nativo está organizada por nombre de paquete al igual que la estructura del código fuente de Java. Sin embargo, debe recordarse que estos métodos nativos no son "JVM", sino "biblioteca de clases", no en la JVM.
-
Componente de área de datos de tiempo de ejecución : la máquina virtual define varios tipos de áreas de datos de tiempo de ejecución que utilizan los programas en ejecución, algunas de las cuales se crean con el inicio de la máquina virtual y se destruyen con la salida de la máquina virtual, como el montón y el área de método. . El segundo es la correspondencia uno a uno con hilos, creados y destruidos con el inicio y el final de los hilos, como pilas y registros.
Módulo de memoria JVM
El modelo de memoria Java es la especificación del lenguaje Java para leer y escribir variables compartidas (en realidad operaciones de memoria correspondientes a variables compartidas) bajo la condición de concurrencia de subprocesos múltiples, principalmente para resolver los problemas de atomicidad y visibilidad de subprocesos múltiples, y resolver el problema de conflicto de operación de subprocesos múltiples de variables compartidas
JMM (modelo de memoria de Java) El modelo de memoria de Java en sí mismo es un concepto abstracto, no real, describe un conjunto de reglas o especificaciones a través de las cuales se define cada variable en el programa (incluidos campos de instancia, campos estáticos y el modo de acceso a los elementos). que componen el objeto de matriz).
JMM define la relación abstracta entre los subprocesos y la memoria principal: las variables compartidas entre los subprocesos se almacenan en la memoria principal (memoria principal), cada subproceso tiene una memoria local privada (memoria local) y la memoria local almacena las copias de lectura/escritura de los subprocesos de los subprocesos compartidos. variables
Tres características principales del modelo de memoria JMM
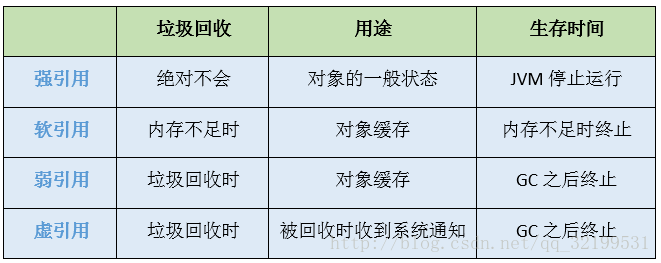
1. Atomicidad
Utilice bloqueos mutex sincronizados para garantizar la atomicidad de las operaciones
2. Visibilidad:
volátil, lo que obligará a que el estado de la variable y otras variables en ese momento se eliminen de la memoria caché.
sincronizado, antes de ejecutar la operación de desbloqueo en una variable, el valor de la variable debe sincronizarse con la memoria principal.
final, una vez que el campo modificado por la palabra clave final se inicializa en el constructor y no existe este escape (otros subprocesos acceden al objeto medio inicializado a través de esta referencia), entonces otros subprocesos pueden ver el valor del campo final.
3. Solicite
el código fuente -> reordenamiento optimizado del compilador -> reordenamiento paralelo de instrucciones -> reordenamiento del sistema de memoria -> comando final ejecutado.
El proceso de reordenación no afectará la ejecución de programas de un solo subproceso, pero afectará la corrección de la ejecución concurrente de subprocesos múltiples.
El procesador debe considerar la dependencia de los datos al realizar el reordenamiento. En un entorno de subprocesos múltiples, los subprocesos se ejecutan alternativamente. Debido a la existencia del reordenamiento de optimización del compilador, no está claro si las variables utilizadas en los dos subprocesos pueden garantizar la coherencia.
JMM define una relación abstracta entre hilos y memoria principal:
Las variables compartidas entre subprocesos se almacenan en la memoria principal (Memoria principal) y
cada subproceso tiene una memoria local privada (Memoria local).La memoria local es un concepto abstracto de JMM y en realidad no existe. Cubre caché, búfer de escritura, registros y otras optimizaciones de hardware y compilador. Una copia de las variables compartidas de lectura/escritura del subproceso se almacena en la memoria local.
Desde un nivel inferior, la memoria principal es la memoria de hardware, y para obtener una mejor velocidad de operación, la máquina virtual y el sistema de hardware pueden permitir que la memoria de trabajo se almacene primero en registros y cachés.
La memoria de trabajo del subproceso en el modelo de memoria de Java es una descripción abstracta de los registros y cachés de la CPU. El modelo de almacenamiento interno estático de JVM (modelo de memoria JVM) es solo una división física de la memoria. Solo está limitado a la memoria y solo está limitado a la memoria JVM.
Asignación de montón:
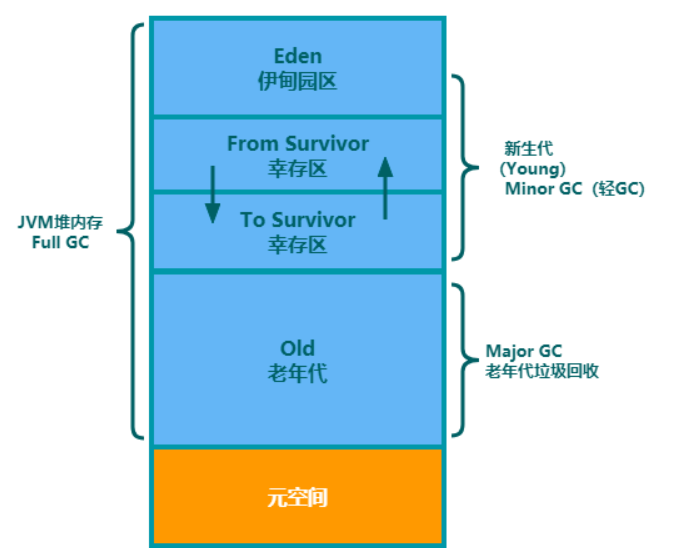
Área de datos de tiempo de ejecución de JVM
1 Área de métodos MethodArea
El área de métodos (MethodArea), al igual que el montón de Java, es un área de memoria compartida por cada subproceso Se utiliza para almacenar datos como información de tipo, constantes, variables estáticas y cachés de código compilados por el compilador instantáneo que han sido cargados por la máquina virtual. . Aunque la "Especificación de máquina virtual de Java" describe el área del método como una parte lógica del montón, tiene un alias llamado "No montón" para distinguirlo del montón de Java.
grupo de constantes de tiempo de ejecución
El conjunto de constantes de tiempo de ejecución (RuntimeConstantPool) forma parte del área de métodos. Además de la versión de clase, los campos, los métodos, las interfaces y otra información de descripción en el archivo de clase, también hay una tabla de agrupación de constantes (ConstantPoolTable), que se utiliza para almacenar varios literales y referencias de símbolos generadas durante la compilación. Una vez cargada la clase, se almacena en el grupo de constantes de tiempo de ejecución en el área de métodos.
La máquina virtual Java tiene regulaciones estrictas sobre el formato de cada parte del archivo de clase (incluido el conjunto de constantes, naturalmente). Por ejemplo, cada byte se usa para almacenar qué datos deben cumplir con los requisitos de la especificación antes de que puedan ser reconocidos, cargados. y ejecutado por la máquina virtual. , pero para el conjunto de constantes de tiempo de ejecución, la "Especificación de la máquina virtual de Java" no establece requisitos detallados. Las máquinas virtuales implementadas por diferentes proveedores pueden implementar esta área de memoria de acuerdo con sus propias necesidades, pero en términos generales, además de guardar el archivo de clase Además de las referencias simbólicas descritas, las referencias directas traducidas de las referencias simbólicas también se almacenan en el conjunto de constantes de tiempo de ejecución [1].
Otra característica importante del grupo de constantes de tiempo de ejecución en comparación con el grupo de constantes de archivo de clase es que es dinámico. El lenguaje Java no requiere que las constantes se generen solo en tiempo de compilación, es decir, los contenidos del grupo de constantes que no están preestablecidos en se puede ingresar el archivo de clase. El grupo de constantes de tiempo de ejecución en el área de métodos también puede colocar nuevas constantes en el grupo durante el tiempo de ejecución. Esta característica es más utilizada por los desarrolladores que el método intern() de la clase String.
Dado que el grupo de constantes de tiempo de ejecución es parte del área de métodos, naturalmente está limitado por la memoria en el área de métodos. Cuando el grupo de constantes ya no puede solicitar memoria, se lanzará una excepción OutOfMemoryError.
2 Montón de Java Montón
Para las aplicaciones de Java, el montón de Java (JavaHeap) es la pieza de memoria más grande administrada por la máquina virtual. El montón de Java es un área de memoria compartida por todos los subprocesos y creada cuando se inicia la máquina virtual. El único propósito de esta área de memoria es almacenar instancias de objetos, y "casi" todas las instancias de objetos en el mundo de Java asignan memoria aquí. La descripción del montón de Java en la "Especificación de la máquina virtual de Java" es: "Todas las instancias de objetos y matrices deben asignarse en el montón", y el "casi" escrito por el autor aquí significa que desde el punto de vista de la implementación, como el lenguaje Java Ahora podemos ver algunas señales de que el soporte para tipos de valor puede aparecer en el futuro.Incluso si solo consideramos el presente, debido al avance de la tecnología de compilación justo a tiempo, especialmente la tecnología de análisis de escape cada vez más poderosa, en Los métodos de optimización de asignación de pila y reemplazo escalar han llevado a que se hayan producido algunos cambios sutiles en silencio, por lo que no es tan absoluto decir que las instancias de objetos Java están todas asignadas en el montón.
El montón de Java es un área de memoria administrada por el recolector de elementos no utilizados, por lo que también se denomina "montón de GC" en algunos materiales. Desde la perspectiva de la recuperación de la memoria, dado que la mayoría de los recolectores de basura modernos están diseñados según la teoría de la recolección generacional, "nueva generación", "antigua generación", "generación permanente", "espacio Eden" y "espacio FromSurvivor" a menudo aparecen en el montón de Java. . "" "ToSurvivor space" y otros términos, estas divisiones de área son solo las características comunes o estilos de diseño de algunos recolectores de basura, no el diseño de memoria inherente de una implementación específica de una máquina virtual Java, y mucho menos la "Especificación de máquina virtual Java". División más detallada del montón de Java. Desde la perspectiva de la asignación de memoria, varios búferes de asignación privados de subprocesos (ThreadLocalAllocationBuffer, TLAB) se pueden dividir en el montón de Java compartido por todos los subprocesos para mejorar la eficiencia de la asignación de objetos. Sin embargo, no importa desde qué punto de vista, no importa cuán dividido, no cambiará el carácter común del contenido de almacenamiento en el montón de Java. No importa en qué área, solo puede almacenar instancias de objetos. El propósito de subdividir el montón de Java es solo para reciclar mejor la memoria o asignar memoria más rápido.
De acuerdo con la "Especificación de la máquina virtual de Java", el montón de Java puede estar en un espacio de memoria físicamente discontinuo, pero lógicamente debe considerarse continuo, al igual que usamos el espacio en disco para almacenar archivos, no Cada archivo debe almacenarse de forma contigua. . Pero para objetos grandes (por lo general, como objetos de matriz), es probable que la mayoría de las implementaciones de máquinas virtuales requieran espacio de memoria continuo en aras de una implementación simple y un almacenamiento eficiente.
El almacenamiento dinámico de Java se puede implementar como un tamaño fijo o expandible, pero las máquinas virtuales de Java principales actuales se implementan de acuerdo con el expandible (establecido por los parámetros -Xmx y -Xms). Si no hay memoria en el montón de Java para completar la asignación de instancias y el montón ya no se puede expandir, la máquina virtual de Java generará una excepción OutOfMemoryError.
3 Pila de máquina virtual
El espacio de memoria requerido por cada subproceso para ejecutarse se convierte en una pila de máquina virtual;
el subproceso es privado y su ciclo de vida es consistente con el subproceso;
cada pila se compone de múltiples marcos de pila, correspondientes a la memoria ocupada por cada uno llamada al método;
Cada subproceso puede tener solo un marco de pila activo, correspondiente al método que se está ejecutando actualmente.
Describe el modelo de memoria de la ejecución del método Java: cada método creará un marco de pila (Stack Frame) para almacenar la tabla de variables locales, la pila de operandos, el enlace dinámico, la salida del método y otra información cuando se ejecuta. Desde la llamada hasta el final de la ejecución, cada método corresponde al proceso de un marco de pila que se empuja desde la pila de la máquina virtual para sacarlo de la pila.
StackOverflowError: la profundidad de pila solicitada por el subproceso es mayor que la profundidad permitida por la máquina virtual.
OutOfMemoryError: si la pila de la máquina virtual se puede expandir dinámicamente, pero no puede solicitar suficiente memoria al expandirse.

4 Contador de programa
El contador de programa (ProgramCounterRegister) es un pequeño espacio de memoria, que puede considerarse como el indicador de número de línea del código de bytes ejecutado por el subproceso actual, que apunta al siguiente código de instrucción a ejecutar, y el motor de ejecución lee el siguiente instrucción de código de instrucción. Más precisamente, la ejecución de un subproceso es cambiar el valor del contador del subproceso actual a través del intérprete de bytecode para obtener la siguiente instrucción de bytecode que debe ejecutarse, para garantizar la correcta ejecución del subproceso.
Contiene la dirección de la instrucción que se está ejecutando actualmente, una vez que se ejecuta el programa, el contador del programa se actualizará a la siguiente instrucción.
Para garantizar que se pueda restaurar la posición de ejecución correcta después del cambio de subproceso (cambio de contexto), cada subproceso tiene un contador de programa independiente, y los contadores de cada subproceso no se afectan entre sí y se almacenan de forma independiente . En otras palabras, el contador del programa es memoria privada de subprocesos.
5 Pila de métodos nativos
Las pilas de métodos nativos (NativeMethodStacks) son muy similares a las pilas de máquinas virtuales Sirven el método local (Nativo) utilizado por la máquina virtual .
La "Especificación de máquina virtual de Java" no tiene regulaciones obligatorias sobre el idioma, el uso y la estructura de datos de los métodos en la pila de métodos local.
Por lo tanto, la máquina virtual específica puede implementarlo libremente de acuerdo con las necesidades, e incluso algunas máquinas virtuales Java (como la máquina virtual Hot-Spot) combinan directamente la pila de métodos locales y la pila de la máquina virtual en una sola. Al igual que la pila de la máquina virtual, la pila de métodos locales también generará excepciones StackOverflowError y OutOfMemoryError cuando la profundidad de la pila se desborde o la expansión de la pila falle.
6 Memoria directa
La memoria directa (DirectMemory) no forma parte del área de datos de tiempo de ejecución de la máquina virtual, ni es el área de memoria definida en la "Especificación de máquina virtual Java". Pero esta parte de la memoria también se usa con frecuencia y también puede causar una excepción OutOfMemoryError, por lo que la ponemos aquí para explicarlo juntos.
En JDK1.4, se agregó recientemente la clase NIO (NewInput/Output) y se introdujo un método de E/S basado en Channel (Channel) y Buffer (Buffer) Puede usar la biblioteca de funciones nativas para asignar directamente memoria fuera del montón y, a continuación , operar a través de un objeto DirectByteBuffer almacenado en el montón de Java como referencia a esta memoria. Esto puede mejorar significativamente el rendimiento en algunos escenarios, ya que evita copiar datos entre el montón de Java y el montón nativo .
Obviamente, la asignación de memoria directa de la máquina no estará limitada por el tamaño del montón de Java, pero dado que es memoria, definitivamente estará limitada por la memoria total de la máquina (incluida la memoria física, la partición SWAP o el archivo de paginación) y el espacio de direccionamiento del procesador. Generalmente, cuando los administradores del servidor configuran los parámetros de la máquina virtual, configurarán -Xmx y otra información de parámetros de acuerdo con la memoria real, pero a menudo ignoran la memoria directa, haciendo que la suma de cada área de memoria sea mayor que la límite de memoria física (incluido el límite de nivel físico y del sistema operativo), lo que genera una excepción OutOfMemoryError durante la expansión dinámica.
4. Motor de ejecución
Aunque no todas las máquinas virtuales Java adoptan la arquitectura en ejecución en la que coexisten el intérprete y el compilador, las máquinas virtuales comerciales de Java actuales, como HotSpot, OpenJ9, etc., contienen tanto el intérprete como el compilador internamente.
Dos (o tres) compiladores justo a tiempo están integrados en la máquina virtual HotSpot, dos de los cuales existen desde hace mucho tiempo y se denominan "Compilador de cliente" y "Compilador de servidor" respectivamente, o compilador C1 y compilador C2 para abreviar (C2 también se llama compilador Opto en algunos materiales y código fuente de JDK), el tercero es el compilador Graal que solo apareció en JDK10, y el objetivo a largo plazo es reemplazar a C2.
recolección de basura (GC)
La recolección de basura manual no es posible, solo recordatorios manuales, esperando que la JVM reclame automáticamente el
área de GC Cuando la JVM realiza GC en el montón (Heap) y el área de método
, estas tres áreas (área nueva, área superviviente y área antigua) no están unificados Reciclaje, la recuperación es la nueva generación.
Light GC (GC ordinario) es solo para el área de nueva generación, y ocasionalmente afecta el área de supervivencia (cuando el área de nueva generación está llena). Heavy
GC (GC global) libera memoria globalmente
14. Algoritmos comunes de recolección de basura
1. Referencias El principio del algoritmo de conteo
es que el objeto tiene una referencia, es decir, se aumenta un conteo, se elimina una referencia y se disminuye un conteo. Durante la recolección de elementos no utilizados, solo se utilizan objetos con un recuento de recolección de 0. El problema más fatal de este algoritmo es que no puede manejar referencias circulares.
2. Algoritmo de copia
Este algoritmo divide el espacio de memoria en dos áreas iguales y solo usa una de las áreas a la vez. Durante la recolección de basura, recorra el área utilizada actualmente, copie los objetos en uso en otra área y recicle los objetos no utilizados al mismo tiempo. Este algoritmo solo procesa los objetos en uso cada vez, por lo que el costo de la copia es relativamente pequeño y, al mismo tiempo, la organización de la memoria correspondiente se puede realizar después de la copia.
Ventajas: no habrá problemas de fragmentación
Desventajas: se requiere el doble de espacio de memoria, desperdiciando
3. Algoritmo de borrado de marcas
Este algoritmo se ejecuta en dos etapas. La primera etapa comienza desde el nodo raíz de referencia para marcar los objetos supervivientes utilizados, y la segunda etapa atraviesa todo el montón para borrar los objetos no marcados.
Ventajas: No se desperdicia espacio de memoria.
Desventajas: Este algoritmo necesita suspender toda la aplicación y, al mismo tiempo, se producirá la fragmentación de la memoria.
4. Algoritmo de compresión de marcas
Este algoritmo combina las ventajas de los algoritmos de "borrar marcas" y "copiar". También se divide en dos fases. La primera fase marca todos los objetos supervivientes a partir del nodo raíz. La segunda fase atraviesa todo el montón, borra los objetos no marcados y "comprime" los objetos supervivientes en uno de los montones, y los descarga en orden. .
Este algoritmo evita el problema de fragmentación del "barrido de marcas" y también evita el problema de espacio del algoritmo de "copia".
Estrategia de reciclaje generacional
1. La mayoría de los objetos recién creados se almacenarán en el área Eden
2. Cuando el área Eden esté llena por primera vez, se activará MinorGC (light GC). Primero, los objetos de basura en el área de Eden se recuperan y limpian, y los objetos supervivientes se copian en S0, y S1 está vacío en este momento.
3. La próxima vez que el área de Eden esté llena, vuelva a realizar la recolección de basura. Esta vez, todos los objetos de basura en las áreas de Eden y S0 se borrarán, y los objetos supervivientes se copiarán en S1, y S0 quedará vacío en este momento. .
4. Después de cambiar entre S0 y S1 varias veces (predeterminado 15 veces), los objetos sobrevivientes se transferirán a la generación anterior.
5. FullGC (GC completo) se activará cuando la generación anterior esté llena. El algoritmo utilizado por
MinorGC es un algoritmo de copia . Se activará cuando el espacio de almacenamiento dinámico de la generación joven sea reducido. En comparación con la recopilación completa, el intervalo de recopilación es más corto. El algoritmo utilizado por FullGC Cuando el espacio de almacenamiento dinámico de la generación anterior está lleno, se activará una operación de recopilación completa. Puede utilizar el método System.gc() para iniciar explícitamente la recopilación completa. La recopilación completa es muy pérdida de tiempo