Clasificación de flores de iris basada en el algoritmo KNN de sklearn
Descarga del conjunto de datos: GitHub
Directorio de artículos
1. Preparación de datos
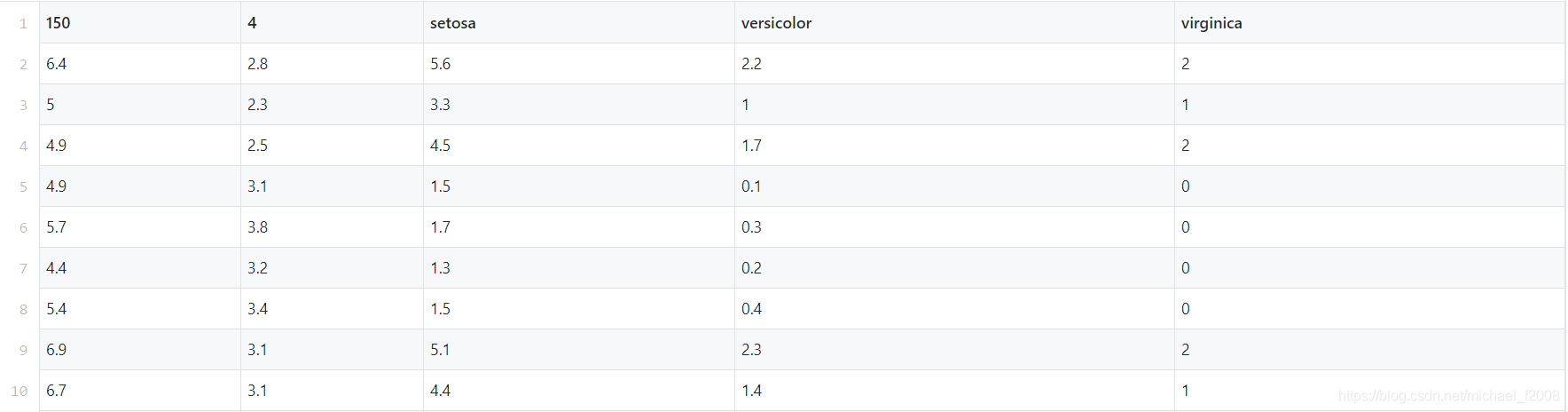
Para los problemas de clasificación de aprendizaje, el conjunto de datos del iris es un ejemplo más utilizado. Este artículo utiliza datos originales, un total de 150 datos válidos, el contenido y formato no han sido modificados.
Las primeras 10 filas de datos son las siguientes:
2. Importar varios paquetes
Incluyendo varios paquetes de pandas y sklearn:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
3. Divida el conjunto de entrenamiento y el conjunto de prueba.
Primero, extraiga las primeras cuatro columnas del conjunto de datos como características y la última columna como etiqueta de clasificación; luego, use train_test_split()las características y etiquetas para dividir aleatoriamente el conjunto de entrenamiento y la prueba. Aquí, establezca la proporción del conjunto de prueba en 20 %, que es 30 Bar; Finalmente, convierta las etiquetas del conjunto de entrenamiento y el conjunto de prueba en una matriz unidimensional (no es posible la conversión, solo para la comodidad de la visualización).
# 读取数据
iris_data_set = pd.read_csv("D:\\iris.csv")
# x是4列特征
x = iris_data_set.iloc[:, 0:4].values
# y是1列标签
y = iris_data_set.iloc[:, -1].values
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 将特征转为一维数组
y_train = y_train.flatten()
y_test = y_test.flatten()
4. Entrene el modelo y prediga
Primero, el KNeighborsClassifier()modelo de algoritmo KNN se establece llamando a la función, donde el n_neighbors=3valor de K se establece en 3; luego, las características del conjunto de entrenamiento y la etiqueta de clasificación se ingresan para el entrenamiento; finalmente, las características del conjunto de prueba se aplican a el modelo para clasificar y obtener el resultado de la clasificación.
# 建模
knn_model = KNeighborsClassifier(n_neighbors=3)
# 训练
knn_model.fit(x_train, y_train)
# 预测
y_pre = knn_model.predict(x_test)
5. Salida de resultados y análisis
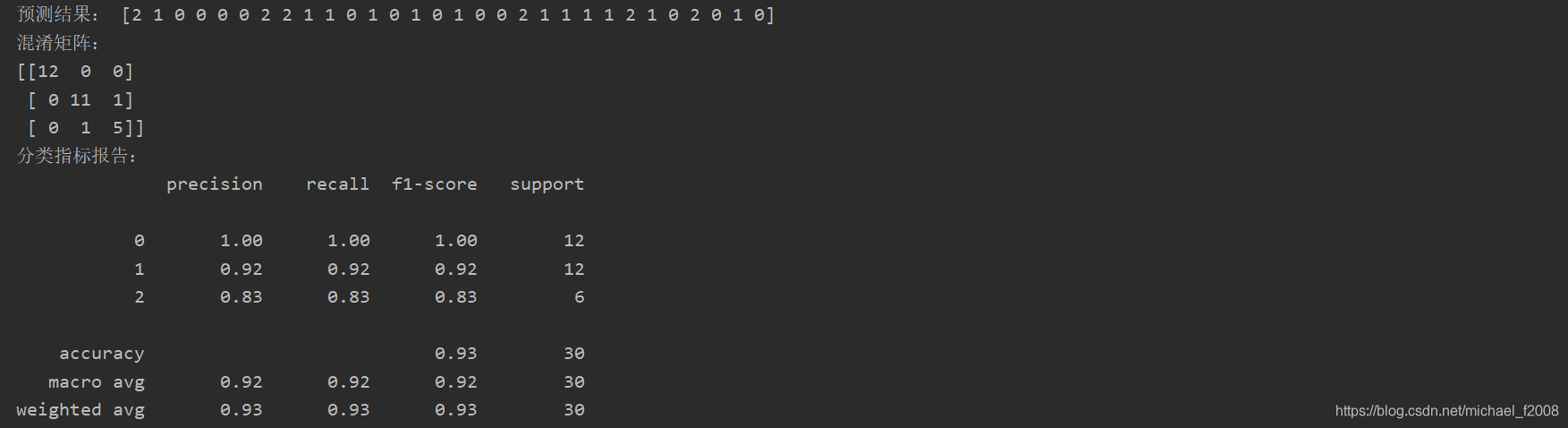
Imprima la clasificación real del conjunto de prueba y la clasificación predicha por el modelo para una comparación intuitiva.
La matriz de confusión es una base importante para evaluar los pros y los contras del modelo de clasificación, y confusion_matrix()la matriz de confusión del modelo se puede devolver llamándola .
El modelo de clasificación de evaluación tiene muchos indicadores, que se classification_report()pueden generar a través de funciones.
print("正确标签:", y_test)
print("预测结果:", y_pre)
# 混淆矩阵
conf_mat = confusion_matrix(y_test, y_pre)
print(conf_mat)
# 分类指标文本报告(精确率、召回率、F1值等)
print(classification_report(y_test, y_pre))
El resultado final es el siguiente:
6. Resumen
Se puede ver que, según la API de sklearn, puede realizar fácilmente la división de conjuntos de datos, la construcción de modelos, el entrenamiento de modelos y la predicción de clasificación sin escribir demasiado código, y también puede calcular los indicadores de clasificación del modelo.
El código completo es el siguiente:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
# 读取数据
iris_data_set = pd.read_csv("D:\\iris.csv")
# x是4列特征
x = iris_data_set.iloc[:, 0:4].values
# y是1列标签
y = iris_data_set.iloc[:, 4:].values
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 将特征转为一维数组
y_train = y_train.flatten()
y_test = y_test.flatten()
# 建模、训练、预测
knn_model = KNeighborsClassifier()
knn_model.fit(x_train, y_train)
y_pre = knn_model.predict(x_test)
print("正确标签:", y_test)
print("预测结果:", y_pre)
# 混淆矩阵
conf_mat = confusion_matrix(y_test, y_pre)
print(conf_mat)
# 分类指标文本报告(精确率、召回率、F1值等)
print(classification_report(y_test, y_pre))
Aprendizaje extendido
- Clasificación del iris de Python basada en la red neuronal BP
- Comprensión del indicador de problema de clasificación de aprendizaje automático: exactitud, precisión, recuperación, puntaje F1, curva ROC, curva PR, área AUC
- Visualización de datos multidimensionales de Python
Bienvenido a seguir mi cuenta pública de WeChat:
