Autores: Shuang Qing, Zhong Huang, Hong Xia

El modelo grande universal y unificado de pre-entrenamiento se ha convertido gradualmente en una tendencia importante en la investigación de IA. Este artículo presentará cómo el modelo multimodal OFA propuesto por Dharma Academy realiza las tres unificaciones de arquitectura, modalidad y tarea.
En los últimos años, el entrenamiento previo basado en datos no supervisados a gran escala se ha convertido gradualmente en un auge en la investigación de aprendizaje profundo, y los modelos de entrenamiento previo a gran escala han desempeñado gradualmente el papel de modelos básicos en el campo de la IA en virtud de su poderosas capacidades de rendimiento y migración del modelo. Recientemente, una serie de divulgaciones de progreso que incluyen Gato, el "Agente general de IA" de DeepMind, el modelo gráfico general Flamingo y Google Pathway, indican que el preentrenamiento multimodal a gran escala se ha convertido gradualmente en la infraestructura de la IA del futuro, y los modelos de IA se han convertido en Gradualmente se vuelven más generales y unificados. Los modelos grandes preentrenados universales y unificados se han convertido gradualmente en una tendencia importante en la investigación actual de IA.
La Academia DAMO está profundamente involucrada en el preentrenamiento multimodal y es la primera en explorar un modelo unificado general. Anteriormente, el Instituto Dharma lanzó varias versiones del modelo M6, explorando desde modelos densos a gran escala hasta modelos expertos mixtos a gran escala, y actualizando gradualmente de decenas de miles de millones de parámetros a diez billones de parámetros. verde/bajo Se han hecho algunos avances en las aplicaciones de IA de carbono, servitización y punto brillante. Este año, Dharma Institute se centró en romper el paradigma unificado (modalidad, tarea y arquitectura) del marco general de preformación multimodal M6-OFA, con la esperanza de reducir la dificultad del modelo en la preformación, adaptándose a las modalidades y tareas posteriores. , y razonamiento, para proporcionar de manera más conveniente capacitación previa, ajuste fino de tareas posteriores, implementación de modelos y publicación de aplicaciones de servicios de proceso completo a gran escala. En la actualidad, M6-OFA ha sido aceptado por la 39.ª Conferencia Internacional sobre Aprendizaje Automático (ICML 2022), que es una de las tres principales conferencias en el campo del aprendizaje automático.
La idea central del modelo unificado multimodal OFA es expresar tareas multimodales en forma de generación de secuencia a secuencia, combinadas con instrucciones específicas de tareas para lograr un entrenamiento previo multitarea en la arquitectura clásica de codificador-decodificador de transformador, para lograr las tres unificaciones siguientes.
-
Arquitectura unificada: al usar un decodificador de codificador de transformador unificado para el entrenamiento previo y el ajuste fino, ya no es necesario diseñar capas de modelo específicas para diferentes tareas, y los usuarios ya no se preocupan por el diseño del modelo y la implementación del código.
-
Unificación modal: unifique NLP, CV y tareas multimodales en el mismo marco y paradigma de capacitación. Incluso si no es un experto en el campo de CV, puede acceder fácilmente a datos de imágenes y jugar con la visión, el lenguaje y los modelos de IA multimodal.
-
Unificación de tareas: la tarea se expresa uniformemente en forma de Seq2Seq. Tanto el entrenamiento previo como el ajuste fino se entrenan utilizando el paradigma generativo. El modelo puede aprender varias tareas al mismo tiempo, lo que permite que un modelo obtenga múltiples capacidades a través de un pre -entrenamiento, incluida la generación de texto y la generación de imágenes, comprensión intermodal, etc.
En la actualidad, el enorme modelo OFA con alrededor de mil millones de parámetros no solo supera a Deepmind Flamingo y Google CoCa en múltiples tareas, como descripción gráfica y comprensión de referencias de objetos, sino que también tiene capacidades de generación de imágenes de alta calidad. ICML 2022 ha aceptado documentos relevantes, y los códigos, modelos y servicios interactivos correspondientes también han sido de código abierto. Los detalles de los documentos y proyectos de código abierto se pueden encontrar al final del artículo.
1. Efecto de la tarea OFA
Echemos un vistazo al efecto primero. OFA es bastante sorprendente en términos de desempeño de algunas tareas, la creación artística y la generación de imágenes reales no son un problema.

En términos de tareas de referencia de objetos en campo abierto, también se puede lograr un reconocimiento preciso en escenas de animación, ¡y Squirrel y Luffy no soltarán ninguno de ellos!
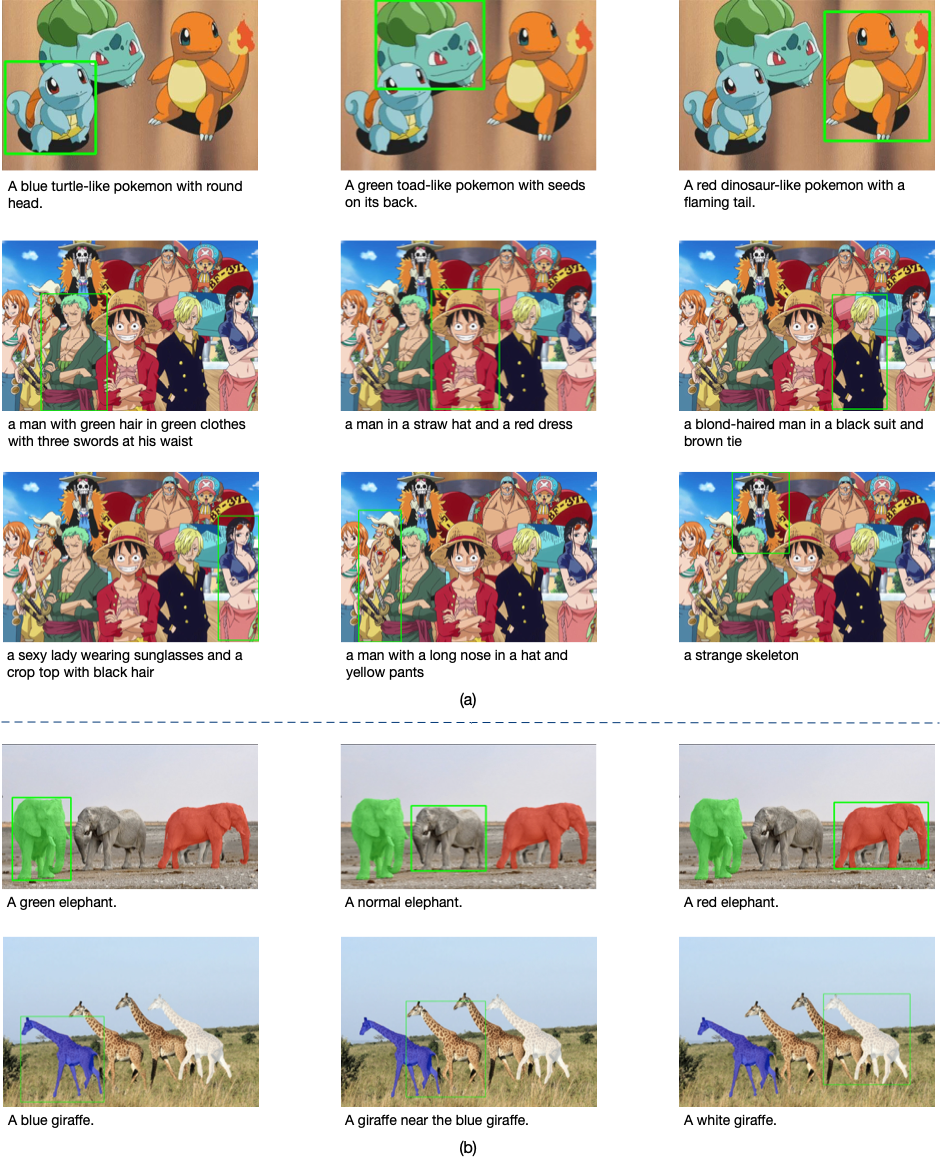
Debido a que se basa en la instrucción para el preentrenamiento multitarea, el modelo similar a T0 puede realizar algunas tareas que no se han aprendido en función de la comprensión de las instrucciones de la tarea, como las siguientes tareas nuevas, es decir, VQA para un área específica, el modelo solo necesita basarse en el problema de entrada y la representación de discretización de coordenadas dada puede hacer la respuesta correcta correspondiente:

No es difícil ver que OFA ha dado el primer paso en el camino de la "multimodalidad, multitarea", mostrando la capacidad del modelo pre-entrenado para realizar diferentes tareas de acuerdo con las instrucciones humanas, que también es un gran búsqueda del sistema Pathways de Google.
2. Principio básico de OFA
Los autores de OFA argumentan que el diseño general del modelo de IA requiere escalabilidad en términos de modalidad, tarea y tamaño del modelo. Con este fin, el artículo propone varias propiedades que deben cumplirse en el diseño de algoritmos, como la independencia de la tarea (TA), la modalidad independiente (MA) y la tarea enriquecida (TC), y señala varias razones por las que los modelos existentes no satisfacen estas propiedades al mismo tiempo. , incluidas las incoherencias en la representación de la tarea Pretrain/Finetune, el diseño estructural adicional relacionado con la tarea Finetune y la dependencia de entrada modal en ciertas tareas. A través de un marco seq2seq simple con tareas, modalidades y estructuras unificadas, OFA obtiene el rendimiento SOTA de muchas tareas intermodales de texto gráfico posteriores con la premisa de satisfacer las tres propiedades anteriores.
El principio de implementación de OFA es relativamente simple, y la arquitectura del modelo central es el codificador-decodificador de transformador más clásico. Para integrar el entrenamiento previo y el ajuste fino en esta arquitectura, OFA expresa varias tareas que involucran multimodalidad y modalidad única (es decir, NLP y CV) en forma de secuencia a secuencia, utilizando el codificador anterior. El decodificador el modelo se entrena, entrena previamente y ajusta sin agregar capas de modelo específicas de la tarea, como la capa de clasificación utilizada por BERT en el ajuste fino de la tarea de clasificación, para reducir la discrepancia entre el entrenamiento previo y el ajuste fino. En términos de implementación específica, OFA ha realizado una serie de diseños para un entrenamiento previo unificado, que incluye cómo realizar la entrada de información modal, como imágenes con diferentes resoluciones, texto y marcos de detección, y cómo unificar diferentes multimodales y tareas monomodales en La forma de secuencia a secuencia se muestra en la siguiente figura:
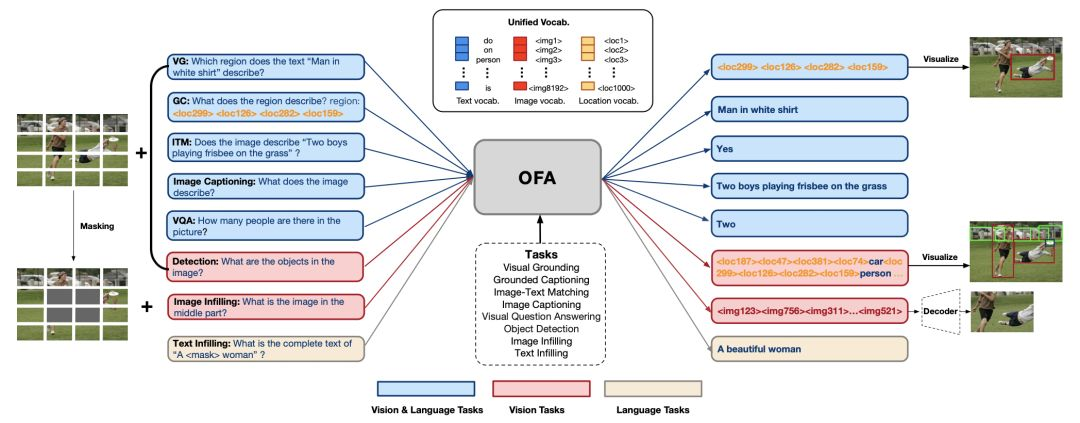
El objetivo general de OFA es lograr las tres unificaciones. El primero es la unificación de E / S. El problema a resolver es cómo ingresar y generar imágenes y texto en el modelo de transformador. En términos de entrada, la codificación BPE tradicional convierte la entrada de texto en una secuencia de incrustación para la entrada de texto, y la entrada de imágenes es relativamente complicada. En primer lugar, la imagen debe convertirse en forma de secuencia de incrustación, y el núcleo del método se realiza al referirse al subparche de ViT. En referencia a la implementación de CoAtNet y SimVLM, OFA conecta la imagen a ResNet y la convierte en incrustación de parches y luego la une con incrustación de texto.Para lograr mejores resultados, OFA agrega la parte de ResNet al entrenamiento del modelo. Sin embargo, para la salida de la imagen, la imagen aún debe expresarse discretamente. Por lo tanto, la implementación de OFA es consistente con el trabajo anterior de DALL-E y Beit. La imagen se convierte en código utilizando el modelo de cuantificación vectorial como objetivo de la modelo y el código se añade al vocabulario. . Además, dado que las tareas previas al entrenamiento del modelo incluyen subtítulos a tierra, puesta a tierra visual y detección de objetos, OFA también necesita procesar la entrada y salida de información de coordenadas. Específicamente, en referencia a la implementación de Pix2Seq, OFA convierte la información de coordenadas continuas en una representación discreta y la agrega al diccionario, integrando así texto, imágenes y coordenadas en un vocabulario unificado.
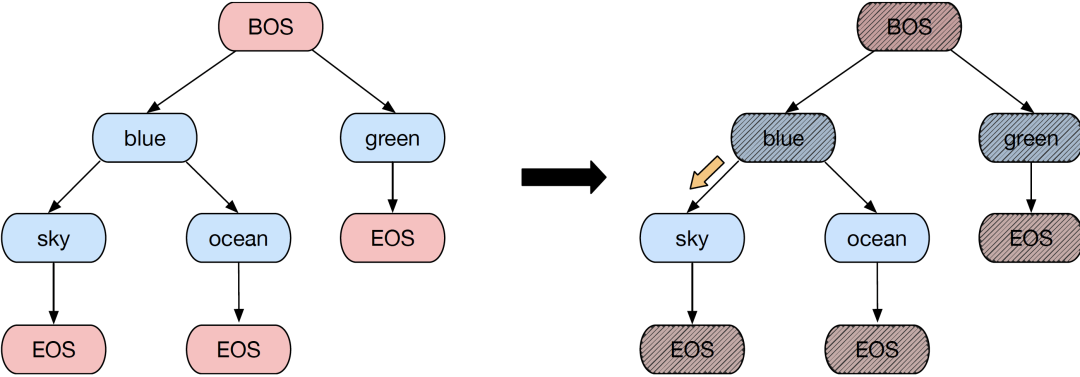
La implementación unificada de tareas se basa en la unificación de E / S mencionada anteriormente. Las tareas como los subtítulos de imágenes y VQA tienen la forma de Seq2Seq, y no se requieren cambios adicionales. Para tareas como puesta a tierra visual o detección de objetos, la salida debe expresarse en forma de secuencia. Específicamente, la información de coordenadas de cada objeto se puede expresar en forma de <x1, y1, x2, y2>, correspondiente a el objeto La esquina superior izquierda y la esquina inferior derecha del marco, y si necesita agregar etiquetas de categoría de objeto, agregue palabras de etiqueta después de las coordenadas, y las palabras de etiqueta también se expresan en codificación BPE. Para tareas como la generación de texto a imagen o el relleno de imágenes, simplemente convierta la imagen en código VQGAN. Para tareas de clasificación, OFA considera todas las etiquetas de clasificación como secuencias de texto. Lo que es más interesante es que para garantizar que el texto generado no se escape del espacio de la etiqueta, OFA usa el método de árbol Trie para limitar el espacio de generación al conjunto de etiquetas, de modo que el modelo pueda usar libremente la búsqueda de haz para generar etiquetas de categoría. en la etapa de inferencia No se preocupe por la salida fuera del espacio.
Para lograr los dos objetivos anteriores, es natural unificar las diferentes tareas de unimodalidad y multimodalidad en la misma arquitectura de Transformer. Pero para la optimización del efecto, OFA también agregó el método Normformer para mejorar la estabilidad del entrenamiento y agregó un árbol Trie para la tarea de clasificación para ayudar al modelo a lograr una mejora estable del efecto en la tarea de clasificación sin generar etiquetas fuera del conjunto.
conjunto de datos previo al entrenamiento
Los investigadores de OFA recopilaron datos de varias modalidades de varios conjuntos de datos públicos, incluidos unos 20 millones de datos multimodales, 35 millones de imágenes sin etiquetar y 140 GB de datos de texto sin formato. El conjunto de datos que utiliza OFA tiene una escala mucho más pequeña que otros modelos multimodales de preentrenamiento, como ALIGN (1800 millones de pares de imagen y texto), CLIP (400 millones de pares de imagen y texto), SimVLM (1800 millones de pares de imagen y texto, 800G texts), etc., pero M6-OFA aún puede superar a estos modelos en múltiples tareas posteriores. En el futuro, los investigadores de OFA dijeron que recopilarán conjuntos de datos previos al entrenamiento más grandes para estudiar más a fondo el impacto del aumento del tamaño de los datos en el rendimiento del modelo.
3. Escala modelo OFA
En los últimos años, muchos estudios sobre modelos de preentrenamiento han planteado el punto de vista de la ley de escalamiento, es decir, a medida que aumenta el tamaño de los datos y el tamaño del modelo, también aumentará el efecto del modelo. En este trabajo, los investigadores de OFA se centraron en el impacto del tamaño del modelo en el efecto y propusieron 5 modelos en el trabajo de OFA, con parámetros de modelo que van desde 33 millones a 940 millones. La configuración de parámetros específicos es la siguiente, como se muestra en la tabla:

Los resultados experimentales también muestran que el aumento del tamaño del modelo tiene un impacto muy significativo en la mejora del efecto del modelo, y el modelo OFA más grande también ha logrado el rendimiento de SOTA en múltiples tareas multimodales.
4. Resultados del experimento OFA
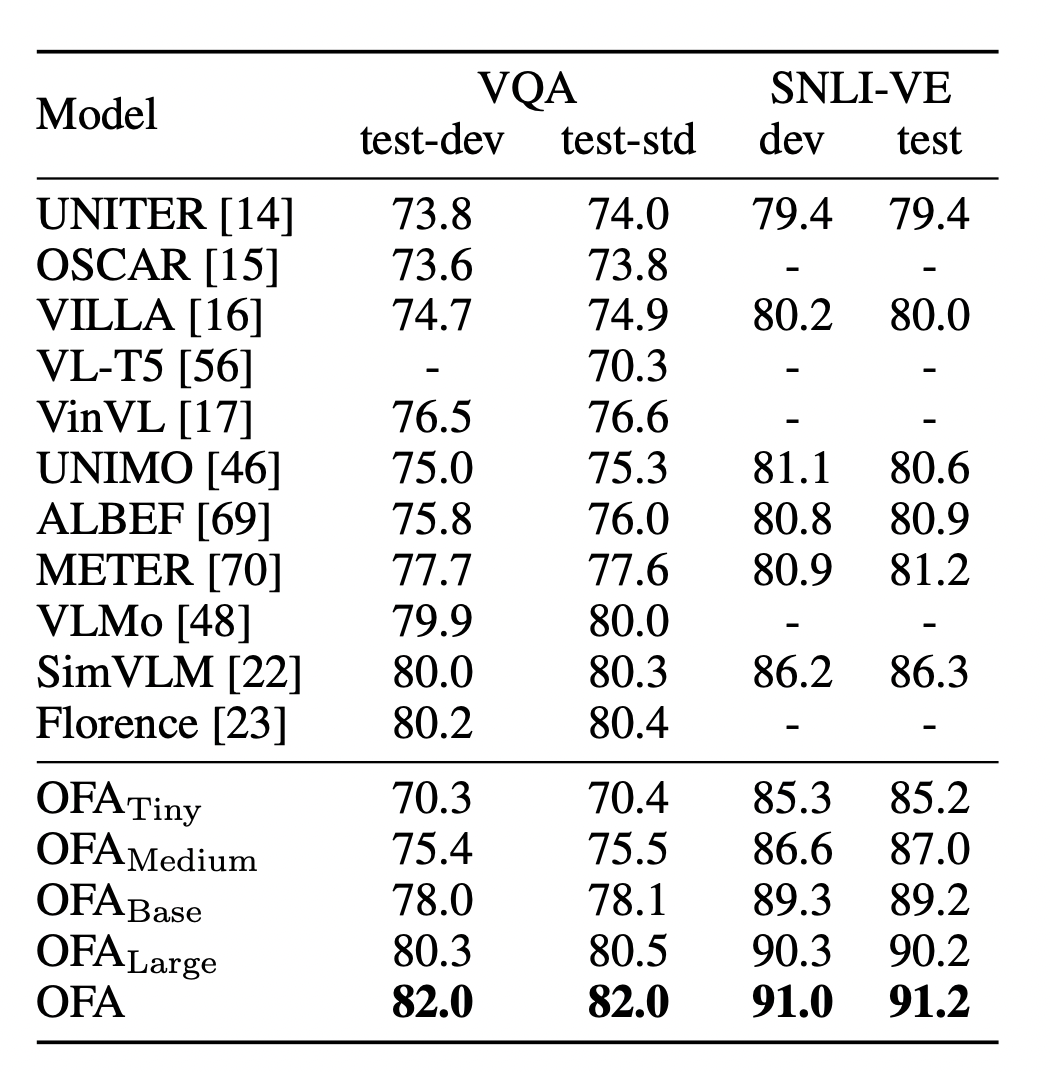
Los resultados experimentales de OFA son bastante sorprendentes, ha logrado el desempeño de SOTA en muchas tareas multimodales, especialmente considerando que todavía es un modelo de paradigma generativo. Para la evaluación de la capacidad de comprensión multimodal, OFA se evaluó en los conjuntos de datos clásicos VQA-v2 y SNLI-VE de respuesta visual a preguntas (VQA) y tareas de razonamiento visual. VQA requiere que el algoritmo seleccione la respuesta correcta de más de 3000 respuestas candidatas en función de una imagen y una pregunta dadas, mientras que el razonamiento visual requiere juzgar la relación entre una imagen dada y el texto. En estas dos tareas desafiantes, OFA ha logrado un rendimiento significativamente mejor que los modelos de preentrenamiento multimodal propuestos anteriormente :
A través de la demostración de la capacidad visual de respuesta a preguntas proporcionada por OFA, también se puede ver que el modelo puede comprender y responder completamente la información de la imagen y las preguntas planteadas por los humanos:
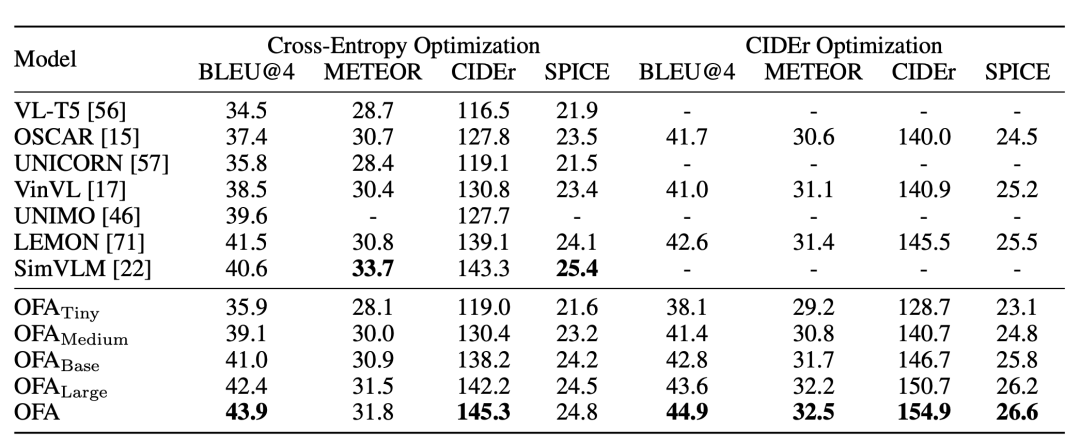
Una tarea típica de la generación multimodal es el subtítulo de imagen (descripción de la imagen), que requiere que el algoritmo genere una descripción correspondiente basada en una imagen dada. En el conjunto de datos clásico MSCOCO de esta tarea, OFA supera significativamente a los modelos anteriores en muchos indicadores de evaluación, y es uno o dos órdenes de magnitud más alto que los datos de preentrenamiento lanzados recientemente y tiene una escala de parámetros más grande que Deepmind Flamingo y Google. y OFA tienen ventajas obvias, y OFA también ocupa el primer lugar en la lista oficial de subtítulos de imágenes de MSCOCO:
https://competitions.codalab.org/competitions/3221#results

En la interfaz interactiva de descripción de la imagen, puede ver que el modelo puede incluso expresar más información que la imagen basada en la imagen, como los Beatles en la imagen, que también muestra el conocimiento aprendido mediante el entrenamiento previo a partir de datos a gran escala. .el papel jugado.
En otra referencia de objeto de tarea multimodal, el modelo necesita encontrar el objeto correspondiente en la imagen de acuerdo con las instrucciones del usuario. En esta tarea, OFA también logró el mejor rendimiento y tiene ventajas obvias. Una de las razones detrás de esto es que el modo de aprendizaje unificado permite que el modelo use otras tareas, como la capacidad de detección de objetos, para mejorar en esta tarea. desempeño de habilidades.

En la pantalla interactiva de la aplicación, se puede ver que el modelo no solo puede identificar con precisión objetos en escenas diarias, sino que incluso puede lograr una identificación precisa en escenas de tráfico complejas, lo que también muestra infinitas posibilidades para la futura implementación de OFA en múltiples escenas. .

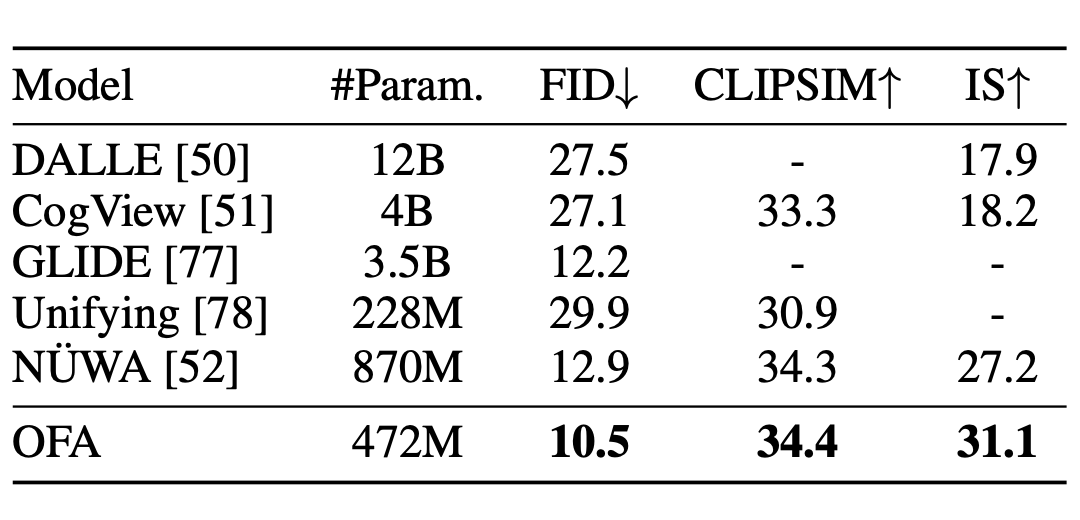
Además, OFA también ha sido evaluado en la tarea de generar imágenes a partir de texto, siendo la primera vez que se aplica un modelo unificado de pre-entrenamiento en este campo. Esta tarea requiere que el modelo de algoritmo genere las imágenes correspondientes de acuerdo con la entrada de texto dada. Es una tarea desafiante garantizar la calidad de la generación de imágenes al mismo tiempo que se garantiza la coherencia semántica. En la evaluación de MSCOCO, OFA también logró un excelente desempeño, superando a GLIDE de OpenAI y NUWA de Microsoft:
En la comparación real de muestras generadas, también se puede ver que en comparación con los modelos públicos GLIDE y Cogview, OFA ha logrado mejores resultados de generación para consultas reales y contrafactuales:

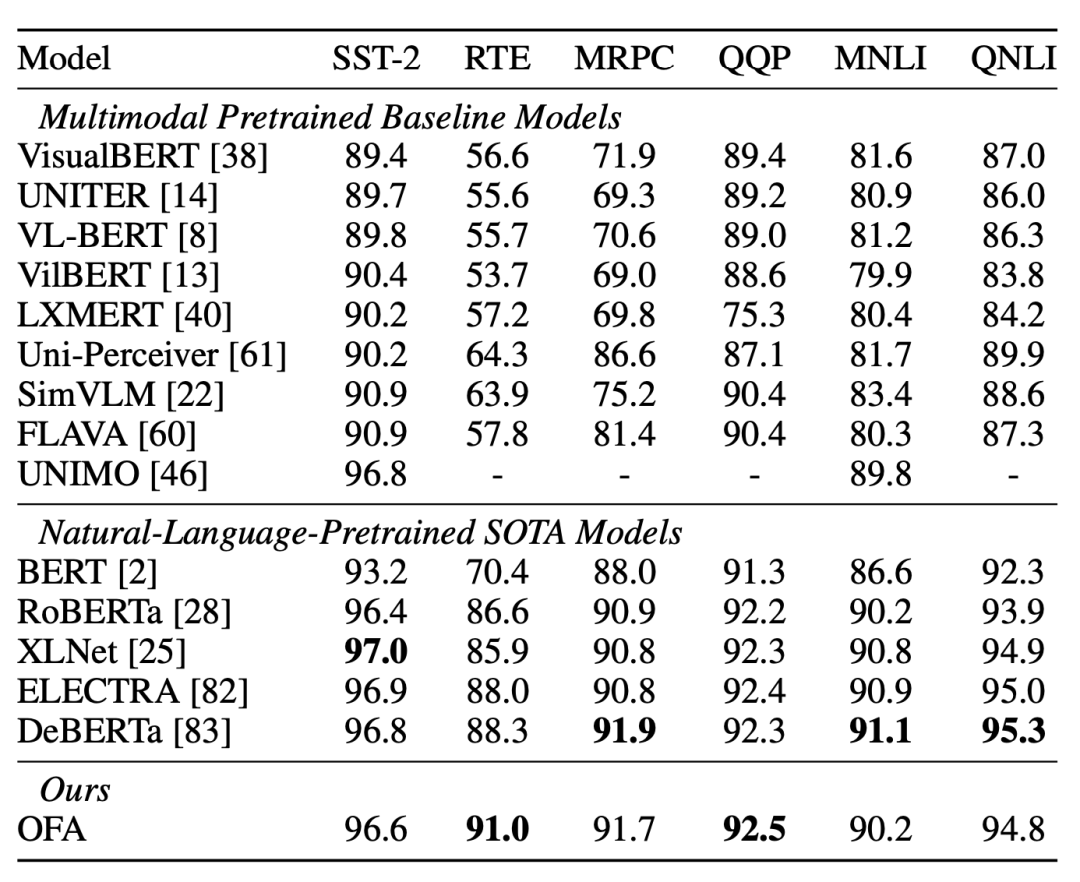
En tareas monomodales, OFA puede lograr el efecto de los modelos de preentrenamiento SOTA en campos de texto sin formato como RoBERTa, XLNET y DeBERTa en GLUE, y en Gigaword para generar resúmenes de texto de tareas, supera a ProphetNet y otros trabajos. actuación. En términos de CV, OFA supera líneas de base como MoCo v3 y DINO en la tarea de clasificación de imágenes de ImageNet y ha logrado un rendimiento comparable a BEiT y MAE. Se puede observar que el modelo OFA con modalidad unificada también puede lograr un rendimiento de alto nivel en tareas monomodales.
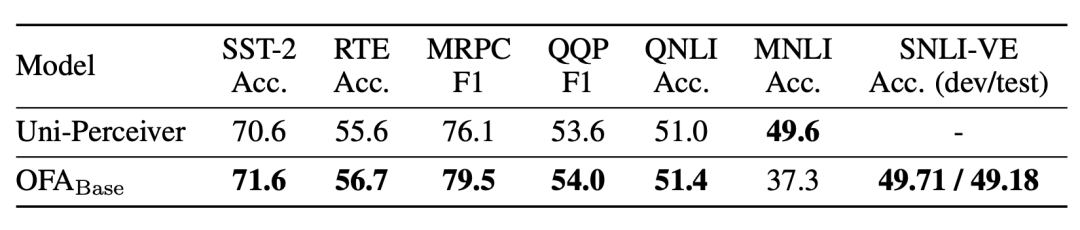
OFA también prueba la capacidad del modelo pre-entrenado para escenarios de aprendizaje de disparo cero y lo prueba en tareas como GLUE y SNLI-VE. El experimento encontró que OFA puede lograr el efecto de Uni-Perceiver más allá del mismo período:
Al mismo tiempo, los investigadores de OFA también encontraron que en tareas desconocidas y datos de dominio desconocidos, el entrenamiento previo del paradigma unificado ayudó a OFA a lograr resultados sobresalientes. Como se muestra en la figura a continuación, el autor diseñó una nueva tarea llamada Grounded QA, es decir, el modelo de algoritmo debe dar una respuesta correcta en función de la imagen de entrada y la posición del objeto dado, así como la pregunta de entrada. El modelo OFA realiza un aprendizaje instantáneo de nuevas tareas en función de su comprensión integral de múltiples tareas, como la respuesta visual a preguntas y el posicionamiento visual:

Para los datos de dominio que no se han visto antes del entrenamiento previo, OFA también puede funcionar bien en esta parte de los datos, lo que también muestra la versatilidad del modelo, como se muestra en la siguiente figura:

El modelo OFA todavía puede dar respuestas correctas cuando se enfrenta a imágenes animadas y escenas de ciencia ficción, aunque apenas ha visto este tipo de imágenes en el set de entrenamiento.
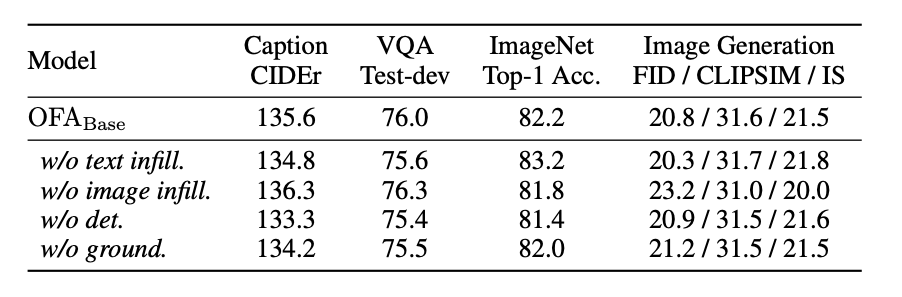
El autor realizó una serie de experimentos de ablación para analizar el impacto de agregar diferentes tareas en el modelo de preentrenamiento. Los experimentos muestran que diferentes tareas previas al entrenamiento en su conjunto pueden traer beneficios para la mejora de los efectos del modelo, lo que indica que el aprendizaje multitarea puede lograr una promoción mutua entre los efectos de la tarea hasta cierto punto. Pero todavía hay algunas excepciones y puede haber conflictos entre tareas. Por ejemplo, para la tarea VQA, el autor descubrió que eliminar la tarea de restauración de imágenes puede generar una mejora significativa en el rendimiento, mientras que para la tarea de clasificación de imágenes, eliminar la tarea de texto sin formato brinda la mayor ganancia.
Ahora, la multitarea se ha convertido gradualmente en una tendencia de investigación. El autor de OFA cree que cómo asignar pesos y secuencias entre tareas, y lograr una programación óptima para lograr el equilibrio de Pareto, también puede ser un tema de investigación importante.
V. Resumen
Con el objetivo de un modelo unificado, Dharma Institute propuso un modelo OFA de pre-entrenamiento multimodal que realiza tres unificaciones principales, es decir, arquitectura unificada, modos unificados y tareas unificadas. Ha logrado SOTA en múltiples tareas multimodales. , y logrado Excelente desempeño también se logra en tareas unimodales. Al mismo tiempo, también se observa que el modelo puede lograr un aprendizaje de disparo cero en tareas no aprendidas y datos de dominio, lo que también muestra el mayor potencial del gran modelo unificado.
En el futuro, una gran cantidad de modelos de aplicaciones se pueden optimizar en función de un modelo básico potente para lograr mejores resultados. Las poderosas capacidades de generación de texto, generación de imágenes e incluso generación de video del modelo básico desempeñarán un papel importante en una gran cantidad de escenarios comerciales, incluidos humanos digitales, diseño de IA y diálogos automáticos de preguntas y respuestas. El modelo grande básico general y unificado también continuará desarrollándose y desempeñará el papel de infraestructura en el campo de la IA. Además, el modelo unificado universal puede lograr la asistencia mutua entre tareas. El futuro modelo de IA logrará el dominio basado en el aprendizaje de tareas múltiples, similar a cómo los humanos pueden lograr una mejora integral de sus propias habilidades a través del aprendizaje de tareas múltiples, y tienen la capacidad de aprender rápidamente nuevas tareas, de modo que la IA ya no dependa de costosos datos de etiquetado a gran escala.
referencia y experiencia
Título del trabajo:
Unificación de arquitecturas, tareas y modalidades a través de un marco de aprendizaje simple de secuencia a secuencia
Dirección en papel:
https://arxiv.org/pdf/2202.03052.pdf
Dirección de código abierto:
https://github.com/OFA-Sys/OFA
Dirección de demostración interactiva:
https://huggingface.co/OFA-Sys