un índice
Explicación del sitio web oficial de Index
MySQL: Index es una estructura de datos ordenados que ayuda a MySQL a obtener datos de manera eficiente
Estructura de datos del índice:
- árbol binario
- árbol negro rojo
- Tabla de picadillo
- Árbol B
Caso: Hay una tabla con dos columnas y siete filas.Si
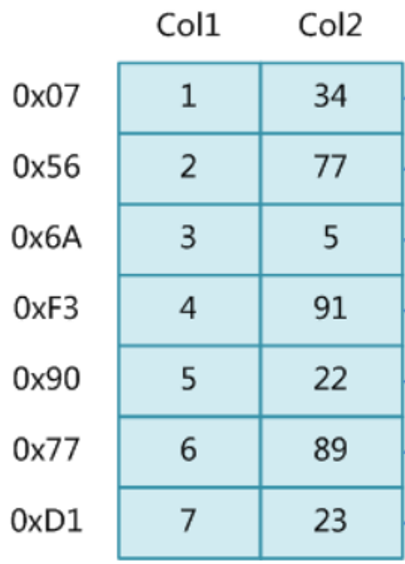
nuestra declaración de consulta sql es:
select * from t where t.col2=89;
En circunstancias normales, el valor de col2 debe extraerse línea por línea y luego compararse con 89 hasta encontrarlo;
Para los datos de una tabla MySQL, varias filas de datos no se almacenan necesariamente una al lado de la otra en el disco (porque si se guarda una fila de datos, la segunda fila de datos se guarda unos días después, puede haber otros datos en el período medio Almacenado en el disco), se almacena aleatoriamente; ejecute una declaración SQL de consulta (si hay muchos datos en la tabla), cada vez que se extrae un dato del disco, debe hacer un I /O leer la interacción con el disco y comparar los datos después de obtener los datos Para ver si son los datos que necesitamos, el rendimiento es muy bajo; nuestro propósito es reducir el número de interacciones con el disco cuando buscamos los datos que necesitamos. necesidad (reducir el número de búsquedas), siempre que este número se controle dentro de un cierto rango, la eficiencia mejorará mucho, en este punto, nació el índice;
De la siguiente manera, index col2, como se mencionó anteriormente, el índice es una estructura de datos, como un árbol binario
Árbol binario
Luego colocamos los datos de la columna col2 en el árbol binario (el nodo secundario izquierdo es más pequeño que el nodo principal y el nodo secundario derecho es mayor que el nodo principal), de la siguiente manera: si busca 89, puede

encontrar buscando solo dos veces, la primera vez que obtiene 34. Se encuentra que los datos que estamos buscando no son los datos que estamos buscando, y los datos que estamos buscando son mayores que 34. Debe buscarse en el el nodo secundario derecho de 34 y 89 se puede encontrar por segunda vez;
En el árbol anterior, cada nodo almacena clave/valor, donde la clave almacena el valor correspondiente al campo col2 (34, 77...89, 23), y el valor almacena la dirección del archivo de disco de la fila donde se encuentra el índice. situado;
De hecho, la capa inferior del índice MySQL no es un árbol binario, las razones son las siguientes
Si nuestra consulta col1 es así:
select * from t where t.col1=6;
Si es un árbol binario, entonces el árbol binario correspondiente a col1 es así:
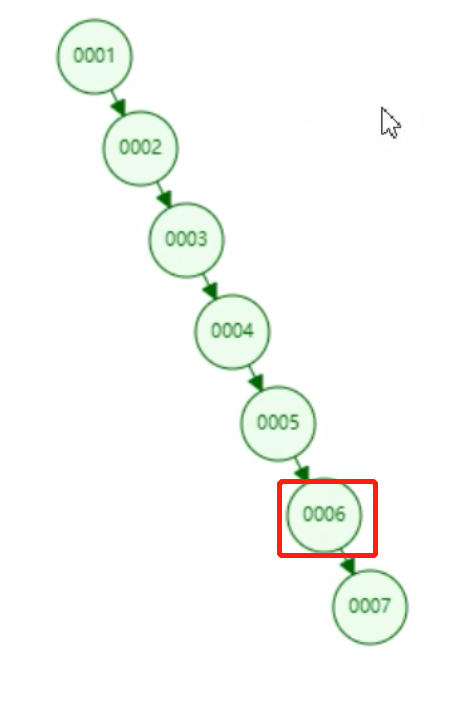
En este momento, el árbol binario es equivalente a una lista enlazada, y el número de veces para buscar col1=6 sigue siendo 6 veces, lo que no mejora la eficiencia de la consulta; es decir, si el índice usa un árbol binario,
el los datos en esta columna son datos incrementales, y el árbol binario no se elevará.Funciona, por lo que la capa inferior del índice no está hecha con un árbol binario;
Árbol rojo-negro El
árbol rojo-negro también se denomina árbol binario equilibrado, que tiene la función de equilibrar automáticamente el árbol.El árbol rojo-negro correspondiente a col1 es el siguiente: En este
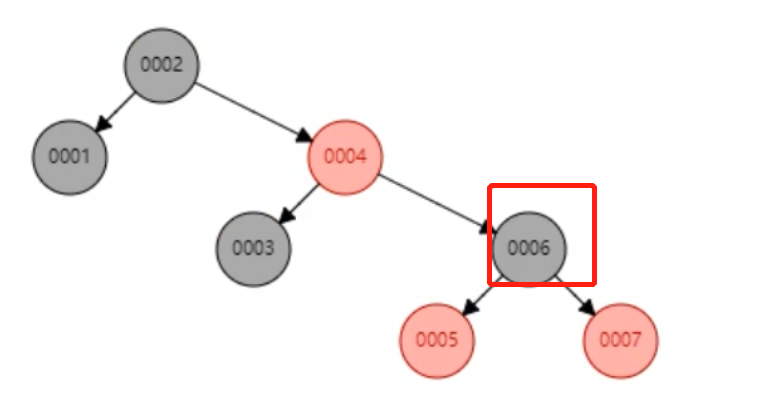
momento, el número de veces para buscar col1= 6 es 3 veces;
La capa inferior del índice MySQL no es un árbol rojo-negro. Las razones son las siguientes:
La altura del árbol es limitada: cuando la cantidad de datos en la tabla es demasiado grande, como 500w, la altura del árbol es muy alto Por ejemplo, la altura del árbol alcanza 20, y debe verificar Los datos se encuentran en el nodo de la hoja inferior, se requieren al menos 20 búsquedas y se requieren 20 E/S de disco, entonces, ¿qué debemos hacer? es reducir la altura del árbol, como altura <= 4, o altura <= 3, etc., somos Aceptable - árbol B;
árbol B
- Los nodos hoja tienen la misma profundidad y el puntero del nodo hoja es nulo
- Todos los elementos del índice no se repiten
- El índice de datos en el nodo se organiza en orden ascendente de izquierda a derecha
El árbol rojo-negro anterior tiene solo un nodo raíz, y el árbol B tiene múltiples nodos raíz (expansión horizontal).La

capa inferior del índice MySQL no usa un árbol B puro, sino que optimiza el árbol B, que es, el árbol B+
B+Árbol (variante BÁrbol)
- Los nodos que no son hoja no almacenan datos, solo almacenan índices (redundancia), y se pueden colocar más índices (es decir, los nodos hoja contienen todos los elementos de índice en la tabla)
- Los nodos que no son hojas se denominan índices redundantes.Después de obtener algunos datos de los nodos hoja, los nodos que no son hojas construyen árboles B+ (es decir, los nodos que no son hojas son para construir árboles B+)
- Los nodos hoja contienen todos los campos de índice
- Los nodos hoja están conectados por punteros (los árboles B no tienen punteros), que almacenan la ubicación del nodo actual en el disco y mejoran el rendimiento del acceso a intervalos
Cada línea de abajo llamamos una página

La capa inferior del índice MySQL usa un árbol B+;
si buscamos col1=30, primero cargaremos todas las páginas del nodo raíz (15, 56, 77) en la memoria (RAM) (relativamente lento) , y luego cargue Compare 30 con estos datos en la memoria (relativamente requiere mucho tiempo), si usa la búsqueda binaria para ubicar rápidamente 30, está entre 15 y 56; luego los datos en la página 15 (15, 20, 49) es también Cargarlo en la memoria y compararlo con 30...;
Entonces, ¿por qué no eliminar otros nodos, dejar solo los nodos de hoja, poner todos los datos en los nodos de hoja y luego cargar los nodos de hoja en la memoria a la vez, y buscar directamente 30 y los datos en la memoria a la mitad? Si la cantidad de datos es tan grande, es fácil reventar la memoria;
El tamaño de cada página es de aproximadamente 16K
#查看mysql页大小:16384字节——16KB
SHOW GLOBAL STATUS LIKE 'Innodb_page_size'
¿Cuántos datos se pueden almacenar después de que el árbol B+ esté lleno?
¿Por qué 16 KB?
Si se usa el tipo bigInt (8 bits), cada índice ocupa 8 bits, y la dirección entre 15 y 16 en la figura anterior es la dirección de la siguiente fila (página) (la dirección de 15, 20, 49), y esta dirección ocupa 6 bits; después de que los 16 KB de datos de la página estén llenos, el número de elementos de índice que se pueden colocar: 16 kb/(8+6)b=1170; el nodo de hoja es especial, tome el nodo de hoja 15 como ejemplo, el índice 15 puede almacenarse en los datos La dirección del espacio en disco donde se encuentra también puede almacenar todas las demás columnas de la fila. Los datos pueden ser relativamente grandes. Si es una fila de datos, será de 1 kb si está lleno (una fila de registros generalmente no excederá 1kb), entonces este nodo hoja La cantidad aproximada de datos que se pueden almacenar es: 1kb/(8+6)b=16 (ya que generalmente es menos de 1kb, el valor de 16 obtenido es un valor hipotético, no calculado realmente aquí);
En resumen, cuando el árbol B+ está lleno, la cantidad de datos de índice que se pueden almacenar es:
1170X1170X16 = 21,902,400, es decir, más de 20 millones; mientras que la altura del árbol es solo 3, es decir, los datos pueden ser encontrado después de 3 IO;
El nodo raíz de MySQL está en realidad directamente en la memoria (el nodo raíz reside en la memoria, es decir, 15, 56 y 77 en la figura anterior ya están en la memoria desde el principio), es decir, en realidad no son 3 IO, sino 2 veces, después de la versión superior de MySQL, todos los nodos que no son hojas se colocan en la memoria, que es más rápido;
¿Por qué la capa inferior del índice MySQL usa el árbol B+ en lugar del árbol B?
Como se mencionó anteriormente, si el árbol B+ almacena 20 millones de números, la altura del árbol es solo 3; ¿y si es un árbol B?
El árbol B es el siguiente:

El tamaño máximo de cada pieza de datos es de 1kb, y cada página es de 16kb, por lo que cada página (fila) de datos solo puede contener 16 elementos de índice, es decir, la n-ésima potencia de 16 debe llegar a 20 millones, y esta n es la altura del árbol, obviamente, n Esta altura es mucho mayor que la altura 3 del árbol B+;
Las tablas y los índices se almacenan en el disco. Si no se cambia la configuración, la ubicación predeterminada es:
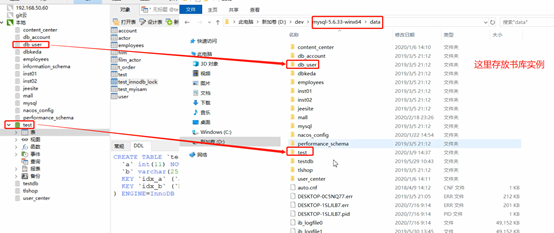
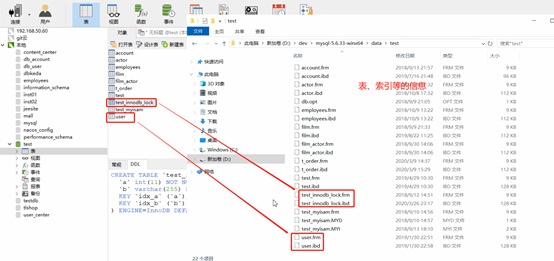
Dos motores de almacenamiento de tablas MySQL
2.1 Introducción al motor de almacenamiento
¿El motor de almacenamiento utiliza la base de datos o la tabla de la base de datos? es una tabla de base de datos.
Cuando usamos Navcat de MySQL para construir una tabla, podemos elegir un motor de almacenamiento, de la siguiente manera: el
motor de almacenamiento generalmente seleccionado es InnorDB, y la versión anterior usa el motor de almacenamiento MyISAM
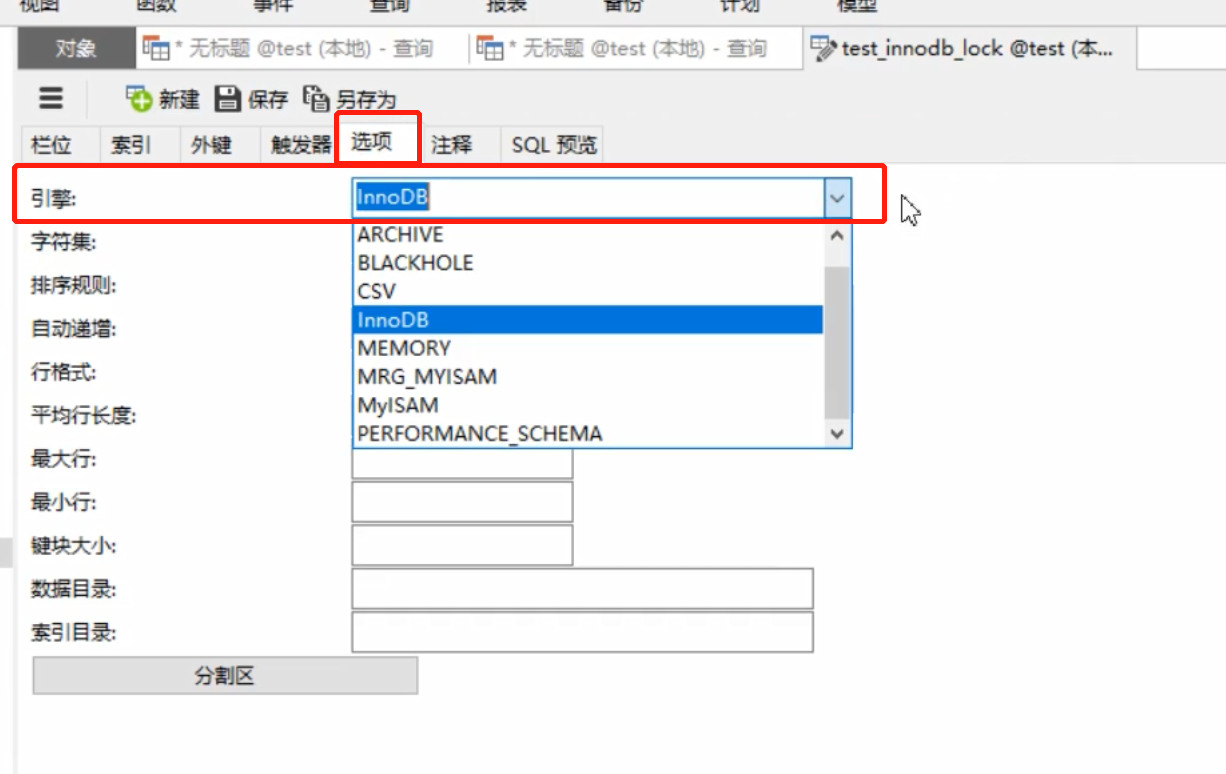
2.2 Motor de almacenamiento MyISAM (ya no se usa)
Cree una nueva tabla y use MyISAM como motor de almacenamiento, de la siguiente manera
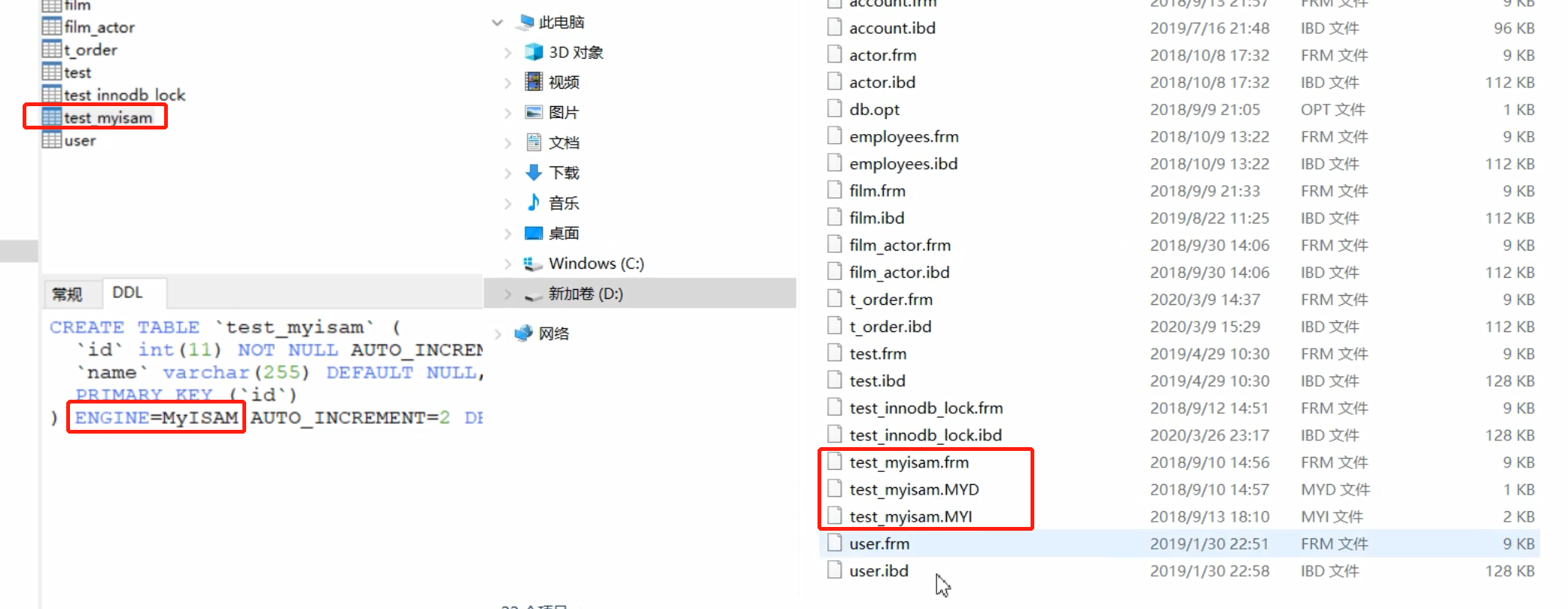
- .frm: almacena la información de la estructura de la tabla de datos (frame frame para abreviar)
- .MYD: almacenar datos (MY es la primera letra de MyISAM, D es DATA)
- .MYI: almacena el índice (MY es la primera letra de MyISAM, I es el índice índice)
Los archivos de índice y los archivos de datos de MyISAM están separados (no agrupados)
Si las condiciones de verificación son las siguientes
select * from t where t.col1=30;
MySQL primero ubicará el elemento de índice en el árbol de índice del archivo MYI 0xF3y luego 0xF3encontrará una fila de datos en el disco en el archivo MYD de acuerdo con la dirección del archivo del disco;
2.3 Motor de almacenamiento InnoDB
Cree una nueva tabla y use InnorDB como motor de almacenamiento, de la siguiente manera
- .frm: almacena la información de la estructura de la tabla de datos (frame frame para abreviar)
- .ibd: almacena datos e index()
Implementación del índice InnoDB (agregación)
- El archivo de datos de la tabla en sí es un archivo de estructura de índice organizado por B+Tree
- Índice agrupado: los nodos hoja contienen registros de datos completos
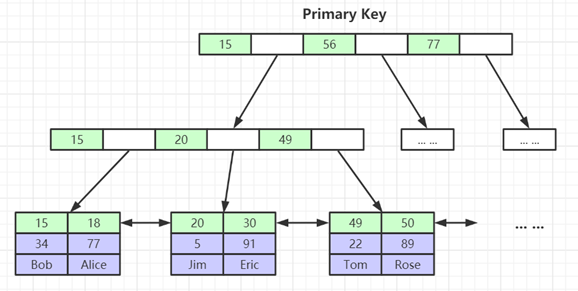
Como se puede ver en la figura anterior, el nodo hoja almacena los datos de otras columnas de la fila actual, por ejemplo, el nodo 15 almacena los datos de todas las demás columnas de la fila 15, 34, Bob, etc. (índice agrupado );
Es decir, los datos e índices de InnoDB están en el mismo árbol (mismo archivo, índice agrupado), mientras que MyISAM no está en el mismo árbol (índice no agrupado);
¿Qué es más rápido, un índice agrupado o un índice no agrupado?
La agregación es rápida, porque el índice agrupado no necesita buscar en archivos;
¿Por qué se recomienda crear una clave principal para las tablas de InnoDB y se recomienda usar claves primarias de incremento automático de enteros ?
El archivo ibd debe organizarse con un árbol B+, entonces, ¿de dónde viene este árbol B+? Si la tabla tiene su propia clave principal, utilice directamente los datos de la columna de esta clave principal para construir los datos de toda la tabla del árbol B+. ¿Qué pasa sin una clave principal? Si no hay una clave principal, comenzará desde la primera columna para seleccionar una columna sin datos repetidos como clave principal y usará esta columna de datos para organizar un árbol B+; si no se selecciona ninguna columna elegible (sin columna de datos no es igual)? Luego, MySQL creará una nueva columna oculta, que mantendrá una identificación única para organizar los datos de toda la tabla;
Para resumir: una vez que hemos creado la clave principal, no necesitamos ser tan problemáticos y no necesitamos que MySQL haga tanto trabajo adicional;
Entonces, ¿por qué se recomienda que la clave principal sea de plástico y se incremente automáticamente?
Razones plásticas
- Al buscar un índice, la operación de comparación de tamaño se realiza en el árbol B+, y el uuid es una cadena, y la comparación de tamaño debe compararse a través de la secuencia de códigos ASSIC y compararse carácter por carácter, por lo que la eficiencia de modelado es alto;
- Y el espacio ocupado por la conformación es relativamente pequeño;
Razones para el autoincremento
Primero entendamos la estructura Hash
Al crear un índice, el valor predeterminado es B+Tree, y también puede elegir la
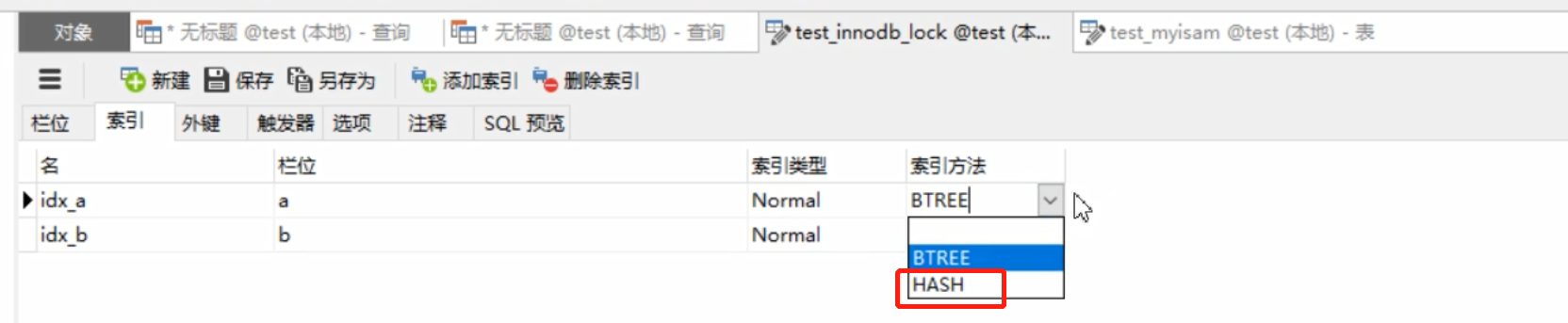
estructura Hash Estructura hash
- Realice un cálculo hash en la clave del índice para ubicar la ubicación del almacenamiento de datos
- En muchos casos, el índice Hash es más eficiente que el índice de árbol B+
- Solo puede satisfacer "=", "IN", no admite consultas de rango
- problema de conflicto hash
la tabla es la siguiente
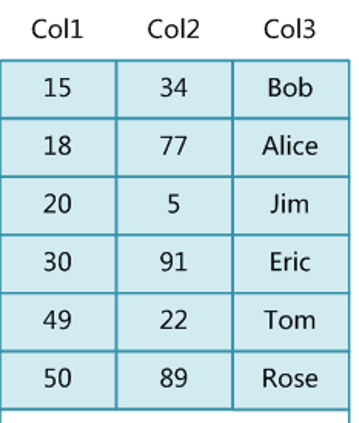
Si col3 se usa como un índice hash, cuando se inserta un dato, se realizará un algoritmo hash (md5 y muchos otros algoritmos) en los datos, y el valor hash obtenido se colocará en el cubo hash (matriz hash) Si el valor hash obtenido es el mismo Si hay un conflicto hash, se genera una lista enlazada para almacenar datos con el mismo valor hash, por ejemplo, si queremos encontrar una fila de datos cuyo nombre = Alice, primero realizamos una operación hash en Alice, obtenga el valor hash y luego recorra la lista vinculada correspondiente; en la lista vinculada Además de almacenar el elemento de índice, cada nodo de .com también almacena la dirección del archivo de disco de la fila donde se encuentra el índice ;
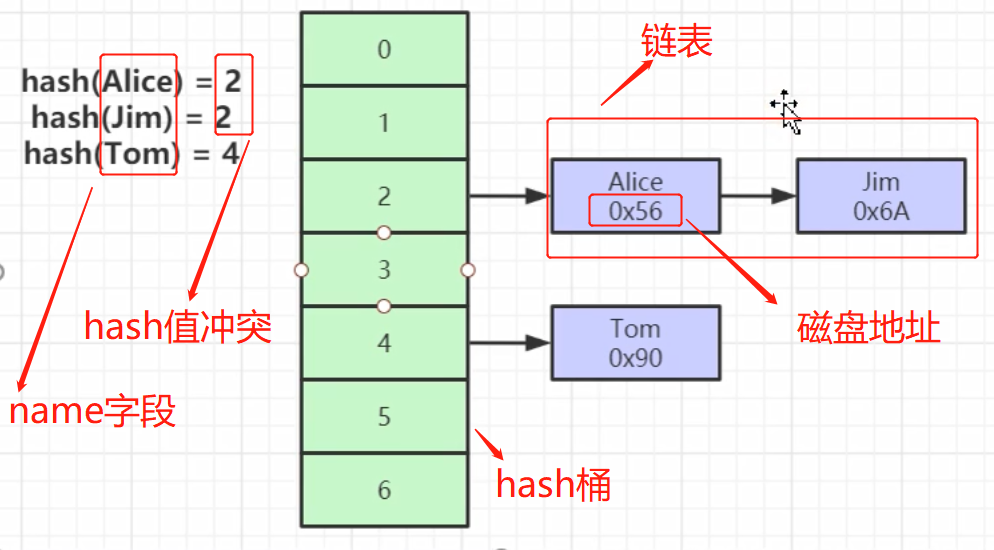
parece que este tipo de búsqueda hash es más rápida; entonces, ¿por qué no usar la estructura Hash, sino usar el árbol B+? La razón principal es que hash no admite consultas =, in y range; el árbol B+ tiene un puntero bidireccional en el nodo hoja, y el árbol B+ está ordenado, por lo que admite consultas de rango;
Incremento no automático: cuando se agregan nuevos datos, el nodo se dividirá y luego se equilibrará el árbol;
Incremento automático: cuando se agreguen nuevos datos, el nodo no se dividirá y se creará un nuevo nodo;
¿Por qué el nodo hoja de la estructura de índice de clave no principal almacena el valor de la clave principal? (Coherencia y ahorro de espacio de almacenamiento)
De la siguiente manera, después de indexar col3, el nodo hoja Alice almacena el valor de clave principal 18
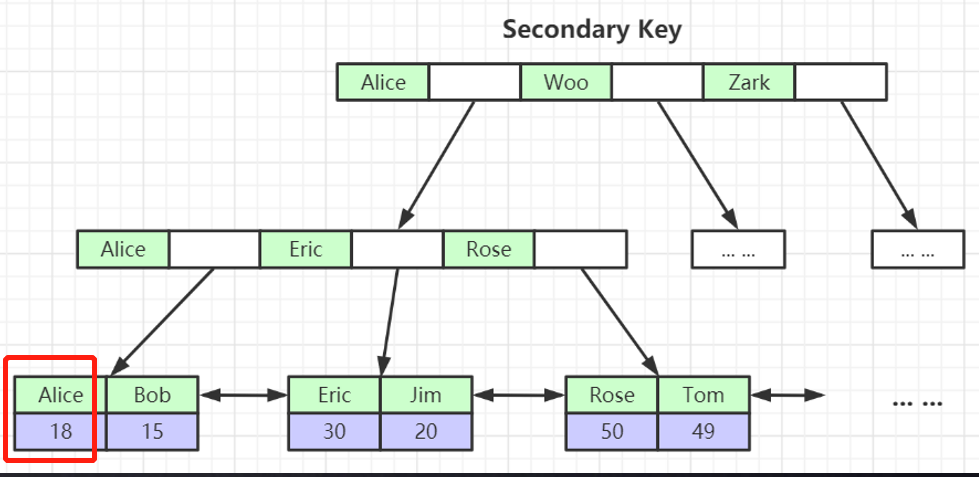
El índice secundario primero encuentra el índice de clave principal y luego encuentra los datos específicos a través del índice de clave principal (el índice secundario tiene una operación de tabla de retorno);
Índice de triple articulación (índice compuesto)
No se recomienda crear varios índices de un solo valor para una tabla; por lo general, al crear 2 o 3 índices conjuntos, se cubre más del 80 % de las declaraciones SQL de consulta;
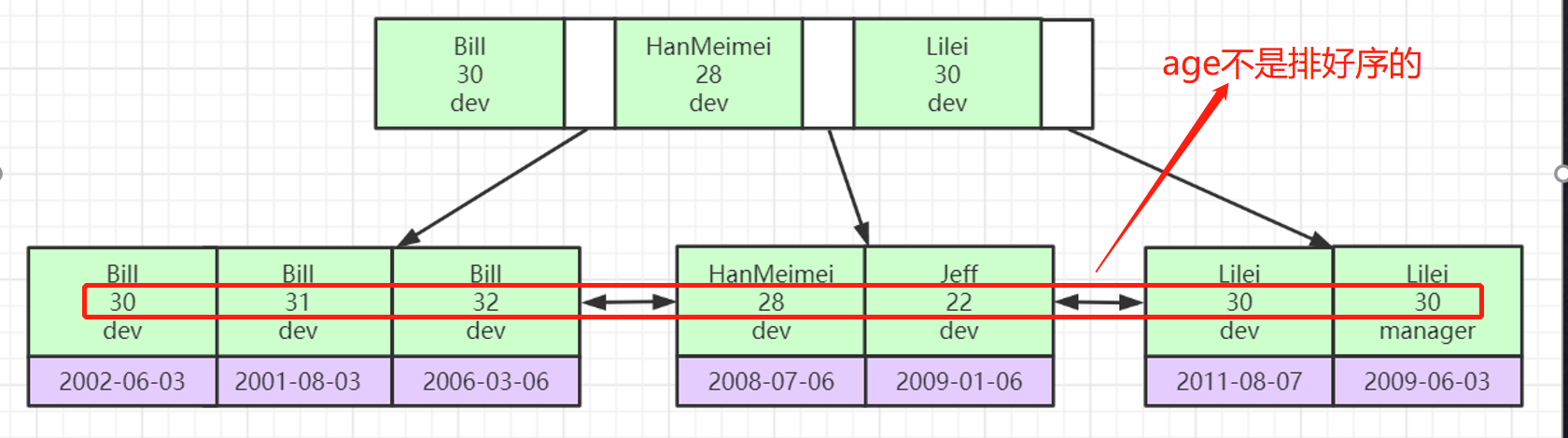
Cree un índice de clave principal conjunto para tres campos : nombre, edad, posición
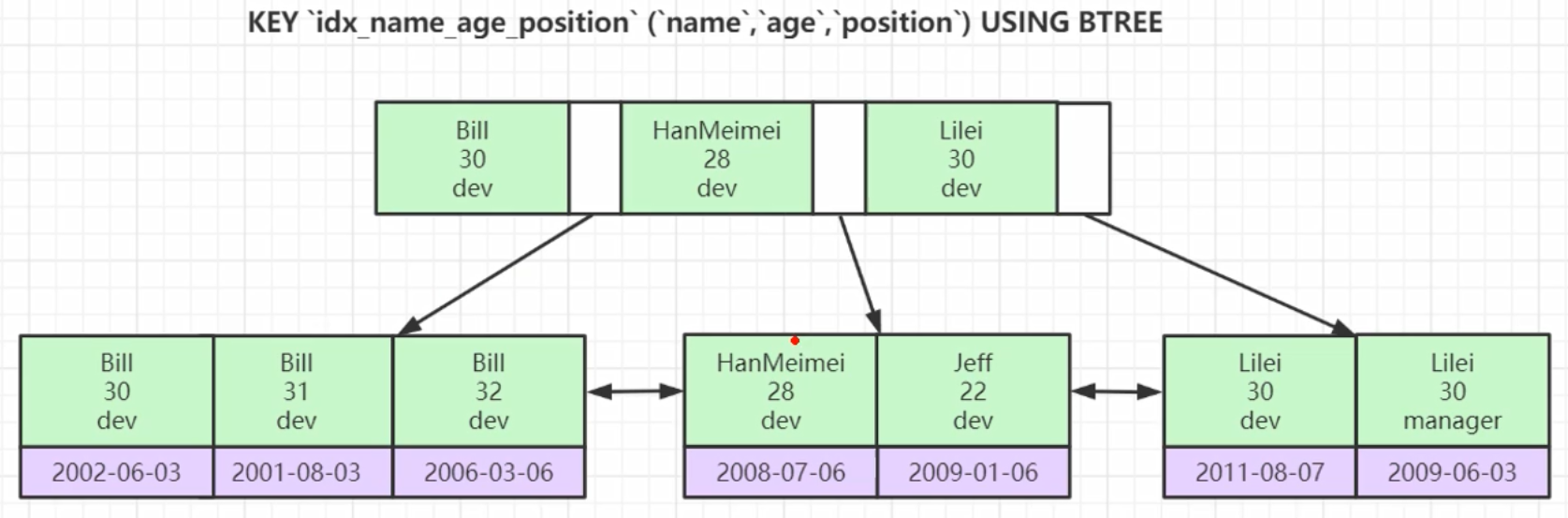
Se ordenará de acuerdo con el orden en que se estableció el índice. Primero compare el nombre, luego compare la edad y luego compare la posición para determinar el orden. Después de ordenar, se colocará en el árbol del índice; si el nombre es un
tipo de cadena, luego compare cada carácter de acuerdo con Assic , cuando el orden se puede ordenar por nombre, la edad y la posición no se consideran; si el nombre es el mismo (ambos se llaman Bill), luego compare la edad, si la edad es lo mismo, compare la posición, porque es una clave primaria conjunta, por lo que aquí estos tres Campos no pueden ser iguales al mismo tiempo;
principio del índice más a la izquierda
Bajo la premisa de establecer un índice conjunto arriba, ¿cuál enunciado abajo utilizará el índice?
# 走索引
1 SELECT * FROM employees WHERE name = 'Bill' and age = 31;
# 不走索引
2 SELECT * FROM employees WHERE age = 30 AND position = 'dev';
# 不走索引
3 SELECT * FROM employees WHERE position = 'manager';
Para el índice conjunto, debe usarse en el orden en que se creó el índice; entonces, ¿por qué debería existir el principio del índice más a la izquierda, por qué debería usarse el índice en el orden de consulta de nombre, edad y posición?
Los datos insertados en el árbol del índice se ordenan y las reglas de clasificación se basan en el orden del nombre, la edad y la posición cuando se crea el índice;
Si no nos ajustamos al principio más a la izquierda, verifique directamente edad = 30. En toda la tabla, la edad no está ordenada, por lo que el índice no juega un papel y es necesario escanear toda la tabla;