Table of contents
1. MySQL Server Logical Architecture
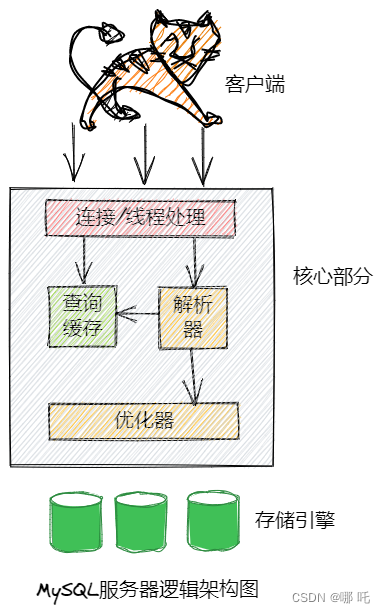
The core part of MySQL includes query parsing, analysis, optimization, caching, and built-in functions, all functions across storage engines, stored procedures, triggers, views, and more.
The storage engine is responsible for the storage and retrieval of data in MySQL. The server communicates with the storage engine through an API. The storage engine API contains dozens of low-level functions to perform operations such as "start a transaction" or "query data based on the primary key", but the storage engine does not parse the SQL, and the different storage engines do not communicate with each other, and Just simply respond to the request of the upper server.
2. Concurrency control
1. Read-write lock
Read locks are shared, or non-blocking, and multiple users can read the same resource at the same time without disturbing each other.
Write locks are exclusive locks, which block other write locks and read locks.
2. Lock granularity
Operations such as acquiring a lock, checking whether the lock is occupied, and releasing the lock will increase the overhead of the system.
Locking strategy means seeking a balance between the overhead of locking and the security of data.
3. Table lock
Table locks are the least expensive locks, table locks = lock the entire table.
A user needs to obtain a write lock before writing to a table, which will block other users' read and write operations on the table. When there is no write lock, other users will acquire the read lock, and the read locks do not block each other.
Although the storage engine can manage its own locks, MySQL uses various efficient table locks for different purposes. For example, the ALTER TABLEstatement uses a table lock, ignoring the lock mechanism of the storage engine.
4. Row-level lock
Row-level locks can support concurrent processing to the greatest extent, but also bring the greatest locking overhead.
3. Affairs
Statements within a transaction are either fully executed or not executed at all. Transactions have ACID characteristics, and ACID means atomicity, consistency, isolation, and durability.
1. Atomicity
A transaction must be regarded as an indivisible minimum unit of work, and all operations in the entire transaction are either fully executed and committed successfully, or none of them fail and roll back.
2. Consistency
The database always transitions from one consistent state to another consistent state.
3. Isolation
Changes made by one transaction are not visible to other transactions until they are finally committed.
4. Durability
Once the transaction is committed, the changes made by the seven will be permanently stored in the database.
4. Isolation level
1. Uncommitted read read uncommited
At the read uncommited level, changes in a transaction, even if not committed, are visible to other transactions. Transactions can read uncommitted data, also known as dirty reads. This causes many problems and is rarely used in practical applications.
2. Submit read read committed
The default isolation level of most database systems is read committed, but MySQL is not. Read committed satisfies the isolation mentioned above. When a transaction starts, only the modifications made by the committed transaction can be seen. Also known as non-repeatable read, because executing the same query twice may result in different results.
3. Repeatable read repeatable read
Repeatable read solves the problem of dirty reads. This level ensures that the results of reading the same record multiple times in the same transaction are consistent. However, it still cannot solve the problem of phantom reading. Phantom reading means that when a transaction is reading records in a certain range, another transaction inserts new records into the atmosphere, and the transaction before the file reads again. When recording in this range, a magic line will occur.
Repeatable read is MySQL's default transaction isolation level.
4. Serializable serializable
Serializable is the highest-level lock. It is executed serially through strong transactions, avoiding the phantom read problem mentioned earlier. Serializable will lock each row of data read, which may cause a large number of timeouts and lock contention problems. This isolation level is rarely used in practical applications.
5. Deadlock
Deadlock is a phenomenon in which two or more transactions occupy each other on the same resource and request to lock the resources occupied by each other, resulting in a vicious circle. Deadlocks can occur when multiple transactional views lock resources in different orders. If two transactions try to execute the same update statement, but find that the row has been locked by the other party, and then both transactions wait for the other party to release the lock, while holding the lock required by the other party, they will fall into a deadlock.
In order to solve the deadlock problem, such as MySQL's InnoDB storage engine, if a circular dependency of a deadlock is detected, InnoDB will roll back the transaction that holds the fewest row-level locks.
6. Transaction log
When the storage engine modifies the data of the table, it only needs to modify its memory copy, and then record the modification behavior in the transaction log of the disk, instead of persisting the modified data itself to the disk every time.
The transaction log adopts the append method. After the transaction log is persistent, the modified data in the memory will be slowly stored in the disk in the background. However, if an exception occurs at this time, after the storage engine is restarted, it will also be based on the transaction log. , save the data to disk.
Seven, multi-version concurrency control MVCC
Most of MySQL's transactional storage engines implement more than simple row-level locking. Based on the consideration of improving concurrency performance, they generally implement multi-version concurrency control MVCC at the same time. It can be considered that MVCC is a variant of row-level locks, but MVCC avoids locking operations in many cases, and the overhead is lower than row-level locks. many.
MVCC is implemented by saving a snapshot at a certain point in time. No matter how long it takes to execute, the data seen by each thing is consistent. Depending on when the transaction starts, each transaction may see inconsistent data for the same table at the same time.
InnoDB's MVCC is implemented by keeping two hidden columns behind each row of records, one for the creation time of the row and one for the deletion time of the row. It is not the actual time value that is stored, but the system version number. Every time a new transaction is started, the system version number is automatically incremented. The system version number at the start of the transaction will be used as the version number of the transaction to compare with the version number of each row of records queried.
MVCC is only used in the two isolation levels of read committed and repeatable read.
The use of MVCC is analyzed separately when adding, deleting, modifying and checking.
1、select
InnoDB checks each row against the following two conditions:
- InnoDB only looks for data rows whose version is earlier than the current transaction version, thus ensuring that the rows read by the transaction either existed before the transaction started, or were inserted or modified by the transaction itself;
- The deleted version of the row is either undefined or greater than the current transaction version number, which ensures that the row read by the transaction is not deleted before the transaction begins;
2、insert
InnoDB saves the current system version number as the row version number for each newly inserted row.
3、update
InnoDB will insert a new row, save the current system version number as the row version number, and save the current system version number to the original row as the row deletion representation.
4、delete
InnoDB saves the current system version number as the row deletion identifier for each row deleted.
Save these two extra system version numbers, so that most read operations can be locked without locking. The design of MVCC is that reading data is very simple, the performance is very good, and it can also ensure that only rows that meet the requirements can be read. The downside is that each row of records requires additional storage space, more row checking work, and some extra maintenance work.
MySQL advanced combat series articles
MySQL advanced combat 1, data types and three paradigms
21 Tips for SQL Performance Optimization
Detailed explanation of mysql index
MySql basic knowledge summary (SQL optimization)
Nezha boutique series of articles
Summary of Java learning routes, brick movers counterattack Java architects
Summary of 100,000 words and 208 Java classic interview questions (with answers)
