1. Introducción
La detección de defectos se usa ampliamente en la detección de defectos de tela, detección de calidad de la superficie de la pieza de trabajo, campos aeroespaciales, etc. El algoritmo tradicional puede funcionar bien en situaciones en las que las reglas fallan y la escena es relativamente simple, pero ya no es adecuado para situaciones en las que las características no son obvias, las formas son diversas y la escena es caótica. En los últimos años, los algoritmos de reconocimiento basados en el aprendizaje profundo se han vuelto cada vez más maduros y muchas empresas han comenzado a intentar aplicar algoritmos de aprendizaje profundo en ocasiones industriales.
2. Datos de defectos
Como se muestra en la figura a continuación, los datos de la tela se usan como ejemplo aquí. Existen los siguientes tres defectos comunes: desgaste, manchas blancas y líneas múltiples.

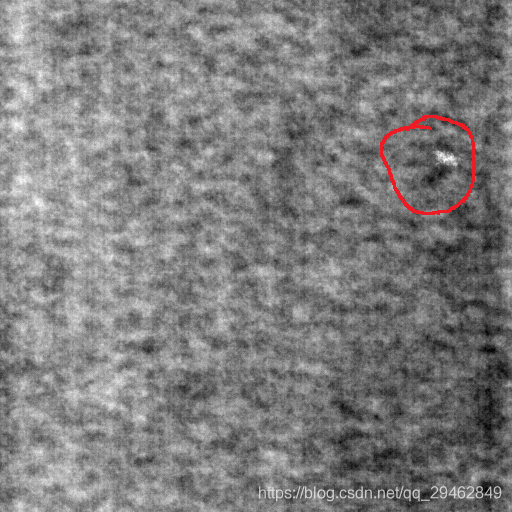

¿Cómo hacer datos de entrenamiento? Aquí está la intercepción en la imagen original, y se intercepta una imagen pequeña. Por ejemplo, la imagen de arriba es de 512x512, y aquí la recorto en una imagen pequeña de 64x64. Tomando como ejemplo el primer tipo de defecto, el siguiente es el método de elaboración de los datos.


Nota: Al generar datos defectuosos, el área defectuosa debe representar al menos 2/3 de la imagen interceptada; de lo contrario, se descartará y no se utilizará como imagen defectuosa.
En términos generales, los datos de defectos son mucho menores que los datos de fondo, no hay manera, consulte mi otra publicación de blog aquí, mejora de datos de imagen https://blog.csdn.net/qq_29462849/article/details/83241797Finally
passed Enhanced datos, defecto: fondo = 1:1, cada clase es alrededor de 1000 ~~~
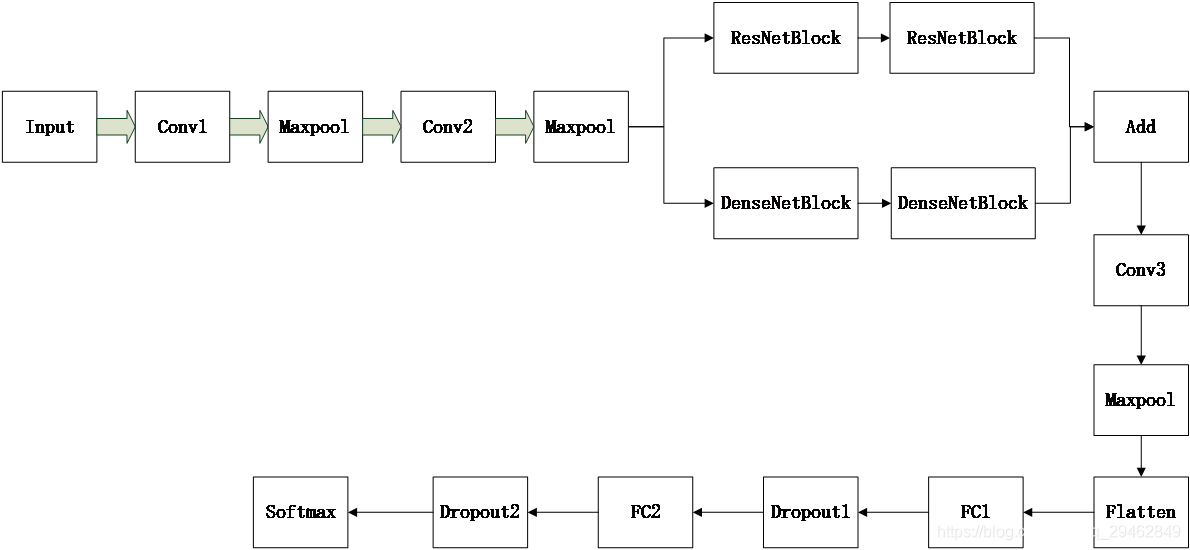
3. Estructura de la red
La estructura de red específica utilizada es la siguiente, el tamaño de entrada es 64x64x3 y se utiliza el tamaño de la imagen pequeña interceptada. A cada capa convolucional Conv le sigue una capa BN, y los parámetros de capa específicos son los siguientes.
Conv1: 64 x 3 x 3
Conv2: Dos
ResNetBlock y DenseNetBlock de 128 x 3 x 3. Para obtener más información, consulte Residual Network y DenseNet.
Agregar: agregue los resultados generados por el módulo residual y los resultados generados por DenseNetBlock en el mapa de funciones correspondiente. El método de adición es el mismo que el del módulo residual. Tenga en cuenta que, de hecho, esto es para una mejor extracción de funciones, el método no es necesariamente el módulo residual + DenseNetBlock, también puede ser el inicio u otros.
Conv3: 128x3x3
Maxpool: zancada=2, tamaño=2x2
FC1: 4096
Dropout1: 0.5
FC2: 1024
Dropout1: 0.5
Softmax: Correspondiente a la categoría a dividir, aquí estoy la segunda categoría.
En cuanto a la función de pérdida final, se recomienda elegir Focal Loss, que es la obra maestra de He Kaiming. El código fuente es el siguiente:
def focal_loss(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
return -K.sum(K.pow(1. - pt_1, 2) * K.log(pt_1))
Los datos están listos, puedes empezar a entrenar~~~
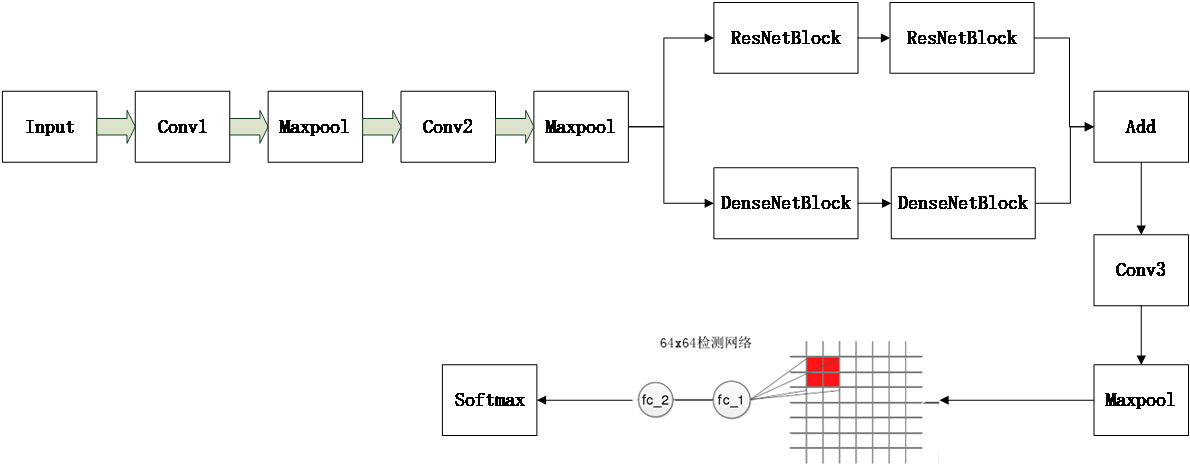
4. Detección de defectos de toda la imagen de la escena.
En la red de entrenamiento anterior, la entrada es 64x64x3, pero la imagen de la escena completa es 512x512. Esta entrada no coincide con la entrada del modelo. ¿Qué debo hacer? De hecho, puede extraer los parámetros del modelo entrenado, asignarlos a otro modelo nuevo y luego cambiar la entrada del nuevo modelo a 512x512, pero el mapa de características extraído en la capa conv3+maxpool es relativamente grande, esto Cuando el mapa de características se asigna a la imagen original, por ejemplo, después de la última capa de maxpool del modelo original, el tamaño del mapa de características de salida es 8x8x128, de los cuales 128 es el número de canales. Si la entrada se cambia a 512x512, el mapa de funciones de salida se convertirá en 64x64x128, y cada 8x8 aquí corresponde a 64x64 en la imagen original, por lo que se puede usar una ventana deslizante de 8x8 para deslizar y recortar la función en el mapa de funciones de 64x64x128. Luego engorde las características recortadas y envíelas a la capa completamente conectada. Los detalles se muestran en la siguiente figura.
La capa completamente conectada también necesita reconstruir un modelo, la entrada es la entrada después de aplanar y la salida es la salida de la capa softmax. Este es un pequeño modelo simple.
Aquí hay un código que lee los parámetros del modelo entrenado en otro modelo
#提取特征的大模型
def read_big_model(inputs):
# 第一个卷积和最大池化层
X = Conv2D(16, (3, 3), name="conv2d_1")(inputs)
X = BatchNormalization(name="batch_normalization_1")(X)
X = Activation('relu', name="activation_1")(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name="max_pooling2d_1")(X)
# google_inception模块
conv_1 = Conv2D(32, (1, 1), padding='same', name='conv2d_2')(X)
conv_1 = BatchNormalization(name='batch_normalization_2')(conv_1)
conv_1 = Activation('relu', name='activation_2')(conv_1)
conv_2 = Conv2D(32, (3, 3), padding='same', name='conv2d_3')(X)
conv_2 = BatchNormalization(name='batch_normalization_3')(conv_2)
conv_2 = Activation('relu', name='activation_3')(conv_2)
conv_3 = Conv2D(32, (5, 5), padding='same', name='conv2d_4')(X)
conv_3 = BatchNormalization(name='batch_normalization_4')(conv_3)
conv_3 = Activation('relu', name='activation_4')(conv_3)
pooling_1 = MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding='same', name='max_pooling2d_2')(X)
X = merge([conv_1, conv_2, conv_3, pooling_1], mode='concat', name='merge_1')
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_3')(X) # 这里的尺寸变成16x16x112
X = Conv2D(64, (3, 3), kernel_regularizer=regularizers.l2(0.01), padding='same', name='conv2d_5')(X)
X = BatchNormalization(name='batch_normalization_5')(X)
X = Activation('relu', name='activation_5')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_4')(X) # 这里尺寸变成8x8x64
X = Conv2D(128, (3, 3), padding='same', name='conv2d_6')(X)
X = BatchNormalization(name='batch_normalization_6')(X)
X = Activation('relu', name='activation_6')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='max_pooling2d_5')(X) # 这里尺寸变成4x4x128
return X
def read_big_model_classify(inputs_sec):
X_ = Flatten(name='flatten_1')(inputs_sec)
X_ = Dense(256, activation='relu', name="dense_1")(X_)
X_ = Dropout(0.5, name="dropout_1")(X_)
predictions = Dense(2, activation='softmax', name="dense_2")(X_)
return predictions
#建立的小模型
inputs=Input(shape=(512,512,3))
X=read_big_model(inputs)#读取训练好模型的网络参数
#建立第一个model
model=Model(inputs=inputs, outputs=X)
model.load_weights('model_halcon.h5', by_name=True)
5. Identificar los resultados del posicionamiento
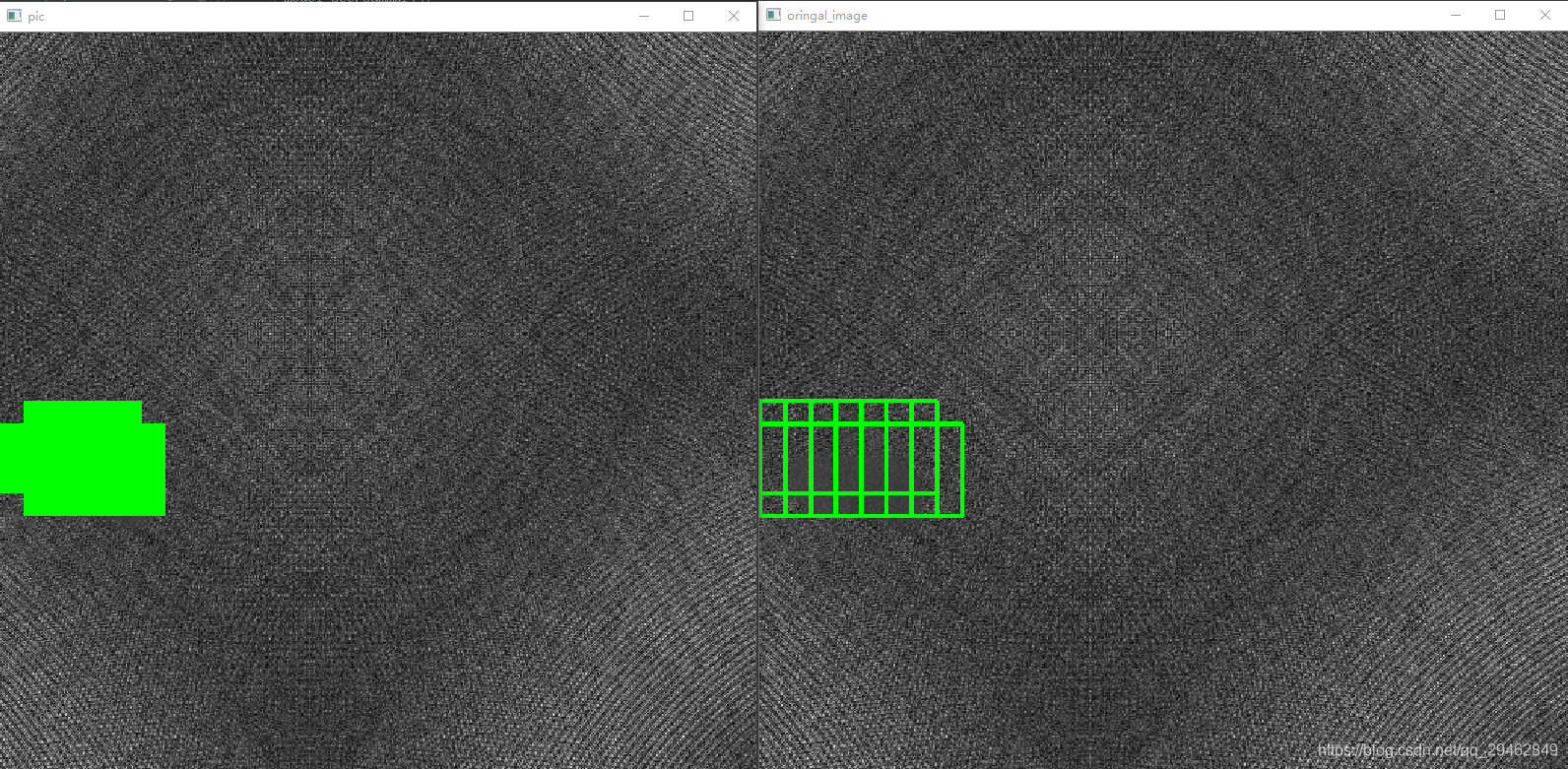
El método de ventana deslizante anterior se puede colocar en la imagen original. La ventana deslizante de 8x8 colocada en la imagen original es 64x64. De manera similar, en la imagen original, de acuerdo con los diferentes métodos de ventana deslizante (aquí, izquierda y derecha y arriba y abajo los pasos son 16 píxeles) Hay más de una posición defectuosa ubicada, lo que implica la precisión del posicionamiento. La forma de votar aquí es en realidad contar cada posición de píxel marcada en la imagen original. Cuando el número es mayor que el umbral especificado, se considera un píxel defectuoso.
El resultado del reconocimiento se muestra en la siguiente figura:


6. Algunos trucos
Para el caso anterior, de hecho, el cuadro de posicionamiento de 64x64 no es lo suficientemente preciso, puede considerar entrenar un modelo de tamaño de 32x32 y luego aplicar el mismo método que el modelo de 64x64, y finalmente votar según la posición de posicionamiento de 32x32 y el posicionamiento de 64x64 posición, pero esto tendrá un problema, es decir, el tiempo aumentará mucho y debe usarse con precaución.
Cuando hay poca diferencia entre el fondo y el primer plano, la red no debe ser demasiado profunda, porque la red que es demasiado profunda básicamente aprenderá las mismas cosas más tarde y no hay una buena capacidad de distinción, por lo que no lo hago. utilice la detección de objetos aquí La razón es que la profundidad de estas redes modelo de detección es a menudo 50+, y el efecto no es bueno, aunque hay un módulo residual como columna vertebral.
Sin embargo, cuando el fondo y el primer plano son muy diferentes, puede elegir una red más profunda.En este momento, el método de detección de objetos es útil.
7. Sobre el código fuente
El código aquí ya no es de código abierto, porque el diseño es técnicamente confidencial, si está interesado, puede implementarlo usted mismo, no es difícil ~