ChatGPT refuerzo aprendizaje gran asesino - optimización de la estrategia próxima (PPO)
La optimización de políticas proximales ( Proximal Policy Optimization ) proviene del artículo Algoritmos de optimización de políticas proximales (Schulman et. al., 2017), que actualmente es el algoritmo de aprendizaje por refuerzo (RL) más avanzado . Este elegante algoritmo se puede utilizar para diversas tareas y se ha aplicado en muchos proyectos. El recientemente popular ChatGPT ha adoptado este algoritmo.
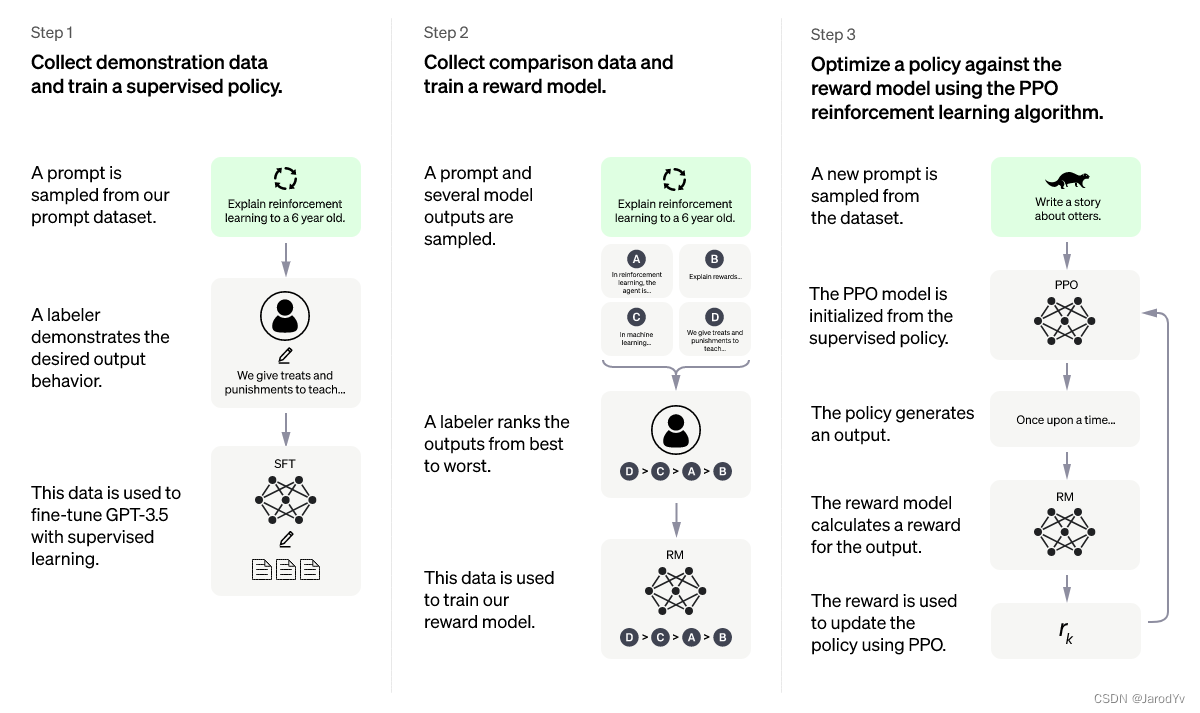
Hay muchos artículos en Internet que explican el algoritmo ChatGPT y el proceso de entrenamiento, pero pocas personas explican en profundidad el algoritmo clave de optimización de la estrategia proximal . En este artículo, me centraré en explicar el algoritmo de optimización de la estrategia proximal y lo implementaré desde cero con PyTorch.
Directorio de artículos
aprendizaje reforzado
Como algoritmo avanzado de aprendizaje por refuerzo, la optimización de la estrategia próxima requiere una comprensión del aprendizaje por refuerzo. Hay muchos artículos sobre el aprendizaje por refuerzo, no introduciré demasiado aquí, pero aquí podemos ver cómo lo explica ChatGPT:

La explicación que da ChatGPT es relativamente fácil de entender, más académicamente hablando, el proceso de aprendizaje por refuerzo es el siguiente:

En la figura anterior, el entorno retroalimenta las recompensas al agente en cada momento y monitorea el estado actual. Con esta información, el agente realiza acciones en el entorno, y luego se retroalimentan nuevas recompensas, estados, etc. al agente, formando un bucle. Este marco es muy general y se puede aplicar en varios campos.
Nuestro objetivo es crear un agente que maximice las recompensas. Por lo general, esta recompensa de maximización es la suma de las recompensas de descuento de tiempo individuales.
GRAMO = ∑ t = 0 T γ trt GRAMO = \sum_{t=0}^T\gamma^tr_tGRAMO=t = 0∑TCt rt
Aquí γ \gammaγ es un factor de descuento, generalmente en el rango de [0.95, 0.99],rt r_trtes la recompensa en el tiempo t.
algoritmo
Entonces, ¿cómo resolvemos los problemas de aprendizaje por refuerzo? Hay una variedad de algoritmos, que pueden (para los procesos de decisión de Markov, o MDP) caer en dos categorías: basado en modelos (crea un modelo del entorno) y sin modelos (aprende solo dado un estado).
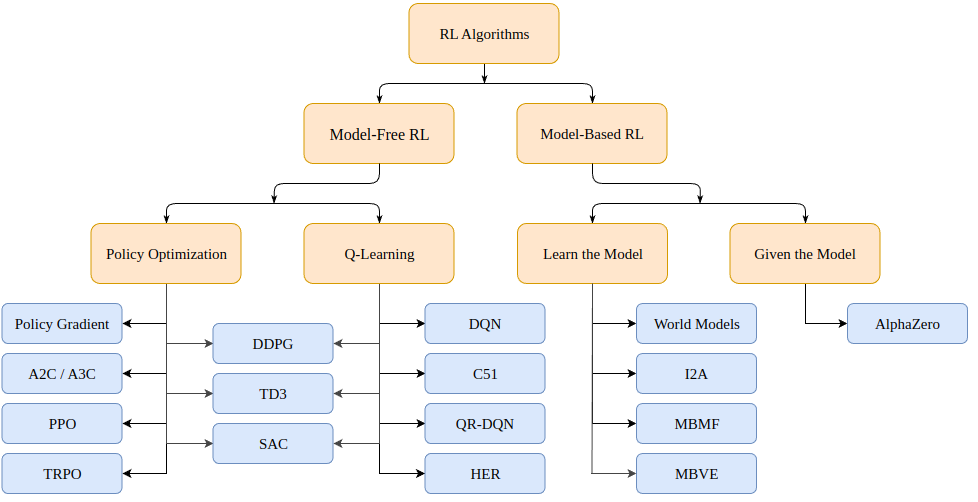
Los algoritmos basados en modelos crean un modelo del entorno y usan ese modelo para predecir estados y recompensas futuras. El modelo se da (por ejemplo, un tablero de ajedrez) o se aprende.
Los algoritmos sin modelo aprenden directamente cómo actuar en los estados encontrados durante el entrenamiento (optimización de políticas o PO) y qué acciones de estado producen buenas recompensas (Q-Learning).
Los algoritmos de optimización de políticas proximales que analizamos hoy pertenecen a la familia de algoritmos PO. Por lo tanto, no necesitamos un modelo del entorno para impulsar el aprendizaje. La principal diferencia entre los algoritmos PO y Q-Learning es que el algoritmo PO se puede usar en entornos con espacios de acción continuos (es decir, nuestras acciones tienen valores verdaderos) y puede encontrar la estrategia óptima; y el algoritmo Q-Learning no puede hacer ambas cosas. Esta es otra razón por la que el algoritmo PO es más popular. Por otro lado, los algoritmos de Q-Learning tienden a ser más simples, más intuitivos y más fáciles de entrenar.
Optimización de políticas (basada en gradiente)
Los algoritmos de optimización de políticas pueden aprender políticas directamente. Para este propósito, la optimización de políticas puede usar algoritmos sin gradientes, como algoritmos genéticos o algoritmos basados en gradientes más comunes.
Por métodos basados en gradientes nos referimos a todos los métodos que intentan estimar el gradiente de la política aprendida con respecto a la recompensa acumulada. Si conocemos este gradiente (o una aproximación del mismo), simplemente podemos cambiar los parámetros de la política en la dirección del gradiente para maximizar la recompensa.
El método del gradiente de políticas estima repetidamente el gradiente g : = ∇ θ E [ ∑ t = 0 ∞ rt ] g:=\nabla_\theta\mathbb{E}[\sum_{t=0}^{\infin}r_t]gramo:=∇iy [ ∑t = 0∞rt] para maximizar la recompensa total esperada. Hay varias expresiones relacionadas diferentes para gradiente de política, que tienen la forma:
gramo = mi [ ∑ t = 0 ∞ Ψ t ∇ θ iniciar sesión π θ ( en ∣ st ) ] (1) g=\mathbb{E}\Bigg\lbrack \sum_{t=0}^{\infin} \Psi_t \nabla_\theta log\pi_\theta(a_t \mid s_t) \Bigg\rbrack \tag{1}gramo=y [t = 0∑∞PDt∇ilogaritmo π _ _i( unt∣st) ]( 1 )
donde Ψ t \Psi_tPDtPuede ser lo siguiente:
- ∑ t = 0 ∞ rt \sum_{t=0}^\infin r_t∑t = 0∞rt: la recompensa total de la trayectoria
- ∑ t ′ = t ∞ rt ′ \sum_{t'=t}^\infin r_{t'}∑t′ =t∞rt': próxima acción en a_tatpremio
- ∑ t = 0 ∞ rt − segundo ( st ) \sum_{t=0}^\infin r_t - b(s_t)∑t = 0∞rt−segundo _ _t) : la versión de referencia de la fórmula anterior
- Q π ( st , en ) Q^\pi(s_t, a_t)qπ (st,at) : función de valor de estado-acción
- A π ( st , a t ) A^\pi(s_t, a_t)Aπ (st,at) : función de ventaja
- rt + V π ( st + 1 ) + V π ( st ) r_t+V^\pi(s_{t+1})+V^\pi(s_{t})rt+ENπ (st + 1)+ENπ (st) : TD residual
Las definiciones específicas de las siguientes tres fórmulas son las siguientes:
V π ( st ) : = E st + 1 : ∞ , at : ∞ [ ∑ l = 0 ∞ rt + l ] Q π ( st , at ) : = E st + 1 : ∞ , en + 1 : ∞ [ ∑ l = 0 ∞ rt + l ] (2) V^\pi(s_t) := \mathbb{E}_{s_{t+1:\infin}, a_ {t: \infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \\ Q^\pi(s_t, a_t) := \mathbb{E}_ {s_{ t+1:\infin}, a_{t+1:\infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \tag{2}ENπ (st):=Yst + 1 : ∞, unt : ∞[l = 0∑∞rt + l]qπ (st,at):=Yst + 1 : ∞, unt + 1 : ∞[l = 0∑∞rt + l]( 2 )
A π ( st , at ) : = Q π ( st , at ) − V π ( st ) (3) A^\pi(s_t, a_t) := Q^\pi(s_t, a_t) - V^\pi (s_t) \tag{3}Aπ (st,at):=qπ (st,at)−ENπ (st)( 3 )
Tenga en cuenta que hay varias formas de estimar gradientes. Aquí, enumeramos 6 valores diferentes: la recompensa total, la recompensa de la acción subsiguiente, la recompensa menos la versión de referencia, la función de valor de acción de estado, la función de dominancia (utilizada en el documento PPO original) y la diferencia de tiempo ( TD) Diferencia residual. Podemos elegir estos valores como nuestro objetivo de maximización. En principio, ambos proporcionan una estimación del verdadero gradiente que nos interesa.
optimización de la estrategia proximal
La optimización de políticas proximales, o PPO para abreviar, es un algoritmo (sin modelo) basado en gradientes de optimización de políticas. El algoritmo tiene como objetivo aprender una política que maximice la recompensa acumulada obtenida en función de la experiencia durante el entrenamiento.
Consiste en un actor π θ ( . ∣ st ) \pi\theta(. \mid st )π θ ( .∣s t ) y uncrítico (critic) V ( st ) V(st)V ( s t ) composición. El primero en el tiempottMuestra la distribución de probabilidad de la siguiente acción en t , que estima la recompensa acumulada esperada (escalar) para ese estado. Dado que tanto los actores como los críticos toman el estado como entrada, la arquitectura de la red troncal se puede compartir entre las dos redes para extraer características de alto nivel.
PPO tiene como objetivo que la política elija acciones con una "ventaja" mayor, es decir, con una recompensa acumulada mucho mayor que la prevista por el evaluador. Al mismo tiempo, no queremos actualizar demasiadas estrategias a la vez, lo que puede causar problemas de optimización. Finalmente, si la política tiene una entropía alta, tendemos a otorgar recompensas adicionales para incentivar una mayor exploración.
La función de pérdida total consta de tres términos: un término CLIP, un término de función de valor (VF) y un término de recompensa de entropía. El objetivo final es el siguiente:
L t CLIP + VF + S ( θ ) = E ^ t [ L t CLIP ( θ ) − c 1 L t VF ( θ ) + c 2 S [ π θ ] ( st ) ] L_t ^{CLIP +VF+S}(\theta) = \hat{\mathbb{E}}_t \Big\lbrack L_t^{CLIP}(\theta) - c_1L_t^{VF}(\theta)+c_2S[\ pi_\theta](s_t)\Grande\rbrackLtC L I P + V F + S( yo )=Y^t[ LtCLIP _ _ _( yo )−C1LtV F( yo )+C2S [ πi] ( st) ]
dondec 1 c_1C1y c 2 c_2C2son hiperparámetros que miden la importancia de la precisión de la evaluación (crítica) y exploración (exploración) de políticas, respectivamente.
elemento CLIP
Como dijimos, la función de pérdida motiva la maximización (o minimización) de la probabilidad de acción, lo que lleva a la acción ventaja positiva (o ventaja negativa)
LCLIP ( θ ) = E ^ t [ min ( rt ( θ ) A t ^ , recortar ( rt ( θ ) , 1 − ϵ , 1 + ϵ ) UN ^ t ) ] L^{CLIP}(\theta) = \hat{\mathbb{E}}_t\Big\lbrack min \Big\lparen r_t (\theta )\hat{A_t},clip \big\lparen r_t(\theta),1-\epsilon, 1+\epsilon\big\rparen \hat{A}_t \Big\rparen \Big\rbrackLCLIP (θ) _ _ _=Y^t[ mi ( rt( yo )At^,clip ( r ) _ _t( yo ) ,1−, _1+) _A^t) ]
Abierto:
rt ( θ ) = π θ ( en ∣ st ) π θ viejo ( en ∣ st ) r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_ {viejo}}(a_t\mid s_t)}rt( yo )=Piiviejo _ _( unt∣st)Pii( unt∣st)
es la proporción que mide la probabilidad de que ahora (política actualizada) realicemos esa acción anterior en relación con antes. En principio, no queremos que este coeficiente sea demasiado grande, porque demasiado grande significa un cambio repentino de estrategia. Por eso tomamos su suma mínima [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon][ 1−, _1+ϵ ] , dondeϵ \epsilonϵ es un hiperparámetro.
La fórmula de cálculo de la ventaja es la siguiente:
A ^ t = − V ( st ) + rt + γ rt + 1 + γ 2 rt + 2 + ⋯ + γ ( T − t + 1 ) r T − 1 + γ T − t V ( s T ) \hat{A}_t = -V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\dots+\gamma^{(T-t +1 )} r_{T-1} + \gamma^{Tt}V(s_T)A^t=- V ( st)+rt+r _t + 1+C2r _t + 2+⋯+C( T - t + 1 ) rT − 1+CT - t V(sT)
donde:A t ^ \hat{A_t}At^es la ventaja estimada, − V ( st ) -V(s_t)- V ( st) es el valor de estado inicial estimado,γ T − t V ( s T ) \gamma^{Tt}V(s_T)CT - t V(sT) es el valor estimado del estado terminal, y la parte media es la recompensa acumulada observada durante el proceso.
Vemos que simplemente mide la respuesta del evaluador a un estado dado st s_tstgrado de error Si obtenemos una recompensa acumulada más alta, la estimación de probabilidades será positiva y será más probable que actuemos en este estado. Lo contrario también es cierto, si esperamos una recompensa mayor pero obtenemos una recompensa menor, la estimación de probabilidades será negativa y reduciremos la probabilidad de tomar medidas en este paso.
Tenga en cuenta que si vamos hasta el estado terminal s T s_TsT, ya no necesitamos confiar en el evaluador, simplemente podemos comparar el evaluador con la recompensa acumulada real. En este caso, la estimación de la ventaja es la ventaja real.
término de función de valor
Para tener una buena estimación de la ventaja, necesitamos un evaluador que pueda predecir el valor de un estado dado. El modelo es aprendizaje supervisado con una pérdida MSE simple:
L t VF = MSE ( rt + γ rt + 1 + ⋯ + γ ( T − t + 1 ) r T − 1 + V ( s T ) , V ( st ) ) = ∣ ∣ A ^ t ∣ ∣ 2 L_t^{VF} = MSE(r_t+\gamma r_{t+1}+\dots+\gamma^{(T-t+1)} r_{T-1}+V( s_T),V(s_t)) = ||\hat{A}_t||_2LtV F=MSE ( rt+r _t + 1+⋯+C( T - t + 1 ) rT − 1+V ( sT) ,V ( st))=∣∣A^t∣ ∣2
En cada iteración, también actualizamos el evaluador para que nos brinde valores de estado cada vez más precisos a medida que avanza el entrenamiento.
término de recompensa de entropía
Finalmente, alentamos una exploración de pequeña recompensa de la entropía de la distribución del producto de la política. La entropía estándar es:
S [ π θ ] ( st ) = − ∫ π θ ( en ∣ st ) log ( π θ ( en ∣ st ) ) dat S[\pi_\theta](s_t) = -\int \pi_ \ theta(a_t \mid s_t) log(\pi_\theta(a_t \mid s_t))da_tS [ πi] ( st)=−∫Pii( unt∣st) log ( p _ _i( unt∣st) ) _t
Implementación de algoritmos
Si la explicación anterior no es lo suficientemente clara, no se preocupe, lo siguiente lo llevará a implementar el algoritmo de optimización de la estrategia proximal paso a paso desde cero.
código de herramienta
Primero importe las bibliotecas requeridas
from argparse import ArgumentParser
import gym
import numpy as np
import wandb
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import LinearLR
from torch.distributions.categorical import Categorical
import pytorch_lightning as pl
Los hiperparámetros importantes de PPO son el número de actores, el horizonte, épsilon, el número de épocas en cada etapa de optimización, la tasa de aprendizaje, el factor de descuento gamma y las constantes c1 y c2 para ponderar diferentes elementos de pérdida. Pasamos estos hiperparámetros a través de parámetros.
def parse_args():
"""解析参数"""
parser = ArgumentParser()
parser.add_argument("--max_iterations", type=int, help="训练迭代次数", default=100)
parser.add_argument("--n_actors", type=int, help="actor数量", default=8)
parser.add_argument("--horizon", type=int, help="每个actor的时间戳数量", default=128)
parser.add_argument("--epsilon", type=float, help="Epsilon", default=0.1)
parser.add_argument("--n_epochs", type=int, help="每次迭代的训练轮数", default=3)
parser.add_argument("--batch_size", type=int, help="Batch size", default=32 * 8)
parser.add_argument("--lr", type=float, help="学习率", default=2.5 * 1e-4)
parser.add_argument("--gamma", type=float, help="折扣因子gamma", default=0.99)
parser.add_argument("--c1", type=float, help="损失函数价值函数的权重", default=1)
parser.add_argument("--c2", type=float, help="损失函数熵奖励的权重", default=0.01)
parser.add_argument("--n_test_episodes", type=int, help="Number of episodes to render", default=5)
parser.add_argument("--seed", type=int, help="随机种子", default=0)
return vars(parser.parse_args())
Tenga en cuenta que, de forma predeterminada, los parámetros se establecen como se describe en el documento. Idealmente, nuestro código debería ejecutarse en la GPU tanto como sea posible, por lo que debemos configurar el equipo de la antorcha.
def get_device():
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Found GPU device: {
torch.cuda.get_device_name(device)}")
else:
device = torch.device("cpu")
print("No GPU found: Running on CPU")
return device
Cuando realizamos el aprendizaje por refuerzo, generalmente configuramos un búfer para almacenar el estado, la acción y la recompensa encontrada por el modelo actual, que se utiliza para actualizar nuestro modelo. Creamos una función run_timestampsque ejecutará un modelo determinado en un entorno determinado y obtendrá una cantidad fija de marcas de tiempo (restableciendo el entorno si finaliza el episodio). También usamos la opción render=Falsepara que solo queramos ver cómo se desempeña el modelo entrenado.
@torch.no_grad()
def run_timestamps(env, model, timestamps=128, render=False, device="cpu"):
"""针对给定数量的时间戳在给定环境中运行给定策略。
返回具有状态、动作和奖励的缓冲区。"""
buffer = []
state = env.reset()[0]
# 运行时间戳并收集状态、动作、奖励和终止
for ts in range(timestamps):
model_input = torch.from_numpy(state).unsqueeze(0).to(device).float()
action, action_logits, value = model(model_input)
new_state, reward, terminated, truncated, info = env.step(action.item())
# (s, a, r, t)渲染到环境或存储到buffer
if render:
env.render()
else:
buffer.append([model_input, action, action_logits, value, reward, terminated or truncated])
# 更新当前状态
state = new_state
# 如果episode终止或被截断,则重置环境
if terminated or truncated:
state = env.reset()[0]
return buffer
El valor de retorno de esta función (cuando no se representa) es un búfer que contiene el estado, las acciones realizadas, las probabilidades de acción (logits), los valores del evaluador, las recompensas y el estado terminal de la política proporcionada en cada marca de tiempo. Tenga en cuenta que esta función utiliza un decorador @torch.no_grad(), por lo que no es necesario almacenar gradientes para las acciones realizadas durante la interacción con el entorno.
código central
Con las funciones de la herramienta anterior, podemos desarrollar el código central de la optimización de la estrategia proximal. Primero, cree un nuevo proceso de función principal :
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# TODO 创建模型,训练模型,输出结果
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
training_loop(env, model, args)
model = load_best_model()
testing_loop(env, model)
Lo anterior es el marco de proceso del programa general. A continuación, solo necesitamos definir el modelo PPO, entrenar y probar las funciones.
No se elabora aquí la arquitectura del modelo PPO, solo necesitamos dos modelos (actor y crítico) que funcionen en el entorno. Por supuesto, la arquitectura del modelo juega un papel crucial en tareas más complejas, pero en nuestra tarea simple, un MLP puede hacer el trabajo.
Por lo tanto, podemos crear una MyPPOclase . Al ejecutar el método directo en algún estado, devolvemos las acciones muestreadas del actor, las probabilidades relativas (logits) de cada acción posible y la estimación del crítico para cada estado.
class MyPPO(nn.Module):
"""
PPO模型的实现。
相同的代码结构即可用于actor,也可用于critic。
"""
def __init__(self, in_shape, n_actions, hidden_d=100, share_backbone=False):
# 父类构造函数
super(MyPPO, self).__init__()
# 属性
self.in_shape = in_shape
self.n_actions = n_actions
self.hidden_d = hidden_d
self.share_backbone = share_backbone
# 共享策略主干和价值函数
in_dim = np.prod(in_shape)
def to_features():
return nn.Sequential(
nn.Flatten(),
nn.Linear(in_dim, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU()
)
self.backbone = to_features() if self.share_backbone else nn.Identity()
# State action function
self.actor = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, n_actions),
nn.Softmax(dim=-1)
)
# Value function
self.critic = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, 1)
)
def forward(self, x):
features = self.backbone(x)
action = self.actor(features)
value = self.critic(features)
return Categorical(action).sample(), action, value
Tenga en cuenta que Categorical(action).sample()se crea una distribución categórica con logits de acción y muestras para una acción (para cada estado).
Finalmente, podemos tratar con el algoritmo real en training_loopla función . Como sabemos por el artículo, la firma real de la función debería verse así:
def training_loop(env, model, max_iterations, n_actors, horizon, gamma,
epsilon, n_epochs, batch_size, lr, c1, c2, device, env_name=""):
# TODO...
El siguiente es el pseudocódigo para el programa de capacitación de PPO en el documento:

El pseudocódigo de PPO es relativamente simple: simplemente recopilamos interacciones con el entorno a través de múltiples copias del modelo de política (llamados actores) y optimizamos las redes de actores y críticos utilizando objetivos previamente definidos.
Dado que necesitamos medir la recompensa acumulada que realmente obtuvimos, necesitamos crear una función que, dado un búfer, reemplace la recompensa cada vez con la recompensa acumulada:
def compute_cumulative_rewards(buffer, gamma):
"""
给定一个包含状态、策略操作逻辑、奖励和终止的缓冲区,计算每个时间的累积奖励并将它们代入缓冲区。
"""
curr_rew = 0.
# 反向遍历缓冲区
for i in range(len(buffer) - 1, -1, -1):
r, t = buffer[i][-2], buffer[i][-1]
if t:
curr_rew = 0
else:
curr_rew = r + gamma * curr_rew
buffer[i][-2] = curr_rew
# 在规范化之前获得平均奖励(用于日志记录和检查点)
avg_rew = np.mean([buffer[i][-2] for i in range(len(buffer))])
# 规范化累积奖励
mean = np.mean([buffer[i][-2] for i in range(len(buffer))])
std = np.std([buffer[i][-2] for i in range(len(buffer))]) + 1e-6
for i in range(len(buffer)):
buffer[i][-2] = (buffer[i][-2] - mean) / std
return avg_rew
Tenga en cuenta que normalizamos la recompensa acumulada al final. Este es un truco estándar para hacer que los problemas de optimización sean más fáciles y que el entrenamiento sea más fluido.
Ahora que tenemos un búfer que contiene el estado, la acción realizada, la probabilidad de acción y la recompensa acumulada, podemos escribir una función que, dado el búfer, calcule tres términos de pérdida para nuestro objetivo final:
def get_losses(model, batch, epsilon, annealing, device="cpu"):
"""给定模型、给定批次和附加参数返回三个损失项"""
# 获取旧数据
n = len(batch)
states = torch.cat([batch[i][0] for i in range(n)])
actions = torch.cat([batch[i][1] for i in range(n)]).view(n, 1)
logits = torch.cat([batch[i][2] for i in range(n)])
values = torch.cat([batch[i][3] for i in range(n)])
cumulative_rewards = torch.tensor([batch[i][-2] for i in range(n)]).view(-1, 1).float().to(device)
# 使用新模型计算预测
_, new_logits, new_values = model(states)
# 状态动作函数损失(L_CLIP)
advantages = cumulative_rewards - values
margin = epsilon * annealing
ratios = new_logits.gather(1, actions) / logits.gather(1, actions)
l_clip = torch.mean(
torch.min(
torch.cat(
(ratios * advantages,
torch.clip(ratios, 1 - margin, 1 + margin) * advantages),
dim=1),
dim=1
).values
)
# 价值函数损失(L_VF)
l_vf = torch.mean((cumulative_rewards - new_values) ** 2)
# 熵奖励
entropy_bonus = torch.mean(torch.sum(-new_logits * (torch.log(new_logits + 1e-5)), dim=1))
return l_clip, l_vf, entropy_bonus
Tenga en cuenta que en la práctica usamos un parámetro de recocido que comienza en 1 y decae linealmente a 0 a lo largo del entrenamiento. Porque a medida que avanza la formación, queremos que nuestra política cambie cada vez menos. Además, a diferencia de new_logitsy new_values, no hacemos un seguimiento del advantagesgradiente de la variable, solo de la diferencia de tensores.
Ahora que tenemos métodos para interactuar con el entorno y almacenar búferes, calcular la recompensa acumulada (verdadera) y obtener el término de pérdida, podemos comenzar a escribir el código de entrenamiento final:
def training_loop(env, model, max_iterations, n_actors, horizon, gamma, epsilon, n_epochs, batch_size, lr,
c1, c2, device, env_name=""):
"""使用最多n个时间戳的多个actor在给定环境中训练模型。"""
# 开始运行新的权重和偏差
wandb.init(project="Papers Re-implementations",
entity="peutlefaire",
name=f"PPO - {
env_name}",
config={
"env": str(env),
"number of actors": n_actors,
"horizon": horizon,
"gamma": gamma,
"epsilon": epsilon,
"epochs": n_epochs,
"batch size": batch_size,
"learning rate": lr,
"c1": c1,
"c2": c2
})
# 训练变量
max_reward = float("-inf")
optimizer = Adam(model.parameters(), lr=lr, maximize=True)
scheduler = LinearLR(optimizer, 1, 0, max_iterations * n_epochs)
anneals = np.linspace(1, 0, max_iterations)
# 训练循环
for iteration in range(max_iterations):
buffer = []
annealing = anneals[iteration]
# 使用当前策略收集所有actor的时间戳
for actor in range(1, n_actors + 1):
buffer.extend(run_timestamps(env, model, horizon, False, device))
# 计算累积奖励并刷新缓冲区
avg_rew = compute_cumulative_rewards(buffer, gamma)
np.random.shuffle(buffer)
# 运行几轮优化
for epoch in range(n_epochs):
for batch_idx in range(len(buffer) // batch_size):
start = batch_size * batch_idx
end = start + batch_size if start + batch_size < len(buffer) else -1
batch = buffer[start:end]
# 归零优化器梯度
optimizer.zero_grad()
# 获取损失
l_clip, l_vf, entropy_bonus = get_losses(model, batch, epsilon, annealing, device)
# 计算总损失并反向传播
loss = l_clip - c1 * l_vf + c2 * entropy_bonus
loss.backward()
# 优化
optimizer.step()
scheduler.step()
# 记录输出
curr_loss = loss.item()
log = f"Iteration {
iteration + 1} / {
max_iterations}: " \
f"Average Reward: {
avg_rew:.2f}\t" \
f"Loss: {
curr_loss:.3f} " \
f"(L_CLIP: {
l_clip.item():.1f} | L_VF: {
l_vf.item():.1f} | L_bonus: {
entropy_bonus.item():.1f})"
if avg_rew > max_reward:
torch.save(model.state_dict(), MODEL_PATH)
max_reward = avg_rew
log += " --> Stored model with highest average reward"
print(log)
# 将信息记录到 W&B
wandb.log({
"loss (total)": curr_loss,
"loss (clip)": l_clip.item(),
"loss (vf)": l_vf.item(),
"loss (entropy bonus)": entropy_bonus.item(),
"average reward": avg_rew
})
# 完成 W&B 会话
wandb.finish()
Finalmente, para ver cómo se verá el modelo al final, usamos la siguiente testing_loopfunción :
def testing_loop(env, model, n_episodes, device):
for _ in range(n_episodes):
run_timestamps(env, model, timestamps=128, render=True, device=device)
De esta manera, nuestro programa principal se volverá muy simple:
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# 创建模型(actor和critic)
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
# 训练
training_loop(env, model, args["max_iterations"], args["n_actors"], args["horizon"], args["gamma"], args["epsilon"],
args["n_epochs"], args["batch_size"], args["lr"], args["c1"], args["c2"], device, env_name)
# 加载最佳模型
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
# 测试
env = gym.make(env_name, render_mode="human")
testing_loop(env, model, args["n_test_episodes"], device)
env.close()
¡Eso es todo lo anterior! Si entiende el código anterior, felicidades, ha entendido el algoritmo PPO.
en conclusión
Proximal Policy Optimization es un algoritmo de optimización de vanguardia para el aprendizaje de refuerzo de políticas que se puede utilizar en casi cualquier entorno. Además, la optimización próxima de políticas tiene una función objetivo relativamente simple y relativamente pocos hiperparámetros para ajustar.
ChatGPT se basa en PPO para obtener más resultados de los esperados en el tercer paso. Puede usarlo en sus propias tareas de aprendizaje por refuerzo y puede obtener resultados inesperados.