Artikelverzeichnis
TransFG: Eine Transformer-Architektur für feinkörnige Erkennung
Abstrakt
Die aktuelle Arbeit bewerkstelligt FGVC hauptsächlich, indem sie sich darauf konzentriert, wie man die diskriminierendsten Regionen lokalisiert und sich auf sie verlässt, um die Fähigkeit des Netzwerks zu verbessern, subtile Änderungen zu erfassen.
Die meisten dieser Arbeiten schlagen gebundene Boxen durch RPN-Module vor und verwenden das Backbone-Netzwerk wieder, um Merkmale der ausgewählten Boxen zu extrahieren.
In den letzten Jahren hat ViT große Erfolge bei traditionellen Klassifizierungsaufgaben erzielt, und sein Selbstaufmerksamkeitsmechanismus verbindet das Token jedes Patches mit dem Klassifizierungstoken. Die Stärke der Aufmerksamkeitsverbindungen kann intuitiv als Indikator für die Wichtigkeit der Repräsentation betrachtet werden.
In diesem Papier wird eine neue transformatorbasierte Struktur TransFG vorgeschlagen.
In diesem Artikel werden alle ursprünglichen Aufmerksamkeitsgewichte in einer Aufmerksamkeitskarte aggregiert, um das Netzwerk anzuweisen, diskriminierende Bildfelder effizient und genau auszuwählen und die Beziehung zwischen ihnen zu berechnen.
Zusätzlich verwenden wir einen kontrastiven Verlust, um den Abstand zwischen Merkmalsdarstellungen ähnlicher Unterklassen weiter zu vergrößern.
Einführung
Um das arbeitsintensive lokale Kennzeichnungsproblem zu vermeiden, konzentrieren wir uns derzeit auf schwach überwachte FGVC mit nur Bildkennzeichnungen.
Existierende Verfahren werden hauptsächlich in zwei Kategorien eingeteilt, nämlich Lokalisierungsverfahren und Merkmalscodierungsverfahren. Der Vorteil der Lokalisierungsmethode besteht darin, dass sie die feinen Unterschiede zwischen verschiedenen Unterklassen klar erfassen kann, was besser interpretierbar ist und zu besseren Ergebnissen führt.
Eine typische Strategie besteht darin, lokale Merkmale zur Klassifizierung zu verwenden und den Rangverlust zu verwenden, um die Konsistenz zwischen Bbox und Ausgabewahrscheinlichkeit aufrechtzuerhalten.
Solche Verfahren ignorieren jedoch offensichtlich die Beziehung zwischen den ausgewählten Regionen und ermutigen RPN, einige große Bboxen zu erzeugen, um mehr Teile zu enthalten, um korrekte Klassifizierungsergebnisse zu erzeugen. Sogar eine große Bbox kann Hintergrundstörungen verursachen.
Der große Erfolg des Vision Transformers zeigt, dass ein reiner Transformer mit einem intrinsischen Aufmerksamkeitsmechanismus, wenn er direkt auf eine Sequenz von Bildfeldern angewendet wird, wichtige Regionen erfassen kann, um die Klassifizierung zu erleichtern.
Dieses Papier schlägt TransFG vor, ein einfaches und effektives Framework, das auf ViT basiert, insbesondere:
- Durch die Nutzung des angeborenen Mehrkopf-Selbstaufmerksamkeitsmechanismus schlägt dieses Papier ein lokales Auswahlmodul vor , um diskriminierende Regionen zu berechnen und redundante Informationen zu entfernen.
- Dieses Papier verbindet das ausgewählte lokale Token mit dem globalen Token als Eingabesequenz der letzten Transformatorschicht von i;
- Das Einführen von doppeltem Verlust zum Schätzen von Mehrkopf-Aufmerksamkeitsmodulen führt zu anderen Ergebnissen.
Eine solche Strategie zwingt das Netzwerk dazu, sich auf verschiedene Regionen des Bildes zu konzentrieren. Um den Abstand zwischen Merkmalsdarstellungen von Proben unterschiedlicher Kategorien weiter zu vergrößern und den Abstand zwischen Merkmalsdarstellungen von Proben der gleichen Art zu verringern, führt dieses Dokument einen Kontrastverlust ein, um die Leistung weiter zu verbessern.
Methode
Vision Transformer als Merkmalsextraktor
Bildsequenzierung
Nach ViT wird das Eingabebild zuerst in eine Reihe von abgeflachten Patches xp x_p vorverarbeitetXp。
Diese ursprünglichen Segmentierungsverfahren beschneiden das Bild jedoch in einige nicht überlappende Flecken, die die lokalen Nachbarstrukturen ernsthaft beschädigen . Besonders der Unterscheidungsbereich wird getrennt (weil es sich um eine einfache Segmentierung handelt, vielleicht ist die Hälfte des Vogelkopfes in einem Stück und die andere Hälfte in einem anderen Stück).
Um dieses Problem zu lösen, schlägt dieser Artikel vor, überlappende Patches mit gleitenden Fenstern zu erzeugen .
Insbesondere setzen wir die Auflösung des Eingabebildes auf H ∗ WH*WH∗W ist die Größe des BildflecksPPP ist die Schrittgröße des GleitfenstersSSS , also können wir N Patches bekommen.
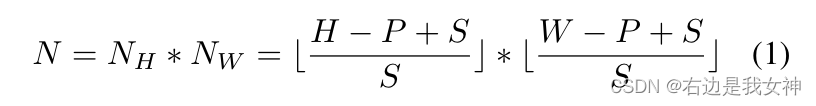
Somit haben zwei verbundene Patches einen überlappenden Bereich der Größe ( P − S ) ∗ P (PS)*P( S−S )∗P hilft dabei, bessere lokale Regionsinformationen zu erhalten.
Es liegt nahe, dass die Leistung umso besser ist, je kleiner die Schrittgröße ist, aber wenn S abnimmt, steigt auch der Rechenaufwand.
Patch-Einbettung
Dieses Papier verwendet trainierbare lineare Projektionen, um vektorisierte Patches in einen latenten D-dimensionalen Raum einzubetten.
Eine lernbare Positionseinbettung wird der Patch-Einbettung hinzugefügt, um Positionsinformationen beizubehalten, und ihre Funktionsweise ist wie folgt:
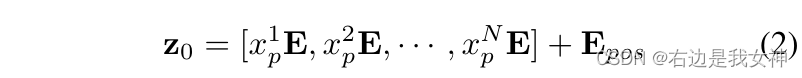
其中,E ∈ R ( P 2 ⋅ C ) ∗ DE\in R^{(P^2\cdot C)*D}E∈R( S2 ⋅C)∗D,E pos ∈ RN ∗ D E_{pos}\in R^{N*D}Ep o s∈RN ∗ D。
Der Transformer-Encoder enthält L Multi-Head Self-Attention (MSA) und MLP-Module.
Die Funktionsweise einer einzelnen Schicht ist wie folgt:
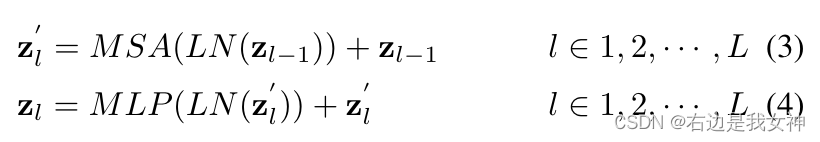
wobei LN ( ⋅ ) LN(\cdot)L N ( ⋅ ) ist die Schichtnormalisierung. ViT wandelt das erste Token der letzten Schichtin ZL 0 Z_L^0ZL0Als globales Merkmal und füttern Sie es in den Kopf eines Klassifikators, um das endgültige Klassifikationsergebnis zu erhalten, ohne die latenten Informationen in den verbleibenden Token zu berücksichtigen .
TransFG-Architektur
reines ViT kann direkt in FGVC verwendet werden, aber es erfasst die von FGVC benötigten lokalen Informationen nicht gut. Zu diesem Zweck schlägt dieses Papier ein partielles Auswahlmodul, PSM, vor und wendet kontrastives Lernen an, um die Repräsentationsdistanz zwischen ähnlichen Unterkategorien zu vergrößern.
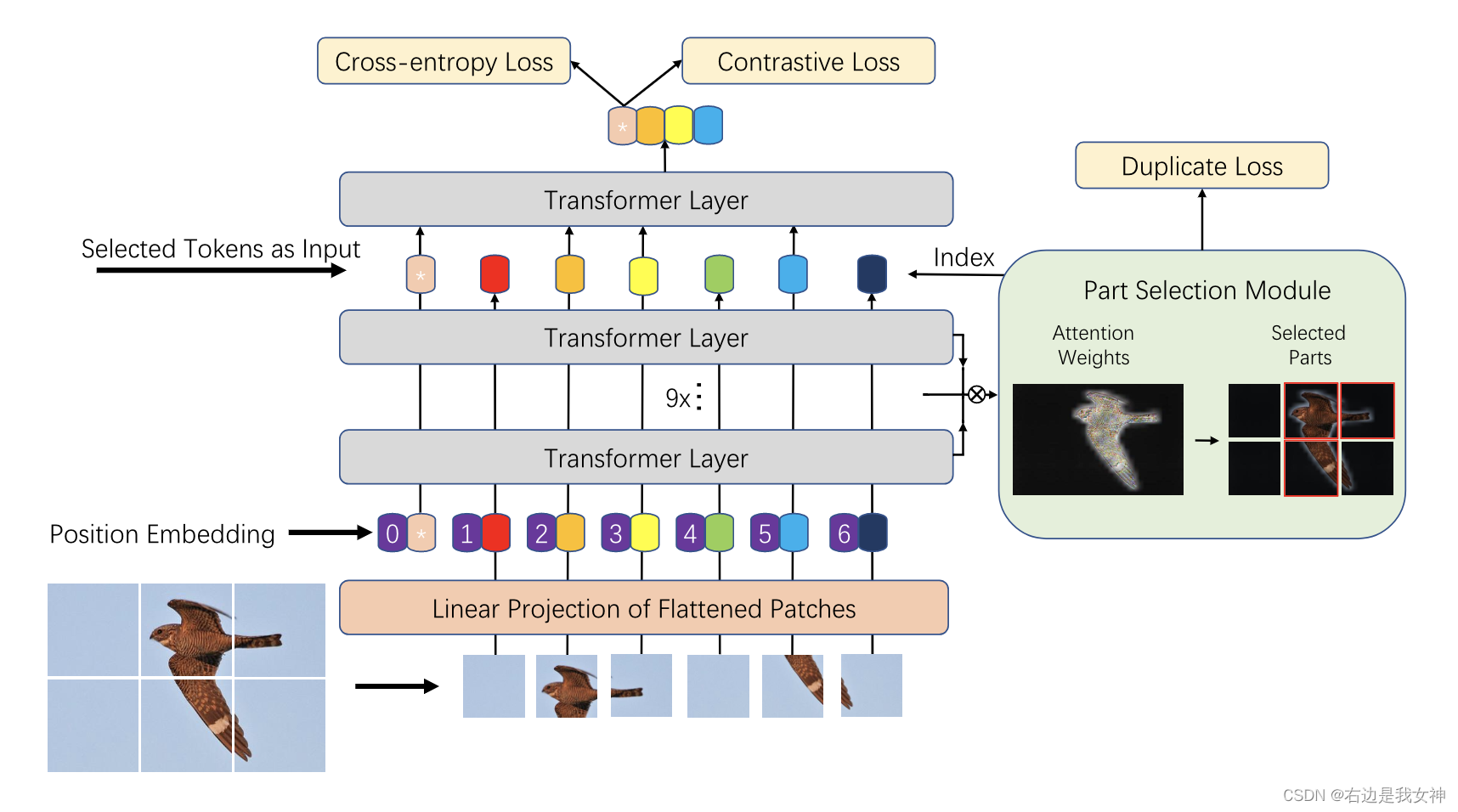
Teileauswahlmodul
Angenommen, das Modell hat K Selbstaufmerksamkeitsköpfe und die an die letzte Schicht gesendeten verborgenen Merkmale seien z L − 1 = [ z L − 1 0 , z L − 1 1 , . . . , z L − 1 N ] z_ { L-1}=[z_{L-1}^0,z_{L-1}^1,...,z_{L-1}^N]zL - 1=[ zL - 10,zL - 11,. . . ,zL - 1N]。
Unter ihnen können die Aufmerksamkeitsgewichte der ersten Schichten wie folgt geschrieben werden:
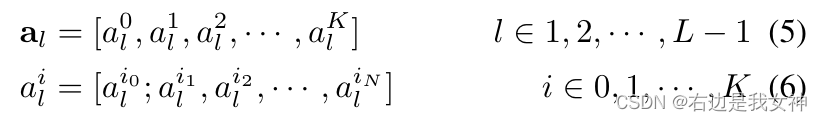
Es ist ersichtlich, dass die Aufmerksamkeit jedes Kopfes ein Vektor ist.
Frühere Arbeiten haben gezeigt, dass rohe Aufmerksamkeitsgewichte nicht unbedingt der relativen Bedeutung von Eingabetoken entsprechen, insbesondere für höhere Schichten des Modells, da eingebettete Token nicht unterscheidbar sind.
Daher erwägen wir, die Aufmerksamkeitsgewichte aller vorherigen Schichten zu aggregieren. Insbesondere wenden wir die Matrixmultiplikation rekursiv auf alle Schichten an:
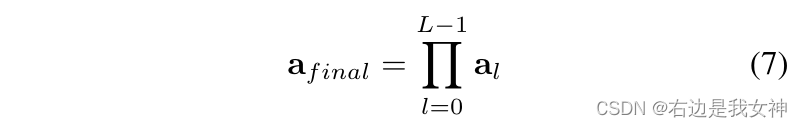
Es erfasst, wie Informationen von der Eingabeschicht zu höheren Einbettungsschichten weitergegeben werden.
Verglichen mit dem ursprünglichen Aufmerksamkeitsgewicht a L − 1 a_{L-1} einer einzelnen SchichtAL - 1, dient diese Matrix als bessere Wahl, um diskriminierende Regionen auszuwählen.
Wir wählen dann etwa afinal a_{final}Af i n a lDer Maximalwert von K verschiedenen Aufmerksamkeitsköpfen A 1 , A 2 , ..., AK A_1, A_2, ..., A_KA1,A2,. . . ,AKIndex von. Diese Positionen werden als Indizes in unser Modell verwendet, um z L − 1 z_{L-1}zL - 1Der entsprechende Index in .
Schließlich verketten wir diese ausgewählten Token und kennzeichnen sie als:
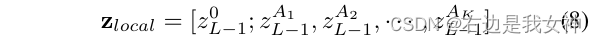
Wir behalten nicht nur globale Informationen, sondern zwingen auch die letzte Transformer-Schicht, auf kleine Unterschiede zu achten.
Um abzuschätzen, dass sich die Multi-Head-Aufmerksamkeit auf verschiedene diskriminierende Regionen konzentriert, haben wir einen doppelten Verlust hinzugefügt, um die Auswahl derselben Region einzuschränken :
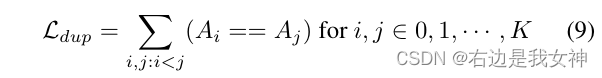
Lernen von kontrastiven Merkmalen
Wir verwenden immer noch das erste Token von PSM für die Klassifizierung. Ein einfacher Kreuzentropieverlust reicht nicht aus, um das Lernen dieses Merkmals vollständig zu überwachen, da der Unterschied zwischen Unterklassen relativ gering ist.
Daher wenden wir einen Kontrastverlust an, um die Ähnlichkeit zwischen Klassifikationstoken zu minimieren, die unterschiedlichen Labels entsprechen, und die Ähnlichkeit zwischen Klassifikationstokens zu maximieren, die demselben Label entsprechen.
Um zu verhindern, dass der Verlust leicht von einfachen negativen Proben dominiert wird, führen wir ein konstantes Intervall α \alpha einα , was bedeutet, dass nur das Ähnlichkeitsverhältnis von negativen Probenpaarenα \alphaNur wenn α groß ist, trägt es zum Verlust bei.
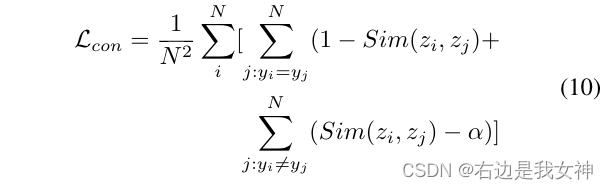
Dies bedeutet, dass die Merkmale, die zwei Proben mit unterschiedlichen Probenetiketten entsprechen, extrem unterschiedlich sein sollten und solche einfachen negativen Proben das Modell stark beeinflussen.
Die endgültige Verlustfunktion besteht aus drei Teilen:
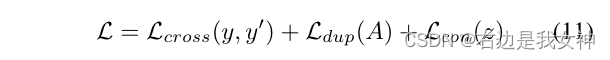
ViT-FOD: Ein auf Vision Transformer basierender feinkörniger Objektdiskriminator
Abstrakt
Gegenwärtig wurden einige ViT-basierte Verfahren vorgeschlagen, die deutlich besser sind als bestehende CNN-basierte Verfahren.
Die direkte Anwendung von ViT auf FGVC hat jedoch einige Einschränkungen:
- ViT muss das Bild in kleine Teile aufteilen und die Aufmerksamkeit jedes Paares berechnen, was zu einer großen Anzahl redundanter Berechnungen führen kann, und die Leistung ist nicht zufriedenstellend, wenn es um feinkörnige Bilder mit komplexen Hintergründen und kleinen Objekten geht;
- Standard-ViT verwendet nur die letzte Schicht von Klassentoken für die Klassifizierung, was nicht ausreicht, um umfassende feinkörnige Informationen zu extrahieren.
Um die beiden oben genannten Probleme anzugehen, schlägt dieses Papier ein neues ViT vor, das auf einem feinkörnigen Objektdiskriminator basiert, der kurz als ViT-FOD bezeichnet wird.
Insbesondere werden zusätzlich zum Hauptteil von ViT auch drei neue Komponenten eingeführt, nämlich Attention Patch Combination (APC), Critical Regions Filter (CRF) und Complementary Tokens Integration (CTI).
Unter anderem teilt APC Informationsblöcke aus zwei Bildern, um ein neues Bild zu erzeugen, wodurch redundante Berechnungen reduziert werden. CRF betont Token mit diskriminierenden Regionen, um neue Kategorie-Token für das Lernen subtiler Merkmale zu generieren. Um umfassende Informationen zu extrahieren, integriert CTI zusätzliche Informationen, die von Kategorie-Tokens in verschiedenen ViT-Schichten erfasst werden.
Einführung
CNN-basierten Methoden fehlen geeignete Mittel, um die Beziehung zwischen diesen Regionen herzustellen und sie in ein einheitliches Konzept zu integrieren , und der Selbstaufmerksamkeitsmechanismus ist eine Möglichkeit, dieses Problem zu lösen.
Aktuell gibt es mehrere Arbeiten, die geforscht und erste Erfolge erzielt haben:
- Ju He, Jie-Neng Chen, Shuai Liu, Adam Kotylewski, Cheng Yang, Yutong Bai, Changhu Wang und Alan Yuille, 2022. TransFG: A Transformer Architecture for Fine-grained Recognition, In Proceedings of the AAAI Conference on Artificial Intelligence
- Yunqing Hu, Xuan Jin, Yin Zhang, Haiwen Hong, Jingfeng Zhang, Yuan He und Hui Xue. 2021. RAMS-Trans: Recurrent Attention Multi-scale Transformer for Fine-grained Image Recognition. In Proceedings of the ACM InternationalConference on Multimedia. 4239 – 4248.
- Xinda Liu, Lili Wang und Xiaoguang Han. 2021. Transformer with Peak Suppression and Knowledge Guidance for Fine-grained Image Recognition.arXivpreprint arXiv:2107.06538(2021).
- Jun Wang, Xiaohan Yu und Yongsheng Gao. 2021. Feature Fusion Vision Transformer for Fine-grained Visual Categorization.arXiv preprint arXiv:2107.02341(2021).
Es sind noch einige Punkte zu berücksichtigen:
1) Standard-ViT muss das Bild als Eingabe in kleine Patches aufteilen, und dann erhält ein Mehrkopf-Selbstaufmerksamkeitsmodul (MSA) in jeder Schicht die Beziehung zwischen zwei beliebigen kleinen Patches. Bei feinen Bildern enthalten viele Samples jedoch komplexe Hintergründe und einige Objekte können relativ klein sein, sodass die Verwendung von ViT zur Verarbeitung von Dingen unweigerlich zu einer Menge nutzloser Berechnungen und sogar zu Rauschen führt .

Die große Anzahl von Grasflecken hilft nicht bei der Klassifizierung durch ViT.
2) ViT verwendet vordefinierte Klassen-Tokens für die Vorhersage. Im Standard-ViT-Modell werden Klassen-Token in MSA wie jeder Bild-Patch verarbeitet, und nur die letzte Schicht wird zur Klassifizierung herausgenommen. Von einem bestimmten Standpunkt aus wird das Token-Like auf der Grundlage aller Bildblöcke in einer Art und Weise der Selbstaufmerksamkeit erhalten, was einer weiteren Fokussierung auf einige Schlüssel- und Subtilbereiche möglicherweise nicht förderlich ist. Aus einer anderen Perspektive können Klassenbezeichnungen gemäß den Experimenten in diesem Artikel Merkmale extrahieren, die auf unterschiedliche Informationen abzielen, und sie sind komplementär. Daher reicht es nicht aus, nur die endgültigen Klassenbezeichnungen zu verwenden, um die Merkmalsextraktionsfähigkeit von ViT voll auszuschöpfen.
Dieses Dokument stellt drei verbesserte Module vor:
- APC zerlegt zwei Bilder in kleine Stücke und fügt die informativen zusammen, um ein neues Bild zu erzeugen. Auf diese Weise reduziert es den Einfluss des Hintergrunds im Eingangsbild, indem es den entsprechenden Bereich teilweise durch den informativen Teil eines anderen Bildes ersetzt;
- Mit einem geringeren Rechenaufwand hebt CRF das Token hervor, das dem differenzierten Bereich entspricht, um ein neues Klassentoken zu erzeugen;
- CTI klassifiziert Token-ähnliche Objekte basierend auf mehreren Schichten, um komplementäre Informationen zwischen verschiedenen Schichten zu erfassen.
Methode
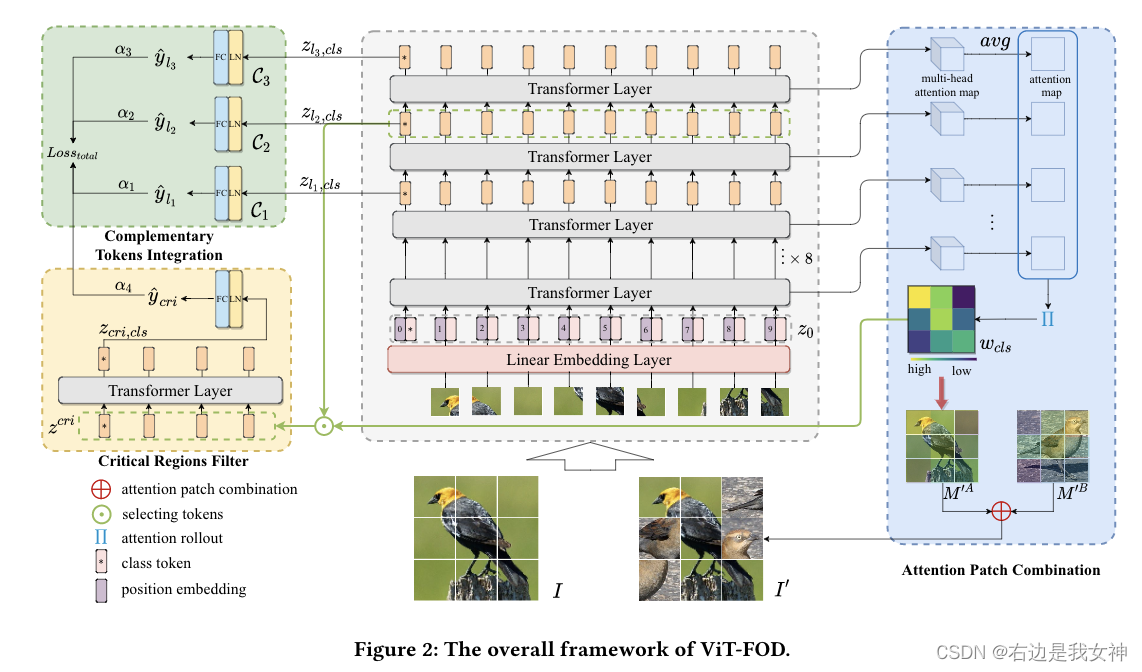
Komplementäre Token-Integration
Bild III ist unterteilt inH × WH\times WH×W个Patchesxi ∈ RP × P × C , i ∈ { 1 , . . . , N } x^i\in R^{P\times P\times C},i\in\{1,...,N\}Xich∈RP × P × C ,ich∈{ 1 ,. . . ,N } , P ist die Größe jedes Patches, C ist die Anzahl der Kanäle des Bildes,N = H × WN=H\times WN=H×W ist die Anzahl der Patches.
Eine lineare Einbettungsschicht wird verwendet, um jeden Patch einem Token zuzuordnen. Zusätzlich ein lernbares Klassentoken xcls x_{cls}Xc l swurde zur Klassifikation eingeführt.
Dann werden Positionscodierungen eingeführt, um räumliche Informationen beizubehalten. Die Dateneingabe in die erste Transformer-Schicht sieht also so aus:
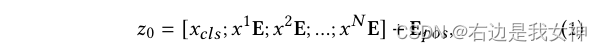
Danach folgt der normale ViT-Betrieb:
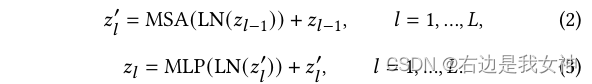
Das Klassentoken der letzten Schicht wird zur Klassifizierung an den Klassifikator gesendet, um Labels zu erzeugen: y ^ = CL ( z L , cls ) \hat{y}=C_L(z_{L,cls})j^=CL( zL , c l s)。
Um die Informationen zu ergänzen, sendet CTI das Klassen-Token jeder Schicht an den Klassifizierer, um die Kategorie zu erhalten:
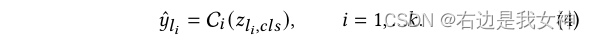
Die endgültige Entscheidung wird durch Gewichtung aller Vorhersagen erhalten, und der entsprechende Verlust beträgt:
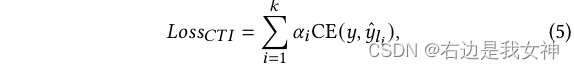
Achtung Patch-Kombination
Stellen Sie zuerst den grundlegenden Funktionsmechanismus der Selbstaufmerksamkeit vor:

Wir erinnern uns an die Aufmerksamkeitskarte als A l ∈ R ( N + 1 ) × ( N + 1 ) A_l\in R^{(N+1)\times(N+1)}AIch∈R( N + 1 ) × ( N + 1 ) , für Mehrkopf-Aufmerksamkeit ist seine GrößeRH-Kopf ( N + 1 ) × ( N + 1 ) R ^ {H_ {Kopf} (N + 1) \times (N +). 1)}RHer e a d( N + 1 ) × ( N + 1 )。
Wir fügen dieser Aufmerksamkeit eine Erkennungsmatrix E hinzu und mitteln sie, um die Aufmerksamkeitsgewichte für jede Schicht zu erhalten:
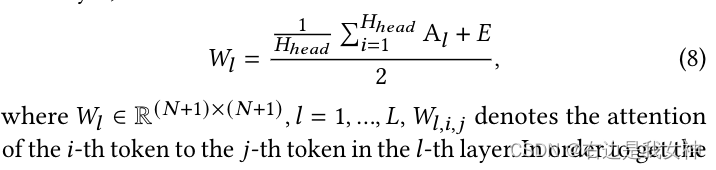
Um die endgültige Aufmerksamkeitskarte zu erhalten, verwendet dieses Papier den Aufmerksamkeits-Rollout-Algorithmus, der iterativ eine Matrixmultiplikation auf die Aufmerksamkeitsgewichte aller Schichten anwendet:
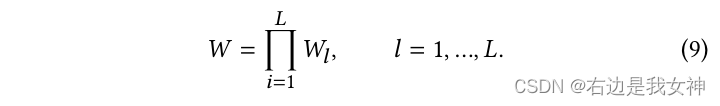
Das Ziel von APC ist es, wichtige Patches von zwei Bildern gemäß der Gewichtskarte zusammenzuführen, um redundante Berechnungen zu eliminieren. Darüber hinaus kann APC auch als Datenaugmentationsmethode verwendet werden, um die Verallgemeinerungsfähigkeit des Modells zu verbessern.
Insbesondere erhalten wir wcls ∈ RN w_{cls}\in R^Nwc l s∈RNach N (dem Aufmerksamkeitsgewicht des Klassentokens relativ zu anderen Token, erhalten von W) formen wir es in ein zweidimensionales um und fassen es dann in pxp zusammen, um wcls ′ ∈ R p × p w_{cls} '\ in R^{p\times p}wc l s'∈Rp × p :
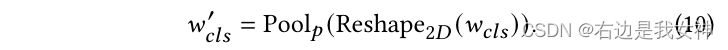
Gemäß der Gewichtskarte können wir die entsprechenden Sequenznummern idxcls idx_{cls} in absteigender Reihenfolge erhaltenich d xc l s。
Für zwei Graphen IA I_AICHAJapanisch IB I_BICHBBeispielsweise die generierte Maske MAM^AMA undMBM^BMB wie folgt:
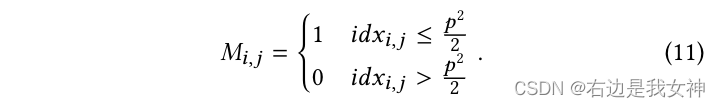
Dann erhalten wir ein neues Bild mit den folgenden Operationen:
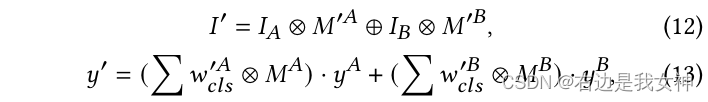
Kreismultiplikation bedeutet Element-für-Element-Multiplikation und Kreisaddition bedeutet, den vorderen 0-Teil mit dem hinteren 1-Teil zu füllen.
Lassen Sie mich übersetzen:
- Erhalten Sie einen Klassen-Token-Teil der Aufmerksamkeitsmatrix vom Originalbild bis zum Finale, der den Grad der Anziehungskraft jedes Tokens auf den Klassen-Token widerspiegelt. Je größer die Anziehungskraft, desto wichtiger ist dieser Teil;
- Eine zweidimensionale + Bündelung dieses lokalen Aufmerksamkeitsvektors ist gleichbedeutend damit, zunächst das Originalbild zu teilen und die Bildblöcke entsprechend ihrer Wichtigkeit zu kennzeichnen: Je wichtiger die Zahl, desto höher die Zahl, von der die Hälfte mit 1 gekennzeichnet ist, und die die andere Hälfte ist als 0 markiert;
- Schließlich werden der 1-Bildblock des A-Bildes und der 1-Bildblock des B-Bildes zusammengefügt.
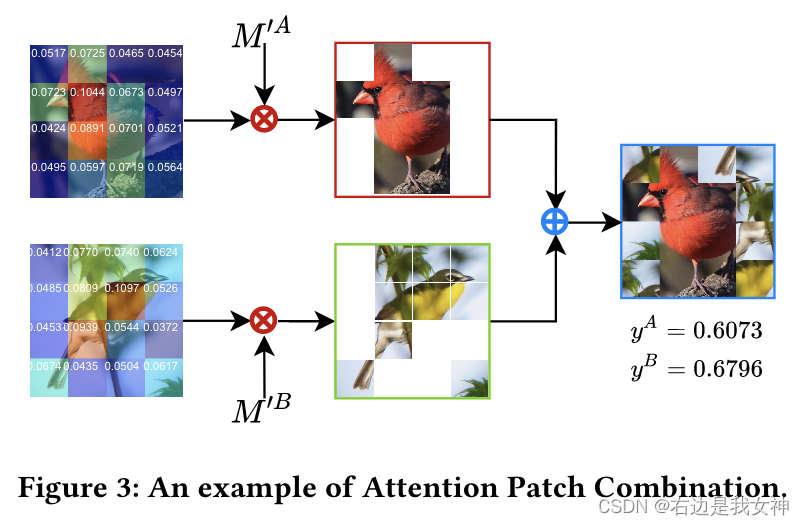
In Bezug auf die Bezeichnung des synthetischen Graphen gibt dieses Papier die entsprechende Berechnungsmethode an.
Dies läuft auf eine komplexe Datenaugmentation hinaus.
Ich denke, der Grund dafür ist, dass das ursprüngliche Modell die Aufmerksamkeitsbeziehung zwischen Hintergrund und Hintergrund lernen wird, was nutzlos ist, also hoffe ich, dass das Modell mehr über die Beziehung zwischen Schlüsselteilen lernen kann.
Filter für kritische Regionen
Es ist eine interessante Idee, diskriminierende Regionen auszuschneiden und dann das Modell zu trainieren, das in RAMS-Trans übernommen wird, aber diese Methode wird den Rechenaufwand erheblich erhöhen. Außerdem gibt es eine große Einschränkung beim Zuschneiden von Rechtecken.
Um die oben genannten Probleme zu lösen, schlägt dieses Dokument ein einfaches und effektives Filtermodul für Schlüsselregionen vor, um Tokens von diskriminierenden Regionen auszuwählen und ein zusätzliches Klassentoken zu erzeugen, um die Informationen der ausgewählten Tokens zu sammeln.
Zunächst wird eine Schwelle η \eta definiertη , um die Anzahl der ausgewählten Token zu steuern.
Angenommen, das Token basiert auf wcls w_{cls}wc l sSortieren Sie die Größe in absteigender Reihenfolge, notieren Sie η N \eta Nη Das Gewicht von N Token ist wcls ˉ \bar{w_{cls}}wc l sˉ, also können wir die Token-Methode wie folgt auswählen:
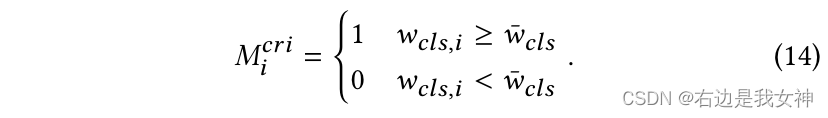
Schließlich werden das ausgewählte Token und das Klassentoken als Eingabe für die Transformer-Schicht im CRF verkettet:

Feature Fusion Vision Transformer für feinkörnige visuelle Kategorisierung
Abstrakt
ViT erreicht eine State-of-the-Art-Leistung bei allgemeinen Bilderkennungsaufgaben. Der Selbstaufmerksamkeitsmechanismus aggregiert und gewichtet Informationen von allen Token, um Token zu klassifizieren. Token mit tiefer Klassifizierung achten jedoch stärker auf globale Informationen und es fehlen lokale und untergeordnete Merkmale, die für FGVC wichtig sind.
In diesem Artikel schlagen wir ein neues rein transformationsbasiertes Framework für die Fusion visueller Transformationen vor, bei dem wir wichtige Token aus jeder Transformationsschicht bündeln, um lokale Informationen auf niedriger und mittlerer Ebene zu kompensieren.
In diesem Artikel entwerfen wir ein neues Token-Auswahlmodell namens Mutual Attention Weight Selection (MAWS), um das Netzwerk effektiv bei der Auswahl diskriminierender Token anzuleiten, ohne zusätzliche Parameter einzuführen.
Einführung
Gängige Methoden werden in lokalisierungsbasierte und aufmerksamkeitsbasierte Methoden unterteilt.
lokalisierungsbasiert: In den Anfängen wurde dies durch direktes Annotieren des diskriminierenden Teils des Bildes realisiert, später wurde RPN aufgrund der hohen Beschriftungskosten verwendet, um potenzielle und diskriminierende Bboxen zu erhalten;
Die derzeitige Methode ignoriert jedoch die Beziehung zwischen Regionen; und diese Art von Methode veranlasst RPN oft dazu, eine große Bbox vorzuschlagen, was ungenau und anfällig für Verwirrung ist; außerdem können einige Regionen nicht einfach mit Rechtecken markiert werden.
Aufmerksamkeitsbasiert: Kontaktierte die Abhängigkeit von manueller Kennzeichnung zur Unterscheidung von Regionen und erzielte gute Ergebnisse.
Das in diesem Dokument vorgeschlagene FFVT aggregiert lokale Informationen von Low-Level-, Mid-Level- und High-Level-Token, um die Klassifizierung zu erleichtern. Dieses Papier schlägt ein neues und wichtiges Token-Auswahlverfahren zum Auswählen repräsentativer Token auf jeder Schicht vor. Diese Token werden der letzten Transformer-Ebene als Eingabe hinzugefügt.
Methoden
ViT zur Bilderkennung
Ein gegebenes Bild der Größe HxB verarbeitet vit zunächst als N = ⌊ HP ⌋ × ⌊ WP ⌋ N=\lfloor\frac{H}{P}\rfloor\times\lfloor\frac{W}{P}\ rfloorN=⌊PH⌋×⌊PW⌋ patchxp x_pXp。
Diese Patches werden dann linear abgebildet und positionscodiert. Fügen Sie dann ein zusätzliches Klassentoken hinzu, und die Eingabe ist abgeschlossen:
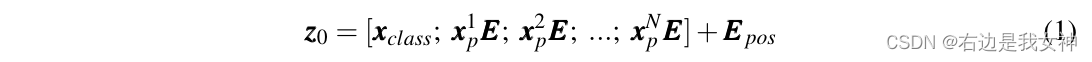
Danach tritt es in die gestapelte MSA-Schicht und die MLP-Schicht ein:
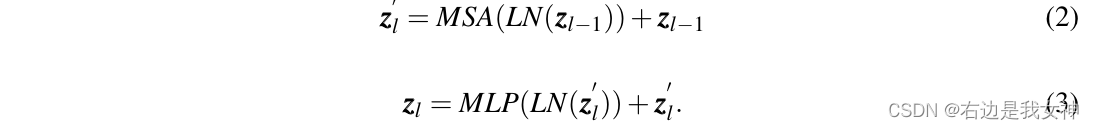
FFVT-Architektur
TransFG impliziert, dass dieses ViT nicht genügend Informationen erfasst. Um dieses Problem zu lösen, schlägt dieses Papier vor, diese Low-Level-Features und Mid-Level-Features zu verschmelzen, um diese lokalen Informationen anzureichern.
Dieses Papier schlägt eine neue Token-Auswahlmethode namens Mutual Attention Weight Selection (MAWS) vor, um das Token-Pooling zu bestimmen.
Der Gesamtrahmen sieht wie folgt aus:

Feature-Fusion-Modul
Bei wichtigen Token ersetzen wir die Eingabe der letzten Schicht durch diese Token (außer dem Klassentoken). Auf diese Weise können das Klassentoken und die letzte Schicht vollständig mit Features auf niedriger, mittlerer und hoher Ebene interagieren, wodurch lokale Informationen und Fähigkeiten zur Darstellung von Features angereichert werden.
Wir markieren die in Schicht l ausgewählten Token als:
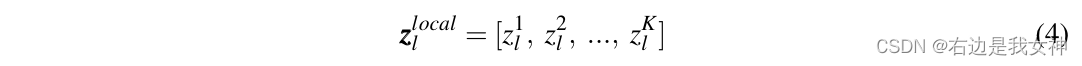
Dann ist die Eingabe für die letzte Ebene:
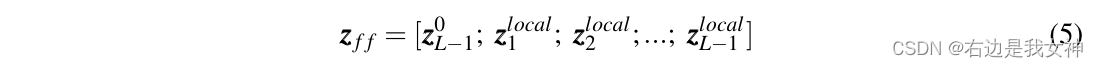
Schließlich ist das Klassentoken der letzten Schicht bereit, an den Klassifizierungskopf verteilt zu werden, um eine Klassifizierung durchzuführen. Somit stellt sich die Frage, wie man wichtige und diskriminierende Token auswählt.
Gewichtungsauswahlmodul für gegenseitige Aufmerksamkeit
Dieses Dokument verwendet direkt die von MSA generierten Aufmerksamkeitswerte, um die Token-Auswahlstrategie zu implementieren. Genauer gesagt, die Aufmerksamkeitsmatrix A ∈ R ( N + 1 ) × ( N + 1 ) A\in R^{(N+1)\times(N+1)} eines AufmerksamkeitskopfesA∈R( N + 1 ) × ( N + 1 ) wird wie folgt ausgedrückt:
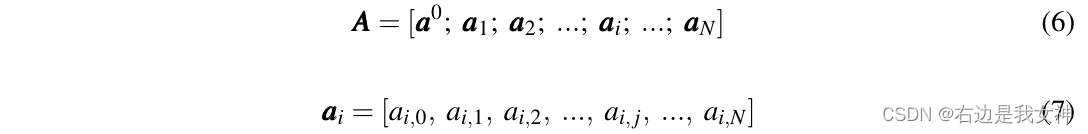
ai , j a_{i,j}Aich , jGibt das Skalarprodukt zwischen der Abfrage von Token I und dem Schlüssel von Token j an.
Eine der einfachsten Strategien besteht darin, ein Token mit einer höheren Aufmerksamkeitspunktzahl als das Klassifizierungstoken auszuwählen, da das Klassifizierungstoken umfangreiche Klassifizierungsinformationen enthält.
Gehen Sie auf diese Weise einfach zu a 0 a_0 überA0Sortieren und wählen Sie den Index aus, der K größeren Werten entspricht.
Dieses Papier nennt diese Methode Single Attention Weight Selection (SAWS).
Diese Methode führt jedoch zu etwas Rauschen, da die ausgewählten Token mehr Informationen aus verrauschten Patches sammeln können.
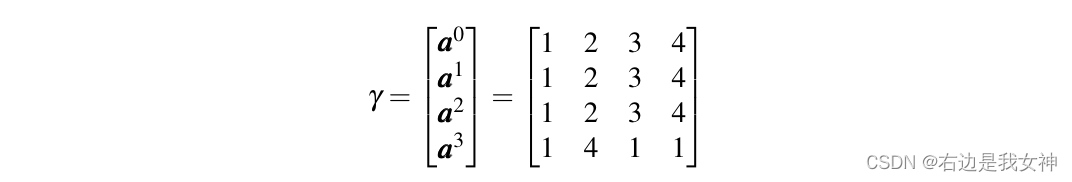
In der obigen Abbildung wählt das Klassifizierungstoken das dritte Token aus, aber das dritte Token enthält zu viele Informationen über das erste Token. Wenn das erste Token ein verrauschtes Token ist, enthält Token3 viel Rauschen.
Um dieses Problem anzugehen, schlägt dieses Papier ein Modul zur Auswahl der gegenseitigen Aufmerksamkeitsgewichtung vor, das erfordert, dass die ausgewählten Token dem kategorialen Token sowohl im Kontext des kategorialen Tokens als auch im Token selbst ähnlich sind.
Stellen Sie die erste Spalte der Aufmerksamkeitskarte als b 0 b_0 darB0, bezeichnen die Aufmerksamkeitswerte des Klassifizierungstokens und anderer Tokens im Kontext anderer Tokens.
Dann mit einer 0 a_0A0Zum Vergleich die interaktiven Aufmerksamkeitsgewichte mai ma_im einichAusgedrückt als:
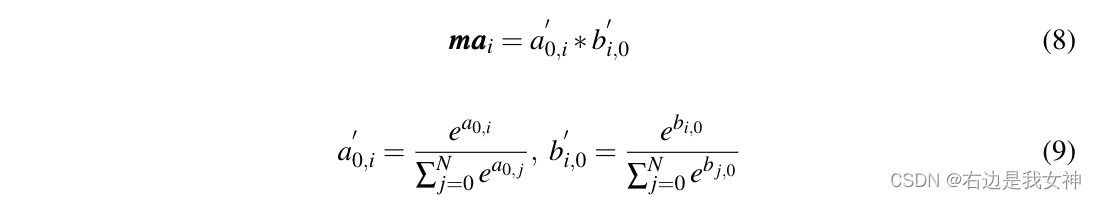
Für die Mehrkopf-Selbstaufmerksamkeit mitteln wir die Aufmerksamkeitswerte aller Köpfe.
Dieser Indikator bedeutet, dass die Aufmerksamkeit des Klassifizierungstokens für Token I und die Aufmerksamkeit von Token I für das Klassifizierungstoken beide hoch sind.