Tabla de contenido
1. Introducción a los vectores
En segundo lugar, la interfaz común de vector
2. Operación de capacidad vectorial
3. Agregar, eliminar, verificar y modificar vectores
Tres, implementación de simulación de vectores.
1. Introducción a los vectores
Vector es una plantilla de clase que puede crear instancias de clases que almacenan diferentes datos de acuerdo con diferentes parámetros de plantilla. La clase vector se puede usar para administrar arreglos.A diferencia de la clase de cadena , la cadena solo puede administrar arreglos de tipo char , mientras que el vector puede administrar arreglos de cualquier tipo.
- Un vector es un contenedor de secuencias que representa una matriz de tamaño variable.
- Al igual que las matrices, los vectores también usan espacio de almacenamiento contiguo para almacenar elementos. Eso significa que se puede acceder a los elementos del vector usando subíndices, que es tan eficiente como una matriz. Pero a diferencia de una matriz, su tamaño se puede cambiar dinámicamente y el contenedor manejará su tamaño automáticamente.
- Esencialmente, vector usa una matriz asignada dinámicamente para almacenar sus elementos. Cuando se insertan nuevos elementos, es necesario cambiar el tamaño de la matriz para aumentar el espacio de almacenamiento. Lo hace asignando una nueva matriz y luego moviendo todos los elementos a esta matriz. En términos de tiempo, esta es una tarea relativamente costosa, porque el vector no cambia de tamaño cada vez que se agrega un nuevo elemento al contenedor.
- Estrategia de espacio de asignación de vectores: el vector asignará espacio adicional para acomodar el posible crecimiento, porque el espacio de almacenamiento es más grande que el espacio de almacenamiento real requerido. Diferentes bibliotecas emplean diferentes estrategias para sopesar el uso y la reasignación del espacio. Pero en cualquier caso, la reasignación debe ser de un tamaño de intervalo logarítmicamente creciente, de modo que la inserción de un elemento al final se realice en una complejidad de tiempo constante.
- Por lo tanto, el vector ocupa más espacio de almacenamiento para obtener la capacidad de administrar el espacio de almacenamiento y crecer dinámicamente de manera eficiente.
- En comparación con otros contenedores de secuencias dinámicas (deque, list y forward_list), el vector es más eficiente al acceder a los elementos, y agregar y eliminar elementos al final es relativamente eficiente. Para otras operaciones de eliminación e inserción que no están al final, es menos eficiente. Mejor que list y forward_list iteradores y referencias unificados.
En segundo lugar, la interfaz común de vector
1. La estructura del vector
| (constructor) declaración de constructor | Descripción de la interfaz |
| vector() (énfasis) | Sin construcción de parámetros |
| vector(tamaño_tipo n, constante valor_tipo& val = valor_tipo()) | Construir e inicializar n vals |
| vector (const vector& x); (énfasis) | copiar construcción |
| vector (InputIterator primero, InputIterator último); | Inicializar la construcción usando iteradores |
Por ejemplo:
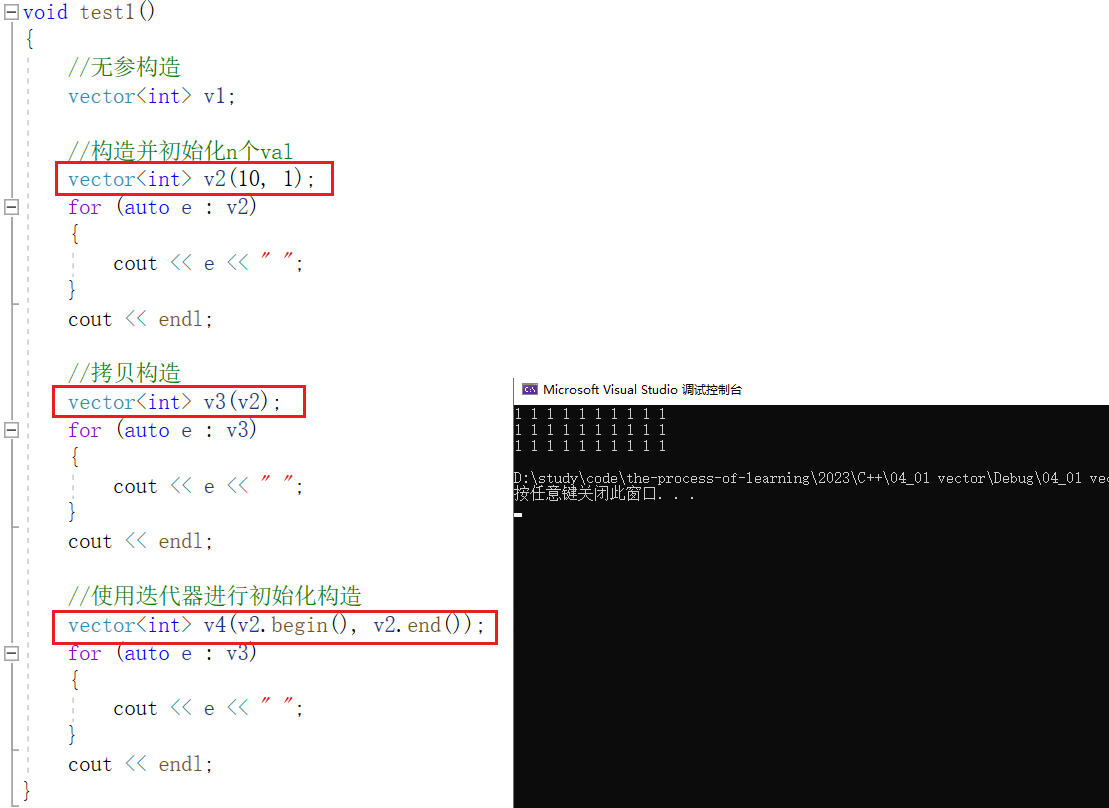
void test1()
{
//无参构造
vector<int> v1;
//构造并初始化n个val
vector<int> v2(10, 1);
for (auto e : v2)
{
cout << e << " ";
}
cout << endl;
//拷贝构造
vector<int> v3(v2);
for (auto e : v3)
{
cout << e << " ";
}
cout << endl;
//使用迭代器进行初始化构造
vector<int> v4(v2.begin(), v2.end());
for (auto e : v3)
{
cout << e << " ";
}
cout << endl;
}El resultado es el siguiente:
2. Operación de capacidad vectorial
| espacio de capacidad | Descripción de la interfaz |
| tamaño | Obtener el número de datos |
| capacidad | Obtener el tamaño de la capacidad |
| vacío | Determinar si está vacío. |
| cambiar el tamaño (énfasis) | Cambiar el tamaño del vector |
| reserva (énfasis) | Cambiar la capacidad del vector |
2.1, reserva
Podemos experimentar la operación de expansión de vector de manera más intuitiva a través del siguiente código:
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}El fenómeno es el siguiente:

Se puede ver que bajo el compilador vs, el vector se expande 1,5 veces cada vez. Si ha determinado el número aproximado de elementos que se almacenarán en el vector, puede establecer suficiente espacio de antemano para evitar el problema de ineficiencia causado por la expansión al insertar:
void TestVectorExpandOP()
{
vector<int> v;
size_t sz = v.capacity();
v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容
cout << "making bar grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
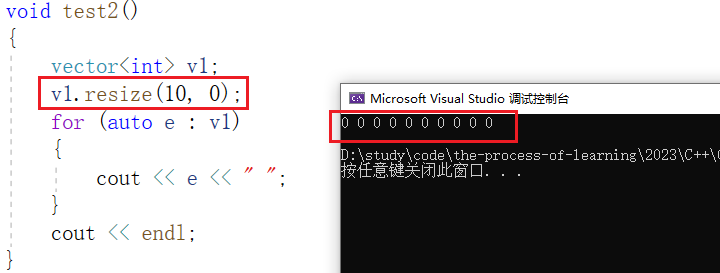
2.2, cambiar el tamaño
cambiar el tamaño puede cambiar el tamaño de tamaño . Se puede inicializar mientras se asigna espacio:
3. Agregar, eliminar, verificar y modificar vectores
| Agregar, eliminar, verificar y modificar vectores | Descripción de la interfaz |
| push_back (énfasis) | tapón de cola |
| pop_back (énfasis) | eliminar cola |
| encontrar | encontrar. (Tenga en cuenta que esta es una implementación de módulo de algoritmo, no una interfaz miembro de vector) |
| insertar | Insertar valor antes de la posición |
| borrar | Eliminar los datos en la posición |
| intercambio | Intercambiar el espacio de datos de dos vectores. |
| operador[] (énfasis) | acceder como una matriz |
3.1, encontrar
Debido a que la búsqueda en el algoritmo es universal y puede ser utilizada por todos los contenedores, no se proporciona una interfaz de búsqueda separada en el vector.

El método de uso es el siguiente:

3.2, insertar
Insertar datos en la posición de subíndice especificada:
Tres, implementación de simulación de vectores.
Primero construyamos el marco más básico de un vector, y sus tres variables miembro son todas punteros:
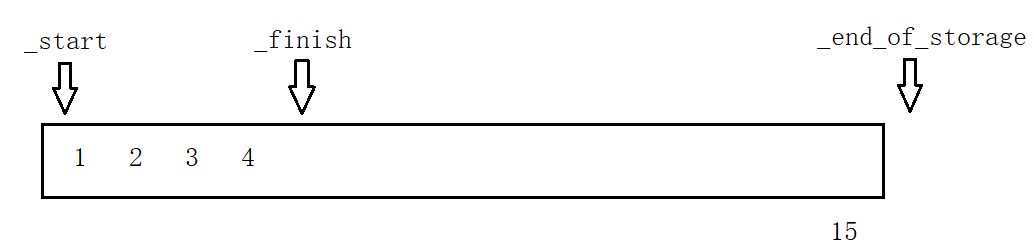
namespace bin
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}1. empezar y terminar
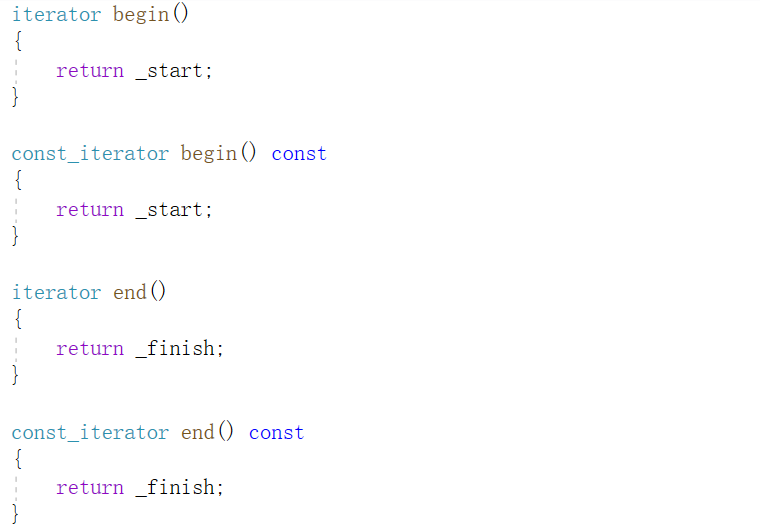
Las funciones constantes y no constantes constituyen una sobrecarga para cumplir con los requisitos de llamada en diferentes situaciones.
2. capacidad y tamaño

3, operador []

Las funciones constantes y no constantes constituyen una sobrecarga para cumplir con los requisitos de llamada en diferentes situaciones.
4, operador =
Para lograr la sobrecarga del operador de asignación, debe usar la construcción de copia.La construcción de copia se discutirá en el siguiente punto y se usará aquí primero.
La implementación específica es la siguiente:

La parte rodeada por el cuadro rojo usa el paso de parámetros por valor en lugar del paso de parámetros por referencia.Esto se debe a que originalmente esperamos que la copia ocurra aquí, se copiará un nuevo objeto y el intercambio se completará en el cuerpo de la función.
5, reserva
Hay una cosa a la que hay que prestar atención en la reserva de la función de expansión :
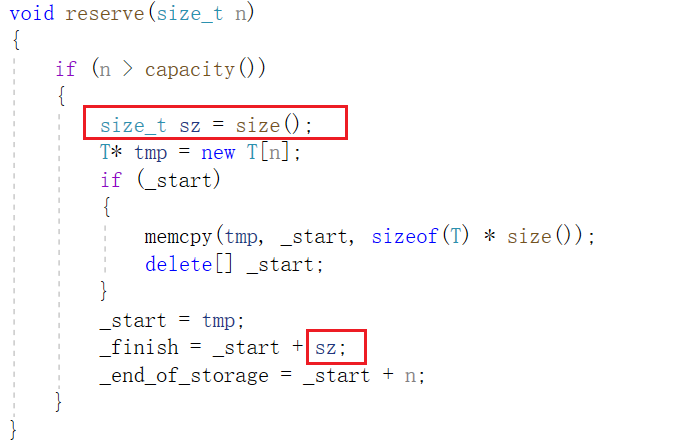
Debido a que la función size() se realiza devolviendo _finsih - _start , si se escribe directamente como _finish = _start + size() , la declaración en esta línea se convertirá en _finish = _start + _finsih - _start , y finalmente _finish todavía apunta a la posición original, lo que resulta en un error. Por lo tanto, necesitamos establecer una variable sz por adelantado para guardar el valor de size() y agregar sz al cálculo final .
Nota : Debido a que la función utilizada es memcpy , el método de escritura anterior causará el problema de la copia superficial. Si el tipo de datos almacenado en el vector no es un tipo incorporado, el compilador informará un error. Para resolver este problema , deberíamos escribirlo en forma de deep copy:
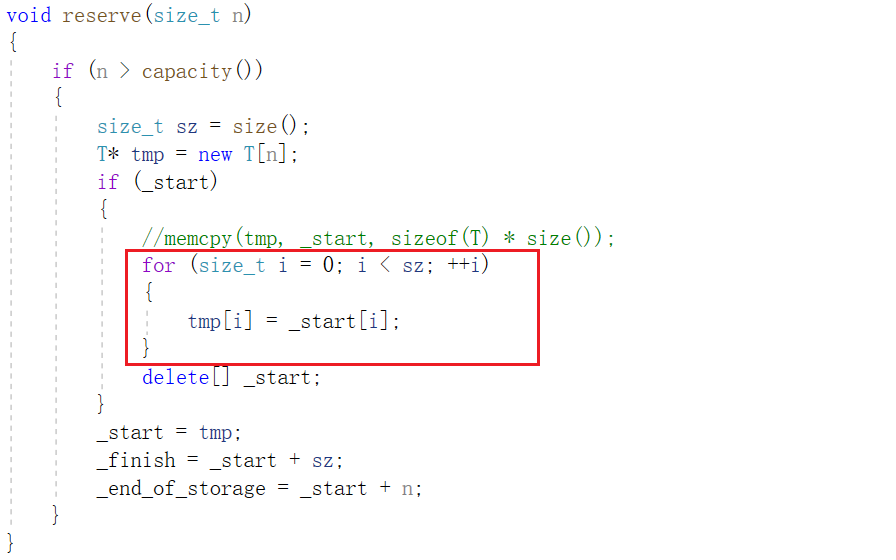
6, retroceso

7, pop_back

8, cambiar el tamaño
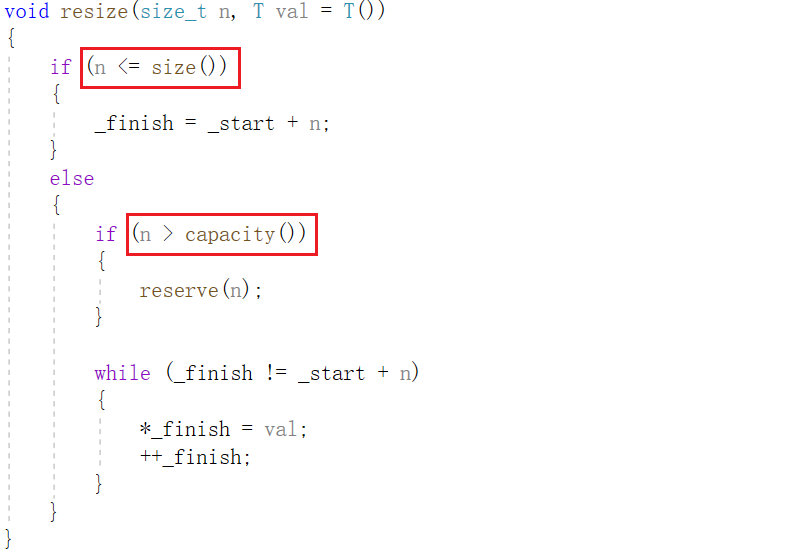
9. invalidación del iterador
La función principal del iterador es permitir que el algoritmo no se preocupe por la estructura de datos subyacente. La estructura de datos subyacente es en realidad un puntero, o un puntero está encapsulado. Por ejemplo, el iterador de vector es el puntero ecológico original T*. Por lo tanto, la invalidación del iterador en realidad significa que el espacio al que apunta el puntero correspondiente en la parte inferior del iterador se destruye y se usa una parte del espacio que se ha liberado, lo que provoca un bloqueo del programa (es decir, si continúa usando el iterador inválido, el programa puede bloquearse).
Las operaciones que provocan cambios en el espacio subyacente pueden hacer que el iterador falle , como: redimensionar, reservar, insertar, asignar, retroceder, etc.
En algunos casos, los iteradores serán invalidados. La falla más clásica del iterador es causada por el problema del puntero salvaje causado por la expansión de la capacidad.
Las razones específicas son las siguientes:

Después de la expansión fuera del sitio, _start , _finish , _end_of_storage apuntan a nuevas ubicaciones, pero el iterador pos obtenido la última vez no actualiza la ubicación señalada, lo que hace que pos se convierta en un puntero salvaje.
Además, la operación de eliminación del elemento en la posición especificada también hará que el iterador falle, lo cual se explicará a continuación.
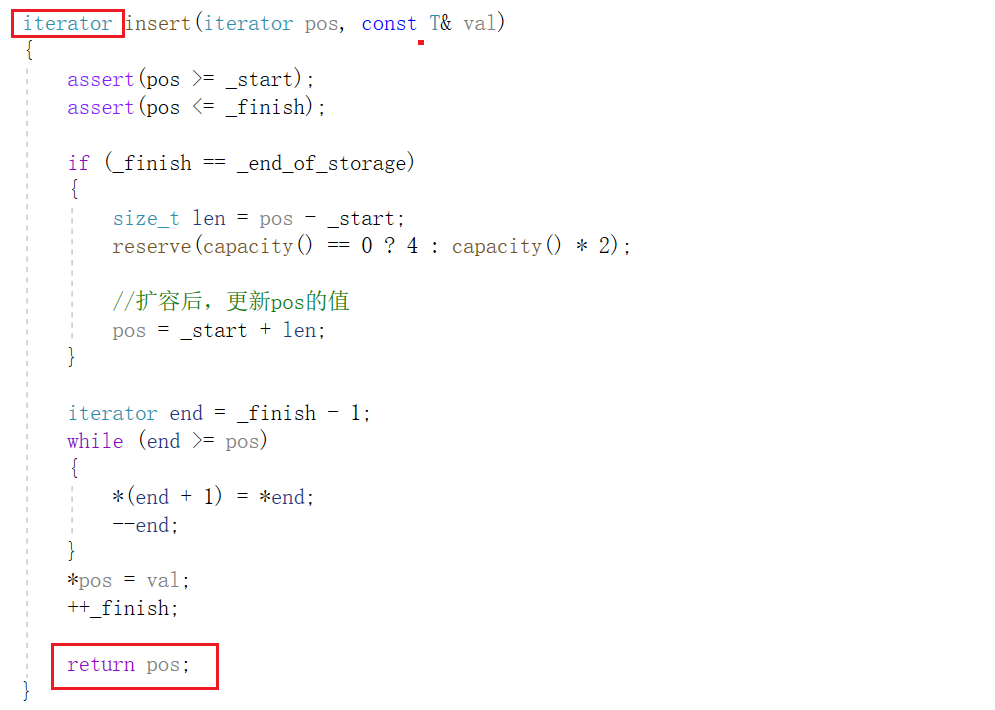
10, insertar
Veamos primero una forma incorrecta de escribir.

El error de esta forma de escribir es que al insertar , también es necesario juzgar si se requiere expansión, con la expansión puede haber un problema de falla del iterador, por lo que es necesario actualizar el apuntamiento de pos :

Conocimiento complementario : el parámetro pos de la función de inserción no se puede pasar por referencia por las siguientes razones:

begin() usa parámetros de paso por valor, todos los parámetros de paso por valor serán pasados por variables temporales, y las variables temporales son constantes y no se pueden cambiar, por lo que si el parámetro pos en la función de inserción usa paso por referencia parámetros, Causará el problema de la amplificación de autoridad, que no está permitida.
La función de inserción del vector en la biblioteca tiene un valor de retorno. Esto se hace para que la posición de pos aún se pueda encontrar después de llamar a la función de inserción :

11, borrar
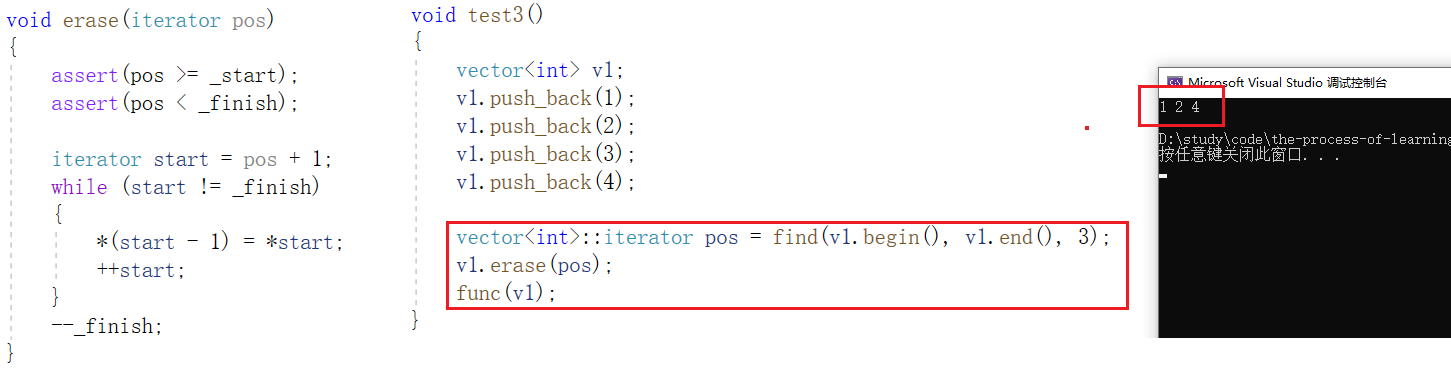
Después de que erase elimina el elemento en la posición pos , los elementos después de la posición pos avanzarán sin causar cambios en el espacio subyacente. En teoría, el iterador no debe invalidarse, pero: si pos resulta ser el último elemento, después de la eliminación, pos pasa a ser la posición final , y la posición final no tiene elementos, entonces pos no será válido. Por lo tanto, al eliminar un elemento en cualquier posición del vector, VS considera que el iterador en esa posición no es válido .
Para resolver el problema de la invalidación del iterador, la función de borrado en la biblioteca tiene un valor de retorno, devolviendo la siguiente posición de los datos eliminados:


12. Constructor
Aquí están los tres constructores:
vector()
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{}
vector(size_t n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n; ++i)
{
push_back(val);
}
}
template <class InputIterator>
vector(InputIterator first, InputIterator last)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
while (first != last)
{
push_back(*first);
++first;
}
}1. Constructor 2
Para el segundo constructor, aquí hay algunas notas:

El parámetro de función utiliza un objeto anónimo como parámetro predeterminado. Hemos dicho antes que el ciclo de vida de los objetos anónimos está solo en esta línea, lo cual no es exhaustivo, el ciclo de declaración de objetos anónimos solo existe en esta línea porque nadie lo usará después. Y en el siguiente escenario, alguien todavía usa el objeto después de esta línea:

El objeto xx es un alias del objeto anónimo, por lo tanto, el ciclo de vida del objeto anónimo se extiende para ser el mismo que xx (porque el objeto anónimo, como la variable temporal, es constante , por lo que debe decorarse con el palabra clave const ).
Este constructor permite la inicialización directa:

Para evitar conflictos con el uso del tercer constructor a continuación, aquí hay otra función con un parámetro de tipo int :

2. Constructor 3

El tercer constructor usa plantillas de funciones para que se puedan usar varios tipos de iteradores:

13. Copiar constructor
Veamos ahora una forma incorrecta de escribir:

Fenómeno de observación:

De hecho, este tipo de construcción de copia no es un problema en el escenario anterior, pero si es el siguiente escenario, aparecerá un error:

Las razones son las siguientes:
- memcpy es una copia de memoria en formato binario, que copia el contenido de un espacio de memoria a otro espacio de memoria intacto
- Si copia un elemento de un tipo personalizado, memcpy es eficiente y no tiene errores, pero si copia un elemento de un tipo personalizado y la administración de recursos está involucrada en el elemento del tipo personalizado, se producirá un error, porque la copia de memcpy es en realidad una copia superficial.
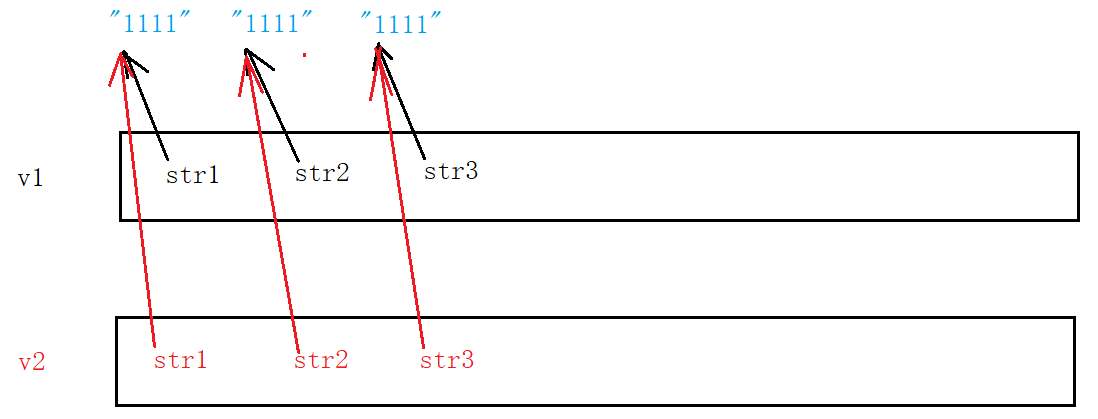
Para resolver este problema, necesitamos implementar una copia profunda:

Para simplificar, también podemos usar la notación moderna para lograr:

Esto es todo sobre el uso de vectores y la implementación subyacente. Espero que me apoyen mucho. Si hay algo mal, corríjanme, ¡gracias!