Tabla de contenido
Generar datos para la detección de círculos y rectángulos
introducción
Se han iterado varias versiones desde su lanzamiento el 18 de mayo de 2020. La última versión es la v7, que agrega capacidades de segmentación. Ha habido muchas publicaciones de blog que explican el principio de yolov5 y cómo usar los datos marcados, como la explicación detallada de la red YOLOv5 y la explicación detallada del conocimiento básico central de Yolov5 en la serie Yolo.
Simple de instalar y fácil de usar, se ha convertido en el punto de referencia de facto para los métodos de detección.
// 克隆代码库即可
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installSolo se necesita una línea de código para completar cuando se usa
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# 图片路径
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# 执行检测推理
results = model(img)
# 检测结果可视化
results.print() # or .show(), .save(), .crop(), .pandas(), etc.¿Qué? No desea escribir una sola línea de código. Si desea desarrollar sin código y ver el efecto directamente desde la cámara, ejecutar detect.py en el almacén también puede cumplir con sus requisitos.
python detect.py --weights yolov5s.pt --source 0El significado de los parámetros detallados es el siguiente, donde --weights especifica el peso previo al entrenamiento que desea usar, --source especifica la fuente que se detectará (imagen, lista de rutas de imágenes, cámara o incluso transmisión de red)
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream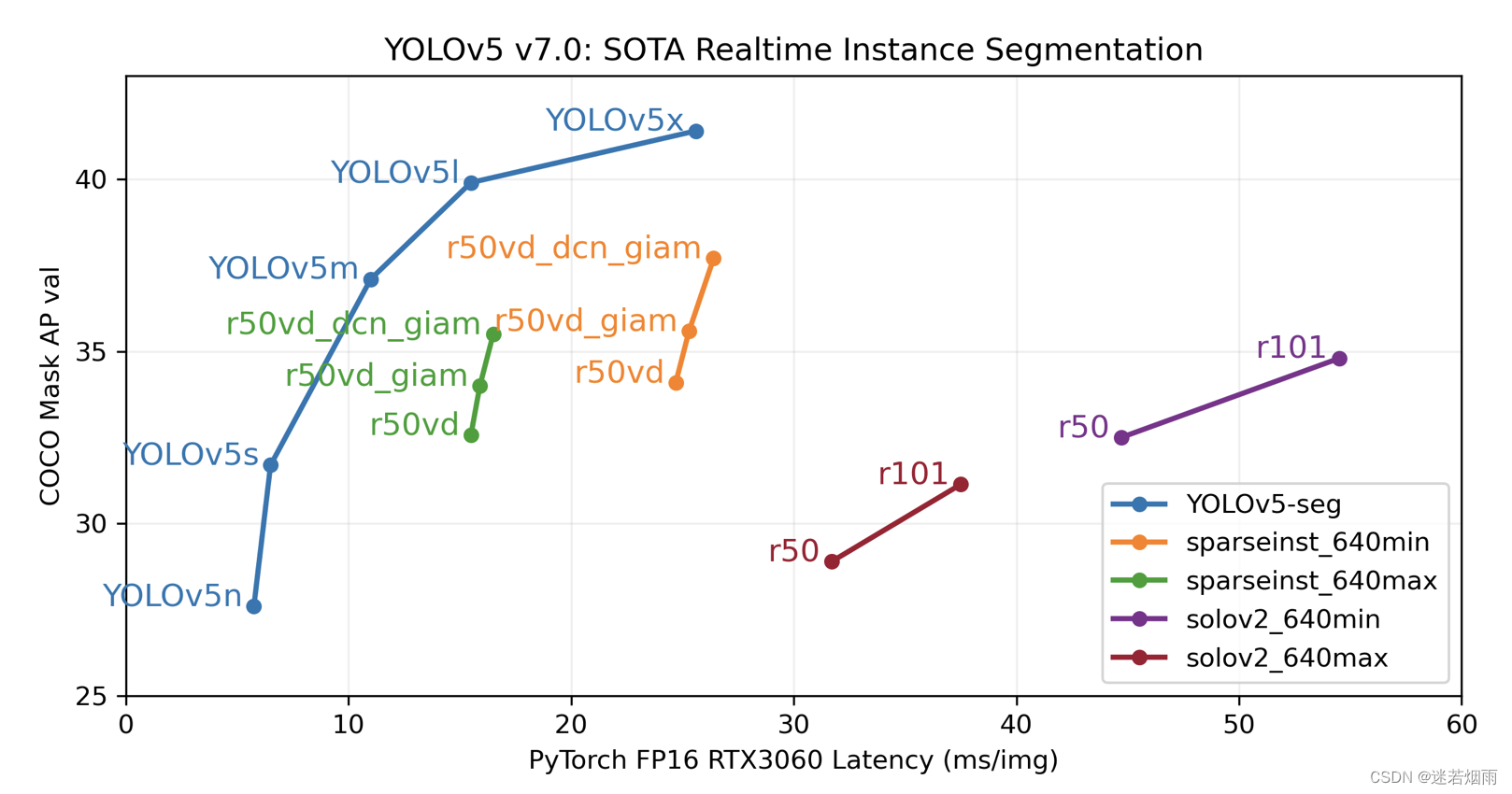
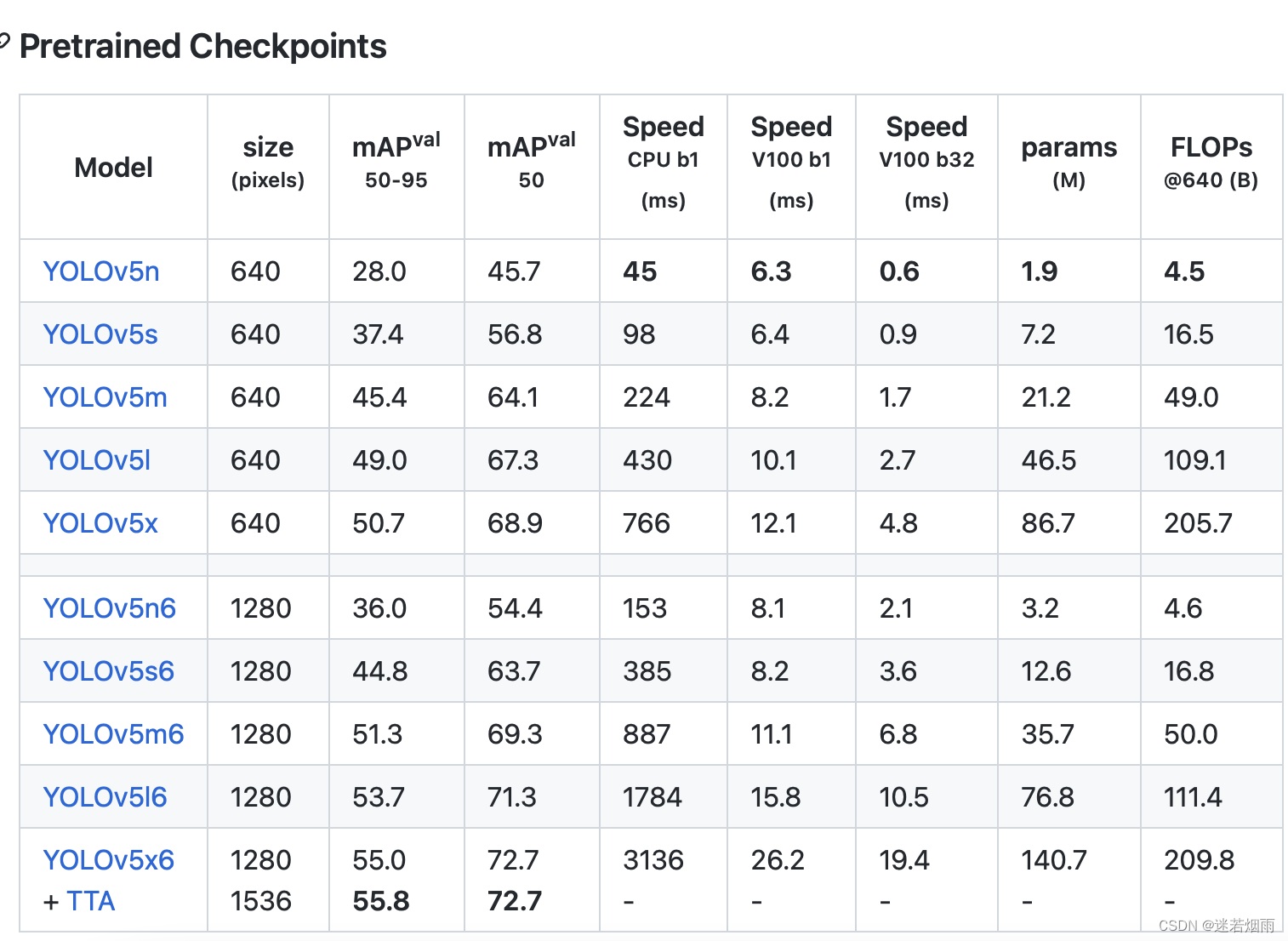
estructura de red
YOLOv5 tiene la misma arquitectura de red general para diferentes tamaños ( n, s, m, l, ), pero usa diferentes profundidades y anchos en cada submódulo para manejar los parámetros en el archivo respectivamente . También cabe señalar que además de la versión oficial , , , , también existen , , , , la diferencia es que esta última es para imágenes con resoluciones más grandes, por ejemplo , por supuesto que hay algunas diferencias en la estructura. capas de características de predicción, mientras que el primero solo reducirá la muestra a 32 veces y utilizará 3 capas de características de predicción.xyamldepth_multiplewidth_multiplensmlxn6s6m6l6x61280x1280
Comparado con la versión anterior, YOLOv5
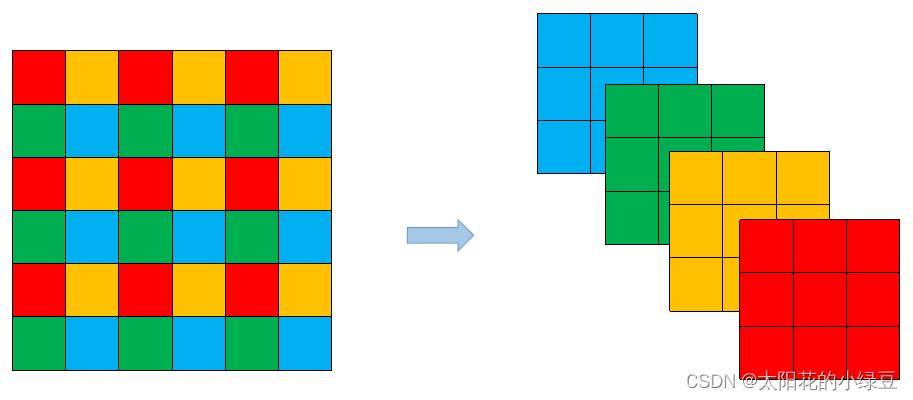
v6.0tiene un pequeño cambio después de la versión, reemplazando la primera capa de la red (originalmente unFocusmódulo) con una6x6capa convolucional grande y pequeña. Los dos son equivalentes en teoría , pero para algunos dispositivos GPU existentes (y los algoritmos de optimización correspondientes), es más eficiente usar6x6capas convolucionales grandes y pequeñas que usarFocusmódulos. Para obtener más información, consulte este número 4825. La siguiente figura es elFocusmódulo original (similar al anteriorSwin Transformer)Patch Merging,2x2divide cada píxel adyacente en unopatch, y luegopatchjunta los píxeles de la misma posición (mismo color) en cada uno para obtener 4feature map, y luego conecta una3x3capa convolucional del tamaño anterior .6x6Esto es equivalente a usar una capa convolucional de un tamaño directamente .
La parte del cuello será
SPPreemplazada por unaSPPF(Glenn Jocherde diseño propio), la función de los dos es la misma, pero la última es más eficiente.SPPLa estructura es pasar la entrada a través de múltiples tamaños diferentes en paraleloMaxPool, y luego hacer una mayor fusión, lo que puede resolver el problema objetivo de múltiples escalas hasta cierto punto. LaSPPFestructura es serializar la entrada a través de capas5x5de varios tamañosMaxPool. Cabe señalar aquí que el resultado del cálculo de la serialización de capas5x5de dos tamaños es el mismo que el de las capas de un tamaño, y el resultado del cálculo de la serialización de capas de tres tamaños es el mismo que el de las capas de un tamaño Los resultados del cálculo de la capa son los mismos.MaxPool9x9MaxPool5x5MaxPool13x13MaxPool

aumento de datos
Mosaico , combina cuatro imágenes en una imagen

Copie y pegue , pegue aleatoriamente algunos objetivos en la imagen, la premisa es que los datos deben tener segmentsdatos, es decir, la información de segmentación de instancia de cada objetivo

Afín aleatorio (rotación, escala, traducción y corte) realiza la transformación afín aleatoriamente, pero de acuerdo con los hiperparámetros en el archivo de configuración, se encuentra que solo se usan la suma Scaley la traducción.Translation

MixUp es mezclar dos imágenes con cierta transparencia, no está claro si es útil o no, después de todo, no hay papeles ni experimentos de ablación. Solo el modelo más grande se usa en el código MixUpy solo el 10 % de las veces.

Albumentaciones , principalmente para filtrar, ecualizar histogramas y cambiar la calidad de la imagen, etc. Veo que el código escrito en el código solo se habilitará cuando se instale el paquete, pero el paquete está comentado albumentationsen el requirements.txtarchivo del proyecto, por lo que no está habilitado por defecto albumentations.
Aumentar HSV (tono, saturación, valor) ajusta aleatoriamente el tono, la saturación y la luminosidad.

Volteo horizontal aleatorio , volteo horizontal aleatorio

Muchas estrategias de entrenamiento se utilizan en el código fuente de YOLOv5
- Entrenamiento multiescala (0,5~1,5x) , entrenamiento multiescala, suponiendo que el tamaño de la imagen de entrada se establece en 640 × 640, el tamaño utilizado durante el entrenamiento se selecciona aleatoriamente entre 0,5 × 640 ∼ 1,5 × 640, preste atención al valor obtenido al seleccionar el valor Ambos son múltiplos enteros de 32 (porque la red reducirá la muestra un máximo de 32 veces).
- AutoAnchor (para entrenar datos personalizados) , al entrenar su propio conjunto de datos, puede volver a agruparse para generar plantillas de anclas de acuerdo con los objetivos de su propio conjunto de datos.
- Calentamiento y programador Cosine LR , calentamiento antes del entrenamiento
Warmupy luego useCosinela estrategia de caída de la tasa de aprendizaje.- La EMA (media móvil exponencial) se puede entender como la adición de un impulso a los parámetros de entrenamiento para que el proceso de actualización sea más fluido.
- La precisión mixta , el entrenamiento de precisión mixta, puede reducir el uso de la memoria de video y acelerar el entrenamiento, siempre que sea compatible con el hardware de la GPU.
- Evolucionar hiperparámetros , optimización de hiperparámetros, las personas que no tienen experiencia en alquimia no deben tocarlo, solo mantenga el valor predeterminado.
La pérdida de YOLOv5 consta principalmente de tres partes:
- Se utiliza pérdida de clases
BCE loss, pérdida de clasificación , preste atención para calcular solo la pérdida de clasificación de muestras positivas. - Todavía se usa la pérdida de objetividad ,
objla pérdidaBCE lossTenga en cuenta que estoobjse refiere al cuadro delimitador de destino predicho por la red y el GT BoxCIoU. Lo que se calcula aquí esobjla pérdida de todas las muestras. - Se utiliza pérdida de ubicación , pérdida de ubicación
CIoU loss, preste atención para calcular solo la pérdida de ubicación de muestras positivas.
desplegar
Las versiones anteriores a yolov5 v6.0 (no incluidas) usan la capa de enfoque, lo que provoca muchos cambios en la implementación y requiere muchas operaciones complicadas . los pasos son los siguientes Detectar YOLOv5 para la implementación
// 1.导出onnx
python models/export.py --weights yolov5s.pt --img 320 --batch 1
// 2.简化模型
python -m onnxsim yolov5s.onnx yolov5s-sim.onnx
// 3. 模型转换到ncnn
./onnx2ncnn yolov5s-sim.onnx yolov5s.param yolov5s.bin
// 4. 编辑 yolov5s.param文件
第4行到13行删除(也就是Slice和Concat层),将第二行由172改成164(一共删除了10层,第二行的173更改为164,计算方法173-(10-1)=164)
增加自定义层
YoloV5Focus focus 1 1 images 159
其中159是刚才删除的Concat层的输出
// 5. 支持动态尺寸输入
将reshape中的960,240,60更改为-1,或者其他 0=后面的数
// 6. ncnnoptimize优化
./ncnnoptimize yolov5s.param yolov5s.bin yolov5s-opt.param yolov5s-opt.bin 1Después de v6.0, es mucho más conveniente usar la convolución 6x6. Puede usar directamente el módulo dnn de opencv para la implementación. Para obtener más detalles, consulte Detección de objetos con YOLOv5, OpenCV, Python y C++ , código yolov5-opencv-cpp-python
Sin embargo, cabe señalar que solo puede cooperar con opencv4.5.5 y superior. Incluye principalmente 6 pasos
// 1.加载模型
net = cv2.dnn.readNet('yolov5s.onnx')
// 2.加载图片
def format_yolov5(source):
# put the image in square big enough
col, row, _ = source.shape
_max = max(col, row)
resized = np.zeros((_max, _max, 3), np.uint8)
resized[0:col, 0:row] = source
# resize to 640x640, normalize to [0,1[ and swap Red and Blue channels
result = cv2.dnn.blobFromImage(resized, 1/255.0, (640, 640), swapRB=True)
return result
// 3.执行推理
predictions = net.forward()
output = predictions[0]
// 4.展开结果
def unwrap_detection(input_image, output_data):
class_ids = []
confidences = []
boxes = []
rows = output_data.shape[0]
image_width, image_height, _ = input_image.shape
x_factor = image_width / 640
y_factor = image_height / 640
for r in range(rows):
row = output_data[r]
confidence = row[4]
if confidence >= 0.4:
classes_scores = row[5:]
_, _, _, max_indx = cv2.minMaxLoc(classes_scores)
class_id = max_indx[1]
if (classes_scores[class_id] > .25):
confidences.append(confidence)
class_ids.append(class_id)
x, y, w, h = row[0].item(), row[1].item(), row[2].item(), row[3].item()
left = int((x - 0.5 * w) * x_factor)
top = int((y - 0.5 * h) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
// 5.非极大值抑制
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45)
result_class_ids = []
result_confidences = []
result_boxes = []
for i in indexes:
result_confidences.append(confidences[i])
result_class_ids.append(class_ids[i])
result_boxes.append(boxes[I])
// 6.可视化结果输出
class_list = []
with open("classes.txt", "r") as f:
class_list = [cname.strip() for cname in f.readlines()]
colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
for i in range(len(result_class_ids)):
box = result_boxes[i]
class_id = result_class_ids[i]
color = colors[class_id % len(colors)]
conf = result_confidences[i]
cv2.rectangle(image, box, color, 2)
cv2.rectangle(image, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)
cv2.putText(image, class_list[class_id], (box[0] + 5, box[1] - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0))
Generar datos para la detección de círculos y rectángulos
A continuación, un proyecto para detectar círculos y rectángulos muestra la generación de datos de entrenamiento y el proceso de entrenamiento de yolov5. Pero etiquetar datos es una tarea que requiere mucho tiempo y mano de obra ¿No sería genial si los datos generados pudieran usarse para verificar rápidamente algunos experimentos?
Basado en Lable Studio [registros de combate reales de yoloV5] ¡Xiaobai también puede entrenar su propio conjunto de datos! Basado en labelimg, te enseñaré cómo usar el aprendizaje profundo para hacer detección de objetos (2): etiquetado de datos- Programador
El formato de etiquetado de yolov5 es muy simple. Las imágenes se colocan en la carpeta de imágenes. Debajo de la carpeta de etiquetas, cada archivo de imagen tiene un archivo txt correspondiente con el mismo nombre, que almacena la categoría, las coordenadas normalizadas y el ancho de cada objetivo por línea. Alto, muchas herramientas de anotación admiten la exportación directa del formato de anotación yolo, y también hay muchas secuencias de comandos que pueden convertir fácilmente de VOC, coco y otros formatos al formato YOLO.
类别1 归一化中心点坐标x 归一化中心坐标y 归一化宽度 归一化高度
类别2 归一化中心点坐标x 归一化中心坐标y 归一化宽度 归一化高度
1. Aquí tomamos el círculo de detección como ejemplo para presentar cada paso en detalle
El primero es la generación y visualización de datos de entrenamiento, dibujar aleatoriamente un círculo con un punto aleatorio como centro y un radio de 60-100 como el objetivo que queremos detectar, y generar un total de 100.000 datos de entrenamiento.
import os
import cv2
import math
import random
import numpy as np
from tqdm import tqdm
def generate():
img = np.zeros((640,640,3),np.uint8)
x = 100+random.randint(0, 400)
y = 100+random.randint(0, 400)
radius = random.randint(60,100)
r = random.randint(0,255)
g = random.randint(0,255)
b = random.randint(0,255)
cv2.circle(img, (x,y), radius, (b,g,r),-1)
return img, [x,y,radius]
def generate_batch(num=10000):
images_dir = "data/circle/images"
if not os.path.exists(images_dir):
os.makedirs(images_dir)
labels_dir = "data/circle/labels"
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
for i in tqdm(range(num)):
img, labels = generate()
cv2.imwrite(images_dir+"/"+str(i)+".jpg", img)
with open(labels_dir+"/"+str(i)+".txt", 'w') as f:
x, y, radius = labels
f.write("0 "+str(x/640)+" "+str(y/640)+" "+str(2*radius/640)+" "+str(2*radius/640)+"\n")
def show_gt(dir='data/circle'):
files = os.listdir(dir+"/images")
gtdir = dir+"/gt"
if not os.path.exists(gtdir):
os.makedirs(gtdir)
for file in tqdm(files):
imgpath = dir+"/images/"+file
img = cv2.imread(imgpath)
h,w,_ = img.shape
labelpath = dir+"/labels/"+file[:-3]+"txt"
with open(labelpath) as f:
lines = f.readlines()
for line in lines:
items = line[:-1].split(" ")
c = int(items[0])
cx = float(items[1])
cy = float(items[2])
cw = float(items[3])
ch = float(items[4])
x1 = int((cx - cw/2)*w)
y1 = int((cy - ch/2)*h)
x2 = int((cx + cw/2)*w)
y2 = int((cy + ch/2)*h)
cv2.rectangle(img, (x1,y1),(x2,y2),(0,255,0),2)
cv2.imwrite(gtdir+"/"+file, img)
if __name__=="__main__":
generate_batch()
show_gt()

Luego construye circle.yaml
train: data/circle/images/
val: data/circle/images/
# number of classes
nc: 1
# class names
names: ['circle']2. Si desea detectar objetivos circulares y rectangulares, debe ajustar el script de generación y el archivo de configuración de datos.
import os
import cv2
import math
import random
import numpy as np
from tqdm import tqdm
def generate_circle():
img = np.zeros((640,640,3),np.uint8)
x = 100+random.randint(0, 400)
y = 100+random.randint(0, 400)
radius = random.randint(60,100)
r = random.randint(0,255)
g = random.randint(0,255)
b = random.randint(0,255)
cv2.circle(img, (x,y), radius, (b,g,r),-1)
return img, [x,y,radius*2,radius*2]
def generate_rectangle():
img = np.zeros((640,640,3),np.uint8)
x1 = 100+random.randint(0, 400)
y1 = 100+random.randint(0, 400)
w = random.randint(80, 200)
h = random.randint(80, 200)
x2 = x1 + w
y2 = y1 + h
r = random.randint(0,255)
g = random.randint(0,255)
b = random.randint(0,255)
cx = (x1+x2)//2
cy = (y1+y2)//2
cv2.rectangle(img, (x1,y1), (x2,y2), (b,g,r),-1)
return img, [cx,cy,w,h]
def generate_batch(num=100000):
images_dir = "data/shape/images"
if not os.path.exists(images_dir):
os.makedirs(images_dir)
labels_dir = "data/shape/labels"
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
for i in tqdm(range(num)):
if i % 2 == 0:
img, labels = generate_circle()
else:
img, labels = generate_rectangle()
cv2.imwrite(images_dir+"/"+str(i)+".jpg", img)
with open("data/shape/labels/"+str(i)+".txt", 'w') as f:
cx,cy,w,h = labels
f.write(str(i%2)+" "+str(cx/640)+" "+str(cy/640)+" "+str(w/640)+" "+str(h/640)+"\n")
def show_gt(dir='data/shape'):
files = os.listdir(dir+"/images")
gtdir = dir+"/gt"
if not os.path.exists(gtdir):
os.makedirs(gtdir)
for file in tqdm(files):
imgpath = dir+"/images/"+file
img = cv2.imread(imgpath)
h, w, _ = img.shape
labelpath = dir+"/labels/"+file[:-3]+"txt"
with open(labelpath) as f:
lines = f.readlines()
for line in lines:
items = line[:-1].split(" ")
c = int(items[0])
cx = float(items[1])
cy = float(items[2])
cw = float(items[3])
ch = float(items[4])
x1 = int((cx - cw/2)*w)
y1 = int((cy - ch/2)*h)
x2 = int((cx + cw/2)*w)
y2 = int((cy + ch/2)*h)
cv2.rectangle(img, (x1,y1),(x2,y2),(0,255,0),2)
cv2.putText(img, str(c), (x1,y1), 3,1,(0,0,255))
cv2.imwrite(gtdir+"/"+file, img)
if __name__=="__main__":
generate_batch()
show_gt()Shape.yaml correspondiente, tenga en cuenta que el número de categorías es 2
train: data/shape/images/
val: data/shape/images/
# number of classes
nc: 2
# class names
names: ['circle', 'rectangle']tren
Comience a entrenar con el siguiente comando
python train.py --data circle.yaml --cfg yolov5s.yaml --weights '' --batch-size 64Si hay dos tipos de blancos, circulares y rectangulares, el comando es
python train.py --data shape.yaml --cfg yolov5s.yaml --weights '' --batch-size 64


Mira las estadísticas, categorías y distribuciones impresas durante el entrenamiento

Entrena algunas épocas para ver los resultados.
epoch, train/box_loss, train/obj_loss, train/cls_loss, metrics/precision, metrics/recall, metrics/mAP_0.5,metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss, x/lr0, x/lr1, x/lr2
0, 0.03892, 0.011817, 0, 0.99998, 0.99978, 0.995, 0.92987, 0.0077891, 0.0030948, 0, 0.0033312, 0.0033312, 0.070019
1, 0.017302, 0.0049876, 0, 1, 0.9999, 0.995, 0.99105, 0.0031843, 0.0015662, 0, 0.0066644, 0.0066644, 0.040019
2, 0.011272, 0.0034826, 0, 1, 0.99994, 0.995, 0.99499, 0.0020194, 0.0010969, 0, 0.0099969, 0.0099969, 0.010018
3, 0.0080153, 0.0027186, 0, 1, 0.99994, 0.995, 0.995, 0.0013095, 0.00083033, 0, 0.0099978, 0.0099978, 0.0099978
4, 0.0067639, 0.0023831, 0, 1, 0.99996, 0.995, 0.995, 0.00099513, 0.00068878, 0, 0.0099978, 0.0099978, 0.0099978
5, 0.0061637, 0.0022279, 0, 1, 0.99996, 0.995, 0.995, 0.00090497, 0.00064193, 0, 0.0099961, 0.0099961, 0.0099961
6, 0.0058844, 0.002144, 0, 0.99999, 0.99998, 0.995, 0.995, 0.0009117, 0.00063328, 0, 0.0099938, 0.0099938, 0.0099938
7, 0.0056247, 0.00208, 0, 0.99999, 0.99999, 0.995, 0.995, 0.00086355, 0.00061343, 0, 0.0099911, 0.0099911, 0.0099911
8, 0.0054567, 0.0020223, 0, 1, 0.99999, 0.995, 0.995, 0.00081632, 0.00059592, 0, 0.0099879, 0.0099879, 0.0099879
9, 0.0053597, 0.0019864, 0, 1, 1, 0.995, 0.995, 0.00081379, 0.00058942, 0, 0.0099842, 0.0099842, 0.0099842
10, 0.0053103, 0.0019559, 0, 1, 1, 0.995, 0.995, 0.0008175, 0.00058669, 0, 0.00998, 0.00998, 0.00998
11, 0.0052146, 0.0019445, 0, 1, 1, 0.995, 0.995, 0.00083248, 0.00058731, 0, 0.0099753, 0.0099753, 0.0099753
12, 0.0050852, 0.0019065, 0, 1, 1, 0.995, 0.995, 0.00085092, 0.00058853, 0, 0.0099702, 0.0099702, 0.0099702
13, 0.0050589, 0.0019031, 0, 1, 1, 0.995, 0.995, 0.00086915, 0.00059267, 0, 0.0099645, 0.0099645, 0.0099645
14, 0.0049664, 0.0018693, 0, 1, 1, 0.995, 0.995, 0.00090856, 0.00059815, 0, 0.0099584, 0.0099584, 0.0099584
15, 0.0049839, 0.0018568, 0, 1, 1, 0.995, 0.995, 0.00093147, 0.00060425, 0, 0.0099517, 0.0099517, 0.0099517
16, 0.0049079, 0.0018459, 0, 1, 1, 0.995, 0.995, 0.0009656, 0.00061124, 0, 0.0099446, 0.0099446, 0.0099446
17, 0.0048693, 0.0018277, 0, 1, 1, 0.995, 0.995, 0.00099703, 0.00061948, 0, 0.009937, 0.009937, 0.009937
18, 0.0048052, 0.0018103, 0, 1, 1, 0.995, 0.995, 0.0010246, 0.00062618, 0, 0.0099289, 0.0099289, 0.0099289
19, 0.0047608, 0.0017947, 0, 1, 1, 0.995, 0.995, 0.0010439, 0.00063123, 0, 0.0099203, 0.0099203, 0.0099203
El mAP alcanzó 99.5+, lo cual es realmente bueno, mira los resultados de la predicción




objetos redondos y rectangulares




desplegar
Finalmente, use el siguiente comando para detectar, recuerde reemplazar la ruta con la ruta local
python detect.py --weights exps/yolov5s_circle/weights/best.pt --source data/circle/images 

La demostración integrada es demasiado larga para ser compatible con varios formatos, y el código de implementación de onnx es mucho más simple
import cv2
import numpy as np
import torch
from torchvision import transforms
import onnxruntime
from utils.general import non_max_suppression
def detect(img, ort_session):
img = img.astype(np.float32)
img = img / 255
img_tensor = img.transpose(2,0,1)[None]
ort_inputs = {ort_session.get_inputs()[0].name: img_tensor}
pred = torch.tensor(ort_session.run(None, ort_inputs)[0])
dets = non_max_suppression(pred, 0.25, 0.45)
return dets[0]
def demo():
ort_session = onnxruntime.InferenceSession("yolov5s.onnx", providers=['TensorrtExecutionProvider'])
img = cv2.imread("data/images/bus.jpg")
img = cv2.resize(img,(640,640))
dets = detect(img, ort_session)
for det in dets:
x1 = int(det[0])
y1 = int(det[1])
x2 = int(det[2])
y2 = int(det[3])
score = float(det[4])
cls = int(det[5])
info = "{}_{:.2f}".format(cls, score*100)
cv2.rectangle(img, (x1,y1),(x2,y2),(255,255,0))
cv2.putText(img, info, (x1,y1), 1, 1, (0,0,255))
cv2.imwrite("runs/detect/bus.jpg", img)
if __name__=="__main__":
demo()
Resumir
Este artículo explica en detalle cómo generar las etiquetas requeridas para los datos de entrenamiento a través de dos ejemplos de detección de círculos y detección de rectángulos, y brinda la implementación de código de todo el proceso de entrenamiento, prueba e implementación.