
Pour transformer numériquement l'entreprise, l'IA doit être en temps réel. Pour que l'IA soit en temps réel, nous avons besoin d'analyses en temps réel. [1]
Le traitement transactionnel/analytique hybride ( HTAP ) est une architecture d'application émergente qui « brise le mur » entre le traitement transactionnel et l'analytique. Il permet une prise de décision plus éclairée et "en temps réel de l'entreprise".
——Défini par Gartner
Contexte - Présentation
Depuis le premier jour de l'open source de StoneDB, nous avons dit que nous voulions faire du vrai HTAP, alors comment comprenons-nous HTAP ? Pour interpréter une technologie, il faut commencer par son contexte de développement. Dans cet article, nous présenterons des concepts liés à HTAP basés sur le développement récent d'OLTP et d'OLAP et les problèmes qu'ils rencontrent.


OLTP : fonctionnalités, scénarios applicables, problèmes rencontrés, derniers développements
Le traitement des données transactionnelles est appelé traitement des transactions en ligne (On Line Transaction Processing, OLTP). Le principal scénario d'utilisation du système OLTP consiste à enregistrer les enregistrements d'interaction entre les opérations quotidiennes et le système métier, et à prendre en charge l'analyse des requêtes avec ces données pour obtenir des résultats d'analyse.
Les données transactionnelles font référence aux informations utilisées pour suivre les interactions liées aux activités organisationnelles, souvent : les transactions commerciales. Par exemple : les paiements reçus des clients, les paiements effectués aux fournisseurs, les produits déplacés de l'inventaire, les commandes acceptées ou les services fournis. Les événements de transaction, qui représentent la transaction elle-même, contiennent généralement une dimension temporelle, des valeurs numériques, etc.
Les transactions nécessitent généralement atomicité et cohérence. L' atomicité signifie que l'ensemble de la transaction réussit ou échoue toujours en tant qu'unité de travail, jamais dans un état à moitié terminé. Si une transaction ne peut pas être achevée, le système de base de données doit annuler toute partie achevée du travail de la transaction, garantissant ainsi que l'ensemble du travail se termine ou échoue. La cohérence signifie qu'une transaction a toujours des données dans un état valide final, et si une partie d'une transaction a été validée dans la base de données, toutes les autres opérations dans la portée de cette transaction source seront également finales et validées dans la base de données. Les bases de données transactionnelles peuvent prendre en charge une forte cohérence des transactions à l'aide de diverses stratégies de verrouillage, telles que le verrouillage pessimiste, pour garantir que toutes les données de tous les utilisateurs et processus sont fortement cohérentes dans le contexte de l'entreprise.
L'architecture de déploiement la plus courante pour les données transactionnelles est une architecture à trois niveaux. Dans cette architecture, les données transactionnelles sont utilisées au niveau de la couche de stockage des données. L'architecture à trois niveaux comprend généralement : une couche de présentation, une couche de logique métier et une couche de stockage de données.
Scène applicable
Si le système de l'entreprise a des contraintes sur l' intégrité des données et les performances en temps réel , et qu'il doit en même temps garantir une intégrité stricte des données pendant le traitement de l'entreprise, et que les données modifiées nécessitent une persistance stricte, alors OLTP sera votre premier choix. En effet, les systèmes OLTP sont conçus pour traiter et stocker efficacement les transactions, ainsi que pour interroger les données transactionnelles.
relever le défi
La mise en œuvre et l'utilisation d'un système OLTP peuvent présenter certains défis :
(1) Les systèmes OLTP ne sont pas particulièrement adaptés au traitement de requêtes complexes dans des scénarios de données volumineuses. Dans les scénarios de requête complexes avec de grandes quantités de données, le système OLTP consomme beaucoup de ressources informatiques et de ressources de stockage, de sorte que l'exécution peut être lente. De plus, si d'autres transactions fonctionnent également sur les données de certaines requêtes complexes à ce moment-là, le mécanisme de verrouillage du système sera souvent déclenché, ce qui entraînera une diminution des performances de l'ensemble du système.
(2) Dans le système OLTP, la convention de dénomination des objets de base de données est généralement concise et raffinée, ce qui nécessite une haute qualité professionnelle des utilisateurs professionnels. La combinaison d'une normalisation améliorée et de conventions de dénomination concises dans les systèmes OLTP rend difficile pour les utilisateurs professionnels d'exécuter des requêtes sans l'aide d'un administrateur de base de données ou d'un développeur de données.
(3) L'historique et le stockage d'une trop grande quantité de données dans une table peuvent ralentir les performances des requêtes. Une solution courante consiste à conserver une période pertinente (par exemple, l'exercice en cours) dans le système OLTP et à décharger les données historiques vers d'autres systèmes, par exemple un entrepôt de données.

OLAP : fonctionnalités, scénarios applicables, problèmes rencontrés, derniers développements
Le traitement analytique en ligne (OLAP), ou OLAP en abrégé, est une méthode utilisée pour résoudre rapidement des problèmes d'analyse multidimensionnelle. OLAP fait partie d'une catégorie plus large d'informatique décisionnelle qui comprend également les bases de données relationnelles, la rédaction de rapports et l'exploration de données.
La base de données qu'une entreprise utilise pour stocker toutes ses transactions et tous ses enregistrements est appelée base de données de traitement des transactions en ligne (OLTP). Ils contiennent souvent une mine d'informations précieuses pour l'organisation. Les bases de données OLTP ne sont pas conçues pour l'analyse. Par conséquent, la récupération des réponses à partir de ces bases de données est coûteuse en temps et en efforts. Les systèmes OLAP sont conçus pour extraire des informations de Business Intelligence à partir de données de manière très performante. En effet, les bases de données OLAP sont optimisées pour les lectures à haute fréquence et les écritures à basse fréquence.
Scène applicable
-
Besoin d'effectuer des analyses complexes et des requêtes ad hoc rapidement et sans impact négatif sur les systèmes OLTP ;
-
Fournir aux utilisateurs professionnels un moyen simple de générer des rapports basés sur des données ;
-
Fournit un grand nombre d'agrégats qui permettront aux utilisateurs d'obtenir rapidement des résultats réactifs. OLAP convient aux scénarios où une grande quantité de données et de requêtes sont principalement des calculs agrégés. Les systèmes OLAP sont optimisés pour les scénarios d'application de lecture à haute fréquence tels que l'analyse et l'informatique décisionnelle.
relever le défi
Les données des systèmes OLAP sont moins mises à jour, en fonction des besoins de l'entreprise, ce qui signifie que les systèmes OLAP sont mieux adaptés aux décisions commerciales de niveau stratégique plutôt qu'aux réponses immédiates aux changements . En outre, un certain niveau de nettoyage des données et des processus métier doivent être planifiés pour maintenir à jour les données du système OLAP.
Contrairement aux tables relationnelles normalisées traditionnelles utilisées dans les systèmes OLTP, les modèles de données d'OLAP sont souvent multidimensionnels, dans lesquels chaque attribut correspond à une colonne, ce qui est difficile ou impossible à mapper directement à des modèles entité-relation ou orientés objet .

OLTP VS OLAP
La comparaison entre OLTP et OLAP de différentes dimensions est la suivante :
| Cote de contraste | OLTP | OLAP |
|---|---|---|
| caractéristique d'une phrase | Scènes avec de nombreuses petites affaires | Scénarios qui utilisent des requêtes complexes pour traiter de plus grandes quantités de données |
| ACIDE | puissant | faible |
| Orienté utilisateur | opérateur de base de données | Décideurs politiques, cadres supérieurs, scientifiques de bases de données, analystes commerciaux et travailleurs du savoir |
| scènes à utiliser | Finance (comme les banques, les actions), le commerce électronique, la réservation de voyages, etc. | Applications d'intelligence d'affaires (BI), d'exploration de données et d'aide à la décision barométrique |
| Opération de base | Principalement : insérer, mettre à jour, supprimer principalement | Principalement pour les opérations d'agrégation, les opérations de fenêtre, etc. |
| Plage de données de fonctionnement | Généralement, la quantité de données lues et écrites est faible (dizaines d'enregistrements) | Généralement de grandes quantités de données à lire et à écrire (des millions d'enregistrements) |
| Indicateurs clés | Débit des transactions (TPS) | Vitesse de réponse aux requêtes (RPS) |
| exigences de temps de réponse | Exigences élevées en temps réel, généralement en millisecondes | Faibles exigences en temps réel, selon la quantité de données traitées, la plage de temps est comprise entre les heures, les minutes, les secondes, les sous-secondes, etc. |
| la source de données | Données de transaction en temps réel du système d'entreprise | Données historiques dans les systèmes d'entreprise, données transactionnelles |
| Spécification de conception de table de base de données | Généralement besoin de satisfaire trois formes normales (3NF) | non normatif |
| Volume de données/espace disque | Petit, niveau MB~TB | Grand, niveau GB ~ PB |
| Concurrence | Nécessité de prendre en charge un grand environnement simultané | Ne nécessite pas une forte simultanéité |
| la stabilité | Haut niveau | Haut niveau |
| Disponibilité (sauvegarde, restauration) | Sauvegarde complète, capacité de récupération (complète, incrémentielle) | La sauvegarde/restauration est principalement effectuée par point dans le temps, et les exigences de sauvegarde/restauration ne sont pas élevées |
| Exigences d'intégrité des données | Exigences de cohérence fortes | Les exigences d'intégrité des données ne sont pas élevées |
| Débit système, IOPS | Bas | haute |
| défi | 1. Haut débit, garantissant l'intégrité, la fiabilité des données… 2. Des outils écologiques complets, difficiles à coordonner et à utiliser entre différents produits hétérogènes ; |
1. Stockage de données efficace et à faible coût pour les données massives 2. Traitement efficace des requêtes complexes ; |
| exigences de fiabilité | Une fiabilité élevée est généralement requise : sauvegarde principale, reprise après sinistre dans la même ville, reprise après sinistre à distance | Les exigences de fiabilité sont relativement faibles et la reprise après sinistre générale dans la même ville |
| caractéristique de lecture | Principalement des requêtes simples, chaque requête ne renvoie qu'une petite quantité de données | Principalement des requêtes complexes, agrégeant de grandes quantités de données |
| fonction d'écriture | 1. Aléatoire, faible latence, petite quantité de données 2. Mises à jour et suppressions de données fréquentes |
1. Peu d'opérations de mise à jour et de suppression ; 2. Importation par lots et parallèle de gros volumes de données |
| modèle de données | ER (entité, relation) | étoile ou flocon de neige, constellation |
| granularité des données | enregistrement au niveau de la ligne | Plusieurs tableaux |
| Structure de données | Hautement structuré et complexe pour l'informatique opérationnelle | Simple et adapté à l'analyse |
| Champ de données | Changement dynamique, mise à jour par champ | Statique, rarement mis à jour directement, régulièrement ajouté et actualisé |
| valeur de retour des données | Généralement, l'enregistrement lui-même ou plusieurs colonnes de cet enregistrement | Généralement des résultats de calcul agrégés |
Au fil du temps, de plus en plus d'exigences commerciales pour AP sont de plus en plus conformes aux indicateurs TP, par exemple, le système AP doit refléter les données réelles dans le système TP actuel en temps réel. Dans le même temps, le système AP peut prendre en charge la mise à jour des données, etc. En un mot, la frontière entre le système TP et le système AP devient de plus en plus floue au niveau métier et au niveau utilisateur.Le marché est avide d'avoir une nouvelle architecture ou soi-disant solution, qui puisse satisfaire les exigences du métier. sur la charge TP en même temps et les exigences de charge AP. Ainsi, le concept de HTAP est né. En 2014 , Gartner a donné un concept clair de HTAP : des systèmes pouvant prendre en charge à la fois OLTP (traitement des transactions en ligne) et OLAP (traitement analytique en ligne) au sein d'une seule transaction.[4]

HTAP : Le but de l'introduction du concept HTAP, la définition, l'introduction de scénarios applicables, le moteur commercial de HTAP - la source du problème ?
moteurs d'activité
À l'heure actuelle, les méthodes de traitement de données sur le marché accordent de plus en plus d'attention au mélange de différents types de charges, c'est-à-dire qu'il existe une logique ou une architecture de traitement unifiée pour l'utilisateur ou l'entreprise. Par exemple, dans des scénarios commerciaux tels que le calcul publicitaire, le portrait d'utilisateur, le sous-contrôle, la logistique, les informations géographiques, etc., la méthode de traitement d'origine consiste à utiliser une base de données AP (traitement analytique) ou une plate-forme de données volumineuses auto-construite pour compléter le traitement. Le calcul des données historiques, puis le résultat du calcul AP est utilisé comme structure d'entrée de TP (traitement transactionnel) pour compléter les exigences de calcul en temps réel.
Par conséquent, dans l'environnement d'architecture d'origine, pour de telles applications, deux ensembles d'environnements doivent être déployés pour gérer les deux types de charges d'AP et de TP, ce qui complique l'ensemble de l'architecture, et de nombreux composants sont impliqués, il est donc impossible de données TP en temps réel Mise à jour du système AP, affectant ainsi la rapidité des applications telles que BI.
"Les rapports obsolètes, les données manquantes, le manque d'analyses avancées et l'absence totale d'analyses en temps réel sont un état intolérable pour toute entreprise qui a besoin de nouvelles informations pour rester compétitive à l'ère des clients commerciaux."[2]
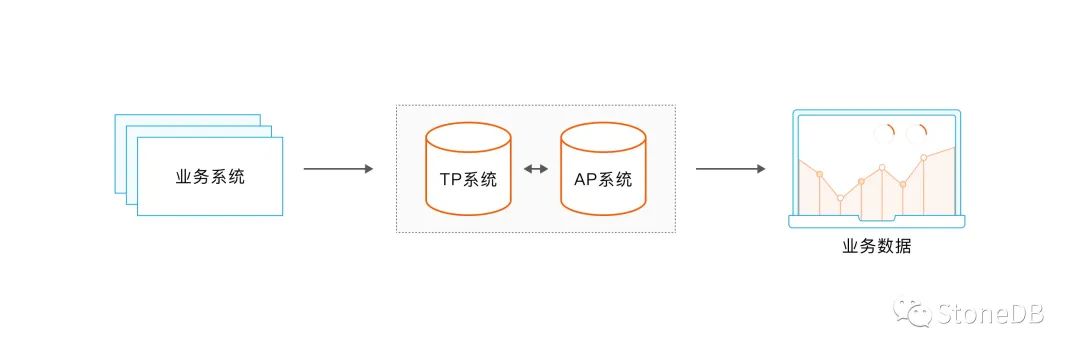
Architecture 1 : modèles d'architecture hétérogènes
La force motrice de l'entreprise vient des besoins de l'entreprise. S'il n'y a pas de changement dans la demande de l'entreprise, cela ne conduira pas à la force motrice de l'entreprise. Parce que, qu'il s'agisse d'une entreprise Internet ou d'autres entreprises traditionnelles dans le marché, dans le processus de développement de ses premières activités commerciales L'architecture 1 est généralement utilisée pour répondre aux besoins commerciaux ; cependant, il existe divers problèmes dans l'utilisation ultérieure de cette architecture, tels que la synchronisation des données entre le module AP et le module TP, les problèmes d'exploitation et de maintenance , etc. , ce qui entraînera des coûts d'exploitation énormes.
Avec le développement des besoins de l'entreprise et le développement de la technologie de base de données, les produits de base de données ont la capacité de traiter AP et TP en même temps, et lors du traitement de la charge AP, cela n'entraînera pas trop de fluctuations de performances pour la charge TP. est que les données TP et les données AP peuvent être mises à jour en "quasi" (ou en temps réel) en temps réel. Par conséquent, sur la base de la capacité de la base de données, le côté commercial peut combiner le module de traitement AP d'origine et le module de traitement TP, et transmettre à la base de données pour traitement, simplifiant ainsi l'architecture du système commercial.
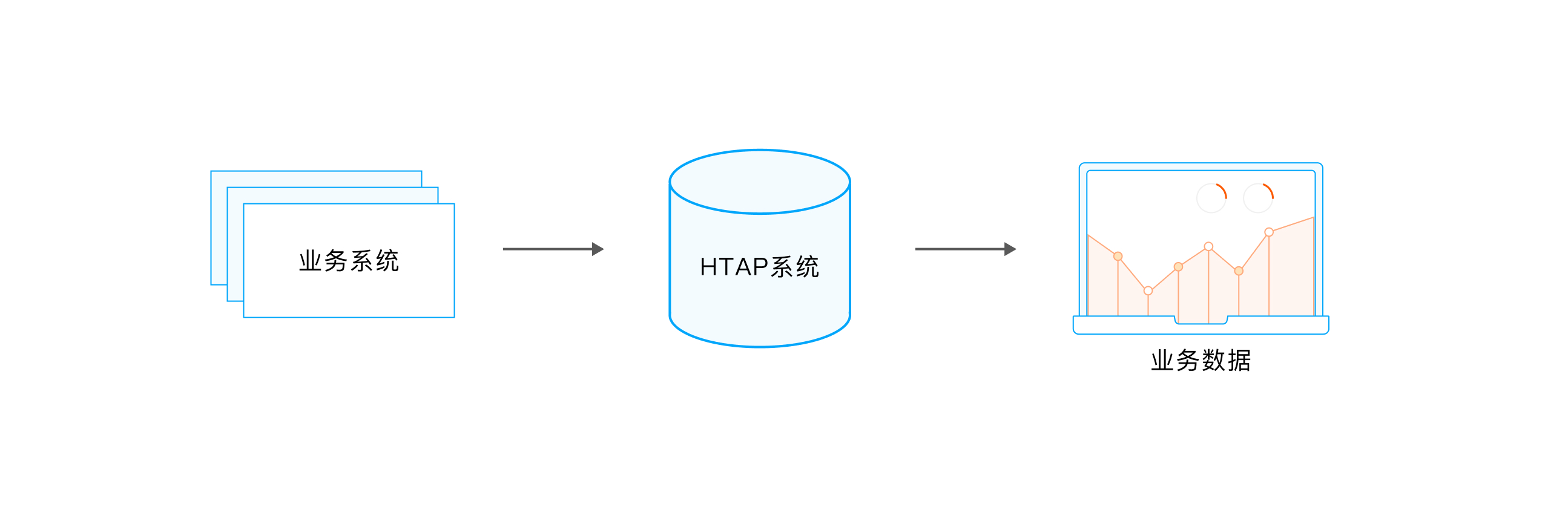
Architecture 2 : Architecture unifiée
HTAP fournit une autre solution et une autre idée pour le problème ci-dessus. Les capacités d'AP et de TP sont fournies en externe par un système unifié, ce qui simplifie l'architecture métier et présente certaines caractéristiques d'extension. Les exigences ou demandes du côté utilisateur HTAP sont les suivantes :
-
Intégration des données transactionnelles et historiques.
-
Comprendre la nécessité d'une analyse de données ultra-dimensionnelle des besoins des utilisateurs ; ce n'est qu'en regardant les données dans une perspective globale que nous pouvons voir l'essence des choses. (Par exemple : les informations de localisation du téléphone mobile, les informations obtenues à partir du remplissage du formulaire de l'utilisateur, les informations multimédias enrichies obtenues à partir des médias sociaux.)
-
La demande en temps réel d'analyse commerciale requise pour le fonctionnement de l'entreprise.
moteur technique
"Que la force soit avec toi." --Guerre des étoiles.
En tant qu'autre source importante d'une nouvelle technologie : force motrice technologique, c'est la pierre angulaire de la réalisation de l'imagination des gens. Examinons une autre source importante de puissance pour promouvoir le développement de HTAP du point de vue du développement technologique : la technologie in-memory , scale-out permet à notre architecture d'être étendue, afin que nous puissions répondre à différents besoins de charge dans une architecture. que possible. Le développement de la technologie de stockage en colonne est la pierre angulaire de notre implémentation de HTAP, et l' architecture de stockage hiérarchisé a trouvé un équilibre entre coût et performance.
1. Technologie de stockage de colonne
Les données orientées colonnes peuvent être retracées dès 1970. Avec l'émergence des fichiers transposés, les fichiers transposés sont utilisés dans les bases de données temporelles pour l'enregistrement des données médicales. On dit que Cantor est l'un des premiers systèmes similaires aux bases de données modernes de stockage de colonnes. Par exemple, les techniques de compression couramment utilisées dans les bases de données de stockage de colonnes modernes, l'encodage delta, etc. peuvent toutes être trouvées dans Cantor.
Il existe deux modèles de stockage de données utilisés pour les données dans les pages de disque : NSM (row-store, N-array Storage Model) et DSM (column-store, Decomposition Storage Model).
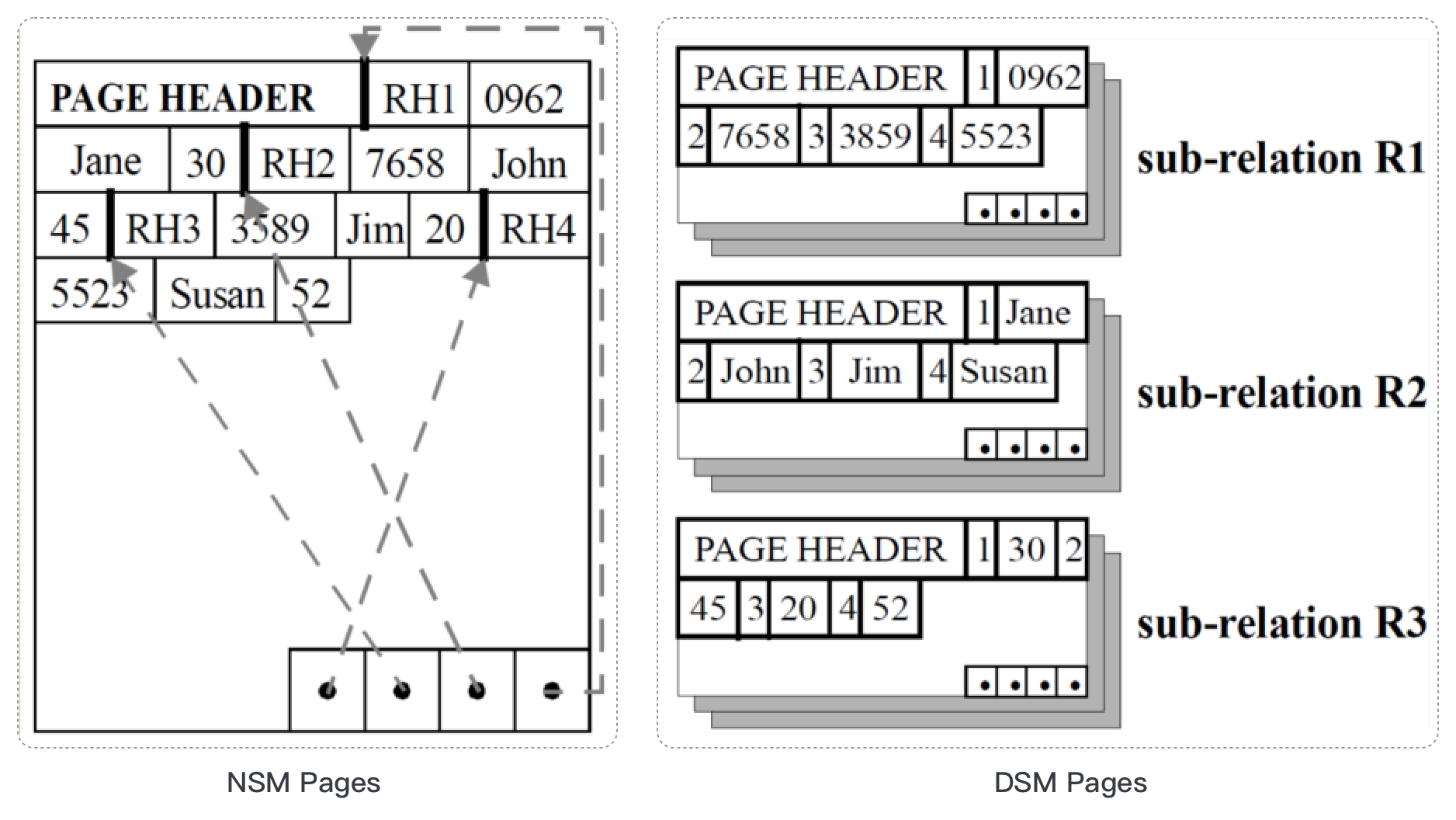
Habituellement, les données de la base de données sont gérées physiquement de manière hiérarchique sous la forme de lignes, de pages, de segments, etc. Une ligne de données dans une table se compose de N attributs de données, N éléments de données constituent une page et plusieurs pages constituent un segment. les dossiers sont gérés efficacement. Ce qui précède est le modèle basé sur les lignes que nous connaissons. Actuellement, la grande majorité des bases de données sont des bases de données en ligne. Nous ne répéterons pas ici les avantages du stockage de ligne correspondant. Parlons de l'autre côté de ses avantages, les inconvénients. Mettre de côté le cas d'usage pour parler des avantages et des inconvénients d'une transaction est une chose étrange en soi.
Correspondant à la méthode de stockage en ligne d'organisation des données, dans le système que j'effectue dans le cadre d'une activité axée sur l'analyse, la quantité de données impliquées dans l'analyse est généralement très importante. Autrement dit, un grand nombre d'enregistrements seront impliqués dans le calcul de l'analyse. Et ces grands nombres d'enregistrements doivent être lus du disque dans le cache de notre base de données. Les données étant organisées en lignes, notre calcul d'analyse ne nécessite que quelques attributs spécifiques, par exemple : Dans une ligne contenant : Product Id, Product L'origine, les ventes de produits, les enregistrements de temps de vente, l'analyse et le calcul peuvent uniquement nécessiter l'ID de produit et les ventes de produits, ces deux attributs peuvent obtenir les résultats d'analyse dont nous avons besoin. Peu importe où le produit est fabriqué et quand il est vendu. On peut en déduire que lorsque nous lisons cet enregistrement du disque dans le cache de la base de données, les deux données d'attribut d'origine du produit et de vente du produit sont un travail invalide. Cela conduira au gaspillage des ressources IO correspondant à nos attributs de données et à ses ressources mémoire dans le cache de la base de données, et ces deux parties de ressources sont des ressources système très précieuses dans la base de données.
Afin de résoudre les problèmes ci-dessus, en 1985, Copeland et Khoshafian ont proposé le modèle DSM, qui a également contribué au développement de bases de données stockées en colonnes. Différent du mode de stockage des lignes, dans le modèle DSM, les données de la table ont été organisées par attributs (colonnes). Comme le montre le modèle de page DSM dans la figure ci-dessus, de cette manière, chaque donnée d'attribut est organisée ensemble pour former une sous-relation et est indépendante des autres attributs. Étant donné que les données sont organisées séparément par attributs, nous pouvons compresser les données lors de leur stockage sur le disque.
Dans ce modèle de stockage de données, nous n'avons besoin que de lire les données d'attribut requises pour l'analyse et le calcul, ce qui peut économiser de précieuses ressources d'E/S et de mémoire. Dans le même temps, le modèle DSM est également compatible avec le cache CPU. Cependant, DSM a un problème : il doit reconstruire l'enregistrement lors du retour du résultat à l'utilisateur, ou lorsque l'opérateur de la couche supérieure effectue le calcul. Parce qu'à l'heure actuelle, les données que nous avons obtenues sont incomplètes et qu'un dossier complet est requis lorsque nous devons revenir à l'utilisateur.
En réponse à l'exploration des problèmes ci-dessus, la communauté universitaire a fait des tentatives actives vers 1990, et le projet MonetDB a vu le jour. Bien sûr, C-Store et VectorWise ont également vu le jour dans les années suivantes.A la fin des années 2000, les bases de données de stockage de colonnes étaient en plein essor, telles que : Vertica, Ingres VectorWise, Paraccel, Infobright, Kickfire, etc. Bien sûr, les sociétés de bases de données commerciales fournissent également des capacités de stockage de colonnes dans leurs produits respectifs par le biais d'acquisitions et d'auto-recherche. Par exemple : IBM BLU, SAP HANA, SQL-Server, etc.
2. Technologie In-Memory (y compris : distribuée en mémoire)
À mesure que les prix de la mémoire baissent à l'avenir, de plus en plus d'individus et d'organisations peuvent obtenir le dividende technologique apporté par le développement technologique à moindre coût : la technologie en mémoire. Comme le montre le tableau ci-dessous, les prix de la DRAM PC et de la DRAM côté serveur ont chuté de 3 à 10 % par trimestre.
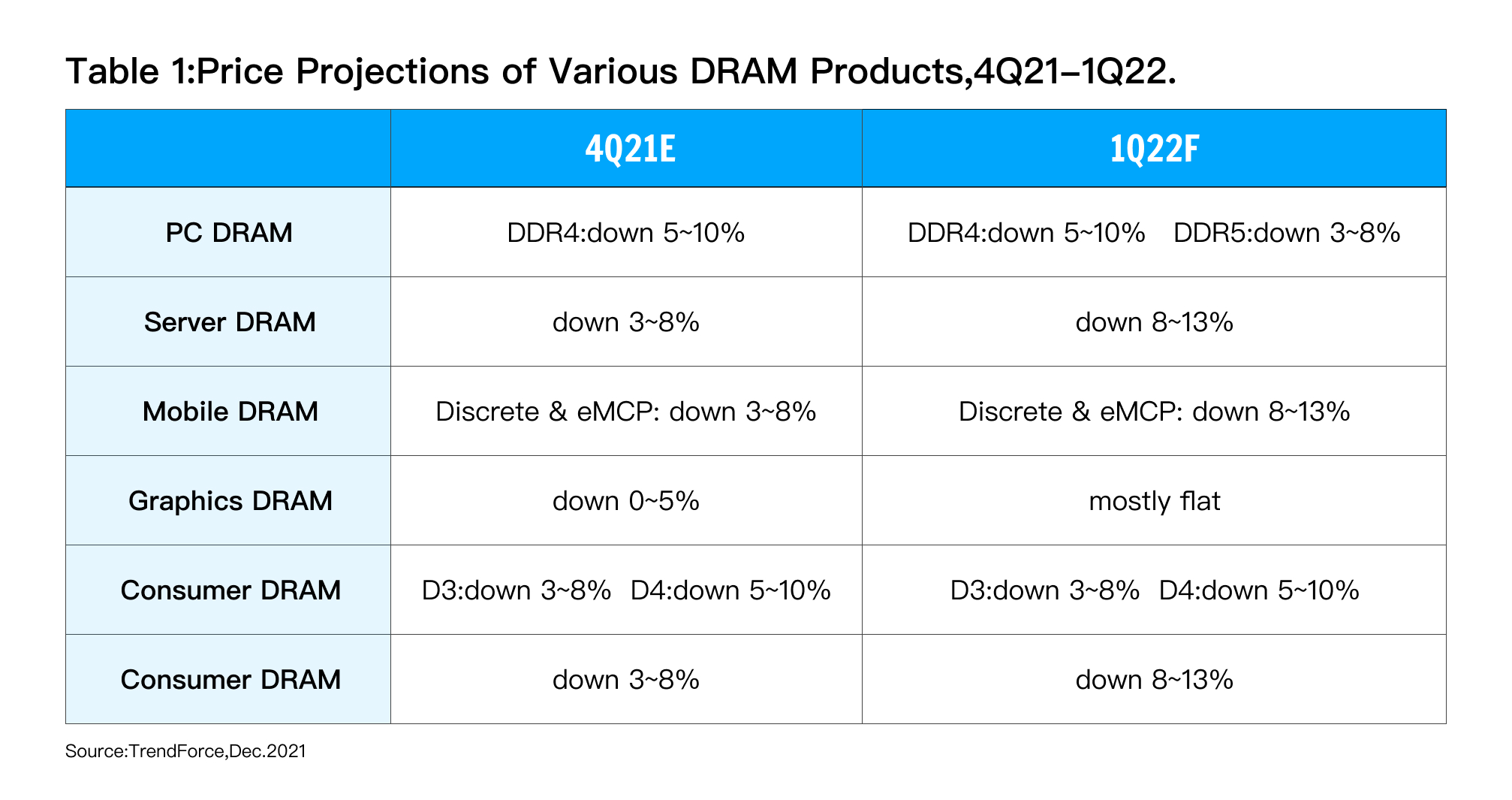
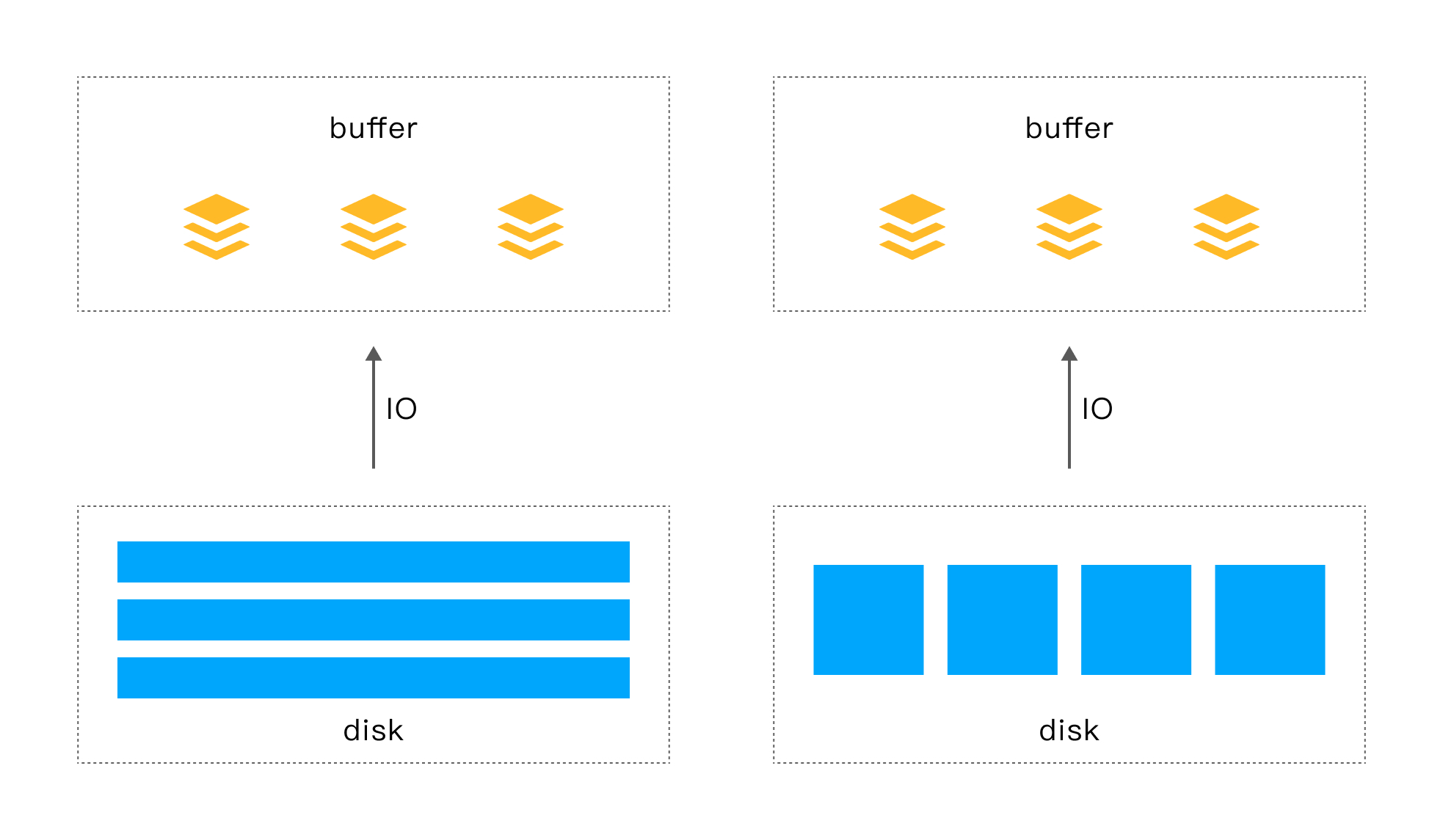
À mesure que le prix de la mémoire baisse, nous pouvons utiliser une approche plus radicale lors de la conception du système : une grande quantité de mémoire, voire une quantité complète de mémoire .
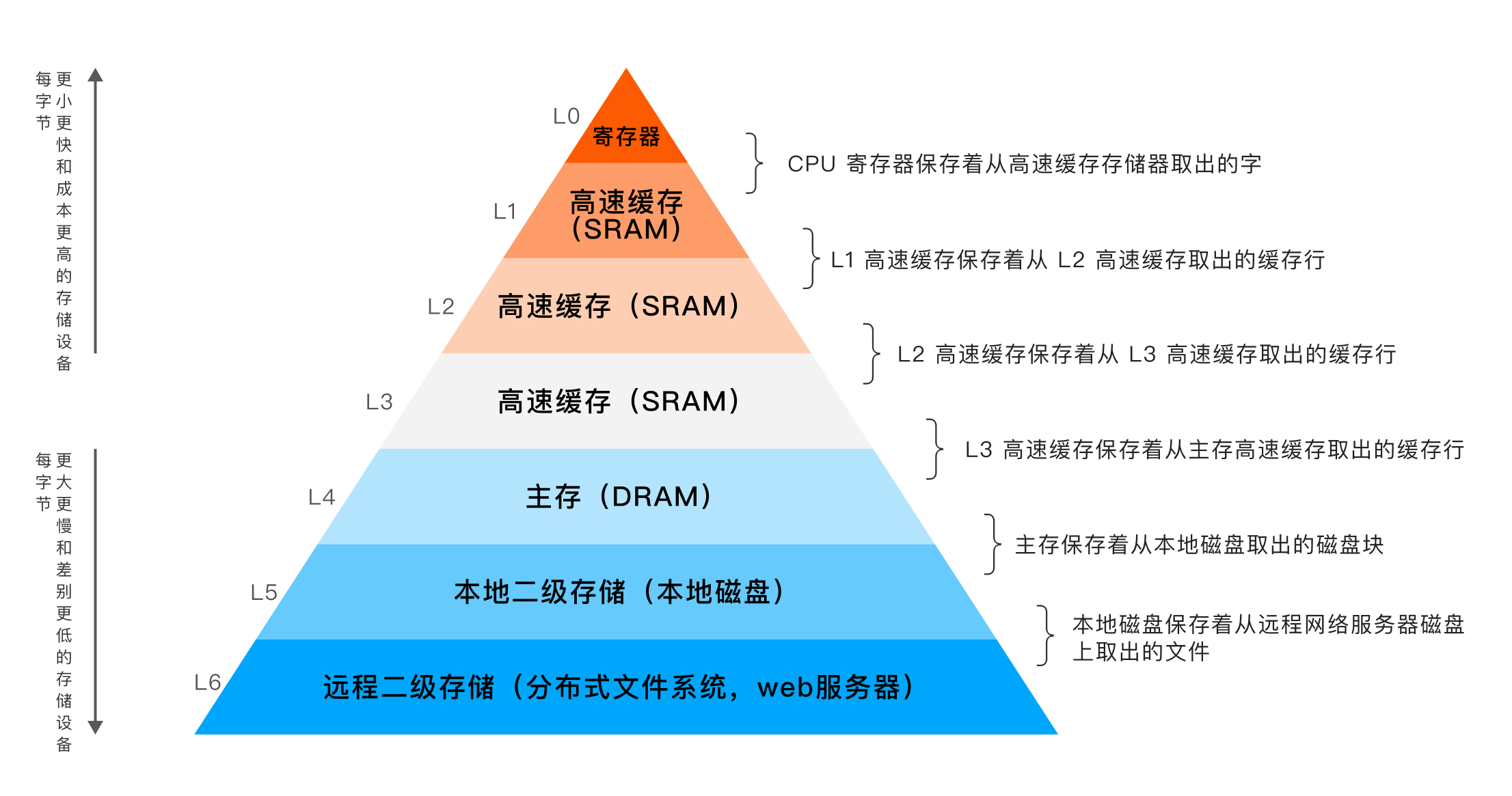
Nous savons d'après le diagramme de hiérarchie de stockage classique que la vitesse d'accès de la DRAM est beaucoup plus rapide que celle du disque local, mais le prix est beaucoup plus cher que le disque. Au début, limité par le prix élevé de la DRAM, la DRAM servait de cache pour sauvegarder les données lues sur le disque, par exemple : Buffer Pool. Avec la baisse continue du prix de la mémoire, la base de données en mémoire n'est plus une existence enneigée et pénètre lentement dans les foyers des gens ordinaires. Les bases de données en mémoire de niveau Go et téraoctet sont également souvent visibles.
Lorsqu'un traitement analytique (AP) doit être effectué, les données requises par l'AP peuvent être chargées dans la mémoire, et même toutes les données de la table requise peuvent être chargées dans la mémoire, de manière à obtenir une vitesse de traitement rapide. Dans le même temps, les modifications de données dans le moteur TP peuvent être synchronisées en continu avec le moteur AP en temps réel, afin de répondre aux exigences en temps réel de l'analyse commerciale.
Enfin, afin de garantir que la récupération puisse être effectuée correctement et rapidement lorsque le système tombe en panne, les données en mémoire doivent être conservées sur le disque.
3. Architecture évolutive : (architecte scale-out) : développement d'une architecture évolutive horizontalement, maturité de la technologie de verrouillage distribué, gestion distribuée des enregistrements
Afin de répondre à la capacité de traitement d'une plus grande quantité de données, sur la base d'un seul nœud, le système à nœud unique est étendu en un système multi-nœud distribué par expansion horizontale, et la capacité de ressources système des multi-nœuds est utilisé pour résoudre le problème Le problème de la puissance de calcul insuffisante dans le scénario. Contrairement à un système à nœud unique, un système distribué est généralement composé de plusieurs nœuds, un système de nœuds informatiques qui communiquent via un réseau et coordonnent le travail pour accomplir une tâche commune. L'émergence des systèmes distribués consiste à utiliser des machines bon marché et ordinaires pour effectuer des tâches de calcul et de stockage qu'un seul ordinateur ne peut pas. Le but est d'utiliser plus de machines pour traiter plus de données. Qu'il s'agisse de l'implémentation actuelle de la sous-base de données et de la sous-table via le middleware, ou que le système de base de données distribué adopte une certaine stratégie de distribution (telle que la distribution des données via le hachage via la clé primaire ou la clé de distribution ou d'autres méthodes) méthode) distribue les données à N nœuds de données, réduisant ainsi la quantité de données traitées par un seul nœud.
L'architecture évolutive n'est pas une technologie inconnue, surtout maintenant que l'informatique distribuée a été largement utilisée dans les systèmes de production, qu'il s'agisse de la technologie de cadre distribué, du système de fichiers distribué, des transactions distribuées, etc. ont formé un ensemble de théories matures et sont également devenus de plus en plus matures. en ingénierie.
Pour une architecture évolutive, la solution de mise à l'échelle des nœuds dynamiques sans connaissance métier devient de plus en plus mature, par exemple l'algorithme de hachage cohérent permet d'équilibrer la charge dans un environnement distribué. Maintenant, pour l'évolutivité horizontale des frameworks distribués, il existe des solutions matures à la fois en théorie et en ingénierie.
Avec le développement de l'architecture distribuée évolutive horizontalement, les capacités des systèmes distribués sont de plus en plus utilisées dans le domaine des bases de données. En plus d'être le cadre distribué sous-jacent, les transactions distribuées ont été développées pour nous permettre de traiter les transactions entre les nœuds. En conséquence, le système de base de données peut utiliser pleinement la puissance de calcul de plusieurs nœuds pour répondre aux exigences en temps réel dans les scénarios commerciaux de Big Data.
Pour HTAP, puisqu'il implique deux modèles (ou formats) de stockage différents, nous avons différentes méthodes de traitement pour les données de base de ligne et de base de colonne en termes de traitement des transactions. Cette partie du support des transactions nous oblige à y prêter une attention particulière. Dans le même temps, le traitement distribué des transactions apporté par l'architecture distribuée requise par HTAP est également un point ici.Heureusement, la technologie liée au traitement distribué des transactions est relativement mature sur le marché actuel.
Enfin, bien sûr, la distribution n'est qu'une condition suffisante pour HTAP, pas une condition nécessaire . Les solutions avec des exigences minimales de déploiement de nœuds qui ne tiennent pas compte de la situation réelle des utilisateurs sont toutes des "hooligans".
4. Compression des données
Considérant que dans le scénario AP, la quantité de données à traiter est généralement énorme. Du point de vue du coût et également du point de vue de l'efficacité des E/S, une compression efficace des données apportera plus d'avantages au système. Avec le support de l'algorithme de compression pour le type de données et l'amélioration du taux de compression, la compression des données est devenue une pratique standard dans le système AP.
5. Stockage hiérarchisé
Considérez le scénario commercial réel des ressources informatiques de l'utilisateur et la quantité de données. Habituellement, la quantité de données à traiter est bien supérieure aux ressources informatiques dont dispose le système. Nous savons que plus le stockage est proche du processeur, plus le prix unitaire est élevé.Afin de fournir aux utilisateurs des performances de la manière la plus rentable, une architecture de stockage à plusieurs niveaux a vu le jour. Par exemple : nous pouvons utiliser DRAM, NVME, SSD, HDD pour former une architecture de stockage à plusieurs niveaux. Chargez les données qui nécessitent un calcul en temps réel dans la DRAM pour le calcul afin d'obtenir des résultats de calcul en temps réel. Si le processus de calcul est complexe et que l'ensemble de résultats intermédiaires est volumineux, l'ensemble de résultats intermédiaires peut être enregistré dans NVME, ce qui peut non seulement garantir les performances en temps réel des données, mais également prendre en charge une plus grande quantité de données pour obtenir un coût plus élevé. performance. De même, les SSD et les HDD jouent le même rôle.
Bien que l'architecture de stockage hiérarchisée semble avoir des scénarios d'utilisation très attrayants et larges, elle présente également les défis suivants, qui nous obligent à être très prudents lors de l'utilisation de ce schéma.
-
Le premier et le plus important est le problème de la cohérence des données entre les différentes couches . Cette question est plus facile à comprendre. Dans une architecture de stockage à plusieurs niveaux, les données sont généralement réparties sur différents niveaux de stockage, et la réécriture des données entraînera inévitablement des incohérences de données. Dans le stockage hiérarchisé interne, une stratégie d'écriture immédiate ou une stratégie d'écriture différée peut être utilisée. Différentes méthodes ont également leurs propres avantages et inconvénients, qui ne seront pas répétés ici. Cependant, la plus grande différence entre le stockage hiérarchisé externe et le stockage hiérarchisé interne est que les données finales du stockage interne doivent être écrites dans la mémoire, alors que dans le stockage hiérarchisé externe, ce n'est pas nécessaire. Bien sûr, un tel schéma de mise en œuvre peut également être conçu, mais dans ce cas, les avantages en termes de performances du stockage hiérarchisé seront certainement affectés.
-
Deuxièmement, comment obtenir rapidement les données correspondantes à partir du stockage hiérarchisé sera également un grand défi. En raison de l'architecture de stockage hiérarchisée, plus le niveau est bas, plus la capacité de stockage est grande et plus la vitesse d'accès est lente. Comment localiser rapidement les données requises dans ces données massives posera des défis à l'organisation et à l'indexation des données. Enfin, il y a un compromis entre performance et coût. Comment choisir les supports de stockage dans chaque niveau, afin d'assurer d'excellentes performances globales sans entraîner une flambée des coûts de stockage.

Résumer
En résumé, cet article fait une analyse détaillée du contexte de HTAP, et en extrait les moteurs commerciaux et techniques.De toute évidence, un nouveau type de technologie est recherché, et il doit être indissociable de la maturité de la technologie, des besoins du marché et succès commercial. , HTAP est né dans ce contexte.
Donc, si nous partons de la définition de HTAP et de sa technologie de base, quelles sont les capacités d'un véritable produit HTAP ? Quels sont les principaux problèmes lors de la construction d'un véritable HTAP ? Quelles sont les solutions à ces problèmes fondamentaux ? Les réponses à ces questions seront révélées dans nos prochains articles.
Spoiler alert : Dans le prochain article, nous soulignerons que le vrai HTAP ne doit pas simplement ajouter TP et AP : TP + AP ≠ HTAP. HTAP doit être le produit d'un degré élevé de fusion de TP et AP.
Le système TP synchronise les données du TP avec le système AP via une méthode simple de synchronisation des données, telle que Binlog, etc., puis le système AP les traite, bien que cette méthode semble être obtenue du point de vue de l'utilisateur pour traiter le TP en même temps et les capacités AP, mais nous ne le voyons pas comme un produit HTAP par essence.
Cet article est le premier de la série "Qu'est-ce que HTAP". Nous continuerons à mettre à jour cette série d'articles à l'avenir, alors restez à l'écoute.
Références
[1] L'IA doit être en temps réel : https://splicemachine.com/blog/how-to-measure-an-htap-data-platform-for-ai-applications/
[2] Forrester : Technologie émergente : les bases de données translytiques fournissent des analyses à la vitesse des transactions.
[3] https://docs.microsoft.com/zh-cn/azure/architecture/data-guide/relational-data/online-transaction-processing
[4] https://www.gartner.com/en/documents/2657815
StoneDB est la première base de données open source HTAP en temps réel intégrée basée sur MySQL en Chine , et le moteur du noyau est entièrement auto-développé. Nous continuerons à travailler dur dans le domaine des bases de données open source et à coopérer avec diverses communautés et entreprises de bases de données open source pour créer un bon écosystème de bases de données open source nationales.
StoneDB a annoncé l' open source officiel le 29 juin . Si vous êtes intéressé, vous pouvez consulter le code source de StoneDB et lire la documentation via le lien ci-dessous, et attendez votre contribution avec impatience !
Référentiel open source StoneDB
https://github.com/stoneatom/stonedb
Li Hao
StoneDB Architecte en chef, StoneDB PMC
Il a travaillé chez Huawei, iQiyi et Peking University Founder dans la conception de l'architecture de base des noyaux de bases de données. Plus de 10 ans d'expérience dans le développement de noyaux de bases de données, bon moteur de requête, moteur d'exécution, traitement parallèle à grande échelle et autres technologies. Il possède des dizaines de brevets d'invention de bases de données et est l'auteur de " Analyse de la technologie de code source du moteur de requête PostgreSQL ".
Édition et relecture : Li Mingkang, Wang Xuejiao
FIN