1.1. Introducción al módulo DNN
El módulo de aprendizaje profundo (DNN) en OpenCV solo proporciona funciones de inferencia, no implica entrenamiento de modelos y admite una variedad de marcos de aprendizaje profundo, como TensorFlow, Caffe, Torch y Darknet.

¿Por qué OpenCV implementa un módulo de aprendizaje profundo?
-
Ligero. El módulo DNN solo implementa la función de inferencia, y la cantidad de código y los gastos generales de compilación y operación son mucho menores que otros marcos de modelos de aprendizaje profundo.
-
Fácil de usar. El módulo DNN proporciona aceleración integrada de CPU y GPU sin depender de bibliotecas de terceros. Si OpenCV se usó anteriormente en el proyecto, el módulo DNN puede agregar fácilmente capacidades de aprendizaje profundo al proyecto original.
-
Versatilidad. El módulo DNN admite una variedad de formatos de modelos de red, y los usuarios pueden usarlos directamente sin conversión adicional de modelos de red. La estructura de red admitida cubre las categorías de clasificación de objetivos, detección de objetivos y segmentación de imágenes de uso común, como se muestra en la siguiente figura:

El módulo DNN admite varios tipos de capas de red, que básicamente cubren los requisitos informáticos de red comunes.

2. Introducción a métodos comunes
2.1.dnn.blobFromImage
blobFromImage(img,
scalefactor=None,
size=None,
mean=None,
swapRB=None,
crop=None,
ddepth=None):parámetro:
- imagen: datos de imagen leídos por cv2.imread
- scalefactor: escala el valor del píxel, asumiendo scalefactor = 1/255 y mean = None, significa que el valor del píxel está normalizado al intervalo [0,1], es decir, img = img * scalefactor
- tamaño: el tamaño del blob de salida (imagen), como (netInWidth, netInHeight)
- media: reste el valor medio de cada canal. Ejemplo: cuando mean = (10,20,30), img = (cv2.merge (img [:,:, 0] -10, img [:,:, 1] -20, img [:,:, 2] -30)) * factor de escala
- swapRB: intercambia el primer y último canal de una imagen de 3 canales, como BGR-RGB
- recortar: si la imagen se recorta después de cambiar el tamaño. Si
crop=True, entonces, después de ajustar y redimensionar el tamaño de la imagen de entrada, un lado corresponde a una dimensión de tamaño y el valor del otro lado es mayor o igual que el otro dimensión del tamaño; luego de la imagen redimensionada Recortar en el centro. Sicrop=Falseno necesita recortar, simplemente mantenga la relación de aspecto de la imagen - ddepth: profundidad del blob de salida. Opcional: CV_32F o CV_8U
2.2.dnn.NMSBoxes
Función: realizar el procesamiento NMS (supresión no máxima) de acuerdo con los cuadros de detección dados y las puntuaciones correspondientes
NMSBoxes(bboxes,
scores,
score_threshold,
nms_threshold,
eta=None,
top_k=None)parámetro:
- cuadros: cuadros delimitadores para procesar
- puntuaciones: para procesar las puntuaciones del cuadro delimitador
- score_threshold: el umbral de puntuación utilizado para filtrar cajas
- nms_threshold: umbral utilizado por NMS
- índices: el valor de índice del cuadro delimitador retenido después del procesamiento NMS
- eta: El coeficiente de correlación en la fórmula del umbral adaptativo:
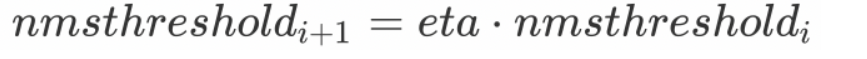
- top_k: si top_k> 0, mantenga como máximo los valores de índice del cuadro delimitador de top_k.
2.3. dnn.readNet
Rol: cargar la red de aprendizaje profundo y los parámetros de su modelo


