Tabla de contenido
2. Detección de anomalías basada en codificador automático
En tercer lugar, la implementación de Tensorflow de detección de anomalías
3.2, construir un modelo de autocodificación
1. Detección de anomalías
Las anomalías se definen como eventos que se desvían del estándar, ocurren raramente y no siguen el resto del "patrón". Ejemplos de excepciones incluyen:
- El mercado de valores se desplomó debido a los acontecimientos mundiales.
- Artículos defectuosos en la fábrica / cinta transportadora
- Muestras contaminadas en el laboratorio
Suponiendo que nuestros datos obedecen a una distribución normal, los datos anormales suelen estar ubicados a ambos lados de la curva de distribución normal. Como se muestra abajo.

Como hemos visto, estos eventos ocurrirán, pero la probabilidad de que ocurran es extremadamente baja. Desde una perspectiva de aprendizaje automático, esto dificulta la detección de anomalías; por definición, tenemos muchos ejemplos de eventos "estándar" y muy pocos ejemplos de eventos "anormales". Por lo tanto, nuestro conjunto de datos tiene una gran desviación. Cuando la anomalía que queremos detectar puede ocurrir solo el 1%, 0,1% o 0,0001% del tiempo, ¿cómo debería funcionar el algoritmo de aprendizaje automático que funciona mejor en el conjunto de datos equilibrados? En este momento, necesitamos usar la detección de anomalías para tratar específicamente este tipo de problema.
Debido al enorme desequilibrio en las etiquetas de nuestro conjunto de datos, los datos anormales rara vez ocurren por definición y tenemos una gran cantidad de datos normales. Para detectar datos anormales, los algoritmos tradicionales de aprendizaje automático derivan como bosques aislados, SVM de una clase, envolventes elípticas y algoritmos de factor de anomalía local. No los presentaré uno por uno aquí. Los estudiantes interesados pueden ir a investigar y estudiar. El tema principal aquí es cómo utilizar el aprendizaje profundo para resolver este problema.
2. Detección de anomalías basada en codificador automático
Autoencoder es una red neuronal no supervisada que puede:
- Acepte un conjunto de datos de entrada;
- Codificar los datos;
- Decodifica las características codificadas para reconstruir los datos de entrada.
Por lo general, un codificador automático consta principalmente de dos partes: codificador y decodificador. El codificador acepta datos de entrada y los convierte en una representación de características. Luego, el decodificador intenta reconstruir las características comprimidas para obtener los datos de entrada. Cuando entrenamos el codificador automático de un extremo a otro, la red puede aprender un filtro potente que incluso puede eliminar el ruido de los datos de entrada.
Desde la perspectiva de la detección de anomalías, el autoencoder es especial porque puede reconstruir la pérdida El error cuadrático medio (MSE) entre la entrada y los datos reconstruidos generalmente se mide cuando se entrena el autoencoder. Si la pérdida es menor, la imagen reconstruida se parece más a los datos originales.

Supongamos que entrenamos un codificador automático en todo el conjunto de datos MNIST, y luego proporcionamos un número al codificador automático y lo reconstruimos. Esperamos poder reconstruirlo para que sea similar a los datos de entrada, y luego encontraremos que el MSE entre estas dos imágenes es relativamente bajo.

Si, en este momento, proporcionamos una imagen no digital, como un elefante, el MSE de estas dos imágenes es muy alto en este momento. Esto se debe a que el codificador automático nunca antes había visto un elefante y, lo que es más importante, nunca ha sido entrenado para reconstruir un elefante, por lo que nuestro MSE es muy alto.

En este momento, si el MSE reconstruido es alto, es posible que tengamos un valor atípico.
En tercer lugar, la implementación de Tensorflow de detección de anomalías
3.1, carga de datos
Aquí usamos el conjunto de datos mnist, la etiqueta es 1 como datos normales, la etiqueta es el 1% del número de datos y la etiqueta es 3 como datos anormales, y los datos son anormales. detalles como sigue:
- Cargar conjunto de datos
# 加载MNIST数据集
print("[INFO] loading MNIST dataset...")
((trainX,trainY),(testX,testY))=tf.keras.datasets.mnist.load_data()- Generar datos anormales
def build_unsupervised_dataset(data,labels,validLabel=1,
anomalyLabel=3, contam=0.01, seed=42):
'''制作数据集'''
# 抓取提供的类标签的所有 * 真正 * 索引特定的标签,
# 然后获取图像的索引个标签将成为我们的“异常”
validIdxs=np.where(labels==validLabel)[0]
anomalyLabelIdx=np.where(labels==anomalyLabel)[0]
#随机打乱数据
random.shuffle(validIdxs)
random.shuffle(anomalyLabelIdx)
#计算并设置异常数据的个数
i=int(len(validIdxs)*contam)
anomalyLabelIdx=anomalyLabelIdx[:i]
#提取正常数据和异常数据
validImages=data[validIdxs]
anomalyImages=data[anomalyLabelIdx]
#打包数据并进行数据打乱
images=np.vstack([validImages,anomalyImages])
return images
# 建立少量的无监督图像数据集,污染(即异常)添加到其中
print("[INFO] creating unsupervised dataset...")
images = build_unsupervised_dataset(trainX, trainY, validLabel=1,
anomalyLabel=3, contam=0.01)3.2, construir un modelo de autocodificación
Aquí está el código directamente:
class ConvAutoencoder:
@staticmethod
def build(width,height,depth=None,filters=(32,64),latentDim=16):
'''
构建自动编码器模型
:param width: 图像的宽度
:param height: 图像的高度
:param depth: 图像的深度
:param filters: 卷积核的尺寸
:param latentDim: 全连接的维数
:return:
'''
#定义解码器
inputs=tf.keras.layers.Input(shape=(height,width,depth))
x=inputs
for filter in filters:
x=tf.keras.layers.Conv2D(filter,kernel_size=(3,3),strides=2,padding='same')(x)
x=tf.keras.layers.LeakyReLU(alpha=0.2)(x)
x=tf.keras.layers.BatchNormalization(axis=-1)(x)
volumeSize=tf.keras.backend.int_shape(x)
x=tf.keras.layers.Flatten()(x)
latent=tf.keras.layers.Dense(latentDim)(x)
encoder=tf.keras.Model(inputs=inputs,outputs=latent,name='encoder')
#定义编码器
latentinputs=tf.keras.layers.Input(shape=(latentDim,))
x=tf.keras.layers.Dense(np.prod(volumeSize[1:]))(latentinputs)
x=tf.keras.layers.Reshape((volumeSize[1],volumeSize[2],volumeSize[3]))(x)
for filter in filters[::-1]:
x=tf.keras.layers.Conv2DTranspose(filter,kernel_size=(3,3),strides=2,padding='same')(x)
x=tf.keras.layers.LeakyReLU(alpha=0.2)(x)
x=tf.keras.layers.BatchNormalization(axis=-1)(x)
x=tf.keras.layers.Conv2DTranspose(depth,(3,3),padding='same')(x)
outputs=tf.keras.layers.Activation('sigmoid')(x)
decoder=tf.keras.Model(latentinputs,outputs,name='decoder')
autoencoder=tf.keras.Model(inputs,decoder(encoder(inputs)),name='autoencoder')
return (encoder,decoder,autoencoder)
autoencoder.summary()La estructura de la trama de red es la siguiente:

3.3, entrenamiento de modelos
epochs=20
lr=1e-3
batch_size=32
#搭建模型
print("[INFO] building autoencoder...")
(encoder, decoder, autoencoder) = ConvAutoencoder.build(28, 28,1)
#搭建优化器
opt=tf.keras.optimizers.Adam(lr=lr,decay=lr/epochs)
autoencoder.compile(loss='mse',optimizer=opt,metrics=['acc'])
#训练
H=autoencoder.fit(trainX,trainX,validation_data=(testX,testX),epochs=epochs,batch_size=batch_size)
El proceso de formación es el siguiente:

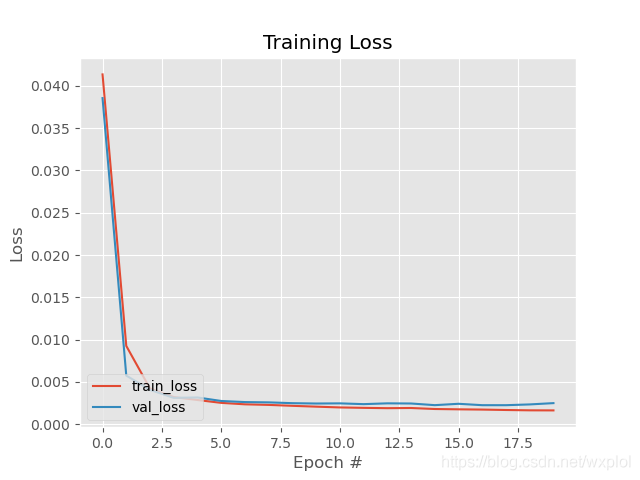
3.4. Predicción del modelo
Utiliza principalmente la imagen reconstruida con autocodificación y la imagen original para calcular el MSE, y luego hace el juicio correspondiente según el umbral. La principal realización es la siguiente:
# 加载模型
print("[INFO] loading autoencoder and image data...")
autoencoder = tf.keras.models.load_model("autoencoder.h5")
images = pickle.loads(open("mages.pickle", "rb").read())
#预测图片
images=images.reshape(-1,28,28,1)
images=images.astype('float32')
images/=255
decoded = autoencoder.predict(images)
errors = []
for (image, recon) in zip(images, decoded):
# 计算预测和真实图片之间的均方差1
mse = np.mean((image - recon) ** 2)
errors.append(mse)
# compute the q-th quantile of the errors which serves as our
# threshold to identify anomalies -- any data point that our model
# reconstructed with > threshold error will be marked as an outlier
thresh = np.quantile(errors, 0.999)
idxs = np.where(np.array(errors) >= thresh)[0]
print("[INFO] mse threshold: {}".format(thresh))
print("[INFO] {} outliers found".format(len(idxs)))Los resultados de la prueba son los siguientes:


Enlace de código detallado: https://github.com/kingqiuol/learning_tensorflow/tree/master/cv/Anomaly_detection
Link de referencia:
https://www.pyimagesearch.com/2020/03/02/anomaly-detection-with-keras-tensorflow-and-deep-learning/
Clasificación de dígitos manuscritos del conjunto de datos MNIST basada en Keras + CNN