Для больших моделей переобучение с полной тонкой настройкой всех параметров модели становится невозможным. Например, ГПТ-3 175Б, содержит ли модель параметры 175Б, будь то доводка обучения и развертывание модели, это невозможно. Поэтому Microsoft предложила адаптацию низкого ранга (Low-Rank Adaptation, LoRA), которая замораживает веса предварительно обученной модели и вводит обучаемую матрицу декомпозиции ранга в каждый уровень архитектуры Transformer, тем самым значительно уменьшая количество обучаемых параметров для последующих задач. .
ЛоРА
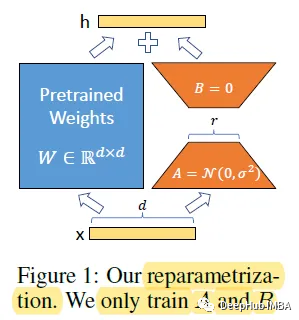
Для предварительно обученной весовой матрицы W0 можно сделать ее обновления зависимыми от последней, выраженной разложением низкого ранга:
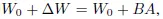
Во время обучения W0 заморожен и не получает обновлений градиента, а A и B содержат обучаемые параметры. Когда h=W0x, модифицированное прямое распространение принимает вид:
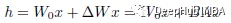
Используйте случайную гауссовскую инициализацию для A и нулевую инициализацию для B, поэтому ΔW = BA равно нулю в начале обучения (это необходимо отметить).
Преимущество этого подхода заключается в том, что при развертывании в рабочей среде необходимо вычислять и сохранять только W = W0 + BA, а логический вывод выполняется как обычно. По сравнению с другими методами здесь нет дополнительной задержки, потому что больше не нужно присоединять слои.
В архитектуре Transformer имеется четыре матрицы весов (Wq, Wk, Wv, Wo) в модуле внутреннего внимания и две матрицы весов в модуле MLP. LoRA регулирует веса внимания только для последующих задач и замораживает модуль MLP. Таким образом, для больших трансформеров использование LoRA может сократить использование видеопамяти на 2/3. Например, на GPT-3 175B использование LoRA может снизить потребление видеопамяти во время обучения с 1,2 ТБ до 350 ГБ.
Отображение результатов

Для оценки использовались предварительная подготовка RoBERTa base (125M), RoBERTa large (355M) и DeBERTa XXL (1,5B) в библиотеке HuggingFace Transformers. Они дорабатываются различными методами тонкой настройки.
Использование LoRA в большинстве случаев дает наилучшую производительность на GLUE.

Сравнение количества обучаемых параметров нескольких адаптивных методов для GPT-3 175B в WikiSQL и сопоставлении mnli

Видно, что при использовании GPT-3 LoRA соответствует или превосходит точно настроенные базовые уровни для всех трех наборов данных.
Стабильная диффузия
Лора впервые применил модель большого языка, но его приложение для SD может быть известно большему количеству людей:

В случае тонкой настройки Stable Diffusion LoRA может применяться к слою перекрестного внимания, который соединяет представления изображений с описывающими их сигналами. Детали изображения ниже не важны, просто знайте, что желтые блоки отвечают за построение отношений между изображением и текстовым представлением.
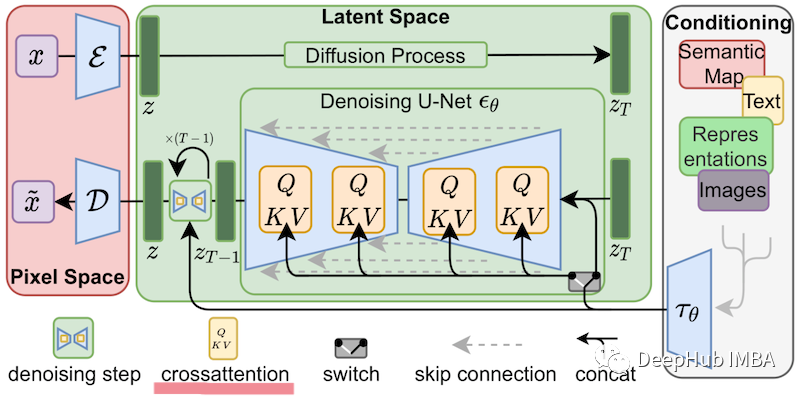
Таким образом, вы можете видеть, что пользовательская модель Лоры, обученная таким образом, будет очень маленькой.
Мой личный эксперимент: для стабильной диффузии требуется как минимум 24 ГБ видеопамяти для всесторонней тонкой настройки. Но с Lora однопроцессное обучение с пакетом размером 2 может быть выполнено на одном графическом процессоре 12 ГБ (10 ГБ без xformer, 6 ГБ с xformer).
Таким образом, Lora также является очень хорошим способом тонкой настройки модели в области генерации изображений. Если вы хотите узнать больше, вот адрес газеты:
https://avoid.overfit.cn/post/407a85d672384969848f8bc5cb9bc5fe