Tabla de contenido
Uno: modo local
1. Introducción al modo local
El modo local es un modo que se ejecuta en una computadora y generalmente se usa para entrenar y probar en esta máquina. Puede configurar el Master de la siguiente manera centralizada.
local: Todos los cálculos se ejecutan en un Núcleo, no hay cálculo paralelo, generalmente ejecutamos algún código de prueba en la máquina, o practicamos manos, usamos este modo;
local [K]: Especifica K núcleos para ejecutar cálculos, como local [4] es ejecutar 4 núcleos para ejecutar;
2. Construir en modo local
1. Después de descomprimir el paquete tar, se puede usar directamente sin configuración relevante
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module/
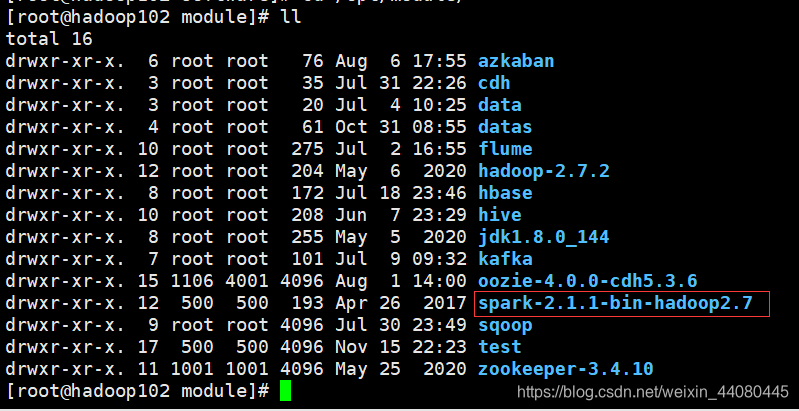
Después de la descompresión, cambie el nombre a spark-local mv spark-2.1.1-bin-hadoop2.7/ spark-local. No es necesario transferir el paquete tar descomprimido a otros nodos.
2. Ejecute el caso de PI oficial y ejecute el siguiente script en / opt / module / spark-local.
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
Dos: construcción en modo autónomo
1.Introducción al modo autónomo:
El modo independiente se refiere al modo de operación del clúster que usa el administrador de recursos nativo de Spark. Requiere el uso de nodos maestro y trabajador. Entre ellos, el nodo maestro es responsable del control, administración y monitoreo de recursos de los nodos trabajadores en el clúster.
2. Construcción del modo autónomo:
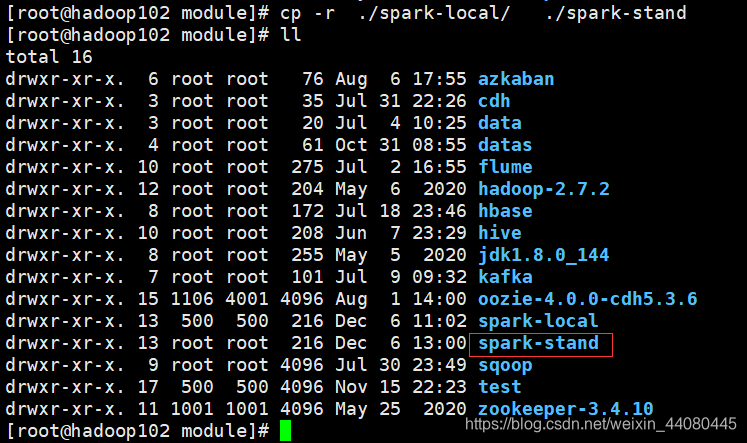
2.1 Ejecute el paquete tar descomprimido en / opt / module [root@hadoop102 module]# cp -r ./spark-local/ ./spark-stand
2.2 Ingrese al directorio conf debajo de spark-stand y cambie el nombre de los dos archivos slaves.template y spark-env.sh.template a slaves spark-env.sh
mv slaves.template slaves
mv spark-env.sh.template spark-env.sh
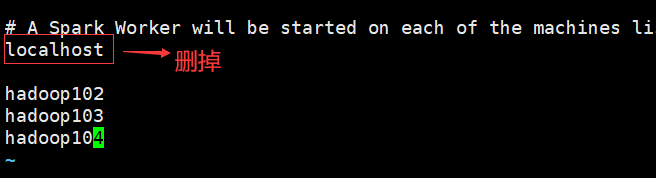
2.3 Ingrese el archivo de esclavos, elimine el localhost en la última línea y reemplácelo con hadoop102, hadoop103 y hadoop104. Estos tres son los nombres de host de mis máquinas de clúster. Aquí debe cambiarlo de acuerdo con su propio nombre de host.
2.4 Modifique spark-env.sh, agregue el siguiente contenido, guarde y salga.
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
2.5 Modifique el archivo spark-config.sh en spark-stand / sbin para agregar el siguiente contenido, cargue JAVA_HOME en él, si no conoce la ruta de instalación de jdk, puede hacer eco de $ JAVA_HOME para ver
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.6 Copie el soporte de chispas en otras dos máquinas
scp -r / opt / module / spark-stand root @ hadoop103: / opt / module
scp -r /opt/module/spark-stand root@hadoop103:/opt/module
scp -r /opt/module/spark-stand root@hadoop104:/opt/module
Una vez realizadas las operaciones anteriores, ejecutamos start-all.sh en spark-stand / sbin en hadoop102 para iniciar el grupo de chispas.
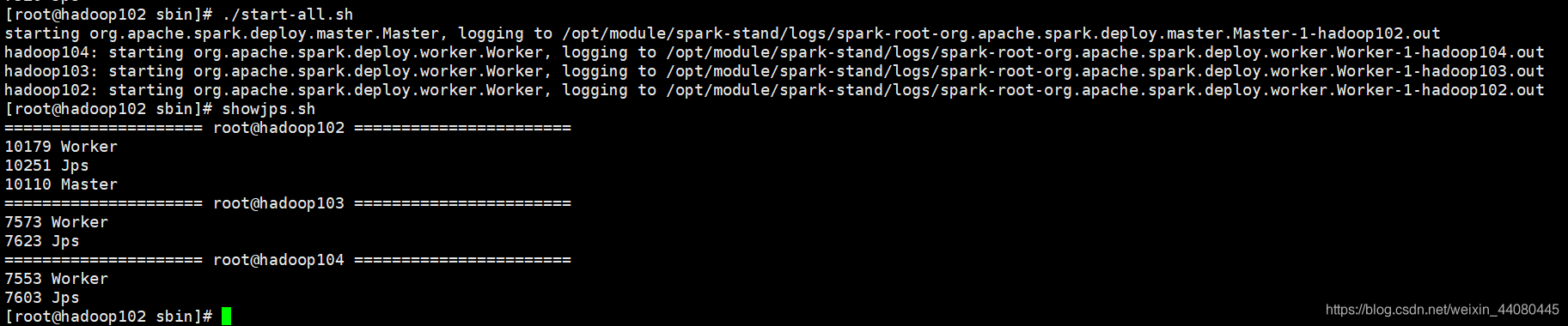
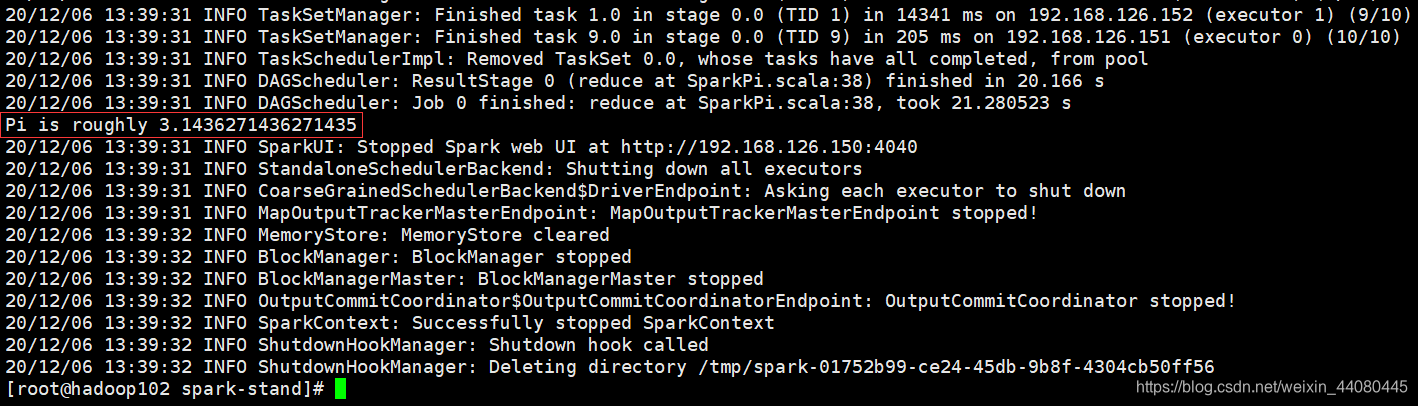
Ejecute la prueba de caso oficial nuevamente
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
Tres: modo de hilo
1. Introducción al modo hilo
El modo YARN se refiere a un modo de operación de clúster que usa YARN de Hadoop como administrador de recursos.
En el modo YARN, no necesita usar los nodos Master y Worker (es decir, no necesita crear un clúster de chispa adicional), pero use los nodos ResourceManager y NodeManager en YARN, que corresponden a los nodos Master y Worker en Standalone modo.
2. Construcción del modo de hilo
1. Copie el soporte de chispa en hadoop102 en el directorio actual
cp -r ./spark-stand/ ./spark-yarn
2. Ingrese spark-yarn / conf en hadoop102 para modificar spark-env.sh, y agregue el siguiente contenido para que Spark sepa dónde está el hilo.
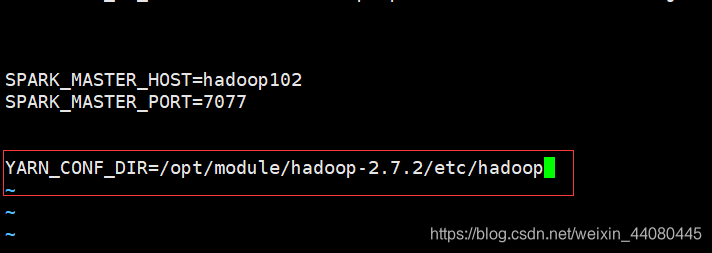
3. Edite el archivo yarn-site.xml en los tres hosts de hadoop102, hadoop103 y hadoop104 para agregar el siguiente contenido. Mi directorio es /opt/module/hadoop-2.7.2/etc/hadoop, puede usar el suyo directorio Realice los cambios correspondientes.
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4. Después de editar el contenido anterior en hadoop102, no hay necesidad de copiar spark-yarn a otra máquina, porque spark no necesita el modo de grupo en el modo de hilo, solo el grupo de hilo es suficiente porque el grupo de hilo ya existe antes de que Hadoop esté encendido .
5. Inicie hadoop ( tenga en cuenta que el modo de hilo en spark debe comenzar primero hadoop ) y ejecute el caso oficial
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.11-2.1.1.jar \
10
Tenga en cuenta que el --master aquí ha cambiado. Justo ahora era hadoop102: 7077 en modo autónomo, y aquí el modo de hilo ha cambiado a hilo .
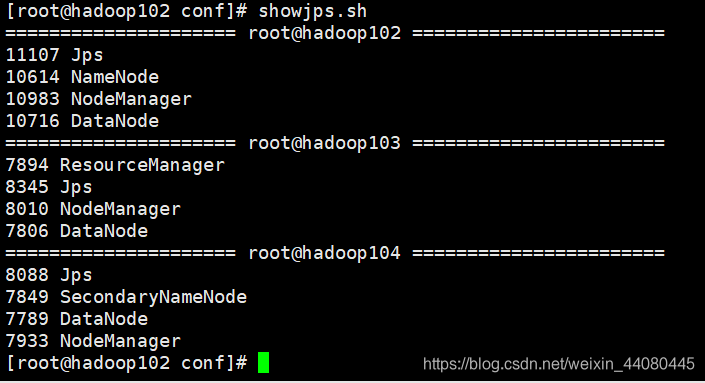
Cuando inicia la ventana de caparazón en modo hilo, puede encontrar el proceso correspondiente.
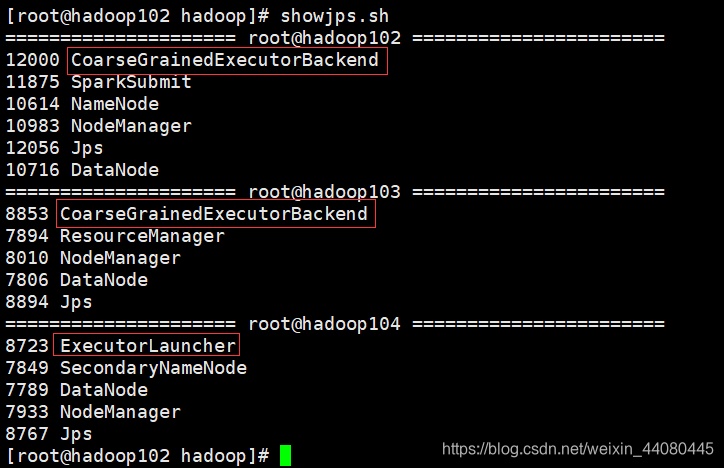
3. Configuración del servidor de historial de Spark
1. Cambie el nombre de spark-default.conf.template a spark-default.conf en spark-yarn / conf
mv spark-defaults.conf.template spark-defaults.conf
2. Modifique el archivo spark-default.conf, abra el Registro, preste atención al hadoop102 después de hdfs: // para que se reescriba de acuerdo con su nombre de host, lo mismo a continuación .
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:9000/directory

Nota: El directorio de directorio bajo Hadoop debe crearse de antemano ..
spark.eventLog.enabled: Habilitar registro
spark.eventLog.dir: Toda la información de la Aplicación durante la operación se registra en la ruta especificada por este atributo.
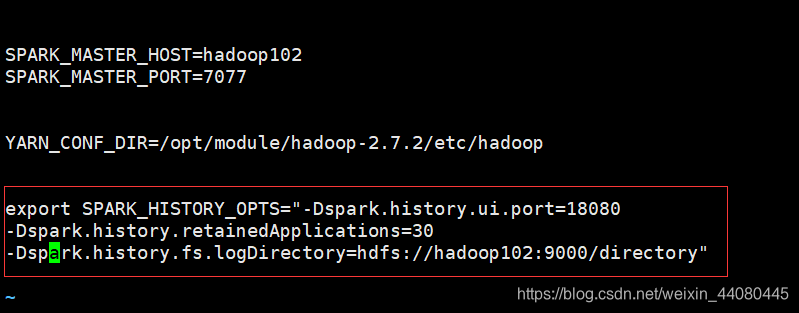
3. Modifique el archivo spark-env.sh y agregue el siguiente contenido
export SPARK_HISTORY_OPTS=
"-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9000/directory"
spark.history.ui.port: el número de puerto de la
interfaz de usuario web del historyServer en Spark spark.history.fs.logDirectory = hdfs: // hadoop102: 9000 / directory: una vez configurada esta propiedad, se establece en start-history -server.sh No es necesario especificar explícitamente la ruta, la página del servidor de historial de Spark solo muestra la información en la ruta especificada