La optimización de la eficiencia de ejecución siempre ha sido el objetivo que persigue Flink. En la mayoría de los trabajos, especialmente en los trabajos por lotes, el costo de transferir datos entre tareas a través de la red (lo que se denomina reproducción aleatoria de datos) es relativamente alto. En circunstancias normales, un dato a través de la red debe pasar por serialización, lectura y escritura de disco, lectura y escritura de socket y deserialización antes de que pueda transmitirse de la tarea ascendente a la descendente; mientras que la transmisión de los mismos datos en la memoria requiere sólo unas pocas CPU, basta con transmitir periódicamente un puntero de ocho bytes.
En la versión anterior de Flink, el mecanismo de encadenamiento de operadores se ha utilizado para integrar los mismos operadores de entrada única adyacentes concurrentes en la misma tarea, eliminando la transmisión de red innecesaria entre operadores de entrada única. Sin embargo, también hay problemas adicionales de reproducción aleatoria de datos entre operadores de múltiples entradas, como unión, y la transmisión de datos entre el nodo de origen con la mayor cantidad de datos aleatorios y el operador de múltiples entradas no se puede optimizar utilizando el mecanismo de encadenamiento del operador.
En Flink 1.12, presentamos múltiples optimizaciones de encadenamiento de fuente y operador de entrada para escenarios que actualmente no pueden ser cubiertos por el encadenamiento de operadores. Esta optimización eliminará la mayoría de las repeticiones redundantes en los trabajos de Flink y mejorará aún más la eficiencia de ejecución de los trabajos. Este artículo tomará un trabajo de SQL como ejemplo para presentar la optimización anterior y mostrar los resultados de Flink 1.12 en el equipo de prueba TPC-DS.
Análisis de casos de optimización: estadísticas de volumen de pedidos
Tomaremos TPC-DS q96 como ejemplo para presentar en detalle cómo eliminar las reorganizaciones redundantes Este SQL está destinado a filtrar y contar pedidos que cumplen condiciones específicas a través de múltiples combinaciones.
select count(*)
from store_sales
,household_demographics
,time_dim, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'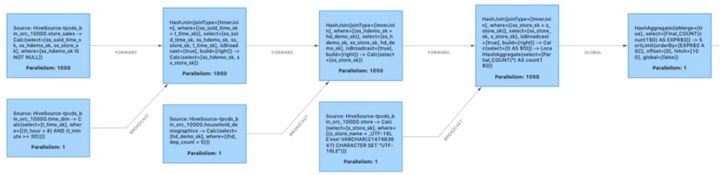
Figura 1-Plan de ejecución inicial
¿Cómo se produce la reproducción aleatoria redundante?
Debido a que algunos operadores tienen requisitos para la distribución de datos de entrada (por ejemplo, el operador de combinación hash requiere el mismo valor hash de la clave de combinación de datos en la misma concurrencia), es posible que los datos deban reorganizarse y ordenarse al pasar entre operadores. Similar al proceso de reproducción aleatoria de map-reduce, Flink shuffle clasifica los resultados intermedios generados por las tareas ascendentes y los envía a las tareas posteriores que necesitan estos resultados intermedios bajo demanda. Sin embargo, en algunos casos, los datos de salida ascendentes ya cumplen con los requisitos de distribución de datos (por ejemplo, varios operadores de combinación hash consecutivos con la misma clave de combinación). En este momento, ya no es necesario organizar los datos y la mezcla resultante También se convierte en una reproducción aleatoria redundante, que está representada por una reproducción aleatoria hacia adelante en el plan de ejecución.
El operador de combinación de hash de la Figura 1 es un operador especial llamado combinación de hash de transmisión. Tome store_sales join time_dim como ejemplo. Dado que la cantidad de datos en la tabla time_dim es muy pequeña, en este momento, la reproducción aleatoria de difusión envía la cantidad completa de datos en la tabla a cada combinación hash concurrente, de modo que cualquier concurrente acepta cualquier dato en la tabla store_sales sin afectar la combinación La corrección de los resultados, al tiempo que mejora la eficiencia de ejecución de la combinación hash. En este momento, la transmisión de red de la tabla store_sales al operador de unión también se convierte en una mezcla redundante. Del mismo modo, no es necesario mezclar entre varias combinaciones.
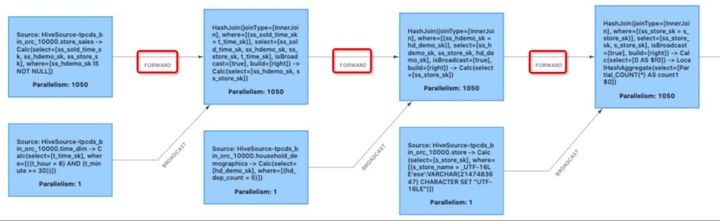
Figura 2: reproducción aleatoria redundante (marcada con un cuadro rojo)
Además de la unión hash y la unión hash de difusión, existen muchos escenarios para generar mezclas redundantes, como agregado hash + unión hash con la misma clave de grupo y clave de unión, múltiples agregados hash con una relación de contención para claves de grupo, etc., que no se ampliará aquí descripción.
¿Puede el encadenamiento de operadores resolverlo?
Los lectores que tengan un cierto conocimiento del proceso de optimización de Flink pueden saber que para eliminar la reproducción aleatoria innecesaria, Flink ha introducido el mecanismo de encadenamiento del operador en la etapa inicial. Este mecanismo integra los mismos operadores de entrada única adyacentes concurrentes en la misma tarea y realiza operaciones juntas en el mismo hilo. El mecanismo de encadenamiento de operadores ya está en efecto en la Figura 1. Sin él, los operadores separados por "->" en los nombres de los tres nodos de origen de la transmisión aleatoria se dividirán en múltiples tareas diferentes, lo que resultará en redundancia en la reproducción aleatoria de datos. La figura 3 muestra el plan de ejecución del encadenamiento de operadores.

Figura 3-Plan de ejecución después de cerrar el encadenamiento del operador
Es una optimización muy eficaz para reducir la transmisión de datos entre TM a través de la red y archivos y fusionar el enlace del operador en la tarea: puede reducir el cambio entre subprocesos, reducir la serialización y deserialización de mensajes y reducir la cantidad de datos en Intercambie y mejore el rendimiento general al tiempo que reduce la latencia. Sin embargo, el encadenamiento de operadores tiene restricciones muy estrictas sobre la integración de operadores. Una de ellas es "el grado de entrada del operador descendente es 1", lo que significa que el operador descendente solo puede tener una entrada. Esto excluye los operadores de entradas múltiples (como unir).
La solución de múltiples operadores de entrada: operador de entrada múltiple
Si podemos imitar las ideas de optimización del encadenamiento de operadores, introduzca un nuevo mecanismo de optimización y cumplamos las siguientes condiciones:
- Este mecanismo puede combinar operadores de entradas múltiples;
- El mecanismo admite múltiples entradas (proporcionando entradas para los operadores que se combinan)
Podemos poner el operador de múltiples entradas conectado con la reproducción aleatoria en una tarea para su ejecución, eliminando así la reproducción aleatoria innecesaria. La comunidad de Flink ha prestado atención a las deficiencias del encadenamiento de operadores hace mucho tiempo. En Flink 1.11, se introdujeron MultipleInputTransformation de la capa de API de transmisión y la correspondiente MultipleInputStreamTask. Estas API cumplen la condición 2 anterior, y Flink 1.12 implementa un nuevo operador que cumple la condición 1 en la capa SQL en este operador de entrada múltiple de base, puede consultar el documento FLIP [1].
El operador de entrada múltiple es una optimización conectable de la capa de la tabla. Se ubica en el último paso de la optimización de la capa de tabla, atravesando el plan de ejecución generado e integrando operadores adyacentes que no están bloqueados por intercambio en un operador de entrada múltiple. La Figura 4 muestra la modificación de la optimización al paso de optimización de SQL original.
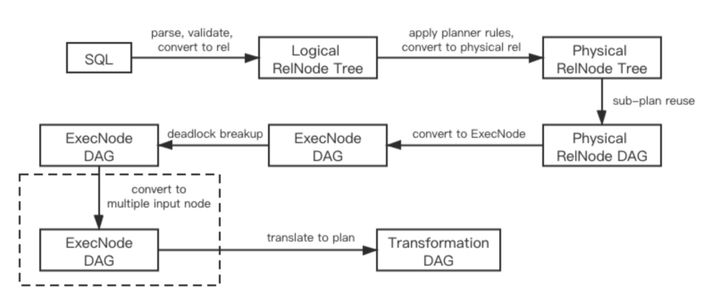
Figura 4-Pasos de optimización después de agregar un operador de entrada múltiple
Los lectores pueden tener preguntas: ¿Por qué no modificar el encadenamiento de operadores existente y comenzar de nuevo? De hecho, además de completar el encadenamiento de operadores, varios operadores de entrada también necesitan ordenar la prioridad de cada entrada. Esto se debe a que algunos operadores de entradas múltiples (como la combinación de hash y la combinación de bucle anidado) tienen restricciones estrictas de orden en la entrada. Si la prioridad de entrada no está ordenada correctamente, puede causar un punto muerto. Dado que la información de la prioridad de entrada del operador solo se describe en el operador de la capa de la tabla, una forma más natural es introducir el mecanismo de optimización en la capa de la tabla.
Vale la pena señalar que el operador de entrada múltiple es diferente del encadenamiento de operadores que maneja múltiples operadores, es en sí mismo un gran operador y su operación interna es una caja negra del mundo exterior. La estructura interna del operador de entrada múltiple se refleja completamente en el nombre del operador.Los lectores pueden ver en el nombre del operador qué operadores se combinan en el operador de entrada múltiple en qué topología cuando se ejecuta un trabajo que contiene el operador.
La figura 5 muestra el diagrama topológico del operador optimizado por entrada múltiple y el diagrama en perspectiva del operador de entrada múltiple. Una vez que se eliminan las combinaciones redundantes entre los tres operadores de combinación hash en la figura, se pueden ejecutar en una tarea, pero el encadenamiento del operador no puede manejar esta situación de múltiples entradas. Colóquelos en el operador de entrada múltiple Ejecución, el operador de entrada múltiple administra el secuencia de entrada de cada operador y la relación de llamada entre los operadores.

Figura 5: topología del operador después de la optimización de múltiples entradas
La construcción y operación del operador de entrada múltiple es más complicada, los lectores interesados en este detalle pueden consultar el documento de diseño [2].
La fuente no se puede perder: encadenamiento de fuentes
Después de la optimización del operador de entrada múltiple, optimizamos el plan de ejecución en la Fig. 1 a la Fig. 6, y la Fig. 3 se convierte en el gráfico de ejecución de la Fig. 6 después de la optimización por el encadenamiento del operador.
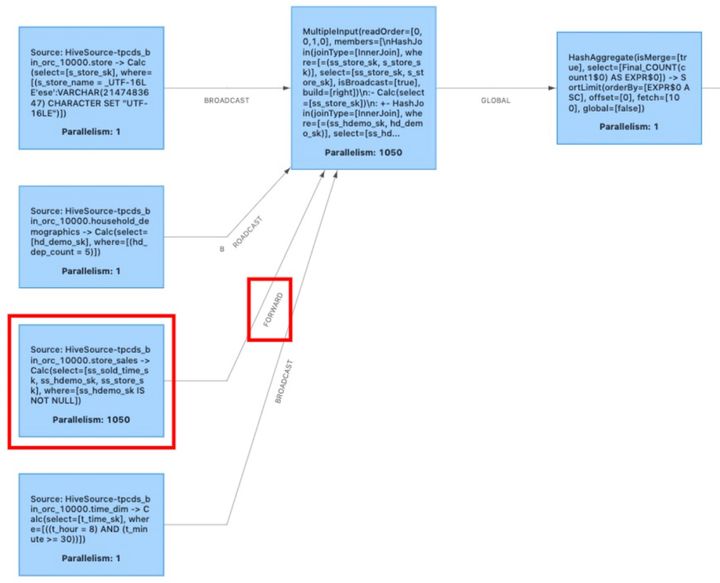
Figura 6-Plan de ejecución optimizado por operador de entrada múltiple
La reproducción aleatoria (que se muestra en el cuadro rojo) generada a partir de la tabla store_sales en la Figura 6 indica que todavía tenemos espacio para la optimización. Como se mencionó en el preámbulo, en la mayoría de las operaciones, los datos generados directamente desde la fuente no son filtrados ni procesados por operadores como join, y la cantidad de datos en orden aleatorio es la mayor. Tomando el TPC-DS q96 con datos 10T como ejemplo, si no se realiza ninguna optimización adicional, la tarea que contiene la tabla de origen store_sales transmitirá 1.03T de datos a la red, y después de una selección de combinación, el volumen de datos cae rápidamente a 16.5 GRAMO. Si podemos omitir la reproducción aleatoria hacia adelante de la tabla de origen, la eficiencia de ejecución general del trabajo puede dar un gran paso adelante.
Desafortunadamente, el operador de entrada múltiple no puede cubrir el escenario de reproducción aleatoria de fuentes, porque la fuente es diferente de cualquier otro operador en que no tiene entrada. Por esta razón, Flink 1.12 agrega una función de encadenamiento de fuente al encadenamiento del operador, que fusiona la fuente que no está bloqueada por la mezcla con el encadenamiento del operador, eliminando la mezcla hacia adelante entre la fuente y el operador aguas abajo.
Actualmente, solo la fuente FLIP-27 y el operador de entrada múltiple pueden usar la función de encadenamiento de fuentes, pero esto es suficiente para resolver el escenario de optimización en este artículo.
Después de combinar el operador de entrada múltiple y el encadenamiento de fuentes, la Figura 7 muestra el plan de ejecución final del caso de optimización en este artículo.

Figura 7-Plan de ejecución optimizado
Resultados de la prueba TPC-DS
El operador de entrada múltiple y el encadenamiento de origen tienen efectos de optimización significativos en la mayoría de los trabajos, especialmente en los trabajos por lotes. Usamos el equipo de prueba TPC-DS para probar el rendimiento general de Flink 1.12. En comparación con el tiempo total de 12267s anunciado por Flink 1.10, el tiempo total de Flink 1.12 fue de solo 8708s, lo que acortó el tiempo de ejecución en casi un 30%.
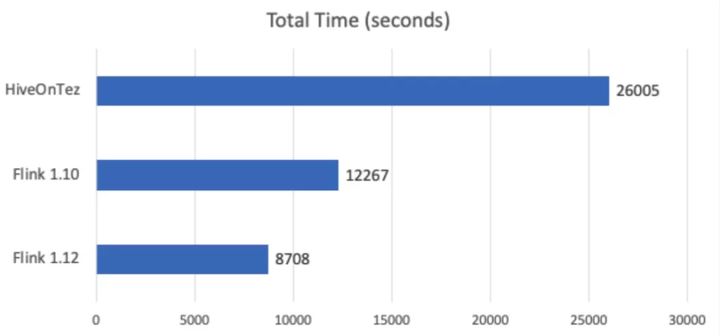
Figura 8-Comparación del tiempo total del equipo de prueba TPC-DS
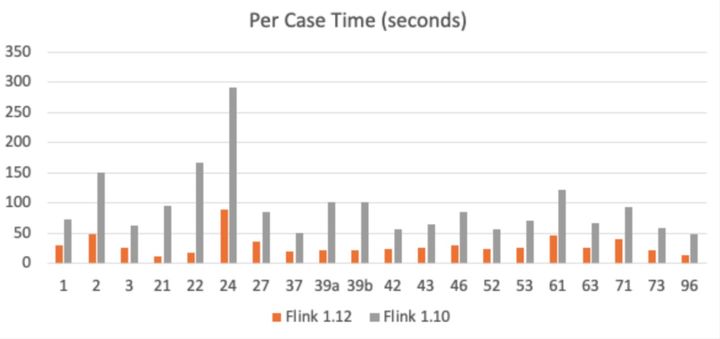
Figura 9-Comparación de tiempo de algunos puntos de prueba de TPC-DS
Plan futuro
A través de los resultados de las pruebas de TPC-DS, podemos ver que el encadenamiento de fuentes + entrada múltiple puede brindarnos una gran mejora en el rendimiento. En la actualidad, se ha completado el marco general y los operadores por lotes de uso común han respaldado la lógica de derivación para eliminar los intercambios redundantes. Apoyaremos más operadores por lotes y algoritmos de derivación más refinados en el futuro.
Aunque la reproducción aleatoria de datos de un trabajo de transmisión no necesita escribir datos en el disco como un trabajo por lotes, la mejora del rendimiento que aporta la transmisión de red a una transmisión de memoria también es muy impresionante. Por lo tanto, el trabajo de transmisión que admite el encadenamiento de origen + entrada múltiple es también muy irritante Optimización esperada. Al mismo tiempo, se requiere mucho trabajo para respaldar esta optimización en trabajos de flujo. Por ejemplo, la lógica de derivación para eliminar intercambios redundantes en operadores de flujo aún no se admite, y algunos operadores deben reconstruirse para eliminar el requisito de que el los datos de entrada son binarios, etc. Es por eso que Flink 1.12 aún no ha introducido el motivo de esta optimización en el trabajo de transmisión. En versiones posteriores, completaremos gradualmente estas tareas y esperamos que más fuerzas de la comunidad se unan a nosotros para implementar más optimizaciones lo antes posible.
Autores | He Xiaoling, Weng Caizhi
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.