With the development of the big data industry, the related technologies in the big data ecosystem have also been iteratively progressing. The author is fortunate to have personally experienced the development process of the domestic big data industry from zero to one. Through this article, I hope to help you quickly build a big data ecosystem complete knowledge system.
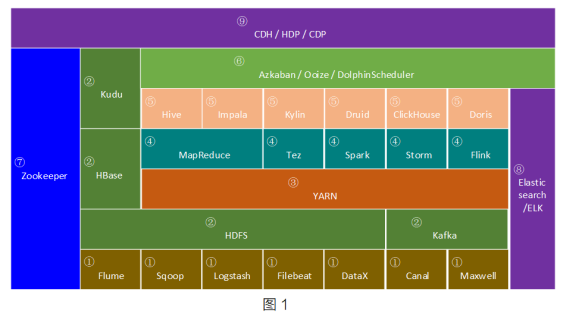
At present, the core technologies in the big data ecosystem are summarized as shown in Figure 1, and are divided into the following 9 categories, which are introduced separately below.
1. Technical framework of data collection
Data acquisition is also known as data synchronization. With the rise of technologies such as the Internet, mobile Internet, and the Internet of Things, massive amounts of data have been generated. These data are scattered in various places, and we need to fuse these data together, and then calculate some valuable content from these massive data. The first step is to collect the data. Data collection is the foundation of big data, without data collection, what about big data!
The technical framework of data collection includes the following:
-
Flume, Logstash and FileBeat are often used for real-time monitoring and collection of log data. The detailed differences between them are shown in Table 1:

-
Sqoop and Datax are often used for offline data collection of relational databases. The detailed differences between them are shown in Table 2:

-
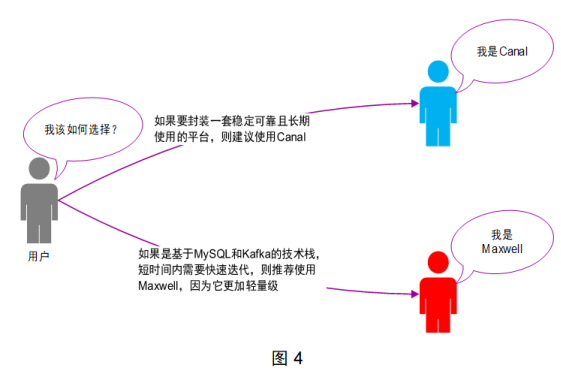
Cannal and Maxwell are often used for real-time data collection in relational databases. The detailed differences between them are shown in Table 3:

The technical selection of Flume, Logstash and FileBeat is shown in Figure 2:

The technology selection between Sqoop and Datax is shown in Figure 3:

The technology selection between Cannal and Maxwell is shown in Figure 4:
2. Data storage technology framework
The rapid growth of data has promoted the development of technology, and a number of excellent and distributed storage systems have emerged.
Data storage technology frameworks include HDFS, HBase, Kudu, Kafka, etc.
-
HDFS can solve the problem of mass data storage, but its biggest disadvantage is that it does not support the modification operation of a single piece of data, because it is not a database after all.
-
HBase is a distributed NoSQL database based on HDFS. This means that HBase can utilize the massive data storage capabilities of HDFS and support modification operations. But HBase is not a relational database, so it cannot support traditional SQL syntax.
-
Kudu is a technical component between HDFS and HBase, which supports both data modification and SQL-based data analysis functions. At present, Kudu's positioning is awkward, it is a compromise solution, and its application in practical work is limited.
-
Kafka is often used for temporary buffer storage of massive data, providing high-throughput read and write capabilities to the outside world.
3. Distributed resource management framework
In the traditional IT field, an enterprise's server resources (memory, CPU, etc.) are limited and fixed. However, the application scenarios of the server are flexible and changeable. For example, a system is temporarily online today, which needs to occupy several servers; after a few days, the system needs to be taken offline and these servers need to be cleaned up.
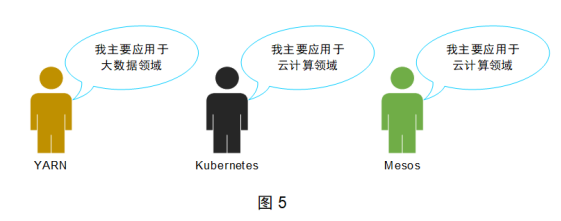
Before the advent of the era of big data, changes in server resources corresponded to the online and offline of the system, and these changes were limited. With the advent of the era of big data, the demand for temporary tasks has increased greatly, and these tasks often require a lot of server resources. It is obviously unrealistic to rely on operation and maintenance personnel to manually connect changes to server resources at this time. Therefore, distributed resource management systems emerge as the times require. Common ones include YARN, Kubernetes, and Mesos. Their typical application areas are shown in Figure 5.
4. Data Computing Technology Framework
Data calculation is divided into offline data calculation and real-time data calculation.
1. Offline data calculation
After more than ten years of development, the offline data computing engine in big data has undergone three major changes so far.
-
MapReduce can be regarded as the first generation of offline data computing engine in the big data industry, which is mainly used to solve distributed parallel computing of large-scale data sets. The core idea of the MapReduce computing engine is to abstract the computing logic into two stages of Map and Reduce for processing.
-
The Tez computing engine has a weak presence in the big data technology ecosystem, and Tez is rarely used alone to develop computing programs in actual work.
-
The biggest feature of Spark is in-memory computing: all intermediate results in the task execution phase are placed in memory, and there is no need to read and write to disk, which greatly improves the computing performance of data. Spark provides a large number of higher-order functions (also called operators), which can implement iterative calculations of various complex logics, and are very suitable for fast and complex computing requirements for massive data.
2. Real-time data calculation
The most typical real-time data computing scenario in the industry is the big data screen of Tmall's "Double Eleven". The data indicators such as the total transaction amount and the total order volume displayed in the big data screen are all calculated in real time. After the user purchases the product, the amount of the product will be added to the total transaction amount in the big data screen in real time.
-
Storm is mainly used to realize distributed computing of real-time data.
-
Flink is a new generation of real-time data distributed computing engine, and its computing performance and ecosystem are better than Storm.
-
The SparkStreaming component in Spark can also provide real-time data distributed computing functions based on seconds.
The differences between him and Storm and Flink are shown in Table 4.
The technical selection between Storm, Spark, and Flink is shown in Figure 6.
At present, Spark is mainly used for offline computing in enterprises, and Flink is mainly used for real-time computing.
Five, data analysis technology framework
Data analysis technical frameworks include Hive, Impala, Kylin, Clickhouse, Druid, Drois, etc. Their typical application scenarios are shown in Figure 7.

Hive, Impala, and Kylin are typical offline OLAP data analysis engines, which are mainly used in the field of offline data analysis. The differences between them are shown in Table 5.

table 5
-
The execution efficiency of Hive is average, but the stability is extremely high;
-
Impala can provide excellent execution efficiency based on memory, but the stability is general;
-
Kylin can provide millisecond-level response to petabyte-level data through precomputing.
Clickhouse, Druid, and Drois are typical real-time OLAP data analysis engines, which are mainly used in real-time data analysis. The differences between them are shown in Table 6.
-
Druid and Doris can support high concurrency, and ClickHouse has limited concurrency capabilities; Druid's SQL support is limited, ClickHouse supports non-standard SQL, and Doris supports standard SQL, which is better for SQL.
-
At present, Druid and ClickHouse are relatively mature, and Doris is in a stage of rapid development.
6. Task scheduling technical framework
Including Azkaban, Ooize, DolphinScheduler, etc. They are suitable for routine tasks executed at ordinary timings, as well as multi-level tasks containing complex dependencies for scheduling, support distribution, and ensure the performance and stability of the scheduling system. The difference between them is shown in Table 7.
Their previous technology selections are shown in Figure 8.
7. The underlying basic technical framework of big data
The underlying basic technical framework of big data mainly refers to Zookeeper. Zookeeper mainly provides common basic functions (such as namespaces, configuration services, etc.), and Zookeeper is used in the operation of technical components such as Hadoop (HA), HBase, and Kafka in the big data ecosystem.
8. Data retrieval technology framework
With the gradual accumulation of data in the enterprise, the requirements for statistical analysis of massive data will become more and more diverse: not only analysis, but also fast and complex queries with multiple conditions. For example, the commodity search function in e-commerce websites and the information retrieval function in various search engines belong to the category of fast and complex queries with multiple conditions.
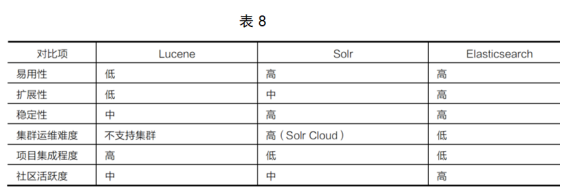
When choosing a full-text search engine tool, comparisons can be made in terms of ease of use, scalability, stability, difficulty in cluster operation and maintenance, project integration, and community activity. The comparison of Lucene, Solr and Elasticsearch is shown in Table 8.
Nine, big data cluster installation management framework
If an enterprise wants to transform from traditional data processing to big data processing, the first thing to do is to build a stable and reliable big data platform.
A complete big data platform needs to include data collection, data storage, data calculation, data analysis, cluster monitoring and other functions, which means that it needs to include Flume, Kafka, Haodop, Hive, HBase, Spark, Flink and other components. It needs to be deployed to hundreds or even thousands of machines.
If you rely on the operation and maintenance personnel to install each component separately, the workload is relatively large, and the matching problem between versions and various conflicts need to be considered, and the later cluster maintenance work will also cause great pressure on the operation and maintenance personnel.
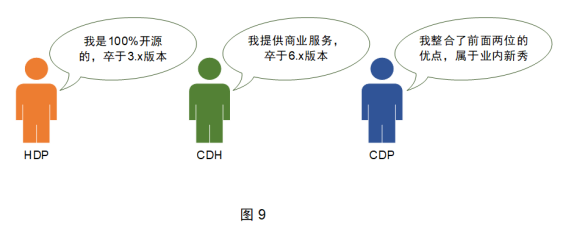
Therefore, some foreign manufacturers have packaged the components in the big data, providing an integrated big data platform, which can be used to quickly install the big data components. At present, the most common ones in the industry include CDH, HDP, CDP, etc.
-
HDP: The full name is Hortonworks Data Platform. It is packaged by Hortonworks based on Apache Hadoop, provides interfaced installation and management with the help of Ambari tools, and integrates common components in big data, providing one-stop cluster management. HDP is an open source free big data platform and does not provide commercial services;
-
CDH: The full name is Cloudera Distribution Including Apache Hadoop. It is commercialized by Cloudera based on Apache Hadoop. It provides interfaced installation and management with the help of Cloudera Manager tool, and integrates common components in big data to provide one-stop cluster management. CDH is a commercial charging big data platform, which can be tried for 30 days by default. After that, if you want to continue to use advanced functions and commercial services, you need to pay for the license, and if you only use basic functions, you can continue to use it for free;
-
CDP: Cloudera acquired Hortonworks in October 2018, and then launched a new generation of big data platform product CDP (Cloudera Data Center). The CDP version number is a continuation of the previous CDH version number. As of version 7.0, CDP supports Private Cloud (private cloud) and Hybrid Cloud (hybrid cloud). CDP integrates the better components of HDP and CDH, and adds some new components.
The relationship between the three is shown in Figure 9.