Tabla de contenido
Una vez completada la primera ejecución, la base de datos de destino tendrá dos tablas más:
1: Modifique el archivo de script histórico, se informará el siguiente error cuando se ejecute
ps: optimización del paquete de archivos
Introducción
Liquibase es una herramienta de código abierto para la reconstrucción y migración de bases de datos, registra los cambios en la base de datos en forma de archivos de registro y luego ejecuta las modificaciones en los archivos de registro para actualizar o revertir la base de datos a un estado coherente. Su objetivo es proporcionar una solución independiente del tipo de base de datos para lograr la migración mediante la ejecución de archivos de tipo esquema. Las principales ventajas son las siguientes:
- Admite casi todas las bases de datos convencionales, como MySQL, PostgreSQL, Oracle, Sql Server, DB2, etc .;
- Apoyar el mantenimiento colaborativo de múltiples desarrolladores;
- Los archivos de registro admiten varios formatos, como XML, YAML, JSON, SQL, etc .;
- Admite múltiples modos de operación, como línea de comando, integración de Spring, complemento de Maven, complemento de Gradle, etc.
instalación
- Descarga y descomprime Liquibase: https://download.liquibase.org
- Instalar java (configurar variables de entorno)
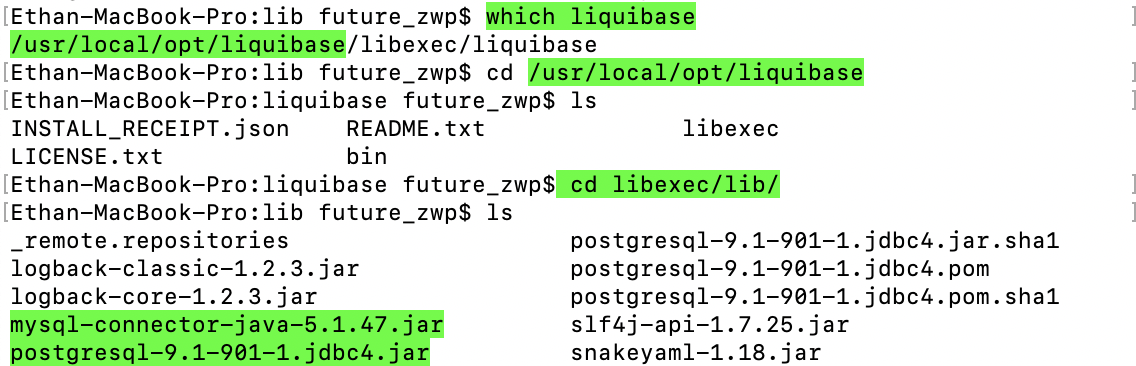
- Descargue el paquete del controlador de la base de datos y colóquelo en la biblioteca en el directorio Liquibase
usar
Hay dos casos de uso, uno se usa en un proyecto completamente nuevo y el otro se usa en un proyecto antiguo (es decir, hay estructuras de tablas históricas y datos en la base de datos, y changeLog debe generarse a la inversa).
Para proyectos antiguos, use las dos soluciones de liquibase:
Uno: puede ordenar el ddl actual en la base de datos del proyecto (tal vez no solo ddl, algunos datos de la tabla también deben mantenerse en liquibase, esto depende de los requisitos específicos del proyecto) y mantenerlo en un changeLog inicializado como un script de inicialización, para que pueda ejecutar el script de inicialización en el nuevo entorno ( ** En este caso, preste especial atención a especificar el contexto en el changeSet, y también debe especificar los contextos al ejecutar, para evitar ejecutar el script de inicialización en el entorno anterior * * ).
Dos: liquibase tiene un comando especial para generar changeLog a la inversa, generateChangeLog. (En cuanto a si es fácil de usar o no, todavía no lo he probado. Lo añadiré cuando lo pruebe ...)
- liquibase crea el directorio en el proyecto
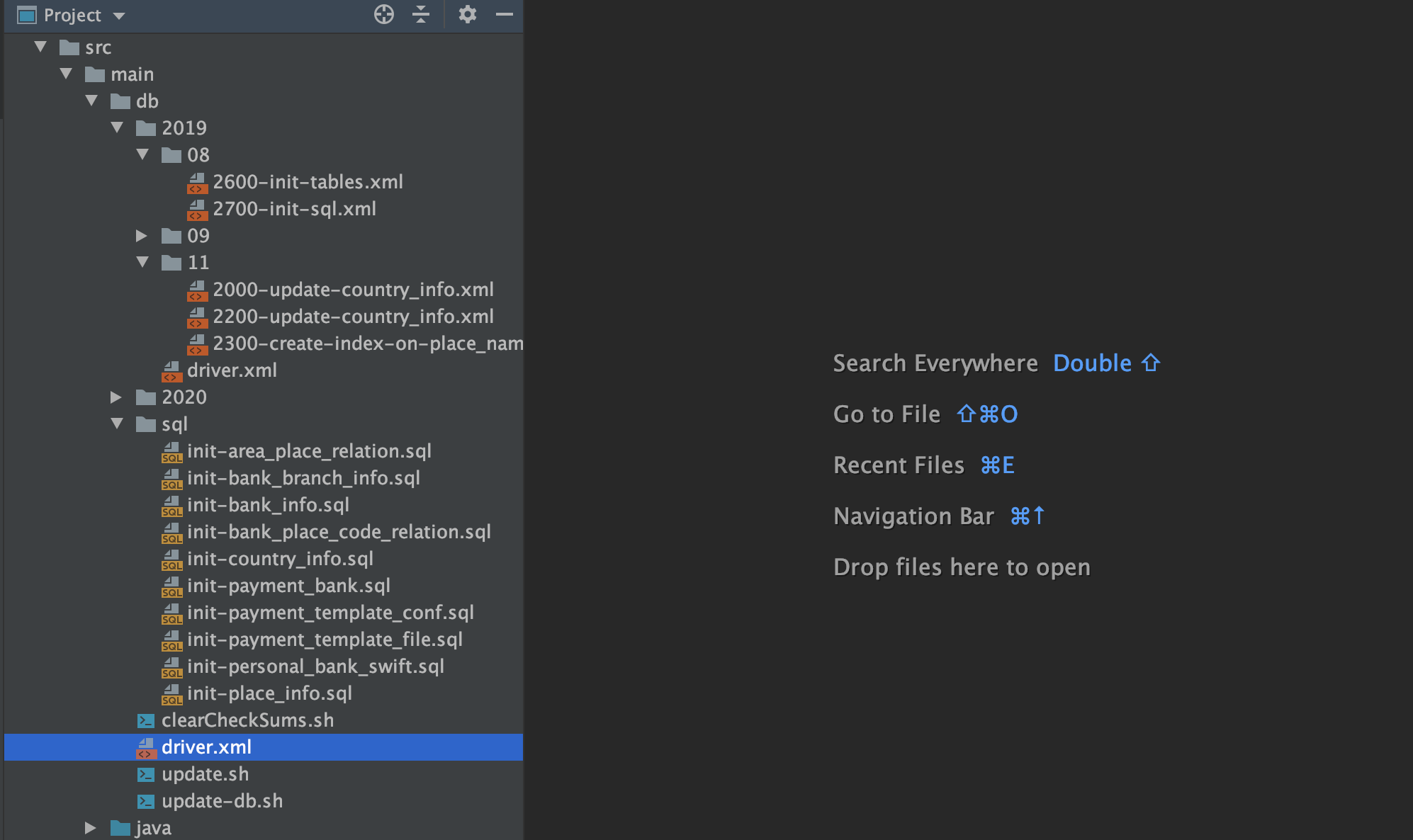
- src / main / db / sql / init-personal_bank_swift.sql
Defina un archivo sql, este archivo sql puede ser referenciado y ejecutado directamente por el changeSet en otro changeLog
INSERT INTO personal_bank_swift (bank_code, clearing_code, swift_code, create_by, create_at, updated_by, updated_at) VALUES
('bank_code2300', '012', 'BKCHHKHHXXX', null, null, null, null),
('bank_code2302', '009', 'CCBQHKAXXXX', null, null, null, null),
('bank_code2304', '041', 'LCHBHKHHXXX', null, null, null, null),
('bank_code2305', '040', 'DSBAHKHHXXX', null, null, null, null),
('bank_code2306', '032', null, null, null, null, null);- src / main / db / 2019/08/2600-init-tables.xml
- changeLog: xml (** es el concepto de registro de cambios en liquibase, se puede anidar en varias capas para hacer referencia a otros registros de cambios **)
- incluir : referencia a la etiqueta del registro de cambios
- archivo : consulte la textura del archivo de registro de cambios
- changeSet : Un changeLog puede contener múltiples etiquetas changeSet. Cada changeSet se identifica de forma única por los atributos id, autor y ruta de archivo. Cuando Liquibase ejecuta el changeLog de la base de datos, lee el changeSet en orden y comprueba la tabla de registro de cambios de la base de datos para cada changeSet. Se ejecuta la combinación id / autor / ruta de archivo. Si ya se está ejecutando, el changeSet se omitirá a menos que haya una etiqueta runAlways real. Después de ejecutar todos los cambios en el changeSet, Liquibase inserta una nueva fila con id / author / filepath y MD5Sum del changeSet en el databasechangelog. Cada changeSet es independiente. La mejor práctica es asegurarse de que cada changeSet se cambie de la forma más atómica posible para evitar el resultado de fallas y dejar las sentencias restantes sin procesar en la base de datos en un estado desconocido.
- autor : autor
- id : El id del changeSet (** Es mejor usar el formato de fecha 2019082600-01 para hacerlo más claro. Si una biblioteca de destino puede ser ejecutada por la liquibase de varios proyectos, el id se escribirá en el mismo databasechangelog table, puede agregar el nombre del proyecto o la abreviatura del nombre del proyecto delante de la fecha para distinguir, como reference-2019082600-01)
- runAlways : realiza los cambios establecidos en cada ejecución, incluso si se ha ejecutado antes del cambio
- contexto : se puede usar para controlar de manera flexible el entorno en el que se ejecuta el script. Nuestro sistema generalmente define el entorno (como team2, uat, prod), si hay más de uno, puede usar o y dividir, y también admite la forma invertida de! prod (* * Si el contexto está definido, los contextos deben especificarse al ejecutar. Si no se especifica, se ejecutarán todos los sql y el contexto no será válido)
- comentario: la descripción del conjunto de cambios .
- preConditions : las precondiciones que deben pasarse antes de que se ejecute el changeSet . Se puede utilizar para realizar comprobaciones de la integridad de los datos en busca de contenido irrecuperable.
- rollback : Describe cómo revertir la instrucción SQL del changeSet o refactorizar la etiqueta
- createTable: crea una etiqueta de tabla
- tableName : nombre de la tabla
- columna: la etiqueta del campo de la tabla
- nombre : nombre del campo
- tipo: tipo de campo
- observaciones: observaciones de campo
- restricciones : restricciones de campo
- primaryKey : verdadero representa la clave principal
- anulable : verdadero, falso
- único : verdadero, falso
- createIndex: crea la etiqueta del índice
- indexName : nombre del índice
- tableName : el nombre de la tabla donde se crea el índice
- columna: la etiqueta del campo de índice (múltiples representantes del índice conjunto)
- nombre : nombre del campo
- addColumn: agrega la etiqueta del campo
- tableName : agrega el nombre de la tabla del campo
- columna: campo agregado
- nombre : nombre del campo
- tipo: tipo de campo
- sql: etiqueta sql, el contenido puede ser directamente declaración sql
- endDelimiter : el delimitador que se aplicará al final de la declaración. El valor predeterminado es;, se puede establecer en ''.
- splitStatement : verdadero, falso
- stripComments : establézcalo en true para eliminar cualquier comentario en el SQL antes de la ejecución; de lo contrario, false. en caso
- Si no se establece, el valor predeterminado es falso
- comentario : comentario
- sqlFile : la etiqueta que hace referencia al archivo sql
- ruta : consulte la dirección del archivo sql
<?xml version="1.1" encoding="UTF-8" standalone="no"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd">
<!--第一种标签建表方式-->
<changeSet author="future_zwp (generated)" id="reference-2019082600-00" context="team2,uat,prod">
<createTable tableName="personal_bank_swift">
<column name="id" type="serial">
<constraints primaryKey="true"/>
</column>
<column name="bank_code" type="text" remarks="银行编码"></column>
<column name="clearing_code" type="text" ></column>
<column name="swift_code" type="text" ></column>
<column name="create_by" type="text" ></column>
<column name="created_at" type="timestamp"></column>
<column name="updated_by" type="text" ></column>
<column name="updated_at" type="timestamp"></column>
<column name="pt" type="text"></column>
</createTable>
<rollback>
<dropTable tableName="personal_bank_swift"/>
</rollback>
</changeSet>
<changeSet author="future_zwp (generated)" id="reference-2019082600-01" context="team2,uat,prod">
<createIndex indexName="idx_bank_info_bank_clearing" tableName="personal_bank_swift">
<column name="bank_code"/>
<column name="clearing_code"/>
</createIndex>
</changeSet>
<changeSet author="future_zwp (generated)" id="reference-2019082600-02" context="team2,uat,prod">
<createIndex indexName="idx_personal_bank_swift_swift_code" tableName="personal_bank_swift">
<column name="swift_code"/>
</createIndex>
</changeSet>
<!--第二种sql建表方式,所有的sql语句都支持,学习成本低,更灵活-->
<changeSet author="zhaowenpeng" id="reference-2019082600-03" context="team2,uat,prod">
<sql splitStatements="true">
drop table if exists personal_bank_swift;
create table personal_bank_swift
(
id serial primary key,
bank_code text,
clearing_code text,
swift_code text,
create_by text,
create_at timestamp(6),
updated_by text,
updated_at timestamp(6)
);
comment on column personal_bank_swift.bank_code
is '银行编码';
create index idx_bank_info_bank_clearing on personal_bank_swift(bank_code,clearing_code);
create index idx_personal_bank_swift_swift_code on personal_bank_swift(swift_code);
</sql>
</changeSet>
<!--引用sql文件-->
<changeSet author="zhaowenpeng" id="reference-2019082600-04" context="team2,uat,prod">
<sqlFile path="sql/init-personal_bank_swift.sql"></sqlFile>
</changeSet>
</databaseChangeLog>- src / main / db / 2019 / driver.xml
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.3.xsd">
<include file="2019/08/2600-init-tables.xml"/>
</databaseChangeLog>- src / main / db / driver.xml
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.3.xsd">
<include file="2019/driver.xml"/>
<include file="2020/driver.xml"/>
</databaseChangeLog>
Ejecución local de changeLog
- src / main / db / update.sh (Este archivo solo se puede ejecutar localmente, idea puede instalar bashSupport, haga clic con el botón derecho en el archivo para ejecutarlo)
El valor de contextos corresponde al valor de contexto del changeSet (si no se satisface, el changeSet no se ejecutará) y se leerá el changeLogFile.
Driver.xml en el mismo directorio de paquetes
#!/usr/bin/env bash
liquibase \
--driver=org.postgresql.Driver \
--changeLogFile=driver.xml \
--url=jdbc:postgresql://118.31.105.14:3546/team2_reference_data \
--username=team2_app \
--password=8sVG98uziKfAEqzM \
--contexts=team2 \
updateLa ejecución está completa:

Pasos de ejecución de Jenkins
- src / main / db / maycur / update-db.sh
#!/bin/bash
DB_HOST="127.0.0.1"
DB_PORT="3306"
DB_TYPE="mysql"
DB_NAME="maycur-pro"
DB_USER="maycur"
DB_PASSWORD="Maycur@2018"
DB_DRIVER="com.mysql.jdbc.Driver"
OPERATOR="update"
CONTEXTS=''
function help_info() {
echo "Please use the canonical setttings: "
echo "./update-db.sh -h <DB_HOST> -p <DB_PORT> -d <DB_NAME> -u <DB_USER> -w <PASSWORD> -t <DB_TYPE> \
-o <OPERATOR>"
echo "ATTENTION! DB_TYPE alternatives would be *mysql* or *postgresql*, nothing more"
exit 1
}
while [[ $# -gt 0 ]]
do
case "$1" in
"-h")
shift
echo "DB_HOST: $1"
DB_HOST=$1
;;
"-p")
shift
echo "DB_PORT: $1"
DB_PORT=$1
;;
"-d")
shift
echo "DB_NAME: $1"
DB_NAME=$1
;;
"-u")
shift
echo "DB_USER: $1"
DB_USER=$1
;;
"-w")
shift
#echo "DB_PASSWORD: $1"
DB_PASSWORD=$1
;;
"-t")
shift
echo "DB_TYPE: $1"
DB_TYPE=$1
if [ "$DB_TYPE" = "mysql" ]; then
DB_DRIVER="com.mysql.jdbc.Driver"
elif [ "$DB_TYPE" = "postgresql" ]; then
DB_DRIVER="org.postgresql.Driver"
else
help_info
fi
echo "DB_DRIVER: $DB_DRIVER"
;;
"-c")
shift
echo "CONTEXTS: $1"
CONTEXTS=$1
;;
"-o")
shift
OPERATOR=$1
;;
*)
shift
;;
esac
shift
done
echo "NOW COMES the EXECUTION..."
/opt/liquibase/liquibase \
--driver=$DB_DRIVER \
--changeLogFile=driver.xml \
--url="jdbc:$DB_TYPE://$DB_HOST:$DB_PORT/$DB_NAME?useSSL=false&useUnicode=yes" \
--username=$DB_USER \
--password=$DB_PASSWORD \
--contexts=$CONTEXTS \
$OPERATOR
if [ $? -eq 0 ]; then
echo "Congratulations! Things are all set, you are good to go!"
else
echo "Oops! Something just went wrong. You're gonna have to take a look at it"
exit 1
fi- Cree un proyecto en jenkins, configure configure
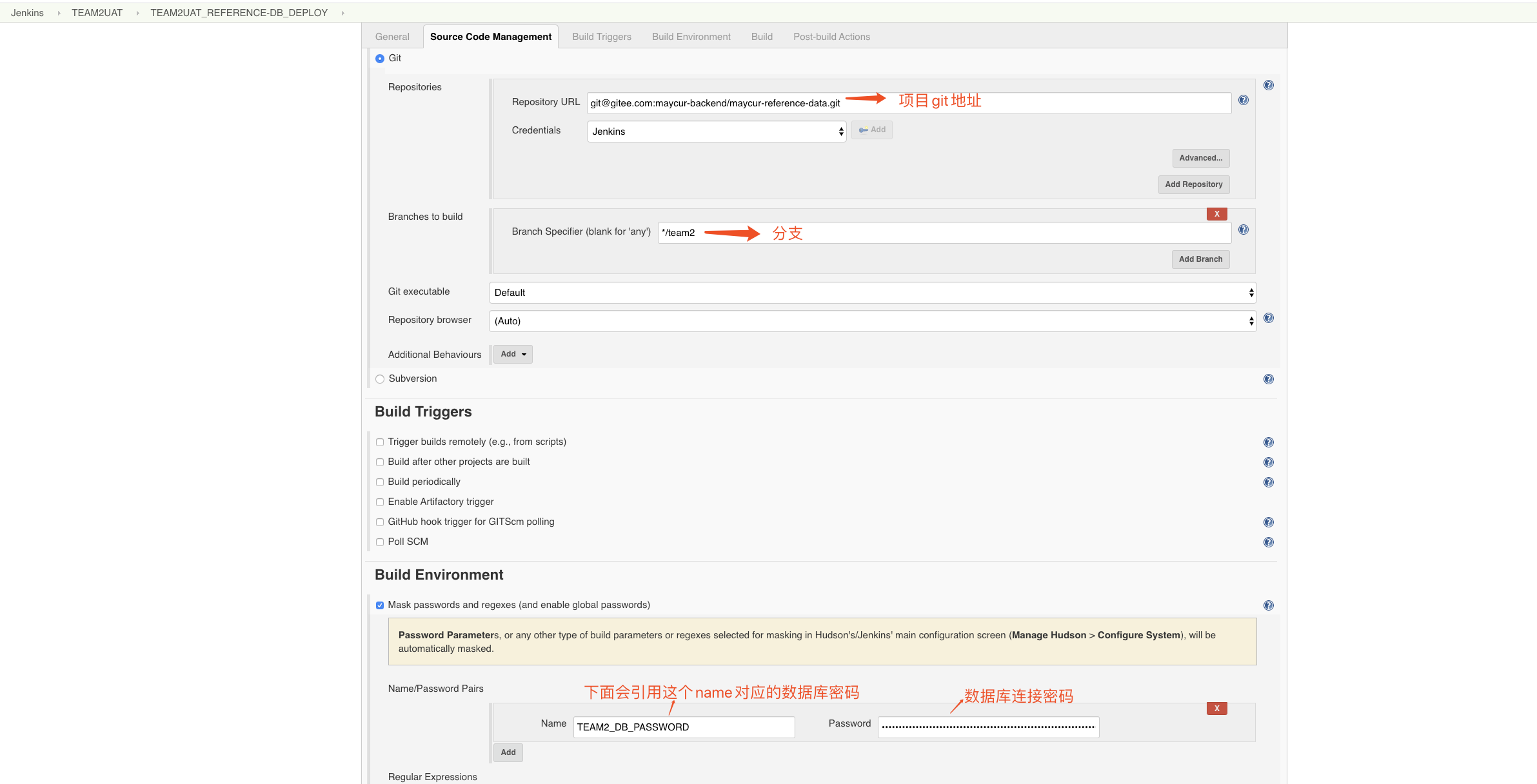
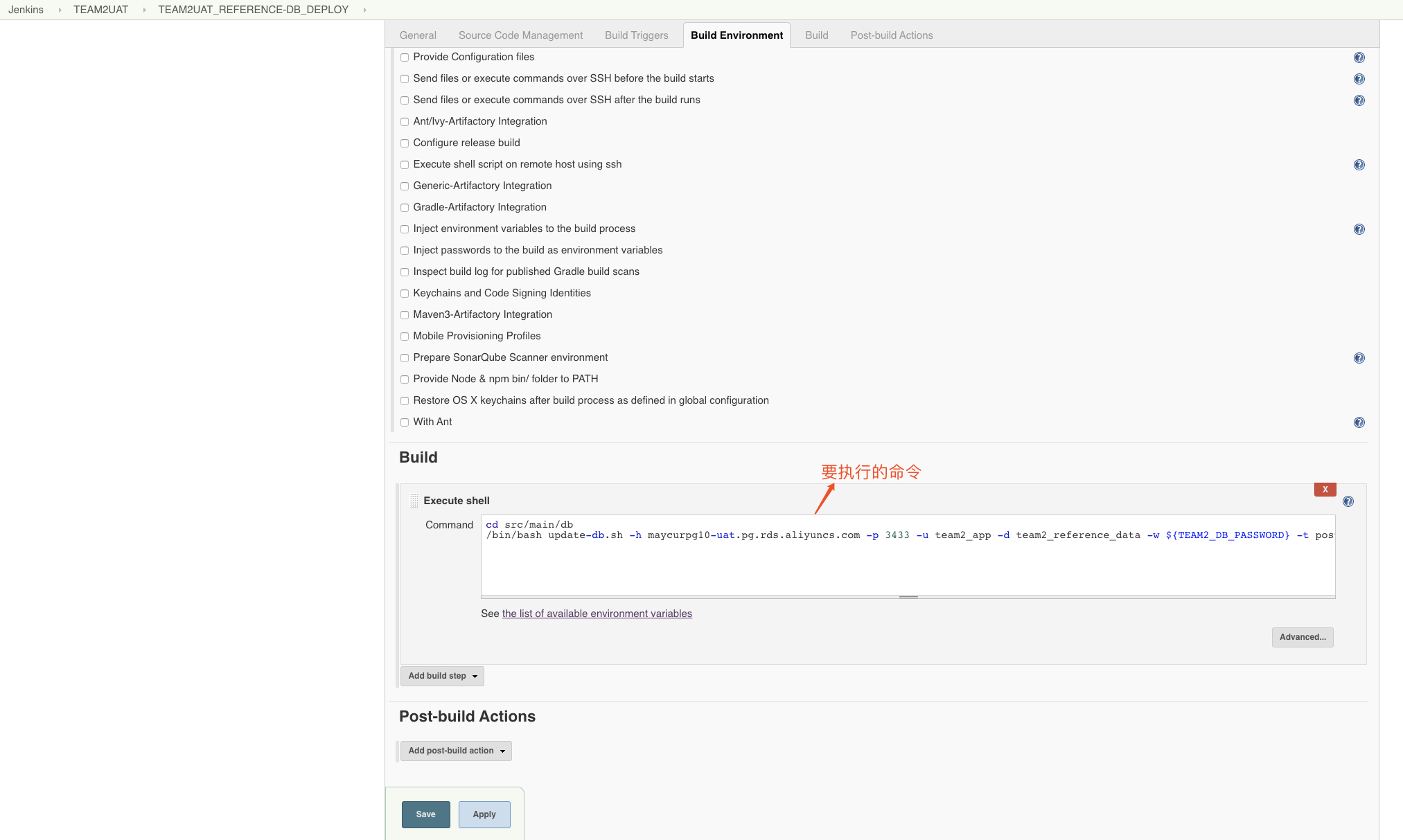
cd src/main/db
/bin/bash update-db.sh -h maycurpg10-uat.pg.rds.aliyuncs.com -p 3433 -u team2_app -d team2_reference_data -w ${TEAM2_DB_PASSWORD} -t postgresql -c team2 -o update- Simplemente guarde y ejecute (antes de la ejecución, asegúrese de que el servidor esté instalado con liquibase y que el paquete jar del controlador de base de datos requerido esté ubicado en la carpeta lib bajo el directorio liquibase)
Descripción del parámetro Update-db.sh:
cd src / main / db Esto es para ingresar al directorio donde existe update-db.sh
-h host de conexión de base de datos
-p puerto de conexión de base de datos
-u nombre de usuario de conexión a la base de datos
-d nombre de la biblioteca de la base de datos
-w contraseña de usuario de conexión a la base de datos (aquí se hace referencia al nombre configurado en jenkins)
-t tipo de base de datos
-c especifica contextos, necesita cooperar con el contexto en el changeSet para ejecutar condicionalmente sql
-o actualizar 、 clearCheckSums
Una vez completada la primera ejecución, la base de datos de destino tendrá dos tablas más:
DATABASECHANGELOG 表
Liquibase utiliza la tabla de registro de cambios de la base de datos para realizar un seguimiento de los conjuntos de cambios que se han ejecutado.
La tabla rastrea cada configuración de cambio como una fila, identificada por la combinación de las columnas id, autor y nombre de archivo de la ruta donde se almacena el archivo de registro de cambios.
| Columna | Tipo de datos estándar | descripción |
ID |
VARCHAR(255) |
changeSetEl idvalor de la propiedad |
AUTHOR |
VARCHAR(255) |
changeSetEl authorvalor de la propiedad |
FILENAME |
VARCHAR(255) |
changelogruta de. Esta puede ser una ruta absoluta o una ruta relativa, dependiendo de changelogcómo se transmita Liquibase. Para obtener los mejores resultados, debe ser una ruta relativa |
DATEEXECUTED |
DATETIME |
changeSetFecha / hora de ejecución . Y se ORDEREXECUTEDutilizan juntos para determinar la reversión del pedido. |
ORDEREXECUTED |
INT |
changeSetEl orden de ejecución . Además DATE EXECUTED, pero también para garantizar el orden correcto, incluso si la base de datos también admite la poca precisión de la fecha y la hora. Nota: El aumento del valor garantizado es solo en una única ejecución de actualización. A veces se reiniciarán en cero. |
EXECTYPE |
VARCHAR(10) |
changeSetUna descripción de cómo se realiza. Los valores posibles son EXECUTED, FAILED, SKIPPED, RERAN, yMARK_RAN |
MD5SUM |
VARCHAR(35) |
changeSetVerifique durante la ejecución . Para cada ejecución para asegurarse de que el changelogarchivo changSetno se cambie accidentalmente |
DESCRIPTION |
VARCHAR(255) |
changeSetDescripción legible generada |
COMMENTS |
VARCHAR(255) |
changeSetcommentEl valor de la etiqueta |
TAG |
VARCHAR(255) |
changeSetEl seguimiento corresponde a la operación de etiquetado. |
LIQUIBASE |
VARCHAR(20) |
Para la ejecución changeSetde la Liquibaseversión |
** La tabla no tiene clave primaria. Esto es para evitar restricciones específicas de la base de datos sobre la longitud de la clave.
DATABASECHANGELOGLOCK 表
Liquibase utiliza la tabla databasechangeloglock para garantizar que solo se esté ejecutando una instancia de Liquibase a la vez.
Debido a que Liquibase solo lee de la tabla de registro de cambios de la base de datos para determinar el changeSet que debe ejecutarse, si se ejecutan varias instancias de Liquibase en la misma base de datos al mismo tiempo, se producirán conflictos. Esto puede suceder si varios desarrolladores utilizan la misma instancia de base de datos o si varios servidores del clúster ejecutan Liquibase automáticamente al inicio.
| Columna | Tipo de datos estándar | descripción |
ID |
INT |
El ID de la cerradura. Actualmente solo hay un candado, pero será útil en el futuro |
LOCKED |
INT |
Si está Liquibaseejecutando contra esta base de datos se establece en "1". De lo contrario, establezca en "0" |
LOCKGRANTED |
DATETIME |
Fecha y hora en que se adquirió el candado |
LOCKEDBY |
VARCHAR(255) |
Descripción de quién estaba bloqueado |
** Si Liquibase no sale limpiamente, las filas bloqueadas pueden permanecer bloqueadas. Puede borrar el bloqueo actual ejecutando UPDATE DATABASECHANGELOGLOCK SET LOCKED = 0
Errores comunes:
1: Modifique el archivo de script histórico, se informará el siguiente error cuando se ejecute
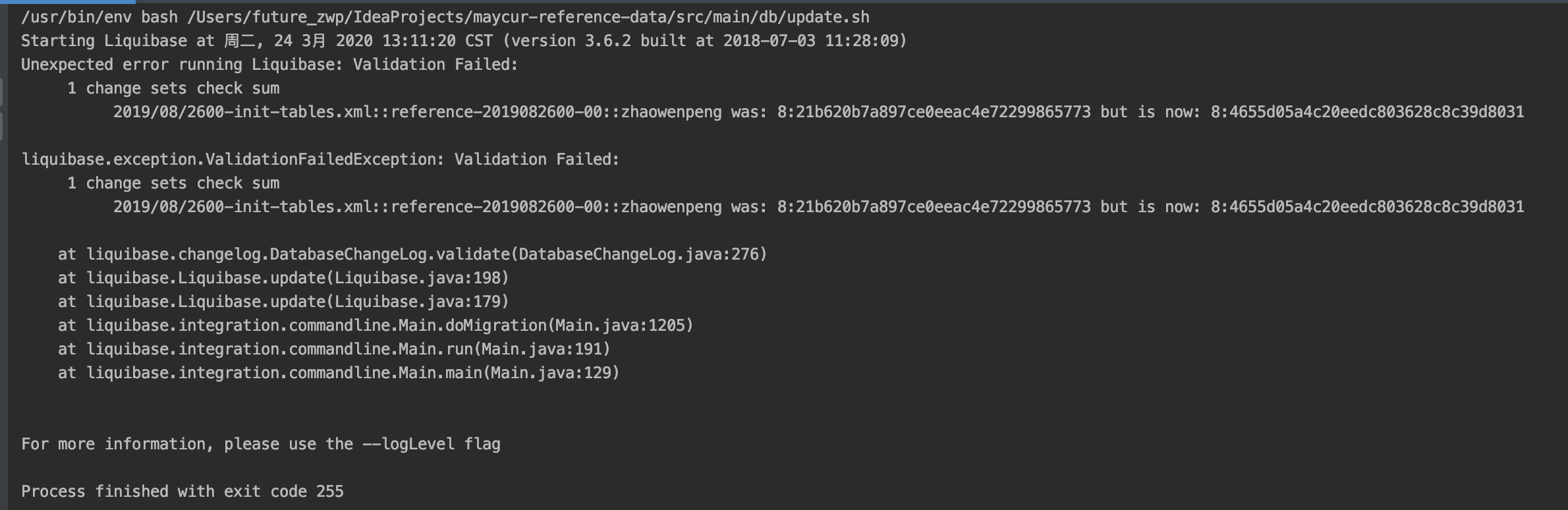
Si necesita ignorar los cambios en este script en este momento, puede cambiar el valor de actualización en src / main / db / update.sh a clearCheckSums y ejecutarlo nuevamente, y luego volver a ejecutar el script.
2: Si la ejecución no se ha completado, es posible que la base de datos esté bloqueada por un liquibaselock anormal.
En este momento, puede conectarse a la base de datos que ejecuta el script, seleccione * from databasechangeloglock;
Si encuentra que bloqueado está en un estado bloqueado, detenga el script, cambie bloqueado a 0 y luego vuelva a ejecutar el script.

ps: optimización del paquete de archivos
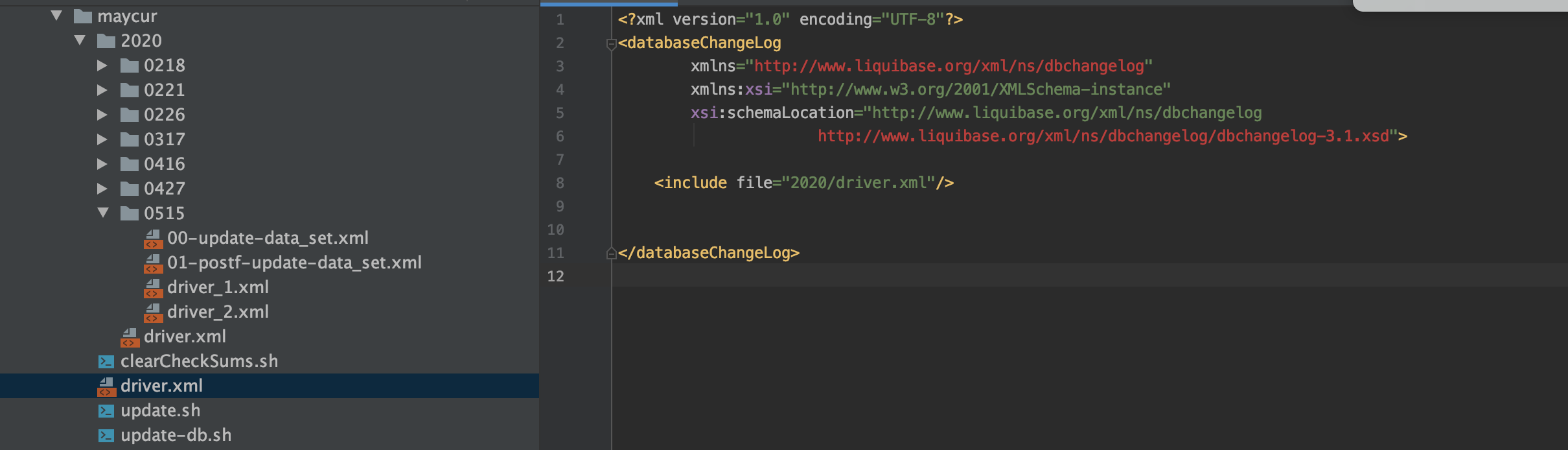
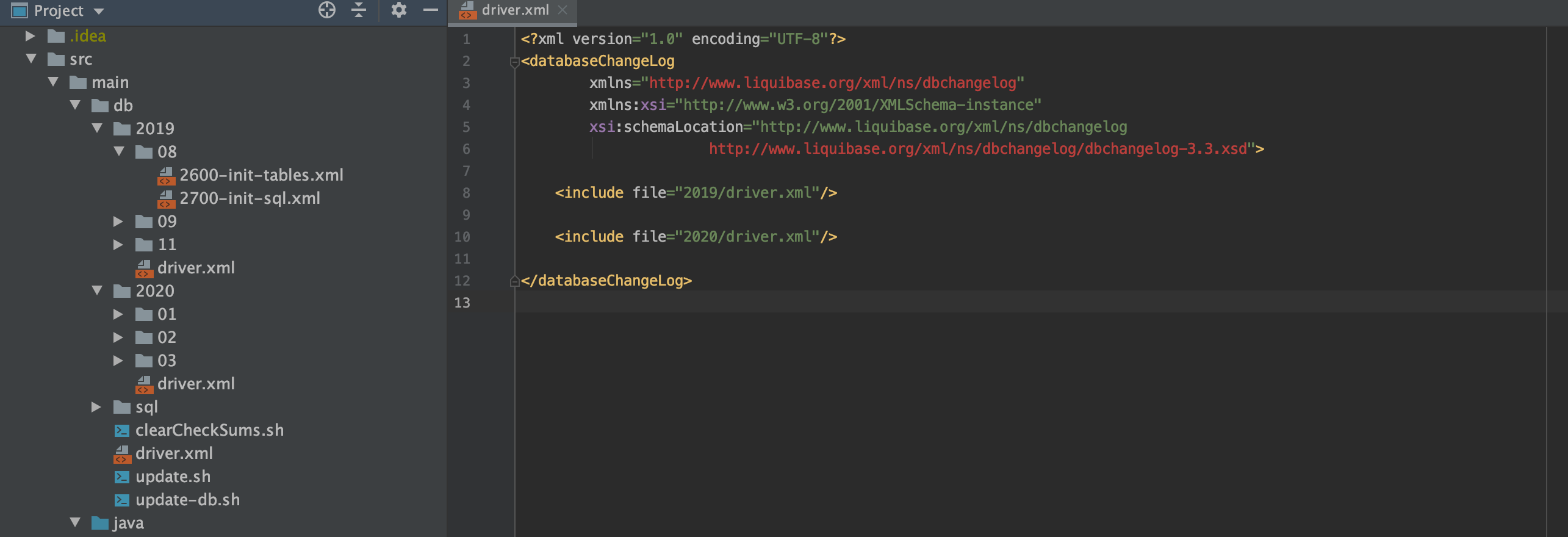
1. Escena 1:
Si coloca todos los archivos xml en un paquete, la estructura del archivo no será muy elegante con el tiempo y el contenido en driver.xml será muy largo. Cada vez que agregue un script, debe agregarlo al final del file., La experiencia es extremadamente mala, por lo que es muy importante definir una estructura de archivo sostenible desde el principio. La solución se muestra en la figura: simplemente agregue el catálogo de un año después de un año.
- Crear directorio db
- Cree un directorio del año en el directorio db
- Cree el driver.xml del directorio del mes y el nivel del año en el directorio del año.
- Cree un script para ejecutarlo en el directorio del mes.
- Cree driver.xml de nivel de año en el directorio de año (incluya los archivos xml en todos los meses en el directorio de año)
- Cree driver.xml de nivel de db en el directorio db (incluya archivos driver.xml en todos los años en el directorio db)
- Al ejecutar, ejecute driver.xml en el directorio db.
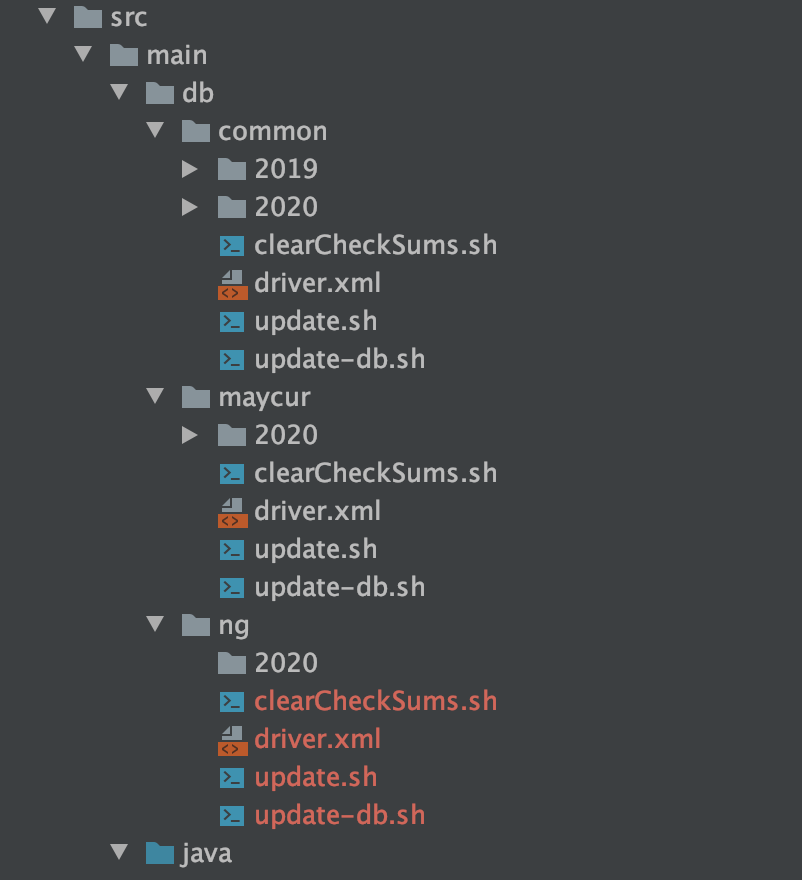
2. Escena dos:
Tenemos dos líneas de productos maycur y ng. Ambas líneas de productos usan el mismo proyecto. Sin embargo, debido a las diferencias en algunas líneas de productos, algunos scripts SQL serán inconsistentes en las dos líneas de productos. En este momento, deben ejecutarse por separado. Arriba. La estrategia de esta solución es clasificar los archivos ejecutados, poner los archivos que pueden ser ejecutados por ambas líneas de producto en la carpeta común, que solo se utilizará en la carpeta a prueba de balas maycur de los archivos ejecutados por maycur, y poner los archivos que se ejecutan sólo en la carpeta ng. Hay driver.xml y update.sh separados en common, maycur, ng y tres directorios. De esta manera, puede implementar de manera diferente al implementar:
- maycur: ejecuta update.sh en los directorios common y maycur
- ng: ejecuta update.sh en los directorios common y ng
3. Escena tres:
A veces, el SQL mantenido en liquibase puede fallar al ejecutarse debido a la versión de la base de datos en un entorno particular. En este momento, el script mantenido por liquibase no será modificado. Generalmente, el programa de modificación del sql se ejecutará directamente en el base de datos para lograr el objetivo. Pero esta solución también vendrá acompañada de algunos problemas (el changSet donde se encuentra el sql siempre se ejecutará sin éxito y no se podrá ejecutar hacia abajo), en este momento debemos considerar cómo ignorar este script.
- Opción uno (no muy recomendable):
Inserte manualmente un registro de ejecución en la tabla de registro de cambios de la base de datos en la biblioteca de destino. Cada conjunto de cambios se identifica de forma única por los atributos id, autor y ruta de archivo, por lo que estos tres valores deben corresponder estrictamente al script que se ignorará (o del base de datos ejecutada Copie el registro de la base de datos changelog correspondiente a sql para insertar, preste atención a los valores inigualables de contextos y versiones de liquibase a cambiar). Debido a que el valor de md5 puede ser diferente, en este momento, ejecute clearCheckSums antes de volver a ejecutar el script.
- Opción dos (recomendada):
Un changeSet puede tener múltiples scripts sql. Nuestro escenario solo puede cambiar un sql. En este momento, podemos cambiar el sql correspondiente a un sql sin sentido (por ejemplo: seleccione 1) para ejecutar liquibase nuevamente. En este momento, la tabla databasechangelog tiene el registro de ejecución correspondiente.En este momento, podemos volver a cambiar el sql y volver a borrarCheckSums.
4. Escena cuatro:
Nuestro servicio de informes tendrá muchas tablas con una gran cantidad de datos, y cada vez que se lanza una versión, cuando se usa liquibase para realizar operaciones DDL en estas tablas, debido a las características de polardb, tomará mucho tiempo. Finalmente, después de ejecutar liquibase, tenemos que ir a Ejecutar la tarea del almacén de datos de inicialización completa (esta operación borrará primero los datos de la tabla), lo que hace que el tiempo de liberación se extienda aún más. Para solucionar este problema, hemos resumido un plan.
Pasos de liberación:
1. Ejecute update.sh después de especificar 2020/0515 / driver_1.xml en changeLogFile en update.sh
2. Tareas de inicialización del almacén de datos relacionadas con la ejecución del almacén de datos
3 Ejecute update.sh después de especificar driver.xml en changeLogFile en update.sh
4. Implementar servicios de front-end y back-end
(Debido a que el primer y segundo paso son todas tablas temporales operativas, se pueden ejecutar con anticipación)
- Para cada versión, creamos un paquete, como 0515.
Cree dos archivos driver_1.xml y driver_2.xml en este paquete
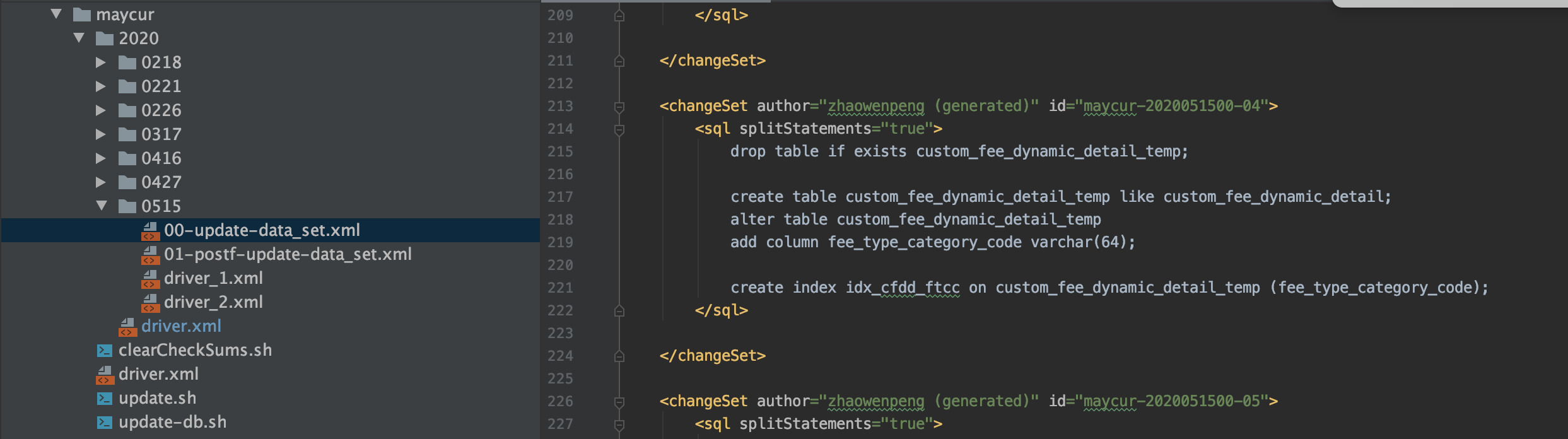
1. En driver_1.xml, incluya el archivo xml que se ejecutará en el primer paso, como se muestra en la figura siguiente. Cuando queramos agregar campos a la tabla custom_fee_dynamic_detail, crearemos una tabla temporal de custom_fee_dynamic_detail_temp, y luego agregaremos campos en la tabla custom_fee_dynamic_detail_temp. La salida de la tarea de inicialización del almacén de datos se puede especificar para que se envíe a custom_fee_dynamic_detail_temp
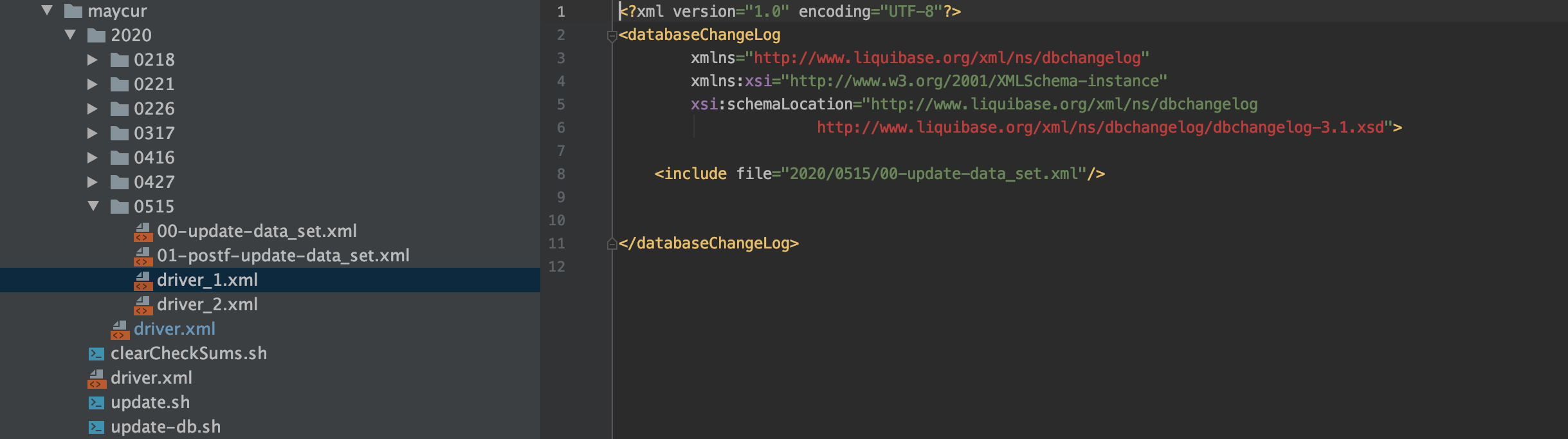
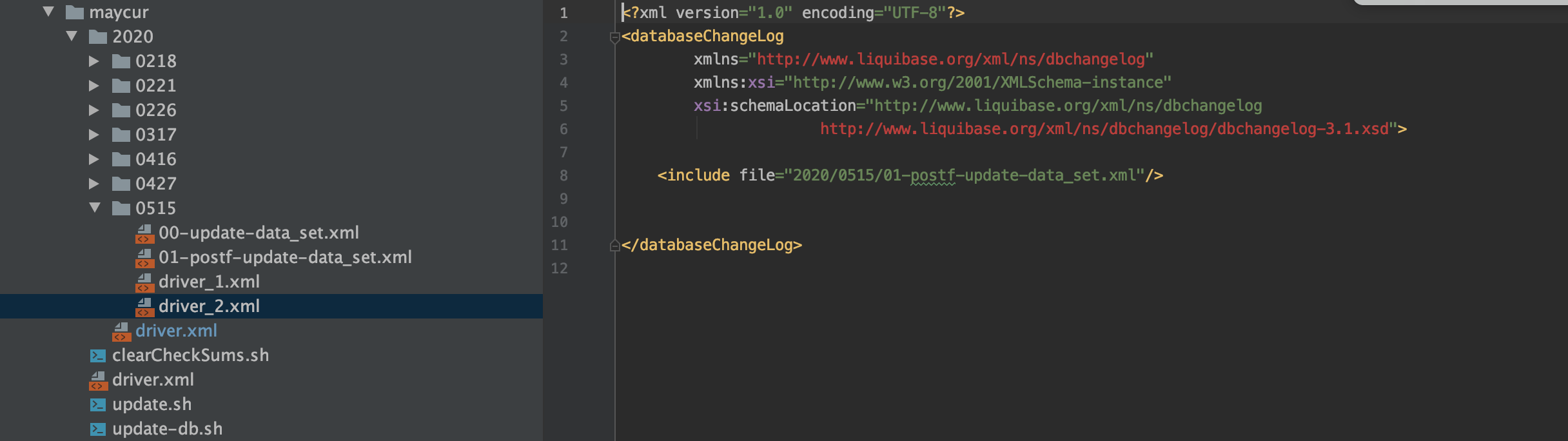
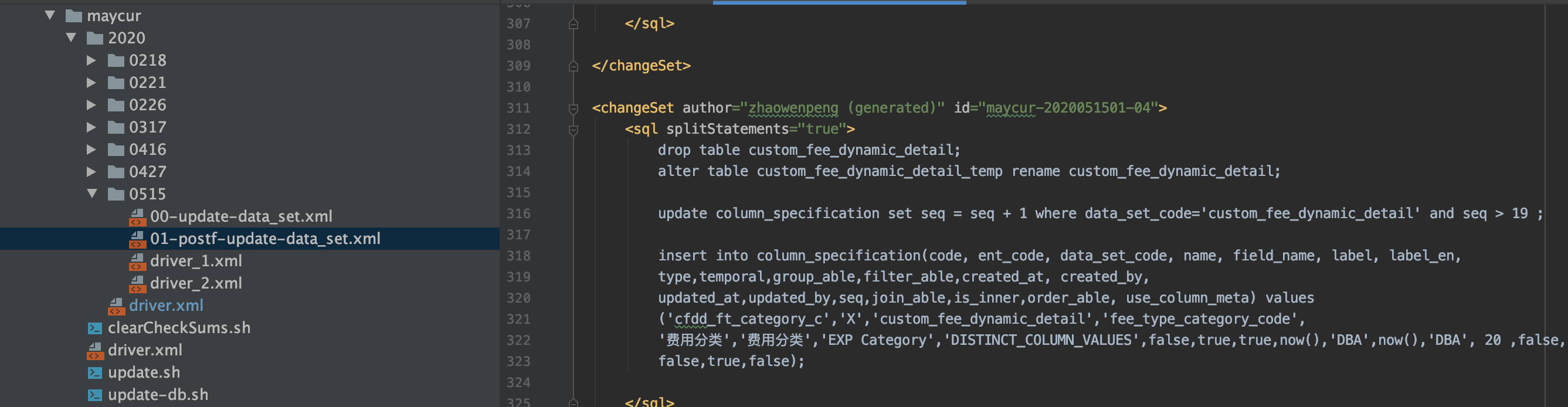
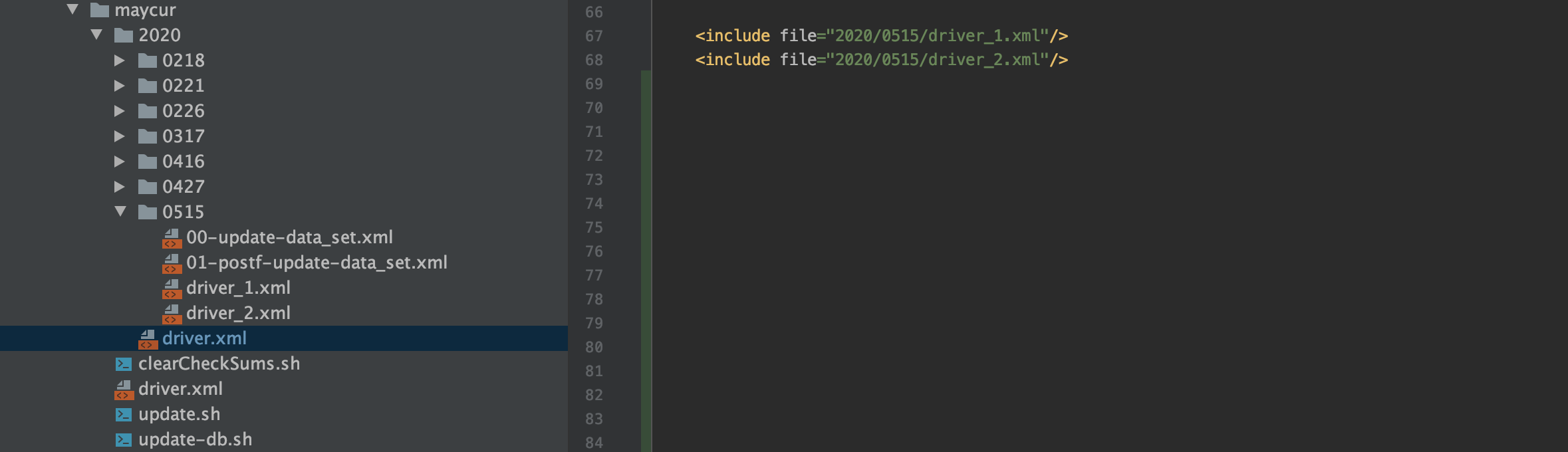
2. El archivo xml que se ejecutará en el segundo paso se puede incluir en driver_2.xml, como se muestra en la figura siguiente. Cuando se especifica que la tarea de inicialización del almacén de datos se envíe a custom_fee_dynamic_detail_temp, eliminaremos la estructura de datos anterior table custom_fee_dynamic_detail, y luego agregaremos la tabla temporal custom_fee_dynamic_detail_temp Renombrar nuevamente a custom_fee_dynamic_detail, y luego en otro lugar puede consultar la tabla custom_fee_dynamic_detail de la nueva estructura de datos
- Driver.xml en el paquete 2020
- driver.xml en el paquete maycur