prefacio
Hace dos días, de repente quise construir un mapa de IA, pero me quedé atónito. La dirección de lgithub, como resultado, Quanying no podía entenderlo. Solo sabía sobre Stable Diffusion. Fui a aprender sobre él en el pasado . dos días. Si quiero una versión web, quiero Stable Diffusion. WebUI, traté de construirlo en mi computadora portátil y encontré varios tutoriales. Mi pequeña computadora rota tuvo varios problemas y se bloqueó para mí. Cuando regresé de salir del trabajo por la noche, no sabía qué tutorial seguir. Me di cuenta de que estaba a punto de tener éxito al final. . .
No tengo más remedio que gg. El portátil que compré en los últimos 18 años, la memoria 8g integrada no puede agregar una tarjeta de memoria, y la tarjeta gráfica también es vieja. Solo puedo encontrar una manera. Acabo de ver que Alibaba Cloud tiene una versión de prueba, así que lo probé durante un mes.
Luego tomé prestado este tutorial: https://blog.csdn.net/weixin_39955411/article/details/128435879
Pero se encontraron varios problemas en el medio, y luego los resumí a altas horas de la noche.
texto
1. Selección de máquina
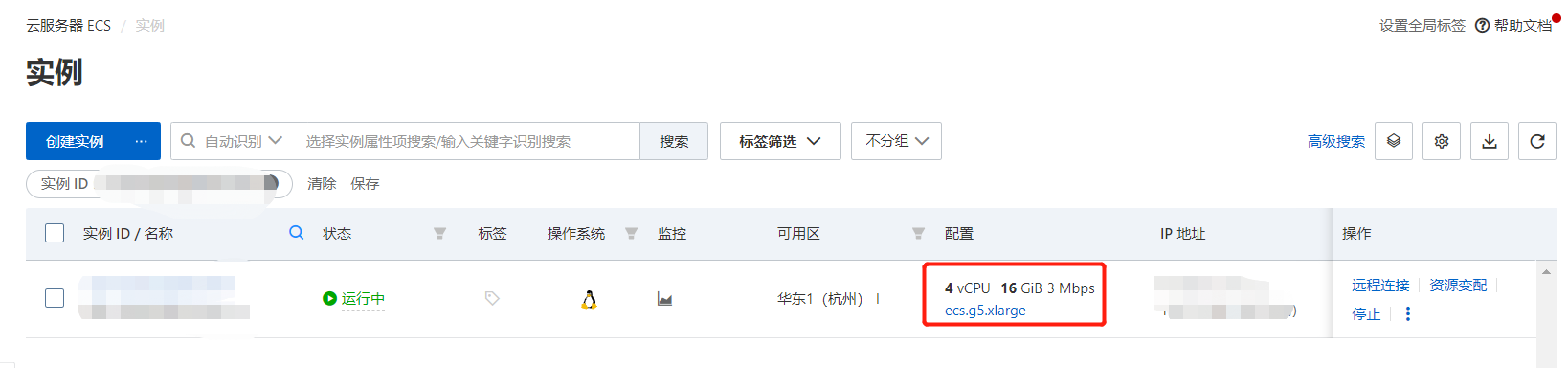
Elegí la máquina de prueba Aliyun, la máquina de prueba no tiene GPU, si la compras tú mismo, recuerda comprar una GPU
El enlace de prueba está aquí: https://www.aliyun.com/daily-act/ecs/activity_selection?userCode=xnfx4mew , la empresa que elegí pasó sin saber por qué, aquí hay una imagen
La prueba es exitosa y entra en la gestión de instancias.
Espere 3 minutos y restablezca la contraseña usted mismo
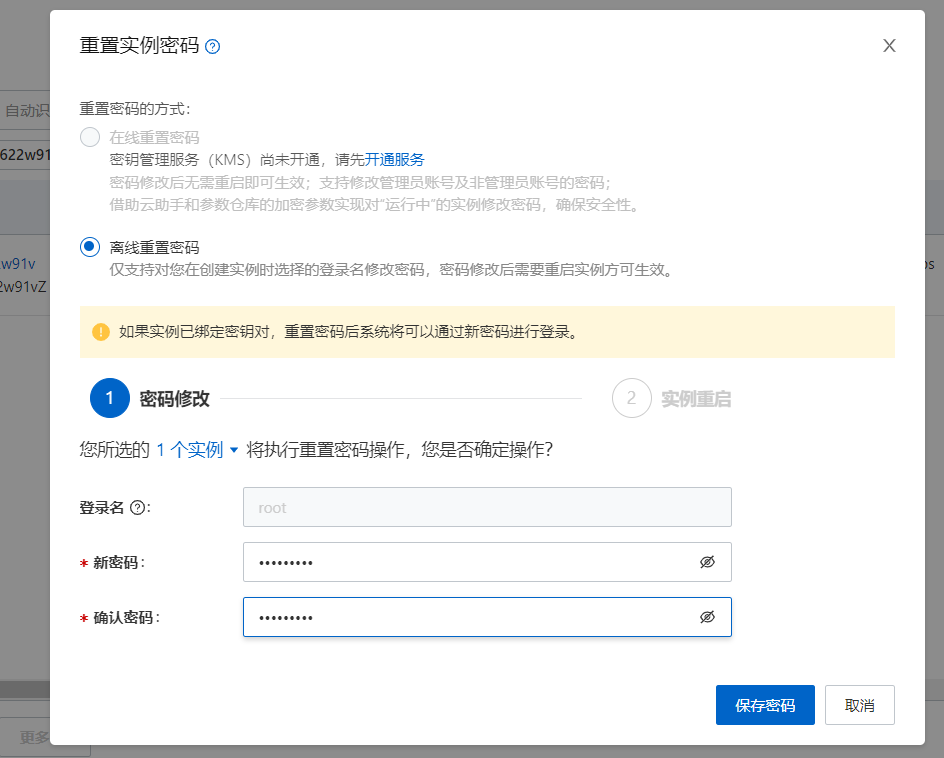
Entonces simplemente conéctese a Xshell usted mismo.
2. Construcción del entorno
1. Instalar el entorno virtual de Python
# Instale el entorno de python
sudo apt install wget git python3 python3-venv
En este momento, informé el siguiente error. Si se informa este error, actualice la biblioteca APT. Si no se informa este error, se puede ejecutar normalmente y luego pasar a 2
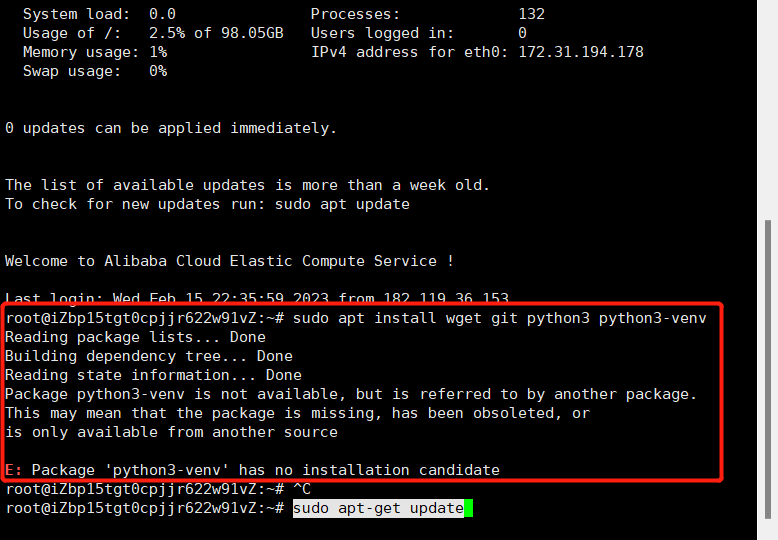
Actualizar repositorio APT
sudo apt-get update
sudo apt-get upgrade
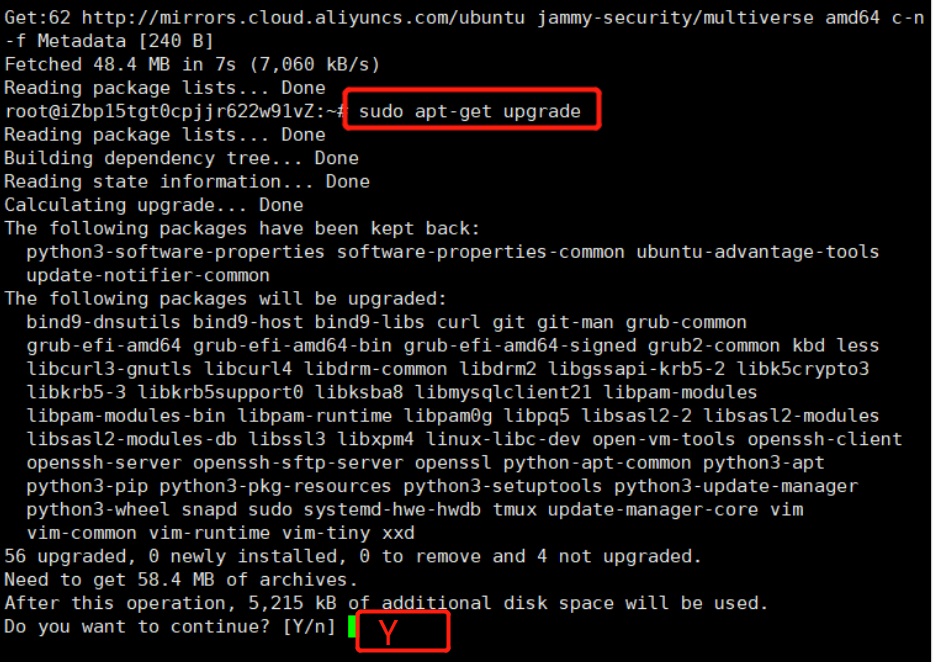
更新APT库的时候,Xshell页面可能会出现这种,不用管,默认的直接回车就行
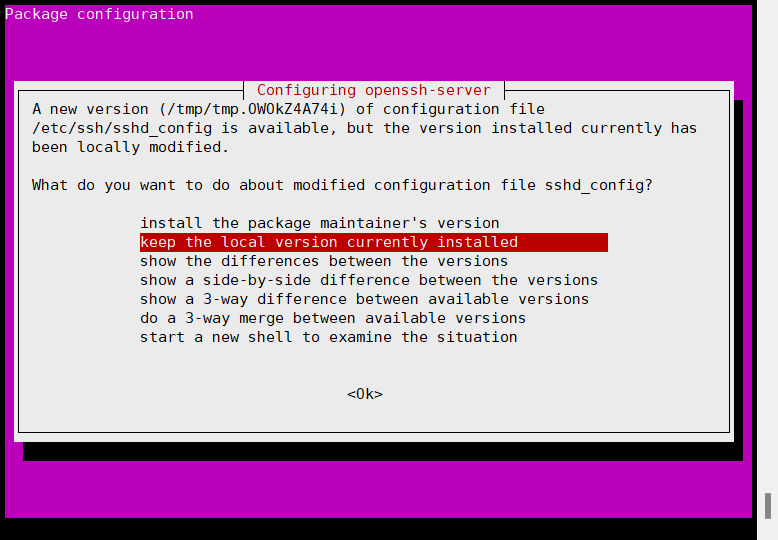
等最后会让你重启服务,回车之后就自动重启了下,然后再执行上面这个代码
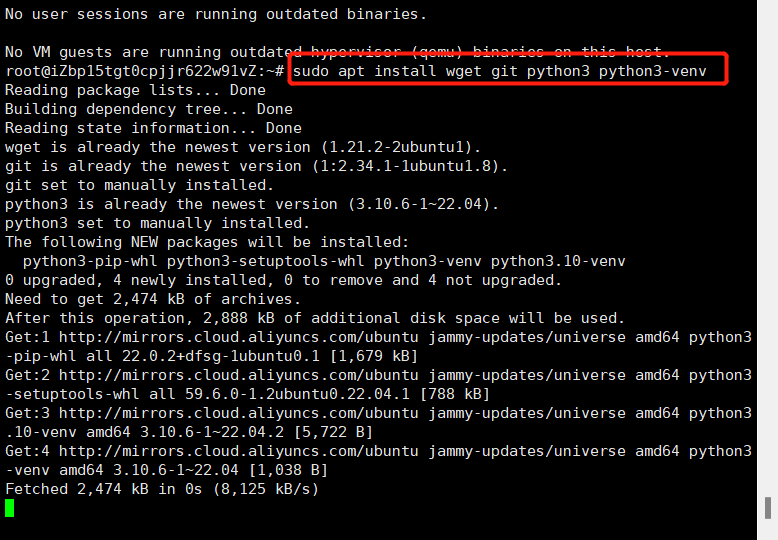
sudo apt install wget git python3 python3-venv
此时就会成功
2、创建非root用户
我最初没创建非root用户,直接用root用户去拉取文件并且执行,于是就有了这个错误
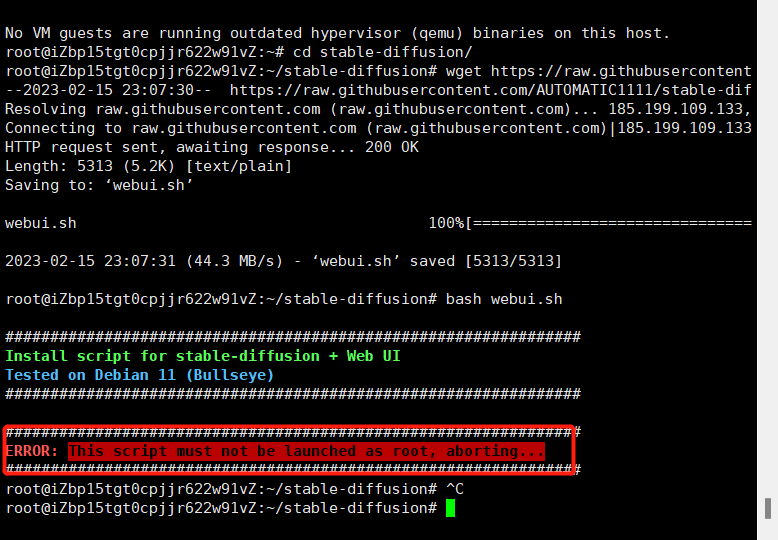
2.1错误列举
解决办法就是创建一个非root用户,然后再去执行。这里我最初采用我参考的上面那个方法创建
adduser --home /sean/sean
但是这样我发现依旧不行,执行 bash webui.sh 的时候报错
ERROR: Can’t cd to /home/sean/, aborting…
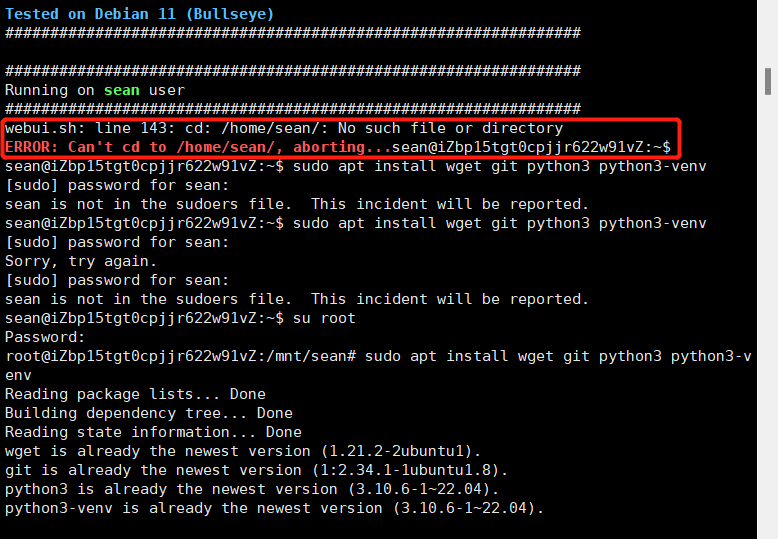
2.2错误分析
我去看了这行代码,如果你 --home创建,他会去home目录下找你自己定义的这个用户目录,我的也就是/home/sean 目录,但是很显然没找到。
通过man useradd查看useradd命令的帮助

我们发现,由于 /etc/login.defs 配置文件中 CREATE_HOME 没有设置为yes,所以使用 adduser username 命令时,默认不建立home下对应目录,除非使用adduser -m username
所以我们要先去修改配置文件,然后再添加用户。
2.3错误解决
我们去 /etc 目录下找到 login.defs打开该配置文件vim /etc/login.defs,使用/CREATE_HOME搜索,无该词,使用G光标移至文档末尾,使用o换行插入,输入CREATE_HOME yes然后esc退出insert模式,:wq保存并退出文档。
(这里忘了截图了)
2.4开始创建
然后我们再创建用户,此时创建的用户自动在 /home 下
adduser sean
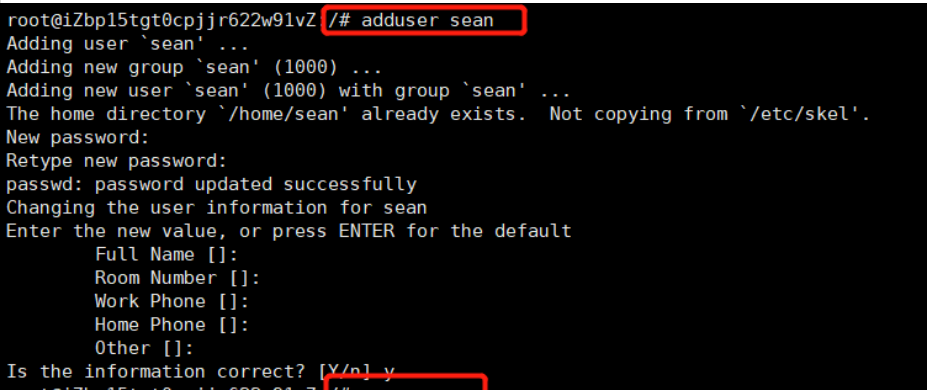
2.5 切换到创建的非root用户
然后我们切换用户到自己刚刚创建的
su sean

3、安装webui
然后开始安装webui
# 这里运行官方的自动化安装脚本webui.sh
wget https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
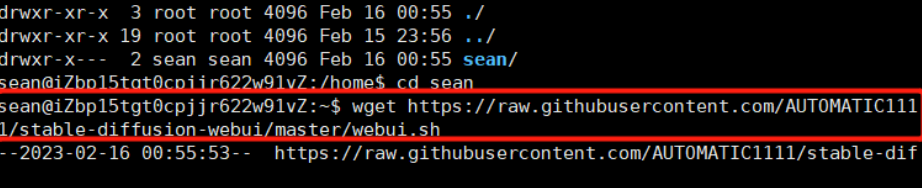
拉取完成,通过ll发现文件有了,然后开始执行
bash webui.sh
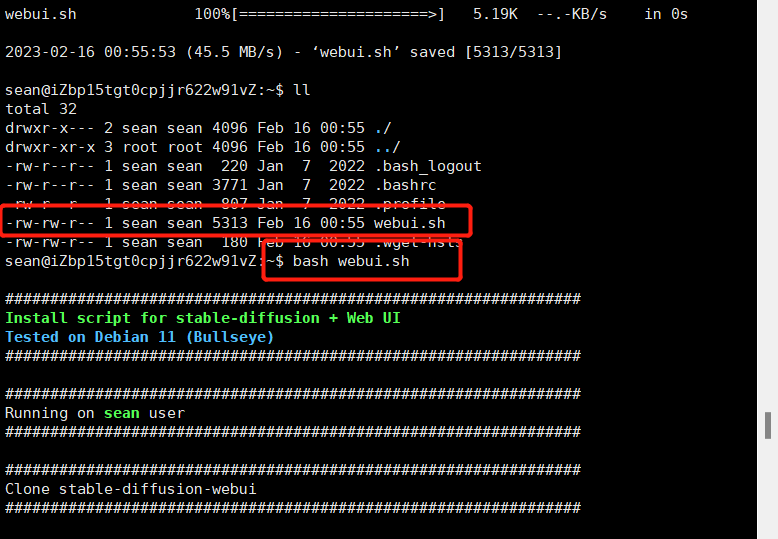
此时就可以顺利执行,自动下载了
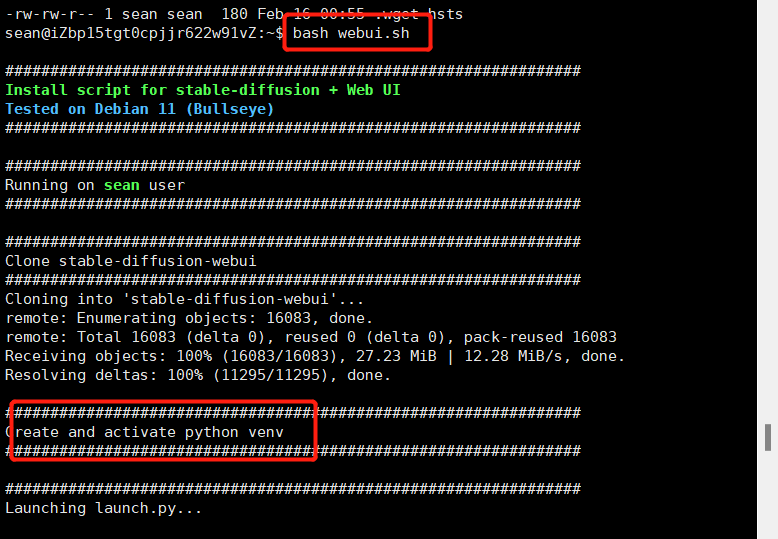
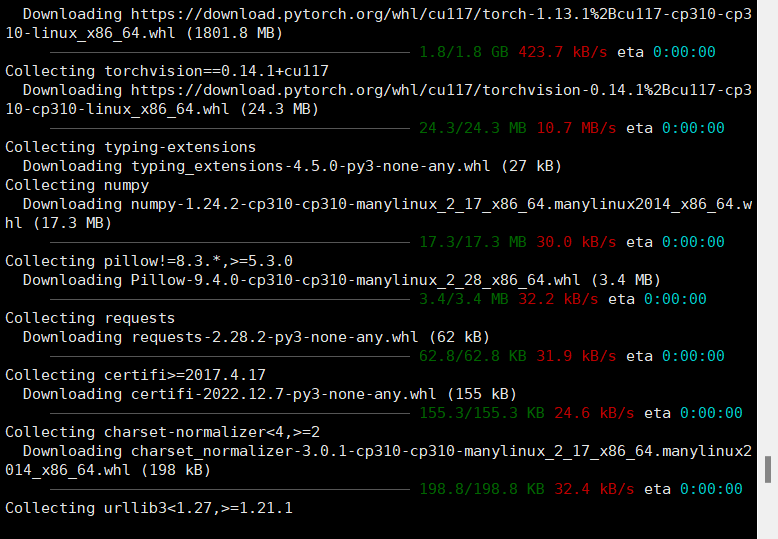
但是我发现我的报错了,如果报这样的错
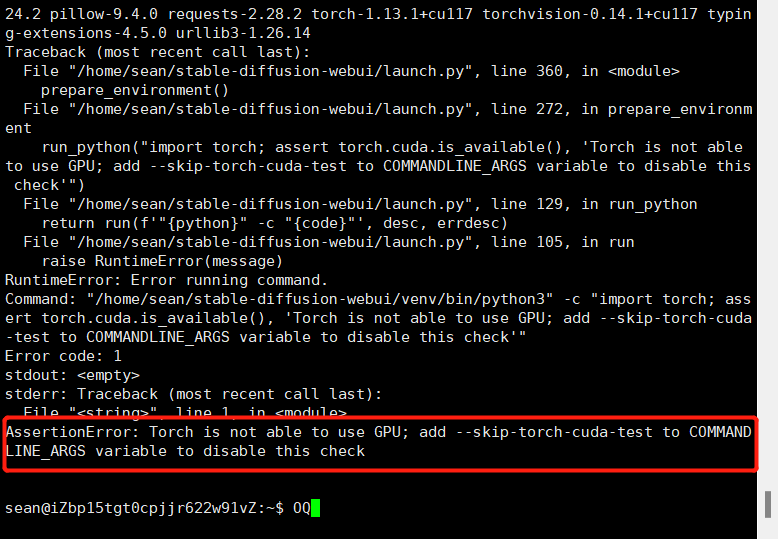
那么我们需要下载驱动,通过命令查看能下载那些
nvidia-smi
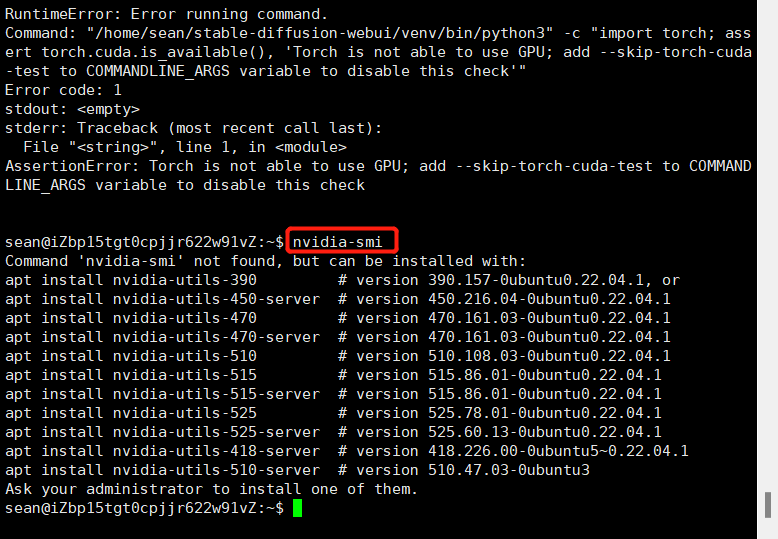
然后切换到管理员进行下载
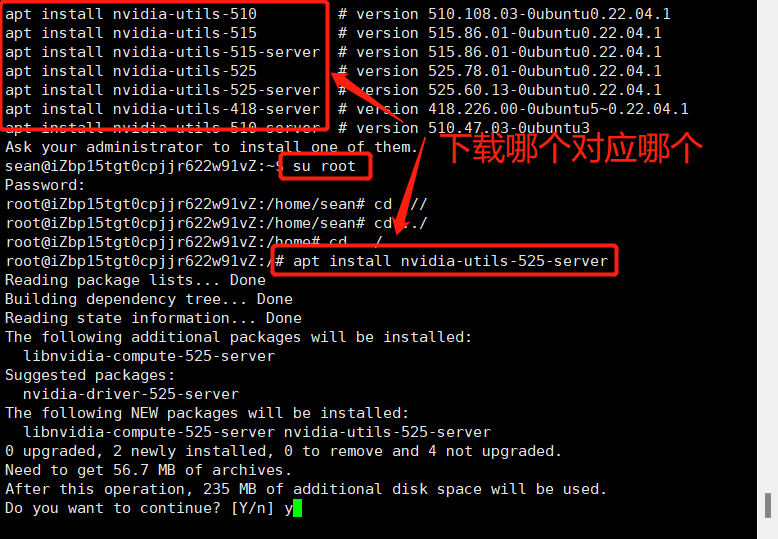
下载过程中还会出现这样的画面
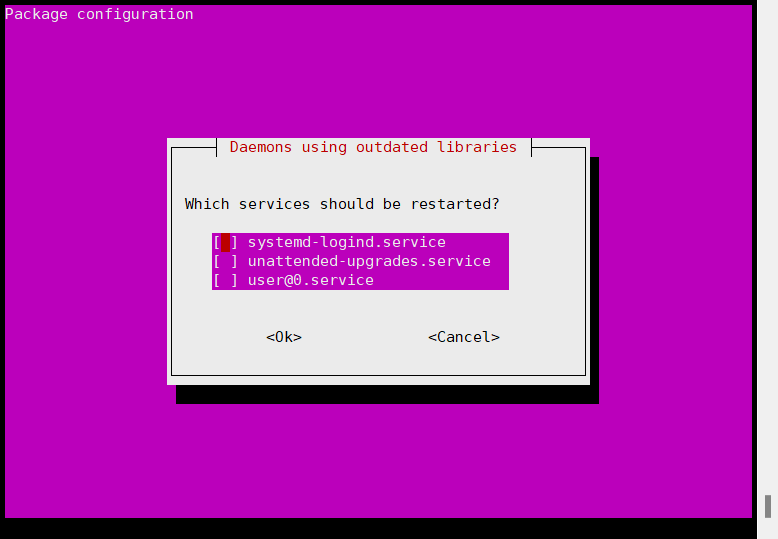
成功之后再次nvidia-smi,还是报错

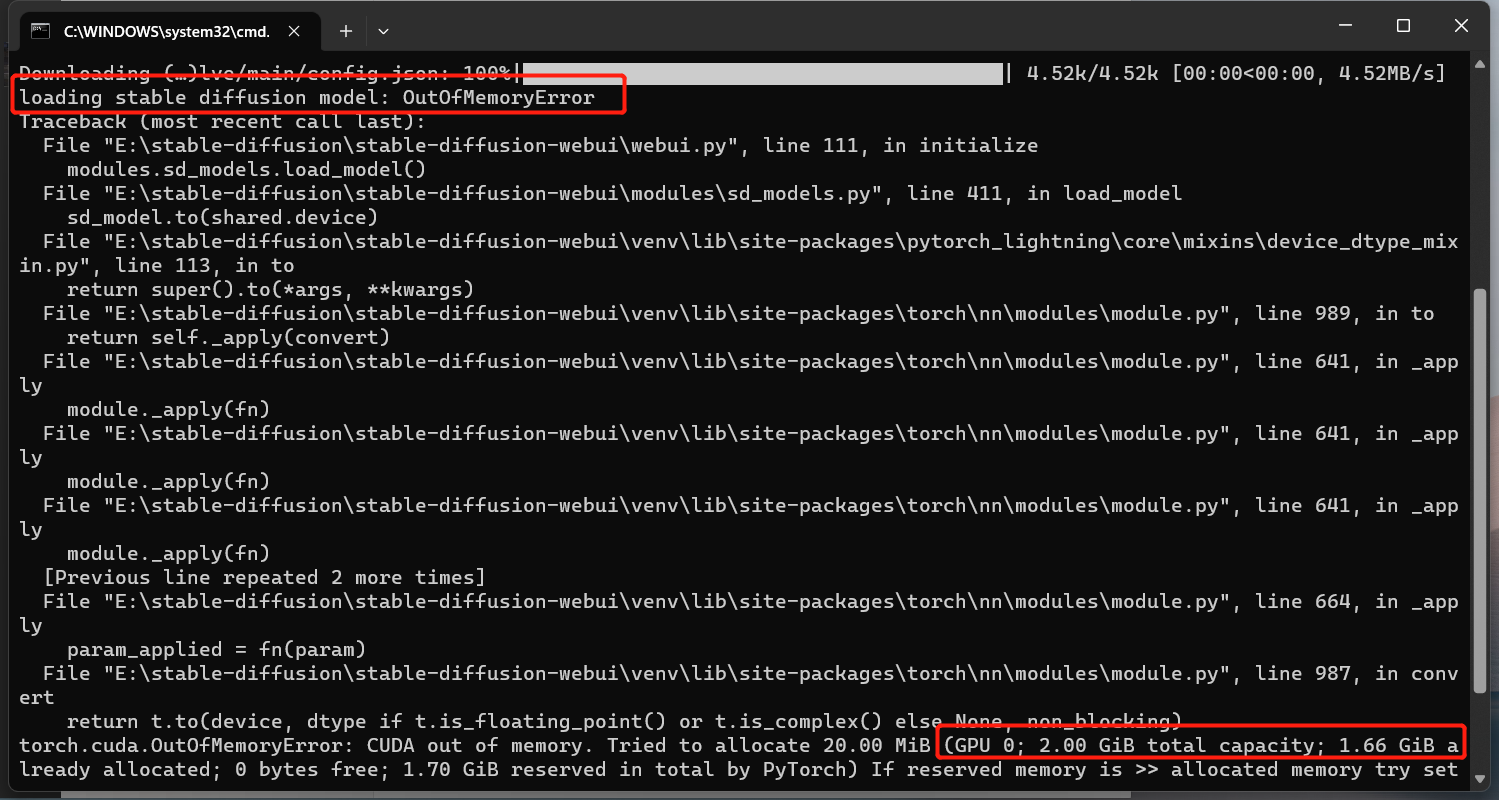
用命令一看,没出现型号,原来我的g5没GPU,没GPU的话上面这个错误就忽略掉,那就用CPU跑吧
lspci | grep -i nvidia
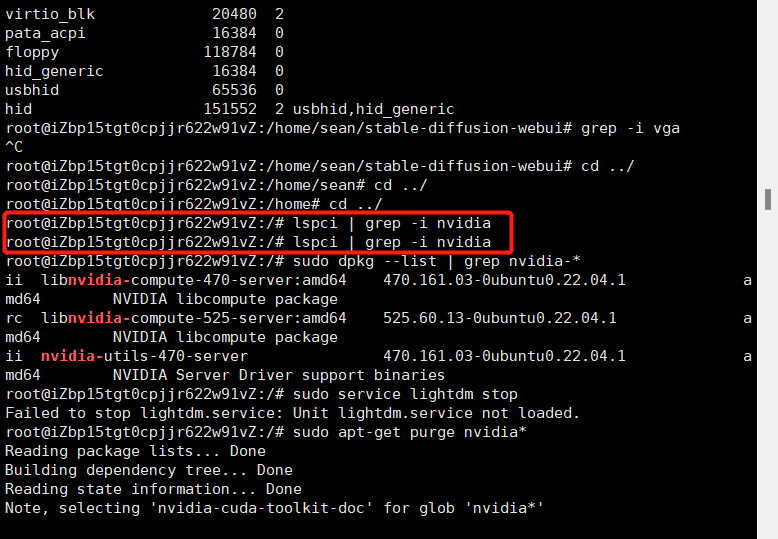
由于我下来了驱动,但是没有GPU,这里给删除了下
sudo apt purge nvidia*
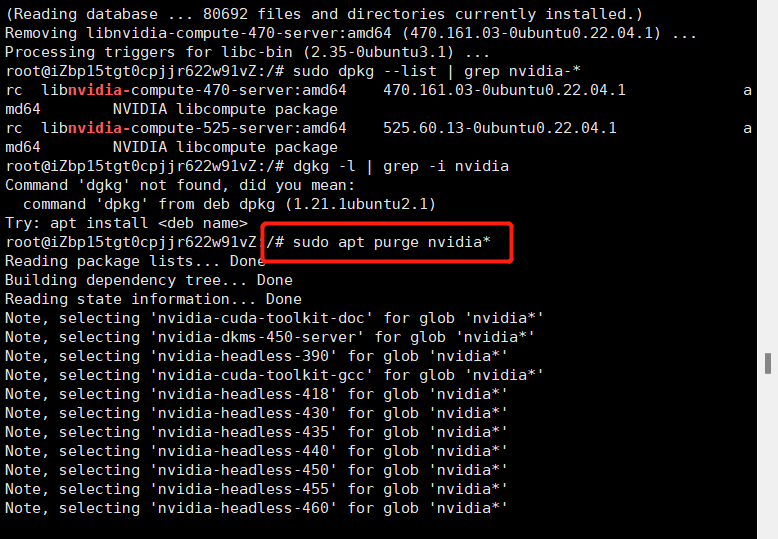
然后再执行下 nvidia-smi,发现已经没那个错误了,驱动清除了
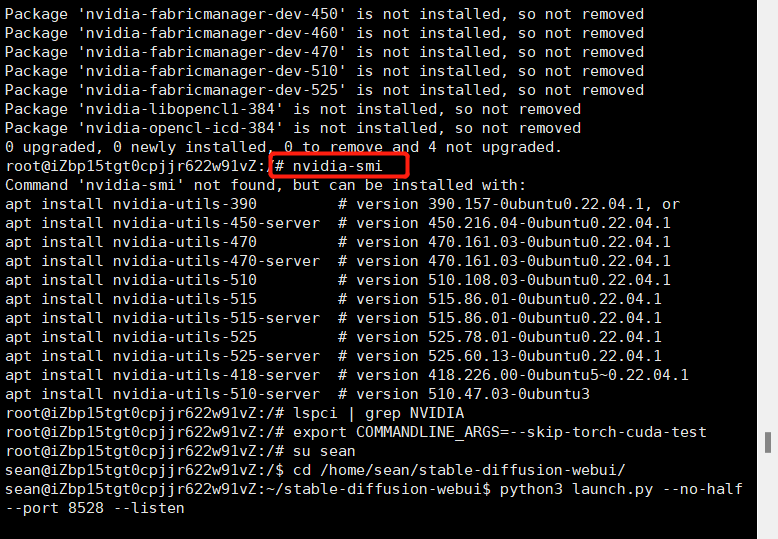
4、下载训练模型
模型其实很多,根据自己需求下载:https://huggingface.co/stabilityai/stable-diffusion-2
我这里是之前随手下了个1.4的训练模型,就直接拿来测试用了

我将下载好的模型改了个名字后放到了这里
/home/sean/stable-diffusion-webui/models/Stable-diffusion
根据自己的用户和拉取存放地址放进去

(也可以下载别的模型,如果下载的模型附带的有.yaml文件的话,连着文件一起改名字放进去,.yaml的文件命名需要和你的.ckpt前面一样)
番外、可能出现的错误
Can’t cd to /home/sean/, aborting…
ERROR: Can’t cd to /home/sean/, aborting…
这个错误再上面 创建非root用户 里已经给了解决方法。或者参考我参考的博主的方法:
手动下载链接: https://github.com/AUTOMATIC1111/stable-diffusion-webui

Torch is not able to use GPU
Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
这个错误我在上面 安装webui 里面也给了我自己的情况解决,如果是有GPU的电脑还出现这种错误,参考我参考的博主解决方法:
GPU驱动手动查找下载链接:https://www.nvidia.com/Download/index.aspx

HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443)
ReadTimeoutError: HTTPSConnectionPool(host=‘ files.pythonhosted.org’, port=443): Read timed out.
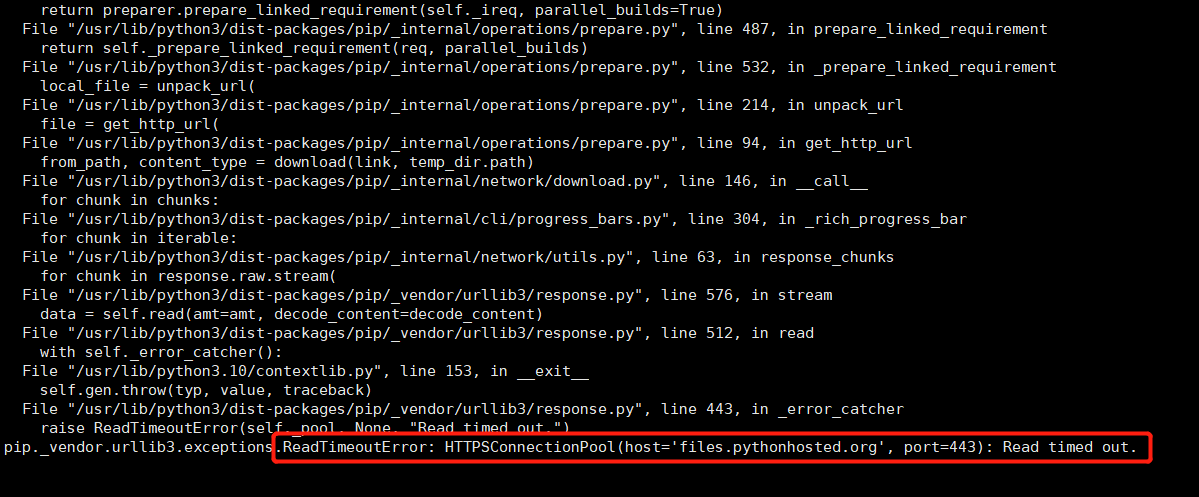
参考那位博主的解决办法,改成清华pip源:
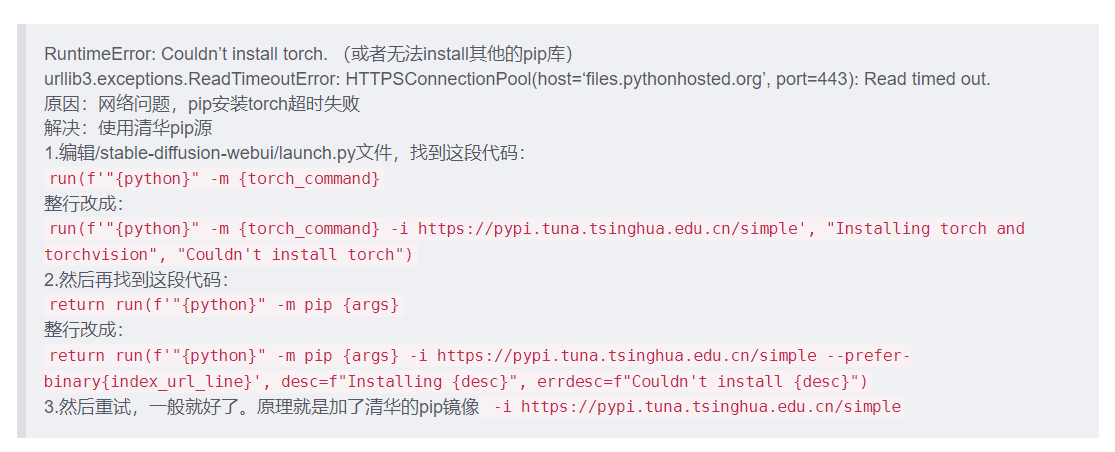
但是这里你去编辑的时候,一定一定不要直接复制粘贴替换,不然就会报缩进错误或者制表符空格错误!
就是下面4和5的错误!
IndentationError: unexpected indent
IndentationError: unexpected indent
TabError: inconsistent use of tabs and spaces in indentation
TabError: inconsistent use of tabs and spaces in indentation
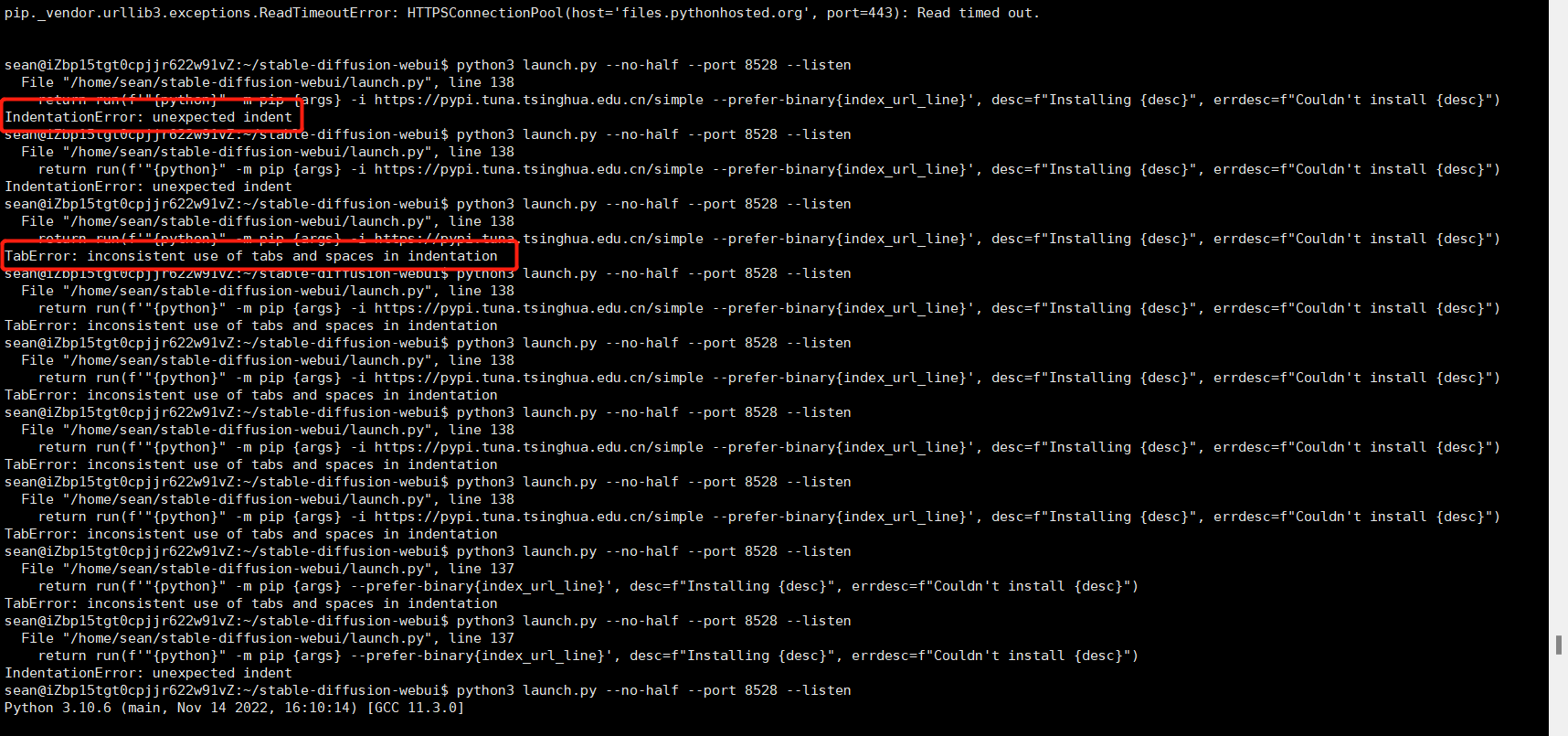
4 和 5 的解决办法其实一样,用Xshell自带的XFTP,编辑launch.py文件的时候,找到要改的这两处之后,不要直接复制粘贴,只需要在参数前面加上要加的东西就行,不要换行、缩进!
-i https://pypi.tuna.tsinghua.edu.cn/simple 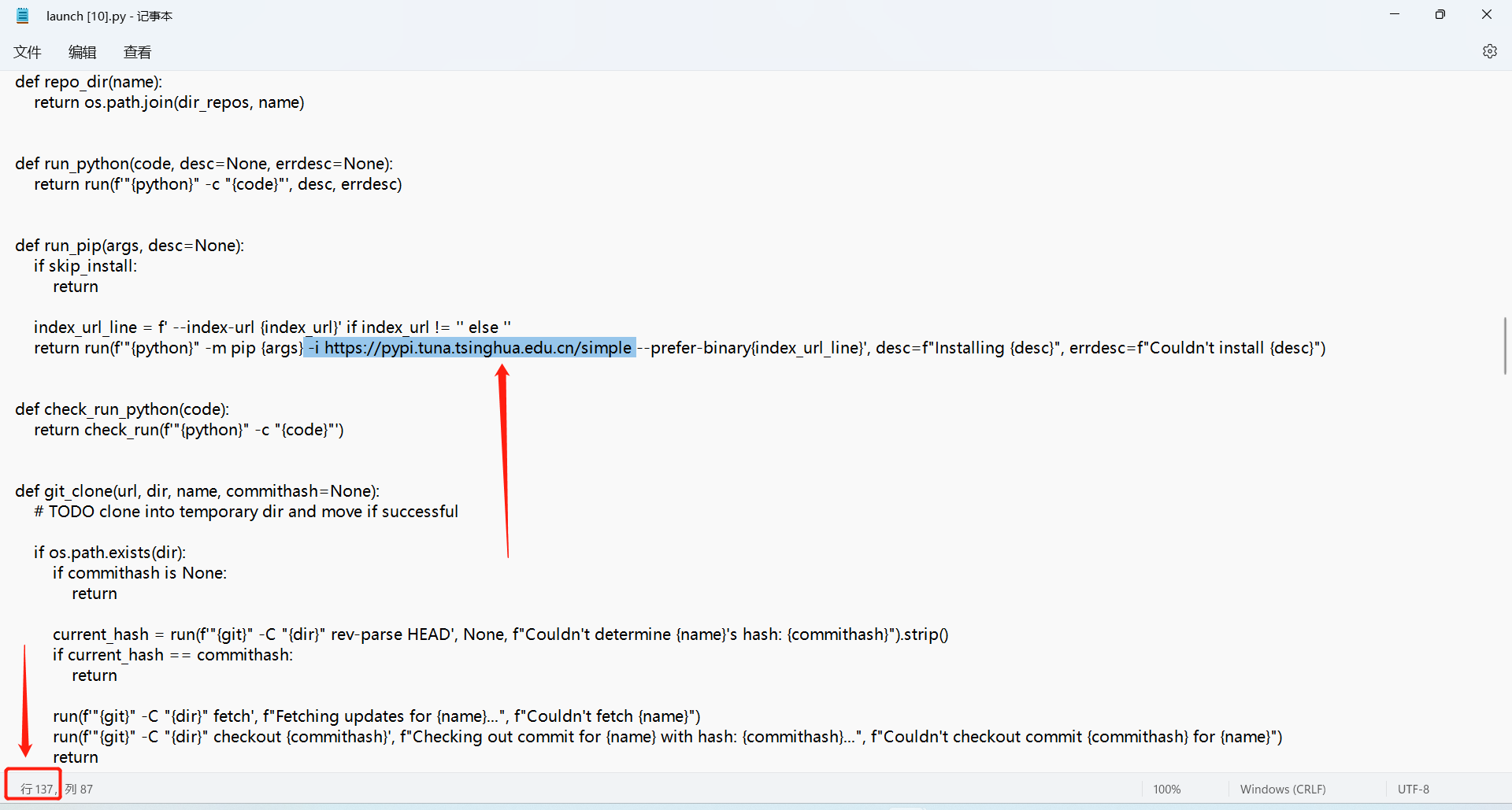
-i https://pypi.tuna.tsinghua.edu.cn/simple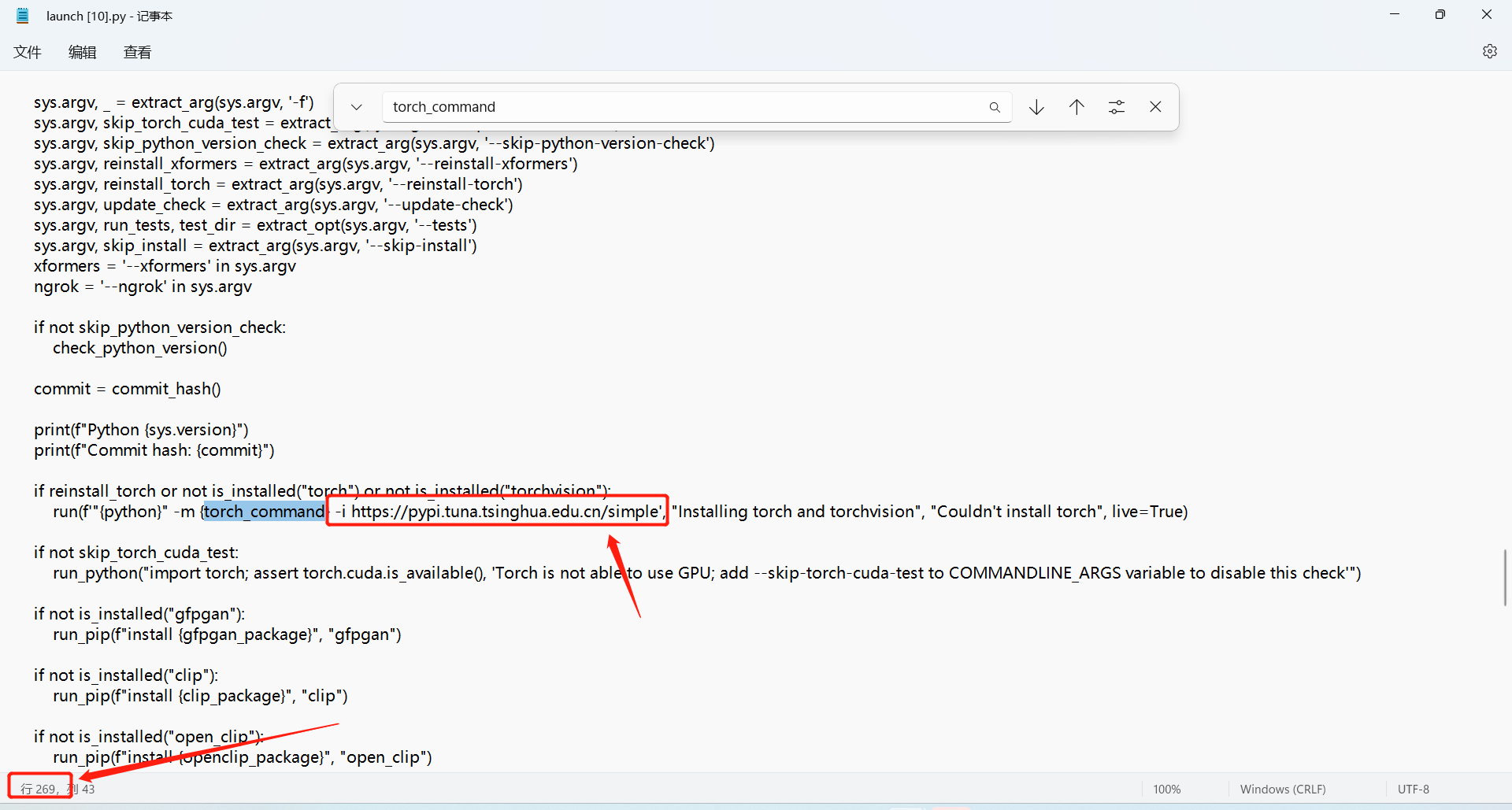
注意别加错!改好之后自己再按原有步骤去执行即可。贴一个我改好之后执行图,看下图里面的1,这里报了4的错误,我修改之后再次执行,不报 4错误了,看图里的 2 可以看出开始下载了,但是后面又报错了,报了6的错误。
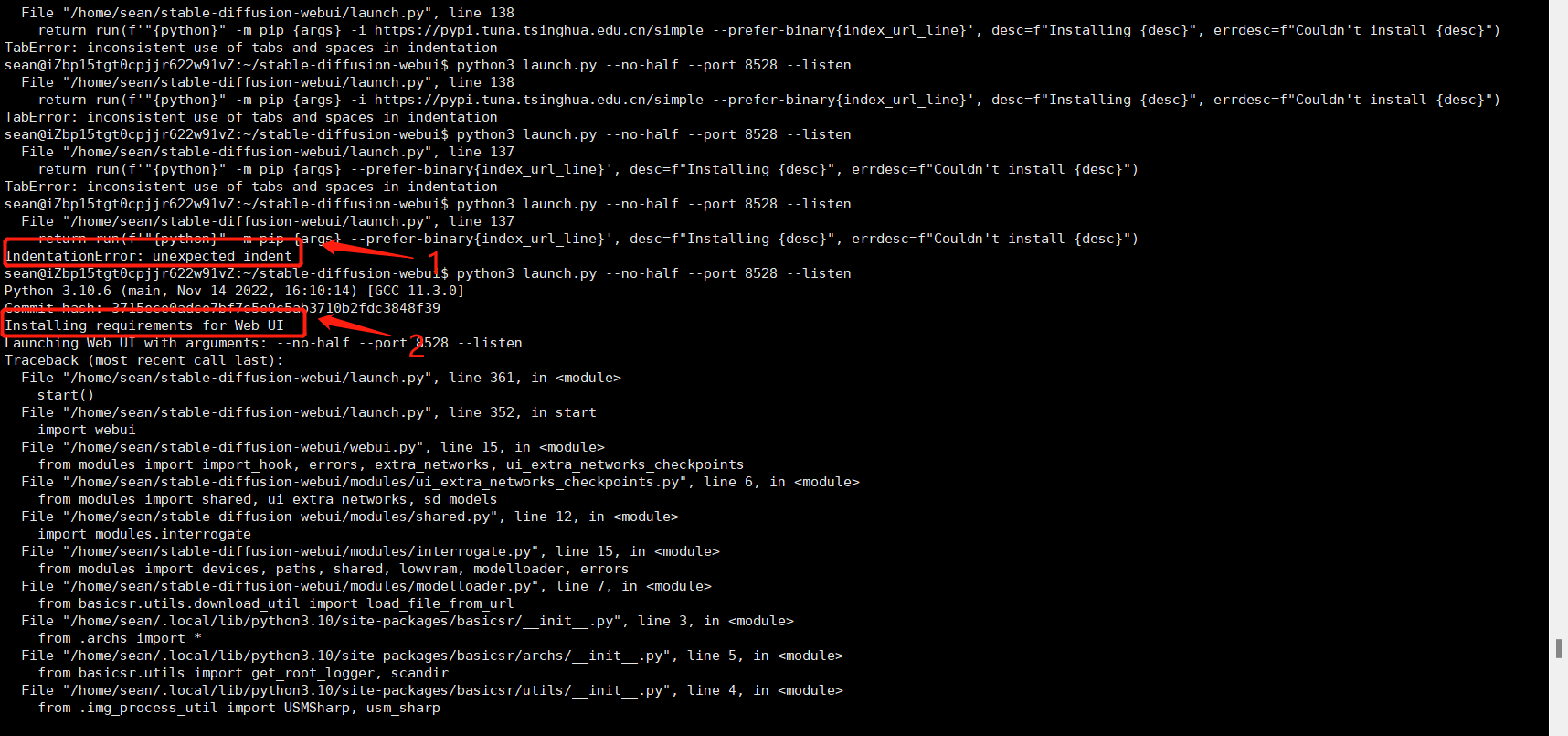
libGL.so.1: cannot open shared object file
ImportError: libGL.so.1: cannot open shared object file: No such file or directory
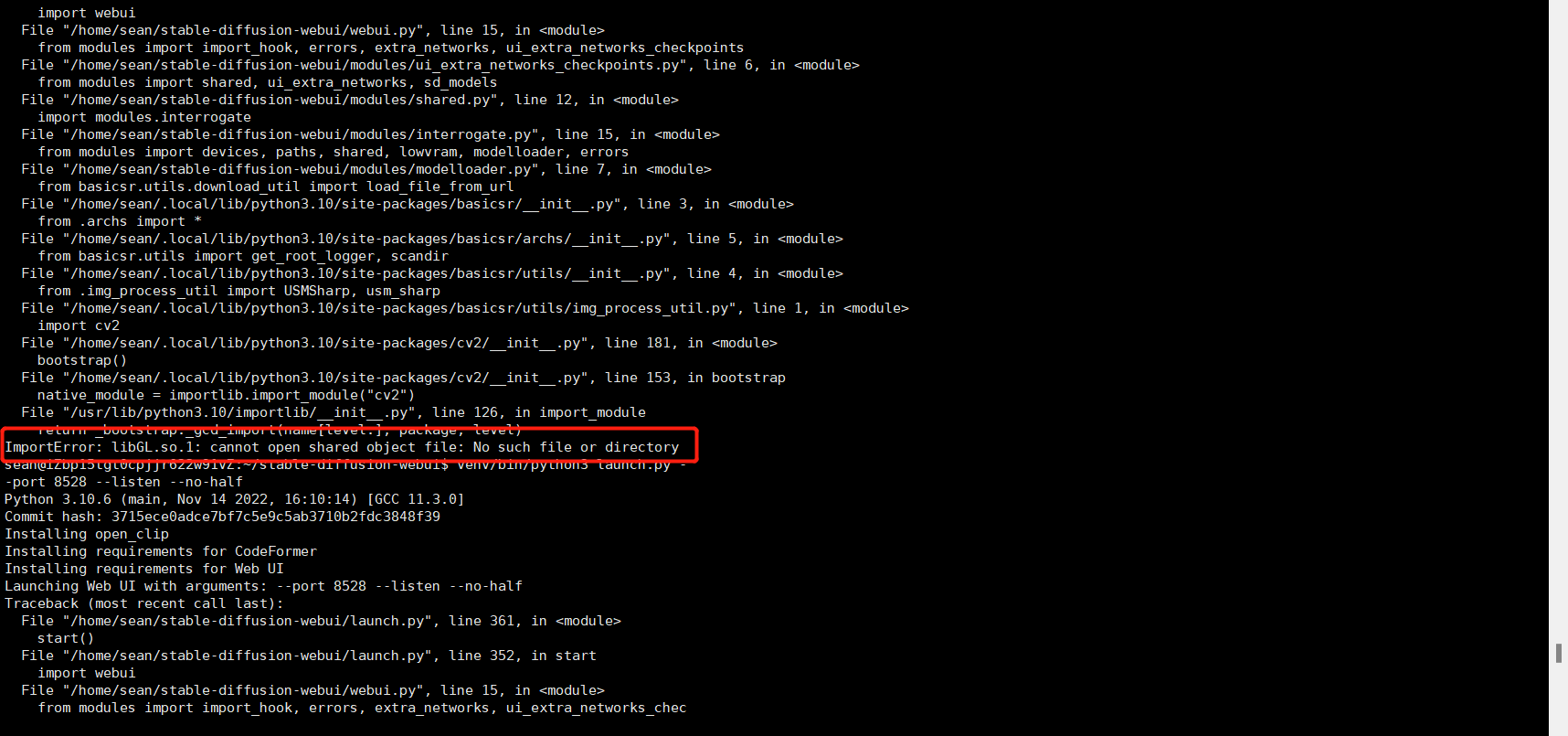
这个错误是无法打开共享文件,环境中缺少libGL.so.1文件,也就是缺少GL库文件,出现这种错误这样解决:(一定要进入到管理员 root 用户的根目录下)
1、更新apt-get:
apt-get update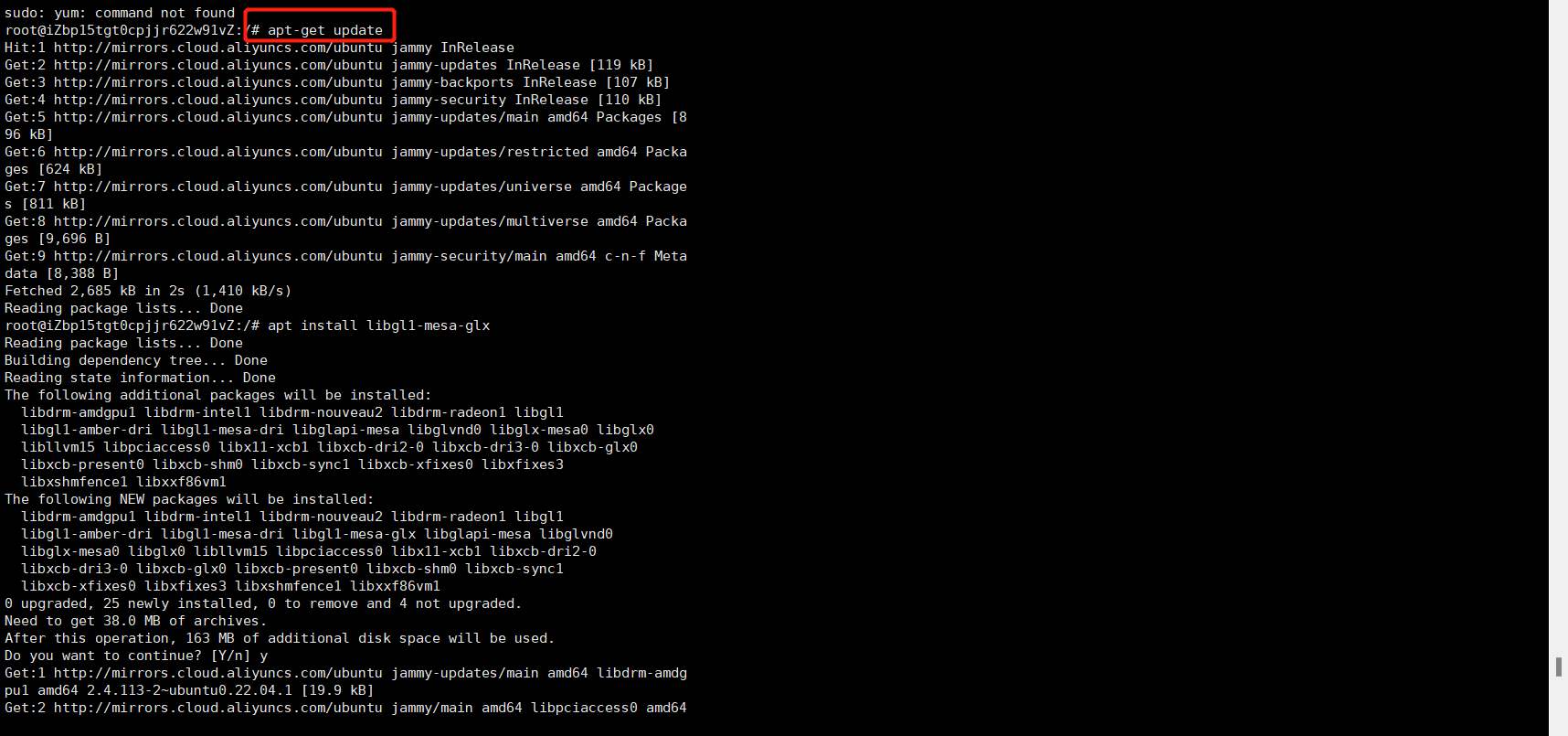
安装GL库
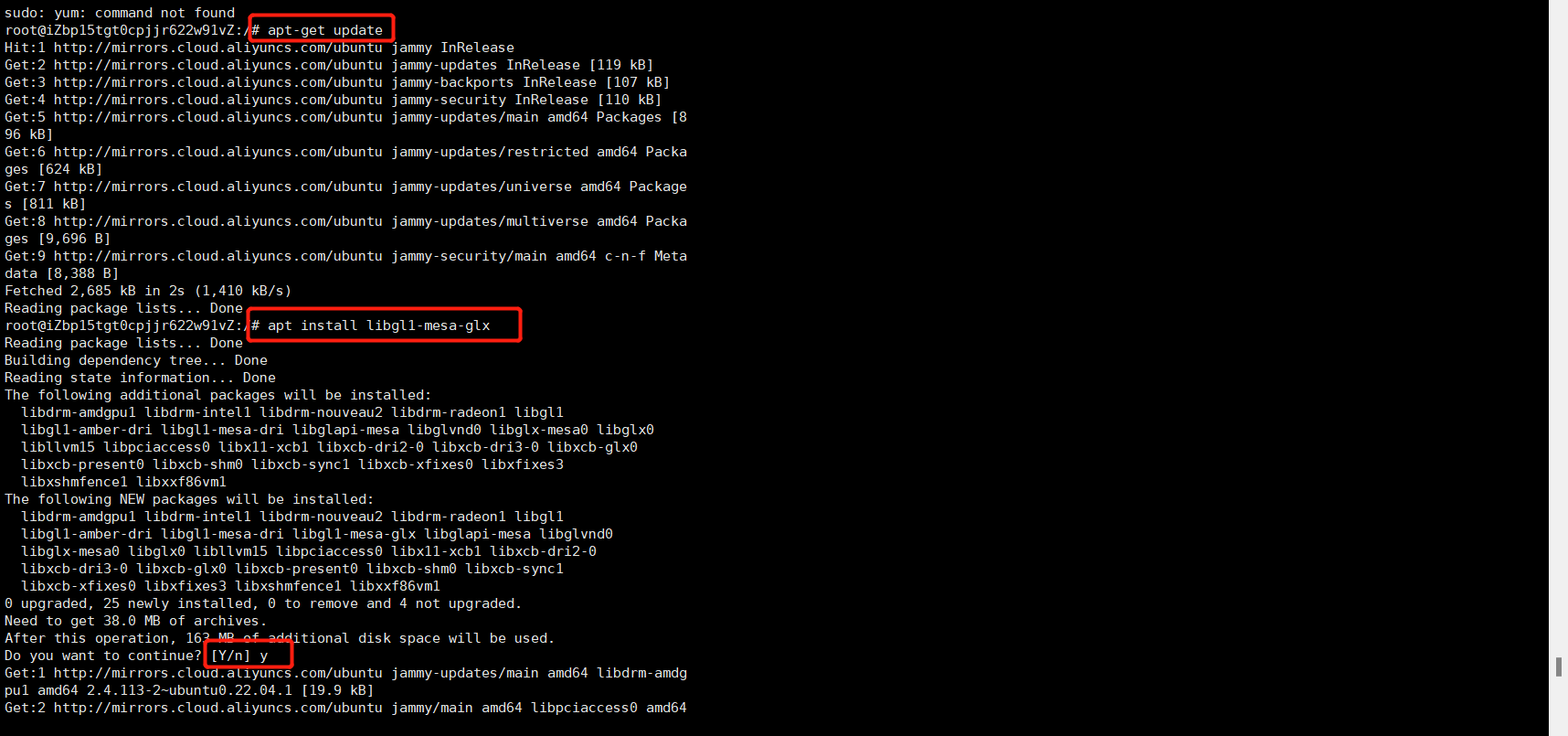
中途记得 y 确认
安装过程这个样子:
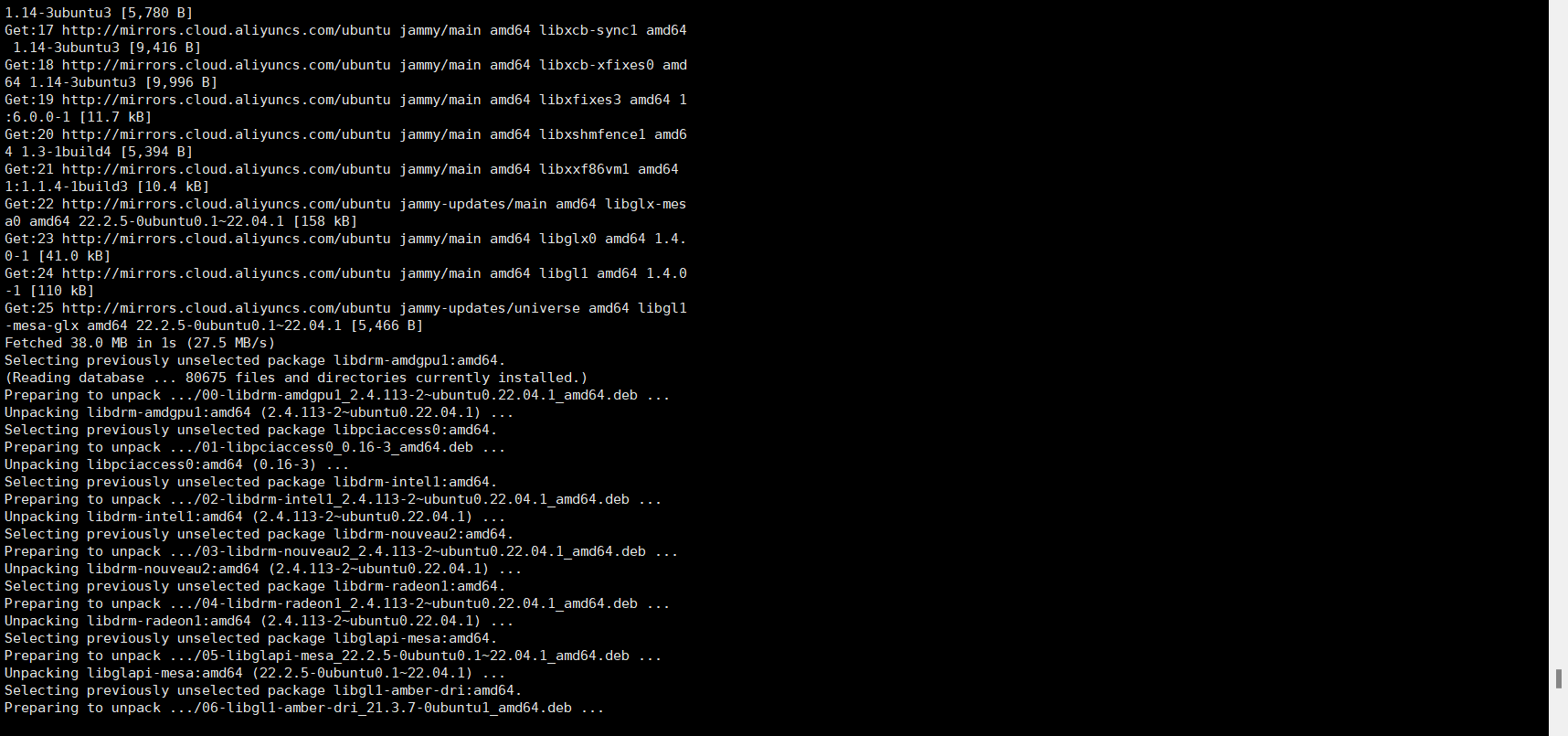
安装完成这个页面记得回车重启服务(默认即可)
三、启动
1、没GPU或者显存太小,使用CPU跑图
设置下环境变量
export COMMANDLINE_ARGS=--skip-torch-cuda-test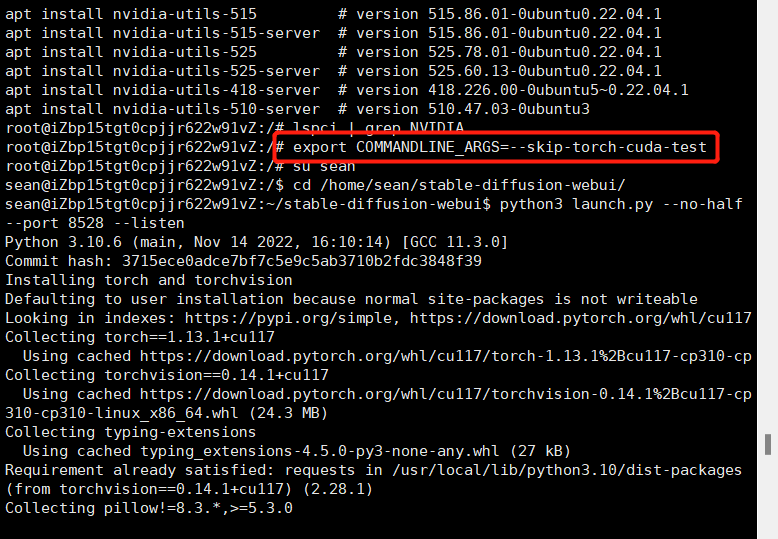
然后再运行,运行时禁用half
#port 后面改为自己想设置的端口
python3 launch.py --no-half --port 8528 --listen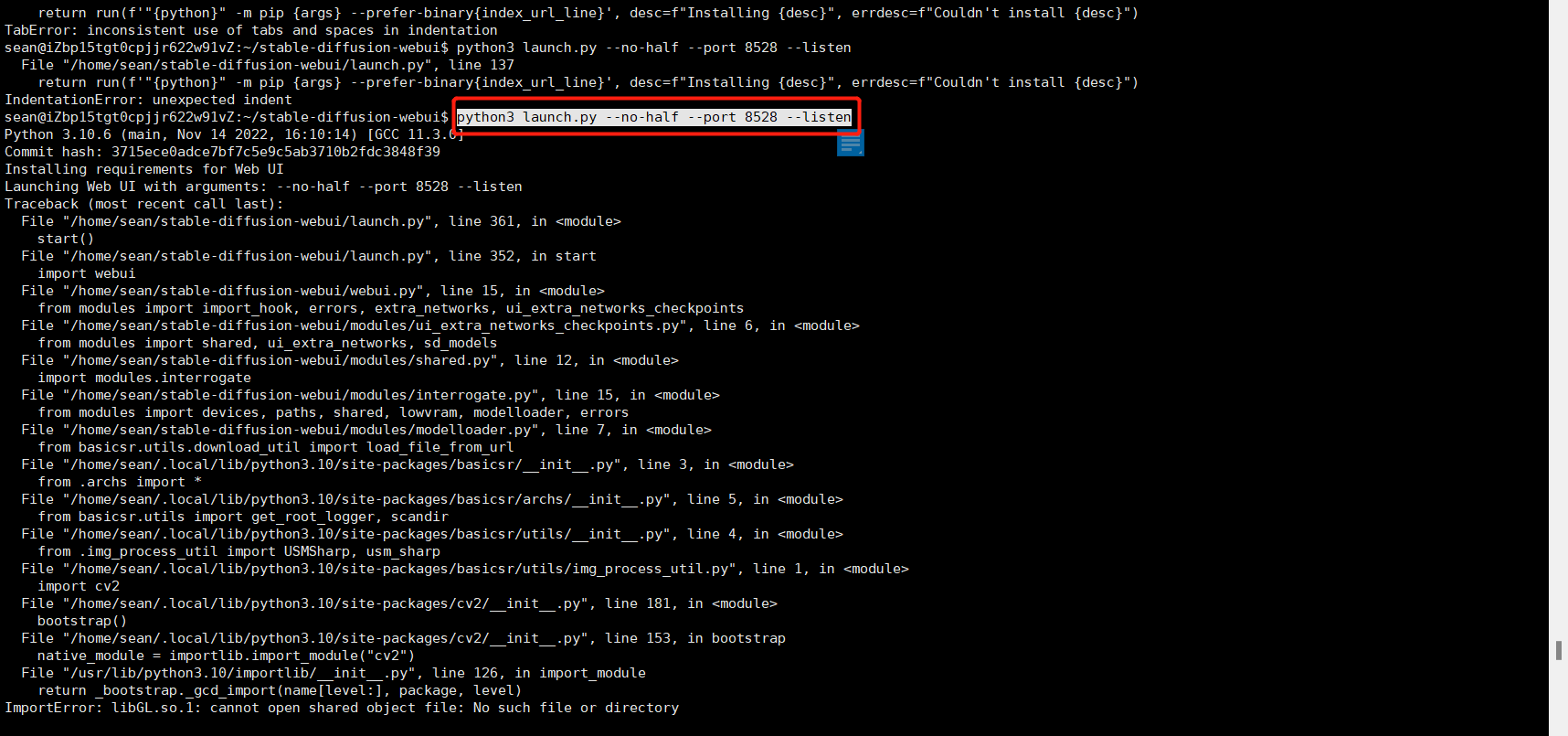
这个时候我其实出现了各种错误,这些错误有的在上面 安装 webui 的时候其实也会出现,所以做了个错误合集,放在了前面,如果这一步出错的,去看看前面错误合集解决方法。
如果错误都解决了,再次执行,就会成功,图如下:
(注意,执行一定要切换到非ROOT用户下,然后进入到目录里去执行,所有错误解决完成,最终成功,图如下)
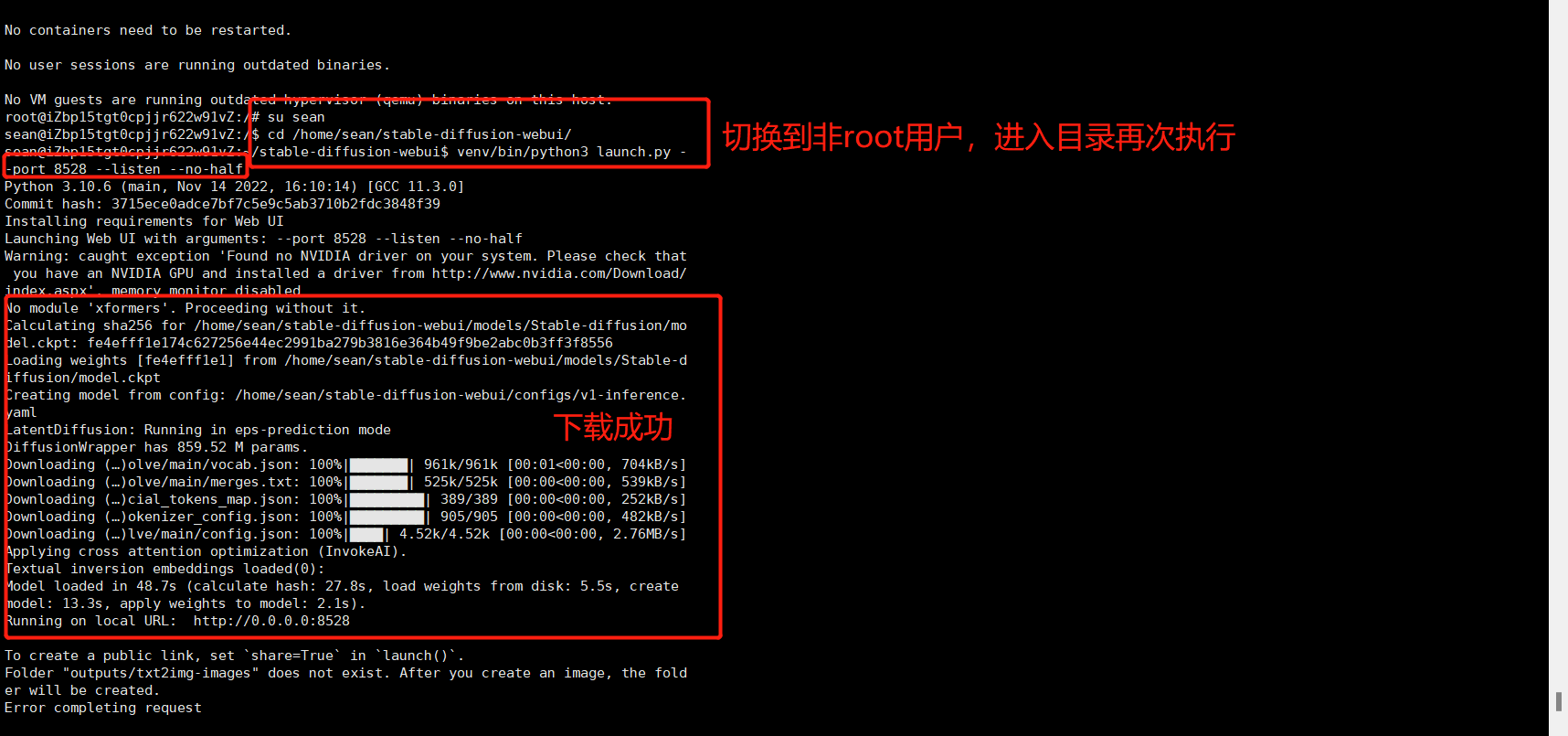
2、有GPU显存足够,使用GPU跑图
venv/bin/python3 launch.py --port 9965 --listen --no-half
这里启动方法和上面没GPU的启动其实一样,只是命令不同,没GPU的只是把环境变量设置下即可。
注意,执行一定要切换到非ROOT用户下,然后进入到目录里去执行,所有错误解决完成,最终成功,图如下:
3、成功后放开端口
如果顺利成功,那么就会出现下面这个
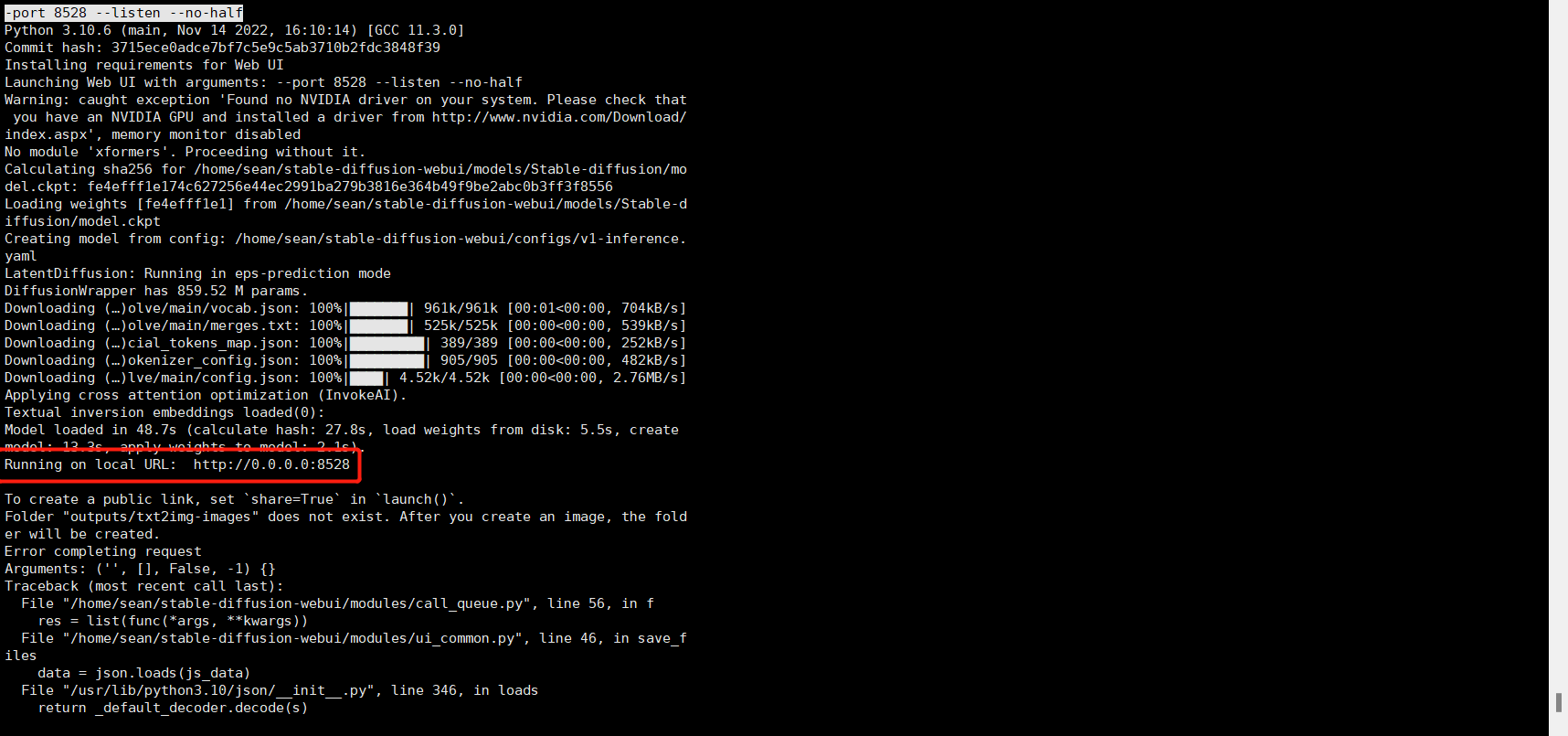
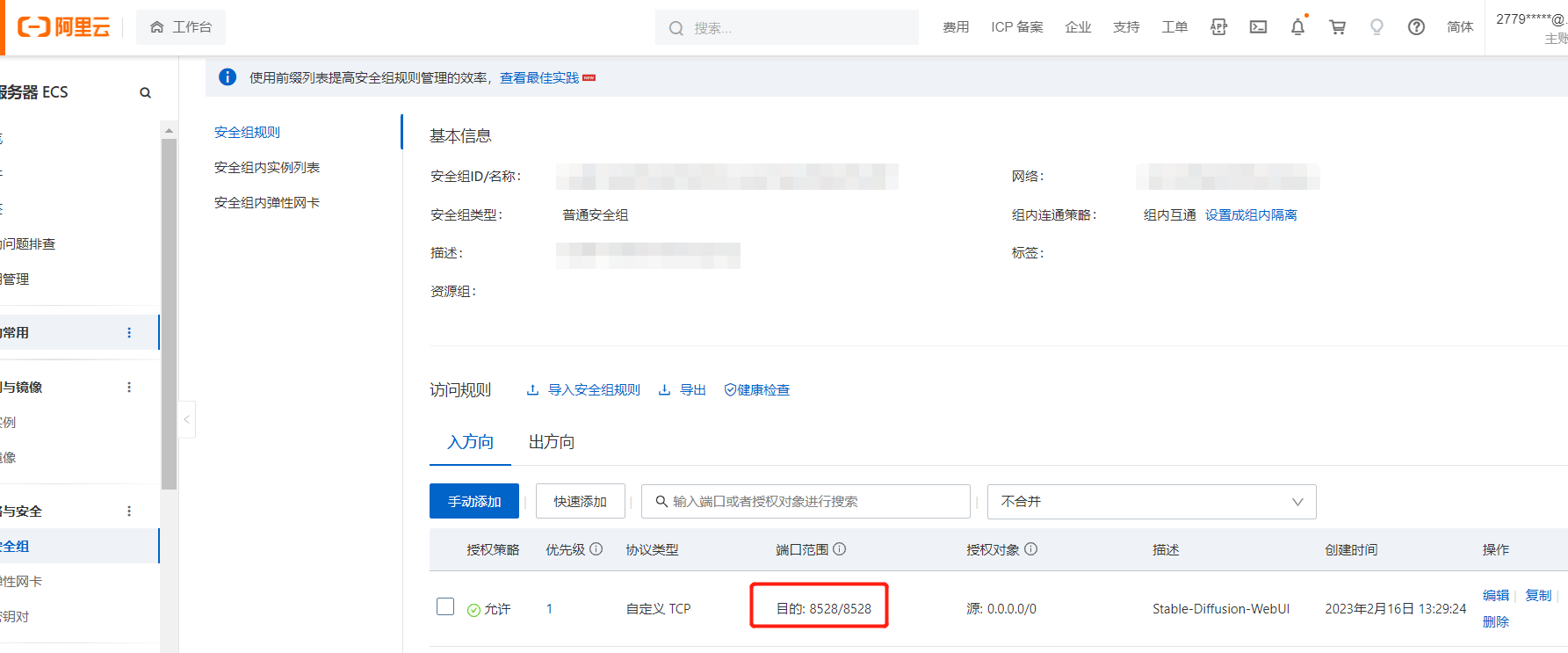
此时去你的服务器,安全组把自己设置的端口放开。
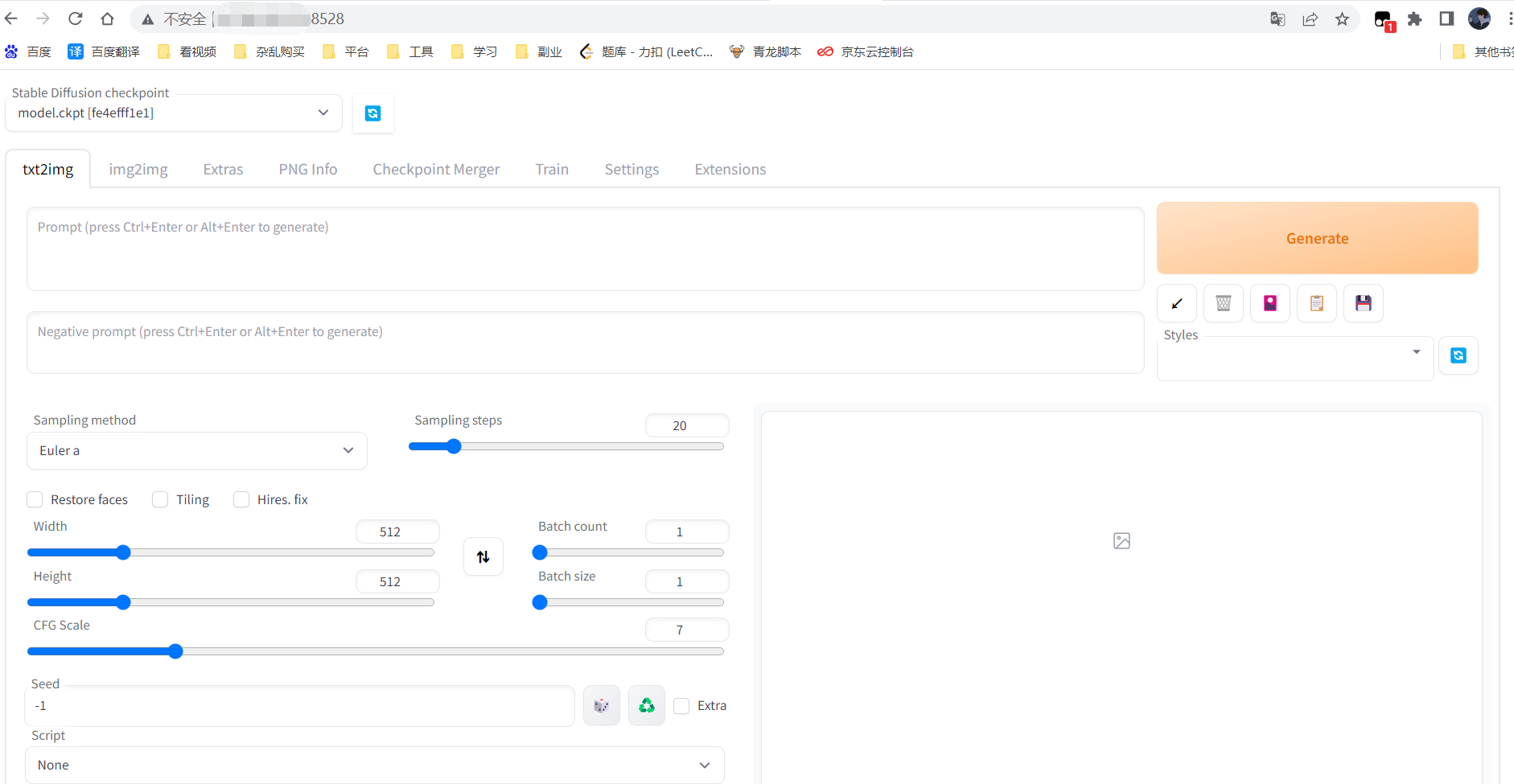
然后浏览器输入你的服务器ip+端口即可访问
四、其它
1、模型更换
启动后可以发现,左上角有个模型可以选择,这里就是自己传入的训练模型,可以根据自己需要,去添加模型、删除模型,添加之后这里可以看到所有模型,然后自己选择去训练。