二分木の紹介
前に実装したシンボル テーブルでは、シンボル テーブルの追加、削除、およびクエリ操作を確認することは難しくありません。要素数 N が増加すると、時間も直線的に増加し、時間の複雑さは O (n). 作業効率を上げるために、次にツリーのデータ構造を学習します。
1.1 ツリーの基本定義
木は私たちのコンピューターにとって非常に重要なデータ構造であると同時に、家系図やユニットの組織構造など、実生活の多くのことを木のデータ構造を使用して記述することができます。
ツリーは、n (n>=1) 個の有限ノードで構成される一連の階層関係です。根が上を向き、葉が下を向いている逆さまの木のように見えることから「ツリー」と呼ばれます。
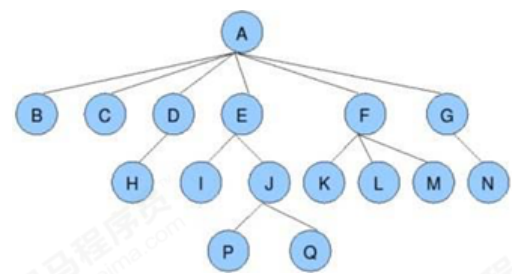
木には次の特徴があります。
- 各ノードには 0 個以上の子ノードがあります。
- 親ノードのないノードはルート ノードです。
- 各非ルート ノードには、親ノードが 1 つだけあります。
- 各ノードとその子孫ノードは、全体としてツリーと見なすことができます。これは、現在のノードの親ノードのサブツリーと呼ばれます。
1.2 木に関する用語
ノードの次数:
ノードに含まれるサブツリーの数は、ノードの次数と呼ばれます。
リーフノード:
次数が 0 のノードはリーフノードと呼ばれ、ターミナルノードとも呼ばれます
分岐ノード:
次数が 0 でないノードは分岐ノードと呼ばれ、非終端ノードとも呼ばれます。
ノードのレベル:
ルート ノードから開始して、ルート ノードのレベルは 1、ルートの直接の後継レベルは 2 など
ノードの層順番号付け:
ツリー内のノードを、上層から下層へ、同じ層内で左から右へと直線的に並べ、連続する自然数にコンパイルします。
ツリーの次数:
ツリー内のすべてのノードの最大次数
ツリーの高さ (深さ):
ツリー内のノードの最大レベル
フォレスト:
m (m>=0) のばらばらなツリーの集合で、空でないツリーのルート ノードを削除すると、ツリーはフォレストになります; 統合されたルート ノードをフォレストに追加すると、フォレストはツリーの子になり
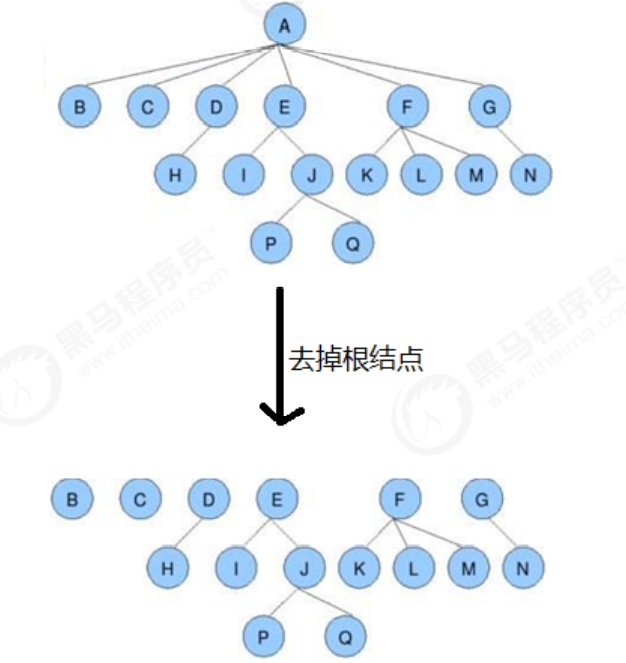
ますノード:
ノードの直接の後続ノードは、ノードの子ノードと呼ばれます
親ノード (親ノード):
ノードの直接の先行ノードは、ノードの親ノードと呼ばれます。
兄弟ノード:
同じ親ノードの子ノードは兄弟ノードと呼ばれます
1.3 二分木の基本定義
二分木は、次数が 2 以下の木です (各ノードには最大 2 つのサブノードがあります).
完全な二分木:
二分木. 各層のノード ツリーが最大値に達すると、二分木は完全な二分木 完全な二分木
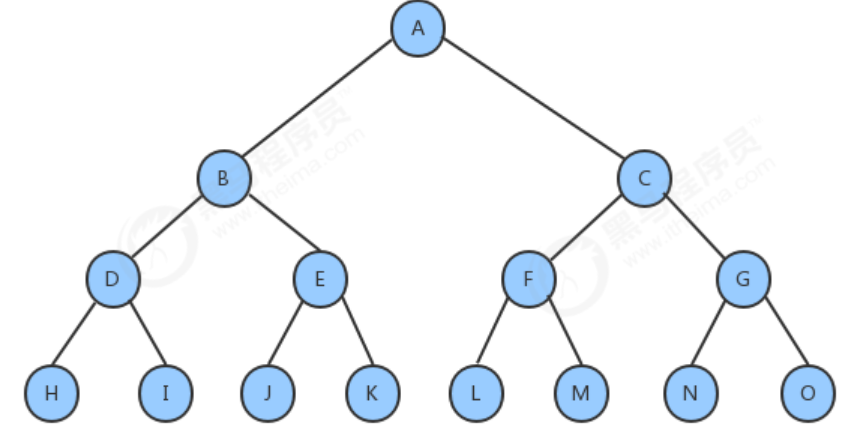
:
葉ノード 最下層と下から 2 番目の層にのみ出現する二分木で、最下層のノードはすべて層の左端に集中しています。
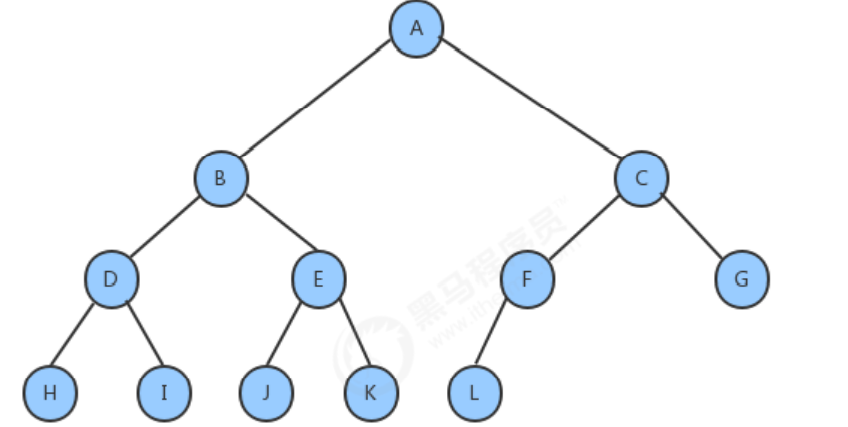
1.4 二分探索木の作成
1.4.1 二分木のノードクラス
グラフの観察によると、二分木は実際には1つのノードとそれらの間の関係で構成されていることがわかりました.オブジェクト指向の考え方に従って、ノードを記述するノードクラスを設計します.
ノード クラス API の設計:

コードの実装:
private class Node<Key,Value>{
//存储键
public Key key;
//存储值
private Value value;
//记录左子结点
public Node left;
//记录右子结点
public Node right;
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
1.4.2 二分探索木 API の設計

1.4.3 二分探索木の実装
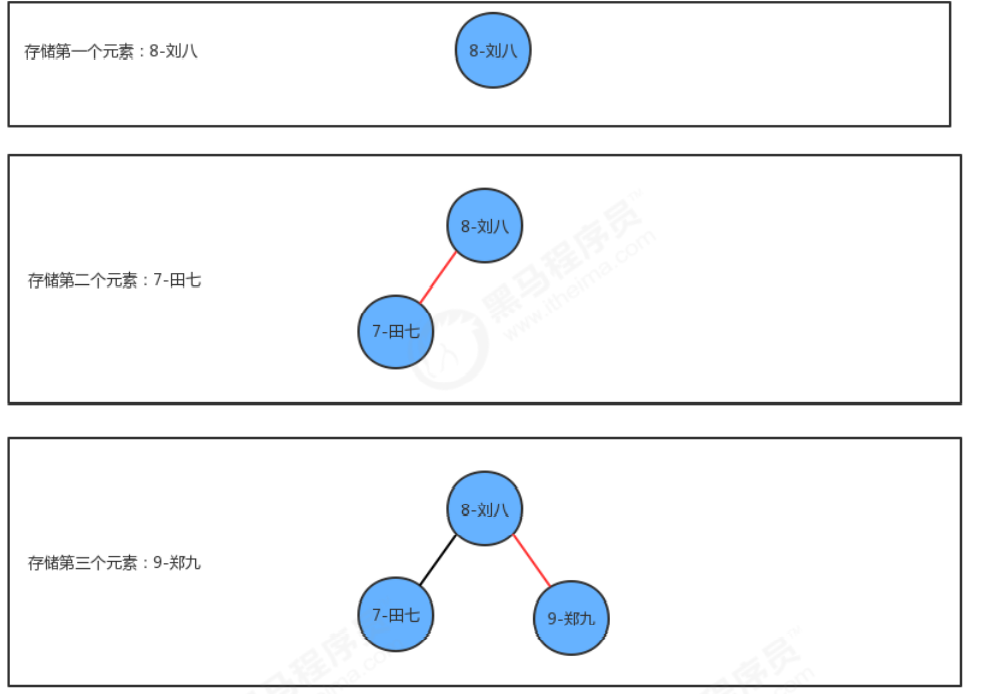
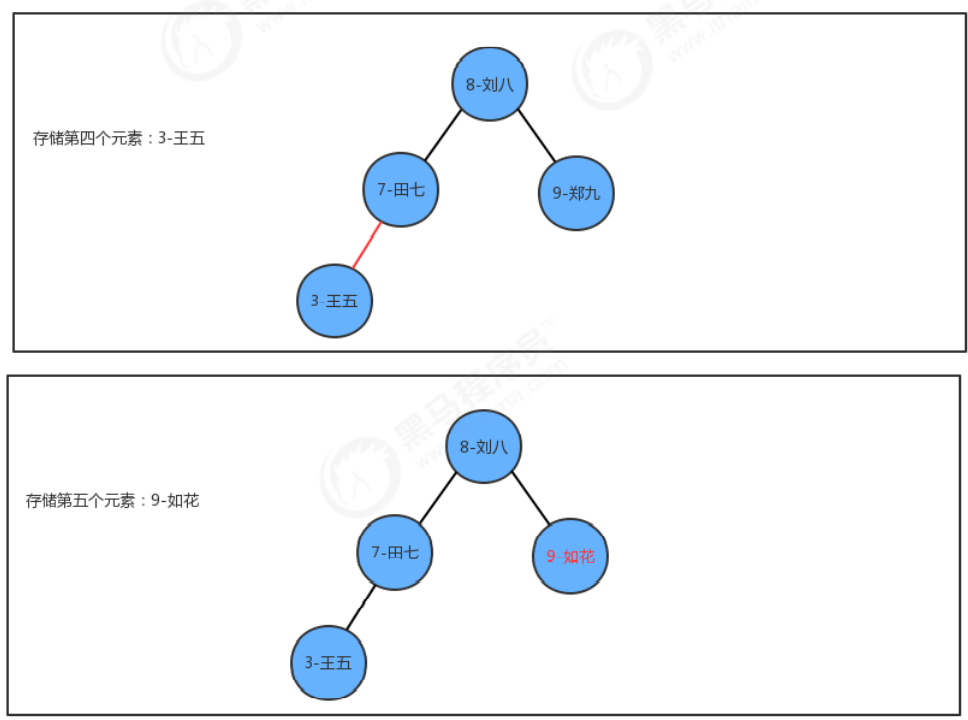
挿入メソッド put はアイデアを実装します:
- 現在のツリーにノードがない場合は、新しいノードを直接ルート ノードとして使用します。
- 現在のツリーが空でない場合は、ルート ノードから開始します:
2.1 新しいノードのキーが現在のノードのキーより小さい場合は、現在のノードの左側の子ノードを探し続けます
。新しいノードが現在のノードよりも大きい 2.3 新しいノードのキーが
現在のノードのキーと等しい場合、そのようなノードがツリーに既に存在する場合は、ノードの値を置き換えるだけです。
クエリ メソッドは実装のアイデアを取得します。
ルート ノードから開始します。
- 照会するキーが現在のノードのキーより小さい場合は、現在のノードの左側の子ノードを検索し続けます。
- 照会するキーが現在のノードのキーより大きい場合は、現在のノードの正しい子ノードを探し続けます。
- 照会するキーが現在のノードのキーと等しい場合、現在のノードの値がツリーに返されます。
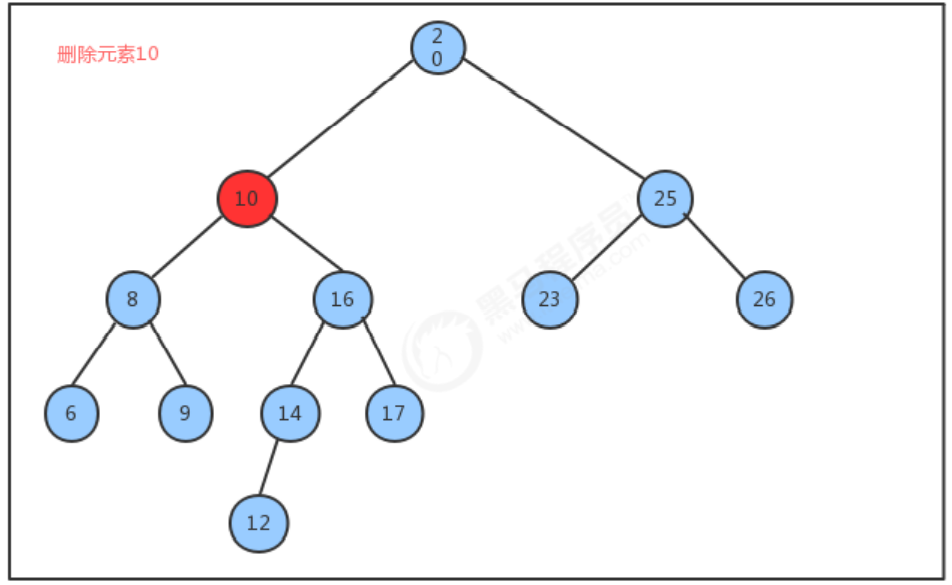
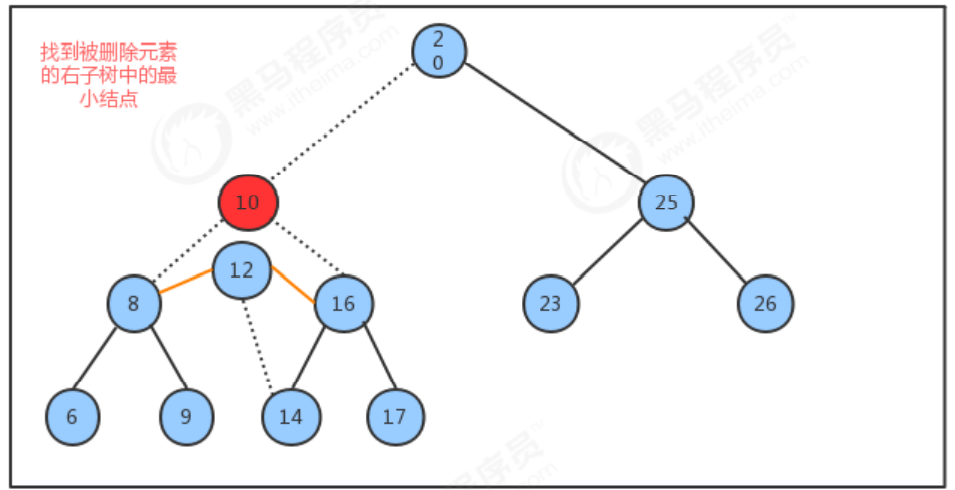
メソッドの削除の実装のアイデアを削除します。
- 削除されたノードを見つけます。
- 削除されたノードの右側のサブツリーで最小のノード minNode を見つけます
- 右側のサブツリーの最小ノードを削除します
- 削除されたノードの左部分木を最小ノード minNode の左部分木と呼び、削除されたノードの右部分木を最小ノード minNode の右部分木と呼ぶことにします。
- 削除されたノードの親ノードが最小ノード minNode を指すようにする

コード:
//二叉树代码
public class BinaryTree<Key extends Comparable<Key>, Value> {
//记录根结点
private Node root;
//记录树中元素的个数
private int N;
//获取树中元素的个数
public int size() {
return N;
}
//向树中添加元素key-value
public void put(Key key, Value value) {
root = put(root, key, value);
}
//向指定的树x中添加key-value,并返回添加元素后新的树
private Node put(Node x, Key key, Value value) {
if (x == null) {
//个数+1
N++;
return new Node(key, value, null, null);
}
int cmp = key.compareTo(x.key);
if (cmp > 0) {
//新结点的key大于当前结点的key,继续找当前结点的右子结点
x.right = put(x.right, key, value);
} else if (cmp < 0) {
//新结点的key小于当前结点的key,继续找当前结点的左子结点
x.left = put(x.left, key, value);
} else {
//新结点的key等于当前结点的key,把当前结点的value进行替换
x.value = value;
}
return x;
}
//查询树中指定key对应的value
public Value get(Key key) {
return get(root, key);
}
//从指定的树x中,查找key对应的值
public Value get(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp > 0) {
//如果要查询的key大于当前结点的key,则继续找当前结点的右子结点;
return get(x.right, key);
} else if (cmp < 0) {
//如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;
return get(x.left, key);
} else {
//如果要查询的key等于当前结点的key,则树中返回当前结点的value。
return x.value;
}
}
//删除树中key对应的value
public void delete(Key key) {
root = delete(root, key);
}
//删除指定树x中的key对应的value,并返回删除后的新树
public Node delete(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp > 0) {
//新结点的key大于当前结点的key,继续找当前结点的右子结点
x.right = delete(x.right, key);
} else if (cmp < 0) {
//新结点的key小于当前结点的key,继续找当前结点的左子结点
x.left = delete(x.left, key);
} else {
//新结点的key等于当前结点的key,当前x就是要删除的结点
//1.如果当前结点的右子树不存在,则直接返回当前结点的左子结点
if (x.right == null) {
return x.left;
}
//2.如果当前结点的左子树不存在,则直接返回当前结点的右子结点
if (x.left == null) {
return x.right;
}
//3.当前结点的左右子树都存在
//3.1找到右子树中最小的结点
Node minNode = x.right;
while (minNode.left != null) {
minNode = minNode.left;
}
//3.2删除右子树中最小的结点
Node n = x.right;
while (n.left != null) {
if (n.left.left == null) {
n.left = null;
} else {
n = n.left;
}
}
//3.3让被删除结点的左子树称为最小结点minNode的左子树,让被删除结点的右子树称为最小结点
minNode的右子树
minNode.left = x.left;
minNode.right = x.right;
//3.4让被删除结点的父节点指向最小结点minNode
x = minNode;
//个数-1
N--;
}
return x;
}
private class Node {
//存储键
public Key key;
//存储值
private Value value;
//记录左子结点
public Node left;
//记录右子结点
public Node right;
public Node(Key key, Value value, Node left, Node right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
}
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<Integer, String> bt = new BinaryTree<>();
bt.put(4, "二哈");
bt.put(1, "张三");
bt.put(3, "李四");
bt.put(5, "王五");
System.out.println(bt.size());
bt.put(1,"老三");
System.out.println(bt.get(1));
System.out.println(bt.size());
bt.delete(1);
System.out.println(bt.size());
}
}
1.4.4 その他の二分探索木の便利な方法
1.4.4.1 二分木で最小のキーを見つける
場合によっては、ツリー内のすべての要素を格納するキーの最小値を見つける必要があります. たとえば、ツリーには生徒のランキングと名前のデータが格納されているため、最も低いランキングは何かを調べる必要があります。ここでは、これを実現するために次の 2 つの方法を設計します。

//找出整个树中最小的键
public Key min(){
return min(root).key;
}
//找出指定树x中最小的键所在的结点
private Node min(Node x){
if (x.left!=null){
return min(x.left);
}else{
return x;
}
}
1.4.4.2 二分木で最大のキーを見つける
場合によっては、ツリー内のすべての要素を格納するキーの最大値を見つける必要があります. たとえば、ツリーには生徒の成績と名前が格納されているため、見つける必要がある最高スコアはいくつでしょうか? ここでは、完了するための 2 つの方法も設計します。

//找出整个树中最大的键
public Key max(){
return max(root).key;
}
//找出指定树x中最大键所在的结点
public Node max(Node x){
if (x.right!=null){
return max(x.right);
}else{
return x;
}
}
1.5 二分木の基本的な走査
多くの場合、ツリーに格納されている各要素を取り出すために、配列の配列をトラバースするようにツリーをトラバースする必要があります. ツリー構造は線形構造とは異なるため、最初から逆方向にトラバースすることはできません.トラバーサルとは、どのような検索パスをトラバースするかという問題です。
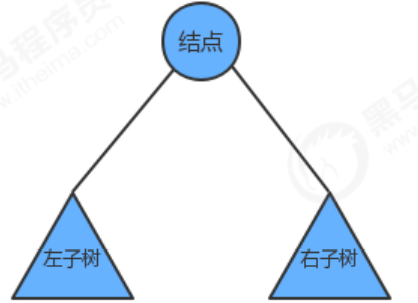
上図のようにルートノード、左部分木、右部分木からなる木を単純に描くと、ルートノードにアクセスするタイミングによって、二分木の走査を次の3つに分けることができます。方法:
- トラバーサルを事前順序付けします。
最初にルート ノードにアクセスし、次に左のサブツリーにアクセスし、最後に右のサブツリーにアクセスします。 - 順序通りのトラバーサル。
最初に左側のサブツリーにアクセスし、中央のルート ノードにアクセスして、最後に右側のサブツリーにアクセスします。 - ポストオーダー トラバーサル。
最初に左のサブツリーにアクセスし、次に右のサブツリーにアクセスし、最後にルート ノードにアクセスします。
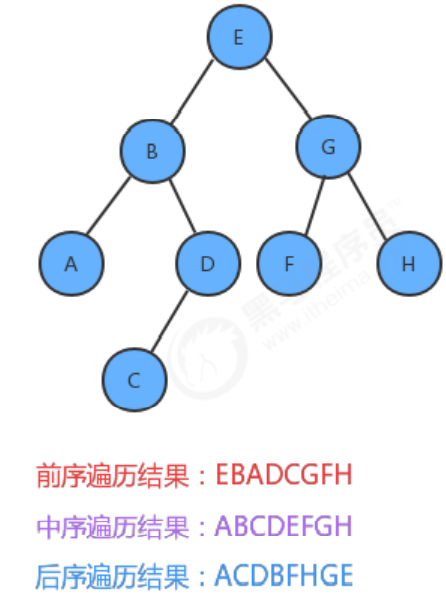
以下のツリーをトラバースするために 3 つのトラバーサル メソッドを使用すると、結果は次のようになります。
1.5.1 予約注文トラバーサル
4.4 で作成したツリーに、事前注文トラバーサル用の API を追加します。
public Queue<Key> preErgodic():使用前序遍历,获取整个树中的所有键
private void preErgodic(Node x,Queue<Key> keys):使用前序遍历,把指定树x中的所有键放入到keys队列中
実装プロセスでは、事前注文をたどり、各ノードのキーを取り出し、キューに入れ、返します。
実装手順:
- 現在のノードのキーをキューに入れます。
- 現在のノードの左側のサブツリーを検索します。空でない場合は、左側のサブツリーを再帰的にトラバースします
- 現在のノードの右側のサブツリーを検索します。空でない場合は、右側のサブツリーを再帰的にトラバースします
コード:
//使用前序遍历,获取整个树中的所有键
public Queue<Key> preErgodic(){
Queue<Key> keys = new Queue<>();
preErgodic(root,keys);
return keys;
}
//使用前序遍历,把指定树x中的所有键放入到keys队列中
private void preErgodic(Node x,Queue<Key> keys){
if (x==null){
return;
}
//1.把当前结点的key放入到队列中;
keys.enqueue(x.key);
//2.找到当前结点的左子树,如果不为空,递归遍历左子树
if (x.left!=null){
preErgodic(x.left,keys);
}
//3.找到当前结点的右子树,如果不为空,递归遍历右子树
if (x.right!=null){
preErgodic(x.right,keys);
}
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<String, String> bt = new BinaryTree<>();
bt.put("E", "5");
bt.put("B", "2");
bt.put("G", "7");
bt.put("A", "1");
bt.put("D", "4");
bt.put("F", "6");
bt.put("H", "8");
bt.put("C", "3");
Queue<String> queue = bt.preErgodic();
for (String key : queue) {
System.out.println(key+"="+bt.get(key));
}
}
}
1.5.2 インオーダー・トラバーサル
1.4 で作成したツリーに、事前注文トラバーサル用の API を追加します。
public Queue<Key> midErgodic():使用中序遍历,获取整个树中的所有键
private void midErgodic(Node x,Queue<Key> keys):使用中序遍历,把指定树x中的所有键放入到keys队列中
実装手順:
- 現在のノードの左側のサブツリーを検索します。空でない場合は、左側のサブツリーを再帰的にトラバースします
- 現在のノードのキーをキューに入れます。
- 現在のノードの右側のサブツリーを検索します。空でない場合は、右側のサブツリーを再帰的にトラバースします
コード:
//使用中序遍历,获取整个树中的所有键
public Queue<Key> midErgodic(){
Queue<Key> keys = new Queue<>();
midErgodic(root,keys);
return keys;
}
//使用中序遍历,把指定树x中的所有键放入到keys队列中
private void midErgodic(Node x,Queue<Key> keys){
if (x==null){
return;
}
//1.找到当前结点的左子树,如果不为空,递归遍历左子树
if (x.left!=null){
midErgodic(x.left,keys);
}
//2.把当前结点的key放入到队列中;
keys.enqueue(x.key);
//3.找到当前结点的右子树,如果不为空,递归遍历右子树
if (x.right!=null){
midErgodic(x.right,keys);
}
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<String, String> bt = new BinaryTree<>();
bt.put("E", "5");
bt.put("B", "2");
bt.put("G", "7");
bt.put("A", "1");
bt.put("D", "4");
bt.put("F", "6");
bt.put("H", "8");
bt.put("C", "3");
Queue<String> queue = bt.midErgodic();
for (String key : queue) {
System.out.println(key+"="+bt.get(key));
}
}
}
1.5.3 ポストオーダートラバーサル
1.4 で作成したツリーに、事前注文トラバーサル用の API を追加します。
public Queue<Key> afterErgodic():使用后序遍历,获取整个树中的所有键
private void afterErgodic(Node x,Queue<Key> keys):使用后序遍历,把指定树x中的所有键放入到keys队列中
実装手順:
- 現在のノードの左側のサブツリーを検索します。空でない場合は、左側のサブツリーを再帰的にトラバースします
- 現在のノードの右側のサブツリーを検索します。空でない場合は、右側のサブツリーを再帰的にトラバースします
- 現在のノードのキーをキューに入れます。
コード
//使用后序遍历,获取整个树中的所有键
public Queue<Key> afterErgodic(){
Queue<Key> keys = new Queue<>();
afterErgodic(root,keys);
return keys;
}
//使用后序遍历,把指定树x中的所有键放入到keys队列中
private void afterErgodic(Node x,Queue<Key> keys){
if (x==null){
return;
}
//1.找到当前结点的左子树,如果不为空,递归遍历左子树
if (x.left!=null){
afterErgodic(x.left,keys);
}
//2.找到当前结点的右子树,如果不为空,递归遍历右子树
if (x.right!=null){
afterErgodic(x.right,keys);
}
//3.把当前结点的key放入到队列中;
keys.enqueue(x.key);
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<String, String> bt = new BinaryTree<>();
bt.put("E", "5");
bt.put("B", "2");
bt.put("G", "7");
bt.put("A", "1");
bt.put("D", "4");
bt.put("F", "6");
bt.put("H", "8");
bt.put("C", "3");
Queue<String> queue = bt.afterErgodic();
for (String key : queue) {
System.out.println(key+"="+bt.get(key));
}
}
}
1.6 二分木のレベル順トラバーサル
いわゆる層順トラバーサルは、ルート ノード (最初の層) から開始し、各層のすべてのノードの値を取得するために下に移動することです. 次のような二分木があります
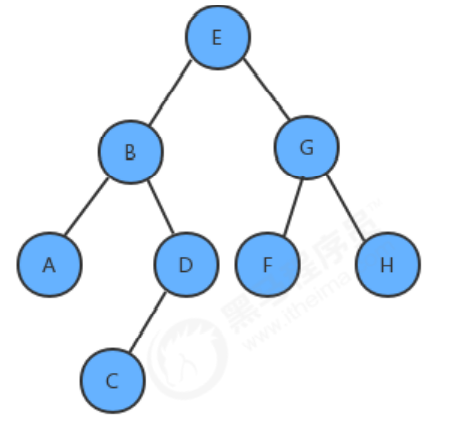
。 traversal は:
4.4 で作成した EBGADFHC ツリーで、層順トラバーサル用の API を追加します。
public Queue<Key> layerErgodic():使用层序遍历,获取整个树中的所有键
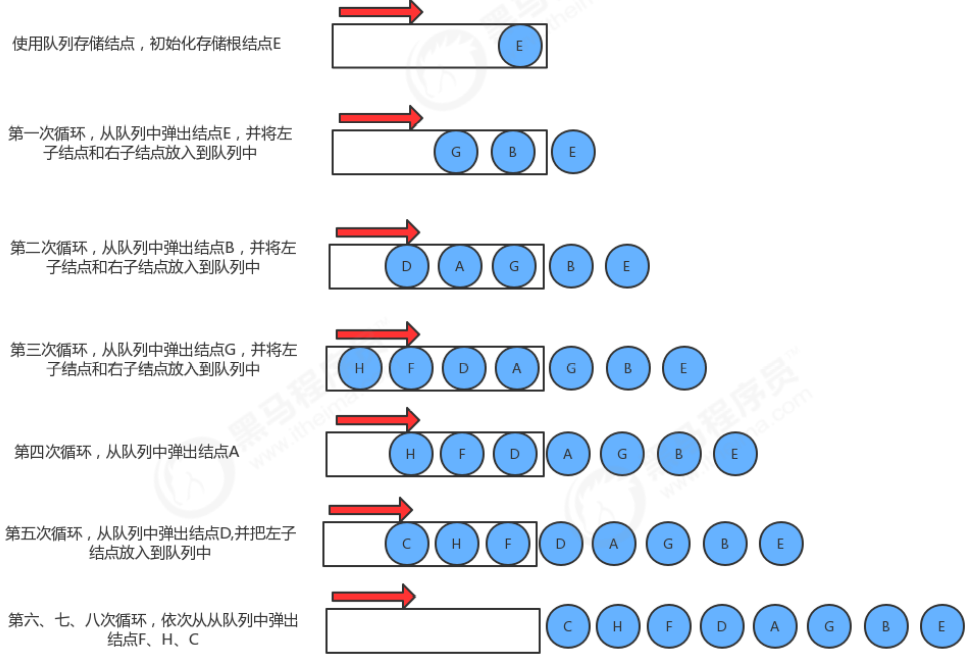
実装手順:
- 各レイヤーのノードを格納するキューを作成します。
- ループを使用してキューからノードをポップします:
2.1 現在のノードのキーを取得します;
2.2 現在のノードの左の子ノードが空でない場合、左の子ノードをキューに入れます
2.3 の右の子ノードの場合現在のノード 子ノードが空でない場合は、正しい子ノードをキューに入れます
コード
//使用层序遍历得到树中所有的键
public Queue<Key> layerErgodic(){
Queue<Key> keys = new Queue<>();
Queue<Node> nodes = new Queue<>();
nodes.enqueue(root);
while(!nodes.isEmpty()){
Node x = nodes.dequeue();
keys.enqueue(x.key);
if (x.left!=null){
nodes.enqueue(x.left);
}
if (x.right!=null){
nodes.enqueue(x.right);
}
}
return keys;
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<String, String> bt = new BinaryTree<>();
bt.put("E", "5");
bt.put("B", "2");
bt.put("G", "7");
bt.put("A", "1");
bt.put("D", "4");
bt.put("F", "6");
bt.put("H", "8");
bt.put("C", "3");
Queue<String> queue = bt.layerErgodic();
for (String key : queue) {
System.out.println(key+"="+bt.get(key));
}
}
}
1.7 二分木の最大深さ問題
要件:
与えられたツリーについて、ツリーの最大深度 (ツリーのルート ノードから最も遠いリーフ ノードまでの最長パス上のノードの数) を計算してください。
上のツリーの深さは最大 4 です。
実装:
1.4 で作成されたツリーの最大深度を見つけるために、次の API を追加します:
public int maxDepth(): ツリー全体の最大深度を計算します
private int maxDepth(Node x): 指定されたツリー x の最大深度を計算します
実装手順:
- ルート ノードが空の場合、最大深度は 0 です。
- 左サブツリーの最大深さを計算します。
- 右部分木の最大深さを計算します。
- 現在のツリーの最大深度 = 左サブツリーの最大深度と右サブツリーの最大深度の大きい方 + 1
コード:
//计算整个树的最大深度
public int maxDepth() {
return maxDepth(root);
}
//计算指定树x的最大深度
private int maxDepth(Node x) {
//1.如果根结点为空,则最大深度为0;
if (x == null) {
return 0;
}
int max = 0;
int maxL = 0;
int maxR = 0;
//2.计算左子树的最大深度;
if (x.left != null) {
maxL = maxDepth(x.left);
}
//3.计算右子树的最大深度;
if (x.right != null) {
maxR = maxDepth(x.right);
}
//4.当前树的最大深度=左子树的最大深度和右子树的最大深度中的较大者+1
max = maxL > maxR ? maxL + 1 : maxR + 1;
return max;
}
//测试代码
public class Test {
public static void main(String[] args) throws Exception {
BinaryTree<String, String> bt = new BinaryTree<>();
bt.put("E", "5");
bt.put("B", "2");
bt.put("G", "7");
bt.put("A", "1");
bt.put("D", "4");
bt.put("F", "6");
bt.put("H", "8");
bt.put("C", "3");
int i = bt.maxDepth();
System.out.println(i);
}
}
1.8 折り紙の問題
必要なもの:
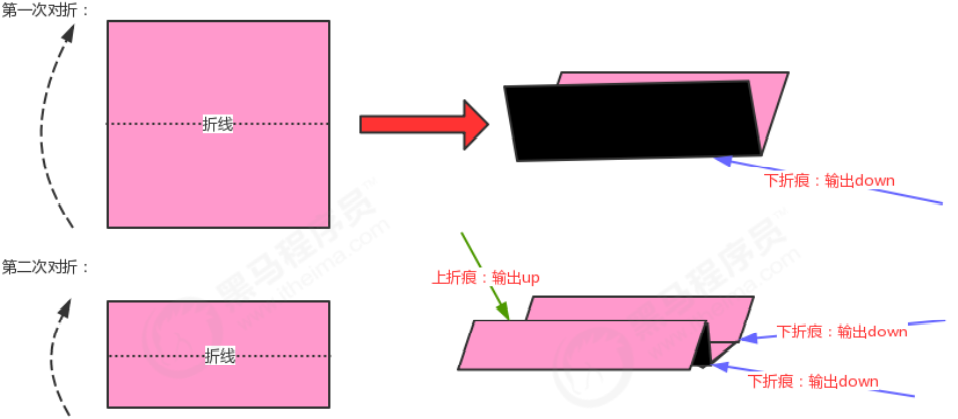
短冊をテーブルの上に垂直に置き、下から上に一度半分に折り、折り目を押し出して広げてください。このとき、折り目は凹んでいます。つまり、折り目の突起の方向が紙片の裏側を向いています。短冊を下から上に連続して2つ折りし、折り目を押し出して広げた場合、このとき、上から下の折り目、下の折り目、上の折り目の3つの折り目があります。下。
入力パラメータ N を指定すると、短冊を下から上に N 回連続して半分に折ることを意味します。すべての折り目の方向を上から下に印刷してください。 N=2 の場合、出力: 下 下 上
分析:
中折り後に紙を裏返し、ピンク色を下に向けます.このとき、最初の半折りで発生した折り目をルートノードと見なし、2番目の半折りで発生した下の折り目をノードの左側. 子ノード, 2番目の半分折りによって生成された上部の折り目は、ノードの右側の子ノードであるため、ツリーデータ構造を使用して、半分折り後に生成された折り目を記述できます.
このツリーには次のような特徴があります。
- ルート ノードは下の折り目です。
- 各ノードの左の子ノードは下の折り目です。
- 各ノードの右側の子ノードは上の折り目です。
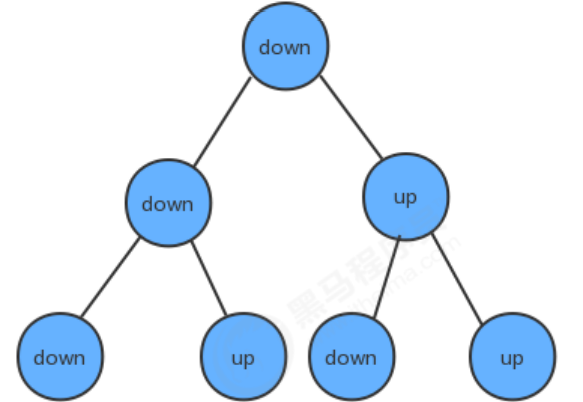
実装手順:
- ノードクラスを定義する
- 深さ N の折り目ツリーを作成します。
- ツリー内のすべてのノードの内容を出力するには、順序通りのトラバーサルを使用します。
深さ N の折り目ツリーを作成します。
- 初めて半分に折り、折り目を 1 つだけ付け、ルート ノードを作成します。
- 最初のハーフ フォールドでない場合は、キューを使用してルート ノードを保存します。
- キューをループします:
3.1 キューからノードを取り出します;
3.2 このノードの左の子ノードが空でない場合、この左の子ノードをキューに追加します;
3.3 このノードの右の子ノードが空でない場合、右の子ノードをキューに追加します;
3.4 現在のノードの左の子ノードと右の子ノードが空でないかどうかを判断します。空である場合は、値を下にして現在のノードの値を作成する必要があります A 左の子値が up のノードと、値が up の右側の子ノード。
コード:
public class PaperFolding {
public static void main(String[] args) {
//构建折痕树
Node tree = createTree(3);
//遍历折痕树,并打印
printTree(tree);
}
//3.使用中序遍历,打印出树中所有结点的内容;
private static void printTree(Node tree) {
if (tree==null){
return;
}
printTree(tree.left);
System.out.print(tree.item+",");
printTree(tree.right);
}
//2.构建深度为N的折痕树;
private static Node createTree(int N) {
Node root = null;
for (int i = 0; i <N ; i++) {
if (i==0){
//1.第一次对折,只有一条折痕,创建根结点;
root = new Node("down",null,null);
}else{
//2.如果不是第一次对折,则使用队列保存根结点;
Queue<Node> queue = new Queue<>();
queue.enqueue(root);
//3.循环遍历队列:
while(!queue.isEmpty()){
//3.1从队列中拿出一个结点;
Node tmp = queue.dequeue();
//3.2如果这个结点的左子结点不为空,则把这个左子结点添加到队列中;
if (tmp.left!=null){
queue.enqueue(tmp.left);
}
//3.3如果这个结点的右子结点不为空,则把这个右子结点添加到队列中;
if (tmp.right!=null){
queue.enqueue(tmp.right);
}
//3.4判断当前结点的左子结点和右子结点都不为空,如果是,则需要为当前结点创建一个值为down的左子结点,一个值为up的右子结点。
if (tmp.left==null && tmp.right==null){
tmp.left = new Node("down",null,null);
tmp.right = new Node("up",null,null);
}
}
}
}
return root;
}
//1.定义结点类
private static class Node{
//存储结点元素
String item;
//左子结点
Node left;
//右子结点
Node right;
//结点类
private static class Node<T>{
public T item;//存储元素
public Node left;
public Node right;
public Node(T item, Node left, Node right) {
this.item = item;
this.left = left;
this.right = right;
}
}
}