control de hilos e hilos
hilo
① Definición de hilo
Todos los flujos de ejecución en Linux se denominan procesos ligeros (LWP), el proceso ligero también se llama hilo
el hilo se ejecuta dentro del proceso -> el hilo se ejecuta dentro del espacio de direcciones del proceso

En Linux, desde la perspectiva de la CPU, ¿puede identificar si task_struct es un proceso o un subproceso?
No, la CPU no necesita identificarse, la CPU solo se preocupa por un solo flujo de ejecución uno por uno, y cada task_struct es un flujo de ejecución
task_struct a los ojos de la CPU<=task_struct del principio OS

②Las ventajas de los hilos
1. Crear un nuevo subproceso es mucho menos costoso que crear un nuevo proceso
2. Cambiar entre subprocesos requiere mucho menos trabajo del sistema operativo que cambiar entre procesos
3. Los subprocesos consumen más recursos que Hay muchos menos procesos
4. Cómputo intensivo aplicaciones, para ejecutarse en un sistema multiprocesador, descomponer el cálculo en varios subprocesos para implementar aplicaciones intensivas de E/S y superponer operaciones de E/S para mejorar el rendimiento. Los subprocesos pueden esperar diferentes operaciones de E/S al mismo tiempo
El intercambio de recursos de subprocesos es muy simple, solo es necesario definir recursos globales, todos los subprocesos pueden ver
Cómputo intensivo: la mayoría de las tareas del flujo de ejecución son principalmente informáticas (cifrado y descifrado, clasificación y búsqueda
) red de acceso)
③ Desventajas del hilo
Penalización de rendimiento:
un subproceso de computación intensivo que rara vez se bloquea por eventos externos a menudo no puede compartir el mismo procesador con otros subprocesos. Si la cantidad de subprocesos de cómputo intensivo es mayor que los procesadores disponibles, puede haber una gran penalización en el rendimiento, y una gran cantidad de subprocesos agrega sincronización adicional y sobrecarga de programación , por lo que cuantos más subprocesos no es mejor.
Robustez reducida:
escribir subprocesos múltiples requiere una consideración más completa y profunda.En un programa de subprocesos múltiples, existe una alta posibilidad de efectos adversos causados por desviaciones sutiles en la asignación de tiempo o por compartir variables que no deberían compartirse. problemas de seguridad; en subprocesos múltiples, el bloqueo de un solo subproceso hará que todo el proceso se bloquee, y es difícil averiguar qué subproceso falla y es difícil de depurar
Falta de control de acceso:
el proceso es la granularidad básica del control de acceso, llamar a algunas funciones del sistema operativo en un hilo afectará todo el proceso
Mayor dificultad de programación:
escribir y depurar un programa de subprocesos múltiples es mucho más difícil que un programa de un solo subproceso
④Excepción de hilo
Si un solo subproceso se divide por cero, el problema del puntero salvaje hará que el subproceso se bloquee, y el proceso también seguirá al
subproceso bloqueado como la rama de ejecución del proceso. Si el subproceso es anormal, es similar a la anomalía del y luego activa el mecanismo de señal para terminar el proceso. Todos los subprocesos dentro se cerrarán inmediatamente y los recursos se reciclarán.
⑤ Proceso e hilo
El proceso es la unidad básica de asignación de recursos y el subproceso es la unidad básica de programación.
Datos exclusivos de subprocesos:
1. ID de subproceso
2. Un conjunto de registros (contexto de guardado, programación)
3. Pila (datos temporales para subprocesos)
4. errno
5. Palabra de máscara de señal
6. Prioridad de programación
Múltiples subprocesos de un proceso comparten el mismo espacio de direcciones, por lo que el segmento de datos y el segmento de código se comparten, y cada subproceso también comparte los siguientes recursos y entorno del proceso:
1. Tabla de descriptores de archivo
2. El método de procesamiento de cada señal
3. El directorio de trabajo actual
4. ID de usuario e ID de grupo
Biblioteca de subprocesos POSIX
Las funciones relacionadas con subprocesos forman una serie completa. La mayoría de los nombres de las funciones comienzan con "pthread_". Al importar el archivo de encabezado <pthread.h>
para vincular estas bibliotecas de funciones de subprocesos, use el comando del compilador "-lpthread" ” opción
① Creación de hilos

Parámetros:
subproceso: identificador de subproceso, parámetro de salida
attr: atributo de subproceso puede especificar el tamaño de la nueva pila de subprocesos, estrategia de programación, si es NULL, es el atributo predeterminado
star_routine: historial de subprocesos, función de devolución de llamada, función de entrada de subprocesos
arg: entrada función para subproceso Pase parámetros, NULL significa que no hay parámetros
Valor devuelto: 0 se devuelve para el éxito, se devuelve el número de error para el fracaso
Ejemplo:
#include<stdio.h>
#include<unistd.h>
#include<pthread.h>
void *Routine(void* arg)//回调
{
char* str=(char*) arg;
while(1)
{
printf("%s:pid:%d,ppid:%d\n",str,getpid(),getppid());
sleep(1);
}
}
int main()
{
pthread_t pt;
pthread_create(&pt,NULL,Routine,(void*)"i am a new pthread");
while(1)
{
printf("i am a main pthread:pid:%d,ppid:%d\n",getpid(),getppid());
sleep(2);
}
return 0;
}

Se puede ver que aunque hay dos flujos de ejecución, es el mismo proceso
para ver el proceso ligero actual: ps -aL

②Obtener la ID del hilo

Cree seis subprocesos y obtenga ID de subprocesos de dos maneras:
#include<stdio.h>
#include<unistd.h>
#include<pthread.h>
void *Routine(void* arg)//回调
{
char* str=(char*) arg;
while(1)
{
printf("%s:pid:%d,ppid:%d,tid:%lu\n",str,getpid(),getppid(),pthread_self());
sleep(1);
}
}
int main()
{
pthread_t tid[6];
for(int i=0;i<6;i++)
{
char buffer[64];
sprintf(buffer,"thread %d",i);
pthread_create(&tid[i],NULL,Routine,(void*)buffer);
printf("%s tid is:%lu\n",buffer,tid[i]);//通过create的输出型参数拿到线程ID
}
while(1)
{
printf("i am a main pthread:pid:%d,ppid:%d,tid:%lu\n",getpid(),getppid(),pthread_self());
sleep(2);
}
return 0;
}

El ID de subproceso obtenido en este momento no es el mismo que el LWP.
Estos dos métodos obtienen el ID de subproceso a nivel de usuario, y el LWP obtiene el ID de subproceso a nivel de kernel
. En Linux, el subproceso de la capa de aplicación y el LWP de el núcleo están en correspondencia uno a uno.
③ hilo en espera
Al igual que los procesos en espera, también es necesario esperar a que los hilos liberen recursos.
¿Por qué los hilos necesitan esperar?
El hilo que ha salido, su espacio no ha sido liberado, todavía está en el espacio de direcciones del proceso.
La creación de un nuevo hilo no reutilizará el espacio de direcciones del hilo que acaba de salir
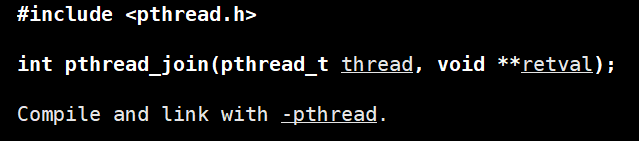
retval: apunta al valor de retorno del hilo
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
void* Routine(void* arg)//回调
{
char* str=(char*) arg;
int count=0;
while(count<5)
{
printf("%s:pid:%d,ppid:%d,tid:%lu\n",str,getpid(),getppid(),pthread_self());
sleep(1);
count++;
}
return (void*)66666;
}
int main()
{
pthread_t tid[6];
for(int i=0;i<6;i++)
{
char* buffer=(char*)malloc(64);
sprintf(buffer,"thread %d",i);
pthread_create(&tid[i],NULL,Routine,(void*)buffer);
printf("%s tid is:%lu\n",buffer,tid[i]);//通过create的输出型参数拿到线程ID
}
for(int i=0;i<6;i++)
{
void* ret=NULL;//返回码
pthread_join(tid[i],&ret);//默认阻塞式等待
printf("i am a main pthread:pid:%d,ppid:%d,tid:%lu,code:%d\n",getpid(),getppid(),pthread_self(),(int)ret);
}
printf("wait finish\n");
return 0;
}

El subproceso solo tiene el código de salida y no tiene información de excepción como el proceso. La razón es que una vez que el subproceso es anormal, todo el proceso finaliza, el subproceso principal no tiene posibilidad de unirse y la robustez del subproceso es baja.
④Terminación de rosca
1.exit: finalizar la llamada del subproceso del proceso finalizará directamente todo el proceso
2.pthread_exit: finalizar el subproceso, equivalente a devolver
3.pthread_cancel: cancelar el subproceso, generalmente el subproceso principal cancela el nuevo subproceso, código de salida -1
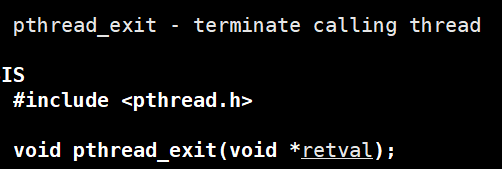
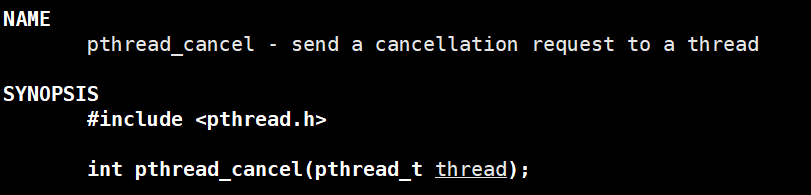
No recomendado:
el nuevo subproceso cancela el subproceso principal: después de que se cancela el subproceso principal, el código posterior ya no se ejecuta y el nuevo subproceso no se ve afectado, continúe ejecutando el código
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
pthread_t main_thread;
void* Routine(void* arg)//回调
{
char* str=(char*) arg;
int count=0;
while(count<5)
{
printf("%s:pid:%d,ppid:%d,tid:%lu\n",str,getpid(),getppid(),pthread_self());
sleep(1);
int ret= pthread_cancel(main_thread);
printf("%d",ret);
printf("已经取消\n");
count++;
}
return NULL;
}
int main()
{
pthread_t tid[6];
main_thread=pthread_self();
for(int i=0;i<6;i++)
{
char* buffer=(char*)malloc(64);
sprintf(buffer,"thread %d",i);
pthread_create(&tid[i],NULL,Routine,(void*)buffer);
printf("%s tid is:%lu\n",buffer,tid[i]);//通过create的输出型参数拿到线程ID
}
for(int i=0;i<6;i++)
{
void* ret=NULL;//返回码
pthread_join(tid[i],&ret);//默认阻塞式等待
printf("i am a main pthread:pid:%d,ppid:%d,tid:%lu,code:%d\n",getpid(),getppid(),pthread_self(),(int)ret);
}
printf("wait finish\n");
return 0;
}

La primera cancelación exitosa devuelve 0 y la cancelación subsiguiente no devuelve 3. El

extinto indica que el hilo ha sido cancelado.
⑤ Separación de hilos
En general, se debe esperar un subproceso, al igual que se espera un proceso
1. El subproceso no se puede unir, pero esto requiere que se separe
el subproceso 2. Después de separar el subproceso, el subproceso sale y el sistema reciclará automáticamente los recursos del subproceso, por lo que no es necesario bloquearlo ni esperarlo. por la combinación
3. Si no le importa el valor de retorno del subproceso, la combinación es una carga, simplemente use la separación de subprocesos
4. Un subproceso no puede ser tanto unible como separable

#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
pthread_t main_thread;
void* Routine(void* arg)//回调
{
sleep(1);
pthread_detach(main_thread);
char* str=(char*) arg;
int count=0;
while(count<5)
{
printf("%s:pid:%d,ppid:%d,tid:%lu\n",str,getpid(),getppid(),pthread_self());
sleep(1);
count++;
}
return NULL;
}
int main()
{
pthread_t tid[6];
main_thread=pthread_self();
for(int i=0;i<6;i++)
{
char* buffer=(char*)malloc(64);
sprintf(buffer,"thread %d",i);
pthread_create(&tid[i],NULL,Routine,(void*)buffer);
printf("%s tid is:%lu\n",buffer,tid[i]);//通过create的输出型参数拿到线程ID
}
while(1)
{
printf("i am a main pthread:pid:%d,ppid:%d,tid:%lu\n",getpid(),getppid(),pthread_self());
sleep(1);
}
printf("wait finish\n");
return 0;
}

El subproceso separado sale y el sistema recicla automáticamente los recursos.
Id. de subproceso y diseño del espacio de direcciones del proceso
thread_t es esencialmente una dirección
Los subprocesos también deben administrarse. Linux no proporciona subprocesos reales, solo LWP. El sistema operativo solo realiza la administración de secuencias en el kernel LWP, mientras que otros datos, como las interfaces para los usuarios, son administrados por la biblioteca de subprocesos pthread, lo que significa que se describe en primero la biblioteca organizar



tabla de paginas secundarias
64 bits usa una tabla de páginas de varios niveles, 32 bits en realidad usa un mapeo de tablas de páginas de dos niveles.Cuando
hay una tabla en la relación de mapeo, el tamaño de la tabla es demasiado grande y debe almacenarse en dos niveles . tabla de páginas de nivel.

