Tabla de contenido
En segundo lugar, el uso de la lista
3, acceso a elementos de lista
7. El iterador de la lista no es válido
Tres, implementación de simulación de lista
5. insertar y su multiplexación
8.2 Construcción de iteradores
1. Introducción a la lista
- list es un contenedor secuencial que se puede insertar y eliminar en cualquier posición dentro de un rango constante, y el contenedor se puede iterar de un lado a otro.
- La capa inferior de la lista es una estructura de lista doblemente enlazada. Cada elemento de la lista doblemente enlazada se almacena en un nodo independiente que no está relacionado entre sí, y el puntero apunta al elemento anterior y al siguiente elemento del nodo.
- list es muy similar a forward_list: la principal diferencia es que forward_list es una lista enlazada individualmente que solo se puede iterar hacia adelante, lo que la hace más simple y eficiente.
- En comparación con otros contenedores en serie (matriz, vector, deque), la lista generalmente tiene una mejor eficiencia de ejecución para insertar y eliminar elementos en cualquier posición.
- En comparación con otros contenedores secuenciales, el mayor defecto de list y forward_list es que no admite el acceso aleatorio en ninguna posición. Por ejemplo, para acceder al sexto elemento de la lista, debe iterar desde una posición conocida (como la cabeza o tail) a la posición sobre la cual la iteración requiere una sobrecarga de tiempo lineal; la lista también requiere algo de espacio adicional para contener información asociada con cada nodo (esto puede ser un factor importante para listas grandes que almacenan elementos de tipos más pequeños)
En segundo lugar, el uso de la lista
1. La estructura de la lista
| Constructor ( (constructor)) | Descripción de la interfaz |
| lista (tipo_tamaño n, const tipo_valor& val = tipo_valor()) | La lista construida contiene n elementos cuyo valor es val |
| lista() | Construye una lista vacía |
| lista (const lista& x) | copiar constructor |
| lista (InputIterator primero, InputIterator último) | Construye una lista con elementos en el rango [primero, último] |

2, lista de capacidad
| declaración de función | Descripción de la interfaz |
| vacío | Verifique si la lista está vacía, devuelva verdadero, de lo contrario devuelva falso |
| tamaño | Devuelve el número de nodos válidos en la lista |
3, acceso a elementos de lista
| declaración de función | Descripción de la interfaz |
| frente | Devuelve una referencia al valor en el primer nodo de la lista |
| atrás | Devuelve una referencia al valor en el último nodo de la lista |
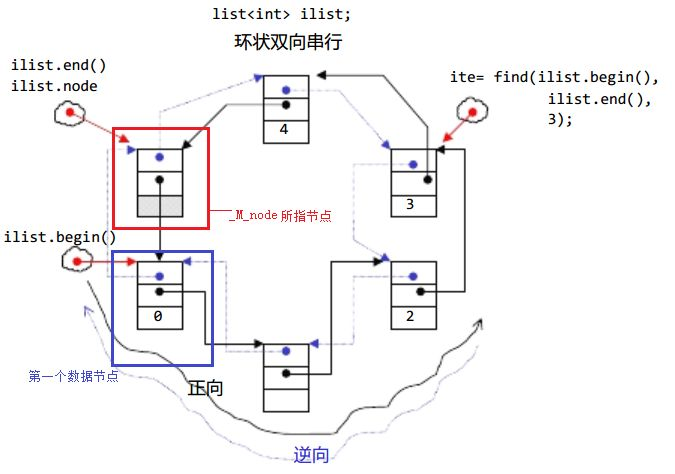
4 iterador de lista
Aquí, puede interpretar temporalmente el iterador como un puntero, que apunta a un determinado nodo en la lista.
| declaración de función | Descripción de la interfaz |
| empezar + terminar |
Devuelve un iterador al primer elemento + devuelve un iterador a la siguiente posición del último elemento |
| rcomenzar + desgarrar |
Devuelve el iterador inverso del primer elemento, que es la posición final, y devuelve el iterador inverso de la siguiente posición del último elemento , que es la posición inicial |
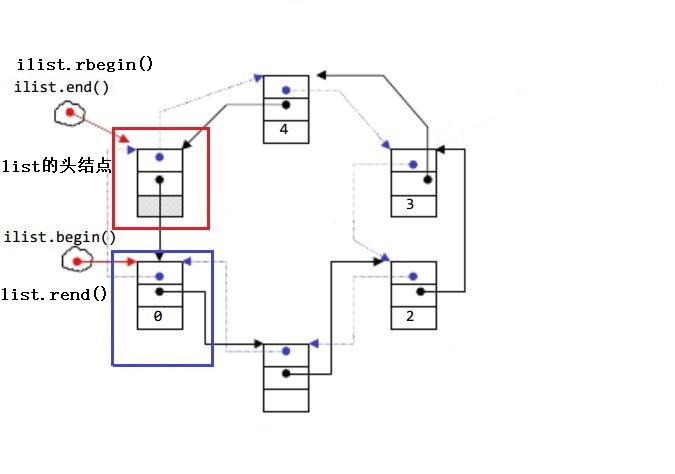
Aviso:
- begin y end son iteradores hacia adelante, realizan operaciones ++ en el iterador y el iterador se mueve hacia atrás
- rbegin(end) y rend(begin) son iteradores inversos, realizan operaciones ++ en el iterador y el iterador avanza
5, modificadores de lista
| declaración de función | Descripción de la interfaz |
| empujar_frente | Insertar un elemento con valor val antes del primer elemento de la lista |
| pop_front | eliminar el primer elemento de la lista |
| hacer retroceder | Inserte un elemento con valor val al final de la lista |
| pop_back | eliminar el último elemento de la lista |
| insertar | Insertar un elemento con valor val en la posición de la lista |
| borrar | Eliminar el elemento en la posición de la lista |
| intercambio | Intercambiar los elementos de dos listas |
| claro | Borrar los elementos válidos de la lista |
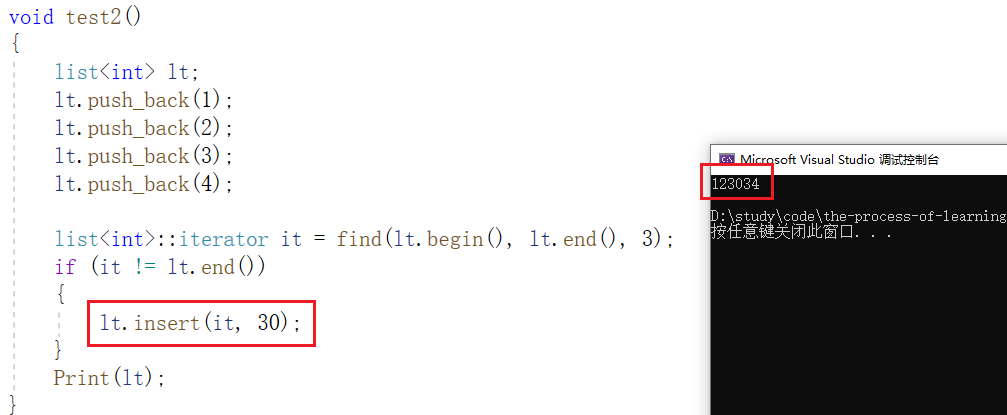
5.1, insertar
El método de uso es el siguiente:
6, operaciones de lista
| declaración de función |
Descripción de la interfaz |
| empalme | transferir elementos de una lista a otra |
| eliminar | eliminar elementos con un valor específico |
| único | eliminar duplicados |
| unir | Fusionar lista de clasificación |
| clasificar | Ordenar los elementos en el contenedor. |
| contrarrestar | invertir el orden de los elementos |
6.1, ordenar
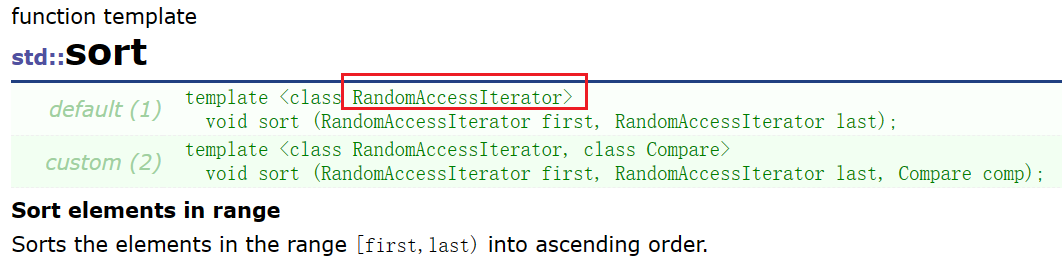
List no puede usar la función de clasificación en la biblioteca de algoritmos, porque la implementación subyacente de la función de clasificación en la biblioteca de algoritmos se muestra en la siguiente figura:

Aquí se utiliza la operación de resta y las direcciones de cada nodo de la lista son discontinuas, por lo que se produce un error. Además, la capa inferior de la función de ordenación en la biblioteca de algoritmos se implementa mediante ordenación rápida, y la ordenación rápida tiene un componente importante: el medio de tres números, que no se aplica a las listas.
La descripción de la función de clasificación en el documento también implica que se debe pasar un iterador aleatorio al usar la función de clasificación en la biblioteca de algoritmos :
El uso de clasificación en la lista es el siguiente:
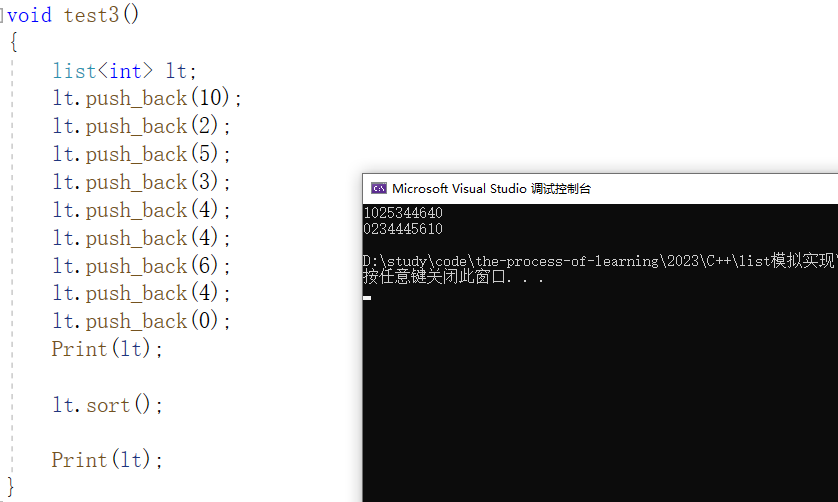
No hay problema con la función, pero rara vez usamos la función de clasificación de la lista porque su eficiencia es muy baja.
Usamos el siguiente código para demostrarlo:
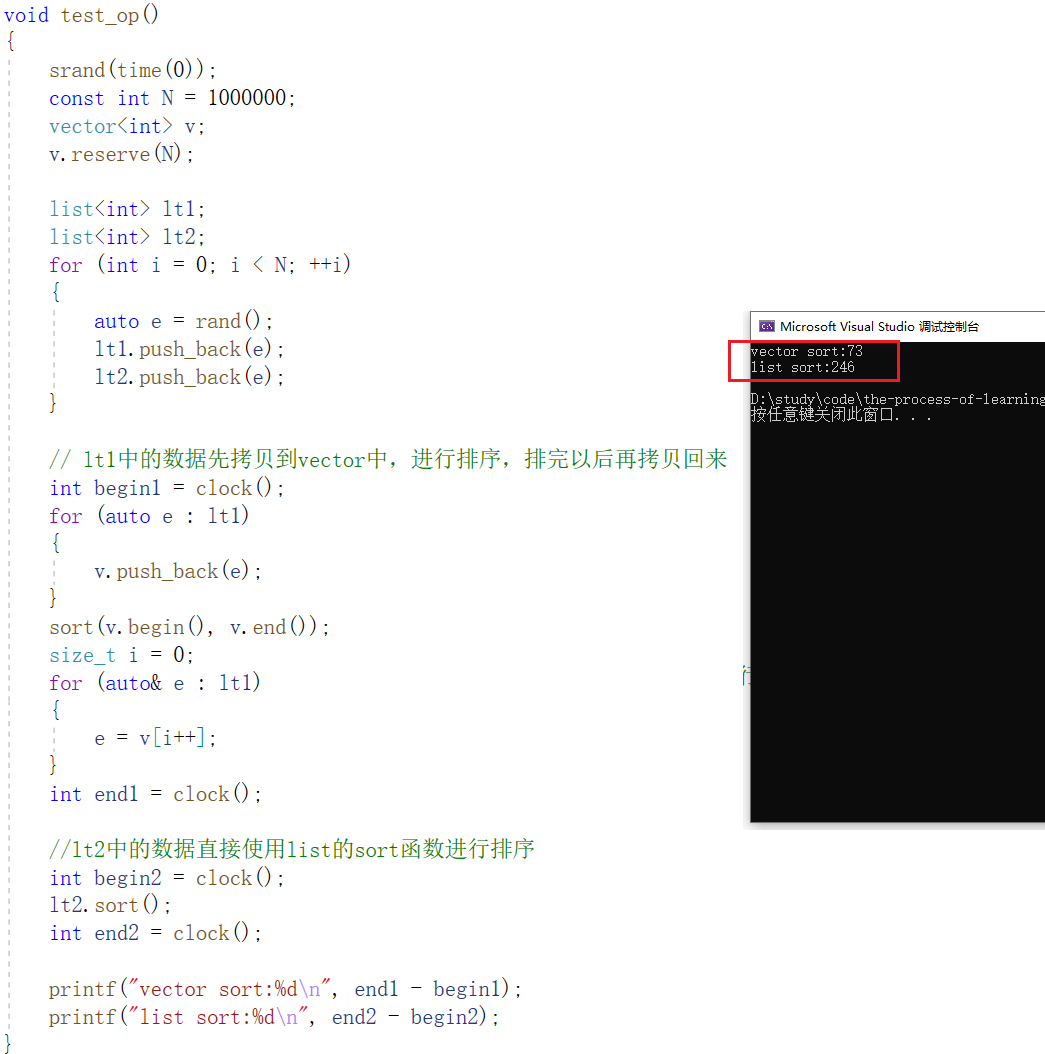
Se puede ver que copiar los mismos datos en el vector para ordenarlos primero y luego volver a copiarlos después de ordenarlos es más rápido que usar la ordenación de listas directamente.
7. El iterador de la lista no es válido
Como se mencionó anteriormente, aquí puede entender temporalmente que el iterador es similar a un puntero. La invalidación del iterador significa que el nodo al que apunta el iterador no es válido, es decir, el nodo se elimina. Debido a que la estructura subyacente de la lista es una lista enlazada circular bidireccional con el nodo principal, el iterador de la lista no se invalidará cuando se inserte en la lista. Solo se invalidará cuando se elimine, y solo el se invalidará la iteración que apunte al nodo eliminado, los otros iteradores no se verán afectados .
Tres, implementación de simulación de lista
Primero construyamos un marco básico para una lista:
namespace bin
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
list_node(const T& x = T())
:_next(nullptr)
,_prev(nullptr)
,_data(x)
{}
};
template<class T>
class list
{
typedef list_node<T> node;
public:
list()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
private:
node* _head;
};
}
需要注意:在 list 类中定义私有成员变量时,一定要注意成员变量类型为类名 + 模板参数。
1、push_back
void push_back(const T& x)
{
node* tail = _head->_prev;
node* new_node = new node(x);
tail->_next = new_node;
new_node->_prev = tail;
new_node->_next = _head;
_head->_prev = new_node;
}
具体底层逻辑可以参照文章《双向链表》 。
2、iterator
list的底层物理空间是不连续的,所以模拟实现迭代器时,就不能直接让指针 "++" 或 "--" 了,而应该实现迭代器 "++" 或 "--" 的重载:
template<class T>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T> self;
node* _node;
__list_iterator(node* n)
:_node(n)
{}
T& operator*()
{
return _node->_data;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
};
因为我们模拟实现的list类中的迭代器是使用原生指针实现的,且原生指针的类型为 _node* ,没办法直接实现,所以又定义了一个 __list_iterator 类进行封装。
实验运行结果正确:
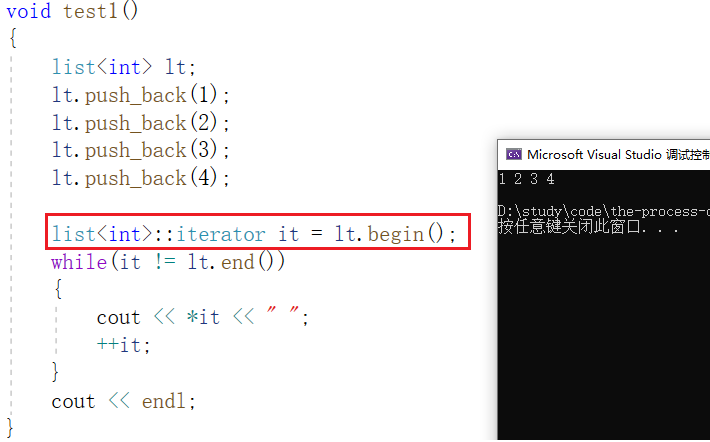
红框框起的部分调用了一次拷贝构造,由于我们没有自己实现拷贝构造函数,所以这里是一次浅拷贝,而我们想要的就是浅拷贝。
这里浅拷贝之所以没有报错,是因为我们封装的迭代器类中没有实现析构函数,因为迭代器仅仅是使用list对象节点,而不是拥有list对象节点,它没有权利释放list的对象。
我们再来完善一下迭代器的其他功能:
template<class T>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T> self;
node* _node;
__list_iterator(node* n)
:_node(n)
{}
T& operator*()
{
return _node->_data;
}
self& operator++()
{
_node = _node->_next;
return *this;
}
self& operator++(int)
{
self tmp(*this);
_node = _node->_next;
return tmp;
}
self& operator--()
{
_node = _node->_prev;
return *this;
}
self& operator--(int)
{
self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const self& s)
{
return _node != s._node;
}
};3、const iterator
先来看一下错误的写法:
直接在list类中定义 const 类型的成员函数。这种写法的错误之处在于,这些 const 类型成员函数所针对的是list类中的成员变量 _head ,虽然 _head 被 const 限制无法更改,但是 _head 所指向的 _data 仍然可以更改,即数据仍然可以被更改,不符合我们的预期。
我们较为容易想到的写法是直接再另外定义一个类,在这个新类中封装 const 类型的迭代器:
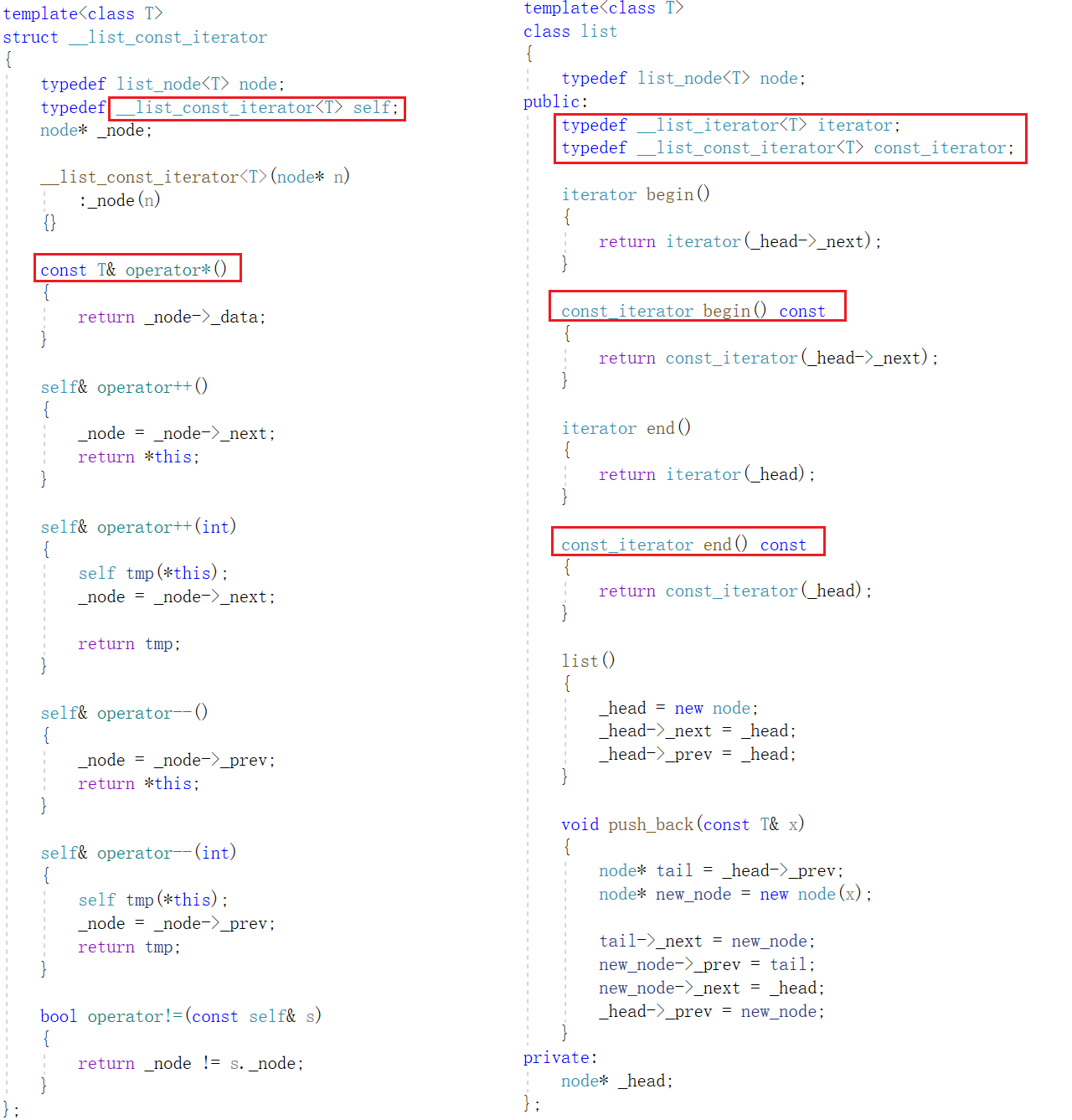
虽然这种写法可以实现功能且完全满足需求,但是代码太过于冗余,接下来我们来学习一种新的写法:
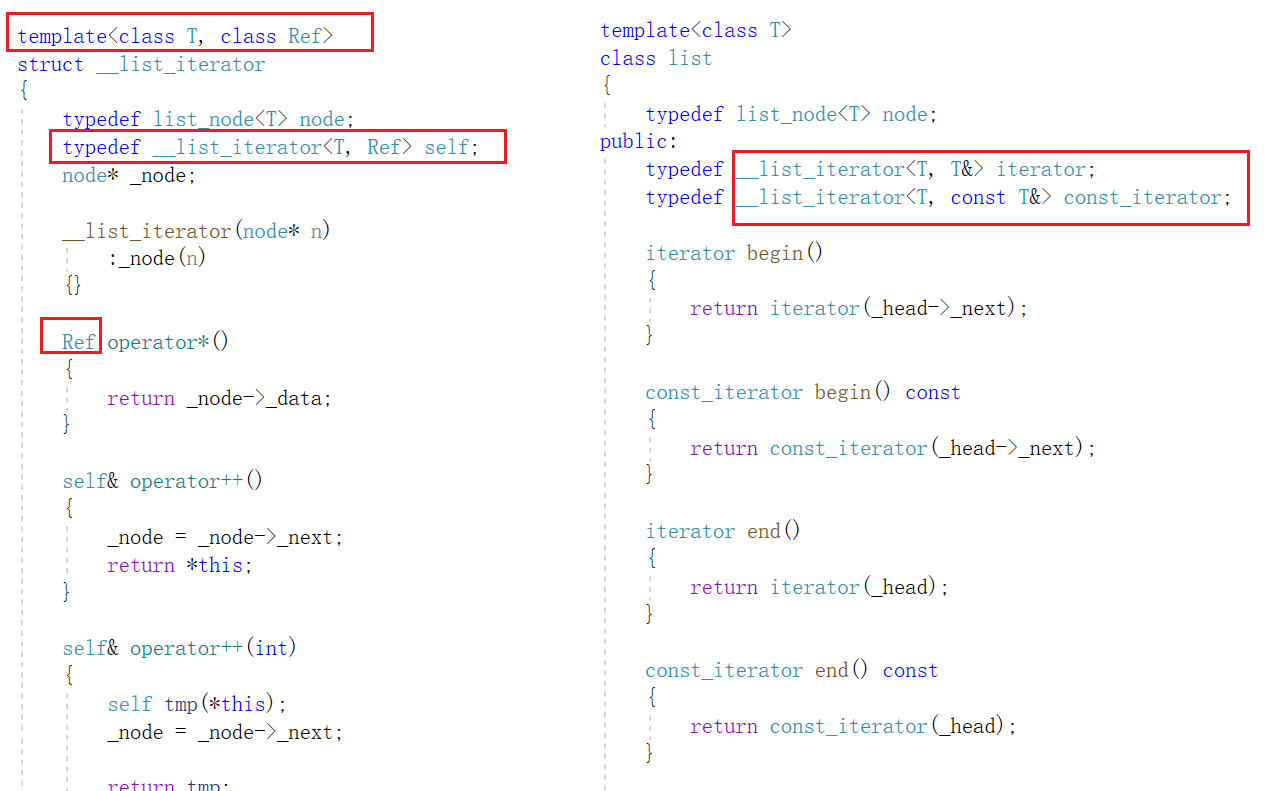
在迭代器模板中多增加了一个模板参数 Ref ,用于满足不同的调用需求。
4、Ptr
观察如下代码:

编译器报错,因为我们没有为自定义类型 AA 实现流插入重载,所以需要写成这种形式:

但是我们在写 C++ 代码时,一般没有写成这种形式的习惯,大多数都是通过 "->" 来实现解引用操作的,所以我们可以改变写法:

这种写法乍一看非常难以理解,这时因为为了增强可读性的缘故,在这里少写了一个 "->" :

大家看一下完整版的写法就一定能够理解:

同理,为了满足不同的调用需求,应该为list类重载一个 const 类型的成员函数,为了不造成代码冗余,同样只需要为list类模板增加一个模板参数就可以了:

5、insert 及其复用
具体实现如下:

list的 insert 不会导致迭代器失效。
可以使用 insert 函数的复用来实现 push_back 与 push_front :

6、erase 及其复用
具体实现如下:

list的 erase 会导致迭代器失效。
为了在使用 erase 函数后仍然可以找到该节点的下一个节点,我们使用返回值来返回需要的信息:

可以使用 erase 函数的复用来实现 pop_back 与 pop_front :

7、clear
具体实现方法如下:

也可以使用下面这种写法:

8、构造函数
8.1、默认构造
void empty_init()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
list()
{
empty_init();
}8.2、迭代器构造
void empty_init()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
template <class Iterator>
list(Iterator first, Iterator last)
{
empty_init();
while (first != last)
{
push_back(*first);
++first;
}
}扩展内容:
const 类型的对象是无法调用 empty_init() 函数的,因为这属于权限放大。那么为什么我们写如下 const 类型对象的实例化不会报错呢?

这是因为该 const 对象在定义的时候并没有 const 属性,在该对象定义完成后,才被赋予了 const 属性,否则就没有办法对对象进行初始化操作了。
9、拷贝构造函数
传统写法如下:
void empty_init()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
list(const list<T>& lt)
{
empty_init();
for ( auto e : lt)
{
push_back(e);
}
}这里再提供一份现代写法:
void swap(list<T>& tmp)
{
std::swap(_head, tmp._head);
}
list(const list<T>& lt)
{
empty_init();
list<T> tmp(lt.begin(), lt.end());
swap(tmp);
}10、析构函数
实现代码如下:
~list()
{
clear();
delete _head;
_head = nullptr;
}11、operator=
实现代码如下:
void swap(list<T>& tmp)
{
std::swap(_head, tmp._head);
}
list<T>& operator=(list<T> lt)
{
swap(lt);
return *this;
}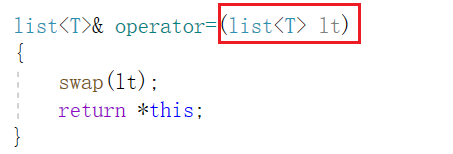
注意:这里的传参没有使用传引用传参,而是采用了传值传参。这是因为我们本来就期望在传参时发生一次拷贝构造,并把拷贝构造出的临时变量与 this 进行交换,这样不会影响到赋值运算符重载的右值本身。
关于list的使用和模拟实现的相关内容就讲到这里,欢迎同学们多多支持,如果有不对的地方欢迎大佬指正,谢谢!