El sitio web de la lista de información de equipos del Rey de Gloria: https://pvp.qq.com/web201605/item.shtml
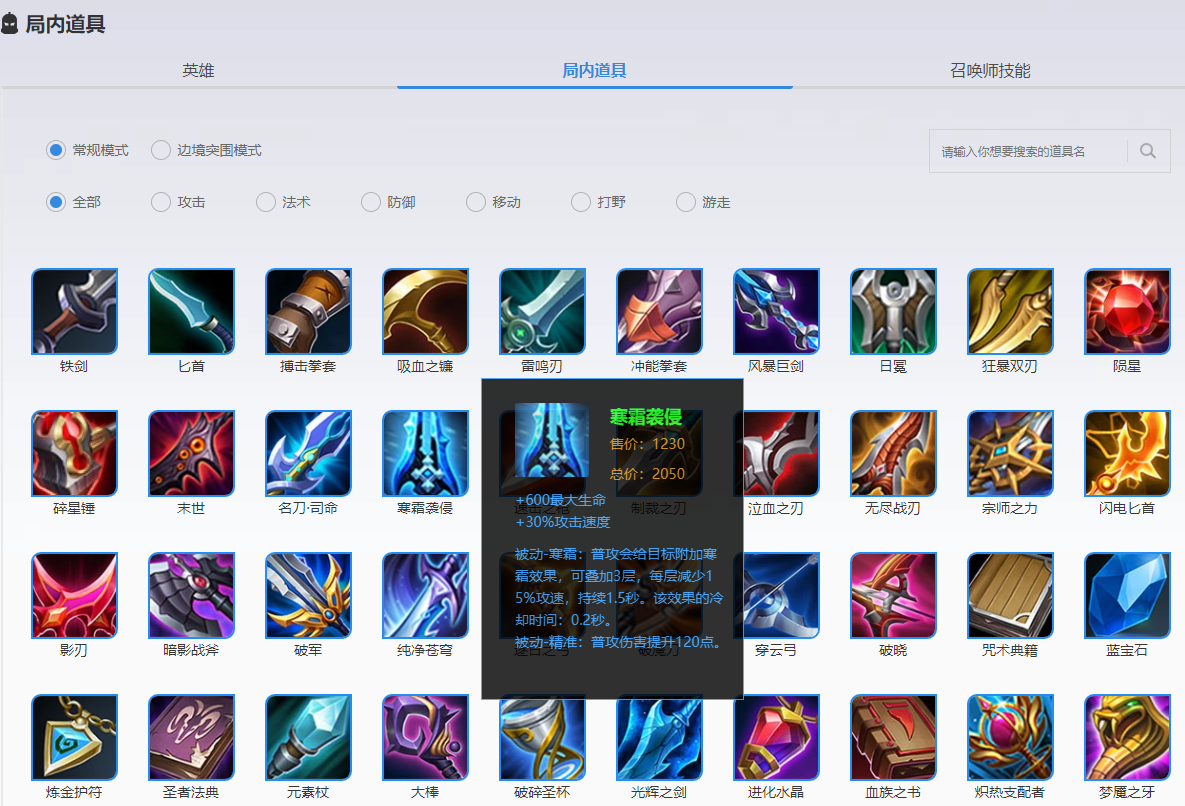
Después de verificar con las herramientas del desarrollador, los datos del equipo se pueden obtener a través de la interfaz https://pvp.qq.com/web201605/js/item.json .
Obtener datos del equipo
Recopilar y organizar datos:
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("</?p>", "", regex=True)
item_df.des2 = item_df.des2.str.replace("</?p>", "", regex=True)
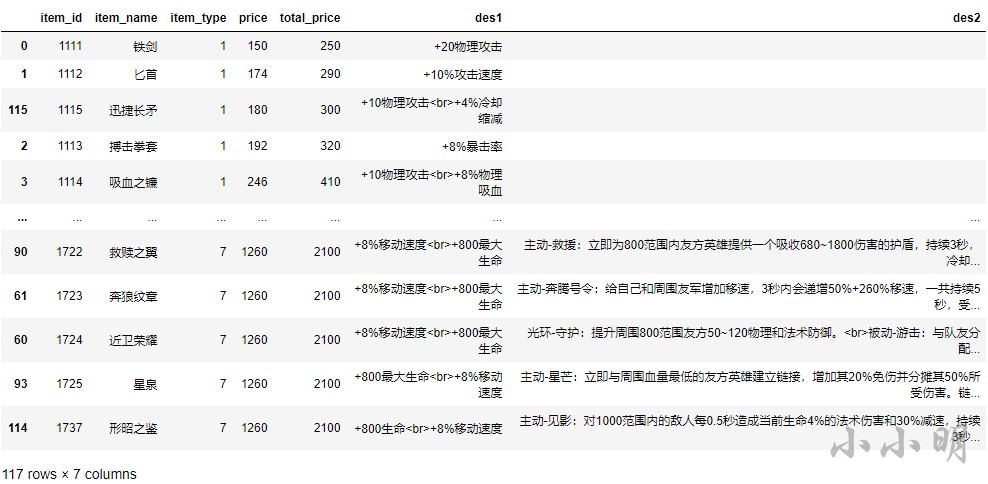
item_df
Ver la URL de la imagen del equipo, por ejemplo, la URL de la espada de hierro es:
https://game.gtimg.cn/images/yxzj/img201606/itemimg/1111.jpg
El patrón se puede encontrar, item_id es el nombre de la imagen.
Imágenes de descarga de subprocesos múltiples
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{
item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{
item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{
item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
nums = executor.map(download_img, item_df.item_id)
Todas las imágenes descargadas en segundos:

Generar documentos Markdown
Generemos el documento Markdown correspondiente, primero organicemos los datos:
item_type_dict = {
1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
item_df
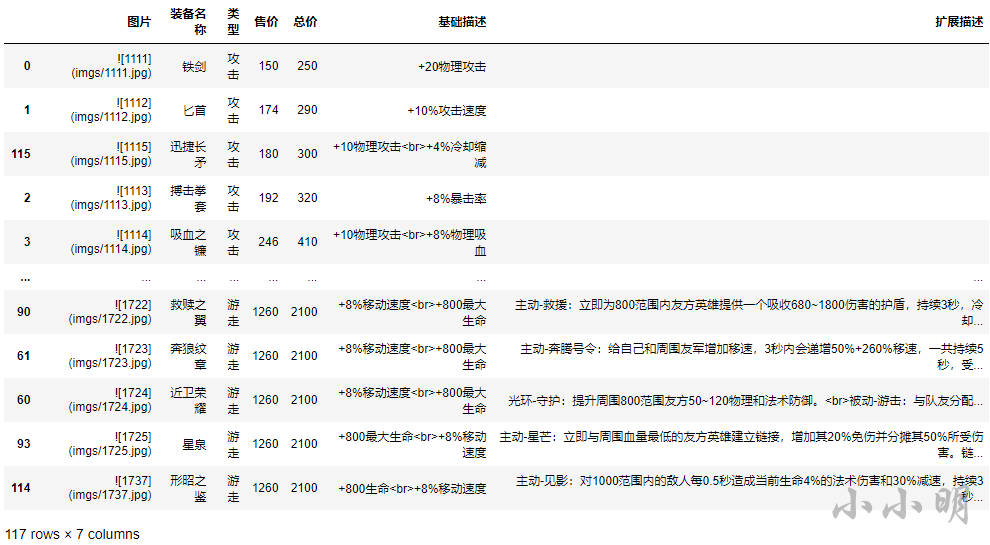
Agrupar por tipo de equipo para generar documentos Markdown:
with open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {
item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n")
El Markdown generado es el siguiente:
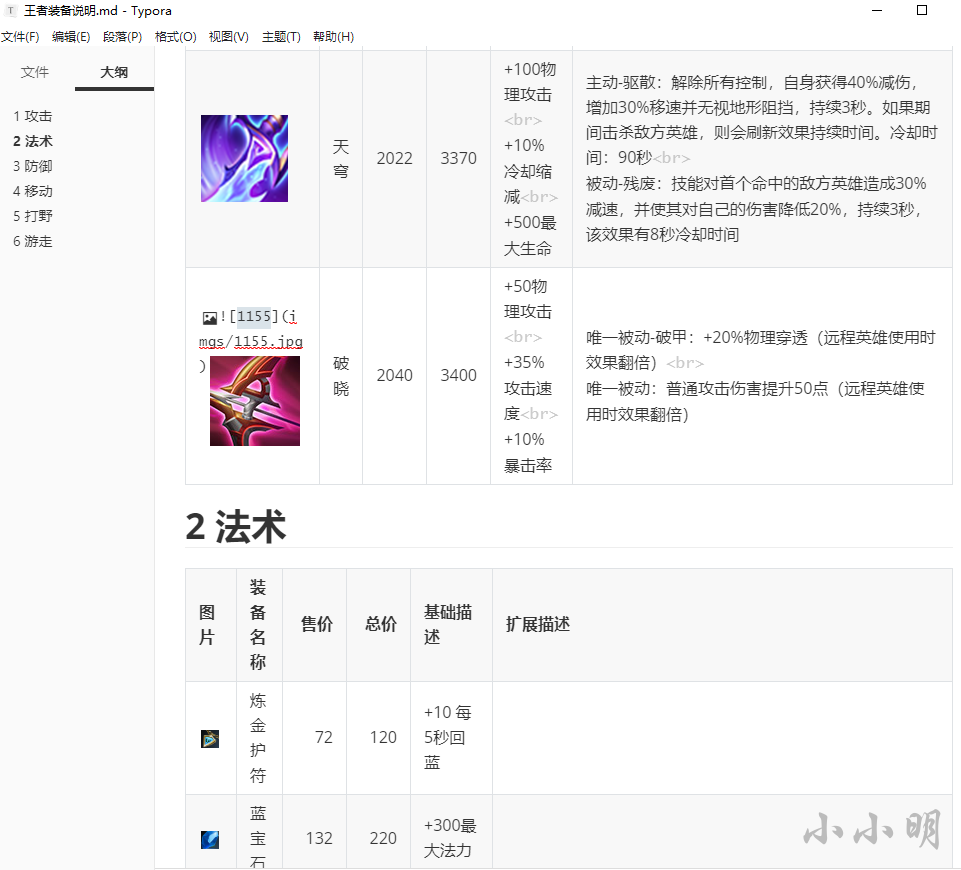
Sin embargo, la tabla de Markdown no se puede ajustar arbitrariamente y se debe hacer clic en la imagen para ampliarla. Consideremos generar una tabla de Excel:
Generar Excel
Primero organiza los datos:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("<br>", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("<br>", "\n")
item_df

Luego escribe la hoja de Excel:
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{
item_id}.jpg"), f'A{
cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()
El resultado es el siguiente:

Después de algunos ajustes manuales:
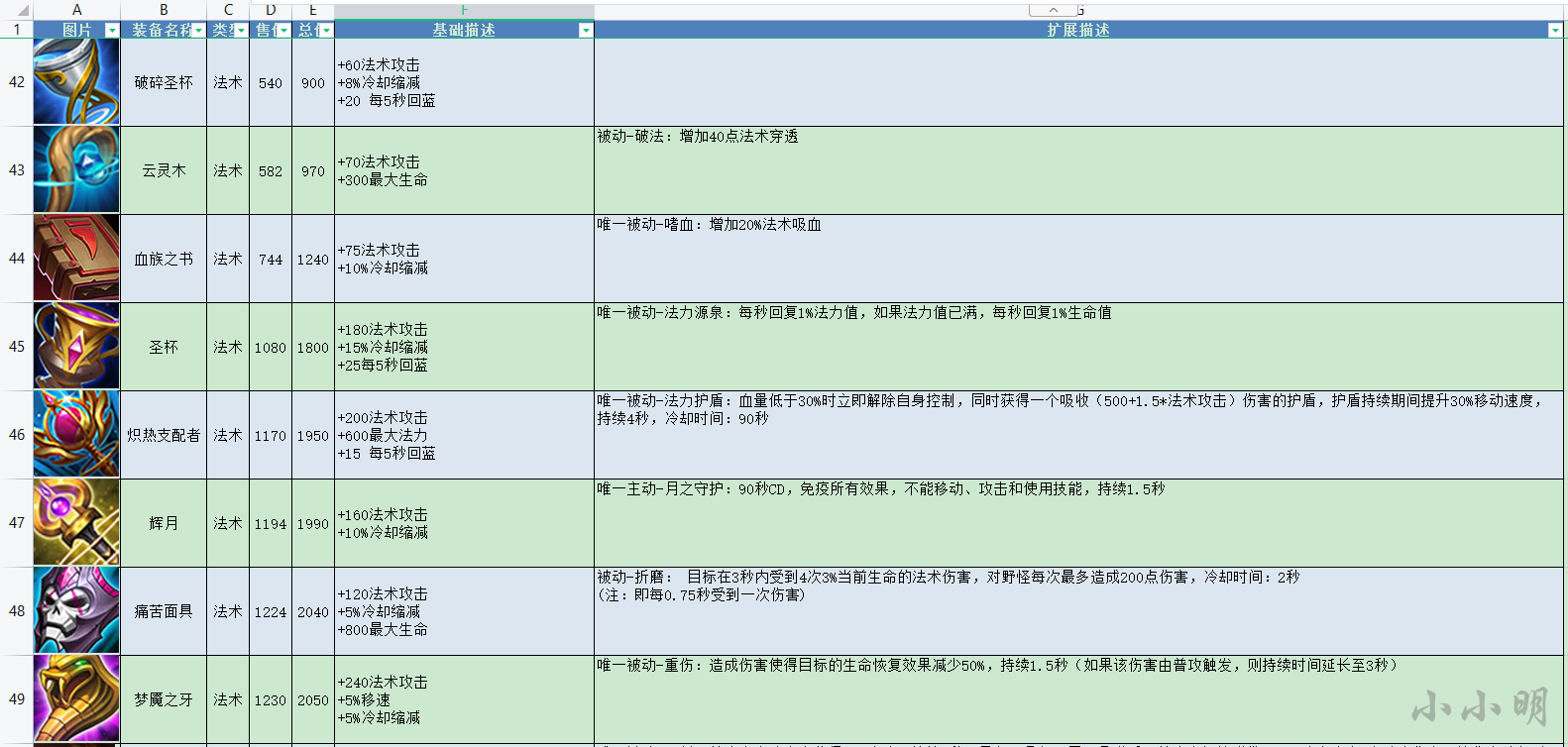
También puedes generar HTML y Word según el efecto que desees.