- Die von BERTs „[CLS]“-Token generierten nativen Satzdarstellungen schneiden bei Satzbewertungs-Benchmarks wie der Semantic Text Similarity (STS)-Aufgabe sehr schlecht ab.
- Fehlen eines effektiven selbstüberwachten Satztrainingssets
- Normalerweise selbstüberwachtes Verfahren: Generiert durch Hinzufügen von Masken oder Vergleichen (NSP)
- ConSERT-Token-Transformation, Feature-Truncation
- SimCSE verwendet eine andere Dropout-Maske
- Selbstüberwachtes Lernen: Unterstützung bei der Generierung von Inhaltsauswahl, gute Ergebnisse, aber weniger Anwendung in der Satzrichtung
- Vorhanden: Sätze werden als Ganzes betrachtet, unterschiedlich zwischen Sätzen
- Dieser Artikel: Satzinterne Perspektive
- Phrase-Aware Sentence Representation (PaSeR): Kodierung der wichtigsten Phrasen in einer Satzrepräsentation
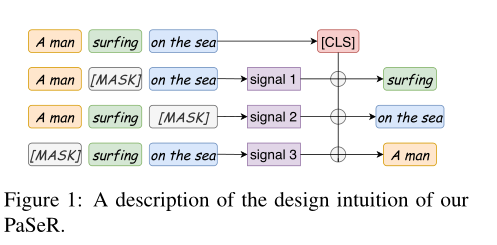
- Kernmethode
- Phrasenextraktion: Ein zufälliger Unterbaum im syntaktischen Analysebaum eines Satzes. Durch die Verwendung von NLTK (Loper und Bird, 2002) können wir die Bestandteile eines Satzes leicht extrahieren, einschließlich Klauseln (SBAR), Verbphrasen (VP) und Nominalphrasen (NP).
- Statistischer Schlüsselphrasen-Extraktionsalgorithmus, RAKE (Rose et al., 2010). RAKE zerlegt zunächst den Originalsatz oder das Originaldokument in Phrasen, wobei Stoppwörter oder Satzzeichen verwendet werden. Um die Wichtigkeit jeder Phrase zu erhalten, konstruiert RAKE zuerst die Co-Occurrence-Matrix des Wortes und berechnet die Wichtigkeit des Wortes w durch seinen Grad deg(w) in der Co-Occurrence-Matrix und seine Häufigkeit freq(w) in das Dokument oder Satzgeschlecht. Schließlich wird die Wichtigkeit des Satzes berechnet, indem die WordScores aller Wörter im Satz summiert werden. (beste Leistung)

-

- Duplizieren und Maskieren
- Differentialmodell: Insbesondere besteht ein gegebener Satz s aus mehreren Phrasen P = {p0, p1, ..., pn}, die nach ihrer von RAKE berechneten Wichtigkeit geordnet sind (Rose et al., 2010). Um die wichtigsten Ausdrücke wie p0 wiederzufinden, kommen wir natürlich auf die folgende Gleichung:
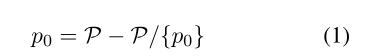
- Kopieren Sie den Satz s in s~, fügen Sie die wichtigste Phrase p0mask ein, die wir generieren möchten, und codieren Sie den Satz als Enc, und dann wird der Satz wie folgt dargestellt.

- PaSeR

- Der linke Teil zeigt den Satzcodierer mit gemeinsam genutzten Parametern.
- Die rechte Seite dient der Generierung des Decoders, der während des Evaluierungsprozesses verworfen wird
, daher werden die zusätzlichen Parameter nur in der Trainingsphase verwendet und beeinflussen die Inferenzgeschwindigkeit der Evaluierungsphase nicht.
- Durch Kombinieren der Darstellungen von Es und Es~ können wir die maskierte Phrase p0 mit einem geeigneten Decoder wiedergewinnen.
- Differentialmodell: Insbesondere besteht ein gegebener Satz s aus mehreren Phrasen P = {p0, p1, ..., pn}, die nach ihrer von RAKE berechneten Wichtigkeit geordnet sind (Rose et al., 2010). Um die wichtigsten Ausdrücke wie p0 wiederzufinden, kommen wir natürlich auf die folgende Gleichung:
- Datenerweiterung
- Synonymersetzung, zufällige Löschung und Token-Neuordnung
- Verwenden Sie die Synonymersetzung für S und S~: semantisch ähnliche Ausdrücke mit unterschiedlichen Token, die dem Modell helfen, semantische Ähnlichkeit statt Token-Ähnlichkeit zu erfassen
- Zufällige Entfernung: Mildern Sie die Auswirkungen häufiger Wörter oder Sätze
- Token-Neuordnung: Satzcodierer sind weniger empfindlich gegenüber Änderungen in der Token-Reihenfolge und positionellen Einbettungen
- Unbeaufsichtigter PaSeR:
- Satzcodierung: Basierend auf dem Bert-Vortrainingsmodell umfasst die Pooling-Methode
- Verwenden Sie [CLS] direkt
- Mittelung der Token-Darstellung von Berts letzter Schicht
- Gewichteter durchschnittlicher Token mit Bert-Zwischenschicht
- Signal decodieren

- Hier sind m und n Skalierungsfaktoren, normalisieren die vier decodierten Signale und wählen diese zwei Variablen durch Gittersuche aus. Wir diskutieren die Wahl von m und n in Anhang A.
- generativer Decoder
- Der generative Decodierer wird als reguläre Darstellung zum Trainieren des Satzcodierers verwendet, der in der Bewertungsstufe verworfen wird. Fügen Sie der Downstream-Aufgabe also keine zusätzlichen Parameter hinzu
- Die Decoder-Variante von Trafos dient als unser Phrasen-Rekonstruktions-Decoder Dec
- Unter der Annahme, dass die maskierte Phrase p0 aus mehreren Tokens besteht, ist bei gegebenem Decodiersignal SignalDec der Phrasenrekonstruktionsprozess
- offiziell

- maskierte Sprachmodellkombination
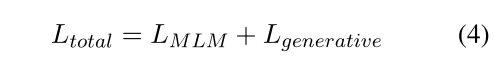
- Satzcodierung: Basierend auf dem Bert-Vortrainingsmodell umfasst die Pooling-Methode
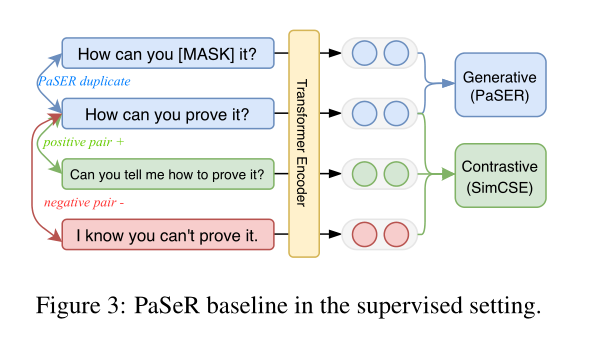
- Überwachter PaSeR: Unüberwachter PaSeR kann einen guten Initialisierungsprüfpunkt zum Trainieren eines überwachten Satzcodierers bereitstellen
- Einführung von Überwachungssignalen in das Satzrepräsentationslernen
- Sequenzklassifizierungstraining basierend auf SBERT
- Lernen aus dem SimCSE-Training
- Dieser Artikel wählt den durch SimCSE eingeführten kontrastiven Verlust und den Verlust unseres PaSeR aus

- Initialisieren Sie den Encoder vom besten Leistungspunkt des nicht überwachten PaSeR. Die ultimative Form der Verlustfunktion
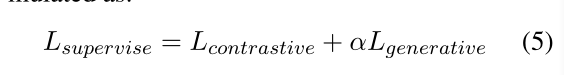
α ist ein einstellbarer Hyperparameter im Experiment
- Einführung von Überwachungssignalen in das Satzrepräsentationslernen
- Experiment
- Daten
- Auswertungsdatensatz: STS. Der Datensatz wird manuell mit einer Punktzahl von 0–5 gekennzeichnet.
- Wir verwenden die Spearman-Korrelation x 100 dieser 7 STS-Datensätze, um die Leistung zwischen allen Basis- und führenden Studien zu bewerten und zu vergleichen
- Quora-Fragenpaar: Das wiederholte Fragenpaar wird als (q1, q2) ausgedrückt, und p2 wird als Fragenbank verwendet, und alle q1 haben mindestens ein positives gepaartes q2 als Abfragesatz. Ein Abfragesatz wird dann verwendet, um ähnliche Fragen aus dem Fragenkorpus abzurufen. Zu den Bewertungsmetriken gehören die mittlere durchschnittliche Präzision (MAP) und der mittlere reziproke Rang (MRR).
- AskUbuntu-Frage: Semantische Neuordnung des Datensatzes. Die Größe des durch jede Abfrage gegebenen Fragenkorpus beträgt 20, und das Modell muss diese 20 gegebenen Fragen gemäß dem Ähnlichkeitsmaß neu ordnen. Wir verwenden auch MAP und MRR als Bewertungsmetriken.
- Trainingsdetails
- Encoder: Bert-Basis
- Maximale Sequenzlänge: 32
- Anfängliche Lernrate:
Maximale Länge der 3e-5-Sequenz und anfängliche Lernrate folgen SimCSE
- Stapelgröße: Wählen Sie aus [32,64,96]
- Unter unbeaufsichtigtem Lernen: Sieben Datensätze von Hybrid-STS
- In einer überwachten Umgebung: SNLI+MNLI kombiniert, SimCSE+PaSeR kombiniert, um den Encoder zu trainieren.
- Satzdarstellung: [CLS]
- Generativer Decoder: Generativer 6-Schicht-Transformator-Decoder
kann jede Art von Transformator-Decoder akzeptieren
- Die Worteinbettungsschicht wird von dem Satzcodierer und dem generativen Decodierer geteilt
- Ergebnisse der semantischen Textähnlichkeit
- Unüberwachte Statistiken
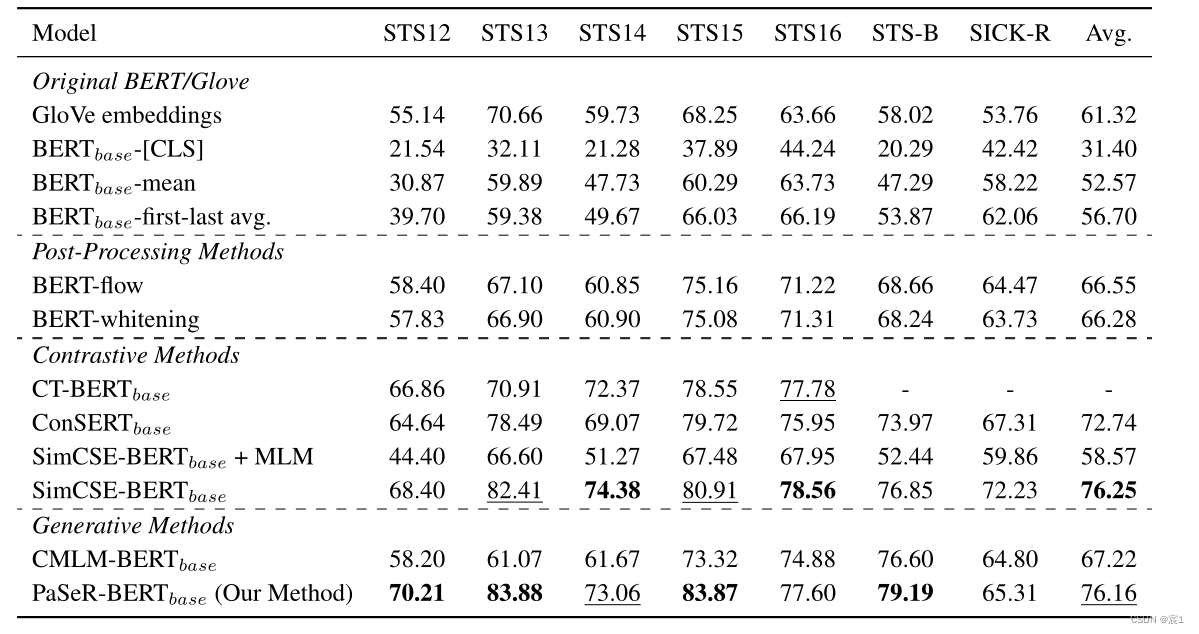
in Fettdruck zeigen eine optimale Leistung an, während unterstrichene Statistiken eine suboptimale Leistung anzeigen.
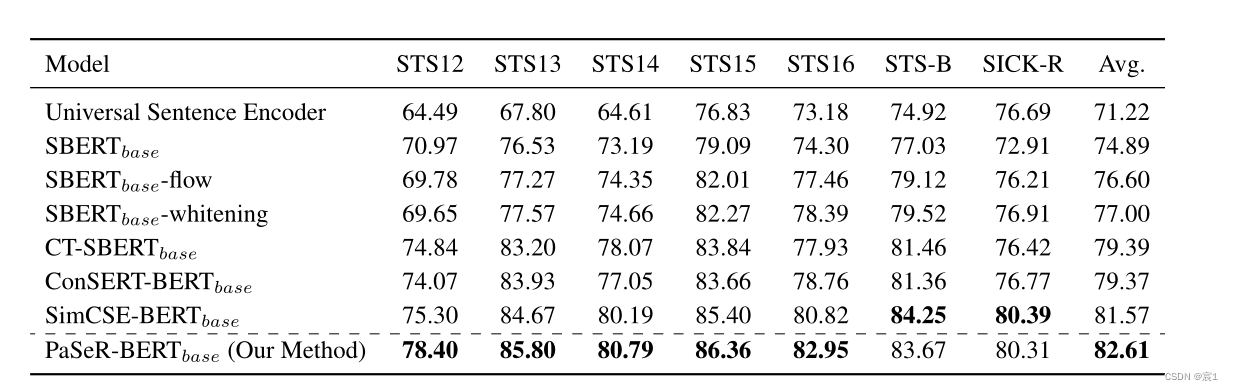
- Beaufsichtigt
- Semantischer Abruf/Neuordnung
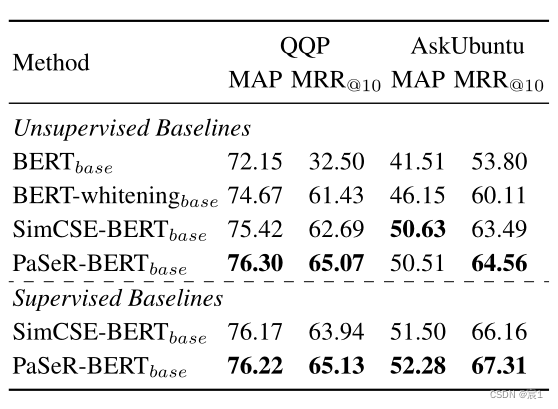
- Unüberwachte Statistiken
- Ablationsexperiment
- Die Komplexität des generativen Decoders
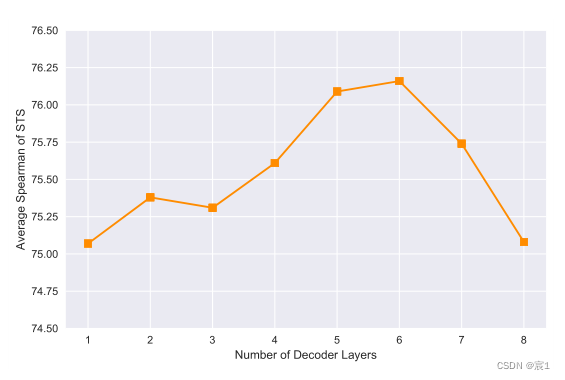
lässt vermuten, dass dies darauf zurückzuführen ist, dass ein zu kleiner Generator nicht genügend Modellkapazität hat, während ein zu großer Generator häufig zu einer Überanpassung der Trainingsdaten führt
- Data Augmentation
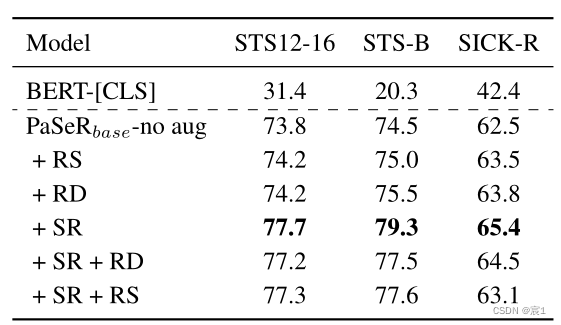
Synonym Replacement (SR) Random Exchange (RS) Random Removal (RD)
- Auswahl der Maskenphrase:
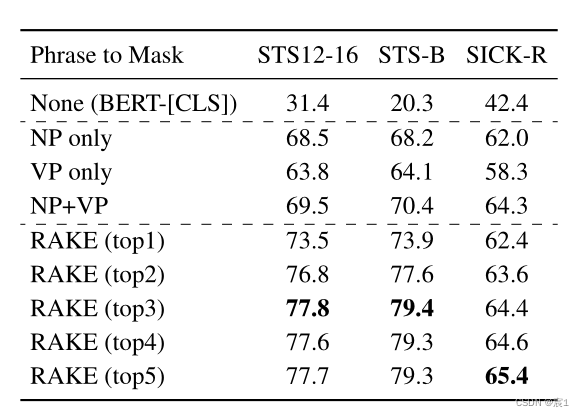
- NLTK:
- Maskieren Sie nur Nominalphrasen NP
- Blockieren Sie nur die Verbphrase VP
- Gleichzeitig NP\VP abschirmen
- RAKE-Maskierung: Wählen Sie die Anzahl der wichtigsten Phrasen, die maskiert werden sollen
- NLTK:
- Die Komplexität des generativen Decoders
- Daten
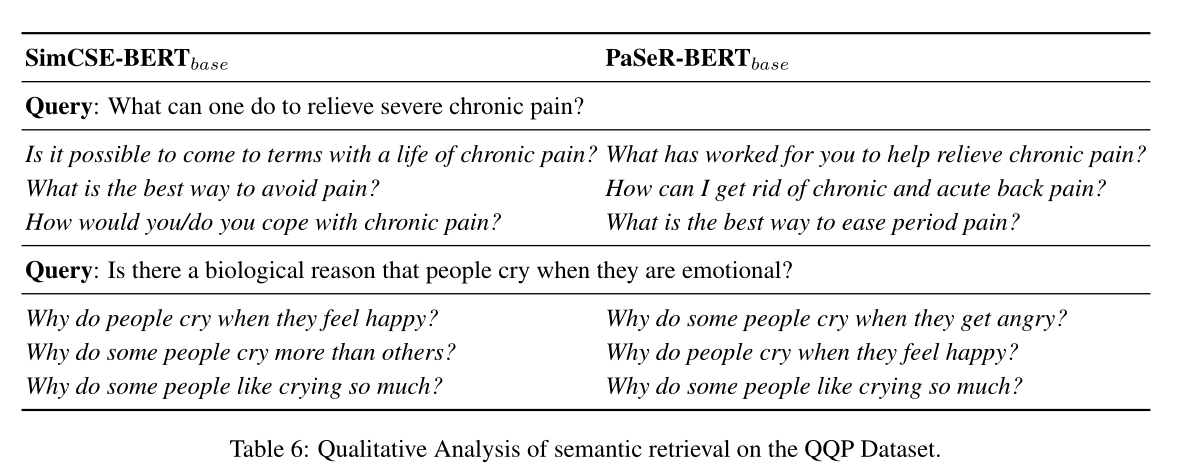
- qualitative Analyse
- Satzabruf
- Vom Decoder generierte Phrasen
- Der generierte Text unterscheidet sich vom Originaltext

- Der generierte Text unterscheidet sich vom Originaltext
- Satzabruf
Satzrepräsentationslernen mit generativem Ziel statt kontrastivem Objekt
Supongo que te gusta
Origin blog.csdn.net/qq_56061892/article/details/127628426
Recomendado
Clasificación