Tabla de contenido
Principio de implementación del hilo del kernel de Linux
Resumen de la diferencia entre proceso y subproceso
Recursos compartidos y no compartidos entre subprocesos
Funciones relacionadas con subprocesos (primitivas de control de subprocesos)
exclusión mutua (bloqueo de exclusión mutua)
bloqueo de lectura y escritura
Implementación del modelo de consumidor productor (versión de variable de condición)
Implementación del modelo de consumidor productor (versión semáforo)
El concepto de hilo
1. Similar a un proceso, un subproceso es un mecanismo que permite que una aplicación ejecute varias tareas al mismo tiempo. Un proceso puede contener varios subprocesos. Todos los subprocesos en el mismo programa ejecutarán independientemente el mismo programa y compartirán la misma área de memoria global, incluido el segmento de datos inicializados (.data), el segmento de datos no inicializados (.bss) y el segmento de memoria de pila.
[Nota: no hay memoria de pila compartida ni segmento de código]
2. Un proceso es la unidad más pequeña de recursos asignados por la CPU, y un subproceso es la unidad más pequeña de ejecución de programación por parte del sistema operativo.
3. Un subproceso es un proceso ligero (LWP: proceso ligero), y la esencia de un subproceso en un entorno Linux sigue siendo un proceso
4. Ver el LWP del proceso especificado: ps -lf pid ( Nota: lwp no es el id del hilo )
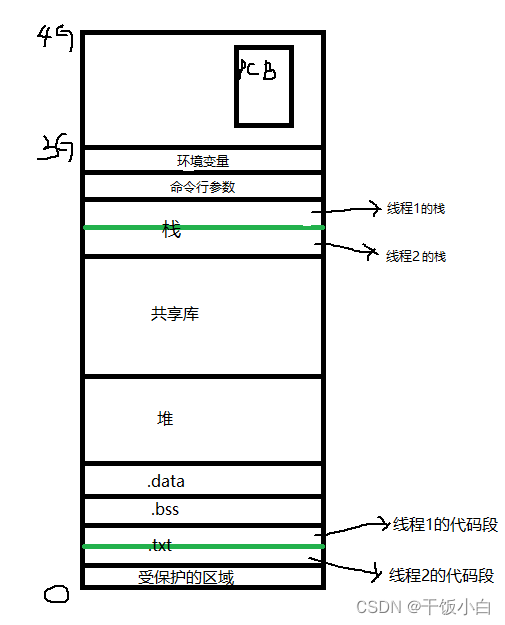
Principio de implementación del hilo del kernel de Linux
1. El proceso ligero (proceso ligero) también tiene una PCB, y las funciones subyacentes utilizadas para crear subprocesos son las mismas que las del proceso, que es clon
2. Desde la perspectiva del kernel, los procesos y los subprocesos son los mismos, y cada uno tiene un PCB diferente, pero la tabla de páginas de tres niveles que apunta a los recursos de memoria en el PCB es la misma.
Mapeo de tres niveles: PCB de proceso --> directorio de páginas (se puede ver que es una matriz, la primera dirección se encuentra en PCB) --> tabla de páginas --> página física --> unidad de memoria
3. Un proceso se puede transformar en un hilo (puede analizarlo mirando el espacio de direcciones virtuales de arriba)
4. Un hilo puede considerarse como una colección de registros y pilas.
5. La diferencia entre LWP y la ID del proceso: el número de LWP es la base para que el kernel de Linux divida los intervalos de tiempo en subprocesos, y la ID del subproceso es para distinguir los subprocesos dentro del proceso.
a
6. Para un proceso, la misma dirección se usa repetidamente en diferentes procesos sin conflicto. La razón es que, aunque sus direcciones virtuales son las mismas, los directorios de páginas, las tablas de páginas y las páginas físicas son diferentes. La misma dirección virtual se asigna a diferentes unidades de memoria de página física y, en última instancia, accede a diferentes páginas físicas.
Sin embargo, los hilos son diferentes. Aunque los dos subprocesos tienen PCB independientes, comparten el mismo directorio de páginas, tabla de páginas y página física. Entonces, ambos PCB comparten el mismo espacio de direcciones.
7. Ya sea fork() para crear un proceso o pthread_creat() para crear un hilo, la implementación subyacente llama a una función del kernel clone(). Si está copiando el espacio de direcciones de la otra parte, se generará un "proceso", y si está compartiendo el espacio de direcciones de la otra parte, se generará un "hilo" . Por lo tanto, el kernel de Linux no distingue entre procesos e hilos. Solo diferencie a nivel de usuario. Por lo tanto, las funciones de operación pthrad_* de todos los subprocesos son funciones de biblioteca, no llamadas al sistema.
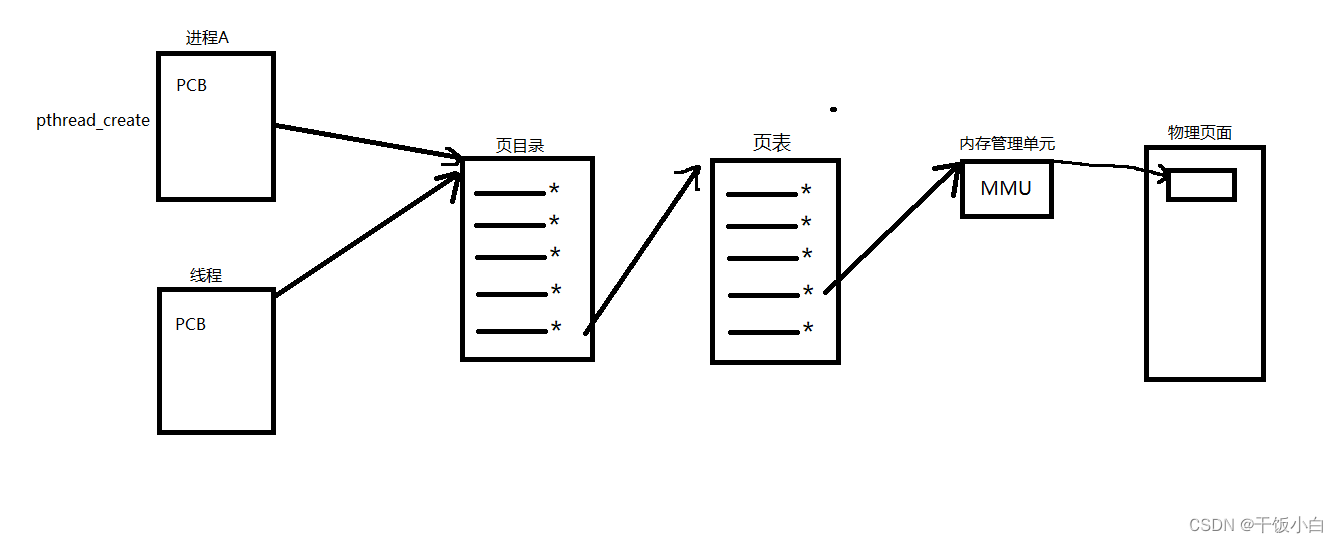
Resumen de la diferencia entre proceso y subproceso
1. Es difícil compartir información entre procesos. Dado que los procesos padre e hijo no comparten memoria excepto el segmento de código de solo lectura, se debe usar alguna forma de comunicación entre procesos para intercambiar información entre procesos.
2. El costo de llamar a fork() para crear un proceso es relativamente alto (copiar un espacio de direcciones), incluso si se adopta el mecanismo de "copia en escritura", varios atributos del proceso, como tablas de páginas de memoria y tablas de descriptores de archivos, aún necesita ser copiado, lo que significa que el tiempo de sobrecarga de la llamada fork() sigue siendo costoso
3. Los subprocesos pueden compartir información de manera conveniente y rápida, simplemente copie los datos en la variable compartida (la pila no funciona, vea la imagen de arriba)
4. Crear un hilo suele ser 10 veces o más rápido que crear un proceso. El espacio de direcciones virtuales se comparte entre subprocesos, no hay necesidad de usar copiar en escritura para copiar la memoria, y no hay necesidad de copiar la tabla de páginas (dije antes que la realización del espacio de direcciones virtuales realmente no asigne 4G de memoria, solo necesita implementar la estructura de datos correspondiente, la tabla de páginas, el directorio de páginas)
Recursos compartidos y no compartidos entre subprocesos
Esta imagen es demasiado importante, mirémosla de nuevo.
Compartir recurso recurso no compartido tabla de descriptores de archivos identificador de subproceso Cómo se maneja cada señal Contexto del procesador y puntero de pila (pila del núcleo) Directorio de trabajo actual, permisos de archivo Espacio de pila independiente (pila de espacio de usuario) ID de usuario, ID de grupo e ID de sesión variable de error Espacio de direcciones virtuales (excepto stack.txt) palabra de máscara de señal prioridad de programación Introducir NPTL (biblioteca de terceros):
Cuando se desarrolló Linux por primera vez, no había soporte real para subprocesos en el núcleo. Los procesos son entidades programables a través de la llamada al sistema clone(). Esta llamada crea una copia del proceso de llamada que comparte el mismo espacio de direcciones que la llamada. Pero esto cumple con los requisitos de POSIX, y hay problemas en el procesamiento de señales, sincronización entre horarios, etc.
Biblioteca de hilos NPTL o POSIX nativos. es una nueva implementación de LinuxThreads que supera las deficiencias de LinuxThreads mientras se ajusta al estándar.
Ver la versión actual de la biblioteca de procesos: getconf GNU_LIBPTHREAD_VERSION
Pros y contras del hilo
Ventajas: 1. Mejorar la concurrencia del programa 2. Gastos generales reducidos 3. Comunicación e intercambio de datos conveniente
Desventajas: 1. Funciones de biblioteca, inestables 3. Difícil de depurar y escribir (gdb no es compatible) 4. Pobre soporte de señal
Las ventajas son relativamente prominentes y las desventajas no son defectuosas. Bajo Linux, debido al método de implementación, la diferencia entre procesos y subprocesos no es muy grande.
Funciones relacionadas con subprocesos (primitivas de control de subprocesos)
En general, el subproceso donde se encuentra la función principal se denomina subproceso principal. El resto de los subprocesos creados se denominan subprocesos secundarios.
función fork() ---> crear proceso
Solo hay un hilo en el programa por defecto, y la función pthread_create() llama --> 2 hilos
función pthread_create
int pthread_create(pthread_t *thread,const pthread_attr_t *attr,
void*(*start_routine)(void*),void *arg);
Función: crear un subproceso secundario
parámetro:
subproceso: el parámetro saliente, después de que el subproceso se crea con éxito, la identificación del subproceso del subproceso se escribe en esta variable
attr establece los atributos del hilo, generalmente usando el valor predeterminado NULL
start_routine: puntero de función, esta función es el código lógico que el subproceso secundario necesita procesar
arg: utilizado para el tercer parámetro
valor de retorno:
Éxito: 0
Error: devolver el número de error
Nota complementaria: debido a que el subproceso es una biblioteca de terceros a través de la biblioteca NPTL, es diferente de nuestra llamada al sistema.
Hemos estado usando perror(ret) antes, pero ahora no es factible.Use char *strerror(int errnum)
#include <iostream> #include <pthread.h> #include <string.h> #include <unistd.h> using namespace std; void *func(void *arg) { printf("pthread:%lu\n",pthread_self()); return NULL; } int main(void) { //typedef unsigned long pthread_t tid; int ret = pthread_create(&tid,NULL,func,NULL); if(ret) { printf("%s\n",strerror(ret)); exit(-1); } sleep(1); printf("我是主线程:%d\n",getpid()); return 0; }Precauciones para la compilación: los pimientos de subprocesos se implementan a través de bibliotecas de terceros
g++ createPthread.cpp -o createPthread -lpthread(-pthread)
función pthread_exit
int pthread_exit(void *retval);
Función: terminar un subproceso, a qué subproceso se llama en nombre de qué subproceso se termina
parámetro:
retval: se debe pasar un puntero como valor de retorno, que se puede obtener en pthread_join().
Estado de salida del subproceso, generalmente pasa NULL
Suplemento: cuando el subproceso principal sale, no afectará a otros subprocesos en ejecución normales
El uso de la función de salida está prohibido en el hilo, lo que hará que todos los hilos del proceso salgan
#include <stdio.h> #include <pthread.h> #include <string.h> #include <unistd.h> void *func(void *arg) { int i = (int)arg; if(i == 2) { pthread_exit(NULL); } sleep(2); printf("我是第%d号线程,线程ID:%lu\n",i,pthread_self()); return NULL; } int main(void) { pthread_t tid; for(int i=0;i<5;++i) { pthread_create(&tid,NULL,func,(void *)i); } sleep(5); printf("我是主线程,线程ID:%lu\n",pthread_self()); return 0; }
función pthread_self
pthread_t pthread_self(vacío)
Función: Obtener el ID de hilo del hilo actual
función pthread_equal
int pthread_equal(pthread_t t1,pthread_t t2);
Función: Compara si dos ID de subprocesos son iguales
Valor devuelto: igual a distinto de cero, distinto de 0
Suplemento: diferentes sistemas operativos tienen diferentes implementaciones de tipos pthread_t, algunos son enteros largos sin signo y otros pueden ser estructuras
#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_t tid_one; void *func(void *arg) { if(pthread_equal(tid_one,pthread_self())) { printf("相等\n"); } else { printf("不相等\n"); } } int main(void) { pthread_t tid; pthread_create(&tid_one,NULL,func,NULL); pthread_join(tid_one,NULL); return 0; }
función pthread_join
int pthread_join(pthread_t thread,void ** retval);
Función: conectarse con un subproceso terminado y recuperar recursos
Reciclar recursos del proceso hijo
Esta función está bloqueando y solo se puede reciclar un proceso secundario a la vez
Generalmente se usa en el hilo principal.
Parámetros: ID de subproceso del proceso secundario que debe reciclarse
retval recibe el valor devuelto cuando el proceso hijo sale
valor de retorno:
0 éxito
Distinto a 0, error, número de error de retorno
separación de hilos
int pthread_detach(pthread_t hilo);
Función: Separar un hilo. Cuando finaliza el subproceso separado, automáticamente liberará recursos y los devolverá al sistema.
Precauciones:
1) No se puede separar varias veces, lo que resulta en un comportamiento impredecible
2) No se puede conectar a un hilo que se ha separado, se informará un error [pthread_join]
parámetro:
ID del hilo que necesita ser separado
valor de retorno:
éxito 0 error número de error
Reflejos:
Estado de separación de subprocesos: especifique este estado y el subproceso se desconectará activamente del subproceso de control principal. Una vez que finaliza el subproceso, su estado de salida no es adquirido por otros subprocesos, sino que se libera automáticamente directamente por sí mismo. Red, servidor de subprocesos múltiples de uso común.
Si el proceso tiene un mecanismo de este tipo, no generará un proceso zombi. La razón principal de la generación de un proceso zombi es que después de que el proceso muere, la mayoría de los recursos se liberan y algunos recursos residuales aún quedan en el sistema, lo que provoca el kernel para pensar que el proceso todavía existe
En circunstancias normales, después de que finaliza un subproceso, su estado terminado se mantiene hasta que otros subprocesos llamen a pthread_join para obtener su estado, pero el subproceso también se puede establecer en el estado separado. Una vez que finaliza dicho subproceso, todos los recursos que ocupa se recuperarán inmediatamente . sin Salir del estado terminado. No es posible llamar a pthread_join en un subproceso que ya está en el estado de desconexión. Tales llamadas devolverán errores EINVAL.
#include <stdio.h> #include <pthread.h> void* func(void *arg) { printf("我是子线程:%lu\n",pthread_self()); return NULL; } int main(void) { pthread_t tid; pthread_create(&tid,NULL,func,NULL); //设置线程分离 pthread_detach(tid); sleep(3); return 0; }
cancelación de hilo
int pthread_cancel(pthread_t hilo);
Función: cancelar el hilo (dejar que el hilo termine)
Cancelar un proceso puede terminar la ejecución de un subproceso.
Pero en lugar de terminar inmediatamente, el subproceso solo terminará cuando el subproceso secundario se ejecute en un punto de cancelación.
Punto de cancelación: llamada al sistema (cuando se cambia del modo de usuario al modo de kernel) creat open pause read write..
Si el subproceso no tiene un punto de cancelación al final, puede establecer un punto de cancelación llamando a la función pthread_testcancel
Para subprocesos cancelados, el valor de salida se define en la biblioteca pthread de Linux. El valor de la constante PTHREAD_CANCELED es -1. Su definición se puede encontrar en pthread.h.
Por lo tanto, cuando usamos pthread_join para reciclar un hilo que ha sido cancelado, obtenemos un valor de retorno de -1
#include <stdio.h> #include <pthread.h> void *func(void *arg) { //printf("我是子线程:%lu\n",pthread_self()); //printf会产生一个系统调用 pthread_testcancel(); //自己设置一个取消点 return NULL; } int main(void) { pthread_t tid; pthread_create(&tid,NULL,func,NULL); //取消这个线程 pthread_cancel(tid); //回收 int childRet; pthread_join(tid,(void **)&childRet); //阻塞的 printf("回收的返回值:%d\n",childRet); return 0; }
propiedades del hilo
Las propiedades del subproceso en Linux se pueden configurar de acuerdo con los requisitos reales del proyecto. Discutimos las propiedades predeterminadas del subproceso antes. Las propiedades predeterminadas ya resuelven la mayoría de los problemas. Si presentamos requisitos más altos sobre el rendimiento del programa, necesitamos establecer atributos de subprocesos.Por ejemplo, podemos reducir el uso de memoria configurando el tamaño de la pila de subprocesos para aumentar la cantidad máxima de subprocesos.
Atributos principales: alcance, tamaño de pila, dirección de pila, prioridad, estado de separación, política de programación
Los valores de atributos de subprocesos no se pueden configurar directamente y deben operarse a través de funciones relacionadas (que se pueden entender como interfaces):
int pthread_attr_init(pthread_attr_t *attr); //Inicializa las variables de atributo del subproceso int pthread_attr_destroy(pthread_attr_t *attr); //Liberar el recurso del atributo del hilo int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate); //Obtenga el atributo de estado de la separación del subproceso int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate); //Establecer el atributo de estado de la separación del subproceso Ver método de atributo de hilo: man pthread_attr_XXX
caso:
//Crear una variable de atributo de hilo
pthread_attr_t atributo;
//Inicializar variables de atributo
pthread_attr_init(&atributo);
// establecer propiedades
pthread_attr_setdetachstate(&attr,PTHREAD_CREATE_DETACHED);
//Establecer el tamaño de la pila de subprocesos
pthread_attr_setstacksize(&atributo,tamaño);
.....
#include <stdio.h> #include <pthread.h> #include <string.h> void* func(void *arg) { printf("子线程:%lu\n",pthread_self()); return NULL; } int main(void) { pthread_t tid; //创建线程属性变量 pthread_attr_t attr; //初始化 pthread_attr_init(&attr); //设置线程分离 pthread_attr_setdetachstate(&attr,PTHREAD_CREATE_DETACHED); //设置栈大小 int size = 256*1024; pthread_attr_setstacksize(&attr,size); pthread_create(&tid,&attr,func,NULL); while(1) { sleep(1); void* retval; int err = pthread_join(tid,&retval); if(err) printf("-------------err= %s\n", strerror(err)); else printf("-----------%d\n",(int)retval); } return 0; }

Notas sobre el uso de hilos
1. El subproceso principal sale y otros subprocesos no salen, el subproceso principal llama a pthread_exit
2. Evite los hilos de zombis
pthread_join
pthread_detach
Establezca el atributo de hilo para separar, luego pthread_create
3. La memoria solicitada por malloc y mmap puede ser liberada por otros subprocesos
4. Evite llamar a fork en un modelo de subprocesos múltiples a menos que se ejecute de inmediato. Solo el subproceso que llama a frok existe en el proceso secundario y todos los demás subprocesos pthread_exit en el proceso secundario
5. La semántica compleja de las señales es difícil de coexistir con subprocesos múltiples, y se debe evitar la introducción de mecanismos de señal en subprocesos múltiples
sincronización de subprocesos
Primero hablemos sobre el concepto de sincronización (no se sienta prolijo, es conveniente que entendamos la sincronización de subprocesos):
La llamada sincronización tiene diferentes significados para diferentes objetos de investigación. Por ejemplo: la sincronización de dispositivos se refiere a especificar una referencia de tiempo común entre dos dispositivos. ¿No son los "libros con el mismo texto y los autos con la misma pista" de Qin Shihuang también una especie de sincronización? La sincronización en la programación se refiere a la coordinación, la asistencia y la cooperación mutua, principalmente con el fin de coordinar los pasos y ejecutar en un orden predeterminado .
sincronización de subprocesos
La sincronización es un paso coordinado que se ejecuta en un orden predeterminado. ¿Alguna vez ha pensado en una pregunta, por qué enfatizamos el orden predeterminado, principalmente porque los hilos en el mismo proceso comparten recursos, además de la razón de la concurrencia, suponiendo que un hilo quiere modificar cada dato, antes de que se complete la modificación, otro hilo lo sacare, dara problemas?
Para ser más profesional: la sincronización de subprocesos significa que cuando un subproceso emite una llamada de función, la llamada no regresa hasta que se obtiene el resultado. Al mismo tiempo, otros subprocesos no pueden llamar a esta función para garantizar la coherencia de los datos. ( Un subproceso no ha terminado de llamar a un recurso compartido y otros subprocesos no pueden llamarlo )
Análisis detallado:
1. La principal ventaja de los hilos es la capacidad de compartir información a través de variables globales. Sin embargo, esta comodidad (la comodidad se compara con la comunicación entre procesos) para compartir tiene un precio. Debe garantizarse que múltiples subprocesos no modificarán la misma variable al mismo tiempo o que un subproceso no leerá variables que están siendo modificadas por otros hilos (encontrará que puede leer ambos al mismo tiempo).
2. Una sección crítica se refiere a un fragmento de código que accede a un recurso compartido, y la ejecución de este código debe ser una operación atómica. Es decir, otros subprocesos que acceden simultáneamente al mismo recurso compartido no deberían interrumpir la ejecución del fragmento.
3. Cuando un subproceso está operando en la memoria, otros subprocesos no pueden operar en este proceso de dirección de memoria. Hasta que el subproceso complete la operación, otros subprocesos pueden operar en la memoria, mientras que otros subprocesos están en un estado de espera .
Entonces, ¿cómo podemos mantener mejor esta operación atómica?
Mutex, semáforo, bloqueo XXX... mecanismo
No sé si he descubierto que muchas veces el desarrollo es para solucionar un determinado problema. Bajo cualquier condición, es difícil ser perfecto, o es difícil dibujar un círculo perfecto. Hemos estado constantemente innovando y acercándonos a este círculo perfecto. Parece que nunca podemos terminar de contar π.
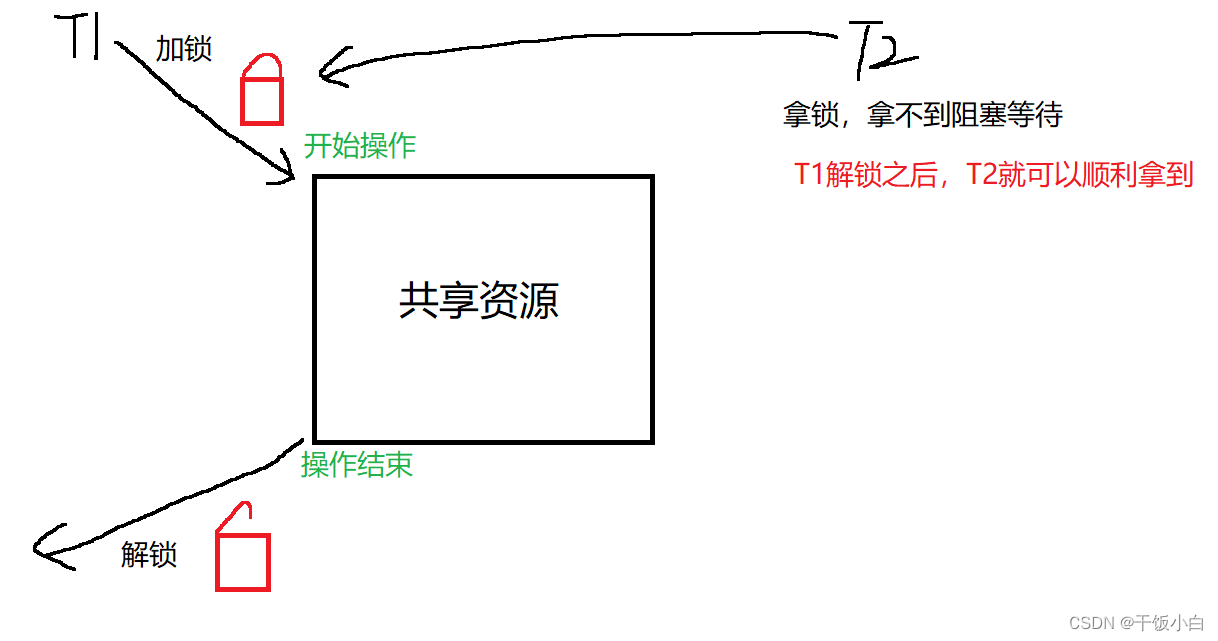
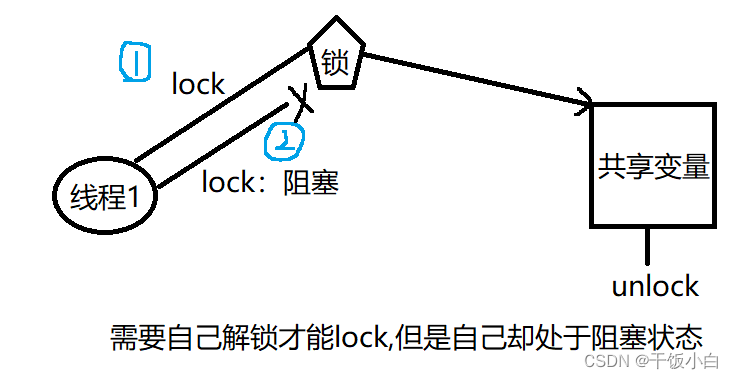
exclusión mutua (bloqueo de exclusión mutua)
Permítanme hablar primero sobre un entendimiento común: ahora hay una habitación, y esta habitación solo puede acomodar a una persona a la vez, para evitar que entren dos o más personas, ahora compre un candado para esta habitación, cuando alguien entre, el portero La gente cierra la habitación con llave, y cuando la gente sale, abre la cerradura. Cuando alguien más entre, cierra la cerradura, eso es todo. De hecho, muchas soluciones a problemas en las computadoras tienen mucho que ver con nuestra vida real.
1. Para evitar problemas cuando los subprocesos actualizan (modifican) variables compartidas, se puede usar un mutex para garantizar que solo un subproceso pueda acceder a un recurso compartido al mismo tiempo. Los mutex se pueden utilizar para garantizar el acceso atómico a recursos compartidos arbitrarios.
2. El mutex tiene dos estados: bloqueado (locked) y unlocked (desbloqueado). En cualquier momento, como máximo un subproceso puede bloquear la exclusión mutua. Los intentos de volver a bloquear un mutex que ya se bloqueó pueden bloquear el subproceso o fallar con un error, según el método utilizado al bloquear. ( Volvamos al ejemplo anterior, nuestros administradores solo abren un candado a la vez, si se agregan dos candados, las personas en la sala no pueden salir y las personas fuera de la sala no pueden entrar, y el administrador ya ha abierto un candado , piensa que la habitación está vacía, esperando a que alguien entre. Hace que se quede atrapado aquí para siempre, woo hoo... )
3. Una vez que el subproceso bloquea la exclusión mutua, inmediatamente se convierte en el propietario de la exclusión mutua, y solo el propietario puede desbloquear la exclusión mutua. En general, se utilizarán diferentes mutex para cada recurso compartido, y cada subproceso utilizará el siguiente protocolo al acceder al mismo recurso:
- Bloquear un mutex para un recurso compartido (bloqueo)
- Acceso a Recursos Compartidos (Acceso)
- Desbloquear el mutex (desbloquear)
4. Si varios subprocesos intentan ejecutar este fragmento de código (sección crítica), de hecho, solo un subproceso puede contener la exclusión mutua (otros subprocesos se bloquearán), es decir, solo un subproceso puede ingresar a esta área de código al mismo tiempo.
Por ejemplo:
Al "bloquear", el acceso a los recursos se vuelve más prolongado y mutuamente excluyente, y luego no se producirán errores relacionados con el tiempo (ejecutados en el orden esperado).
Explicación: cuando el subproceso A bloquea y accede a una variable global, B intenta bloquearla antes de acceder, pero si no se puede obtener el bloqueo, B bloquea. El subproceso C no se bloquea, pero accede directamente a la variable global, a la que aún se puede acceder, pero se producirá una confusión de datos.
Por lo tanto, el mutex es esencialmente un "bloqueo sugerido" (también conocido como "bloqueo cooperativo"). Se recomienda usar este mecanismo cuando varios subprocesos acceden a recursos compartidos en el programa, pero no es obligatorio. (¿A qué se refiere? Es decir, antes de que cierto subproceso acceda al recurso compartido, no accede al bloqueo y accede directamente al recurso compartido, y también se puede acceder a él. Debemos seguir los pasos prescritos para evitar la confusión de datos . cuando uso el mutex. Voy directamente a la sala, no me importa si hay un administrador)
funciones relacionadas
Tipo de exclusión mutua: pthread_mutex_t
función pthread_mutex_init
int pthread_mutex_init(pthread_mutex_t *restringir mutex,
const pthread_mutexattr_t *restringir attr);
Rol: inicializar el mutex
Parámetros: mutex La variable mutex que debe inicializarse
attr Atributos relacionados con Mutex, generalmente pasan NULL
restrict: un modificador en lenguaje C, el puntero modificado no puede ser operado por otro puntero
función pthread_mutex_destroy
int pthread_mutex_destroy(pthread_mutex_t *mutex);
Rol: liberar los recursos del mutex
función pthread_mutex_lock
int pthread_mutex_lock(pthread_mutex_t *mutex);
Función: bloqueo, bloqueo (si un subproceso está bloqueado, entonces otros subprocesos solo pueden bloquear y esperar)
función pthread_mutex_trylock
int pthread_mutex_trylock(pthread_mutex_t *mutex);
Función: intente bloquear, sin bloqueo (si el bloqueo falla, no se bloqueará y regresará directamente)
función pthread_mutex_unlock
int pthread_mutex_unlock(pthread_mutex_t *mutex);
Función: desbloquear
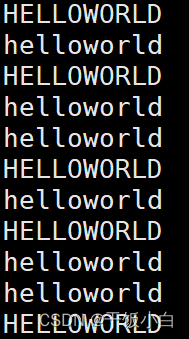
Último caso: (objetivo -> poder imprimir HOLA MUNDO o hola mundo completo)
Sin mutex:
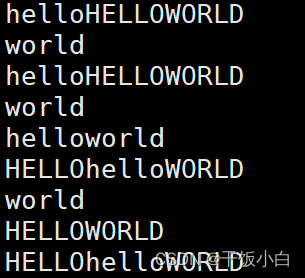
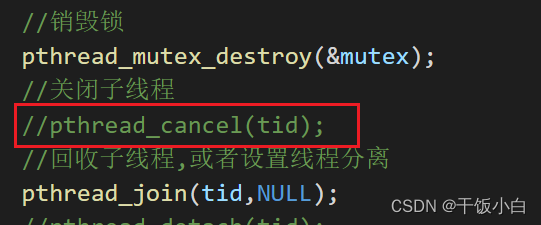
#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_mutex_t mutex; //定义为全局变量,不能定义为栈上的临时变量 void *func(void *arg) { srand(time(NULL)); while(1) { //pthread_mutex_lock(&mutex); //加锁 printf("hello"); sleep(rand()%3); printf("world\n"); //pthread_mutex_unlock(&mutex); //解锁 sleep(rand()%3); } return NULL; } int main(void) { int n = 5; pthread_t tid; srand(time(NULL)); //设置随机种子 //初始化互斥量,在创建线程之前 pthread_mutex_init(&mutex,NULL); //创建线程 pthread_create(&tid,NULL,func,NULL); while(n--) { //pthread_mutex_lock(&mutex); //加锁 printf("HELLO"); sleep(rand()%3); printf("WORLD\n"); //pthread_mutex_unlock(&mutex); //解锁 sleep(rand()%3); } //销毁锁 pthread_mutex_destroy(&mutex); //关闭子线程 pthread_cancel(tid); //回收子线程,或者设置线程分离 pthread_join(tid,NULL); //pthread_detach(tid); return 0; }agregar exclusión mutua
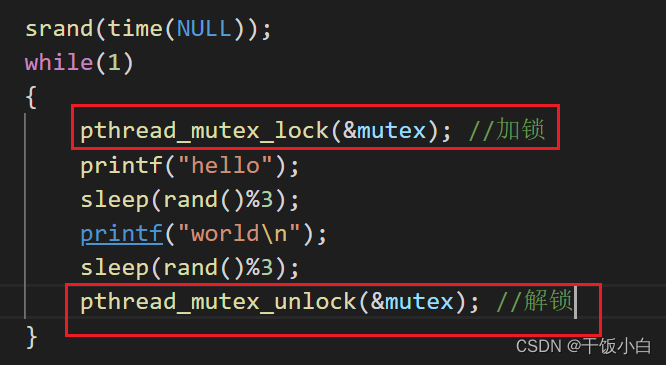
#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_mutex_t mutex; //定义为全局变量,不能定义为栈上的临时变量 void *func(void *arg) { srand(time(NULL)); while(1) { pthread_mutex_lock(&mutex); //加锁 printf("hello"); sleep(rand()%3); printf("world\n"); pthread_mutex_unlock(&mutex); //解锁 sleep(rand()%3); } return NULL; } int main(void) { int n = 5; pthread_t tid; srand(time(NULL)); //设置随机种子 //初始化互斥量,在创建线程之前 pthread_mutex_init(&mutex,NULL); //创建线程 pthread_create(&tid,NULL,func,NULL); while(n--) { pthread_mutex_lock(&mutex); //加锁 printf("HELLO"); sleep(rand()%3); printf("WORLD\n"); pthread_mutex_unlock(&mutex); //解锁 sleep(rand()%3); } //销毁锁 pthread_mutex_destroy(&mutex); //关闭子线程 pthread_cancel(tid); //回收子线程,或者设置线程分离 pthread_join(tid,NULL); //pthread_detach(tid); return 0; }¿Nuestra discusión está por aquí?
Por supuesto que no, veamos un caso especial.
Ahora cambio el código a esto, ¿qué resultado obtendré...?
En un bucle infinito, el subproceso principal ya no puede competir por la CPU
El subproceso debe desbloquearse inmediatamente después de operar el recurso compartido, pero después de la modificación, el subproceso duerme manteniendo el bloqueo. Después de despertarse y desbloquearse, se volverá a bloquear inmediatamente. Estas dos funciones de biblioteca en sí mismas no se bloquean. Entonces, la probabilidad de perder CPU entre estas dos líneas de código es muy pequeña. Por lo tanto, es difícil que otro subproceso tenga la oportunidad de bloquearse.
Volvamos a modificar el código:
Se encuentra que el subproceso secundario no ha terminado y el subproceso principal está bloqueado esperando reciclar el subproceso secundario
La razón es obvia, pthread_join bloqueará la espera de que finalice el subproceso secundario, y el subproceso secundario entra en un bucle infinito... así que...
punto muerto
Las cuatro condiciones necesarias para que se produzca un interbloqueo al aprender el sistema operativo (definidas en el libro de texto):
1. Condiciones de exclusión mutua (nuestros bloqueos mutex son recursos compartidos mutuamente excluyentes, y solo puede ingresar un subproceso en un momento determinado)
2. Condiciones de solicitud y espera (cada proceso debe mantener el estado existente)
3. Sin privación de condiciones (sin influencia externa)
4. Condición de espera de bucle (esperando a que otros procesos liberen recursos)
Esta es la definición que nos da el libro de texto, seguida de algunas explicaciones para facilitar su comprensión.
Luego, la escena en el proceso de programación real (hay principalmente tres situaciones):
1. Olvidarse de abrir la cerradura
2. Repita el bloqueo
3. Multi-hilo y multi-bloqueo, apropiación de recursos de bloqueo
(El primer caso es fácil de entender, por lo que no explicaré demasiado aquí. Centrémonos en analizar el segundo y tercer caso)
A veces, un hilo necesita acceder a dos o más recursos compartidos diferentes al mismo tiempo, y cada recurso compartido es administrado por un mutex diferente. El interbloqueo puede ocurrir cuando más de un subproceso bloquea el mismo conjunto de exclusiones mutuas. (Bloquear el mismo mutex dos veces)
Solución: Desbloquee inmediatamente después de acceder al recurso compartido, espere a que se completen los pasos y luego vuelva a bloquear
Durante el proceso de ejecución, dos o más procesos esperan el uno al otro debido a la competencia por los recursos, si no hay una fuerza externa, no podrán avanzar. En este momento, se dice que el sistema está en un estado de interbloqueo o se ha producido un interbloqueo en el sistema. (El subproceso 1 posee el bloqueo A, solicita el bloqueo B, el subproceso 2 posee el bloqueo B, solicita el bloqueo A)
Solución: trylock reemplaza la función de bloqueo y desbloquea (abandona activamente todos los bloqueos cuando no se adquieren todos los bloqueos)
El caso anterior:
#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_mutex_t mutex1; void* deadlock1(void *arg) { pthread_mutex_lock(&mutex1); printf("hello"); pthread_mutex_lock(&mutex1); printf("world1\n"); pthread_mutex_unlock(&mutex1); pthread_mutex_unlock(&mutex1); return NULL; } int main(void) { pthread_t tid1; //初始化 pthread_mutex_init(&mutex1,NULL); //创建线程 pthread_create(&tid1,NULL,deadlock1,NULL); //设置线程分离 pthread_detach(tid1); //退出主线程 pthread_exit(0); return 0; }#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_mutex_t mutex1; pthread_mutex_t mutex2; void* deadlock1(void *arg) { pthread_mutex_lock(&mutex1); printf("hello"); sleep(4); pthread_mutex_lock(&mutex2); printf("world1\n"); pthread_mutex_unlock(&mutex2); pthread_mutex_unlock(&mutex1); return NULL; } void* deadlock2(void *arg) { // sleep(1); pthread_mutex_lock(&mutex2); printf("HELLOE"); sleep(3); pthread_mutex_lock(&mutex1); printf("WORLD\n"); pthread_mutex_unlock(&mutex1); pthread_mutex_unlock(&mutex2); return NULL; } int main(void) { pthread_t tid1,tid2; //初始化 pthread_mutex_init(&mutex1,NULL); pthread_mutex_init(&mutex2,NULL); //创建线程 pthread_create(&tid1,NULL,deadlock1,NULL); pthread_create(&tid2,NULL,deadlock2,NULL); //设置线程分离 pthread_detach(tid1); pthread_detach(tid2); //退出主线程 pthread_exit(0); return 0; }

bloqueo de lectura y escritura
Similar a los mutex, pero los bloqueos de lectura y escritura permiten un mayor paralelismo. Sus características son: escritura exclusiva, lectura compartida
Cuando un subproceso ya tiene el mutex, el mutex bloquea todos los subprocesos que intentan ingresar a la sección crítica. Pero considere una situación en la que el subproceso que actualmente contiene la exclusión mutua solo quiere leer y acceder al recurso compartido y, al mismo tiempo, varios otros subprocesos también desean leer el recurso compartido, pero debido a la exclusividad de la exclusión mutua, todos los demás subprocesos no pueden acceder al recurso compartido Al no poder adquirir bloqueos, es imposible obtener acceso a los recursos compartidos, pero de hecho múltiples subprocesos leen y acceden simultáneamente a los recursos compartidos no causarán problemas.
En las operaciones de lectura y escritura de datos, hay más operaciones de lectura y relativamente pocas operaciones de escritura. Por ejemplo: aplicaciones de lectura y escritura de datos de bases de datos. Para cumplir con el requisito actual de permitir múltiples lecturas pero solo una escritura, el subproceso proporciona un bloqueo de lectura y escritura.
Funciones de bloqueo de lectura y escritura:
1. Si otros subprocesos leen datos, otros subprocesos pueden realizar operaciones de lectura, pero no se permiten operaciones de escritura.
2. Si otros subprocesos escriben datos, otros subprocesos no pueden leer y escribir operaciones
3. La escritura es exclusiva y la escritura tiene una alta prioridad (para evitar la falta de escritura)
Habiendo dicho tanto, descubrí que es el problema del lector-escritor en el libro de texto del sistema operativo... jajaja
funciones relacionadas
Tipo de bloqueo de lectura y escritura: pthread_rwlock_t
función pthread_rwlock_init
int pthread_rwlock_init(pthread_rwlock_t *restringir rwlock,
const pthread_rwlockattr_t *restringir attr);
Función: inicializar un bloqueo de lectura y escritura
parámetro:
attr indica el atributo del bloqueo de lectura y escritura, generalmente usa el atributo predeterminado, solo pasa NULL
función pthread_rwlock_destroy
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
Función: destruir un bloqueo de lectura y escritura
función pthread_rwlock_rdlock
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
Función: solicitar bloqueo de lectura-escritura en modo de lectura (solicitar bloqueo de lectura)
función pthread_rwlock_wrlock
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
Rol: solicitar un bloqueo de lectura y escritura en modo de escritura (solicitar un bloqueo de escritura)
función pthread_rwlock_unlock
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
Función: desbloquear
función pthread_rwlock_tryrdlock
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
Función: bloqueo de lectura de solicitud sin bloqueo
función pthread_rwlock_trywrlock
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
Rol: bloqueo de escritura de solicitud sin bloqueo
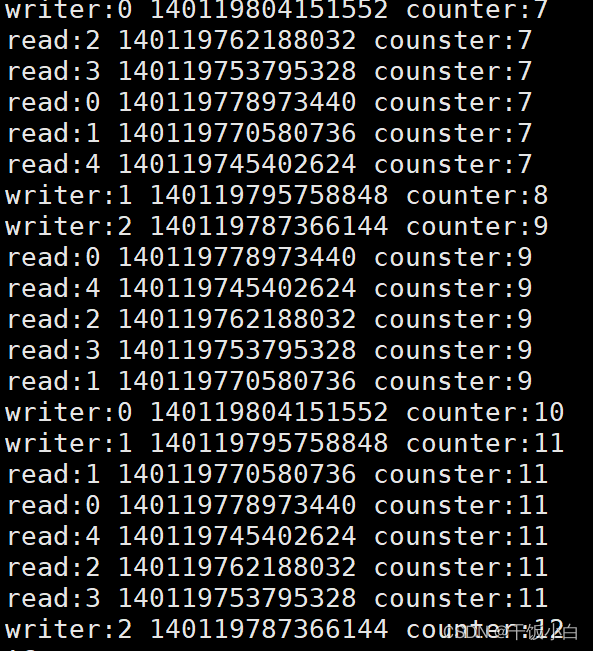
El caso anterior (múltiples subprocesos leen y escriben los mismos datos compartidos al mismo tiempo)
#include <stdio.h> #include <pthread.h> #include <unistd.h> pthread_rwlock_t rwlock; int counter = 0; //写线程 void *th_write(void *arg) { int t; int i = (int)arg; while(1) { pthread_rwlock_wrlock(&rwlock); //上写锁 sleep(2); printf("writer:%d %lu counter:%d\n",i,pthread_self(),++counter); pthread_rwlock_unlock(&rwlock); //解锁 usleep(10000); } } //读线程 void *th_read(void *arg) { int i = (int)arg; while(1) { pthread_rwlock_rdlock(&rwlock); //上读锁 printf("read:%d %lu counster:%d\n",i,pthread_self(),counter); pthread_rwlock_unlock(&rwlock); sleep(3); } } int main(void) { int i; pthread_t tid[8]; pthread_rwlock_init(&rwlock,NULL); for(i=0;i<3;++i) { pthread_create(&tid[i],NULL,th_write,(void *)i); } for(i=0;i<5;++i) { pthread_create(&tid[i],NULL,th_read,(void *)i); } //回收子线程 for(i=0;i<8;++i) { pthread_join(tid[i],NULL); } //销毁读写锁 pthread_rwlock_destroy(&rwlock); return 0; }
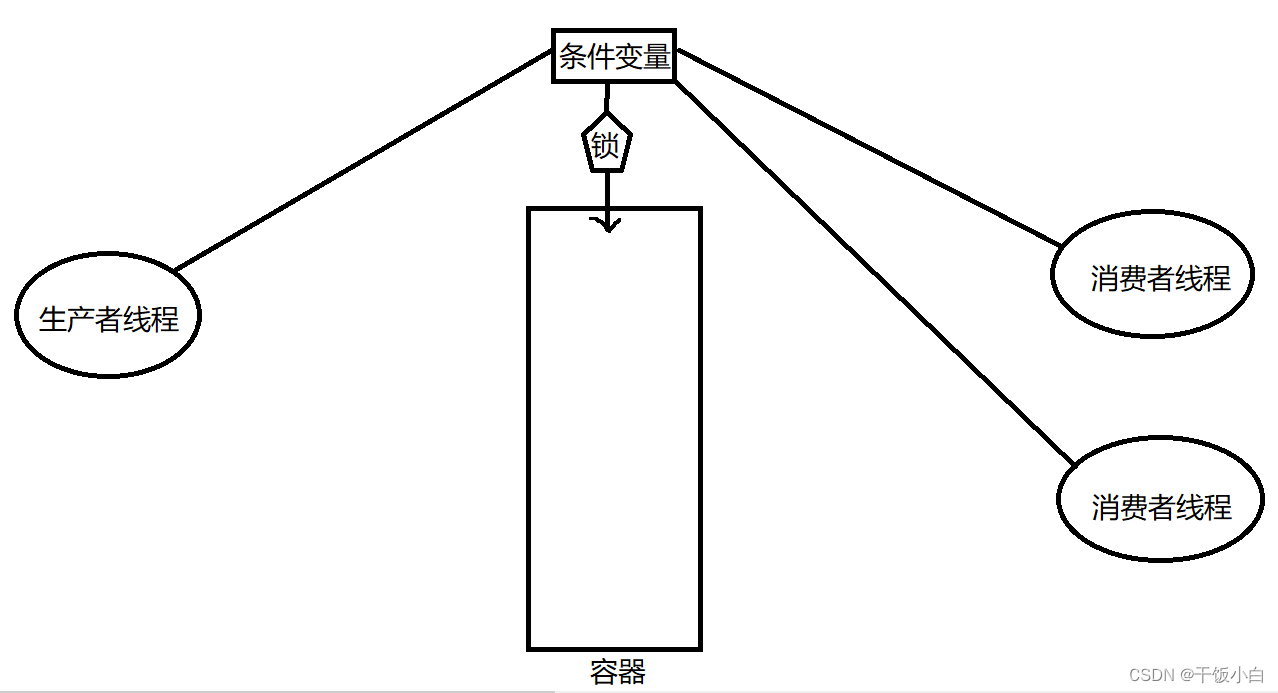
variable de condición
La variable de condición en sí no es un bloqueo, pero puede hacer que el subproceso se bloquee . Por lo general, se usa junto con un mutex. Proporcione un lugar adecuado para subprocesos múltiples. (Problema de sincronización de subprocesos, mutex y bloqueo de lectura y escritura para resolver la exclusión mutua de subprocesos)
funciones relacionadas
Tipo de variable de condición: pthread_cond_t
función pthread_cond_init
int pthread_cond_int(pthread_cond_t *restringir cond,
const pthread_condattr_t *restringir attr);
Parámetros: attr indica el atributo de la variable de condición, normalmente pasa NULL
Puede usar el método de inicialización estática para inicializar variables de condición
pthread_cond_t cond = PTHREAD_COND_INITIALIZER
función pthread_cond_destroy
int pthread_cond_destroy(pthread_cond_t *cond);
Rol: destruir una variable de condición
función pthread_cond_wait
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
Función: 1. Bloqueo y espera a que se satisfaga una variable de condición cond [No satisfecho: bloqueado esperando satisfacción Satisfecho: no bloqueado]
2. Liberar el mutex que ha sido masterizado (desbloquear el mutex) es equivalente a pthread_mutex_unlock(&mutex);
[1,2 son operaciones atómicas, indivisibles]
3. Cuando se despierte, cuando la función pthread_cond_wait regrese, desbloquee y vuelva a solicitar el mutex
pthread_mutex_lock(&mutex);
función pthread_cond_timedwait
int pthread_cond_timewat(pthread_cond _t *restringir cond,
pthread_mutex_t *restringir mutex,
const struct timespec *restrict abstime);
Función: espera una variable de condición por un tiempo limitado
parámetro:
abstime es un tiempo absoluto, time(NULL) devuelve un tiempo absoluto,
alarm(1) es un tiempo relativo, 1s relativo al tiempo actual.
Instrucciones:
Uso incorrecto:
estructura especificación de tiempo t = {1,0};
pthread_cond_timedwait(&cond,&mutex,&t); //solo programado para 1970.1.1 00:00:01
Uso Correcto:
time_t cur = time(NULL); //Obtener la hora actual
struct timespec t;
t.tv_sec = cur+1;//Define un segundo
pthread_cond_timedwait(&cond,&mutex,&t);
función pthread_cond_signal
int pthread_cond_signal(pthread_cond_t *cond);
Rol: despertar uno o más subprocesos en espera
función pthread_cond_broadcast
int pthread_cond_broadcast(pthread_cond_t *cond);
Función: despertar todos los hilos mediante la transmisión
Por ejemplo, vea el modelo consumidor-productor

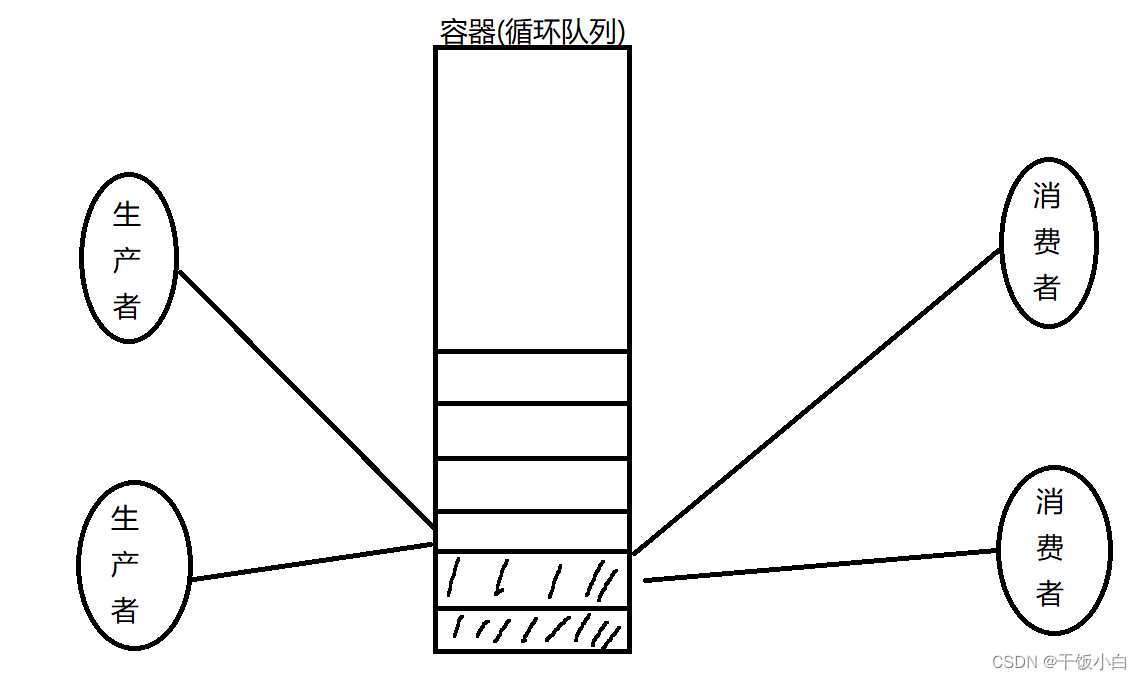
productor consumidor modelo
Objetos en el modelo productor: productores, consumidores, contenedores
Un extremo se dedica a la producción de bienes y el otro extremo se dedica al consumo de bienes. Luego habrá algunos problemas a los que se debe prestar atención.Cuando el contenedor está lleno, el productor bloqueará y esperará a que el consumidor consuma los bienes para que el contenedor pueda almacenar los artículos. Cuando el contenedor está vacío, debe bloquear y esperar a que el productor produzca artículos y los almacene en el contenedor.
Solo hay un subproceso que ingresa al contenedor a la vez (se forma una relación de exclusión mutua y el productor y el consumidor mantienen una relación sincrónica)
¿Por qué hablar del modelo de productor y consumidor, porque en el desarrollo de proyectos reales, este modelo se usa en muchos lugares?
Implementación del modelo de consumidor productor (versión de variable de condición)
Un caso típico de sincronización de subprocesos es el modelo productor-consumidor, y es más conveniente implementar este modelo con la ayuda de variables de condición. Supongamos que hay dos hilos, uno que simula el comportamiento del productor y el otro que simula el comportamiento del consumidor. Dos subprocesos operan simultáneamente en un recurso compartido (comúnmente llamado grupo), desde el cual los productores agregan elementos y desde el cual los consumidores consumen productos.
Porque las operaciones de inserción y eliminación en el programa son más frecuentes (utilizo una lista enlazada para implementar el contenedor)
#include <stdio.h> #include <unistd.h> #include <pthread.h> struct msg { struct msg *next; int num; }; struct msg *head; //静态方法初始化 pthread_cond_t cond = PTHREAD_COND_INITIALIZER; pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; //消费者 void* consumer(void *p) { struct msg *mp; while(1) { //取产品 pthread_mutex_lock(&mutex); while(head==NULL) //不能用 if 防止虚假唤醒 { pthread_cond_wait(&cond,&mutex); } mp = head; head = mp->next; pthread_mutex_unlock(&mutex); //消费产品 printf("消费:%d\n",mp->num); free(mp); sleep(rand()%5); } return NULL; } //生产者 void *product(void *arg) { struct msg *mp; while(1) { //生产产品 mp = malloc(sizeof(struct msg)); mp->num = rand()%200; printf("生产:%d\n",mp->num); //防止产品 pthread_mutex_lock(&mutex); mp->next = head; head = mp; pthread_mutex_unlock(&mutex); pthread_cond_signal(&cond); sleep(rand()%5); } return NULL; } int main(void) { pthread_t pid,cid; srand(time(NULL)); pthread_create(&pid,NULL,product,NULL); pthread_create(&cid,NULL,consumer,NULL); pthread_join(pid,NULL); pthread_join(cid,NULL); return 0; }Ventajas de las variables de condición:
Las variables de condición pueden reducir la competencia en comparación con mutex.
Si usa mutex directamente, además de la competencia entre productores y consumidores, los consumidores también deben competir por mutex, pero si no hay datos en la agregación (lista vinculada), no hay competencia significativa entre consumidores. Con el mecanismo de condición variable, solo cuando el productor complete la producción se generará competencia entre los consumidores y se mejorará la eficiencia del programa.
cantidad de señal
Debido a la granularidad relativamente grande del mutex, si queremos compartir parte de los datos de un objeto entre varios subprocesos , no hay forma de usar el mutex para lograrlo, y solo podemos bloquear todo el objeto de datos. Aunque esto logra el propósito de garantizar la exactitud de los datos cuando las operaciones de subprocesos múltiples comparten datos, prácticamente conduce a una disminución en la concurrencia de subprocesos. Los subprocesos cambian de ejecución concurrente a ejecución en serie. No es diferente de usar un solo proceso directamente.
El semáforo es un método de procesamiento relativamente comprometido, que no solo puede garantizar la sincronización, los datos no se confundirán, sino que también mejorará la concurrencia de subprocesos.
(También se puede utilizar entre procesos)
Los semáforos son como operaciones PV
funciones relacionadas
Tipo de semáforo: sem_t
El valor inicial del semáforo determina el número de subprocesos que ocupan el semáforo
función sem_init
int sem_init(sem_t *sem,int pshared,valor int sin signo);
parámetro:
semáforo sem_t
pshared 0 es hilo, distinto de cero (generalmente 1) se usa para el proceso
valor especifica el valor inicial del semáforo
función sem_destroy
int sem_destroy(sem_t *sem);
Función: destruir un semáforo
función sem_esperar
int sem_espera(sem_t *sem);
Función: primer juez sem==0 bloqueo, valor -1
Reste 1 al valor del semáforo, si es 0 bloquee
función sem_trywait
int sem_trywait(sem_t *sem);
Efecto: intenta restar 1 al semáforo (sin bloqueo)
función sem_timedwait
sem_timedwait(sem_t *sem,const struct timespec *abs_timeout);
Función: intente bloquear el semáforo dentro de un límite de tiempo--
Parámetro: abs_timeout es un tiempo absoluto
Tiempo para 1 segundo:
time_t cur = time(NULL); //Obtener la hora actual
struct timespec t; //Definir la variable de estructura timespec t
t.tv_sec = en + 1;
//t.tv_nsec = t.tv_sec + 100;
sem_timedwait(&sem,&t);
función sem_post
int sem_post(sem_t *sem);
Función: suma 1 al semáforo
función sem_getvalue
sem_getvalue(sem_t *sem,int *sval);
Función: Obtener el valor del semáforo actual
Por ejemplo, vea el modelo del consumidor del productor
Implementación del modelo de consumidor productor (versión semáforo)
#include <stdio.h> #include <unistd.h> #include <pthread.h> #include <semaphore.h> #define NUM 5 int queue[NUM]; //缓冲区 sem_t produc_number,blank_number; void *product(void *arg) { int i = 0; while(1) { sem_wait(&blank_number); //缓冲区是否已满 queue[i] = rand()%100 + 1; //生产产品 printf("放缓冲区:%d\n",queue[i]); sem_post(&produc_number); //产品数 ++ i = (i+1)%NUM; sleep(rand()%3); } return NULL; } void *consumer(void *arg) { int i = 0; while(1) { sem_wait(&produc_number); //产品数量-- printf("取走缓冲区:%d\n",queue[i]); queue[i] = 0; sem_post(&blank_number); //格子数目++ i = (i+1)%NUM; //循环队列,下一个位置 sleep(rand()%3); } return NULL; } int main(void) { pthread_t pid,cid; sem_init(&blank_number,0,NUM); //初始时缓冲区空格子为5(或者说初始时生产者为5) sem_init(&produc_number,0,0); //初始时产品数为0(或者说消费者为0) pthread_create(&pid,NULL,product,NULL); pthread_create(&cid,NULL,consumer,NULL); pthread_join(pid,NULL); pthread_join(cid,NULL); //线程销毁 sem_destroy(&blank_number); sem_destroy(&produc_number); return 0; }
bloqueo de archivo
Use la función fcntl para implementar el mecanismo de bloqueo. Cuando el proceso de operación del archivo no adquiere el bloqueo, se puede abrir, pero no puede realizar operaciones de lectura y escritura. La función fcntl: obtiene y establece permisos de control de acceso al archivo.
int fcntl(int fd,int cmd,.../*arg*/);
Referencia 2:
F_SETLK(struct flock*) Establecer bloqueo de archivos (trylock)
F_SETLKW(struct flock*) Establecer bloqueo de archivo (bloqueo) W-->esperar
F_GETLK(struct flock*); Obtener bloqueo de archivo
Referencia 3:
bandada de estructuras{
...
short l_type; Tipo de bloqueo: F_RDLCK F_WRLCK F_UNLCK (desbloquear)
corto l_cuándo; posición de desplazamiento: SEEK_SET SEEK_CUR SEEK_END
corto l_start; posición de inicio: 1000
short l_len; length: 0 significa que todo el precio solicitado está bloqueado
l_pid corto; ID de proceso que contiene el candado: F_GETLK
...
}
#include <stdio.h> #include <fcntl.h> #include <unistd.h> void sys_err(char *str) { perror(str); exit(-1); } int main(int arg,char *argv[]) { int fd; struct flock f_lock; if(arg < 2) { printf("./a.txt filename\n"); exit(1); } if(fd == open(argv[1],O_RDWR) < 0) { sys_err("open"); } // f_lock.l_type = F_WRLCK; //设置写锁 f_lock.l_type = F_RDLCK; //设置读锁 f_lock.l_whence = SEEK_SET; //文件头部 f_lock.l_start = 0; f_lock.l_len = 0; fcntl(fd,F_SETLKW,&f_lock); //上锁 printf("get flock\n"); sleep(10); f_lock.l_type = F_UNLCK; fcntl(fd,F_SETLK,&f_lock); //解锁 printf("un flock\n"); close(fd); return 0; }Todavía siga "leer compartir, escribir exclusivo". Sin embargo, el proceso puede operar directamente el archivo sin bloquearlo, y aún se puede acceder a él con éxito, pero es probable que los datos se confundan.
El descriptor de archivo se comparte entre varios subprocesos, y el bloqueo de archivo se realiza modificando las variables miembro en la estructura de archivo a la que apunta el descriptor de archivo, por lo que el bloqueo de archivo no puede ser utilizado por varios subprocesos.