En los últimos meses, los círculos de Internet y tecnología casi se han deslizado por la pantalla de ChatGPT, y también hay varias publicaciones sobre el concepto y la aplicación de ChatGPT. Cuando se lanzó ChatGPT a fines del año pasado, ChatGPT realmente sorprendió a todos. Resulta que la IA todavía puede jugar así, y es aún más insincero para las llamadas compañías de inteligencia artificial en China.
El 9 de marzo, el CTO de Microsoft Alemania, Andreas Braun (Braun), dijo en un evento de IA que GPT4 se lanzará la próxima semana y es un modelo multimodal, que no se limita a texto, sino también a video. Entonces, ¿en qué se diferencia GPT4, en qué se diferencia de la versión anterior de GPT3, el ChatGPT que usamos en enero? Son temas que nos interesan más.
De hecho, GPT3 (Transformador Generativo Preentrenado 3) y GPT4 (Transformador Generativo Preentrenado 4) son los modelos preentrenados más avanzados en Procesamiento del Lenguaje Natural (PNL). Cuando OpenAI lanzó por primera vez GPT3, tenía 17.500 millones de parámetros, uno de los modelos de lenguaje más grandes en la historia de la inteligencia artificial en ese momento.
Este récord no duró mucho y pronto OpenAI lanzó GPT3.5. Este es un modelo de transición entre GPT3 y GPT4, que tiene 175 mil millones de parámetros de aprendizaje automático, 10 veces más que los 17,5 mil millones de parámetros de GPT3. GPT4 es el modelo de lenguaje de próxima generación que lanzará OpenAI. Se prevé que tendrá más de 10 billones de parámetros, que es 57 veces más que GPT3.5.

Entonces, ¿qué tan poderoso es GPT 4? En las primeras horas de esta mañana, se lanzó oficialmente el tan esperado modelo multimodal a gran escala GPT 4.

Al mismo tiempo, OpenAI emitió un documento que dice que GPT-4 puede aceptar imágenes y texto de entrada y salida de contenido de texto. Aunque su capacidad no es tan buena como la de los humanos en muchos escenarios del mundo real, ha logrado un rendimiento a nivel humano. en varias pruebas de referencia académicas y profesionales. ¿Qué tan poderoso es? Ingrese un boceto dibujado a mano y GPT-4 puede generar directamente el código de la página web del diseño final.
Al mismo tiempo, en varias pruebas estandarizadas, GPT-4 obtuvo 700 puntos en el SAT, casi la máxima puntuación en el GRE, y su habilidad lógica superó a GPT-3.5.
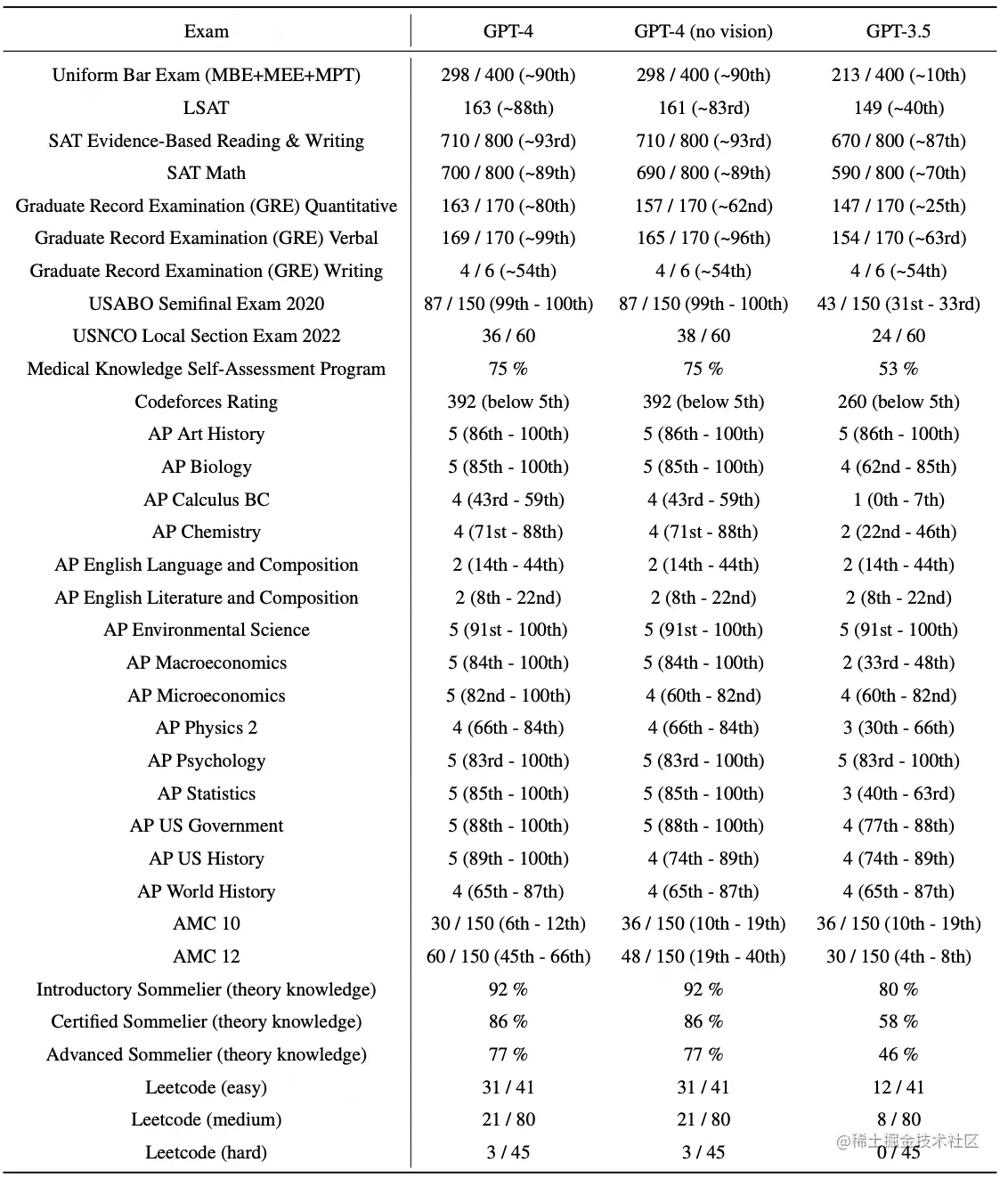
GPT-4 supera a ChatGPT en capacidad de razonamiento avanzado. En el examen simulado de abogado, GPT-3.5 detrás de ChatGPT se ubica en el 10% inferior, mientras que GPT-4 se ubica en el 10% superior.
El límite de longitud de GPT-4 se incrementa a 32 000 tokens, lo que significa que puede procesar textos de más de 25 000 palabras y puede usar creación de contenido de formato largo, diálogo extendido, búsqueda y análisis de documentos, etc.
OpenAI está lanzando la función de entrada de texto de GPT-4 a través de ChatGPT y API, pero la función de entrada de imágenes aún no está disponible. Los suscriptores de ChatGPT plus pueden obtener directamente el derecho de prueba de GPT-4 con un límite superior y solo pueden publicar un máximo de 100 mensajes en 4 horas. Los desarrolladores también pueden solicitar la API GPT-4 e ingresar a la lista de espera para su aprobación. Enlace de la aplicación: https://openai.com/waitlist/gpt-4-api
Con el tiempo, OpenAI lo actualizará automáticamente al modelo estable recomendado (puede bloquear la versión actual llamando a gpt-4-0314, que OpenAI admitirá hasta el 14 de junio). El precio es de $0.03 por 1k tokens de solicitud y $0.06 por 1k tokens de finalización. El límite de tasa predeterminado es 40k tokens por minuto y 200 solicitudes por minuto.
La longitud del contexto de GPT-4 es de 8192 tokens. También brinda acceso limitado a 32768 contextos (alrededor de 50 páginas de texto) versión gpt-4-32k, que también se actualizará automáticamente con el tiempo (la versión actual gpt-4-32k-0314 también será compatible hasta el 14 de junio). El precio es de $0,06 por 1k tokens de solicitud y $0,12 por 1K tokens de finalización.
Además, OpenAI también tiene OpenAI Evals de código abierto, un marco para evaluar automáticamente el rendimiento de los modelos de IA, de modo que los desarrolladores puedan evaluar mejor las fortalezas y debilidades del modelo, guiando así al equipo para mejorar aún más el modelo.
Dirección de código abierto: github.com/openai/evals
Entonces, ¿qué funciones impactantes trae GPT-4? Repasémoslas una por una a continuación.
GPT-4 se actualizó a "Kaoba", y el rendimiento de referencia fue mucho mejor que el modelo grande existente
Si está chateando casualmente, es posible que no pueda sentir la diferencia entre GPT-3.5 y GPT-4. Pero cuando la complejidad de la tarea alcanza un umbral suficiente, GPT-4 será significativamente más confiable, más creativo y capaz de manejar instrucciones más detalladas que GPT-3.5.
Para ver la diferencia entre los dos modelos, OpenAI lo probó en varios puntos de referencia, incluidos los exámenes simulados diseñados originalmente para humanos. Utilizaron las últimas preguntas del examen público (en el caso de las preguntas de respuesta libre de Olympiad y AP) o compraron preguntas del examen de práctica de la edición 2022-2023.
OpenAI no recibió capacitación específica para estos exámenes. Durante el entrenamiento del modelo, se encontraron una pequeña cantidad de problemas en el examen. Sin embargo, OpenAI cree que los resultados son representativos. Para obtener más información, consulte el documento GPT-4 ( https://cdn.openai.com/papers/gpt-4.pdf ).
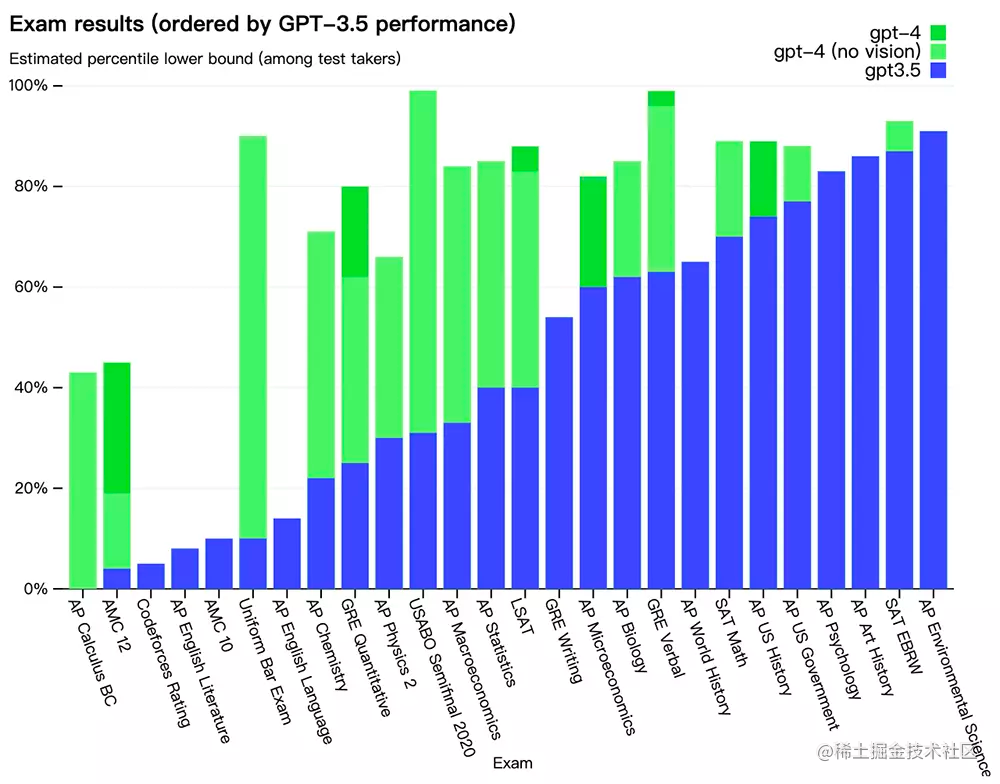
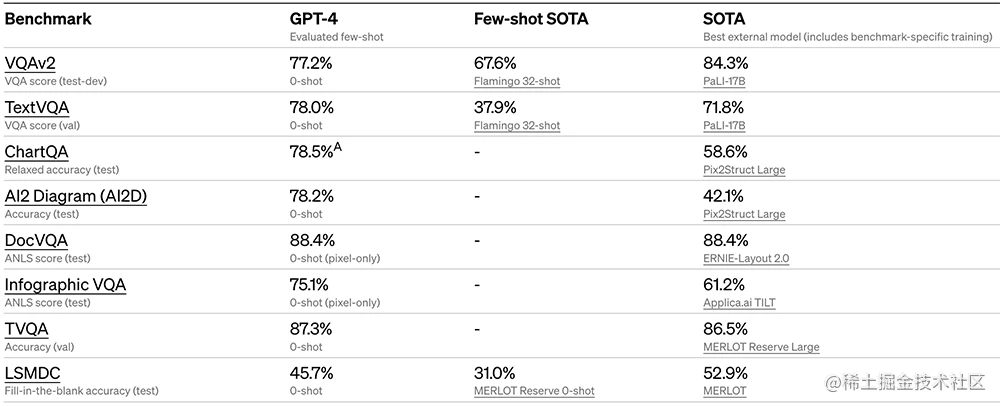
OpenAI también evaluó GPT-4 en puntos de referencia tradicionales diseñados para modelos de aprendizaje automático. GPT-4 supera sustancialmente a los modelos de lenguaje grande existentes, así como a la mayoría de los modelos de última generación (SOTA), que pueden incluir la fabricación específica de referencia o protocolos de capacitación adicionales:
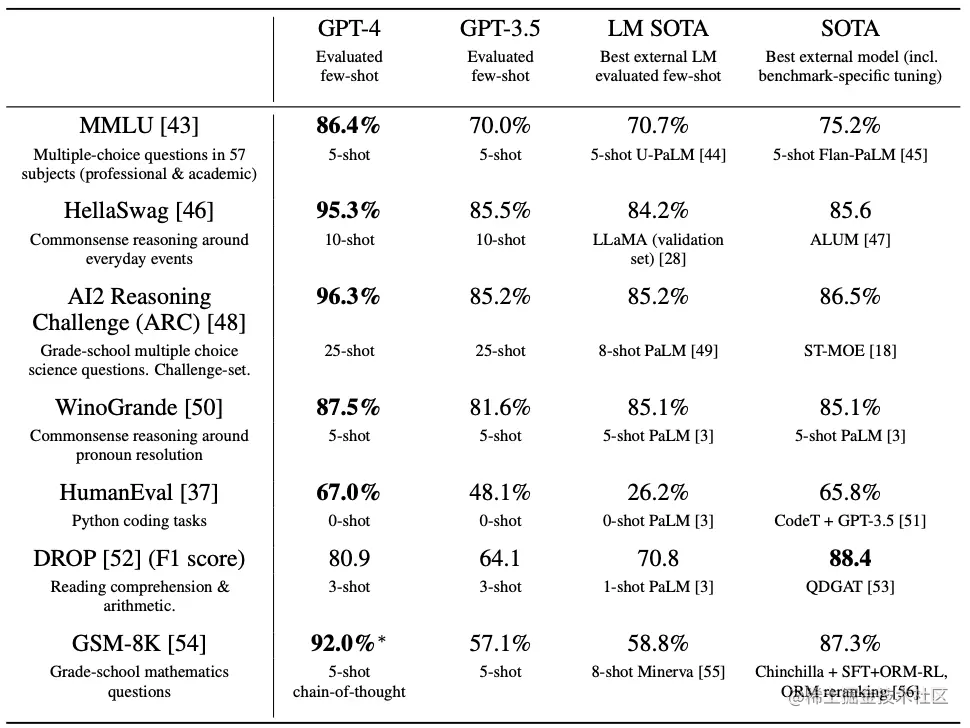
Muchos puntos de referencia de aprendizaje automático (ML) existentes están escritos en inglés. Para obtener un primer vistazo a su rendimiento en otros idiomas, OpenAI usó Azure Translate para traducir el punto de referencia de MMLU (un conjunto de 14 000 preguntas de opción múltiple que cubren 57 temas) a varios idiomas.
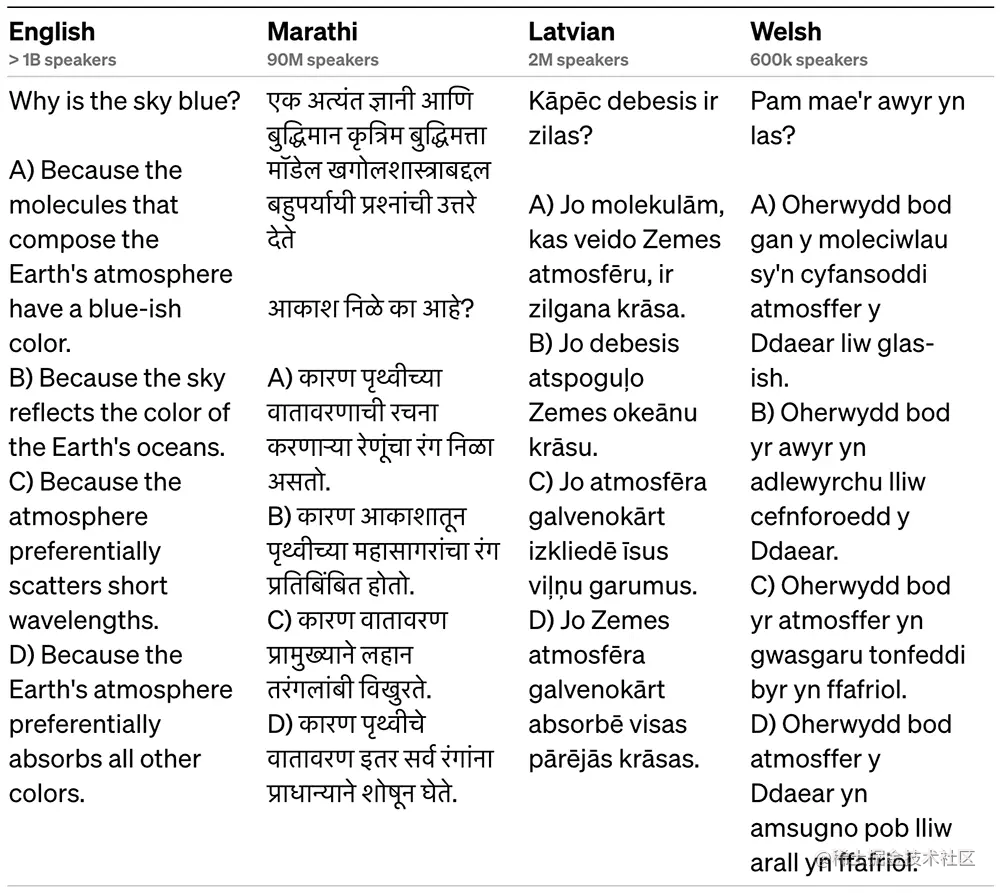
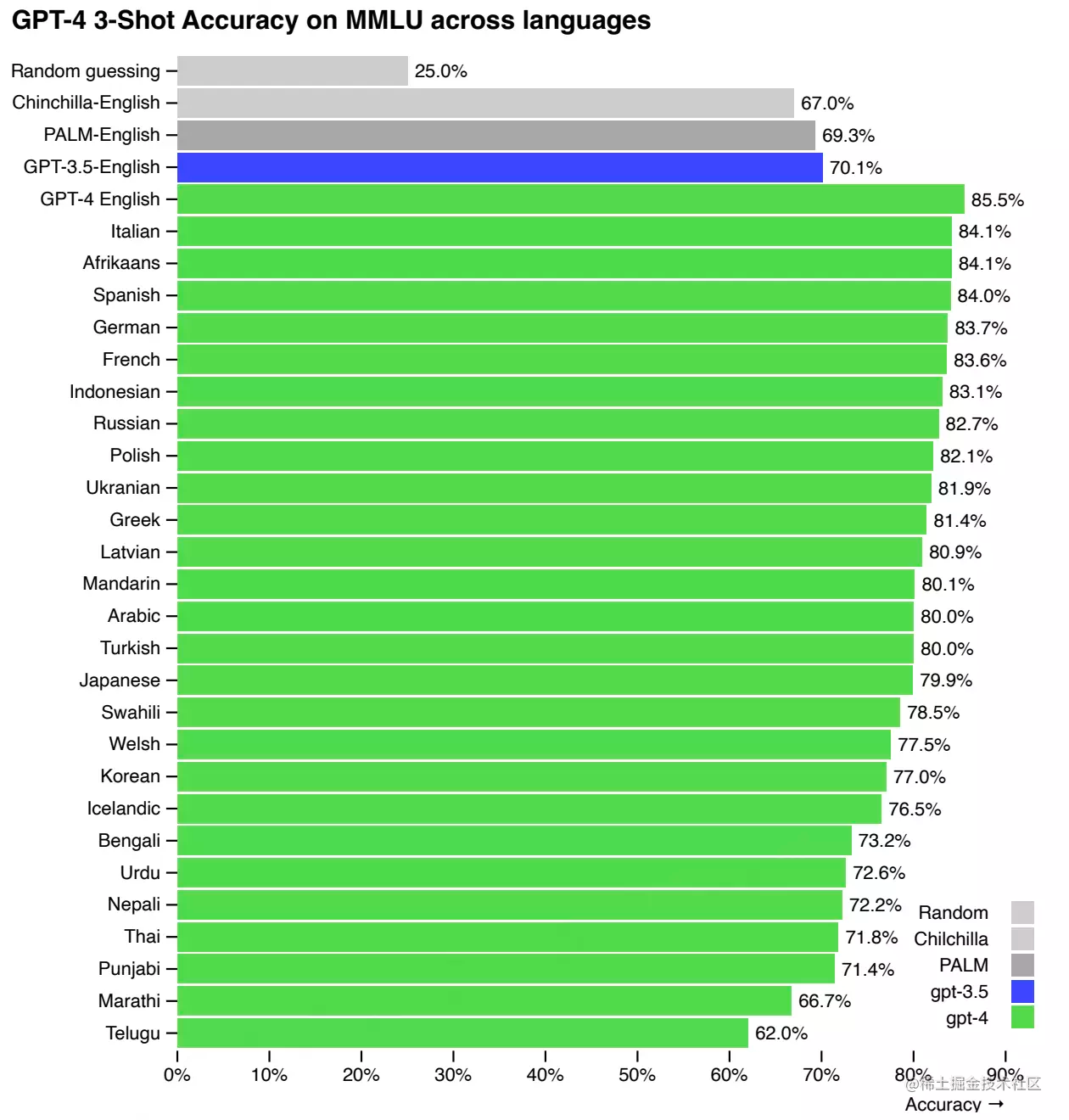
En 24 de los 26 idiomas probados, GPT-4 supera a GPT-3.5 y otros modelos de idiomas grandes (Chinchilla, PaLM) en inglés, incluido el idioma letón, galés, swahili, etc.
OpenAI también usa GPT-4 internamente, lo que tiene un gran impacto en funciones como soporte, ventas, moderación de contenido y programación. OpenAI también lo está utilizando para ayudar a los humanos a evaluar el resultado de la IA, comenzando la segunda fase de su estrategia de alineación.
Describir fotografías, comprender diagramas y responder ensayos
GPT-4 puede aceptar señales de texto e imágenes, que son paralelas a la configuración de solo texto, lo que permite a los usuarios especificar cualquier tarea visual o de lenguaje. Específicamente, dada una entrada que consiste en texto e imágenes intercaladas, es capaz de generar una salida textual en lenguaje natural, código, etc. En términos de generación de documentos, diagramas o capturas de pantalla con texto y fotos, GPT-4 demuestra capacidades similares a la entrada de texto sin formato.
Además, GPT-4 se puede mejorar utilizando técnicas de tiempo de prueba desarrolladas para modelos de lenguaje de texto sin formato, incluidas sugerencias de pocas tomas y de cadena de pensamiento. La entrada de imagen aún se encuentra en la vista previa de investigación y aún no es pública.
OpenAI muestra 7 ejemplos de entrada visual en el sitio web oficial.
1. Describa el contenido de varias imágenes y descubra lo que no es razonable
Ingrese una imagen compuesta por tres imágenes, y el usuario ingresa "¿qué tiene de extraño esta imagen? Descríbala una por una", y GPT-4 describirá el contenido de cada imagen por separado y señalará que conectar un puerto VGA grande y obsoleto en un pequeño y moderno puerto de carga para teléfonos inteligentes es ridículo.

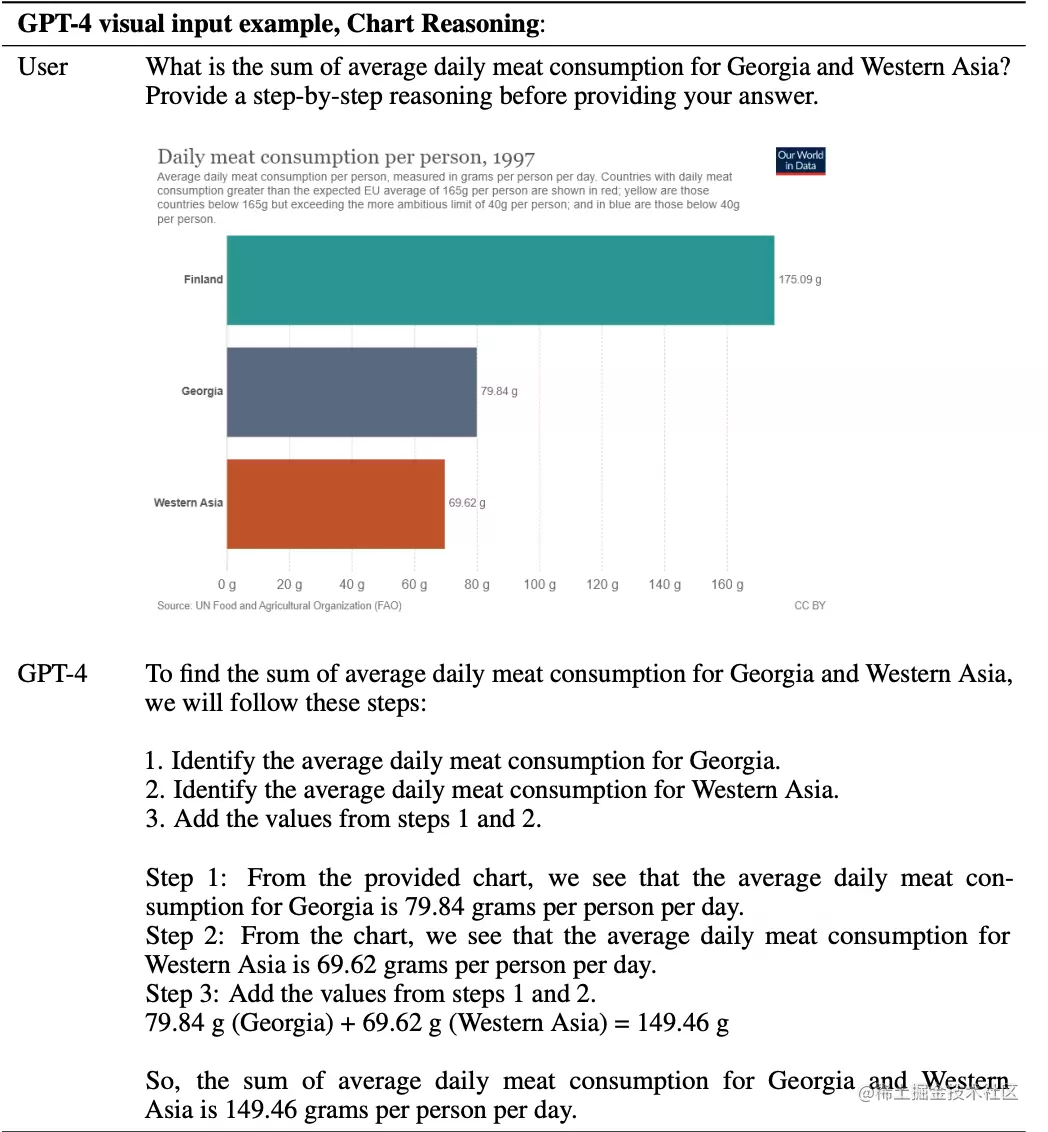
2. Responde según el gráfico y el razonamiento
El usuario pregunta la suma del consumo medio diario de carne en Georgia y Asia occidental, de modo que GPT-4 puede proporcionar un razonamiento paso a paso antes de dar la respuesta, y GPT-4 también puede responder a pedido.
3. Prueba de lectura de imágenes
Los usuarios también pueden dar directamente una foto de una pregunta de prueba y dejar que GPT-4 piense y responda paso a paso.

4. Señale de manera concisa la violación de la imagen.
Cuando un usuario preguntó: "¿Qué tiene de inusual esta imagen?", GPT-4 respondió sucintamente: "Un hombre está planchando ropa en una tabla de planchar en el techo de un taxi en movimiento".

5. Lea el artículo, resuma el resumen e interprete los gráficos
Dadas algunas fotos de documentos, GPT-4 puede hacer un resumen y también puede explicar el contenido de las imágenes especificadas por el usuario.

6. Interpretación del "mapa de nuggets de pollo"
Pídele a GPT-4 que explique el meme de la imagen y GPT-4 responde que es una broma que combina dos cosas no relacionadas, una foto de la Tierra en el espacio y un nugget de pollo.

7. Comprender el significado de los cómics
El último ejemplo es pedirle a GPT-4 que interprete esta caricatura, que GPT-4 cree que satiriza la diferencia entre el aprendizaje estadístico y las redes neuronales para mejorar el rendimiento del modelo.

OpenAI ofrece una vista previa de esto al evaluar el desempeño de GPT-4 en un conjunto limitado de puntos de referencia de visión académica estándar. Pero esos números no representan exactamente sus capacidades, ya que OpenAI descubre constantemente tareas nuevas y emocionantes que el modelo puede manejar. OpenAI planea publicar pronto más números de análisis y evaluación, así como una investigación exhaustiva del impacto técnico en el momento de la prueba.
Además, OpenAI ha estado trabajando en aspectos del plan descrito en su artículo sobre la definición del comportamiento de la IA, incluida la manipulabilidad. A diferencia de ChatGPT, que tiene verbosidad, entonación y estilo fijos, los desarrolladores (y pronto los usuarios de ChatGPT) ahora pueden dictar el estilo y las tareas de su IA describiendo estas instrucciones en los mensajes del "sistema".
Los mensajes del sistema (mensajes del sistema) permiten a los usuarios de la API personalizar la experiencia del usuario hasta cierto punto. OpenAI continuará realizando mejoras en esta área (especialmente sabiendo que los mensajes del sistema son la forma más fácil de "liberar" el modelo actual, es decir, el cumplimiento de los límites no es perfecto), pero OpenAI alienta a los usuarios a probarlo y hacerles saber lo que saben. pensar.
En cuanto a la manipulabilidad, OpenAI muestra 3 ejemplos.
1, ejemplo 1
El ejemplo 1 es hacer que GPT-4 actúe como un tutor que siempre responde en un estilo socrático, sin darle directamente al estudiante la respuesta a un determinado sistema de ecuaciones lineales, sino guiando al estudiante dividiendo ese problema en partes más simples Aprenda a pensar de forma independiente .

2, ejemplo 2
El ejemplo 2 es convertir a GPT-4 en un "pirata de Shakespeare" y ser fiel a su propia personalidad. Se puede ver que mantiene su propia "personalidad" durante múltiples rondas de diálogo.

3, ejemplo 3
El ejemplo 3 es hacer que GPT-4 sea un asistente de IA, siempre escriba la salida de respuesta en json, y luego el estilo de la respuesta de GPT-4 se vuelve así:

El más real, el más estable y el más controlable
OpenAI dijo que su equipo pasó 6 meses usando el programa de pruebas contradictorias y las lecciones aprendidas de ChatGPT para ajustar iterativamente GPT-4 y logró los mejores resultados en términos de autenticidad y capacidad de control (todavía lejos de ser perfecto).
En los últimos dos años, OpenAI ha reconstruido toda su pila de aprendizaje profundo y ha codiseñado una supercomputadora desde cero para su carga de trabajo con la plataforma en la nube Azure de Microsoft.
Hace un año, OpenAI entrenó GPT-3.5 como la primera "ejecución de prueba" del sistema, encontrando y corrigiendo algunos errores y mejorando su base teórica. Como resultado, la ejecución de entrenamiento de GPT-4 fue (al menos para OpenAI) estable sin precedentes, convirtiéndose en el primer modelo grande para el que OpenAI pudo predecir con precisión su rendimiento de entrenamiento por adelantado.
A medida que continúa enfocándose en escalamiento confiable, OpenAI tiene como objetivo refinar sus métodos para ayudarlo a predecir y prepararse cada vez más para el futuro con anticipación. OpenAI considera que esto es fundamental para la seguridad.
Al igual que los modelos GPT anteriores, el modelo base GPT-4 está capacitado para predecir la siguiente palabra en un documento, y se entrenó utilizando datos disponibles públicamente, como datos de Internet, así como datos con licencia de OpenAI. Estos datos son corpus de datos a escala web que incluyen soluciones correctas e incorrectas a problemas matemáticos, razonamiento débil y fuerte, declaraciones contradictorias y consistentes, y representan una amplia variedad de ideologías e ideas.
Como resultado, cuando se le solicita una pregunta, el modelo subyacente puede responder en una variedad de formas que pueden estar lejos de la intención del usuario. Para alinearlo con la intención del usuario dentro de las medidas de seguridad, OpenAI utiliza el aprendizaje de refuerzo con retroalimentación humana (RLHF) para ajustar el comportamiento del modelo.
Tenga en cuenta que la capacidad del modelo parece provenir principalmente del proceso de capacitación previa: RLHF no mejora los puntajes de las pruebas (en realidad, disminuye los puntajes de las pruebas si no se trabaja activamente). Pero el control del modelo proviene del proceso posterior al entrenamiento: el modelo base requiere una ingeniería rápida para saber que debe responder a la pregunta.
Limitaciones de GPT-4
Aunque más potente, GPT-4 tiene limitaciones similares a los modelos GPT anteriores. Además de eso, todavía no es del todo confiable (hay "ilusiones" fácticas y errores de razonamiento). Se debe tener cuidado al usar la salida del modelo de lenguaje, especialmente en contextos de alto riesgo, usando el protocolo exacto que satisface las necesidades de un caso de uso específico (por ejemplo, revisión humana, una base para contexto adicional o evitar el uso de alto riesgo por completo).
Aún así, GPT-4 reduce significativamente las alucinaciones en relación con los modelos anteriores (que mejoran con cada iteración). En la evaluación de realismo adversario interno de OpenAI, GPT-4 obtuvo un puntaje 40% más alto que GPT-3.5.
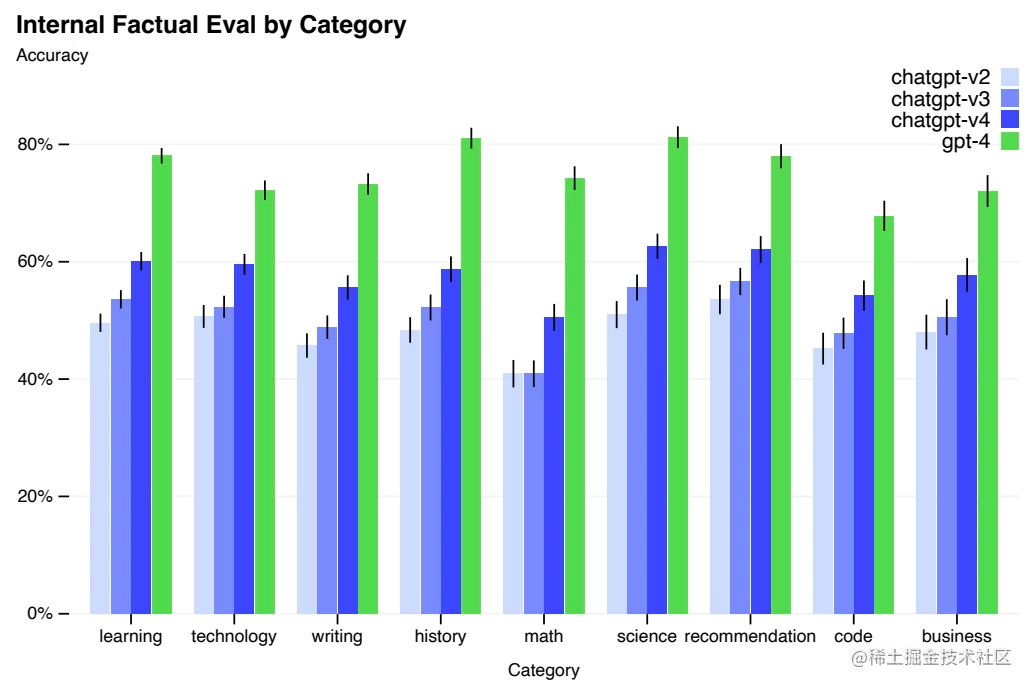
OpenAI ha progresado en puntos de referencia externos como TruthfulQA, que prueba la capacidad de un modelo para separar los hechos de un conjunto de declaraciones erróneas seleccionadas por el adversario. Las preguntas se combinaron con respuestas objetivamente incorrectas que eran estadísticamente atractivas.
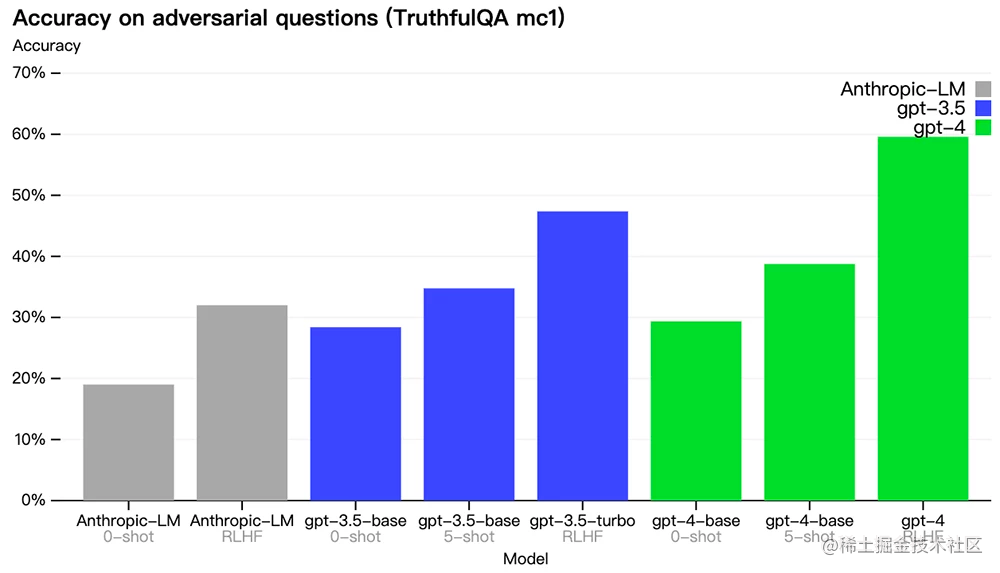
El modelo base GPT-4 es solo un poco mejor que GPT-3.5 en esta tarea, pero después del entrenamiento RLHF (aplicando el mismo procedimiento que GPT-3.5), hay una gran brecha.
Examinando algunos ejemplos a continuación, GPT-4 se niega a elegir proverbios comunes (no se pueden enseñar nuevas habilidades a un perro viejo, es decir, "el arte viejo es difícil de aprender"), pero aún pierde algunos detalles sutiles (Elvis Pray Seeley no es el hijo de un actor).

GPT-4 generalmente carece de comprensión de lo que sucedió después de la gran mayoría de las interrupciones de datos (septiembre de 2021) y no ha aprendido de la experiencia. A veces comete errores de razonamiento simples que parecen fuera de proporción con su competencia en múltiples dominios, o es demasiado crédulo al aceptar tergiversaciones obvias de los usuarios.
A veces falla en problemas difíciles como los humanos, como introducir agujeros de seguridad en el código que genera. GPT-4 también podría errar con confianza en sus predicciones, sin verificar dos veces su trabajo cuando podría serlo. Curiosamente, el modelo preentrenado subyacente está altamente calibrado (su confianza predicha en la respuesta generalmente coincide con la probabilidad de ser correcta). Sin embargo, con el proceso posterior al entrenamiento actual de OpenAI, la calibración se reduce.

¿Cómo evita OpenAI los riesgos?
OpenAI ha estado iterando en GPT-4 para hacerlo más seguro y consistente desde el comienzo del entrenamiento. Su trabajo incluye la selección y el filtrado de datos previos al entrenamiento, la evaluación y la participación de expertos, la mejora de la seguridad del modelo y el monitoreo y la aplicación. GPT-4 presenta riesgos similares a los modelos anteriores, como generar sugerencias dañinas, código incorrecto o información inexacta. Al mismo tiempo, las funciones adicionales de GPT-4 traerán nuevos riesgos.
Para comprender el alcance de estos riesgos, OpenAI contrató a más de 50 expertos en riesgo alineado con IA, ciberseguridad, riesgo biológico, confianza y seguridad, y seguridad internacional para probar el modelo de manera adversaria. Sus hallazgos permiten a OpenAI probar el comportamiento del modelo en dominios de alto riesgo que requieren conocimiento experto para la evaluación. Los comentarios y datos de estos expertos se utilizan para mejorar el modelo.
GPT-4 incorpora una señal de recompensa de seguridad adicional durante el entrenamiento de RLHF para reducir la producción dañina al entrenar al modelo para que rechace las solicitudes de dicho contenido. Las recompensas son proporcionadas por un clasificador de tiro cero GPT-4 que juzga los límites seguros y cómo completarlos en función de las señales relacionadas con la seguridad. Para evitar que el modelo rechace solicitudes válidas, OpenAI recopila diversos conjuntos de datos de varias fuentes y aplica señales de recompensa de seguridad (con valores positivos o negativos) en categorías permitidas y no permitidas.
Sus mitigaciones mejoran significativamente muchas de las funciones de seguridad de GPT-4 en comparación con GPT-3.5, han reducido la probabilidad de que los modelos respondan a solicitudes de contenido prohibido en un 82 % y GPT-4 responde a solicitudes confidenciales (como consejos médicos y autolesiones). ) aumentó un 29%.
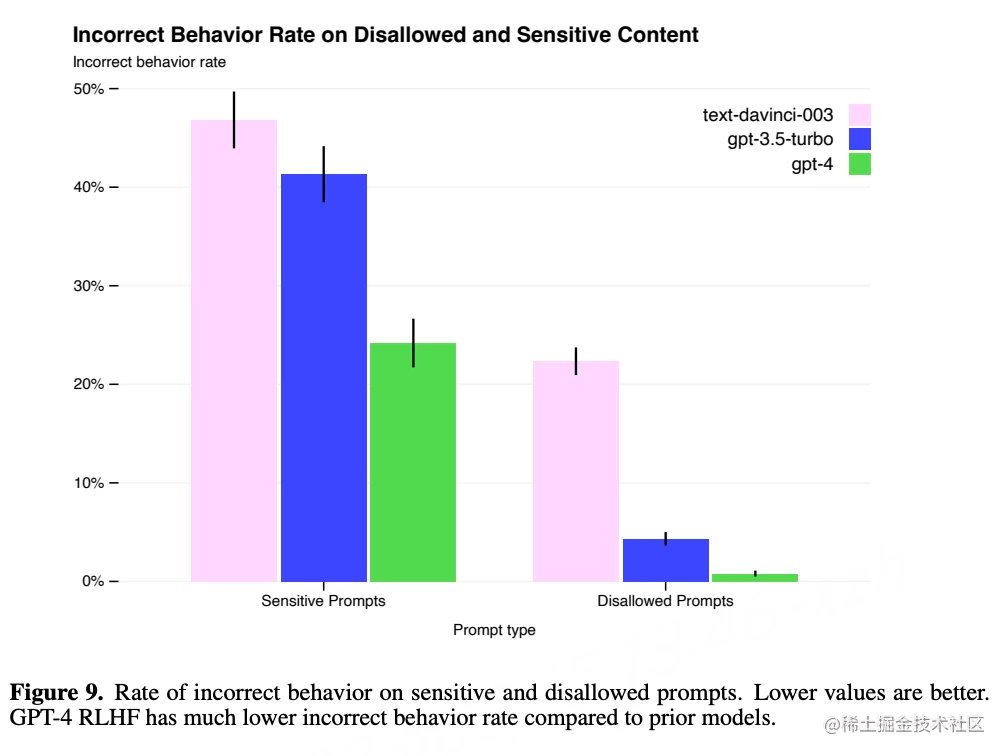

En general, la intervención a nivel de modelo de OpenAI hace que sea más difícil inducir un mal comportamiento, pero aún así no se puede evitar por completo. OpenAI enfatiza que estas limitaciones se complementan actualmente con técnicas de seguridad en tiempo de implementación, como el monitoreo de abuso.
GPT-4 y los modelos posteriores tienen el potencial de impactar significativamente en la sociedad de manera beneficiosa y perjudicial. OpenAI está colaborando con investigadores externos para mejorar la forma en que comprende y evalúa el impacto potencial y la evaluación de características potencialmente peligrosas en sistemas futuros, y pronto compartirá más sobre los impactos sociales y sociales potenciales de GPT-4 y otros sistemas de IA. de impacto económico.
Cree una pila de aprendizaje profundo que escale de manera predecible
Un gran enfoque del proyecto GPT-4 es construir pilas de aprendizaje profundo que se escalen de manera predecible. La razón principal es que para ejecuciones de entrenamiento muy grandes como GPT-4, no es factible un ajuste extenso específico del modelo. La infraestructura y las optimizaciones desarrolladas por OpenAI tienen un comportamiento muy predecible en múltiples escalas.
Para verificar esta escalabilidad, OpenAI predijo con precisión el rendimiento final de GPT-4 en su base de código interno (que no forma parte del conjunto de entrenamiento) mediante la extrapolación de un modelo entrenado con el mismo método pero reducido a 1/10000 de la pérdida de cálculo original. :
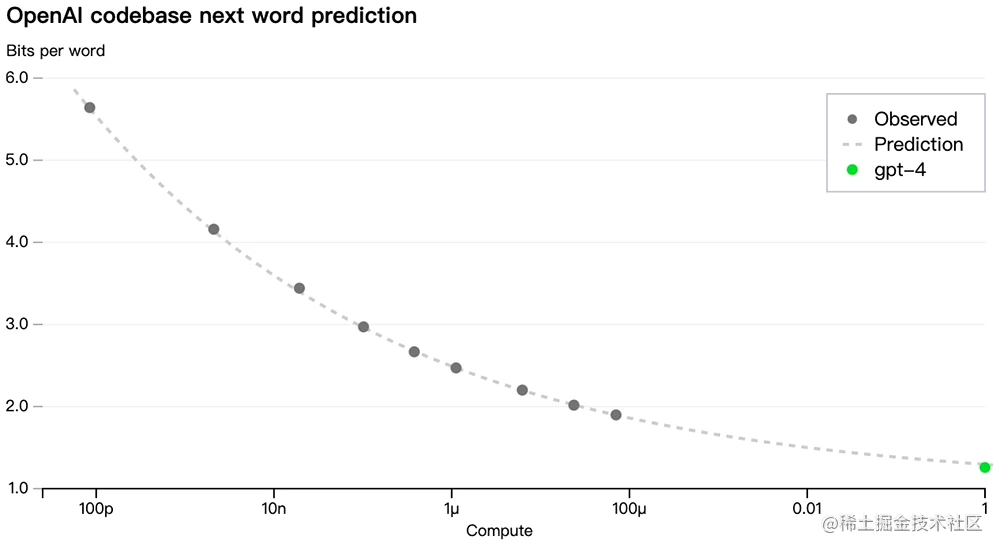
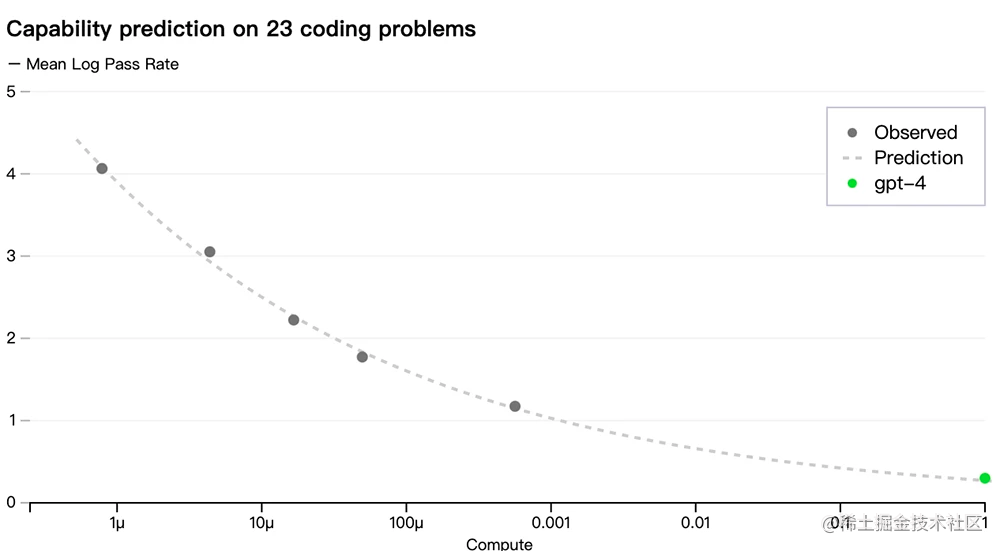
Ahora que OpenAI puede predecir con precisión la métrica (pérdida) que optimizó durante el entrenamiento, comenzó a desarrollar métodos para predecir métricas más interpretables, como predecir con éxito la tasa de aprobación de un subconjunto del conjunto de datos HumanEval, reduciendo la cantidad de cálculo del original. 1 Modelo de inferencia para /1000:
Algunas capacidades aún son impredecibles. Por ejemplo, el Premio de escala inversa es una competencia para encontrar métricas que empeoran a medida que aumenta el cálculo del modelo, y la negligencia retrospectiva es uno de los ganadores. Al igual que otro resultado reciente, GPT-4 invirtió la tendencia:
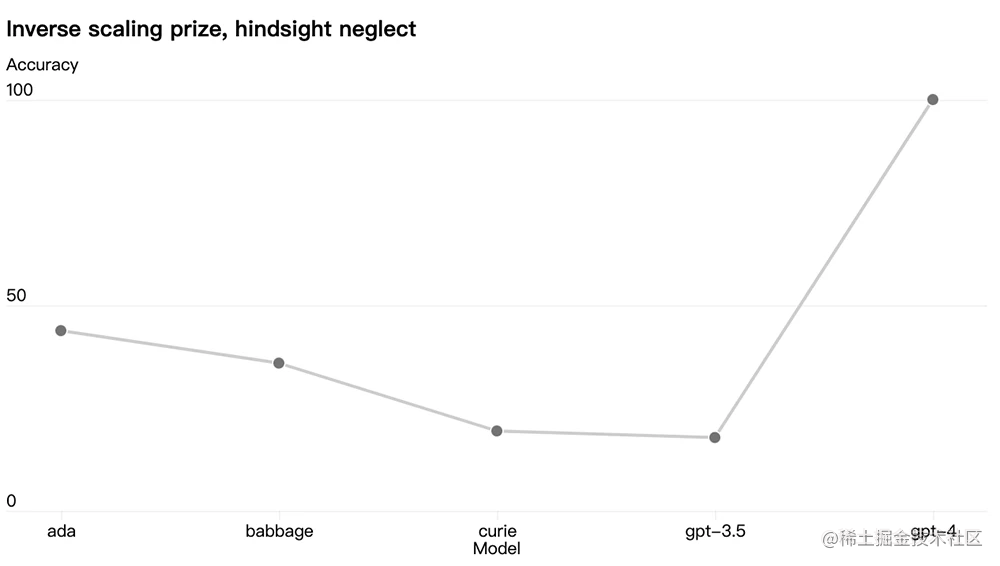
OpenAI cree que la capacidad del aprendizaje automático para predecir con precisión el futuro es una parte importante de la seguridad, pero no ha recibido suficiente atención en relación con su impacto potencial. OpenAI está aumentando sus esfuerzos para desarrollar métodos que brinden a la sociedad una mejor orientación sobre qué esperar de los sistemas futuros y espera que esto se convierta en un objetivo común en el campo.
Evaluación del marco de software de código abierto
OpenAI está abriendo su marco de software, OpenAI Evals, para crear y ejecutar puntos de referencia para evaluar modelos como GPT-4, mientras verifica su rendimiento muestra por muestra.
OpenAI usa Evals para guiar el desarrollo de sus modelos, y sus usuarios pueden aplicar el marco para rastrear el rendimiento de las versiones del modelo (que ahora se lanzarán regularmente) y las integraciones de productos en evolución. Stripe, por ejemplo, usa Evals para complementar sus evaluaciones humanas para medir la precisión de sus herramientas de documentación basadas en GPT.
Debido a que el código es de código abierto, Evals admite la escritura de nuevas clases para implementar una lógica de evaluación personalizada. Pero en la experiencia de OpenAI, muchos puntos de referencia siguen una de las pocas "plantillas", por lo que también incluyen las plantillas más útiles internamente (incluida la plantilla para la "Evaluación de calificaciones del modelo": OpenAI descubrió que GPT-4 es útil para verificar su propio trabajo de manera sorprendente) poderoso). Por lo general, la forma más eficiente de construir una nueva evaluación es instanciar una de estas plantillas y proporcionar los datos.
OpenAI quiere que Evals sea una herramienta para compartir y hacer crowdsourcing de puntos de referencia que representen la gama más amplia de modos de falla y tareas difíciles. Como ejemplo, OpenAI creó una evaluación de rompecabezas lógico con diez pistas fallidas de GPT-4. Evals también es compatible con los puntos de referencia existentes; OpenAI ya tiene algunos portátiles que implementan puntos de referencia académicos y algunas variantes que integran CoQA (un pequeño subconjunto) como ejemplos.
OpenAI invita a todos a usar Evals para probar sus modelos, enviar sus ejemplos más interesantes, hacer contribuciones, preguntas y comentarios.
El último hito de OpenAI en la ampliación del aprendizaje profundo
GPT-4 es el último hito de OpenAI en el camino para escalar el aprendizaje profundo. OpenAI espera que GPT-4 sea una herramienta valiosa que mejore la vida al potenciar muchas aplicaciones.
Como dijo OpenAI, todavía queda mucho trabajo por delante, lo que requiere los esfuerzos colectivos de la comunidad para construir, explorar y contribuir al modelo para continuar haciéndolo más y más fuerte.
referencia:
https://cdn.openai.com/papers/gpt-4.pdf
https://openai.com/research/gpt-4