1. Optimización de la capa de código
1. Uso directo de variables innecesarias

2. Extraiga los archivos de configuración utilizados en varios lugares a un lugar público.


3. Use conjuntos para manejar múltiples variables

cambie a
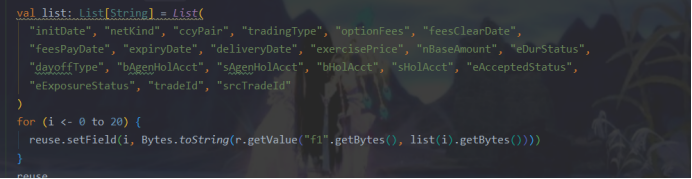
4. Cambie el código redundante

Para:
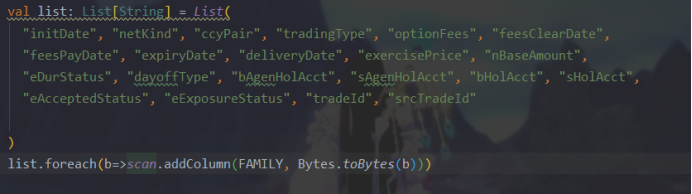
5. Redacción de notas normativas

6. Para el manejo de excepciones, si se captura la captura, se debe manejar, de lo contrario la tarea reportará un error y no hay lugar para consultar

7. La información de configuración se extrae de la clase y se escribe directamente en el archivo de configuración para facilitar la búsqueda y la modificación unificada de la siguiente manera:

2. Optimización de procesos:
-
El paralelismo del operador de la tarea se establece por separado,


2. Escritura de partición de tabla de aterrizaje Hbase, agregar caché para más de 100 W de datos, escritura de actualización por lotes;

3. Nota sobre la optimización de la escritura:

Otra forma de escribir: hive se asigna a los campos recién agregados de hbase en orden lexicográfico. Si está obteniendo datos de hbase, aumente la legibilidad y reduzca el uso de subíndices. De lo contrario, agregar un campo tendrá que coincidir con la posición del subíndice uno por uno.

4. Optimización del entorno operativo
脚本启动:
/opt/flink/bin/flink run -m yarn-cluster -ytm 4g -yjm 2g -ynm sq1_job -c com.yss.optionUnexpired.FlinkMain /opt/sq_project/job/ceshi100w-02.jar -6226220968126435072 30 >/opt/sq_project/log/optionUnexpired.log 2>&1 &Se encuentra que si la unidad está configurada a 90 grados de paralelismo, los recursos estarán ocupados hasta que se aplique el primer trabajo. Cuando se ejecuta el segundo trabajo, ha estado en la etapa de creación y no se puede
agregar a la configuración (predeterminado Núcleo 8G / 1, ysm puede solicitar un máximo de recursos a 8G)
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>24576</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>15</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>24576</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>15</value>
</property>Verifique si el nodo de disco es de 16 núcleos 64G, luego ajústelo a la memoria de 48G o use el script de shell para enviar por lotes
for i in `cat hosts`;do scp /opt/hadoop/etc/hadoop/yarn-site.xml $i:/opt/hadoop/etc/hadoop/yarn-site.xml;done
Finalmente, la situación específica requiere una asignación razonable de slot ytm tjm p de acuerdo con la complejidad del negocio, la cantidad de datos y la situación del clúster. De hecho, la configuración del paralelismo se puede establecer de acuerdo con las diferentes condiciones en el operador, pero el paralelismo máximo está determinado por el [(ranura * datos de jobmanager) * número de nodemanager], el número de jobmanager = (memoria máxima que se puede aplicar para-yjm) / ytm. De hecho, a veces, cuanto más grande es la ranura, mayor es el rendimiento. Los recursos del clúster deben reservarse para almacenes de datos como hbase hive para el almacenamiento en caché. Una vez que la capa de código no se puede optimizar, los recursos del clúster y los recursos operativos deben ser probado y ajustado según la situación real.
5. Optimización del operador interno de Flink
El marco de Flink es muy complejo y proporciona muchas formas de ajustar su ejecución. En este artículo, presentaré cuatro formas diferentes de mejorar el rendimiento de las aplicaciones Flink.
Si no está familiarizado con Flink, puede leer algunos artículos introductorios, como este , este y este . Pero si ya está muy familiarizado con Apache Flink, el contenido descrito en este artículo puede ayudarlo a mejorar la velocidad de ejecución de su aplicación.
1. Usa tuplas de Flink
Cuando se utilizan operaciones como groupBy, join o keyBy, Flink proporciona una variedad de formas para que los usuarios seleccionen la clave principal en el conjunto de datos. El usuario puede utilizar la clave principal para seleccionar la función:
// Unir conjuntos de datos de películas y clasificaciones
movies.join (calificaciones)
// Usa ID de película como clave en ambos casos
.where (new KeySelector <Movie, String> () {
@Anular
public String getKey (Movie m) arroja Exception {
return m.getId ();
}
})
.equalTo (nuevo KeySelector <Rating, String> () {
@Anular
public String getKey (Rating r) arroja Exception {
return r.getMovieId ();
}
})
También puede especificar el nombre del campo en el tipo POJO:
movies.join (calificaciones)
// Usa los mismos campos que en el ejemplo anterior
.donde ("id")
.equalTo ("movieId")
Pero si está utilizando el tipo de tupla de Flink, puede utilizarlo como clave principal simplemente especificando la posición de la tupla de campo:
DataSet <Tuple2 <String, String >> películas = ...
DataSet <Tuple3 <String, String, Double >> ratings = ...
movies.join (calificaciones)
// Especificar las posiciones de los campos en tuplas
.donde (0)
.equalTo (1)
Se puede ver que el rendimiento del último método es el mejor, pero ¿qué hay de la legibilidad? ¿El código ahora se parece al siguiente?
DataSet <Tuple3 <Integer, String, Double >> result = movies.join (ratings)
.donde (0)
.equalTo (0)
.with (new JoinFunction <Tuple2 <Integer, String>, Tuple2 <Integer, Double>, Tuple3 <Integer, String, Double >> () {
// ¿Que está sucediendo aquí?
@Anular
public Tuple3 <Integer, String, Double> join (Tuple2 <Integer, String> primero, Tuple2 <Integer, Double> segundo) lanza Exception {
// Algunas tuplas se unen con otras tuplas y se devuelven algunos campos ???
return new Tuple3 <> (first.f0, first.f1, second.f1);
}
});
En este caso, la forma más común de mejorar la legibilidad es crear una clase que necesite extender la clase TupleX e implementar captadores y definidores para estos campos en la clase. La siguiente es la clase Edge de la biblioteca Flink Gelly, que hereda la clase Tuple3:
La clase pública Edge <K, V> extiende Tuple3 <K, K, V> {
Public Edge (fuente K, destino K, valor V) {
this.f0 = fuente;
this.f1 = objetivo;
this.f2 = valor;
}
// Getters y setters para mejorar la legibilidad
public void setSource (fuente K) {
this.f0 = fuente;
}
public K getSource () {
return this.f0;
}
// También tiene getters y setters para otros campos
...
}
2. Reutiliza objetos Flink
Otra opción que se puede utilizar para mejorar el rendimiento de las aplicaciones Flink es utilizar objetos mutables al devolver datos de funciones definidas por el usuario. Eche un vistazo al siguiente ejemplo:
Arroyo
.apply (new WindowFunction <WikipediaEditEvent, Tuple2 <String, Long>, String, TimeWindow> () {
@Anular
public void apply (String userName, TimeWindow timeWindow, Iterable <WikipediaEditEvent> iterable, Collector <Tuple2 <String, Long >> collector) lanza Exception {
cambios largos Cuenta = ...
// Se crea una nueva instancia de Tuple en cada ejecución
collector.collect (new Tuple2 <> (userName, changesCount));
}
}
Se puede ver que cada vez que se ejecuta la función de aplicación, se creará una nueva instancia de la clase Tuple2, aumentando así la presión sobre el recolector de basura. Una forma de resolver este problema es usar la misma instancia una y otra vez:
Arroyo
.apply (new WindowFunction <WikipediaEditEvent, Tuple2 <String, Long>, String, TimeWindow> () {
// Crea una instancia que reutilizaremos en cada llamada
private Tuple2 <String, Long> resultado = new Tuple <> ();
@Anular
public void apply (String userName, TimeWindow timeWindow, Iterable <WikipediaEditEvent> iterable, Collector <Tuple2 <String, Long >> collector) lanza Exception {
cambios largos Cuenta = ...
// Establecer campos en un objeto existente en lugar de crear uno nuevo
result.f0 = nombre de usuario;
// ¡¡Auto-boxeo !! Se puede crear un nuevo valor largo
result.f1 = changesCount;
// Reutiliza el mismo objeto Tuple2
collector.collect (resultado);
}
}
Este enfoque es mejor. Aunque se crea una nueva instancia de Tuple2 cada vez que se llama, en realidad crea una instancia de la clase Long de forma indirecta. Para resolver este problema, Flink tiene muchas de las llamadas clases de valor: IntValue, LongValue, StringValue, FloatValue, etc. A continuación se explica cómo utilizarlos:
Arroyo
.apply (new WindowFunction <WikipediaEditEvent, Tuple2 <String, Long>, String, TimeWindow> () {
// Crea una instancia de recuento mutable
recuento privado de LongValue = new IntValue ();
// Asignar recuento mutable a la tupla
private Tuple2 <String, LongValue> resultado = new Tuple <> ("", recuento);
@Anular
// Observe que ahora tenemos un tipo de retorno diferente
public void apply (String userName, TimeWindow timeWindow, Iterable <WikipediaEditEvent> iterable, Collector <Tuple2 <String, LongValue >> collector) arroja Exception {
cambios largos Cuenta = ...
// Establecer campos en un objeto existente en lugar de crear uno nuevo
result.f0 = nombre de usuario;
// Actualizar el valor del recuento mutable
count.setValue (changesCount);
// Reutiliza la misma tupla y la misma instancia de LongValue
collector.collect (resultado);
}
}
Este enfoque se usa a menudo en bibliotecas Flink, como Flink Gelly.
3. Utilice la función de anotación
Otra forma de optimizar la aplicación Flink es proporcionar información sobre lo que hará la función definida por el usuario con los datos de entrada. Dado que Flink no puede analizar y comprender el código, puede proporcionar información importante que favorezca la creación de un plan de ejecución más eficaz. Se pueden utilizar las siguientes tres anotaciones:
@ForderedFields: especifique qué campos en el valor de entrada permanecen sin cambios y qué campos se utilizan para la salida.
@NotForderedFields: especifique los campos que no conservan la misma posición en la salida.
@ReadFields: especifique los campos utilizados para calcular el valor del resultado. Los campos especificados solo deben usarse en cálculos, no solo copiarse en parámetros de salida.
Eche un vistazo a cómo usar las anotaciones de ForderedFields:
// Especifica que el primer elemento se copia sin cambios
@ForwardFields ("0")
class MyFunction implementa MapFunction <Tuple2 <Long, Double>, Tuple2 <Long, Double >> {
@Anular
public Tuple2 <Long, Double> map (valor Tuple2 <Long, Double>) {
// Copiar el primer campo sin cambios
devolver nuevo Tuple2 <> (valor.f0, valor.f1 + 123);
}
}
Esto significa que el primer elemento de la tupla de entrada no se ha cambiado y volverá a la misma posición.
Si no cambia el campo, sino que simplemente lo mueve a otra ubicación, también puede usar ForderedFields. En el siguiente ejemplo, intercambiamos los campos en la tupla de entrada y notificamos a Flink:
// El 1er elemento pasa a la 2da posición y el 2do elemento a la 1ra posición
@ForwardFields ("0-> 1; 1-> 0")
clase SwapArguments implementa MapFunction <Tuple2 <Long, Double>, Tuple2 <Double, Long >> {
@Anular
public Tuple2 <Double, Long> map (Tuple2 <Long, Double> valor) {
// Intercambiar elementos en una tupla
devolver nuevo Tuple2 <> (valor.f1, valor.f0);
}
}
Las anotaciones mencionadas anteriormente solo se pueden aplicar a funciones con un solo parámetro de entrada, como map o flatMap. Si la función tiene dos parámetros de entrada, puede utilizar ForderedFieldsFirst y ForderedFieldsSecond para proporcionar información sobre el primer y segundo parámetro, respectivamente.
A continuación, se explica cómo utilizar estas anotaciones en la implementación de la interfaz JoinFunction:
// Se copian dos campos de la tupla de entrada a la primera y segunda posiciones de la tupla de salida
@ForwardFieldsFirst ("0; 1")
// El tercer campo de la tupla de entrada se copia a la tercera posición de la tupla de salida
@ForwardFieldsSecond ("2")
class MyJoin implementa JoinFunction <Tuple2 <Integer, String>, Tuple2 <Integer, Double>, Tuple3 <Integer, String, Double >> () {
@Anular
public Tuple3 <Integer, String, Double> join (Tuple2 <Integer, String> primero, Tuple2 <Integer, Double> segundo) lanza Exception {
return new Tuple3 <> (first.f0, first.f1, second.f1);
}
})
Flink también proporciona anotaciones NotForderedFieldsFirst, NotForderedFieldsSecond, ReadFieldsFirst ReadFirldsSecond, estas anotaciones pueden lograr propósitos similares.
4. Seleccione Tipo de unión
Si le da a Flink otra pista, puede hacer uniones más rápido, pero antes de discutir cómo funciona, analicemos cómo Flink realiza uniones.
Cuando Flink procesa lotes de datos, cada máquina del clúster almacena parte de los datos. Para realizar una combinación, Apache Flink necesita encontrar dos conjuntos de datos que cumplan las condiciones de combinación. Para hacer esto, Flink primero debe colocar los elementos de los dos conjuntos de datos en la misma máquina. Aquí hay dos estrategias:
Estrategia de reparto-distribución : en este caso, los dos conjuntos de datos se separan por sus respectivas claves primarias y se envían a través de la red. Esto significa que si el conjunto de datos es grande, puede llevar mucho tiempo completar la replicación a través de la red.
Estrategia de reenvío de difusión : en este caso, un conjunto de datos no se ve afectado, pero el segundo conjunto de datos se replica en cada máquina del clúster y tienen una parte del primer conjunto de datos.
Si va a unir un conjunto de datos pequeño a un conjunto de datos más grande, puede utilizar una estrategia de reenvío de difusión, que también puede evitar el costoso costo de particionar el primer conjunto de datos. Esto es fácil de hacer:
ds1.join (ds2, JoinHint.BROADCAST_HASH_FIRST)
Esto significa que el primer conjunto de datos es mucho más pequeño que el segundo conjunto de datos.
También puede utilizar otras indicaciones de conexión:
BROADCAST_HASH_SECOND: el segundo conjunto de datos es mucho más pequeño
REPARTITION_HASH_FIRST: el primer conjunto de datos es un poco más pequeño
REPARTITION_HASH_SECOND: el segundo conjunto de datos es más pequeño
REPARTITION_SORT_MERGE: use estrategias de clasificación y combinación para reasignar el conjunto de datos
** OPTIMIZER_CHOOSES: ** Flink optimizer decidirá cómo unirse al conjunto de datos
4. Tenga cuidado de no utilizar el operador de salida para enviar el trabajo en el código.

Estos dos trabajos son en realidad generados por una tarea, y se debe generar un trabajo. Esto conduce a una pérdida de recursos y tiempo para ejecutar los dos trabajos, porque el código usa dataSet.collect (); por supuesto, el tipo de salida print, syso y otros flinks se enviarán varias veces, el código fuente es el siguiente
public void print() throws Exception {
List<T> elements = collect(); //这边也是调用了collect 方法
for (T e: elements) {
System.out.println(e);
}
}public List<T> collect() throws Exception {
final String id = new AbstractID().toString();
final TypeSerializer<T> serializer = getType().createSerializer(getExecutionEnvironment().getConfig());
this.output(new Utils.CollectHelper<>(id, serializer)).name("collect()");
JobExecutionResult res = getExecutionEnvironment().execute(); //重点来了,熟悉么,是它 是它就是他
ArrayList<byte[]> accResult = res.getAccumulatorResult(id);
if (accResult != null) {
try {
return SerializedListAccumulator.deserializeList(accResult, serializer);
} catch (ClassNotFoundException e) {
throw new RuntimeException("Cannot find type class of collected data type.", e);
} catch (IOException e) {
throw new RuntimeException("Serialization error while deserializing collected data", e);
}
} else {
throw new RuntimeException("The call to collect() could not retrieve the DataSet.");
}
}
Referencia: https://www.jianshu.com/p/da9d518017c7