In recent years, governments and enterprises at all levels have responded to the call for digital transformation and have begun or are about to begin digital transformation. Various enterprises have accumulated a large amount of data through the online and informatization of their businesses in the early stage, and digital transformation is to aggregate these data, conduct in-depth mining and analysis, use data to drive business, use data to support decision-making, and use data to promote business. And business model innovation, promote business process optimization, and then achieve cost reduction and efficiency increase.
To realize the value of data, building a data warehouse is a task that has to be faced in the process of digital transformation. The data warehouse aggregates the data of various business departments, avoids data silos, and makes the data truly become the data of the entire enterprise, rather than the data of a certain department.
The technical architecture of data warehouse includes offline data warehouse and real-time data warehouse or quasi-real-time data warehouse. Offline data warehouses have been developed for many years, and currently they cannot fully meet the development needs of enterprises to stand out from the competition. Real-time data warehouses are increasingly becoming the first choice for enterprises to build data warehouses. However, due to the strict real-time requirements of real-time data warehouses, the technical difficulty of realizing real-time data warehouses is far greater than that of offline data warehouses. Some existing real-time data warehouse architectures can only achieve quasi-real-time, and cannot solve the problem of peak-shaving and valley-free, senseless expansion, etc.
This article provides you with an efficient real-time data warehouse architecture: a real-time data warehouse architecture based on Amazon Cloud Technology's Serverless architecture.
Appreciation of common scenarios of real-time data warehouse and the practice of Amazon cloud technology
Let's first appreciate the common real-time data warehouse scenarios and the successful implementation of the real-time data warehouse of Amazon Cloud Technology's Serverless architecture:
1. Real-time collection and analysis of APP embedded data (for example: real-time intelligent recommendation, real-time fraud detection)
Here, we take the intelligent recommendation scenario as an example: according to the user's historical purchase or browsing behavior, the user's interests and needs are predicted through the recommendation algorithm, and the most suitable recommended assets (may be short videos, advertisements, and animations) are selected from the mass of recommended assets. to push. The recommendation system is developing rapidly, and the requirements for delay are becoming more and more stringent and real-time. Businesses often hope that customers can make dynamic recommendations based on current behavior and historical data when they use the app (or browse the web).
The data sources are generally collected from the app buried point and historical browsing data, consumption data, and advertising assets.
Common practice: Flume, Kafka and other tools may be used for streaming ETL and data synchronization and transmission, and big data computing tools such as ClickHouse, Flink, and Spark may be used for calculation. There are various types of data sources and data consumers, which will not be expanded here. (The same technical architecture also appears in scenarios such as real-time fraud detection)
Let's take a look at the case of Amazon Cloud Technology: use Amazon Kinesis Data Streams (streaming data access product, Amazon KDS) to access APP buried point data in real time to Amazon Redshift (cloud native data warehouse) for indicator analysis and BI show. It supports data ingestion rate up to 300,000/second, and the delay is less than 10 seconds; while the data is ingested into the data warehouse in real time, it supports high concurrent real-time query, and supports various SQL queries such as large-width table multi-table association, complex aggregation, etc. The result is a second-level response.

Figure 1 Real-time data warehouse architecture--APP real-time collection and analysis of embedded point data
2. RDBMS CDC+KDS+Amazon Redshift Serverless (real-time BI reports, complex event processing)
In this case, the source log data and the change data dynamic capture (CDC) of RDS structured data are mainly collected. This is a very common requirement of a data warehouse. When an external database system (account, deposit, manufacturing, human resources, etc.) is used as a data source, the business team needs to dynamically access the CDC log data to the data warehouse to achieve real-time analysis requirements, such as real-time BI reporting, complex event processing (emergency response).
CDC log data is sent to Amazon KDS in real time through Amazon Kinesis. After stream processing, the result is written to RDS, and API is provided for third-party query. At the same time, Amazon Redshift can directly consume Kinesis data for query analysis, and the overall delay is less than 30 seconds.
Various CDC log collection methods are supported, including Amazon DMS, Debezium, Flink CDC, Canal, etc. After the collected data is written to Kinesis, the Amazon Redshift Streaming Ingestion function is used to write the CDC data to Amazon Redshift in real time.
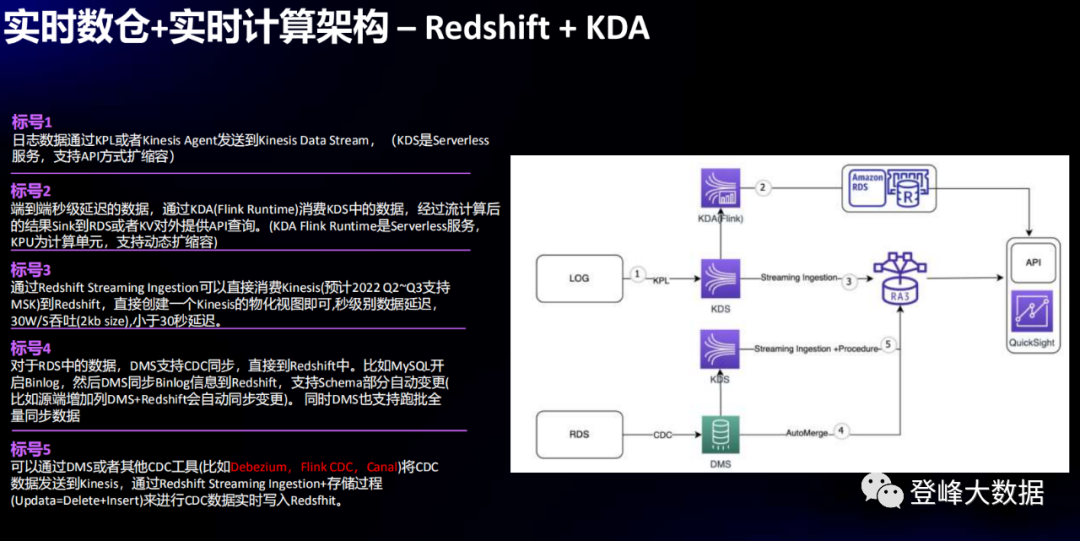
Figure 2 Real-time data warehouse--RDBMS CDC+KDS+Amazon Redshift Serverless
Classic Solution —Building a Cloud Native Data Warehouse with Amazon Redshift
Before proceeding further, we need to introduce a product that cannot be bypassed - Amazon Redshift, a fast, scalable, secure and fully managed cloud data warehouse that can help users analyze various types of data simply and cost-effectively through standard SQL language .
Whether building a traditional data warehouse architecture or a real-time data warehouse architecture, Amazon Redshift users can deploy in one-stop. Compared to other cloud data warehouses, Amazon Redshift can achieve up to three times the price-performance ratio. Tens of thousands of customers are processing exabytes of data every day with Amazon Redshift, powering high-performance business intelligence (BI) reporting, dashboard applications, data exploration, real-time analytics, and other analytical workloads, as well as machine learning, data mining . Amazon Redshift supports ACID transaction features, ANSI SQL standard, MPP schema columnar storage data warehouse with JDBC/ODBC connection protocol. Amazon Redshift can not only perform data analysis based on its own internal tables, but also query data in Amazon S3. S3 is an extremely elastic object storage. It has become the de facto standard for data lakes on the cloud. It can store structured Data can also be semi-structured data or unstructured data. Redshift and S3 can be seamlessly combined to realize the intelligent lake warehouse architecture.
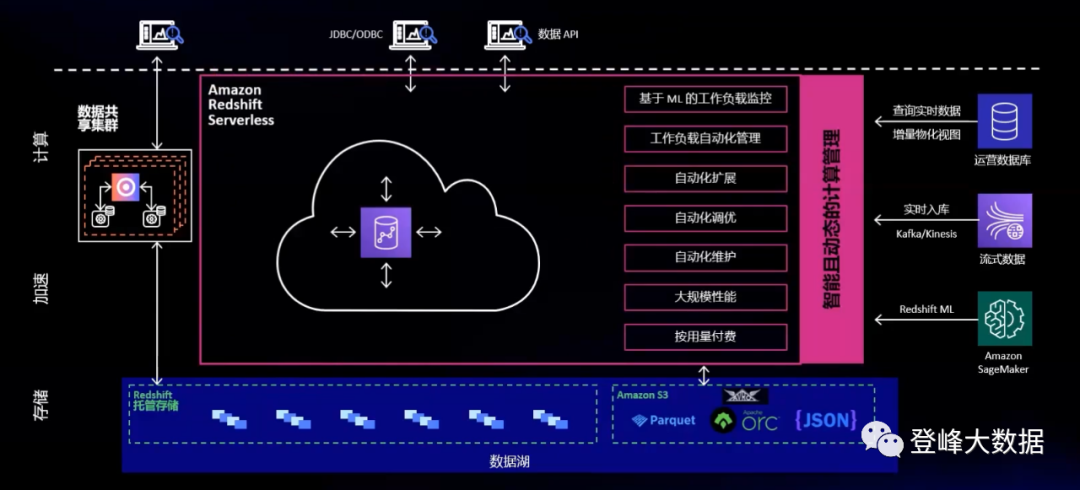
Figure 3 Amazon Redshift Serverless Architecture
Problems to be solved by the real-time data warehouse architecture
A good real-time data warehouse architecture can solve the following four problems: real-time data access, real-time data analysis, and real-time data output.
-
Real-time data access: The data warehouse is mainly used to store data from various business systems. The first step in the real-time data warehouse is to solve the problem of how to enter the data warehouse in real time.
-
Real-time data analysis: The data accessed in real time must be available immediately to meet the needs of ad hoc query, report analysis, and mining prediction, with accurate data and low latency.
-
Real-time data output: The results of real-time data analysis must be able to display BI reports in a timely manner and provide them to third parties in the form of data services.
-
Real-time data warehouse intelligence: data analysis solves what happened in the past, and data warehouse intelligence solves what will happen in the future. Making real-time data warehouses capable of machine learning and intelligent prediction is an essential function for realizing intelligent lake warehouses.
The serverless architecture not only makes up for the shortcomings of traditional offline data warehouses, but also perfectly solves the above four problems. Let’s first look at the overall real-time data warehouse architecture diagram:
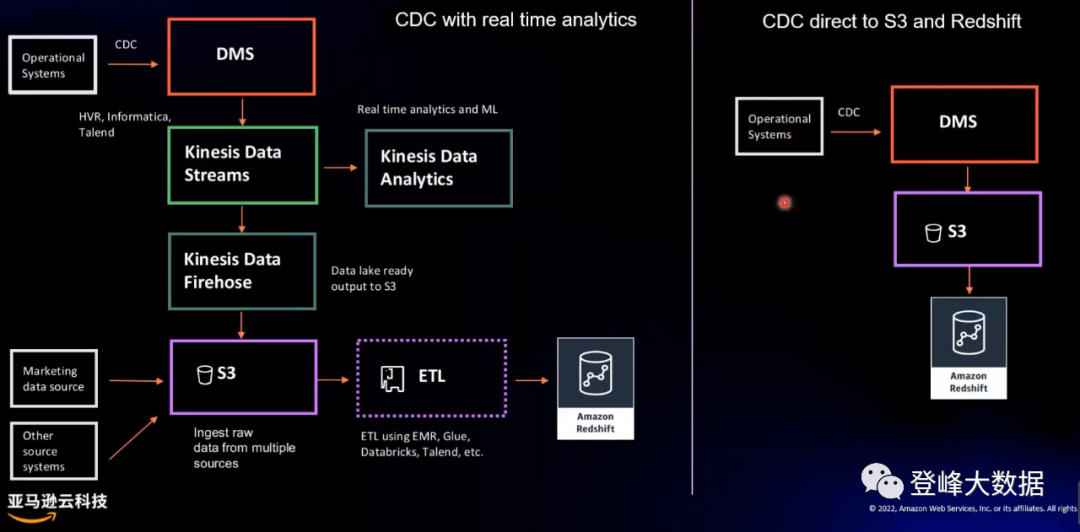
Figure 4 Amazon Cloud Technology Serverless real-time data warehouse architecture diagram
Serverless real-time data warehouse architecture adopts Amazon KDS (Amazon Kinesis Data Streams) + Amazon Redshift Serverless+Redshift ML+S3 technology product combination, KDS is responsible for real-time data access, Redshift Serverless+Redshift ML+S3 is responsible for the implementation of "smart lake warehouse" , to realize real-time data analysis, real-time output, and real-time prediction. At the same time, Redshift Serverless architecture, simple operation and maintenance, on-demand billing, cost reduction and efficiency increase, freeing customers from complicated structure construction, monitoring, operation and maintenance, focusing on data query analysis, data value mining, and realizing data-driven decision making.
-
Real-time data access: The data accessed can be divided into three categories: structured data (database data), semi-structured data (Json, CSV data) and unstructured data (picture video data).
For structured data originating from databases, a common real-time access method is incremental access using CDC technology. In the real-time data warehouse architecture of Amazon Cloud Technology, Amazon DMS products are used to access CDC data to Amazon KDS. Amazon DMS supports homogeneous migration, heterogeneous migration between different database platforms, and CDC data access, enabling low-latency, continuous replication of data from any supported source to any supported destination. Additionally, data from Kinesis can be ingested into Amazon Redshift with very low latency using Amazon Redshift streaming ingestion.
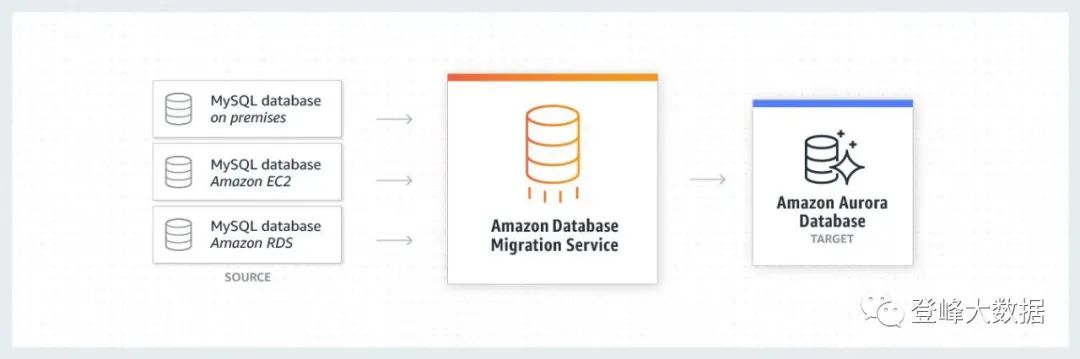
Figure 5 Amazon Database Migration Service (Amazon DMS) migrates data to Smart Lake Warehouse
For unstructured data, the traditional real-time access method is to scan the specified directory, write the new file into the file system (HDFS, Amazon S3, etc.), and then develop a program to parse the file and write it into the database table. However, using the DMS+S3+Redshift method provided by Amazon Cloud Technology, there is no need to develop a data parsing program, and data can be written to S3 through simple configuration. Redshift can be perfectly integrated with S3, that is, the data can be entered into S3. Query analytics in Redshift.
-
Real-time data analysis: The real-time analysis of data is provided by Amazon Redshift Serverless. All layers of the smart lake warehouse are created in the Redshift database. SQL statements are used to calculate data warehouse indicators, and ETL tools are used to schedule indicator calculation tasks. It is compatible with open source ETL tools. , you can also use Amazon's ETL tools.
-
Real-time data output: Amazon Redshift supports the JDBC protocol and can be used as a data source for various BI report products to achieve real-time data output; Amazon Redshift Data API can provide data to third parties in the form of API, Amazon Redshift Data API does not need to be connected with A persistent connection to the cluster. Provides secure HTTP endpoints and integration with the Amazon Cloud Technology SDK. Use endpoints to run SQL statements without managing connections. Calls to the Data API are asynchronous.
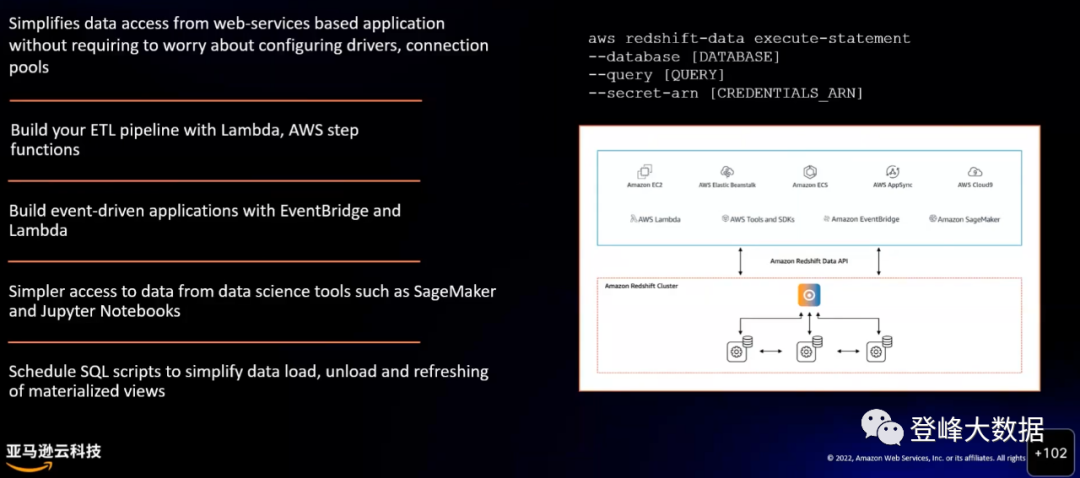
Figure 6 Amazon Redshift Data API
-
Amazon Redshift real-time data warehouse + ML: Adding machine learning and artificial intelligence capabilities to real-time data warehouses is a difficult problem faced by most companies in the process of building real-time data warehouses. The main problems are: 1. The threshold for machine learning is high; 2. , Recruitment of machine learning developers is difficult. The Amazon Redshift real-time data warehouse architecture uses Amazon Redshift ML products to solve the above difficulties, greatly reducing the difficulty of building smart lake warehouses.
Amazon Redshift ML makes it easy for SQL users to create, train, and deploy machine learning models using familiar SQL commands. Using Amazon Redshift ML, you can use data from a Redshift cluster to train models with Amazon SageMaker. The model is then localized and can make predictions in the Amazon Redshift database. With Amazon Redshift ML, you don't need to move data or learn new skills to take advantage of Amazon SageMaker, a fully managed machine learning service.
With Amazon Redshift ML powered by Amazon SageMaker, use SQL statements to create and train machine learning models from data in Amazon Redshift, and then use those models for a variety of use case scenarios, such as churn prediction directly in queries and BI reports and Fraud Risk Score.
By writing SQL statements to develop machine learning functions, the complexity of various underlying machine learning algorithms is resolved by Amazon Redshift ML, and customers can focus more on business.
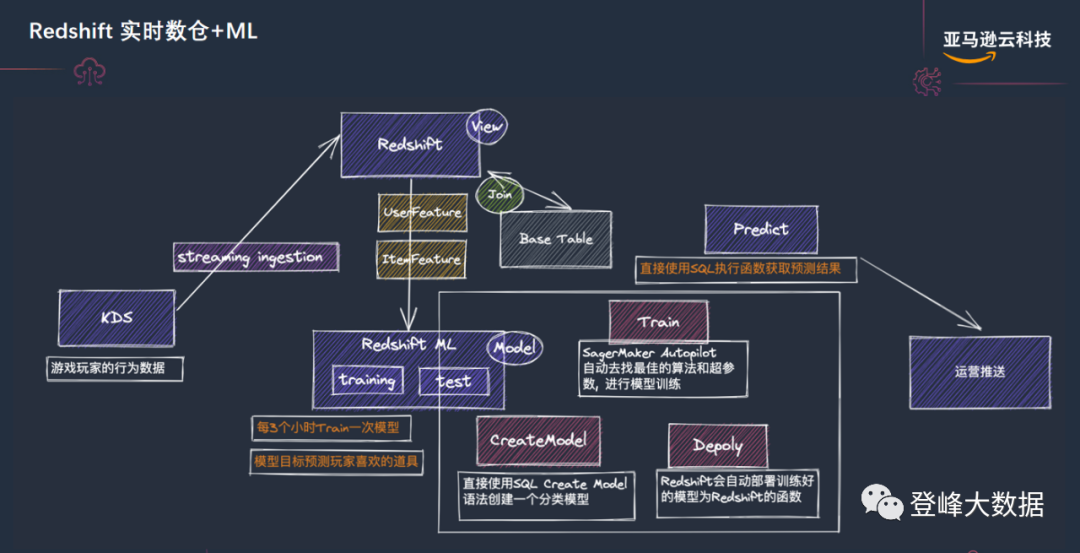
Figure 7 A mazon Redshift real-time warehouse + ML
Advantages of serverless real-time data warehouse architecture
A mature technical architecture can greatly reduce the human and financial costs of enterprises. The traditional real-time data warehouse architecture (using a managed server) cannot achieve peak-shaving and valley-shaving. Taking the e-commerce industry as an example, the server resources of the real-time data warehouse architecture must be able to cope with the pressure brought by data peaks (various large-scale events, promotions, and other unpredictable workloads), so hardware procurement is often based on resource peaks. , the result is that most of the resources are idle most of the time, which invisibly increases the cost of the enterprise; the traditional real-time data warehouse architecture cannot achieve inductive expansion, that is, the increase and decrease of server cluster nodes will increase the workload of operation and maintenance personnel. There may be a suspension of business. In general, the advantages of the serverless real-time data warehouse architecture include the following:
-
The serverless real-time data warehouse architecture enables the data warehouse to elegantly have real-time data analysis capabilities (real-time OLAP kanban, real-time business monitoring);
-
Serverless real-time data warehouse architecture makes real-time intelligent analysis possible (real-time risk control/real-time recommendation/real-time machine learning based on real-time data and historical data);
-
Amazon Cloud Technology provides the most comprehensive functional components for building real-time data warehouses on the cloud, allowing users to build their own real-time data warehouses with agility, efficiency, and low cost;
- Using the serverless real-time data warehouse cloud platform, it automatically has the advantages of cutting peaks and flat valleys, non-inductive expansion, simple operation and maintenance, and easy to use.
Reprinted from Dengfeng Big Data
Link: https://mp.weixin.qq.com/s/CWIppvQIMrwX4z2iVV-G1g