Hadoop は、Apache Foundation の下で最もよく知られているインフラストラクチャ オープン ソース プロジェクトの 1 つです。2006 年の誕生以来、大規模なデータ ストレージと処理のための最も重要な基本コンポーネントに徐々に発展し、非常に豊かな技術エコシステムを形成しています。
中国でトップの Hadoop オープン ソース エコロジカル テクノロジー サミットとして、第 4 回 China Apache Hadoop Meetup が 2022 年 9 月 24 日に上海で成功裏に開催されました。
「クラウド データ インテリジェンスが主力を集める」というテーマに焦点を当てると、Huawei、Alibaba、NetEase、ByteDance、bilibili、Ping An Bank、Kangaroo Cloud、Intel、Kyligence、Ampere などの企業や、Spark の企業が参加しています。 、Fluid、ChunJun など、Kyuubi、Ozone、IoTDB、Linkis、Kylin、Uniffle などのオープン ソース コミュニティのゲストが共有とディスカッションに参加しました。

このミートアップに参加しているコミュニティの 1 つであり、ビッグ データ分野のプロジェクトでもある ChunJun は、次のような新しい意見ももたらしました。
リアルタイムのデータ収集と復元におけるChunJunフレームワークの実装と原則は何ですか? この期間にChunJunはどのような新しい開発を行いましたか?また、将来の開発のためにどのような新しいアイデアを持っていますか?
Kangaroo Cloud のシニア ビッグ データ エンジン開発エキスパートである Chao Xu 氏は、独自の視点からデータ復元における ChunJun データ統合の調査と実践を紹介します。
1. ChunJun フレームワークの紹介
最初の質問: ChunJun フレームワークとは何ですか? 私に何ができる?
ChunJun (以前の FlinkX) は、Flink ベースに基づいてカンガルー クラウドによって開発されたデータ統合フレームワークです. 4 年以上の反復の後、安定した、効率的で使いやすいバッチ ストリーム統合データ統合ツールになりました。さまざまな異種データ ソースの効率的なデータ同期を実現できます。現在、3.2K+Star です。
オープンソース プロジェクトのアドレス:
https://github.com/DTStack/chunjun
https://gitee.com/dtstack_dev_0/chunjun
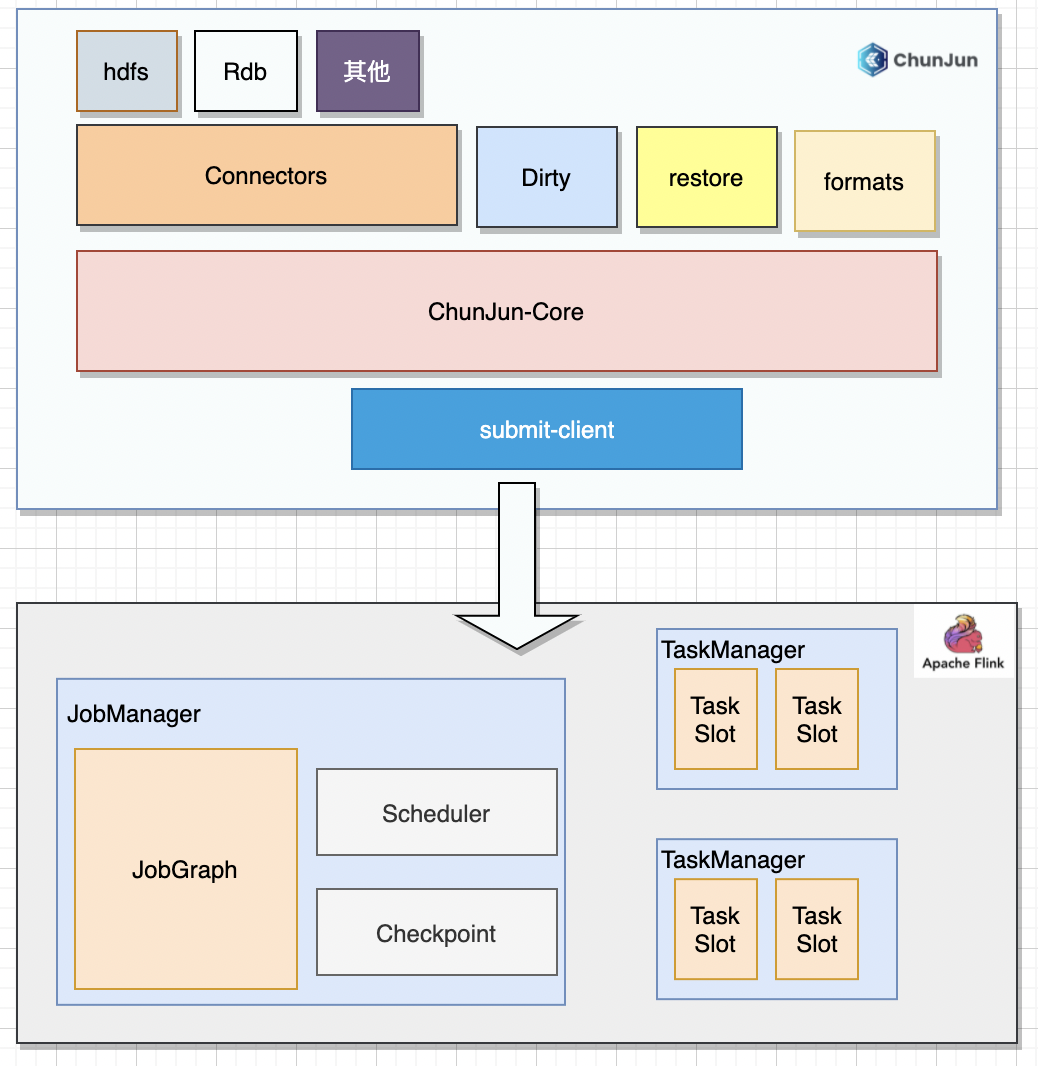
01 ChunJunフレーム構造
ChunJun フレームワークは Flink に基づいて開発され、豊富なプラグインを提供し、ブレークポイントの再開、ダーティ データ管理、データ復元などの機能を追加します。
02 ChunJun バッチ同期
• 増分同期のサポート
• 再開可能なアップロードをサポート
• マルチチャネルと同時実行をサポート
• ダーティ データのサポート(ロギングと制御)
• 電流制限をサポート
• 変圧器のサポート
03 チュンジュン オフライン
第二に、リアルタイムデータ取得の実現と原理
01 サンプル
02 ChunJun プラグインのロードロジック
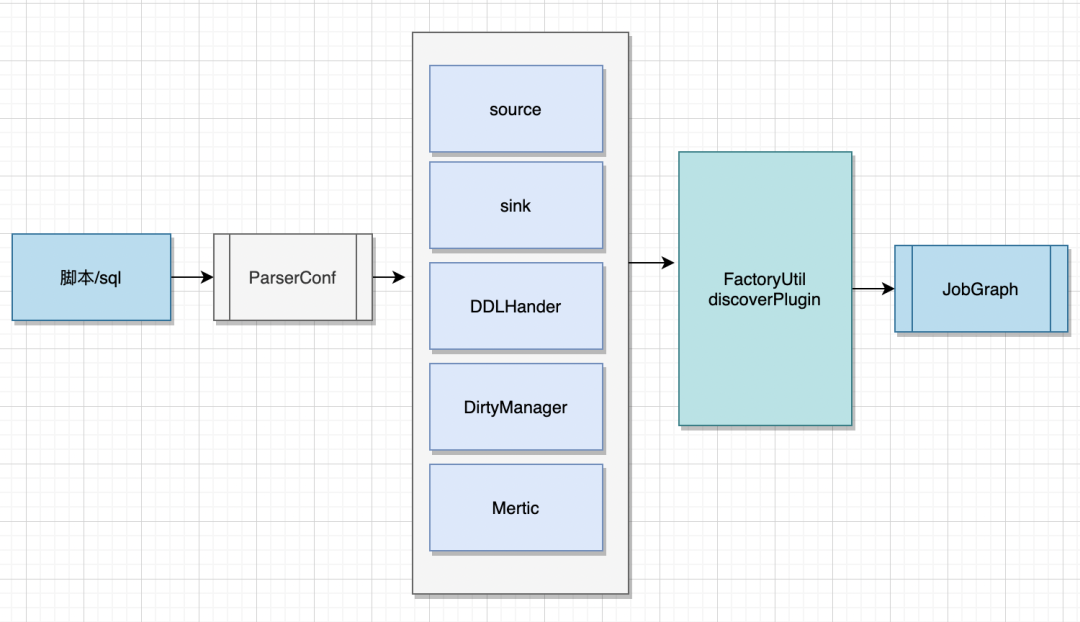
03 ChunJun プラグイン定義
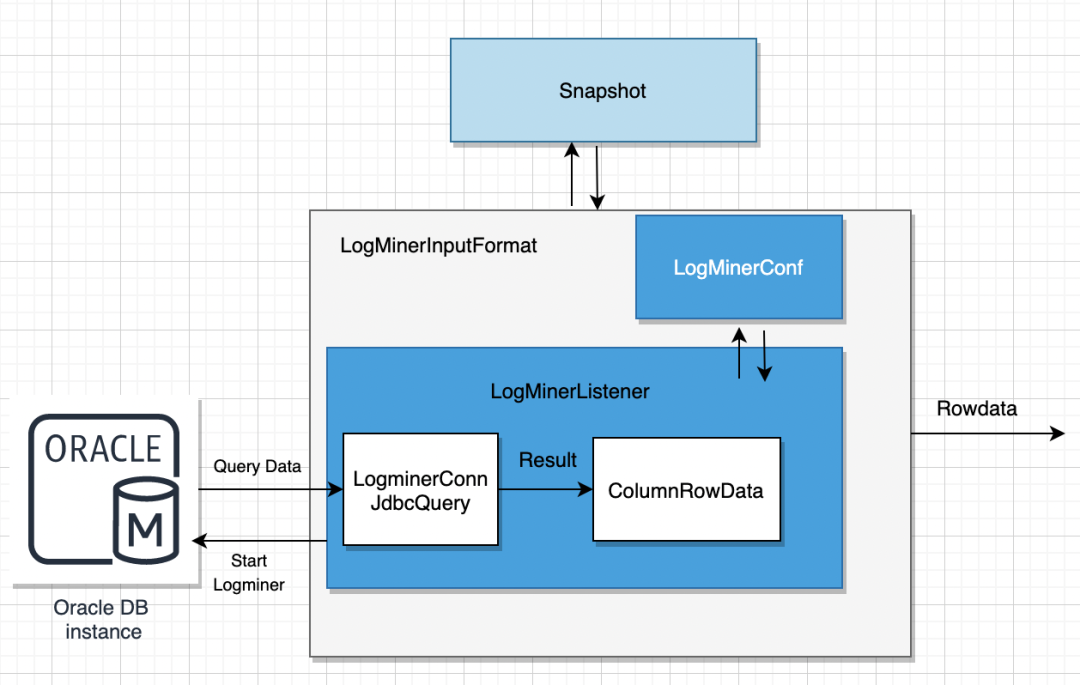
04 ChunJunデータフロー
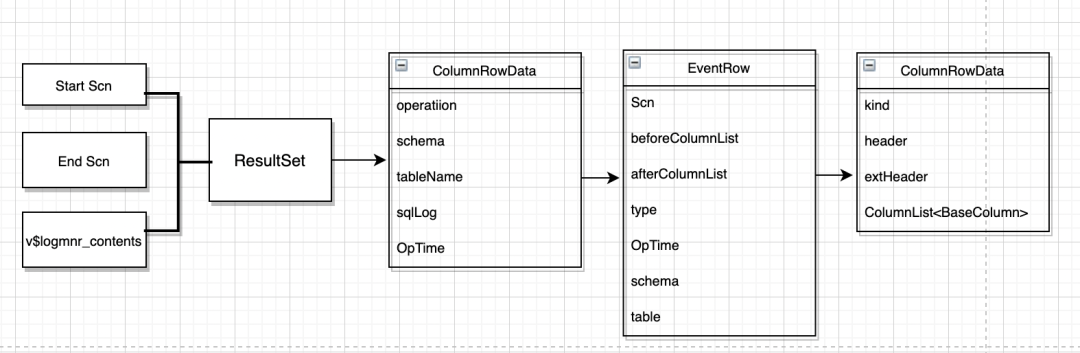
05 ChunJun動的実行
新しく追加されたテーブルからのデータを含む複数のテーブルの監視に直面した場合、ダウンストリーム書き込みをどのように実行しますか?
• サポート アップデートの変換前、変換後
• 拡張パラメータ、DB、Schema、Table、ColumnInfo を追加
• PreparedStatement の動的構築をサポート
06 ChunJunインターバルポーリング
インターバルポーリングとは どうやってそれをするのですか?
• ポーリング フィールドの型を確認してください。数値型ではなく、ソースの並列度が 1 より大きい場合、エラーはサポートされません。
• 3 つのデータ シャードを作成します。startlocation は null または構成された値です。mod はそれぞれ 0、1、2 です。
• SQL の構築: SQL ごとに異なる剰余関数があり、それぞれのプラグインによって実装されます。
(id > ? and ) mod(id, 3) = 0 id 順のテーブルから id,name,age を選択します。
(id > ? and ) mod(id, 3) = 1 order by id; テーブルから id,name,age を選択します。
(id > ? and ) mod(id, 3) = 2 order by id; テーブルから id,name,age を選択します。
• SQL を実行し、lastRow をクエリして更新する
• 最初の結果クエリの後、スクリプトで startlocation が構成されていない場合、前のクエリ SQL は次のようになります。
mod(id, 3) = 1 order by id; テーブルから id,name,age を選択します。
次のように更新します。
id > ? のテーブルから id、name、age を選択します。mod(id, 3) = 1 id 順;
• CP 中に lastRow の id 値を取得し、state に保存します。
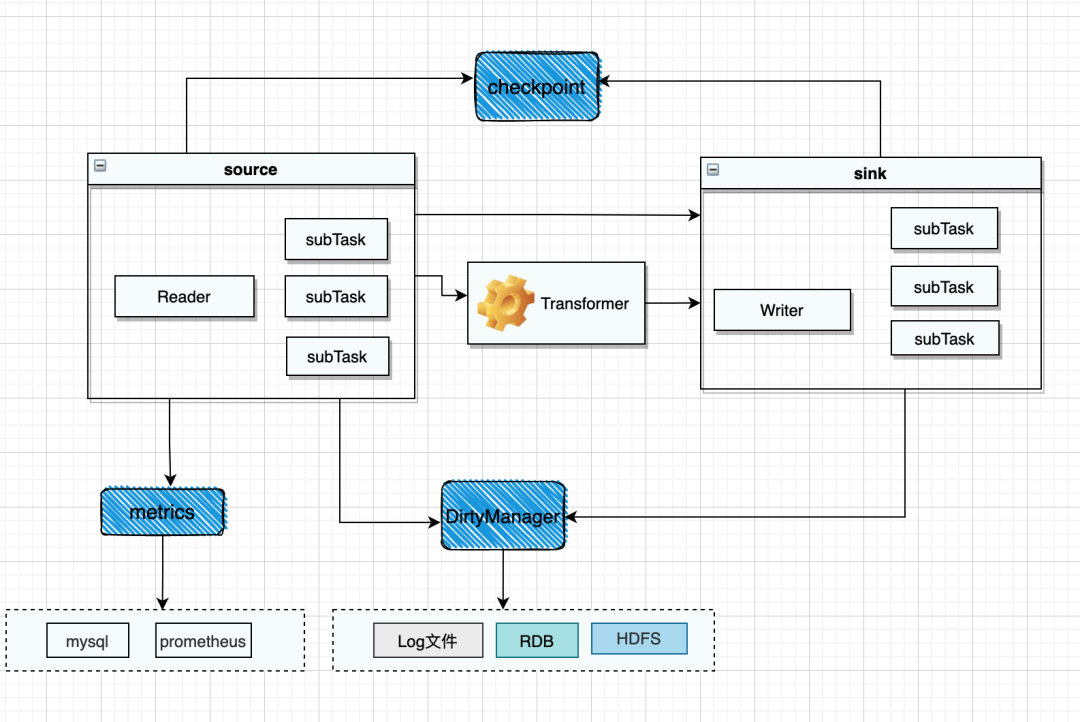
3.リアルタイムデータ復旧の実装と原理
01 データ復元入門
データ復元は、前述の Oracle Logminer や MySQL binglog など、該当するデータベースの CDC 収集機能に基づいており、キャプチャされたデータのダウンストリームへの完全な復元をサポートしているため、DML だけでなく、DDL も監視する必要があります。 、upstream データ ソースへのすべての変更は、ダウンストリーム データベースの復元に送信されます。
困難
DDL、DML が順序どおりにダウンストリームに送信される方法
ダウンストリーム データ ソースの特性に応じて DDL ステートメントが対応する操作を実行する方法 (異種データ ソース間の DML 変換)
DML ステートメントで挿入更新と削除を処理する方法
02 サンプル

03 全体の流れ
データが上流のデータソースから取得され、一連のオペレーターによって処理された後、データは元のテーブルのデータの順序に従ってターゲットデータソースに正確に復元され、リアルタイムデータ取得リンクが完了します.
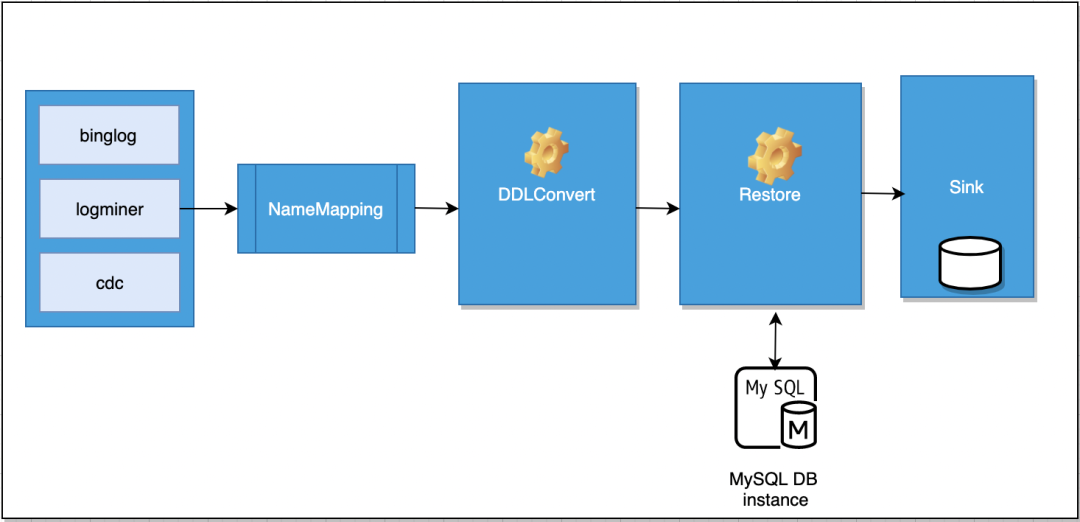
04 DDL分析

データ復元 - DDL 変換
· Calcite 解析データ ソース DdlSql から SqlNode に基づく
・SqlNodeを中間データDdlDataに変換
· ddlData から sql: 異なる構文間の変換; 異なるデータ ソース フィールド タイプの相互変換
05 ネームマッピング
リアルタイム復元では、現在の上流と下流のテーブル フィールドの対応が同じである必要があります。つまり、上流のデータベース スキーマ テーブルに対応するテーブルは、下流のデータベース スキーマ テーブルと同じテーブルにのみ書き込むことができ、フィールド名はも同じでなければなりません。この繰り返しにより、テーブル パスのカスタム マッピングとフィールド タイプのカスタム マッピングが実行されます。
• データベースまたはスキーマの変換
• テーブル名の変換
• フィールド名 (大文字と小文字の変換あり)、型の暗黙的な変換
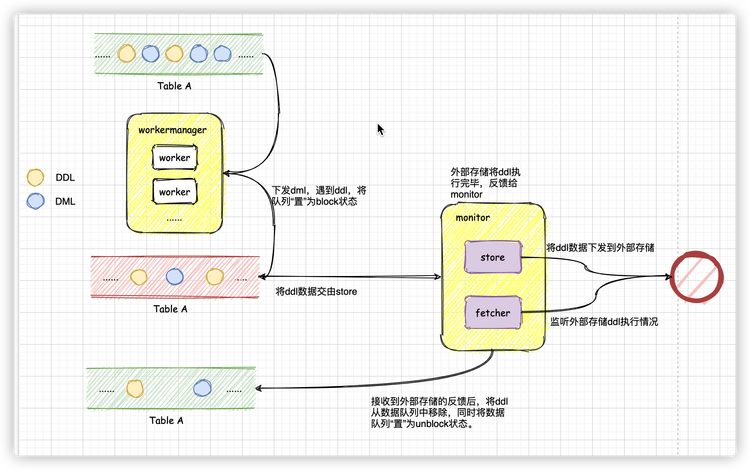
06 中間データキャッシュ
データ (ddl データまたは dml データのいずれか) は、対応するテーブル名の下のブロック解除キューに送信されます. ポーリング プロセス中に、ワーカーはブロック解除データ キュー内のデータを処理します. ddl データに遭遇した後、データ キューはブロック状態 そして、処理のためにストアへのキュー参照を渡します。
ストアは、キュー参照を取得した後、キューの先頭にある ddl データを外部ストレージに送信し、ddl に関する外部ストレージのフィードバックを監視します (監視作業は、ストア内の追加のスレッドによって実行されます)。時、キューはまだブロック状態です。
外部ストレージからのフィードバックを受け取った後、データ キューの先頭にある ddl データを削除し、キューの状態をブロック解除状態に戻し、キューの参照をワーカーに返します。
07 宛先がデータを受信する
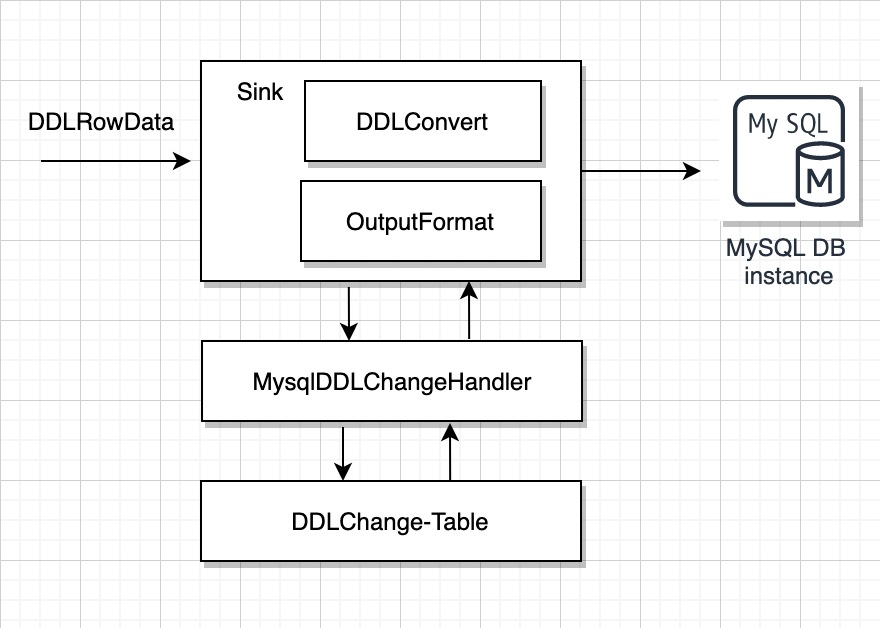
• DdlOperator オブジェクトを取得する
• ターゲット データ ソースに対応する DDLConvertImpl パーサーに従って、ターゲット データ ソース sql に変換します。
• テーブルの削除など、対応する SQL を実行する
• DDLChange テーブルを調整し、対応する DDL ステータスを変更するトリガー
• 中間ストア オペレータを復元し、状態の変化を監視し、その後のデータ配信操作を実行します
4. チュンジュンの今後の予定
• セッション管理の提供
•ChunJun自体をサービスとして提供し、周辺システムとの統合が容易な、安らかなサービスを提供します
• より多くのデータ ソースをサポートするための拡張 DDL 解析など、リアルタイム データ復元の機能強化
また、今回シェアした全文動画コンテンツも随時視聴可能ですので、興味のある方はカンガルークラウドB駅のプラットフォームでご覧ください。
Apache Hadoop ミートアップ 2022
ChunJun ビデオ レビュー:
https://www.bilibili.com/video/BV1sN4y1P7qk/?spm_id_from=333.337.search-card.all.click
Kangaroo Cloud Open Source Framework DingTalk Technology Exchange Group (30537511) は、ビッグデータ オープン ソース プロジェクトに関心のある学生を歓迎し、最新の技術情報に参加して交換します。オープン ソース プロジェクト ライブラリのアドレス: https://github.com/DTStack/Taier